
Off-line State-dependent Parameter Models Identification using Simple
Fixed Interval Smoothing
Elvis Omar Jara Alegria, Hugo Tanzarella Teixeira and Celso Pascoli Bottura
Semiconductors, Instruments, and Photonics Department, School of Electrical and Computer Engineering,
State University of Campinas - UNICAMP, Av. Albert Einstein, N. 400 - LE31 - CEP 13081-970, Sao Paulo, Brazil
Keywords:
Time Series Identification, State-dependent Parameter, Data Reordering.
Abstract:
This paper shows a detailed study about the Young’s algorithm for parameter estimation on ARX-SDP models
and proposes some improvements. To reduce the high entropy of the unknown parameters, data reordering
according to a state ascendant ordering is used on that algorithm. After the Young’s temporal reordering
process, the old data do not necessarily continue so. We propose to reconsider the forgetting factor, internally
used in the exponential window past, as a fixed and small value. This proposal improves the estimation
results, especially in the low data density regions, and improves the algorithm velocity as experimentally
shown. Other interesting improvement of our proposal is characterized by the flexibility to the changes on the
state-parameter dependency. This is important in a future On-Line version. Interesting features of the SDP
estimation algorithm for the case of ARX-SDP models with unitary regressors and the case with correlated
state-parameter are also studied. Finally a example shows our results using the INCA toolbox we developed
for our proposal.
1 INTRODUCTION
Parameters of linear regression models can be satis-
factorily estimated by using conventional estimation
methods for Time Variable Parameters (TVP) based
on least squares techniques, but its time parameter
variations must be slow compared to the system state
variations (Yaakov Bar-Shalom, 2001). But when the
system presents State Dependent Parameters (SDP)
(Priestley, 1988) the model response can be heavily
nonlinear and even chaotic. The regression models
with SDP, called SD-ARX (Priestley, 1988; Young
et al., 2001) or quasi-ARX (Hu et al., 2001; F. Pre-
vidi, 2003), are always non-linear due to the product
between the regressor function and the SDP. Conven-
tional methods can’t estimate SDP models because
parameters vary very fast.
Young proposed a solution to SDP estimation
(Young et al., 2001). It’s based in a special tempo-
ral data reordering to smoothen the parameter varia-
tions. This proposed algorithm uses an optimal Fixed
Interval Smoothing (FIS) algorithm as a first approx-
imation and next a model with reordered data is re-
cursively estimated. His justification for that data re-
ordering is based on the fact that if this dependence
between a parameter and a state exists, then both
should react the same manner to this data reordering.
Young shows that when the data and estimated pa-
rameters are returned to the normal temporal order,
then the relationship among the SDP and the respec-
tive state is turned evident. When the time series are
sorted in ascending order of magnitude, then the rapid
natural variations are effectively eliminated from the
data and replaced by much smoother and less rapid
variations.
This paper studies the Young’s algorithm in detail
for SDP estimation and the forgetting factor α of the
Exponentially-Weighted-Past (EWP) used on the FIS
estimations with data reordering. We proposethis fac-
tor should be reconsidered because: after the Young’s
reordering process, the old data not necessarily con-
tinues so. To obtain a more accurate and faster re-
sult, we propose using a fixed and low forgetting fac-
tor, here called as a filter factor, instead of using the
current CAPTAIN tootlbox (Taylor et al., 2007) as it
satisfies the continuous optimization of α for each it-
eration. The justification for this is probably that a
small set of reordered samples corresponds with to
the real samples. Then a small window past may be
more useful in the data reordering case than a con-
ventional optimized α. A practical advantage of this
is the flexibility for structural changes modeling, it is
336
Omar Jara Alegria E., Tanzarella Teixeira H. and Pascoli Bottura C..
Off-line State-dependent Parameter Models Identification using Simple Fixed Interval Smoothing.
DOI: 10.5220/0005573903360341
In Proceedings of the 12th International Conference on Informatics in Control, Automation and Robotics (ICINCO-2015), pages 336-341
ISBN: 978-989-758-122-9
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

important for a future On-Line version algorithm.
Two interesting cases of state-parameter depen-
dence estimation of ARX-SDP models are shown
also. The first one is when unitary regressors are con-
sidered and the other one is when the state and the pa-
rameter are correlated. Finally a example shows the
use of our proposed Off-Line state-parameter depen-
dence estimation algorithm using the INCA
1
(Alegria,
2015b).
2 SIMPLE FIXED INTERVAL
SMOOTHING ALGORITHM
For the autoregressive with exogenous input (ARX)
model:
y(k) = z
T
(k)ρ(k) + e(k); e(k) = N(0, σ
2
) (1)
where,
z
T
(k) =
h
−y(k − 1) −y(k −2) ··· −y(k − n)
u(k− δ) ··· u(k− δ − m)
i
ρ(k) =
h
ρ
1
(k) ρ
2
(k) ·· · ρ
n+m+1
(k)
i
T
the Simple Fixed Interval Smoothing (SFIS) algo-
rithm for TVP estimation could be used. The regres-
sion vector z(k) is composed of the scalar measure
y(k) and of the scalar exogenous input u(k). The TVP
are expressed as ρ
i
(k), i = 1, ..., n + m+ 1,. Also, δ is a
pure time delay on the input variable and e(k) is a zero
mean white noise.
The SFIS algorithm is a simple but useful recur-
sive estimation method and can be obtained by a sim-
ple combination of the recursive estimation with for-
ward data
ˆ
ρ
f
and backward data
ˆ
ρ
b
, i.e. with data
from sample k to N and from N to k respectively.
To allow the TVP in each one of these cases, an
Exponentially-Weighted-Past(EWP) with a fixed for-
getting factor α is used. In the case of conventional
FIS algorithm, an optimal value of α is obtained by
the hyper-parameters optimization (Jazwinski, 2007;
Young, 2011). For these reasons, in this paper we pro-
pose a SFIS instead of an optimal FIS algorithm. The
cost function using the exponential weighting factor
α is (Young, 2011):
J
EWP
=
k
∑
i=1
h
y(i) −z
T
(i)
ˆ
ρ
i
2
α, 0 < α < 1.0 (2)
1
Identificac¸˜ao N˜ao Linear para Controle Autom´atico
(INCA) toolbox we developed for our proposal for SDP es-
timation using SFIS algorithm
The SFIS algorithm for TVP estimation based on the
Recursive Least Squares (RLS) method is:
Forward estimation k = 1, 2, · ·· , N:
ˆ
ρ
f
(k) =
ˆ
ρ
f
(k− 1) + g(k)
n
y(k) −z
T
(k)
ˆ
ρ
f
(k− 1)
o
g(k) = P(k −1)z(k)
α+ z
T
(k)P(k −1)z(k)
−1
P(k) =
1
α
P(k −1) − g(k)z
T
(k)P(k −1)
Backward estimation k = N, N − 1, · ·· , 1:
ˆ
ρ
b
(k) =
ˆ
ρ
b
(k− 1) + g(k)
y(k) −z
T
(k)
ˆ
ρ
b
(k− 1)
g(k) = P(k −1)z(k)
α+ z
T
(k)P(k −1)z(k)
−1
P(k) =
1
α
P(k −1) − g(k)z
T
(k)P(k −1)
SFIS Estimation (Smoothing):
ˆ
ρ(k) =
ˆ
ρ
f
(k) +
ˆ
ρ
b
(k)
2
3 OFF-LINE IDENTIFICATION
An autoregressive with exogenous input and state de-
pendent parameters (ARX-SDP) model, shown below
in its simplest single input and singel output form, is
characterized by the dependence among the parame-
ter ρ
i
(k) and the state x
i
(k), k = 1, 2, ..., N, on the linear
regression model:
y(k) = z
T
(k)ρ{x(k)} + e(k); e(k) = N(0, σ
2
) (3)
where,
z
T
(k) =
h
−y(k − 1) −y(k −2) ·· · −y(k− n)
u(k− δ) ··· u(k− δ− m)
i
ρ{x(k)} =
h
ρ
1
{x
1
(k)} ρ
2
{x
2
(k)} ·· ·
ρ
n+m+1
{x
n+m+1
(k)}]
T
.
In this ARX-SDP model, the SDP ρ
i
is assumed to
be functions of only one state that could be one regres-
sion vector element or other variable that may affect
the relationship between these two primary variables,
ρ
i
(k) and x
i
(k), e.g. a regressors combination.
3.1 Recursive Off-line Identification of
ARX-SDP Model
Here we the modify Young’s SDP algorithm by using
a SFIS algorithm. The reason of using a SFIS instead
of an optimal FIS is because it allow the use of a fixed
Off-lineState-dependentParameterModelsIdentificationusingSimpleFixedIntervalSmoothing
337
forgetting factor α, as justified in section 3.2. From
equation (3), a first SFIS parameter estimation
ˆ
ρ
first
i
is computed. This does not show any state-parameter
dependence yet, but serves as a starting point to the
recursive algorithm:
ˆ
ρ
k
i
(k) =
ˆ
ρ
first
i
(k) (4)
To analyze the parameters ρ
i
of the ARX-SDP
model one by one, first the Modified Dependent Vari-
able y
mdv
i
is calculated as follows:
y
mdv
i
(k) = y(k) −
∑
j6=i
z
j
(k)
ˆ
ρ
k
j
(k) (5)
The signal y
mdv
i
is obtained from equation (5); then
the one-parameter model is:
y
mdv
i
(k) = z
i
(k) ρ
i
{x
i
(k)} . (6)
Because signals y
mdv
i
, z
i
, x
i
have high entropy, they
are reordered based on the ascendant value of the state
x
i
. The justification for this reordering process is de-
tailed in (Young et al., 2001) and an interesting obser-
vation is shown in the numerical example, see section
4. In this paper, the symbol (
∗
) is used to represent the
reordered data:
x
i
−→ x
∗
i
, y
mdv
−→ y
∗
mdv
, z
i
−→ z
∗
i
.
then, the reordered equation (6) is:
y
∗
mdv
i
(k) = z
∗
i
(k)ρ
∗
i
{x
i
(k)} (7)
where, the parameter ρ
∗
i
is smoothed by the depen-
dence with x
i
; the signal y
mdv
i
is lightly smoothed be-
cause it depends on ρ
∗
i
and also on the regressor z
i
.
The smoothing of the regressor z
i
is dependent on the
correlation among z
i
and x
i
. Experimentally, an un-
correlated selection of them is recommended.
From equation (7), a SFIS parameter estimation
ˆ
ρ
∗
i
is computed, it is reordered with respect to the normal
ordering of the state x
i
, i.e:
ˆ
ρ
∗
i
{x
i
(k)} −→
ˆ
ρ
i
{x
i
(k)} (8)
where,
ˆ
ρ
i
is a more exact estimation than
ˆ
ρ
first
i
and it
is able to show dependency with the state x
i
.
The steps shown from equations (4) to (8) describe
the iterative procedure for the parameter ρ
i
; this pro-
cedure should be used for the other parameters. No-
tice that only for the first iteration
ˆ
ρ
first
i
is used.
3.2 Forgetting Factor Considerations
The Young’s FIS estimation algorithm uses an Expo-
nential Windows Past (EWP) with a forgetting fac-
tor α to consider parametric changes (Young, 2011).
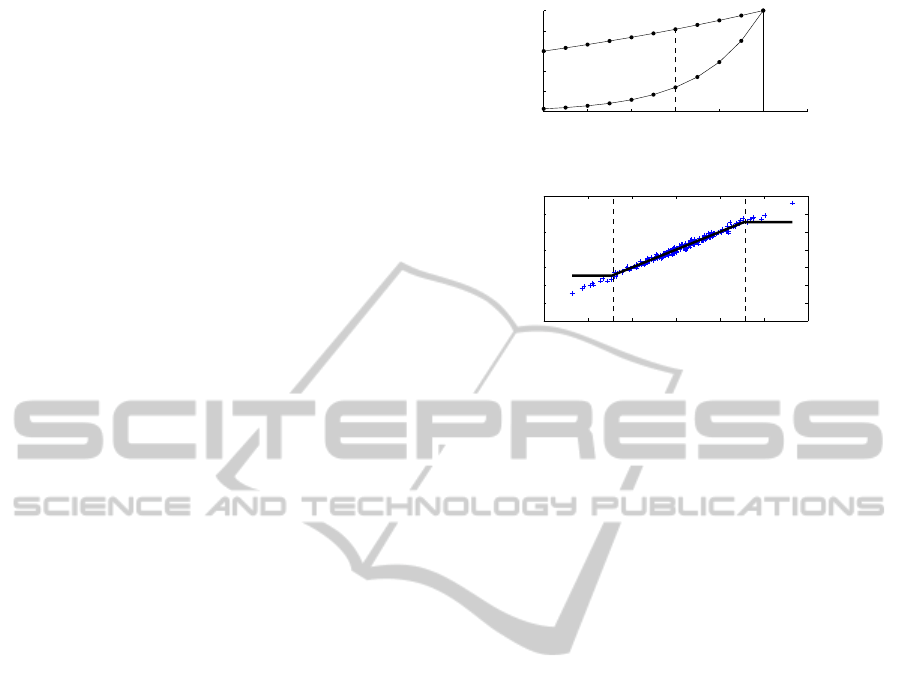
0 2 4 6 8 10 12
0
0.2
0.4
0.6
0.8
1
Number of samples
Weighting function
α = 0.7
α = 0.95
Figure 1: Weighting function for α = 0.95 and α = 0.7.
1 2 3 4 5 6 7
0
1
2
3
4
5
6
7
x(k)
ρ(k)
Low LowHigh
Figure 2: Example of a data density regions, and its SDP
estimation using the CAPTAIN toolbox.
The FIS algorithm uses a variable factor α(k), initially
smaller than α but approaches it asymptotically. In the
CAPTAIN toolbox (Taylor et al., 2007), this value is
optimized by maximum likelihood.
Here we propose an important consideration about
this forgetting factor α because the data affected by it
is reordered. This consideration is because the old
data not necessarily remain old after the reordering
process. Then, instead studying a method to choose a
forgetting factor α suitable to the reordering process,
this paper proposes to consider a small and constant
value of α.
A small value of α is proposed because after the
reordering transformation, only the nearby data prob-
ably corresponds to the unsorted data or at least to an
affine data. For example, when α = 0.7 the weight for
the fourth older data is much lower than weight when
α = 0.95, see Fig. 1. In this sense, the forgetting factor
here should be called a filter factor α.
We do not recommend a high value for the for-
getting factor α because it could disregard sampled
data with low density, e.g. the sampled data on the
extremes of a Gaussian distribution, because after de
reordering process, the low density data is averaged
with the high state density. The Fig. 2 shows a ex-
ample of data density distribution, divided by dashed
lines and labeled as low and high, and the typical
fault identification in the low data density region us-
ing Young’s algorithm and the CAPTAIN toolbox.
3.3 Unit Regressors Model
Considerations for SDP Estimation
This paper also considers the case of an ARX model
without regressors, i.e. z
i
(k) = 1, k = 1, 2, ..., N. In this
case the equation model (3) with unitary regressors
ICINCO2015-12thInternationalConferenceonInformaticsinControl,AutomationandRobotics
338

could be simply expressed as:
y(k) = ρ(k) + e(k) (9)
A practical advantage of considering unitary re-
gressors is that the shape of the state-parameter de-
pendency detection is better than when non-unitary
regressors are considered. For example, let us ana-
lyze the equation (5) with unitary regressors:
y
mdv
i
(k) = y(k) −
∑
j6=i
z
j
(k)
ˆ
ρ
k
j
(k) (10)
y
mdv
i
(k) = y(k) −
∑
j6=i
ˆ
ρ
k
j
(k) (11)
We can see that, for unitary regressors, y
mdv
i
is sim-
plified to the measured signal subtracted by the effects
of the other parameters ρ
j
, j 6= i. Then y
mdv
i
should be
very similar to ρ
i
.
Now, lets analyze the equation (6), see section 3.1;
for unitary regressors y
mdv
i
= ρ
i
{x
i
} and the mean value
E [y
mdv
i
] = E [ρ
i
{x
i
}]. Then, the respective estimated
parameter should have the same mean that y
mdv
i
and
it should be identical to the sum of the other parame-
ters. Then it is obvious that an offset is generated for
each parameter
ˆ
ρ
i
(k) = ρ
i
(k) + of fset
i
.
Nevertheless, the estimated model is consistent
with the input-output data, because when the es-
timated parameters are replaced on the regression
model, the sum of all parameters offsets are compen-
sated, i.e:
∑
n+m
i=1
of f set
i
≈ 0
4 NUMERIC EXAMPLE
Initially we treat the estimation process to detect three
state-parameter dependences in the model:
y(k) = ρ
1
{x
1
(k)} u
1
(k− 1)+ ρ
2
{x
2
(k)} u
2
(k− 1)
+ρ
3
{x
3
(k)} u
3
(k− 1)+ e(k) (12)
The dependences to be estimate are:
ρ
1
{x
1
(k)} = sin
π
2
x
1
(k− 1)
+ 2 (13)
ρ
2
{x
2
(k)} = x
2
2
(k− 1)+ 1 (14)
ρ
3
{x
3
(k)} = 0.8x
3
(k− 1)+ 3 (15)
where, the states x
i
;i = 1, 2, 3, are white noises; the in-
puts u
i
;i = 1, 2, 3, are white noises with displaced mean
to 2, −1 and 1 respectively and the measure noise
e(k);k = 1, 2, . .. , N;N = 1500, is white and zero mean.
The signal-noise ratio (SNR) is 33% and all signals
are uncorrelated.
Now, the detailed process from equations (5) to (8)
is implemented and, in order to understand how the
0 500 1000 1500
−20
0
20
Ordered data
y
mdv
1
k
0 500 1000 1500
−5
0
5
0 500 1000 1500
−20
0
20
Reordered data
k
0 500 1000 1500
−5
0
5
x
1
Figure 3: Temporally ordered data (left) an the effect of the
reordering process for y
mdv
1
.
reordering process is useful to detect state-parameter
dependence, the first iteration of the first parameter is
detailed. The modified dependent variable y
mdv
1
, cor-
responding to the first parameter ρ
1
is:
y
mdv
1
(k) = y(k)−ρ
2
{x
2
(k)} u
2
(k− 1)−ρ
3
{x
3
(k)} u
3
(k− 1)
(16)
The signal y
mdv
1
is the measure y without the ef-
fect provided by the parameters ρ
2
and ρ
3
, each one
multiplied by the regressors z
2
and z
3
, respectively.
The modified dependent variable in the reordered
space corresponding to the first transformed param-
eter y
mdv
1
→ y
∗
mdv
1
is:
y
∗
mdv
1
(k) = ρ
∗
1
(k){x
∗
1
(k)} u
∗
1
(k− 1) (17)
We can say that the relationship y
∗
mdv
1
has only the
first parameter effect. Then the relation among x
∗
1
and
y
∗
mdv
1
shows the shape of the dependence between x
1
and ρ
1
after of the reordering process. This effect is
shown in Fig. 3: The original sinusoidal shape of the
state-parameter dependence ρ
1
is evident after de re-
ordering of y
mdv
1
based on the ascendant value of the
state x
1
.
This process should be repeated for the other pa-
rameters ρ
2
and ρ
3
iteratively. Only for the first iter-
ation ρ
first
i
, i = 1, 2, 3, is used. A stopping criteria for
the algorithm should be a maximum iteration num-
ber or a minimal difference in two sequential estima-
tions of ρ
i
; in our tests 40 iterations were used for
each case to contrast our results. This example was
implemented in the INCA toolbox, for the cases of
filter factor α = 0.9 and α = 0.95. The state-parameter
dependence non-parametrically estimated is shown in
Fig. 4.
In order to contrast graphically our dependence
estimation, Fig. 5 shows the state-parameter depen-
dences estimation using the function
sdp.m
of CAP-
TAIN. Note the differences of figures 4 and 5 espe-
cially on the low data density regions. The Table 1
shows results of the state-parameter dependency for
the three unknown parameters using the INCA tool-
box, i.e with low and fixed α, and the CAPTAIN tool-
box, i.e. with optimized α.
Off-lineState-dependentParameterModelsIdentificationusingSimpleFixedIntervalSmoothing
339
−4 −2 0 2 4
0.5
1
1.5
2
2.5
3
3.5
x
1
ρ
1
−5 0 5
−2
0
2
4
6
8
10
12
14
x
2
ρ
2
−5 0 5
0
1
2
3
4
5
6
x
3
ρ
3
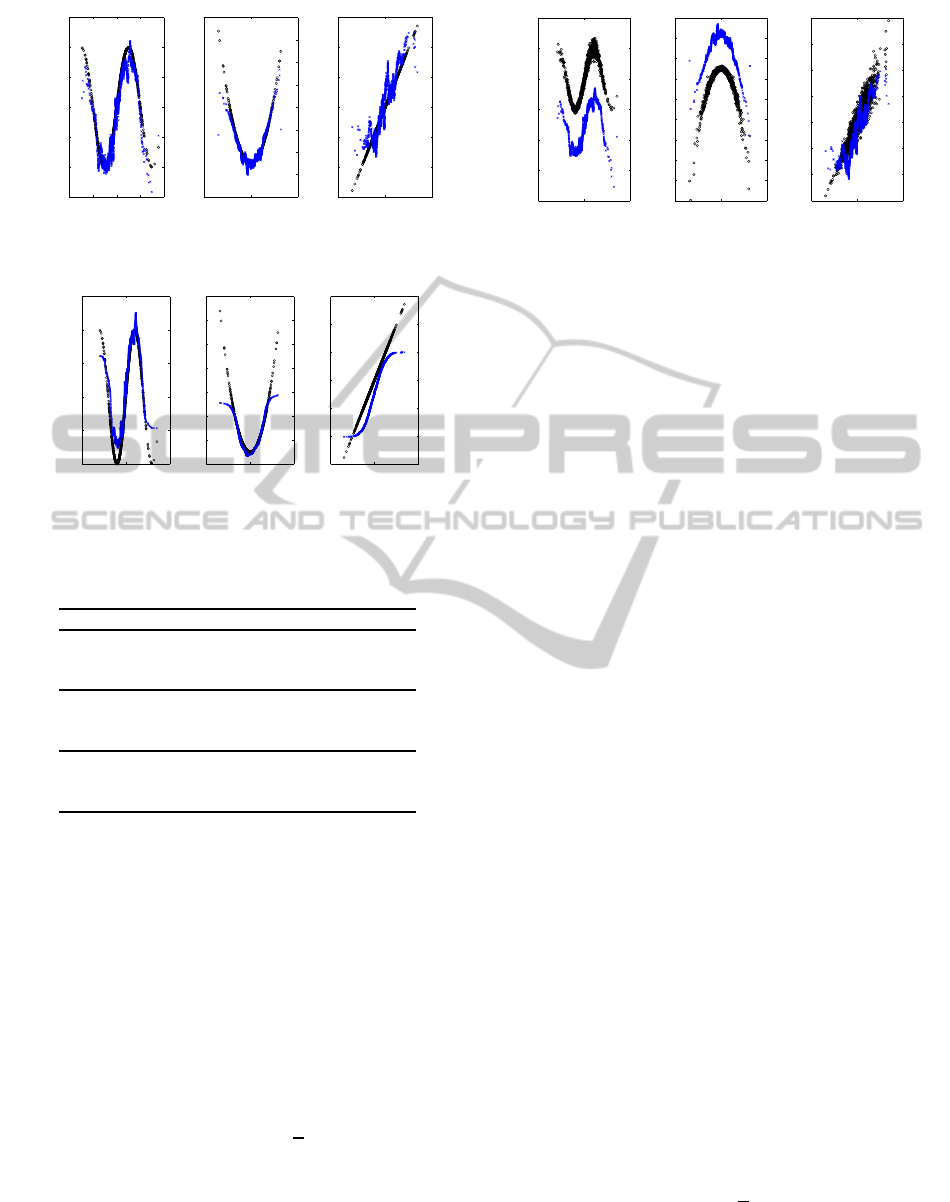
Figure 4: SDP estimation using the INCA for α = 0.95
(blue) and reference (black).
−5 0 5
1
1.5
2
2.5
3
3.5
x
1
ρ
1
−5 0 5
0
2
4
6
8
10
12
14
x
2
ρ
2
−5 0 5
0
1
2
3
4
5
6
x
3
ρ
3
Figure 5: SDP estimation using the CAPTAIN (blue) and
the reference (black).
Table 1: Estimation error of the state-parameter dependency
using the INCA and CAPTAIN toolboxes.
SDP Method α MAE(
ˆ
ρ
i
− ρ
i
) Time[s]
ˆ
ρ
1
INCA 0.90 0.4423 16
INCA 0.95 0.2917 15
CAPTAIN - 0.7564 31
ˆ
ρ
2
INCA 0.90 0.4267 16
INCA 0.95 0.3104 15
CAPTAIN - 0.2956 31
ˆ
ρ
3
INCA 0.90 0.2521 16
INCA 0.95 0.1665 15
CAPTAIN - 0.2847 31
4.1 Estimation of ARX-SDP Model with
Unitary Regressors
Now we consider the ARX-SDP model with unitary
regressors:
y(k) = ρ
1
{x
1
(k)} + ρ
2
{x
2
(k)}
+ρ
3
{x
3
(k)} + e(k) (18)
The dependences to be estimate are:
ρ
1
{x
1
(k)} = u
1
(k− 1)
sin
π
2
x
1
(k− 1)
+ 2
ρ
2
{x
2
(k)} = u
2
(k− 1)
x
2
2
(k− 1)+ 1
ρ
3
{x
3
(k)} = u
3
(k− 1)(0.8x
3
(k− 1)+ 3)
The modified dependent variable y
mdv
in this case is
simply:
−5 0 5
−4
−2
0
2
4
6
8
x
1
ρ
1
−5 0 5
−14
−12
−10
−8
−6
−4
−2
0
2
4
x
2
ρ
2
−5 0 5
0
1
2
3
4
5
6
7
x
3
ρ
3
Figure 6: SDP estimation using the INCA toolbox, when
model has unitary regressors (blue) and reference (black).
y
mdv
1
(k) = y(k) −
ˆ
ρ
2
(k) +
ˆ
ρ
3
(k) (19)
Notice that y
mdv
1
is exactly the measurement signal
without the other two parameters effect
ˆ
ρ
2
and
ˆ
ρ
3
.
Then the signal y
mdv
1
should have shape similarity
with the first parameter ρ
1
. In the previous case, we
can say that y
mdv
1
also have ρ
1
information but per-
turbed by the regressor effects z
i
, see equations (16)
and (17). The dependence estimation result of this
case is shown in Fig. 6.
We recommend to select a model with unitary re-
gressors when the state-regressor dependence shape is
more important than its exact value. e.g. in the case of
parametric fault detection it could be more important
to monitor the structure invariance of the model than
its exact parameter value.
4.2 Estimation of ARX-SDP Model with
Equal Regressors and States
Finally we consider ARX-SDP model with correlated
regressors and states, exactly z
i
= x
i
:
y(k) = ρ
1
{x
1
(k)} x
1
(k− 1)+ ρ
2
{x
2
(k)} x
2
(k− 1)
+ρ
3
{x
3
(k)} x
3
(k− 1)+ e(k) (20)
Notice that in equations (12) both signals are uncorre-
lated then the product of them keep, in some manner,
the shape of the unknownparameter. In (20) the shape
is completely affected because the parameter and the
regressor are correlated. Thus, ρ
i
{x
i
(k)} x
i
(k−1) has a
completely different shape from parameter ρ
i
{x
i
(k)}.
In the models 12 and 18 the parameters and states
were uncorrelated and their product shapes was con-
served. For this case the modified dependent variable
for the first parameter ρ
1
is:
y
mdv
1
(k) = ρ
1
{x
1
(k)} x
1
(k) (21)
= x
1
(k)sin
π
2
x
1
(k)
+ 2x
1
(k) (22)
and its sinusoidal form isn’t maintained, because
the regressor x
1
(k) is correlated with the parameter
ICINCO2015-12thInternationalConferenceonInformaticsinControl,AutomationandRobotics
340
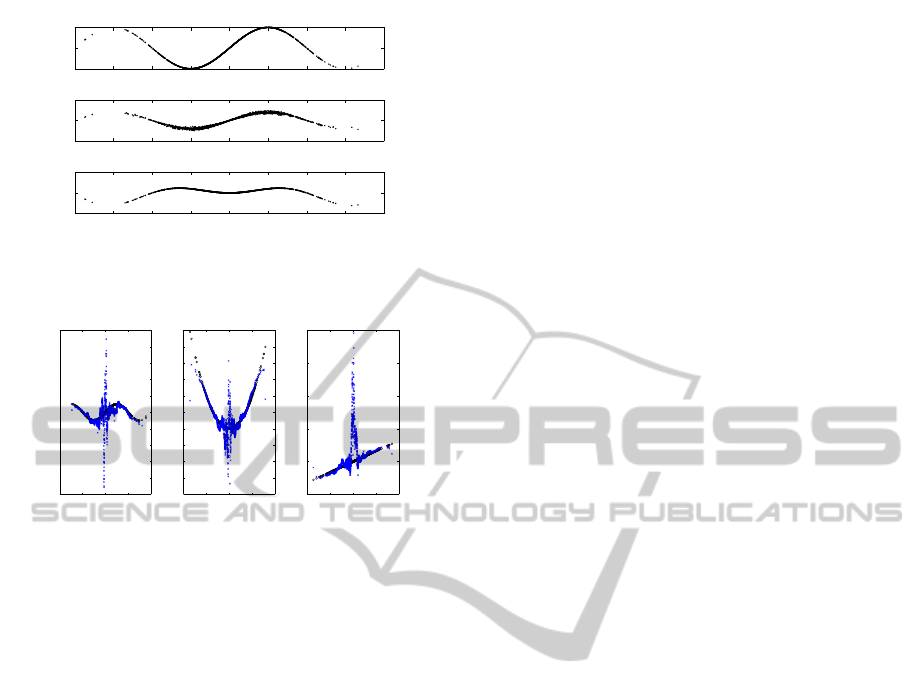
−4 −3 −2 −1 0 1 2 3 4
−1
0
1
original dependence
ρ
1
−4 −3 −2 −1 0 1 2 3 4
−5
0
5
uncorrelated product
ρ
1
u
1
−4 −3 −2 −1 0 1 2 3 4
−5
0
5
correlated product
ρ
1
x
1
x
1
Figure 7: Original state-parameter dependence (top) and re-
lation between state and regressor-parameter product, when
the factors are uncorrelated (middle) and correlated (below).
−4 −2 0 2 4
−10
−8
−6
−4
−2
0
2
4
6
8
10
x
1
ρ
1
−4 −2 0 2 4
−8
−6
−4
−2
0
2
4
6
8
10
12
x
2
ρ
2
−4 −2 0 2 4
−5
0
5
10
15
20
x
3
ρ
3
Figure 8: SDP estimation using the INCA toolbox, when
state and parameter are correlated.
ρ
1
{x
1
(k)}, see Fig. 7. Finally Fig. 8 shows the SDP
estimation for the three parameters when regressors
and parameters are correlated.
5 CONCLUSIONS
Inspired on Young’s algorithm, temporal data re-
ordering strategy to reduce the data entropy, the
state-parameter dependence estimation for ARX-SDP
model is studied in this paper. Firstly, we proposed a
fixed and relatively low value of the forgetting factor
α instead of considering its optimal value. It showed
a good estimation performance especially in the low
density regions. It is because after de reordering pro-
cess, the low density data is averaged with the high
state density.
In spite of our proposal do not result in smoother
state-parameter dependency as in CAPTAIN, this is
not disadvantageous, because it is still necessary a pa-
rameterization stage, e.g. by using support vector re-
gression (Alegria, 2015a). An important consequence
of our proposal, low and fixed forgetting factor, is the
flexibility to structural changes that our parameter-
state dependency algorithm presents. This is very im-
portant for a future On-Line version of SDP estima-
tion.
The three ARX-SDP estimation examples showed
the usefulness of our proposal and implementation for
the SFIS algorithm. For the first case the parame-
ter and regressor are uncorrelated, and the SDP es-
timation results were good. For the second case with
unitary regressors the SDP estimation results are also
very good but with offsets. For the third case when
the parameters and regressors are correlated the SDP
estimation is poor. It is interesting to observe that, for
the three parameters, the SDP estimation around the
zero state has greater errors. This is due to the very
low value of the regressor-parameter product that re-
duces the data richness.
ACKNOWLEDGEMENTS
We thank Brazilian agency CAPES for the financial
support.
REFERENCES
Alegria, E. J. (2015a). State-dependent parameter models
identification using data transformations and support
vector regression. In 12th International Conference
on Informatics in Control, Automation and Robotics
ICINCO.
Alegria, E. J. (2015b). State dependent parameters on-line
estimation for nonlinear regression models. Master’s
thesis, Universidade estadual de Campinas - UNI-
CAMP.
F. Previdi, M. L. (2003). Identification of a class of non-
linear parametrically varying models. International
Journal of Adaptive Control and Signal Processing,
17:33–50.
Hu, J., Kumamura, K., and Hirasawa, K. (2001). A quasi-
ARMAX approach to modeling of nonlinear systems.
International Journal of Control, 74:1754–1766.
Jazwinski, A. H. (2007). Stochastic Processes and Filtering
Theory. Dover publications.
Priestley, M. (1988). Non-linear and non-stationary time
series analysis. Academic Press, London.
Taylor, C., Pedregal, D., Young, P., and Tych, W. (2007).
Environmental time series analysis and forecasting
with the captain toolbox. Environmental Modelling
& Software, 22(6):797–814.
Yaakov Bar-Shalom, X. Rong Li, T. K. (2001). Estimation
with Applications to Tracking and Navigation. John
Wiley& Sons, Inc. cop., New York (N.Y.), Chichester,
Weinheim.
Young, P., McKenna, P., and Bruun, J. (2001). Identifica-
tion of non-linear stochastic systems by state depen-
dent parameter estimation. International Journal of
Control, 74(18):1837–1857.
Young, P. C. (2011). Recursive Estimation and Time-Series
Analysis. Springer-Verlag, 2 edition.
Off-lineState-dependentParameterModelsIdentificationusingSimpleFixedIntervalSmoothing
341
