
A Benchmark for Online Non-blocking Schema Transformations
Lesley Wevers, Matthijs Hofstra, Menno Tammens, Marieke Huisman and Maurice van Keulen
University of Twente, Enschede, The Netherlands
Keywords:
Online Schema Transformations, Database Transactions, Benchmark.
Abstract:
This paper presents a benchmark for measuring the blocking behavior of schema transformations in relational
database systems. As a basis for our benchmark, we have developed criteria for the functionality and perfor-
mance of schema transformation mechanisms based on the characteristics of state of the art approaches. To
address limitations of existing approaches, we assert that schema transformations must be composable while
satisfying the ACID guarantees like regular database transactions. Additionally, we have identified impor-
tant classes of basic and complex relational schema transformations that a schema transformation mechanism
should be able to perform. Based on these transformations and our criteria, we have developed a benchmark
that extends the standard TPC-C benchmark with schema transformations, which can be used to analyze the
blocking behavior of schema transformations in database systems. The goal of the benchmark is not only
to evaluate existing solutions for non-blocking schema transformations, but also to challenge the database
community to find solutions that allow more complex transactional schema transformations.
1 INTRODUCTION
For applications storing data in a database, changes
in requirements often lead to changes in the database
schema. This often requires changing the physical
layout of the data to support new features, or to im-
prove performance. However, current DBMSs are
ill-equipped for changing the structure of the data
while the database is in use, causing downtime for
database applications. For instance, an investigation
on schema changes in MediaWiki, the software be-
hind Wikipedia, shows that 170 schema changes are
performed in less than four years time (Curino et al.,
2008). Many of these changes required a global
lock on database tables, which made it impossible to
edit articles during the schema change. The largest
schema change took nearly 24 hours to complete.
Downtime due to schema changes is a real prob-
lem in systems that need 24/7 availability (Neamtiu
and Dumitras, 2011). Unavailability can lead to
missed revenue in case of payment systems not work-
ing, economic damage in case of service level agree-
ments not being met, to possibly life threatening situa-
tions if medical records cannot be retrieved. Not only
is this a problem in its own right, evolution of soft-
ware can also be slowed down as developers tend to
avoid making changes because of the downtime con-
sequences.
Goals. We have specified criteria for non-blocking
schema transformations, and we have developed a
benchmark to evaluate DBMSs with regard to these
criteria. Our benchmark extends the standard TPC-C
benchmark with basic and complex schema transfor-
mations, where we measure the impact of these trans-
formations on the TPC-C workload. This benchmark
can be used to evaluate the support for online schema
changes in existing DBMSs, and serves as a challenge
to the database community to find solutions to per-
form non-blocking schema changes.
Problem Statement. The SQL standard provides
the data definition language (DDL) to perform ba-
sic schema changes such as adding and removing of
columns and relations. However, in current DBMSs,
not all of these operations can be executed in parallel
with other transactions. The effect is that concurrent
transactions completely halt until the (possibly long)
execution of the schema change has finished.
Moreover, not all realistic schema changes can
be expressed using a single DDL operation. Impor-
tant examples of such transformations include split-
ting and merging of tables (Ronstr
¨
om, 2000; Løland
and Hvasshovd, 2006), changing the cardinality of a
relationship, and changing the primary key of a table.
Many of these schema changes involve bulk transfor-
mation of data using UPDATE statements, which is
288
Wevers L., Hofstra M., Tammens M., Huisman M. and van Keulen M..
A Benchmark for Online Non-blocking Schema Transformations.
DOI: 10.5220/0005500202880298
In Proceedings of 4th International Conference on Data Management Technologies and Applications (DATA-2015), pages 288-298
ISBN: 978-989-758-103-8
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

blocking in most DBMSs to avoid concurrency con-
flicts. To complicate matters further, schema transfor-
mations can affect existing indices, as well as (foreign
key) constraints.
To illustrate the problem, PostgreSQL can per-
form many DDL operations instantaneously, and al-
lows DDL operations to be safely composed into
more complex schema changes using transactions.
This approach allows composed schema changes to
be performed without significant blocking as long as
they consist only of operations that can be performed
instantaneously. However, bulk UPDATE operations
and some DDL operations cannot be performed in-
stantaneously, and all DDL and UPDATE operations
take a global table lock for the duration of the trans-
formation. The effect is that many complex transfor-
mations cannot be performed without blocking.
Another example is MySQL, which recently
added limited support for online DDL opera-
tions
1
. However, while MySQL supports transac-
tional schema transformations, it auto-commits after
every operation, which requires the application pro-
gram to handle all intermediate states of the trans-
formation. Moreover, UPDATE operations cannot be
performed online, which makes it impossible to per-
form many complex transformations online.
Tools such as pt-online-schema-change
2
, oak-
online-alter-table
3
, and online-schema-change
4
have
been developed in industry to allow online schema
transformations on existing DBMSs using a method
developed by Ronstr
¨
om (Ronstr
¨
om, 2000). While
these tools are limited in capability, they show that
there is a strong need for solutions, and that there is
room for improvement in current DBMSs.
Overview. In 2 we provide an overview of the
state of the art in online schema changes, and show
that current techniques are not sufficient for complex
schema changes. To address the limitations of exist-
ing approach, we have specified general criteria for
non-blocking schema changes, as discussed in 3. Ad-
ditionally, as discussed in 4, we have identified impor-
tant classes of relational schema transformations that
we believe should be supported by schema transfor-
mation mechanisms. In 5 we discuss our benchmark
which evaluates how DBMSs cope with the schema
changes that we have identified against our criteria.
In 6 we discuss our implementation of the bench-
mark, and show example results for PostgreSQL and
MySQL.
1
dev.mysql.com/doc/refman/5.6/en/innodb-online-ddl.html
2
www.percona.com/doc/percona-toolkit
3
code.openark.org/forge/openark-kit
4
www.facebook.com/notes/430801045932
Contributions. The contributions of this paper are:
• A challenge for the database community to find
solutions for non-blocking transactional schema
transformations.
• Criteria for evaluating online schema transforma-
tion mechanisms in general, and for the relational
data model in particular.
• A concrete benchmark based on TPC-C to evalu-
ate the blocking behavior of online schema trans-
formations in existing database systems.
2 STATE OF THE ART
This section provides a brief overview of the state
of the art in non-blocking schema transformations.
While we show that existing solutions are insufficient
for complex transformations, we use their characteris-
tics as a basis for our criteria for online schema trans-
formations, which are discussed in the next section.
Synchronization based Methods. Ronstr
¨
om pro-
posed a method that allows changing of columns,
adding indices, and horizontally and vertical split-
ting and merging of tables by using database triggers
(Ronstr
¨
om, 2000). A benefit of Ronstr
¨
om’s method is
that it can be implemented on top of existing DBMSs
that provide support for triggers. A number of tools
have already been developed in industry, such as pt-
online-schema-change. Løland and Hvasshovd pro-
vide log redo as an alternative implementation ap-
proach to Ronstr
¨
oms method, which reduces impact
on concurrent transactions, but requires built-in sup-
port from the DBMSs (Løland and Hvasshovd, 2006).
While Ronstr
¨
oms method can perform many
schema transformations without blocking, it can take
a long time until a transformation commits. More-
over, Ronstr
¨
oms methods only provides ACID guar-
antees for individual transformations. For complex
transformations that consist of multiple schema trans-
formations, Ronstr
¨
om proposes the use of SAGAs.
The idea of SAGAs is to execute the individual op-
erations of a transaction as a sequence of transac-
tions, where for each operation an undo operation
is provided that can be used to rollback the com-
plete sequence (Garcia-Molina and Salem, 1987).
While SAGAs provide failure atomicity for composed
transactions, they expose intermediate states of the
transformation to database programs. This requires
database programs to be adapted to handle these in-
termediate states, which requires additional develop-
ment effort, and which is potentially prone to mis-
takes.
ABenchmarkforOnlineNon-blockingSchemaTransformations
289

On-the-fly Schema Changes. Neamtiu et al.
propose on-the-fly schema changes in databases
(Neamtiu et al., 2013). In their approach, a schema
change command can specify multiple operations on
multiple tables. Upon access of a table, a safety check
is performed to see if a schema change is in progress.
If so, data is transformed before it can be accessed.
The authors have implemented a prototype in SQLite,
and have performed experiments, showing very short
time to commit and low overhead. However, their
implementation does not allow a new schema trans-
formation to start before any running schema trans-
formation has completed. Their approach allows for
composition of schema transformations to a limited
degree, as an update operation can consist of multi-
ple operations on multiple tables. However, they only
support relatively simple operations, such as adding
and removing relations and columns. Complex oper-
ations such as splitting and joining relations are men-
tioned as future work.
Online Schema Change in F1. Rae et al. in-
vestigate online schema change in the Google F1
database (Rae et al., 2013), which is a relational
DBMS built on top of a distributed key-value store.
The distributed setting introduces additional compli-
cations, as inconsistencies between schemas in dif-
ferent compute nodes can lead to incorrect behavior.
Their solution is to split a complex schema change
into a sequence of simpler schema changes that are
guaranteed not to perform conflicting operations on
the distributed state. Each schema change operation
is fully executed before the next one starts, so that the
composed operation is guaranteed to be correct. How-
ever, while this approach allows for some complex
transformations, many types of transformations are
not covered. Moreover, similar to the use of SAGAs
in Ronstr
¨
oms method, intermediate states of transfor-
mations are visible to database applications, which
may have to be adapted to handle these states.
Rewriting Approaches. Curino et al. investigate
automatic rewriting of queries, updates and integrity
constraints based on schema transformation specifica-
tions (Curino et al., 2010). This provides an alterna-
tive approach to schema transformations by rewriting
operations on the new schema to operations on the old
schema. A similar approach is to use updatable views,
where the new schema is represented as an updatable
view over the old schema. However, these approaches
do not provide a complete solution to online schema
transformations, as the schema may need to be ex-
tended to store new types of data, or data may need to
be physically rearranged to improve performance.
Related Topics. Apart from physical transforma-
tion of data without blocking, another challenge in
schema evolution is handling application migration.
For instance, there is work on schema versioning,
which investigates how multiple schema versions
can be used concurrently through versioned inter-
faces (Roddick, 1995). Work in this field can bene-
fit from the ability to perform non-blocking schema
transformations.
Also of note is the problem of keeping material-
ized views up to date, as many of the same issues of
performing non-blocking physical schema transfor-
mations are encountered (Gupta and Mumick, 1995).
Discussion. Each of the discussed approaches to
physical transformation of data has their own
strengths and limitations. In particular, existing meth-
ods have different characteristics in terms of time to
commit and the impact on concurrent transactions.
For instance, on-the-fly transformations commit be-
fore the physical transformation of data starts, while
Ronstr
¨
oms method commits after the physical trans-
formation has completed. However, not all transfor-
mations can be performed on the fly, such as creating
of indices or checking of constraints. Another im-
portant observation is that none of the existing ap-
proaches provides a satisfactory solution to compo-
sition of schema transformations. Current solutions
generally expose database programs to intermediate
states of the transformation, which breaks the isola-
tion property of the ACID guarantees.
3 CRITERIA FOR ONLINE
TRANSFORMATIONS
In this section we define criteria for non-blocking
schema transformations, which we use as the ba-
sis for our benchmarks. Our criteria are based on
the characteristics of the state of the art approaches
to non-blocking schema transformations as discussed
in the previous section. We address the limitations
of existing approaches, while also considering their
strengths. We specify criteria both for the function-
ality of schema transformations and for their perfor-
mance. For every criterion, we discuss the ideal be-
havior of the schema transformation mechanism, and
we also discuss what behavior we would still consider
acceptable for systems that must be online 24/7. Note
that our criteria make no assumptions about the spe-
cific strategies used to perform schema transforma-
tions, and also apply to data models other than the
relational model.
DATA2015-4thInternationalConferenceonDataManagementTechnologiesandApplications
290

Functional Criteria. First, we specify criteria for
the functionality provided by a schema transforma-
tion mechanism:
1. Expressivity. Ideally, an online schema trans-
formation mechanism can perform any conceiv-
able schema transformation online. For example,
in the relational model this would be all schema
transformations that can be expressed in SQL.
However, in practice, it could be sufficient if we
can only perform a subset of all possible trans-
formations online. For instance, we discuss an
important set of relational transformations in 4,
which could be sufficient in practice.
2. Transformation of Data. After a schema change
commits, all existing data must be available in the
new schema. This is the main challenge in per-
forming schema transformations online, and any
lesser guarantees are generally unacceptable.
3. Transactional Guarantees. For the correctness
of database programs, and to ensure database in-
tegrity, it is important that schema transformations
satisfy the ACID properties, as is currently the
norm for OLTP transactions:
(a) Atomicity. Systems must allow transac-
tional composition of basic schema transforma-
tions into more complex transformations, while
maintaining transactional guarantees. If this is
not possible, intermediate schemas of the ba-
sic schema transformations are visible to other
transactions. For some applications this may be
acceptable, but handling them comes at the cost
of additional development effort.
(b) Consistency. Ideally, all defined constraints
hold for the new schema. However, deferring
the checking of constraint to a later time may
be acceptable for certain applications.
(c) Isolation. The execution of transformations
must have serializable semantics, i.e., all con-
current transactions must either see data in the
old schema, or see data in the new schema.
Partially transformed states where one part of
the data is available in the old schema, and the
other part is available in the new schema must
not be visible to concurrent transactions.
(d) Durability. Once a schema transformation has
been committed, its effect must be persistent,
even in the event of a system failure, i.e. all
transactions that are serialized after the trans-
formation must see the result of the transforma-
tion. After a system failure, it may never be the
case that data is lost, that a database is left in a
partially transformed state, or that a database is
left in an intermediate state of a transformation.
4. Application Migration. There must be a mecha-
nism to ensure that database programs can con-
tinue to operate correctly during and after the
schema transformation. Ideally, the system pro-
vides schema versioning or automatic rewriting of
queries, updates and integrity constraints. How-
ever, it may be sufficient if stored procedures can
be updated as part of a schema transformation.
5. Declarativity. Ideally, schema transformations
are specified declaratively. The user should not
have to be concerned with the execution details of
a schema transformation. For instance, the SQL
data definition language can be considered to be
declarative. Manual implementation of schema
transformations, e.g., using Ronstr
¨
oms method,
can be expensive to develop and can be prone to
mistakes that can damage data integrity, but could
be acceptable in certain applications.
Performance Criteria. Second, we specify criteria
for the performance of online schema change mech-
anisms, where we assume that OLTP transactions
and schema transformation transactions are executing
concurrently. We first discuss the impact of schema
transformations on OLTP transactions, and then we
describe performance criteria for the schema transfor-
mations themselves.
1. Impact of a Schema Transformation on
Concurrent Transactions Executing a schema
change concurrently with other transactions will
have an impact on those transactions. We distin-
guish several kinds of impact:
(a) Blocking. Transactions should always be able
to make progress independent of the progress
of concurrent schema transformations. Ideally,
a schema transformation never blocks the exe-
cution of concurrent transactions. However, de-
pending on the application, blocking for short
periods of time, e.g., up to a few seconds, could
be acceptable. Additionally, schema transfor-
mation mechanisms must never prevent new
transactions from starting while a schema trans-
formation is in progress.
(b) Slowdown. A general slowdown in through-
put and latency of transactions is acceptable
to a certain degree, depending on the applica-
tion. Ideally, more complex transformations
can be performed without causing additional
slowdown. However, slowdown that depends
on the complexity of the transformation could
be acceptable, but may impose limitations on
the complexity of online transformations.
ABenchmarkforOnlineNon-blockingSchemaTransformations
291

(c) Aborts. Ideally, schema transformations allow
transactions that are already running to con-
tinue executing without aborting them. For in-
stance, by means of snapshot isolation, and by
translating updates on the old schema to the
new schema. This is especially important for
long-running transactions. However, it is ac-
ceptable to abort short-running transactions, as
long as they do not suffer from starvation dur-
ing the execution of the transformation.
2. Performance Criteria for Online Schema
Transformations. For online schema transforma-
tions, we have identified different requirements:
(a) Time to Commit. The time to commit is de-
fined by how long it takes for the results of
a schema transformation to be visible to other
transactions. A very long time to commit can
be unacceptable in time critical situations. To
cater for on-the-fly transformation of data, i.e.,
transformation of data after the transformation
has been committed (Neamtiu et al., 2013), we
want to distinguish time to commit from the
transformation time, which is the total amount
of time needed to transform all data in the
database. As long as concurrent transactions
are not impacted, the transformation time does
not matter.
(b) Aborts and Recovery. Due to their long run-
ning time, it is generally not acceptable to abort
schema transformations due to concurrency is-
sues. As an exception, aborting a transforma-
tion before it is executed is acceptable, for in-
stance, in case a conflicting schema transforma-
tions is already in progress. Moreover, aborts
due to semantic reasons, such as constraint vio-
lations, cannot be avoided. In case of a system
failure during a transformation, ideally the sys-
tem can recover and continue execution of the
transformation. However, due to the rarity of
system failures, aborting the transaction could
be acceptable. It is important that recovery
from an abort also minimizes impact on concur-
rent transactions. Finally, a request for schema
transformation should only be rejected if there
is a conflicting uncommitted schema transfor-
mation; processing of any schema transforma-
tion that has already been committed should not
delay the start of another schema transforma-
tion.
(c) Memory Usage. Apart from timing behavior,
a schema transformation should not consume
large amounts of memory. Ideally, a transfor-
mation should be performed in-place, and not
construct copies of the data. However, depend-
ing on available hardware resources, it could
be acceptable if additional memory is needed
to perform the transformation.
Discussion. Sockut and Iyer also discuss require-
ments for strategies that perform online reorganiza-
tions (Sockut and Iyer, 2009). They consider not
only logical and physical reorganizations, but they
also have a strong focus on maintenance reorganiza-
tions, i.e., changing the physical arrangement of data
without changing the schema. Their main require-
ments are correctness of reorganizations and user ac-
tivities; tolerable degradation of user activity perfor-
mance during reorganizations; eventual completion of
reorganizations; and, in case of errors, data must be
recoverable and transformations must be restartable.
Our main addition to these requirements is that ba-
sic transformations should be composable into com-
plex transformations using transactions, while main-
taining ACID guarantees and satisfying the perfor-
mance requirements. A difference in our require-
ments is that instead of requiring eventual comple-
tion of transformations, we only consider the time to
commit, and leave the matter of progress as an im-
plementation detail to the DBMS, which may choose
to make progress if this reduces impact on running
transactions.
4 RELATIONAL
TRANSFORMATIONS
In this section we identify important classes of rela-
tional schema transformations that could be required
in practice. In our benchmark, we select representa-
tive transformations for these classes on the TPC-C
schema. We do not make any a priori assumptions
about the difficulty of schema transformations or the
capabilities of existing systems. To identify impor-
tant schema transformations, we consider databases
that are implementations of Entity-Relationship (ER)
models.
ER Models and Implementations. ER modelling
is a standard method for high-level modelling of
databases (Chen, 1976). In the ER model, a domain
is modelled using entities and relationships between
these entities, where entities have named attributes,
and relationships have a cardinality of either 1-to-1,
1-to-n or n-to-m. An ER model can be translated to a
relational database schema in a straightforward man-
ner: Entities are represented as relations, attributes are
mapped to columns and relationships are encoded us-
ing foreign keys. Several implementation decisions
DATA2015-4thInternationalConferenceonDataManagementTechnologiesandApplications
292

are made in this translation, for example, which types
to use for the attributes and which indices to create.
Based on this, we can identify two kinds of schema
transformations: logical transformations that corre-
spond to changes in the ER model, and physical trans-
formations that correspond to changes in the imple-
mentation decisions.
ER Model Transformations. We consider logical
transformations on relational databases that corre-
spond to the following ER-model transformations:
• Creating, renaming and deleting entities and at-
tributes.
• Changing constraints on attributes, such as
uniqueness, nullability and check constraints.
• Creating and deleting relationships, and changing
the cardinality of relationships.
• Merging two entities through a relationship into
a single entity, and the reverse, splitting a single
entity into two entities with a relationship between
them.
• Moving attributes from an entity to another entity
through a relationship.
Note that certain changes in the ER model do not
result in an actual change of the database schema, but
only in a data transformation. For instance, chang-
ing the currency of a price attribute is an example of
an ER-model transformation that needs no database
schema change, but only a data transformation. Such
schema transformations correspond to normal bulk
data updates.
Implementation Transformations. Furthermore,
we also consider physical transformations on rela-
tional databases that correspond to changes in the im-
plementation decisions:
• Changing the names and types of columns that
represent an attribute.
• Changing a (composite) primary key over at-
tributes to a surrogate key, such as a sequential
number, and vice versa.
• Adding and removing indices.
• Changing the implementation of relationships to
either store tuples of related primary keys in a sep-
arate table, store relationships in an entity table
(for 1-to-n and 1-to-1 relationships), or merging
of entity tables that have a 1-to-1 relationship.
• Changing between computing aggregations on-
the-fly, or storing precomputed values of aggre-
gations.
The above set of transformations is by no means
complete, but it provides an important subset of
schema changes that are used in practice, and it is
sufficient for the benchmark to showcase the limita-
tions of schema transformation mechanisms in exist-
ing database systems.
5 BENCHMARK SPECIFICATION
In this section, we describe a benchmark to investi-
gate the behavior of online schema transformations
in database systems. We shortly discuss the TPC-C
benchmark, we specify how our benchmark should
be performed, we discuss the interpretation of the re-
sults, and we define concrete schema transformations
for the TPC-C schema. Finally, we discuss the com-
pleteness of our benchmark.
The TPC-C Benchmark. The TPC-C bench-
mark (TPC, 2010) is an industry standard OLTP
benchmark that simulates an order-entry environ-
ment. 1 shows a high-level overview of the TPC-C
benchmark schema. TPC-C specifies the generation
of databases of arbitrary sizes by varying the number
of warehouses W . The workload consists of a num-
ber of concurrent terminals executing transactions of
five types: New Order, Payment, Order Status, De-
livery and Stock Level. The transaction type is se-
lected at random, following a distribution as specified
by TPC-C. The TPC-C benchmark measures the num-
ber of New Order transactions per minute. Addition-
ally, TPC-C also specifies response time constraints
for all transaction types.
Our benchmark extends the TPC-C benchmark
with schema transformations, but does not require
modifications, i.e., we use a standard TPC-C database
and workload. This means that existing TPC-C
benchmark implementations can be used. However,
we assume that the TPC-C transactions are imple-
mented as stored procedures that can be changed as
part of a schema transformation. The TPC-C scal-
ing factor should be chosen such that the impact of a
schema transformation are measurable.
History
W×30k+
New-Order
W×9k+
Order-Line
W×300k+
District
W×10
Warehouse
W
Customer
W×30k
Stock
W×100k
Order
W×30k+
Item
100k
100k
10
3K
1+W
5-15
0-1
1+
3+
Figure 1: TPC-C schema overview (TPC, 2010).
ABenchmarkforOnlineNon-blockingSchemaTransformations
293

Benchmarking Process. The execution of a bench-
mark case is done in multiple phases:
1. Setup: Create a TPC-C database.
2. Preparation: If specified by the benchmark case,
perform the preparation transformation.
3. Intro: Start the TPC-C benchmark load, while
logging the executed transactions. Wait for 10
minutes before starting the transformation, while
measuring the baseline TPC-C performance.
4. Transformation: Start the execution of the actual
transformation, and wait for it to complete. Log
the transformation begin and end time.
5. Outro: Wait for another 10 minutes while mea-
suring the TPC-C performance in the outro phase.
Note that on-the-fly schema changes may require
more than 10 minutes to complete. In this case,
additional time can be added to the outro phase.
After each transaction attempt, the type of transaction,
its starting time and its end time are logged. Failed
transactions are logged with type ERROR.
Result Analysis. As shown in 2, we present the re-
sult of a benchmark as a line graph that plots the TPC-
C transaction execution rate in time intervals of fixed
length. In the graph, we mark the start and commit
time of the transformation with vertical lines. Addi-
tionally, we plot ERROR transactions in red to detect
aborted and failed transactions.
We use these graphs to evaluate the impact of
schema transformations. First, we can see the time
to commit for the transformation. Second, we can see
the effect of the schema transformation on the transac-
tion throughput both during the transformation phase,
and during the outro phase. The latter can be used
to investigate the performance of on-the-fly schema
transformations. Note that we are not interested in the
absolute transaction throughput, but only in the rela-
tive throughput during the transformation compared
to the baseline performance in the intro phase. If a
schema change is blocking, we see a throughput of
zero. We can determine the total blocking time by
computing the cumulative time of the intervals where
the throughput is below a certain threshold. Addition-
ally, we can compute the average throughput during
time periods to determine the slowdown caused by the
schema transformation.
Transformations. 1 and 2 show the transforma-
tions that we have selected for our benchmark. These
were chosen as representatives for the transforma-
tions identified in 4. Like the TPC-C specification,
we do not prescribe a specific implementation for the
transformations, as we do not want to preclude the
use of features provided by the DBMS. We define
most schema transformations on the ORDER-LINE
table, which is the largest table in a populated TPC-
C database. Transformations affecting multiple tables
are performed on the ORDER and ORDER-LINE ta-
bles. Note that we prefix all column names with the
abbreviated table name. For example, OL NAME is a
column in ORDER-LINE. and O NAME is a column
in ORDER. Some transformations have a preparation
part (presented in italics) where the TPC-C schema is
transformed prior to the actual transformation that we
want to evaluate. For some benchmarks, we use the
resulting schema of another benchmark as a starting
point. For instance, there is a benchmark where a ta-
ble is split, which we also use as the preparation phase
for a transformation where we rejoin the tables to ob-
tain the original TPC-C schema. Also note that many
transformations change the stored procedures, so that
the TPC-C benchmark can continue running on the
transformed schema. We have divided the benchmark
into basic and complex transformations:
• Basic Transformations: 1 shows basic bench-
mark cases that correspond to the operations pro-
vided by the SQL standard, categorized by differ-
ent types of transformations. These cases are rela-
tively synthetic in nature, and can mainly be used
to compare the capabilities of different schema
transformation strategies. For most benchmark
cases, there are two versions, one that does not
affect running transactions, and one that does.
The latter have names ending in -sp, and require
changing the stored procedures. Note that while
creating indices is not technically a schema trans-
formation, it is an important DDL operation.
• Complex Transformations: 2 shows complex
benchmark cases, which generally require multi-
ple DDL operations, and involve UPDATE state-
ments. If a DBMS can perform these complex
cases, it is likely that the basic cases are also cov-
ered, as most complex cases overlap with the ba-
sic cases. The following list provides a high-level
overview of the transformations:
1. add-column-derived: Instead of storing only
the total amount of the order, we also want to
separately store the sales tax paid on the or-
der. We assume that all previous and new or-
ders have a 21% sales tax.
2. change-primary: In the original TPC-C
benchmark, each warehouse maintains a sepa-
rate order counter, so that orders from different
warehouses share the same key space. In this
benchmark, we change orders to have a glob-
ally unique order identifier. We also change all
order lines to refer to this new identifier.
DATA2015-4thInternationalConferenceonDataManagementTechnologiesandApplications
294

Table 1: Basic benchmark cases.
Relation Transformations
create-relation Create a new relation TEST.
rename-relation Rename ORDER-LINE to ORDER-LINE-B. Change the stored procedures to
use ORDER-LINE-B instead of ORDER-LINE.
remove-relation Copy ORDER-LINE to ORDER-LINE-B. Drop ORDER-LINE-B.
remove-relation-sp Copy ORDER-LINE to ORDER-LINE-B. Drop ORDER-LINE. Change the
stored procedures to use ORDER-LINE-B instead of ORDER-LINE.
Column Transformations
add-column Create OL TAX as NULLABLE of the same type as OL AMOUNT.
add-column-sp Create OL TAX as NULLABLE of the same type as OL AMOUNT. Change
the stored procedures to set OL TAX to OL AMOUNT × 0.21 upon insertion.
add-column-default Create OL TAX as NOT NULL with default value 0 of the same type as
OL AMOUNT.
add-column-default-sp Create OL TAX as NOT NULL with default value 0 of the same
type as OL AMOUNT. Change the stored procedures to set OL TAX to
OL AMOUNT × 0.21 upon insertion.
rename-column Copy column OL AMOUNT to OL AMOUNT B. Rename column
OL
AMOUNT B to OL AMOUNT C.
rename-column-sp Rename column OL AMOUNT to OL AMOUNT B. Change the stored pro-
cedures to use OL AMOUNT B instead of OL AMOUNT.
remove-column Copy OL AMOUNT to OL AMOUNT B. Drop OL AMOUNT B.
remove-column-sp Copy OL AMOUNT to OL AMOUNT B. Drop OL AMOUNT. Change the
stored procedures to use OL AMOUNT B instead of OL AMOUNT.
change-type-a Change OL NUMBER to use a greater range of integers.
change-type-b Split OL DIST INFO into two columns OL DIST INFO A and
OL DIST INFO B. Change the stored procedures to split the value for
OL
DIST INFO into two parts upon insertion, and to concatenate the values
upon retrieval.
Index Transformations
create-index Create an index on OL I ID.
remove-index Execute create-index-a. Drop the index created by create-index.
Constraint Transformations
create-constraint Create a constraint to validate that 1 ≤ OL NUMBER ≤ O OL CNT.
remove-constraint Execute create-constraint-a. Drop the constraint created by create-constraint.
create-unique Create a column OL U, and fill this with unique values. Add a uniqueness
constraint on OL U.
remove-unique Execute create-unique-a. Drop the uniqueness constraints created by create-
unique.
Data Transformations
change-data Set OL AMOUNT to OL AMOUNT × 2.
3. split-relation: We want to store the relation
between ORDER and ORDER-LINE in a sep-
arate table ORDER-ORDER-LINE, and use a
surrogate key for ORDER-LINES.
4. join-relation: We perform split-relation in re-
verse, i.e., we take the resulting schema of split-
relation, and transform this back to the original
TPC-C schema.
ABenchmarkforOnlineNon-blockingSchemaTransformations
295

Table 2: Complex benchmark cases.
Complex Transformations
add-column-derived Create OL TAX as NOT NULL and initial value OL AMOUNT × 0.21.
Change the stored procedures to set OL TAX to OL AMOUNT × 0.21 upon
insertion.
change-primary Add a column O GUID with unique values. Add a column OL O GUID, and
set its value to the O GUID of the order corresponding to this order line.
Set (OL O GUID, OL O NUMBER) as the primary key. Drop OL O ID,
OL D ID and OL W ID. Add a column NO O GUID, and set its value to
the O GUID of the corresponding order. Drop NO O ID, NO D ID and
NO W ID. Set NO O GUID as the primary key. Drop O ID. Update the stored
procedures to use the new structure, change STOCK LEVEL to select the top
20 rows ordered by O GUID instead of the condition OL O ID ≥ (ST O ID -
20).
split-relation Create ORDER-ORDER-LINE with columns OOL O ID, OOL D ID,
OOL W ID, OOL OL ID and OOL NUMBER. Create a column OL ID
with unique values as primary key. Insert all tuples (OL O ID, OL D ID,
OL W ID, OL ID, OL NUMBER) into ORDER ORDER LINE. Drop
columns OL O ID, OL D ID, OL W ID, OL ID and OL NUMBER. Update
the stored procedures to use the new structure.
join-relation Execute split-relation. Add columns OL O ID, OL D ID, OL W ID and
OL NUMBER and set their values to the corresponding values in ORDER-
ORDER-LINE. Drop OL ID, and set primary key (OL O ID, OL D ID,
OL W ID, OL NUMBER). Drop relation ORDER-ORDER-LINE. Update the
stored procedures to use the original stored procedures.
defactorize Add column OL CARRIER ID, and set its value to O CARRIER ID of the
corresponding order. Drop column O CARRIER ID. Update the stored proce-
dures to use the new structure.
factorize Execute defactorize. Add column O CARRIER ID, and set its value to
OL CARRIER ID for the corresponding order line where OL NUMBER =
1. Drop column OL CARRIER ID. Update the stored procedures to use the
original stored procedures.
factorize-boolean Add boolean column O IS NEW and set its value to true if NEW-ORDER
contains the corresponding order, otherwise set it to false. Drop relation NEW-
ORDER. Update the stored procedures to use the new structure.
defactorize-boolean Execute factorize-boolean. Create table NEW-ORDER as original. Insert the
primary key of all orders into NEW-ORDER where O IS NEW = true. Drop
column O IS NEW. Update the stored procedures to use the original stored
procedures.
precompute-aggregate Add column O TOTAL AMOUNT and set its value to the sum of
OL AMOUNT of the corresponding order lines. Update the stored proce-
dures to update O TOTAL AMOUNT when inserting order lines, and to use
O TOTAL AMOUNT instead of computing the aggregate.
5. defactorize: Instead of allowing only a single
carrier for an order, we want the ability to have
multiple carriers. To do this, we store the car-
rier per order line instead of per order.
6. factorize: We perform the inverse operation of
defactorize. Instead of a carrier per order line,
we want only a single carrier for every order.
We take the carrier of the first order line as the
carrier for the order.
7. factorize-boolean: Instead of using the NEW-
ORDER table to mark orders as being new, we
store this using a boolean field in ORDER.
DATA2015-4thInternationalConferenceonDataManagementTechnologiesandApplications
296
8. defactorize-boolean: We perform the reverse
transformation of factorize-boolean.
9. precompute-aggregate: Instead of computing
the total amount of an order dynamically, we
want to precompute this value and store it in
the ORDER table.
Discussion. We now briefly discuss the complete-
ness of our benchmark with regard to our criteria, and
we discuss the correctness and accuracy of results ob-
tained using our benchmark.
With regard to our criteria on functionality, our
benchmark evaluates the expressivity of schema
transformation mechanisms in the sense that it covers
basic DDL operations, and the complex transforma-
tions as discussed in 4. The ability to perform applica-
tion migration is only covered in the sense that stored
procedures can be updated. More complex migration
approaches such as schema versioning are not cov-
ered. Our criteria specify that transformations should
be specified declaratively, but an implementation of
our benchmark does not have to adhere to this. It
is up to the implementor to evaluate this aspect. For
the correctness of benchmark results, we assume that
all transformations are implemented correctly, that the
data is transformed correctly, and that the ACID guar-
antees are satisfied.
With regard to our performance criteria, our
benchmark measures throughput, blocking and aborts
of the TPC-C transactions. Moreover, we measure
the time to commit of schema transformations, and
we can detect whether schema transformations abort.
Our benchmark does not cover the impact of recovery
in case of system failure, and it does not cover mem-
ory consumption of schema transformations. How-
ever, our benchmark could be extended to cover these
cases. Finally, note that for accurate results, a suffi-
ciently large TPC-C instance should be used to show
the impact of the schema transformations. Moreover,
the database should be given sufficient time to warm
up, and no background tasks should be running.
6 IMPLEMENTATION AND
RESULTS
As the main topic of this paper is the presentation of
the benchmark, an in depth analysis of our experimen-
tal results is outside the scope of this paper. However,
in this section we briefly discuss our implementation
of the benchmark, and provide example results. A
detailed analysis of our experimental results can be
found in our technical report (Wevers et al., 2014).
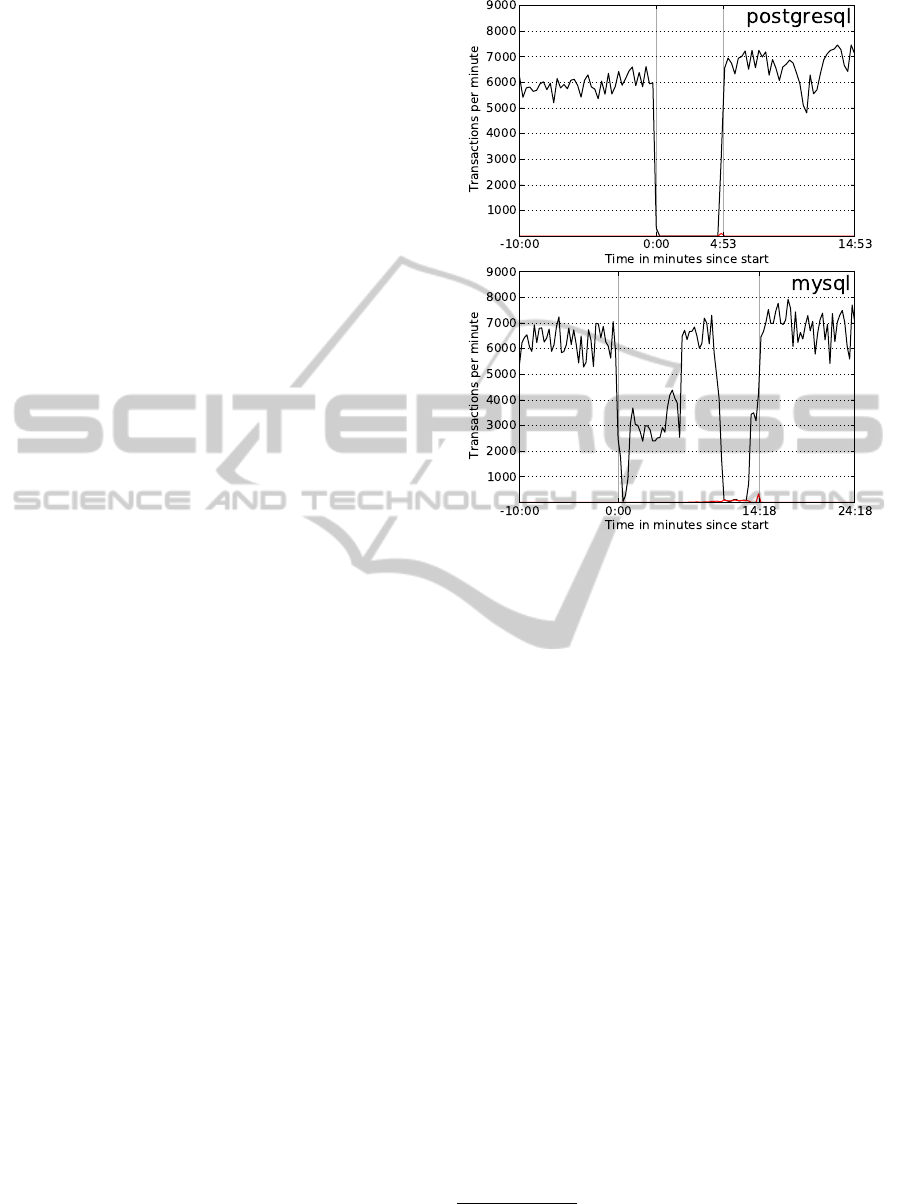
Figure 2: Benchmark results for PostgreSQL and MySQL
for the defactorize case.
We have implemented benchmark scripts for Post-
greSQL and MySQL, which can be accessed from our
website
5
. We use the TPC-C implementation Ham-
merDB
6
to create the TPC-C database and to provide
stored procedures. We generate one TPC-C database
for each DBMS, which we backup once, and then re-
store in the setup phase of every experiment. Before
starting the introduction phase of the experiment, we
let the TPC-C benchmark run for ten seconds, as to
give the DBMS some time to warm up. Finally, to
generate load on the system, and to measure the TPC-
C performance, HammerDB provides a driver script.
However, as this script does not perform logging of
transactions, we have ported the script to Java and we
have added logging facilities.
2 shows typical results for PostgreSQL and
MySQL for the complex transformation cases. While
PostgreSQL supports transactional DDL and can per-
form many DDL operations instantaneously, the DDL
operations do still take a full table lock, which per-
sist during the transaction. Moreover, bulk UPDATE
statements also take a full table lock, and can take a
long time to complete. The effect is that the TPC-C
workload is completely blocked. In contrast to Post-
greSQL, MySQL cannot perform DDL operations in-
5
wwwhome.ewi.utwente.nl/
∼
weversl2/?page=ost
6
hammerora.sourceforge.net
ABenchmarkforOnlineNon-blockingSchemaTransformations
297

stantaneously, but it can perform some of them online.
However, MySQL commits every DDL operation im-
mediately after it is executed, which means that stored
procedures may need to be updated after every trans-
formation step. In 2, MySQL shows a short period
of blocking at the beginning of the transformation
when adding a column, and we see reduced through-
put while the column is being added. The last phase
of the transformation involves an UPDATE, where we
see that MySQL blocks the TPC-C workload.
7 CONCLUSIONS
Current DBMSs have poor support for non-blocking
online schema transformations beyond basic transfor-
mations. The literature describes a number of meth-
ods for non-blocking schema transformations. How-
ever, these techniques do not cover all cases, and gen-
erally do not compose without exposing intermediate
states of the transformation. While complex transfor-
mations are generally possible by adapting programs
to work on intermediate states, these transformations
are non-declarative, and require significant develop-
ment effort to implement.
While we do not provide solutions to solve this
problem, we have provided criteria that clarify the
problem, and we have specified characteristics of
an ideal solution. In particular, we would like to
see that DBMSs provide a mechanism for declara-
tive and composable non-blocking schema transfor-
mations that satisfy the ACID properties. We have
provided a benchmarking methodology together with
a concrete benchmark to evaluate schema change
mechanisms with regard to our criteria. With this
benchmark, we challenge the database community
to find solutions to allow transactional non-blocking
schema transformations.
REFERENCES
Chen, P. P.-S. (1976). The Entity-relationship Model – To-
ward a Unified View of Data. ACM Transactions on
Database Systems, 1(1):9–36.
Curino, C. A., Moon, H. J., Deutsch, A., and Zaniolo, C.
(2010). Update Rewriting and Integrity Constraint
Maintenance in a Schema Evolution Support System:
PRISM++. PVLDB, 4(2):117–128.
Curino, C. A., Tanca, L., Moon, H. J., and Zaniolo, C.
(2008). Schema evolution in wikipedia: toward a web
information system benchmark. In ICEIS, pages 323–
332.
Garcia-Molina, H. and Salem, K. (1987). Sagas. In SIG-
MOD ’87, pages 249–259. ACM.
Gupta, A. and Mumick, I. S. (1995). Maintenance of ma-
terialized views: Problems, techniques, and applica-
tions. IEEE Data Engineering Bulletin, 18(2):3–18.
Løland, J. and Hvasshovd, S.-O. (2006). Online, Non-
blocking Relational Schema Changes. In EDBT ’06,
pages 405–422, Berlin, Heidelberg. Springer-Verlag.
Neamtiu, I., Bardin, J., Uddin, M. R., Lin, D.-Y., and Bhat-
tacharya, P. (2013). Improving Cloud Availability
with On-the-fly Schema Updates. COMAD ’13, pages
24–34. Computer Society of India.
Neamtiu, I. and Dumitras, T. (2011). Cloud soft-
ware upgrades: Challenges and opportunities. In
MESOCA ’11, pages 1–10. IEEE.
Rae, I., Rollins, E., Shute, J., Sodhi, S., and Vingralek, R.
(2013). Online, Asynchronous Schema Change in F1.
In VLDB ’13, pages 1045–1056.
Roddick, J. F. (1995). A survey of schema versioning is-
sues for database systems. Information and Software
Technology, 37:383–393.
Ronstr
¨
om, M. (2000). On-Line Schema Update for a Tele-
com Database. In ICDE ’00, pages 329–338. IEEE.
Sockut, G. H. and Iyer, B. R. (2009). Online Reorganization
of Databases. ACM Computing Surveys, pages 14:1–
14:136.
TPC (2010). TPC Benchmark C Standard Specification.
www.tpc.org/tpcc/spec/tpcc current.pdf. Accessed 19
may 2015.
Wevers, L., Hofstra, M., Tammens, M., Huisman, M., and
van Keulen, M. (2014). Towards Online and Transac-
tional Relational Schema Transformations. Technical
Report TR-CTIT-14-10, University of Twente.
DATA2015-4thInternationalConferenceonDataManagementTechnologiesandApplications
298
