
Trajectory Tracking Control of Robot Manipulators using Discrete
Time-varying Pole Placement Technique
Yasuhiko Mutoh, Masakatsu Kemmotsu and Lisa Awatsu
Department of Engineering and Applied Sciences, Sophia University, 7-1 Kiocho, Chiyoda-ku, Tokyo, Japan
Keywords:
Trajectory Tracking Control, Linear Time-varying System, Discrete System, Time-Varying Pole Placement
Control.
Abstract:
For the trajectory tracking control problem of nonlinear systems, the most basic and classic strategy may
be applying the linear control technique to a linear time-varying approximate model around some desired
trajectory. However, this method is not commonly used because the design of a linear time-varying controller
is not simple. The authors proposed the simple design method of the pole placement controller for linear
time-varying discrete systems. In this paper, to show the applicability of the proposed linear time-varying
discrete pole placement technique to the trajectory tracking control problem of nonlinear systems, we apply
this control method to actual 2-link robot manipulator and present the experimental results.
1 INTRODUCTION
For the trajectory tracking control problem of non-
linear systems, the most basic and classic strategy
may be applying the linear control technique to a lin-
ear time-varying approximate model around some de-
sired trajectory. This method can be applied to any
type of nonlinear systems. However, since, controller
design method for linear time-varying system is not
necessarily simple (Nguyen(1987)) (Valsek(1995))
(Valsek(1999)), gain scheduling strategy, the nonlin-
ear control strategy, or PID control is commonly used
for such a control design problem.
The author et.al. proposed the simple pole place-
ment controller design method for linear time-varying
discrete systems (Mutoh(2011)) (Mutoh and Hara
(2011)). Such controller is obtained by finding a new
output signal so that the relative degree from the input
to this new output is equal to the system degree.
In this paper, we apply this control method to the
tracking control of an actual 2-link robot manipulator
to show the applicability of the proposed linear time-
varying discrete pole placement technique to the tra-
jectory tracking control problem of practical nonlin-
ear systems. In the following, some basic properties
of linear time-varying discrete systems are stated in
Section 2. Section 3 summarizes the design procedure
of a pole placement controller for linear time-varying
discrete systems. In Section 4, this control method
is applied to the trajectory tracking control problems
of practical 2-link robot manipulator and experimen-
tal results are presented to show the validity of this
control system.
2 BASIC PROPERTIES OF
LINEAR TIME-VARYING
DISCRETE SYSTEMS
In this section, some basic properties of linear time
varying multi variable discrete systems are presented.
Consider the following system.
x(k+ 1) = A(k)x(k) + B(k)u(k) (1)
Here, x ∈ R
n
and u ∈ R
m
are the state variable and the
input. A(k) ∈ R
n×n
and B(k) ∈ R
n×m
are time-varying
coefficient matrices. The state transition matrix of the
system (1) from k = j to k = i, Φ(i, j), is defined as
follows.
Φ(i, j) = A(i− 1)A(i− 2)···A( j) i > j (2)
Definition 1. System (1) is called ”completely reach-
able in n steps” if and only if, for any x
1
∈ R
n
there
exists a bounded input u(l) (l = k, ··· , k+n−1) such
that x(k) = 0 and x(k + n) = x
1
for all k.
Lemma 1. System (1) is completely reachable in n
steps if and only if the rank of the reachability matrix
defined below is n for all k.
U
R
(k) =
B
0
(k), B
1
(k), ··· , B
n−1
(k)
(3)
373
Mutoh Y., Kemmotsu M. and Awatsu L..
Trajectory Tracking Control of Robot Manipulators using Discrete Time-varying Pole Placement Technique.
DOI: 10.5220/0005533603730379
In Proceedings of the 12th International Conference on Informatics in Control, Automation and Robotics (ICINCO-2015), pages 373-379
ISBN: 978-989-758-122-9
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

where,
B
0
(k) = B(k + n− 1)
B
1
(k) = Φ(k+ n, k+ n− 1)B(k + n− 2)
.
.
. (4)
B
n−1
(k) = Φ(k+ n, k+ 1)B(k)
Let b
l
i
(k) be the i-th column of B
l
(k), then, the reach-
ability matrix U
R
(k) can be written as
U
R
(k) =
b
0
1
(k)···b
0
m
(k)|···|b
n−1
1
(k)···b
n−1
m
(k)
(5)
Note that b
r
i
(k) also satisfies the same equation as
(4), i.e.,
b
0
i
(k) = b
i
(k+ n − 1)
b
1
i
(k) = Φ(k + n, k+ n− 1)b
i
(k+ n − 2)
.
.
. (6)
b
n−1
i
= Φ(k + n, k+ 1)b
i
(k) (i = 1, ··· , m)
where b
i
(k) is the i-th column of B(k). Suppose that
the system (1) is completely reachable in n steps.
Then, the reachability indices, µ
i
(i = 1, ··· , m), can
be defined such that
m
∑
i=1
µ
i
= n (7)
and the n× n truncated reachability matrix
R(k) =
h
b
0
1
(k), ··· , b
µ
1
−1
1
(k)|···|b
0
m
(k), ··· , b
µ
m
−1
m
i
(8)
is non-singular. It is assumed that µ
1
≥ µ
2
≥ ·· · ≥ µ
m
without loss of generality.
Finally, the vector relative degree of a linear
MIMO system is defined. Let the following η(k) ∈
R
m
be the output vector of the system (1).
η(k) = H(k)x(k), H(k) ∈ R
m×n
(9)
Definition 2. System (1), (9) has the vector relative
degree, r
1
, r
2
, ···, r
m
from u to η, if and only if there
exist some matrix D(k) ∈ R
m×n
and some nonsingular
matrix Λ(k) ∈ R
m×m
that satisfy the following equa-
tion.
α
1
(z)
.
.
.
α
m
(z)
η(k) = D(k)x(k)+Λ(k)u(k)
(10)
Here, α
k
(z) is an arbitrary monic polynomial of de-
gree r
k
and z is a forward shift operator.
3 DESIGN OF DISCRETE
TIME-VARYING POLE
PLACEMENT CONTROLLER
In this section, the design procedure of the pole place-
ment controller for linear time-varying multi input
discrete systems is summarized. Suppose that the
system (1) is completely reachable with its reacha-
bility indices, µ
1
, ··· , µ
m
. The problem is to design a
state feedback for the system (1) so that the resulting
time-varying closed-loop system becomes equivalent
to some linear time-invariant system with arbitrarily
stable poles. For this purpose, we first define a new
output signal y(k) ∈ R
m
of the system (1) by
y(k) = C(k)x(k) (11)
so that the total relative degree from u(k) to y(k) is
equal to the system degree n. Here,
y(k) =
y
1
(k)
y
2
(k)
.
.
.
y
m
(k)
∈ R
m
, C(k) =
c
1
(k)
c
2
(k)
.
.
.
c
m
(k)
∈ R
m×n
(12)
where y
i
(k) ∈ R and c
i
(k) ∈ R
1×n
. We have the fol-
lowing Theorem (Mutoh and Hara (2011)).
Theorem 1. If the system (1) is completely reachable
in n steps, there exists a new output y(k) such that
the vector relative degree from u(k) to y(k) becomes
µ
1
, ··· , µ
m
, which implies that the total relative degree
from u(k) to y(k) is n. And, such C(k) can be calcu-
lated by the following equation.
C(k) = WR
−1
(k− n) (13)
where
W = diag(w
1
, w
2
, ··· , w
m
)
w
i
=
0 ··· 0 1
∈ R
1×µ
i
(14)
(i = 1, ··· , m)
From this, the pole placement state feedback is ob-
tained in the following procedure.
Let q
i
(z) be the desired stable characteristic poly-
nomial of z as
q
i
(z) = z
µ
i
+ α
i
µ
i
−1
z
µ
i
−1
+ · ·· + α
i
1
z+ α
i
0
. (15)
(i = 1, ··· , m)
Since, the vector relative degree from u(k) to y(k) is
µ
1
, µ
2
, ···, µ
m
, we have the following equation.
q
1
(z)
.
.
.
q
m
(z)
y(k) = D(k)x(k) + Λ(k)u(k)
(16)
ICINCO2015-12thInternationalConferenceonInformaticsinControl,AutomationandRobotics
374

Here,
D(k) =
D
1
(k)
D
2
(k)
.
.
.
D
m
(k)
, Λ(k) =
Λ
1
(k)
Λ
2
(k)
.
.
.
Λ
m
(k)
(17)
and D
i
(k) ∈ R
1×n
and Λ
i
(k) ∈ R
1×n
are defined by
D
i
(k) =
α
i
0
, α
i
1
, ··· , α
i
µ
i
−1
, 1
c
0
i
(k)
c
1
i
(k)
.
.
.
c
µ
i
i
(k)
(18)
Λ
i
(k) = [0, ·· · , 0, 1, γ
i(i+1)
, ··· , γ
im
].
In the above equation, c
l
i
(k) is defined by the follow-
ing recursive equations, using c
i
(k),
c
0
i
(k) = c
i
(k)
c
(l+1)
i
(k) = c
l
i
(k+ 1)A(k) (19)
(l = 0, 1, 2, ···)
and,
γ
ij
= c
µ
i
−1
i
(k+ 1)b
j
(k) (20)
for i = 1, ·· · , m. Then, by applying the state feedback
u(k) = −Λ
−1
(k)D(k)x(k) (21)
to the system (1), the closed loop system becomes as
follows.
q
1
(z)
.
.
.
q
m
(z)
y(k) = 0 (22)
This system is time-invariant and has the following
state representation.
w(k+ 1) = A
∗
w(k) (23)
where w(k) ∈ R
n
is the new state variable. The matri-
ces A
∗
∈ R
n×n
is written by
A
∗
=
A
∗
1
0
.
.
.
0 A
∗
m
(24)
and A
∗
i
∈ R
µ
i
×µ
i
is defined as follows.
A
∗
i
=
0 1 0
.
.
.
.
.
.
.
.
.
.
.
. 1
−α
i
0
. . . . . . −α
i
µ
i
−1
(i = 1, . . . , m) (25)
From this, the characteristic polynomial of A
∗
is writ-
ten as follows using q
i
(z) defined by (15).
q(z) =
m
∏
i=1
q
i
(z) (26)
(19) and (22) imply that w(k) is written as follows.
w(k) :=
y
1
(k)
.
.
.
y
1
(k+ µ
1
− 1)
.
.
.
y
m
(k)
.
.
.
y
m
(k+ µ
m
− 1)
=
c
0
1
(k)
.
.
.
c
µ
1
−1
1
(k)
.
.
.
c
0
m
(k)
.
.
.
c
µ
m
−1
m
(k)
x(k)
= P(k)x(k) (27)
On the other hand, from (1) and (21), the time-
varying state equation of the closed loop system be-
comes
x(k+ 1) = (A(k) − B(k)Λ
−1
D(k))x(k). (28)
Thus, the system (28) is equivalentto the system (23),
with the transformation matrix P(k). It is then obvi-
ous that the following equation holds.
P(k+ 1)(A(k) − B(k)Λ
−1
D(k))P
−1
(k) = A
∗
(29)
This implies that the state feedback (21) makes the
closed loop system equivalent to the system (23) that
has an arbitrarily stable characteristic polynomial,
q(z).
Note that the transformation matrix P(k) and
P
−1
(k) must be bounded functions, in other words,
P(k) must be a Lyapunov transformation, to ensure
the stability of the closed-loop system.
The procedures to obtain the state feedback gain
is summarized below.
Pole Placement Design Procedure
STEP 1. Calculate the reachability matrix U
R
(k− n)
and the reachability indices µ
i
.
STEP 2. Calculate C(k) = WR
−1
(k − n) for the new
output signal, y(k), using the truncated reachabil-
ity matrix R(k).
STEP 3. Determine the desired stable closed-loop
characteristic polynomials as follows for i =
1, ··· , m.
q
i
(z) = z
µ
i
+ α
i
µ
i
−1
z
µ
i
−1
+ · ·· + α
i
1
z+ α
i
0
STEP 4. Using (17) ∼ (20), calculate D(k) and Λ(k).
Then, the state feedback for the pole placement is
u(k) = −Λ
−1
(k)D(k)x(k)
TrajectoryTrackingControlofRobotManipulatorsusingDiscreteTime-varyingPolePlacementTechnique
375
4 TRAJECTORY TRACKING
CONTROL OF 2-LINK
MANIPULATORS
In this section, discrete time-varying pole placement
technique is applied to the trajectory tracking control
of a two-link robot manipulator.
4.1 The Model of the Manipulator
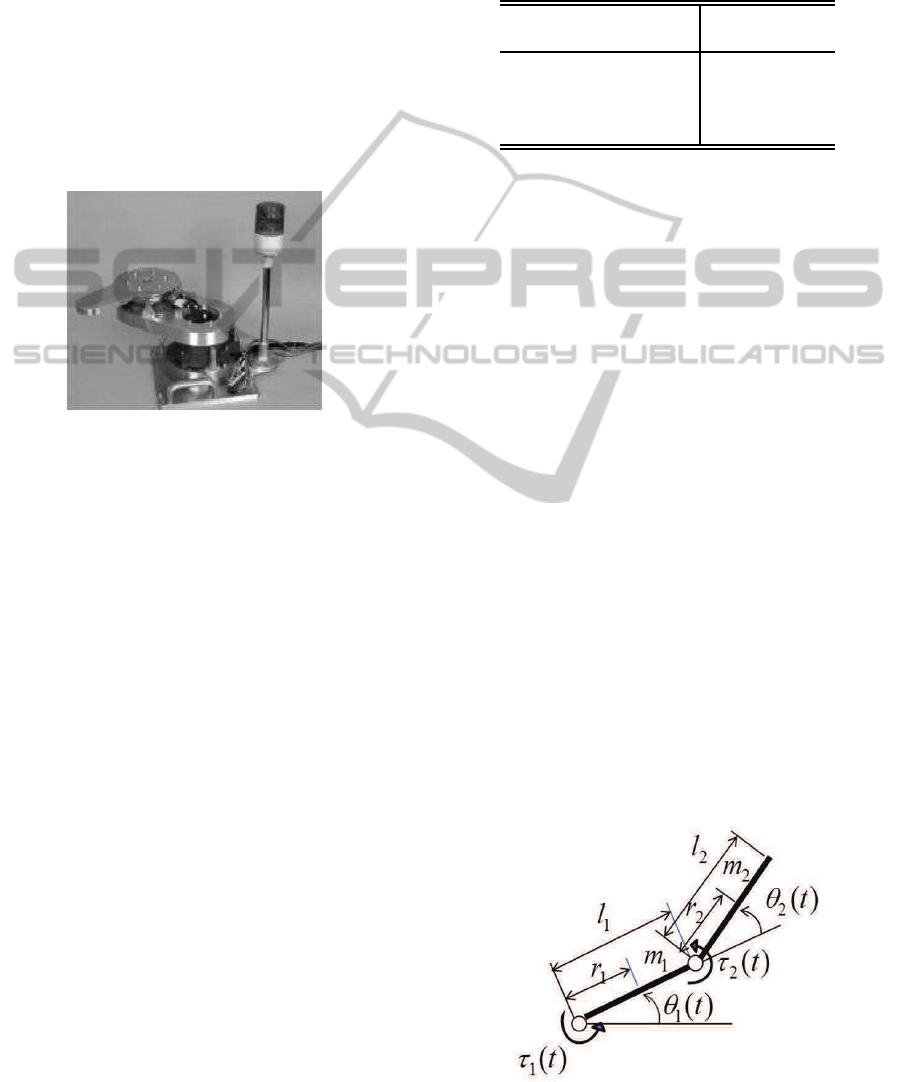
Fig. 1 and Fig. 2 show the picture and the model of
the 2-link robot manipulator for the experiment. All
links rotate in the horizontal plane.
Figure 1: Two-Link Manipulator(SR-402DDII.)
Its motion equation is described as follows.
M(θ(t))
¨
θ(t) +C(θ(t),
˙
θ(t))
˙
θ(t) + D(
˙
θ(t)) = τ(t)
(30)
where,
θ(t) =
θ
1
(t)
θ
2
(t)
M(θ(t)) =
J
1
+ J
2
+ 2m
2
r
2
l
1
cosθ
2
(t),
J
2
+ m
2
r
2
l
1
cosθ
2
(t),
J
2
+ m
2
r
2
l
1
cosθ
2
(t)
J
2
C(θ(t),
˙
θ(t)) =
−2m
2
r
2
l
1
˙
θ
2
(t)sinθ
2
(t),
m
2
r
2
l
1
˙
θ
1
(t)sinθ
2
(t),
−m
2
r
2
l
1
˙
θ(t)
2
sinθ
2
(t)
0
D(
˙
θ(t)) =
2sgn(
˙
θ
1
(t))
0.25sgn(
˙
θ
2
(t))
J
i
= J
l
i
+ m
i
r
2
i
(i = 1, 2).
Here, θ
i
(t) and τ
i
(t) are joint angle and input torque
of i-th joint, l
i
and r
i
are length of the i-th link and
the distance between the i-th joint and the center of
gravity of the i-th link, and J
l
i
is the moment of inertia
of the i-th link about its center of gravity (i = 1, 2).
D(
˙
θ(t)) is a friction term which is estimated from the
experimental data.
In the above, the values of the physical parameters
are shown in Table 1.
Table 1: Parameter of Manipulator.
variable unit link1 link2
(i = 1, 2)
i = 1 i = 2
m
i
[kg] 3.43 1.55
l
i
[m] 0.2 0.2
r
i
[m]
0.1 0.1
J
l
i
[kgm
2
]
0.208 0.03
4.2 Experimental Results
In this section, we show the experimental result of the
trajectory tracking control of the 2-link robot manip-
ulator using the time-varying discrete pole placement
controller.
To design the discrete controller, we discretize the
manipulator system (30) by Euler method as follows.
Here, T
s
is the sampling time.
x(k+ 1) = x(k) +
0 T
s
I
2
0 T
s
Γ(x(k))
x(k)
+
0
T
s
Φ(x(k))
u(k)
= f(x(k), u(k)) (31)
where
x(k) =
θ(k)
˙
θ(k)
∈ R
4
u(k) =
τ
1
(k)
τ
2
(k)
∈ R
2
(32)
I
2
=
1 0
0 1
Γ(x(k)) = −M(θ(k))
−1
C(θ(k),
˙
θ(k)) ∈ R
2×2
Φ(x(k)) = M(θ(k))
−1
∈ R
2×2
Figure 2: Two-Link Manipulator Model.
ICINCO2015-12thInternationalConferenceonInformaticsinControl,AutomationandRobotics
376
The sampling time T
s
is 10 [msec] for the experi-
ment.
Let the desired trajectory of the end portion of this
manipulator be the circle in the horizontal X-Y work
space as presented by the the following equation,
X(t) = 0.08cos
π
5
t + 0.3 (33)
Y(t) = 0.08sin
π
5
t + 0.05 (34)
which is described in Fig.3.
0.2 0.3 0.4 0.45
−0.05
0
0.1
0.2
x
[m]
y [m]
Figure 3: Desired Trajectory of the End Portion.
From the desired trajectory of the end portion, the
desired trajectory of the joint angles, θ
∗
(t), and their
speed,
˙
θ
∗
(t), can be calculated using the inverse kine-
matics. Which gives the desired state variable x
∗
(t) as
follows.
x
∗
(t) =
θ
∗
(t)
˙
θ
∗
(t)
(35)
The desired input signal u
∗
(t) is obtained from θ
∗
(t)
and
˙
θ
∗
(t) using (30). MAXIMA is used to calcu-
late the explicit function representations for x
∗
(t) and
u
∗
(t), which are omitted here because of the space
limitation. Instead of this, the graphs of x
∗
(t) and
u
∗
(t) are shown in Fig.4 and 5.
By discretizing these signals using the sampling
time T
s
, the discrete desired state trajectory x
∗
(k) and
the discrete desired input u
∗
(k) are obtained. Note
that we use the same variable for continuous space
and discrete space, i.e., x(t) is continuous variable,
0 5 10 15
−1
0
1
2
2.5
time [sec]
x
( )
x
( )
x
( )
x
( )
x
( )
t
t
t
t
t
Figure 4: Desired Trajectory x
∗
(t).
0 5 10 15
−4
−2
0
2
4
time [sec]
u
1
( ) [Nm]
0 5 10 15
−0.5
0
0.5
time [sec]
u
2
( ) [Nm]
t
t
Figure 5: Desired Input u
∗
(t).
x(k) is a discrete variable of k-th step and x(kT
s
) is a
sampling variable in the t-axis.
To obtain the linear time-varying approximate
model around the desired trajectory, x
∗
(k) and u
∗
(k),
define ∆x(k) and ∆u(k) by
∆x(k) = x(k) − x
∗
(k)
∆u(k) = u(k) − u
∗
(k)
(36)
Then we have the following approximate model from
(31).
x(k+ 1) =
∂
∂x
f(x
∗
(k), u
∗
(k))∆x(k)
+
∂
∂u
f(x
∗
(k), u
∗
(k))∆u(k)
= A(k)∆x(k) + B(k)∆u(k) (37)
where,
A(k) =
0 0 1 0
0 0 0 1
0 a
32
(k) a
33
(k) a
34
(k)
0 a
42
(k) a
43
(k) a
44
(k)
(38)
B(k) =
0 0
0 0
β
31
(k) β
32
(k)
β
41
(k) β
42
(k)
(39)
Here, the explicit function representation of A(k) and
B(k) are obtained by using MAXIMA, which are de-
scribed in Appendix A, for reference.
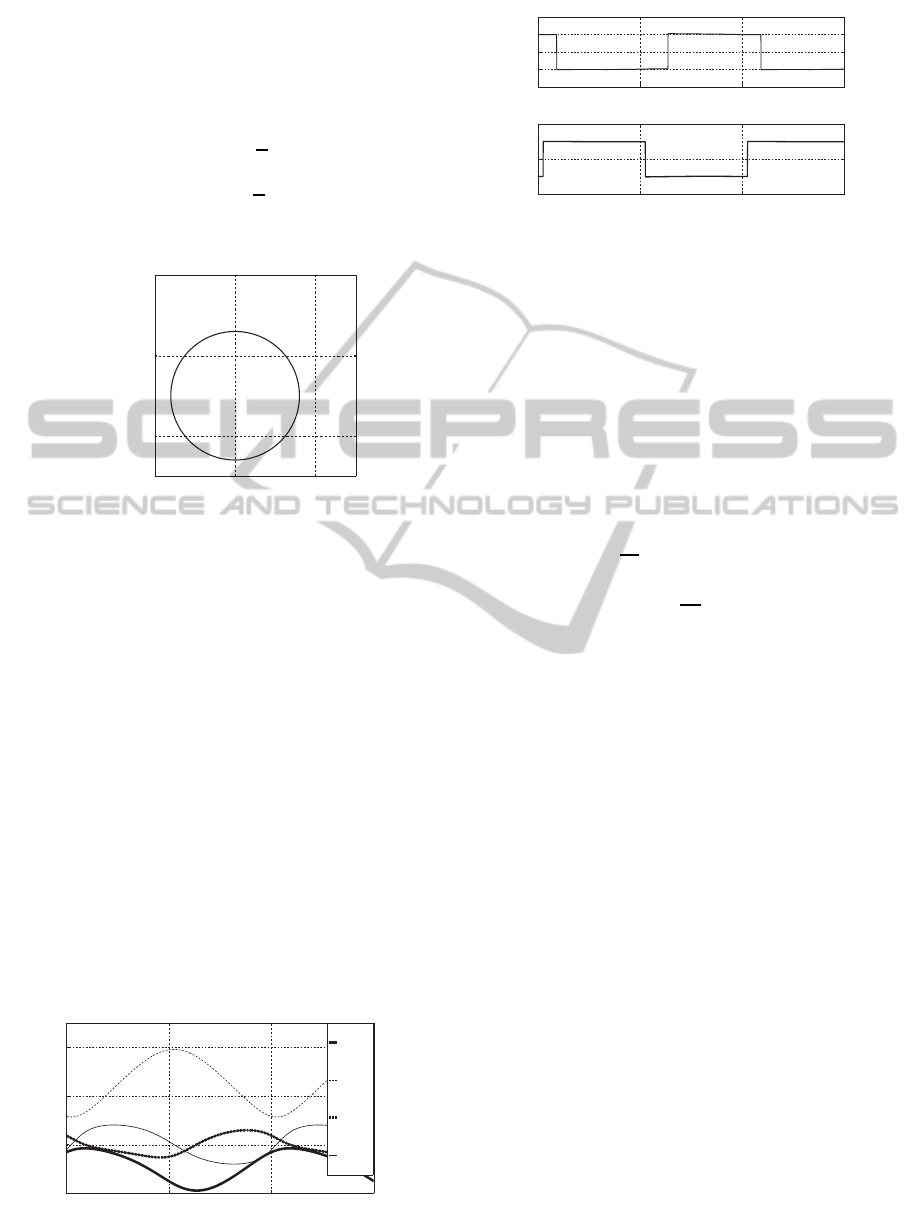
Fig.6 shows the closed loop response of the ma-
nipulator end portion in the horizontal work space.
The initial position of the end portion is (0.4, 0) in
the coordinate of the horizontal work space. This ini-
tial condition corresponds to the initial condition of
state variable vector, x
1
(0) = x
2
(0) = x
3
(0) = x
4
(0) =
0. The response of the manipulator state variable
x(kT
s
) (joint angles and their speed), the state er-
ror ∆x(kT
s
) = x(kT
s
) − x
∗
(kT
s
), are shown in Fig.7
TrajectoryTrackingControlofRobotManipulatorsusingDiscreteTime-varyingPolePlacementTechnique
377

and Fig.8 respectively. The control input u(kT
s
) =
u
∗
(kT
s
) + ∆u(kT
s
) is shown in Fig.9. The desired sta-
ble poles of the closed loop system and the observer
are chosen as (−5, −90, −5, −90).
0.2 0.3 0.4 0.45
−0.05
0
0.1
0.2
x [m]
y [m]
Experimental Result
Desired Trajectory
Figure 6: Response of End Portion.
0 5 10 15
−1
0
1
2
2.5
time [sec]
x(kTs)
x
1
(kTs)
x
2
(kTs)
x
3
(kTs)
x
4
(kTs)
Figure 7: Response of State Variable x(k).
0 5 10 15
−1
0
1
2
2.5
time [sec]
∆x(kTs)
∆x
1
(kTs)
∆x
2
(kTs)
∆x
3
(kTs)
∆x
4
(kTs)
Figure 8: State Error ∆x(k) = x(k) − x
∗
(k).
0 5 10 15
−4
−2
0
2
4
time [sec]
u
1
(kTs) [Nm]
0 5 10 15
−0.5
0
0.5
time [sec]
u
2
(kTs) [Nm]
Figure 9: Input Torque u(k).
5 CONCLUSIONS
In this paper, the trajectory tracking control of non-
linear systems was considered. For this purpose, the
pole placement controller designed by the simple pro-
cedure was applied to the linear time-varying discrete
approximate model of the system around some de-
sired trajectory. This controller was applied to track-
ing control of the actual 2-link robot manipulator to
show the applicability of this type of controller. The
experimental results showed that this controller has
very good performance.
REFERENCES
Chi-Tsong Chen (1999) C Linear System Theory and De-
sign (Third edition). Oxford University Press
Charles C. Nguyen (1987) C Arbitrary eigenvalue assign-
ments for linear time-varying multivariable control
systems. International Journal of Control, 45-3, 1051–
1057
W. J. Rugh (1993) Linear System Theory 2nd Edition pren-
tice hall
Y. Mutoh (2011) C A New Design Procedure of the Pole-
Placement and the State Observer for Linear Time-
Varying Discrete Systems. Informatics in Control, Au-
tomation and Robotics, p.321-334, Springer
Michael Val´aˇsek (1995) C Efficient Eigenvalue Assignment
for General Linear MIMO systems. Automatica, 31-
11, 1605–1617
Michael Val´aˇsek, Nejat Olgac¸ (1999) C Pole placement
for linear time-varying non-lexicographically fixed
MIMO systems. Automatica, 35-1, 101–108
Y. Mutoh and N. Kimura (2011) C Observer-Based
Pole Placement for Non-Lexicographically-fixed Lin-
ear Time-Varying Systems. 50th IEEE CDC and ECC
Y. Mutoh and T. Hara (2011) C A New Method for Pole
Placement of Linear Time-Varying Discrete Multivari-
able Systems. 30th CCC
APPENDIX
The followings are the explicit form of functioins of
the elements of A(t) and B(t) in equation (37) calcu-
lated by MAXIMA. We used this result with T = T
s
.
ICINCO2015-12thInternationalConferenceonInformaticsinControl,AutomationandRobotics
378

a
32
=
31
28830cos(x
2
(k))
3
x
4
(k)
2
+ 185340cos(x
2
(k)) x
4
(k)
2
T
(31cos(x
2
(k))− 90)
2
(31cos(x
2
(k))+ 90)
2
+
31
57660cos(x
2
(k))
3
x
3
(k) x
4
(k) +370680cos(x
2
(k)) x
3
(k) x
4
(k)
T
(31cos(x
2
(k))− 90)
2
(31cos(x
2
(k))+ 90)
2
+
31
28830cos(x
2
(k))
3
x
3
(k)
2
+ 472409cos(x
2
(k))
2
x
3
(k)
2
(31cos(x
2
(k))− 90)
2
(31cos(x
2
(k))+ 90)
2
+
31
185340cos(x
2
(k)) x
3
(k)
2
− 251100x
3
(k)
2
T
(31cos(x
2
(k))− 90)
2
(31cos(x
2
(k))+ 90)
2
a
33
= 1−
62sin(x
2
(k)) (30x
4
(k) +31cos(x
2
(k)) x
3
(k) +30x
3
(k)) T
(31cos(x
2
(k))− 90) (31cos(x
2
(k))+ 90)
a
34
= −
1860sin(x
2
(k)) (x
4
(k) +x
3
(k)) T
(31cos(x
2
(k))− 90) (31cos(x
2
(k))+ 90)
a
42
= −
31(28830cos(x
2
(k))
3
x
4
(k)
2
+ 472409cos(x
2
(k))
2
x
4
(k)
2
)T
(31cos(x
2
(k)) − 90)
2
(31cos(x
2
(k)) + 90)
2
−
31(185340∗ cos(x
2
(k))x
4
(k)
2
− 251100x
4
(k)
2
)T
(31cos(x
2
(k)) − 90)
2
(31cos(x
2
(k)) + 90)
2
−
31(57660cos(x
2
(k))
3
∗ x
3
(k)x
4
(k) +944818cos(x
2
(k))
2
x
3
(k)x
4
(k))T
(31cos(x
2
(k)) − 90)
2
(31cos(x
2
(k)) + 90)
2
−
31(370680cos(x
2
(k))x
3
(k)x
4
(k) −502200x
3
(k)x
4
(k))T
(31cos(x
2
(k)) − 90)
2
(31cos(x
2
(k)) + 90)
2
−
31(288300cos(x
2
(k))
3
x
3
(k)
2
+ 944818cos(x
2
(k))
2
x
3
(k)
2
)T
(31cos(x
2
(k)) − 90)
2
(31cos(x
2
(k)) + 90)
2
+
31(1853400cos(x
2
(k))
2
x
3
(k) −502200x
3
(k)
2
)T
(31cos(x
2
(k)) − 90)
2
(31∗ cos(x
2
(k)) + 90)
2
a
43
=
62sin(x
2
(k)) (31cos(x
2
(k)) x
4
(k) +30x
4
(k) +62cos(x
2
(k)) x
3
(k))T
(31cos(x
2
(k))− 90) (31cos(x
2
(k))+ 90)
+
31(300x
3
(k)) T
(31cos(x
2
(k))− 90) (31cos(x
2
(k))+ 90)
a
44
=
62 (31cos(x
2
(k))+ 30) sin(x
2
(k)) (x
4
(k) +x
3
(k)) T
(31cos(x
2
(k))− 90) (31cos(x
2
(k))+ 90)
+ 1
b
31
= −
30000T
961cos(x
2
(k))
2
− 8100
b
32
=
(31000cos(x
2
(k))+ 30000) T
961cos(x
2
(k))
2
− 8100
b
41
=
(31000cos(x
2
(k))+ 30000) T
961cos(x
2
(k))
2
− 8100
b
42
= −
(62000cos(x
2
(k))+ 300000) T
961cos(x
2
(k))
2
− 8100
.
TrajectoryTrackingControlofRobotManipulatorsusingDiscreteTime-varyingPolePlacementTechnique
379
