
On using Markov Decision Processes to Model Integration Solutions
for Disparate Resources in Software Ecosystems
Rafael Z. Frantz
1
, Sandro Sawicki
1
, Fabricia Roos-Frantz
1
, Iryna Yevseyeva
2
and Michael Emmerich
3
1
UNIJUÍ University, Department of Exact Sciences and Engineering, Ijuí, Brazil
2
Newcastle University, School of Computing Science, Newcastle, U.K.
3
Leiden University, Leiden Institute of Advanced Computer Science, Leiden, The Netherlands
Keywords:
Simulation, Enterprise Application Integration, Domain-Specific Language, Markov Decision Process.
Abstract:
The software ecosystem of an enterprise is usually composed of an heterogeneous set of applications,
databases, documents, spreadsheets, and so on. Such resources are involved in the enterprise’s daily activ-
ities by supporting its business processes. As a consequence of market change and the enterprise evolution,
new business processes emerge and the current ones have to be evolved to tackle the new requirements. It is
not a surprise that different resources may be required to collaborate in a business process. However, most of
these resources were devised without taking into account their integration with the others, i.e., they represent
isolated islands of data and functionality. Thus, the goal of an integration solution is to enable the collabo-
ration of different resources without changing them or increasing their coupling. The analysis of integration
solutions to predict their behaviour and find possible performance bottlenecks is an important activity that
contributes to increase the quality of the delivered solutions. Software engineers usually follow an approach
that requires the construction of the integration solution, the execution of the actual integration solution, and
the collection of data from this execution in order to analyse and predict their behaviour. This is a costly, risky,
and time-consuming approach. This paper discusses the usage of Markov models for formal modelling of
integration solutions aiming at enabling the simulation of the conceptual models of integration solutions still
in the design phase. By using well-established simulation techniques and tools at an early development stage,
this new approach contributes to reduce cost, risk, development time and improve software quality attributes
such as robustness, scalability, and maintenance.
1 INTRODUCTION
Enterprises rely on integration solutions to support
their business processes by promoting the reuse
of resources available in their software ecosys-
tem (Messerschmitt and Szyperski, 2003), which is
usually composed of an heterogeneous set of applica-
tions, databases, documents, spreadsheets, and so on.
The success of such business processes is highly de-
pendent on the correct and efficient execution of the
integration solutions. All over the years, several tech-
nologies have emerged to support the development
of integration solutions, chiefly by providing method-
ologies and tools to design, implement, and run in-
tegration solutions. The state-of-the-art technologies
have been pushing the development of integration so-
lutions from a code centric to a model centric ap-
proach, by providing domain-specific languages that
enable the design of conceptual models at a high level
of abstraction. In this paper we are interested in the
analysis of the conceptual models designed for inte-
gration solutions using the domain-specific language
of Guaraná technology. The goal of an integration
solution is to enable the collaboration of different re-
sources that were devised without taking into account
their integration with the others, i.e., they represent
isolated islands of data and functionality. Thus, an in-
tegration solution enables data synchrony and the de-
velopment of new functionalities on top of the actual
resources (Hohpe and Woolf, 2003).
The analysis of integration solutions to predict
their behaviour and find possible performance bot-
tlenecks is an important activity that contributes to
increase the quality of the delivered solutions. It is
not enough to design a conceptual model for an in-
tegration solution, but it is also essential to analyse
its behaviour under different workloads and minimise
performance bottlenecks. Most often, the approach
260
Z. Frantz R., Sawicki S., Roos-Frantz F., Yevseyeva I. and Emmerich M..
On using Markov Decision Processes to Model Integration Solutions for Disparate Resources in Software Ecosystems.
DOI: 10.5220/0005346902600267
In Proceedings of the 17th International Conference on Enterprise Information Systems (ICEIS-2015), pages 260-267
ISBN: 978-989-758-097-0
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

adopted by software engineers requires the construc-
tion of the integration solution, the execution of the
actual integration solution, and the collection of data
from this execution. This is a costly, risky, and time-
consuming approach. The construction of integra-
tion solutions is expensive because it demands a good
command on an integration technology to map the
conceptual model into executable code. The execu-
tion involves the setup of a controlled environment in
which the integration solution can be deployed, the
generation and injection of input data into the inte-
gration solution, and the emulation of critical running
scenarios. Any faults in the constructed solution may
cause the execution to fail and negatively affect the
analysis. The collection of data requires the insertion
of extra code into the constructed integration solution
and the configuration of the runtime system of the
adopted integration technology that enables monitor-
ing and data collection. A new approach that enables
the analysis of the behaviour and discovering possi-
ble performance bottlenecks still in the design phase,
taking as input the conceptual models of integration
solutions, would help to reduce cost, risk, and devel-
opment time.
In this context, enterprise integration solutions
shall be understood as discrete event systems. Dis-
crete models are event-oriented and so used to model
systems that change their state at discrete moments in
time according to the occurrence of events. Integra-
tion solutions can be characterised as discrete systems
for the reason that all components involved in an inte-
gration solution consume a particular execution time
when an event occurs. Thus, any event can change the
state of the integration solution.
As a discrete system, the conceptual model de-
signed for an integration solution can be simulated
taking the advantage of well-established techniques
and tools for discrete-eventsimulation. It would allow
software engineers to focus on performance measures
that allow for discovering possible problems before
deploying the integration solution into production and
the commitment of capital and resources. The simu-
lation of integration solutions would help to prevent
unexpected behaviours and cut down cost, risk, and
time to deliver better integration solutions.
High-level state-based modelling languages avail-
able in the integration technologies provide descrip-
tion syntaxes for model construction, ability to com-
pute the reachable state space, indication if specific
properties are satisfied by the model and other quan-
titative results relevant to identify interesting patterns
or trends in the behaviour of a system. Model check-
ing, simulation and experiments configuration sup-
port allows for the analysis of system properties as
functions of model and property parameters. In this
paper we discuss the use of Markov models for formal
modelling of integration solutions, chiefly Markov
Decision Process models, which allow for both prob-
abilistic and nondeterministic modelling.
The rest of this paper is organised as follows: Sec-
tion 2 discusses the related work that has also used
discrete-event simulation to analyse the behaviour
and discover possible performance bottlenecks in ac-
tual systems; Section 3, provides an overview of
Guaraná domain-specific language that we use to de-
sign the integration solution conceptual models; Sec-
tion 4, discusses the use of Markov models to enable
simulation of discrete systems; Section 5 presents a
case study in which we introduce a conceptual model
designed using Guaraná and its corresponding formal
model using Markov Decision Process; and, finally,
Section 6 presents our main conclusions.
2 RELATED WORK
There are some previous work in the literature that
have used discrete-event simulation techniques and
tools to analyse systems to predict their behaviour and
find possible performance bottlenecks. Nevertheless,
from the literature there is no evidence that discrete-
event simulation has been explored aiming at the anal-
ysis of conceptual models of enterprise integration so-
lutions. There is a work that has used discrete-event
simulation in the field of enterprise integration, how-
ever in this work Janssen and Cresswell (2005) fo-
cus on organisational issues and the interests of stake-
holders, by providing a simulation-based methodol-
ogy to evaluate the impact of enterprise integration
at business level before its implementation. They ar-
gue that the commitment of stakeholders is one of
the keys for the success of enterprise integration, and
thus make stakeholders central to their methodology.
Their research analyses integration problems only in
the context of public organisations, in which they use
discrete-event simulation to quantify the benefits that
the integration could bring to the organisation at busi-
ness level. The proposal presented in this paper dif-
fers from theirs since its focus is on the infrastructure
technology used to design and implement integration
solutions.
Simulation has also been studied in the context of
business processes (van der Aalst, 2010; van der Aalst
et al., 2010; van der Aalst, 2015; Rozinat et al., 2009).
Recently, in van der Aalst (2015) the author discusses
potential pitfalls involved in the traditional simula-
tion approaches, which can lead to bad results. He
proposes the use of simulation as an analysis tool for
OnusingMarkovDecisionProcessestoModelIntegrationSolutionsforDisparateResourcesinSoftwareEcosystems
261

business process management and the construction of
simulation (formal) models using mining techniques,
which take as input real event data. In van der Aalst
(2010), the author argues that the use of simulation is
often limited in real world and typically fails in com-
panies. He then discusses the limitations and point
out his ideas to overcome the problem. In van der
Aalst et al. (2010), the authors go deep and study the
problem of modelling in a naive manner the behaviour
of resources involved in a business process. In Roz-
inat et al. (2009), the authors now focus on the use
of process mining techniques based on process his-
toric data that would help, for instance, to evaluate
the performance of different alternative designs. In
our context we do not have real event data, since the
simulation models have to be created during the de-
sign phase of the integration solution, in which there
is no constructed solution yet. We aim at building a
simulation model from an application integration con-
ceptual model, so that the conceptual model can be
analysed and possibly improved to solve performance
problems.
Al-Aomar (2010), describes the basic structure of
service system simulation using application case stud-
ies targeting the performance of the service system.
The author identifies and defines the main characteris-
tics and elements of service system as system entities,
service providers and customer service. In addition,
he explores the modelling techniques that are used in
the development of discrete-event simulation models
targeting service systems. This work considers model
elements, model logic, model data, model parameters,
decision variables, and performance measures in its
case studies simulation. The number of entities that
arrive in the specified time interval is a random vari-
able that follows Poisson distribution. Arrival rates
and service rates are essential to calculate system per-
formance measures. In this study the author collects
the arrival and service rates, which are attributes used
to represent customers arriving at a service centre.
For example, for each customer, the times of arrival,
service start, and service end are calculated. Having
these times collected, the Time Between Arrival and
Service Time can also be computed. Time Between
Arrival is the time since last arrival and Service Time
is the total time used by a service. After, Mean Time
Between Arrivals and Mean Service Time are used to
compute the average time. By using this strategy to
collect inter-arrival and service times, it is possible to
find bottlenecks located at services and queues.
The article presented by Desa et al. (2013),
demonstrates the potential of discrete-event simula-
tion for detecting bottlenecks. The authors developed
a discrete-event simulation model based on the logic
and using data collected from a manufacturing plant
specialised in producing aircraft parts. In this work,
the detection of bottlenecks was based on resource
utilisation and work in process. Arena simulation
software was employed to model and analyse the sev-
eral activities. With the model proposed in this study,
it was possible to understand and improve the perfor-
mance of the production system; furthermore, it was
found that the discrete-event simulation is capable of
analysing the behaviour of complex and sophisticated
systems. Kunz et al. (2011) present a performance
prediction methodology that calculates the best possi-
ble performancebound for expanded parallel discrete-
event simulations. According to the authors, predict-
ing and analysing runtime performance features and
understanding its behaviour is an important step in the
development process of parallel discrete-event simu-
lations. Their methodology is based on linear pro-
gramming that calculates an optimal event execution
schedule for a given simulation and a set of micro-
processors. They use linear programming for predict-
ing the runtime performance of a parallel simulation
model. A trace is used to the linear program that
computes an optimal event schedule targeting to min-
imise the overall simulation runtime. Discrete-event
simulation model can also be used to an automated
bottleneck analysis to detect running production con-
straints. Faget et al. (2005) present a case study that
was conducted in Toyota Company. The authors de-
scribe the application of a method for detecting bottle-
necks using discrete-event models and design of ex-
periments to suggest improvement alternatives. They
also report that the main challenge was to educate the
decision makers about the importance of simulation
as a support tool to analyse the behaviour of produc-
tion systems. The results obtained with the simulation
had better accuracy in bottleneck analysis and provide
useful information for improvements.
3 GUARANÁ TECHNOLOGY
Guaraná technology supports software engineers in
the design, implementation, and execution of integra-
tion solutions. Since the focus of this paper is on the
simulation of conceptual models, this section aims to
provide a brief overview of the modelling language
provided by this technology. In Guaraná, the concep-
tual models are designed using a domain-specific lan-
guage, which has an easy-to-learn and intuitive graph-
ical notation. This language is based on the integra-
tion patterns documented by Hohpe and Woolf (2003)
and enables the design of platform-independent mod-
els, i.e., the resulting models are not committed to a
ICEIS2015-17thInternationalConferenceonEnterpriseInformationSystems
262

Table 1: Guaraná concrete syntax.
Concept
Notation
X
particular implementation technology (Frantz et al.,
2010). The following integration concepts are sup-
ported by constructors in Guaraná language:
Message: An abstraction of a piece of information
that is exchanged and transformed across an in-
tegration solution. It is composed of a header, a
body, and one or more attachments. The header
includes custom properties and frequently the fol-
lowing pre-defined properties: message identi-
fier, correlation identifier,sequence size, sequence
number, return address, expiration date, and mes-
sage priority. The body holds the payload data,
whose type is defined by the template parameter
in the message class. Attachments allow mes-
sages to carry extra pieces of data associated with
the payload, e.g., an image or an e-mail message.
Task: Represents an atomic operation that can be
executed on messages, such as split, aggregate,
translate, chop, filter, correlate, merge, rese-
quence, replicate, dispatch, enrich, slim, promote,
demote, and delay. Roughly speaking, a task may
have one or more inputs from which it receives
messages, and one or more outputs by means of
which messages depart. Depending on the kind of
operation, a task may be stateless or stateful. In a
stateless task, the completion of its operation does
not depend on previous or future messages; con-
trarily, the operation of a stateful task depends on
previous or future messages to be completed, such
as the case of the aggregator task, which has to
collect the different correlated inbound messages
to produce a single outbound message. In this pa-
per, stateful tasks are not considered because the
vast majority of tasks in Guaraná technology are
stateless.
Slot: A buffer connecting an input of one task to
the output of another task aiming at messages to
be processed asynchronously by tasks. A slot
can follow different policies to serve messages to
tasks, such as a priority-based output or a first-
come, first-served. If a priority is defined in the
message, slots follow the former policy; other-
wise, the latter policy is adopted. In this paper,
it is assumed that messages have no priority and
the slot serves them in a first-come, first-served
policy.
Port: Abstracts away from the details required to
interact with an resources within the software
ecosystem. Roughly speaking, by means of a port
it is possible to establish read, write, solicit, and
respond communication operations with the re-
sources being integrated.
Integration Process: Contains integration logic
that executes transformation, routing, modifica-
tion, and time-related operations over messages.
An integration process is composed of ports that
allow it to communicate with the resources being
integrated, slots and a set of tasks to specify the
integration logic.
Conceptually, an integration solution aggregates
one or more integration processes through which mes-
sages flow and are processed asynchronously. The
integration flow is actually implemented as a Pipe
and Filter architecture, in which the pipes are im-
plemented by Slots and the filters are implemented
by Tasks. Every task realises an integration pat-
tern (Hohpe and Woolf, 2003) and its execution de-
pends on the availability of messages in all slots con-
nected to its inputs. Slots are key constructors to en-
able asynchrony in an integration solution, thus mes-
sages are stored on them until they can be read by the
next task in the integration flow. A detailed discussion
on the domain-specific language provided by Guaraná
is presented by the authors in Frantz et al. (2011).
Table 1 shows the concrete syntax for the con-
structors in Guaraná. Since the domain-specific lan-
guage of Guaraná provides support to several integra-
tion patterns, the symbol that we depict in Table 1
to represent them is generic. Note the small rounded
connectors on the sides of the icon; they represent the
inputs and the outputs. Slots are connected to tasks
using these rounded connectors. Note that, in this
table we have included the notation we use to rep-
resent the resources (such as applications, databases,
documents, and spreadsheets) being integrated. In
the table, this notation does not specify which layer
(database, channel, file, API, user interface, and so
on) is being used to communicate the integration solu-
tion to the resource. However, software engineers can
replace the doted circle containing an “X” by well-
known icons, cf. Figure 1. Messages do not appear in
this table, because they are not part of the conceptual
model, they only exist and flow in the constructed and
running integration solution.
OnusingMarkovDecisionProcessestoModelIntegrationSolutionsforDisparateResourcesinSoftwareEcosystems
263

4 SIMULATION MODEL
In this paper, a formal modelling based on probabilis-
tic extensions of temporal logics is also addressed,
aiming at the characterisation of integration solution
as solutions that exhibit stochastic behaviour, oper-
ate under constraints on timing and other resources.
Model checking tools based on probabilistic exten-
sions of temporal logics are introduced for formal and
quantitative model verification, bottleneck detection
and performance analysis.
A stochastic process represents in this context the
evolution of a system of random variables over time.
In other words, a process with some degree of un-
certainty, that evolves through a set of possible direc-
tions, starting from one of the possible states.
Stochastic model simulation in general and model
checking in particular is an important component
in the design and analysis of critical software sys-
tems, with probabilistic, nondeterministic and real
time characteristics. Model checkers are able to anal-
yse if a system satisfies a state/transition model and
a temporal logic specification. In addition to conven-
tional system analysis, stochastic model checking cal-
culates the likelihood of certain events during system
execution, including temporal relationship considera-
tions (Kwiatkowska et al., 2011).
Amongst several existing probabilistic models,
discrete-time Markov chains, which allow to specify
the probability of making a transition from one state
to another, continuous-time Markov chains, which al-
low to model continuous real time and probabilistic
choice, and Markov Decision Processes, which al-
low for both probabilistic and nondeterministic mod-
elling, are of special interest for integration solution
formal modelling. In Markov models, future states
are influenced only by the current state and no in-
fluence exist from past states. Markov based simu-
lation and model checking allows for systems proper-
ties analysis, such as path-based, transient and steady-
state properties (Parker, 2011).
Discrete-time Markov Chains can be described as
state-transition models augmented with probabilities.
More formally, as a tuple of a finite set of states (S),
an initial state s0 belonging to S, a transition prob-
ability matrix (P) of S × S → [0 − 1] where transi-
tions sum from a state must be 100%, a labelling
function assigning to states a set of atomic propo-
sitions (L : S → 2
AP
). Time is commonly seen in
Discrete-time Markov Chain models as discrete time-
steps, homogeneous, and transition probabilities are
independent of time. An execution of a Discrete-time
Markov Chain is represented by a path, with length
equal to path transitions. Paths probabilities calcu-
lation allow for system behaviour analysis and rea-
son on properties such as probabilistic reachability.
Quantitative and qualitative properties, including re-
peated reachability and persistence, might be of inter-
est in the context of a system behaviour analysis, and
addressed with Discrete-time Markov Chain proba-
bilistic model checking. Reward structures modelling
can also be used to represent benefit or cost charac-
teristics (e.g. energy consumption). Transition re-
wards (instantaneous) and state rewards (cumulative)
are modelled by the reward functions rs : S → R
≥0
and rt : S × S → R
≥0
respectively. A reward struc-
ture can be used to measure the number of time-steps
spent in a state or the chance that the system is in
a specific state after a certain number of time-steps
(Kwiatkowska et al., 2011; Parker, 2011).
Continuous-time Markov Chains main differences
from Discrete-time Markov Chains models rely on the
fact that transitions occur in real time and transitions
are represented in a transition rate matrix (R : S×S →
R
≥0
), assigning rates to pairs of states (with proba-
bility of transition being triggered within t time-units
equal to 1 − e
−R(s,s)·t
), instead of giving the proba-
bility of making a transition between states. If in
a state s, there is more than one state s
′
for which
R(s, s
′
) > 0 (known as a race condition), the first tran-
sition to be triggered determines the next state of the
Continuous-time Markov Chain. Paths are sequences
of states with time attributes (states execution dura-
tion). Transient and steady-state behaviour are prop-
erties of high interest and analysis in Continuous-time
Markov Chains models, they address the likelihood
of a system to be in a state at a specific time (or in
the long-run), and time spent in specific system states.
Reward structures are used to analyse number of re-
quests served in a time interval or in the long-run, as
well as the analysis of queue sizes at any time instant
or in the long-run (Kwiatkowska et al., 2011; Parker,
2011).
Markov decision processes, like Discrete-time
Markov chains, model a system as a discrete set of
states and transitions between states occurring in dis-
crete time-steps. In addition, Markov decision pro-
cess models extend Discrete-time Markov chains by
allowing for nondeterministic choice. This type of
modelling is specially suited for concurrency, un-
known environments, and underspecification appli-
cation scenarios. Since Discrete-time Markov chain
models are fully probabilistic, they are unable to ad-
dress some aspects of a system, such as nondetermin-
istic choice(Parker, 2011).
Formally, a Markov decision process is a tuple
(S, s
init
, Steps, L) where S is a finite set of states,
s
init
∈ S is the initial state, Steps : S → 2
Act×Dist(S)
ICEIS2015-17thInternationalConferenceonEnterpriseInformationSystems
264
T1
P1
Widget
Inventory
Invalid
Items Log
Gadget
Inventory
T2
T3
T4
T5
P3
P2
P4
Ordering
System
Inventory
System
S1
S2
S3
S4
T6
T7
T8
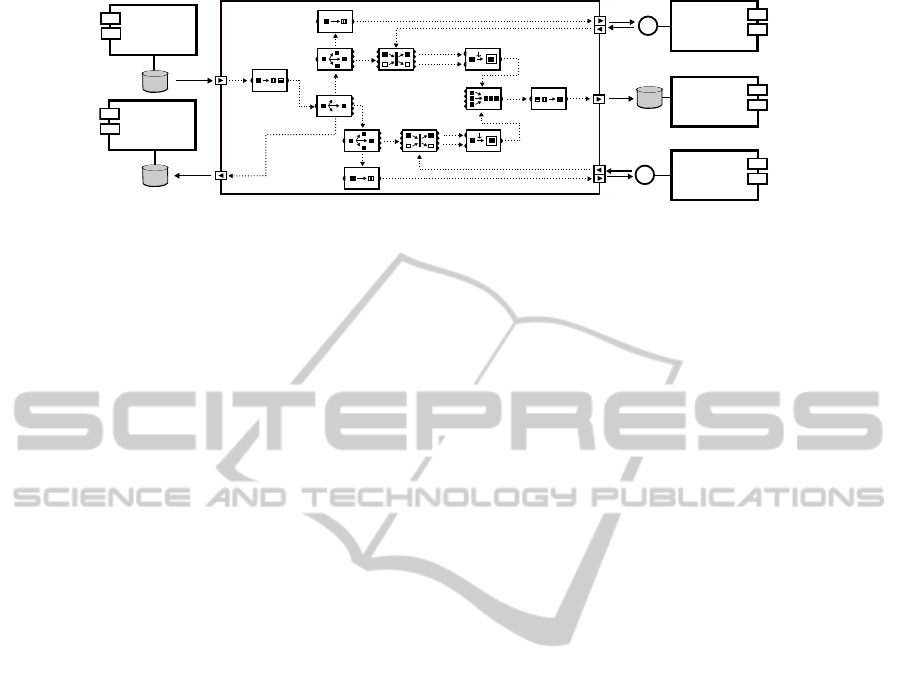
Figure 1: A conceptual model using Guaraná.
is the transition probability function, Act a set of ac-
tions, Dist(S) the set of discrete probability distribu-
tions over S, and L : S → 2
AP
a labelling with atomic
propositions. A path in a Markov decision process is
a sequence of states and action/distribution pairs, e.g.,
s
0
(a
0
, µ
0
)s
1
(a
1
, µ
1
)s
2
, representing a system execu-
tion. Paths resolve nondeterministic (turn the model
into a Discrete-time Markov Chain) and probabilistic
choices, and then calculate a probability measure over
paths(Kwiatkowska et al., 2011; Parker, 2011).
In Markov decision processes, adversaries (also
known as strategies or policies) are used to resolve
nondeterministic choices (multiple distributions) and
may belong to different classes such as memoryless,
finite-memory, randomised, fair. An adversary is a
function mapping every finite path to an element of
the Markov decision process model Steps. Markov
decision processes provide best/worst case analysis
based on lower/upper bounds on probabilities over
all possible adversaries (Kwiatkowska et al., 2011;
Parker, 2011).
For integration solutions formal model checking
and performance analysis, Markov decision processes
seem to be the most suitable type of probabilistic
models to adopt. This type of probabilistic mod-
elling has extensive support on modern probabilistic
model checker software tools such as PRISM (Ox-
ford, 2014). PRISM is a free and open source proba-
bilistic model checker software, for formal modelling
and analysis of systems in many different application
domains (e.g. distributed systems). It is widely used
in software, communications, distributed and embed-
ded systems research, having a strong support from
the formal methods research community.
5 CASE STUDY
Processing orders is a very common task. This sec-
tion presents a well-known integration problem intro-
duced by Hohpe (2005) to check the availability of
order items. In this context, there are cases in which
items listed in multi-item orders have to be processed
separately because they are served by different inven-
tories.
The software ecosystem in this case study involves
five applications, namely: Ordering System, Widget
Inventory, Gadget Inventory, Invalid Items Log, and
Inventory System. Apart from the Widget Inventory
and the Gadget Inventory, which provide an applica-
tion programming interface that enables the commu-
nication with them, the interaction with the remain-
ing applications has to be done by means of their
database. Orders are placed by customers at the Or-
dering System. Because an order may be composed of
several items, every order has to be split to check the
availability of its items in the Widget Inventory or the
Gadget Inventory. Items that do not belong to any of
these inventories cannot be checked, so that they have
to be logged in the Invalid Items Log. After checking
the availability of every item in an order, they have to
be aggregated into a single order to be processed by
the Inventory System.
The following sections present a conceptual and a
formal model. The former is designed using Guaraná
Technology and the latter using Markov decision pro-
cess notation.
5.1 Conceptual Model
This section introduces a conceptual model designed
to represent a possible integration solution for this
case study. Figure 1, presents this model using the
domain-specific language of Guaraná technology.
The workflow begins at entry port
P1
, which pe-
riodically polls the
Ordering System
to find new
orders, and ends by writing messages with infor-
mation regarding their availability to the
Inventory
System
. Inbound messages polled by entry port
P1
are written to slot
S1
, which is the input for task
T1
.
Every message with a new order is split by task
T1
into individual messages, each of which contain only
one item; the resulting messages are written to slot
S2
,
which is the input of task
T2
and desynchronises
tasks
T1
and
T2
. Messages in slot
S2
are analysed
by task
T2
and then dispatched either in direction of
OnusingMarkovDecisionProcessestoModelIntegrationSolutionsforDisparateResourcesinSoftwareEcosystems
265

S
0
S
1
S
2
S
3
1
S
4
S
5
S
6
S
7
S
8
S
9
1
1
1
1
1
1
1
1
1
1
1
{order received}
{items classified}
{items routed}
dispatch
split
prepare
{items requested}
{items rejected}
{order rejected}
merge
aggregate
{order delivered}
{service characterised}
{items ready}
request
{items synchronised}
S
10
{order invalid}
1
1
Figure 2: Markov decision process model of a simple (partial) integration solution.
the
Widget Inventory
or the
Gadget Inventory
.
Messages with items that do not belong to any of
these inventories, are routed to the
Invalid Items
Log
and written to this system by means of port
P2
.
Task
T3
replicates the message aimed at
Widget
Inventory
, so that one copy can be translated into a
query message by task
T4
and the other copy (base
message) is used by task
T5
to find the correlated re-
sponse. The interaction with
Widget Inventory
to
check the availability of items is made by means of
port
P3
, which reads query messages from slot
S3
and writes the responses to slot
S4
. Correlated mes-
sages are read by task
T6
from its inbound slots and
the information about the item availability is then
used to enrich the content of the base message, which
keeps going in the flow. The interaction with
Gadget
Inventory
occurs symmetrically.
Base messages now having the responses of avail-
ability for every item in the original order are merged
by task
T7
into a single slot and then aggregated again
into a single order message by task
T8
, and written to
the
Inventory System
by means of port
P4
.
5.2 Markov Decision Process Model
A simplified and partial Markov decision process
model of the integrationsolution presented in Figure 1
is shown in Figure 2, to illustrate schematically the
modelling ability of Markov decision processes in the
enterprise integration domain.
This model can be specified in PRISM modelling
language for model checking and analysis. Markov
decision process concepts are directly supported by
PRISM modelling concepts and are introduced next.
The concept of module in PRISM represents sys-
tem processes, including process variables, which
describe system states and commands (process be-
haviour, i.e., the way states change over time) com-
prising a guard (condition referring to variables of
this or other module, required for the update to take
place) and one or more updates together with the cor-
responding probabilities (updates can only affect vari-
ables belonging to the module). A PRISM model is
constructed as the parallel composition of its mod-
ules. Variables can be of Boolean, Integer or Clock
type. PRISM provides also full support for concepts
such as labels, atomic prepositions, paths, rewards
(transition and state rewards), invariants, race condi-
tions, steady state and transient behaviour, defined in
Markov decision processes models (Oxford, 2014).
Since it is not the purpose of this document
to present the full PRISM syntax and functionality,
only the simplified formal specification of Figure 2
Markov decision process model is described, as the
basis for the PRISM model construction. Assuming
a Markov decision process as a tuple M = (S, sinit,
Steps, L), the example presented in Figure 2 can be
described as:
S = s
0
, s
1
, s
2
, s
3
, s
4
, s
5
, s
6
, s
7
, s
8
, s
9
, s
10
, the finite set
of states, or state space.
s
init
= s
0
, the initial state.
AP = {order_received, items_classified,
items_routed, items_requested, items_rejected,
items_ready, service_characterised, or-
der_rejected, order_served, order_invalid},
the set of atomic propositions.
L , the labelling with atomic propositions (L : S →
2
AP
), which are simply associated to the states in
the current example.
Steps : S → 2
Act×Dist(S)
, the transition probability
function where Act is a set of actions {split,
dispatch, replicate, transform, correlate, enrich,
merge, aggregate} and Dist(S) is the set of dis-
crete probability distributions over the set S. In S
all actions were simply associated probability 1,
with action “merge” and “prepare” being repre-
sented as nondeterministic choices.
ICEIS2015-17thInternationalConferenceonEnterpriseInformationSystems
266

6 CONCLUSION
There is a high cost, risk, and development time
spent associated with the simulation approach fre-
quently adopted by software engineers to analyse the
behaviour and find possible performance bottlenecks
in enterprise integration solutions. This occurs due
to the activities related with the construction, execu-
tion, and the collection of data from the execution of
integration solutions. This paper proposes a new ap-
proach, based on discrete-event simulation, to cutting
down cost, risk, and time to deliver better integration
solutions. In this paper, modelling integration solu-
tions as discrete-event systems was proposed in order
to enhance the ability of software engineers to anal-
yse not only the functional correctness of an integra-
tion solution (e.g. deadlocks detection), but also its
non functional properties such as performance and re-
sources usage. This extended formal analysis is pro-
posed to be done by the means of Markov decision
process models with the support of state of the art
simulation tools, such as PRISM probabilistic model
checker. A simple and representative integration solu-
tion was modelled with Guaraná domain specific lan-
guage and its Markov decision process based formal
model derived and described. This proposal addresses
a major concern in the integration solutions software
development life cycle and presents a scientifically
innovative approach in the enterprise integration do-
main.
ACKNOWLEDGEMENT
The research work on which we report in this paper
is supported by CAPES, FAPERGS, and the internal
Research Programme at UNIJUÍ University. Iryna
Yevseyeva acknowledges funding for Choice Archi-
tecture for Information Security (ChAISe) project
EP/K006568/1 from Engineering and Physical Sci-
ences Research Council (EPSRC), UK, and Govern-
ment Communications Headquarters (GCHQ), UK,
as a part of Cyber Research Institute.
REFERENCES
Al-Aomar, R. (2010). Simulating service systems. In Got,
A., editor, Discrete Event Simulations, pages 1–25. In-
Tech.
Desa, W. L. H. M., Kamaruddin, S., Nawawi, M. K. M.,
and Khalid, R. (2013). Evaluating the performance of a
multipart production system using discrete event simula-
tion (DES). In International Proceedings of Economics
Development & Research, pages 64–67.
Faget, P., Eriksson, U., and Herrmann, F. (2005). Apply-
ing discrete event simulation and an automated bottle-
neck analysis as an aid to detect running production con-
straints. In Proceedings of the 37th Conference on Winter
Simulation, pages 1401–1407.
Frantz, R. Z., Molina-Jimenez, C., and Corchuelo, R.
(2010). On the design of a domain specific language for
enterprise application integration solutions. In Int. Work-
shop on Model-Driven Engeneering, pages 19–30.
Frantz, R. Z., Reina-Quintero, A. M., and Corchuelo, R.
(2011). A Domain-Specific language to design enterprise
application integration solutions. International Journal
of Cooperative Information Systems, 20(2):143–176.
Hohpe, G. (2005). Your coffee shop doesn’t use two-phase
commit. IEEE Software, 22(2):64–66.
Hohpe, G. and Woolf, B. (2003). Enterprise Integration
Patterns - Designing, Building, and Deploying Messag-
ing Solutions. Addison-Wesley.
Janssen, M. and Cresswell, A. M. (2005). An en-
terprise application integration methodology for e-
government. Journal of Enterprise Information Manage-
ment, 18(5):531–547.
Kunz, G., Tenbusch, S., Gross, J., and Wehrle, K. (2011).
Predicting runtime performance bounds of expanded par-
allel discrete event simulations. In IEEE 19th Annual In-
ternational Symposium on Modelling, Analysis, and Sim-
ulation of Computer and Telecommunication Systems,
pages 359–368.
Kwiatkowska, M., Norman, G., and Parker, D. (2011).
PRISM 4.0: Verification of Probabilistic Real-Time Sys-
tems. In Gopalakrishnan, G. and Qadeer, S., editors,
Computer Aided Verification, pages 585–591. Springer
Berlin Heidelberg.
Messerschmitt, D. and Szyperski, C. (2003). Software
EcoSystemm: Understanding an Indispensable Technol-
ogy and Industry. MIT Press.
Oxford (2014). Oxford University - PRISM Manual v. 4.2.
Parker, D. (2011). Lectures - Probabilistic Model Checking,
Department of Computer Science, University of Oxford.
Rozinat, A., Mans, R. S., Song, M., and van der Aalst, W.
(2009). Discovering Simulation Models. Information
Systems, 34(3):305–327.
van der Aalst, W. (2010). Business Process Simulation Re-
visited. In Barjis, J., editor, Enterprise and Organiza-
tional Modeling and Simulation, volume 63 of Lecture
Notes in Business Information Processing, pages 1–14.
Springer Berlin Heidelberg.
van der Aalst, W. (2015). Business Process Simulation Sur-
vival Guide. In vom Brocke, J. and Rosemann, M., edi-
tors, Handbook on Business Process Management, Inter-
national Handbooks on Information Systems, pages 337–
370. Springer Berlin Heidelberg.
van der Aalst, W., Nakatumba, J., Rozinat, A., and Rus-
sell, N. (2010). Business Process Simulation: How to
get it right? In vom Brocke, J. and Rosemann, M., edi-
tors, Handbook on Business Process Management, Inter-
national Handbooks on Information Systems, pages 313–
338. Springer Berlin Heidelberg.
OnusingMarkovDecisionProcessestoModelIntegrationSolutionsforDisparateResourcesinSoftwareEcosystems
267
