Recommending Access Policies in Cross-domain Internet
Nuno Bettencourt
1
, Nuno Silva
1
and Jo
˜
ao Barroso
2
1
GECAD and Instituto Superior de Engenharia, Instituto Polit
´
ecnico do Porto, Porto, Portugal
2
INESC TEC and Universidade de Tr
´
as-os-Montes e Alto Douro, Vila Real, Portugal
Keywords:
Recommendation, Access Policy, Unknown-unknown.
Abstract:
As the amount of content and the number of users in social relationships is continually growing in the Inter-
net, resource sharing and access policy management is difficult, time-consuming and error-prone. In order to
aid users in the resource-sharing process, the adoption of an entity that recommends users with access poli-
cies for their resources is proposed, by the analysis of (i) resource content, (ii) user preferences, (iii) users’
social networks, (iv) semantic information, (v) user feedback about recommendation actions and (vi) prove-
nance/traceability information gathered from action sensors. A hybrid recommendation engine capable of
performing collaborative-filtering was adopted and enhanced to use semantic information. Such recommenda-
tion engine translates user and resources’ semantic information and aggregates those with other content, using
a collaborative filtering technique. Recommendation of access policies over resources promotes the discov-
ery of known-unknown and unknown-unknown resources to other users that could not even know about the
existence of such resources. Evaluation to such recommender system is performed.
1 INTRODUCTION
The Internet has recently grown to over three bil-
lion users. On certain social networks, more than
two hundred thousand photographs are uploaded ev-
ery minute. Such rate of content generation and social
network building make the task of sharing resources
more difficult for users.
Standard resource sharing in the Internet is
achieved by granting users with access to resources,
but they are commonly restricted to resources hosted
on a single domain. Access policies are consequently
issued to users registered on the same domain. Shar-
ing resources with users that are not registered on
the same domain has proven insecure or difficult to
achieve. Referencing and accessing resources pro-
tected by access policies in other web domains (apart
from where they are hosted) is practically unsup-
ported by existing web applications.
In cross-domain sharing, such difficulties encour-
age:
• the cloning of the resource to different domains;
• the multiplication of users’ internal and social
identity.
The goal of this work is to provide a seamless
cross-web-domain infrastructure that provides secure,
rich and supportive resource managing and sharing
processes. It proposes a distributed and decentralised
architectural model by fostering cross-web-domain
resource sharing, resource dereferencing and access
policy management. It adopts the principles of the
Web and of World Wide Web Consortium (W3C)
standards or recommendations.
In order to support user management of access
policies, a recommendation provider capable of rec-
ommending access policies to users is included in the
architecture (section 2). The proposed recommen-
dation engine features a hybrid engine consisting on
the combination of different filtering techniques that
exploit user profiles, their social networks, resources
content, (distributed) provenance and traceability in-
formation (section 3).
A prototype to demonstrate the infrastructure’s
feasibility was designed and implemented to prove
that the architecture model can be deployed in a real
world scenario. The hybrid recommendation process
was tested using an available data set where informa-
tion was interpreted to simulate human behaviour in
the system (section 4 and 5).
Finally, the last section gives an overview of the
proposed solution and suggests further research.
50
Bettencourt, N., Silva, N. and Barroso, J..
Recommending Access Policies in Cross-domain Internet.
In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2015) - Volume 3: KMIS, pages 50-61
ISBN: 978-989-758-158-8
Copyright
c
2015 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
2 BACKGROUND KNOWLEDGE
This work allows the recommendation of access poli-
cies to resource authors. This section provides an in-
sight about recommendation processes, resources that
are currently not easily shared because of access pol-
icy restrictions and Authentication, Authorisation and
Accountability (AAA) architectures.
2.1 Recommendation
Recommendation is something that has become part
of everyone’s daily lives. To reduce uncertainty and
help coping with information overload when trying
to choose among various alternatives, people usually
rely on suggestions given by others, which can be
given directly by recommendation texts, opinions of
reviewers, books, newspapers, etc. (Shardanand and
Maes, 1995).
Users are willing to follow others’ recommenda-
tions and to give back recommendations to the com-
munity.
When deciding between which product to buy,
users want to be able to read opinions from other buy-
ers (MacKinnon, 2012) and tend to follow them as
they are considered experienced users (Wasserman,
2012).
Currently, recommendation is widely used in elec-
tronic commerce (Adomavicius and Alexander, 2011;
Linden et al., 2003; Schafer et al., 2001). In e-
commerce web applications, trust is based on the
feedback of previous online interactions between
members as shown by the authors in (Resnick et al.,
2000; Ruohomaa et al., 2007).
In the Internet perspective, there are other areas
in which recommendation is also relevant, such as re-
source recommendations on websites (e.g. Pinterest),
documents (e.g. Slideshare, Pocket) and users (e.g.
LinkedIn, Facebook, Google+).
With the Internet’s continual evolution, recom-
mender systems have also evolved. While initially
recommendation was only used in e-commerce web-
sites for recommending similar or most bought items
to users, nowadays the process of recommendation
has improved such that the recommendation of friend-
ship and/or relationship between users of a social net-
work has become a quite common task on typical so-
cial web applications.
Every recommender system is typically based on
two elements:
User/Item Actions. Represents user actions upon
items and may include a possible rating.
Item Similarities. Represents the associations be-
tween users or between items. Some recom-
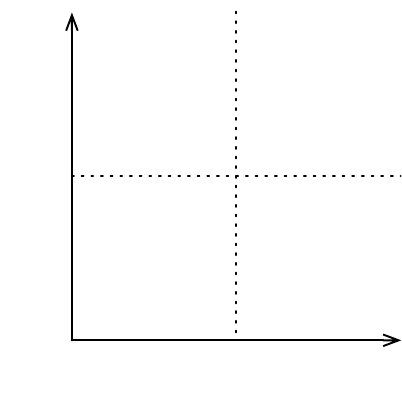
Low High
Low
High
Knowledge Awareness
Location Awarenes
Known
Known
Unknown
Known
Unknown
Unknown
Known
Unknown
Figure 1: Location Awareness vs. Knowledge Awareness.
mender systems provide algorithms to calculate
item similarity during the recommendation pro-
cess, while others even allow the usage of external
pre-computed item similarities during the process.
The output of a recommender system is a scored
list of recommended items that are recommended to
a list of users. The maximum number of retrieved
recommendations is specified by the value of AT.
A systematisation of the user’s consciousness
about resources is presented next, which will be help-
ful to perceive the importance of the recommendation
process in the scope of this work.
2.2 Known-known, Unknown-unknown
A user’s consciousness about something can be char-
acterised according to two dimensions: perception of
reality and reality of perception.
Applying such rationale to resources’ location and
users’ knowledge awareness of those, a particular re-
source can be classified as (cf. Figure 1):
Known-knowns. These are resources whose exis-
tence and location are known by the user e.g. a
photograph is taken of a person, and the person
knows about its existence and its location.
Known-unknowns. These are resources a user
recognises he/she knows nothing about until
he/she finds them e.g. a person finds a photo by
chance on which he/she appears, knows its loca-
tion but was not aware of its existence.
Unknown-knowns. These are resources that the user
does not know how to find, but knows about their
existence, e.g. a photo is taken of a person, the
person knows about its existence but does not
Recommending Access Policies in Cross-domain Internet
51
know about its location. With time and searching
investment the person might get to its location.
Unknown-unknowns. These are resources whose
existence the user is not even aware of e.g. a photo
is taken of a person but the person does not know
its existence or where to locate it. These type of
resources would only come up on searches related
to the user if contextual information is used.
This classification emphasises the fact that the
same existing information is perceived differently by
users. There are different reasons for these different
perceptions, including (i) access policy restrictions
and (ii) information overload. Recommender systems
are conceptually fit to help users perceive resources as
(useful) known-knowns.
Access policy restrictions prevent users to access
resources that would be of their interest. The recom-
mender system mediates between the owner (that has
the resource and can grant access to it) and the ben-
eficiary (that is interested in the resource). Recom-
mender systems will:
• recommend the owner with access policies to
grant access permissions to another user upon the
resource;
• recommend the beneficiary to request access per-
missions for a certain resource that is not acces-
sible and that is a known-unknown, unknown-
known or unknown-unknown to the reader.
Information Overload “occurs when the amount
of input to a system exceeds its processing capacity”
(Speier et al., 1999). In this context, information over-
load occurs because the owner is not able to match the
large number of his/her protected resources with the
potentially large number of interested readers. In that
sense, recommender systems will:
• recommends the owner with suggestions of poten-
tially interested users that are not able to access
the resources;
• recommends the beneficiary, which is overloaded
by the quantity of users that he/she would
have to contact to request access to known-
unknown, unknown-known or unknown-unknown
resources.
2.3 Conceptual Architecture
Based on the nomenclature and responsibilities pro-
posed by the Internet Engineering Task Force’s refer-
ence architecture for AAA in the Internet (Vollbrecht
et al., 2000), this section describes the architecture
for a system capable of accomplishing the envisaged
goal.
When included as part of a multi-domain decen-
tralised AAA system, the conceptual architecture sets
the stage for defining protocol requirements between
engaged systems.
Commonly accepted names for the various entities
involved in the architecture are:
• Policy Enforcement Point (PEP) (Parducci and
Lockhart, 2013; Vollbrecht et al., 2000; Wester-
inen and Schnizlein, 2001; Yavatkar et al., 2000);
• Policy Decision Point (PDP) (Parducci and Lock-
hart, 2013; Vollbrecht et al., 2000; Westerinen and
Schnizlein, 2001; Yavatkar et al., 2000);
• Policy Information Point (PIP) (Parducci and
Lockhart, 2013; Vollbrecht et al., 2000);
• Policy Retrieval Point (PRP) (Nair, 2013; Voll-
brecht et al., 2000);
• Policy Administration Point (PAP) (Convery,
2007; Parducci and Lockhart, 2013; Stephen
et al., 2008).
Other existing architectures use the concept of an
IDentity Provider (IdP) that provide features for cre-
ating and maintaining users identity.
The decentralised structure is capable of provid-
ing authentication, authorisation, access control man-
agement and recommendation based on resources,
users, provenance and traceability information in a
distributed and decentralised system, by promoting
the usage of action sensors, metadata generators and
semantic rules (cf. Figure 2). This architecture is
novel in respect to the following aspects:
• despite most of the components maintaining the
same names as in typical architectures, their re-
sponsibilities and features are enhanced to address
the defined requirements;
• adds a recommendation component that is respon-
sible for the recommendation of access policies;
• boosts these components by replacing legacy and
traditional non-standard formats and procedures
with new data representation by using semantic
web standards, capable of a better and explicit
knowledge and information description.
In particular, managed and exploited information
is a cornerstone of this work:
• resource, i.e. anything in the world that can be re-
ferred, either physical or virtual, that is identified;
• user, a special kind of resource representing a hu-
man or artificial agent in the system.
The conceptual architecture uses components that
have been previously addressed by the authors in
KMIS 2015 - 7th International Conference on Knowledge Management and Information Sharing
52
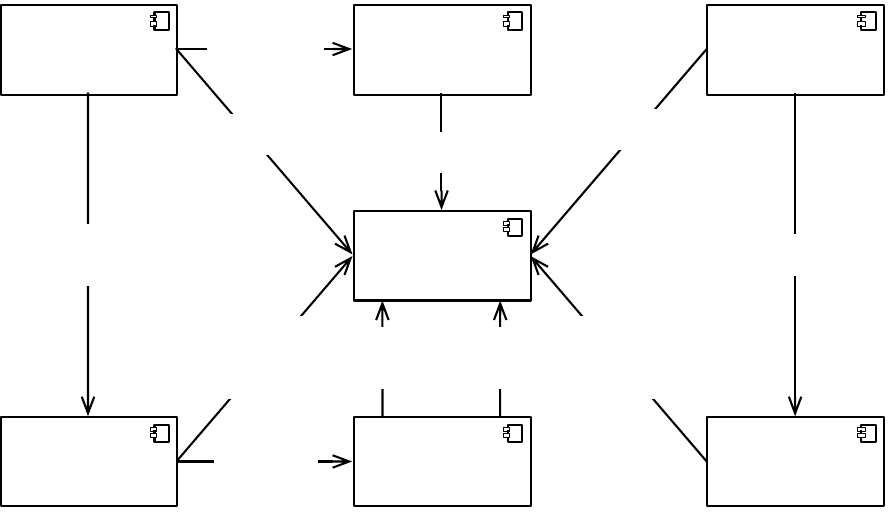
Web Domain
Request:
Authentication;
Authorisation
Get
Resource
Get: User; Resource
Store: Provenance;
Traceability;
Content
Get
Extra
Information
Get
Access
Policies
Get
Recommendations
Get:
Users; Resources;
Traceability;
Provenance
Retrieve/Store:
Access Policies
Evaluate
Authorisation
Request
Request
Authentication
(Relying Party)
Get/Set: User Profile
Get Extra Information
Identification
Provider
Point
Policy
Administration
Point
Policy
Recommendation
Point
Policy
Enforcement
Point
Policy
Decision
Point
Policy
Information
Point
Figure 2: Conceptual Architecture.
(Bettencourt and Silva, 2010) and proposes the adop-
tion of a new component which is the focus of the
work being presented. Each component has specific
responsibilities and features (cf. Figure 2).
In (Nimmons, 2012) the author suggests a typi-
cal operation pattern for providing resource authori-
sation. In this operation pattern, the PEP is responsi-
ble for intercepting access requests sent from the user
to perform some type of action upon a resource. The
PEP, on behalf of the user, requests authorisation for
accessing the resource. This request is forward to the
PDP, which is the entity that has the engine for evalu-
ating access policies. It uses the information provided
by the PEP and the specified access policies to deter-
mine if the user should be allowed or denied access to
the resource.
The PDP uses the PRP and PIP to retrieve poli-
cies and attributes referenced in the policies. When
the PDP finishes the evaluation of access policies,
it returns an answer to the PEP stating whether ac-
cess has been granted or denied to the user. If access
is granted, the resource is retrieved from the hosting
server. The PAP is the system entity used for manag-
ing the access policies. For that it uses the features of
PRP to retrieve existing policies and store changes to
those. Some of the component features are described
next.
2.3.1 Identification Provider Point
Provides users with a new identity and appropriate
credentials. The following features are enhanced or
added:
• allows identity generation and credentials creation
to new users;
• allows managing each user’s internal and social
identity in the virtual world;
• provides an authentication relying party service
that allows legacy domains that do not pro-
vide Friend-Of-A-Friend + Secure Sockets Layer
(FOAF+SSL) authentication to validate users cre-
dentials.
2.3.2 Policy Enforcement Point
Enforces user’s authentication and guarantees con-
trolled and authorised access to resources. The fol-
lowing features are enhanced or added:
• typical basic authentication methods are replaced
by FOAF+SSL cross-domain authentication;
• enforcement is no longer achieved by using local
access policies, but instead it is replaced by a dis-
tributed and decentralised method;
• action sensors capture User-Generated Content
(UGC) and actions.
Recommending Access Policies in Cross-domain Internet
53
2.3.3 Policy Decision Point
Evaluates access policies in order to decide if a user
should or not be granted access to a resource. The
following features are added or changed:
• replaces traditional role or attribute based autho-
risation mechanisms by an authorisation mecha-
nisms capable of handling semantic, declarative
and expressive access policy languages;
• provides decentralised access policy evaluation
that is used in a cross-domain perspective;
• obtains, if necessary, semantic information from
the PIP for evaluating a particular policy;
• offers reasoning capabilities over more expressive
access policy rules that exploit the system’s se-
mantics.
2.3.4 Policy Information Point
Manages the information needed for the authentica-
tion, authorisation and recommendation processes.
The following features are added or enhanced:
• information management of:
– resources’ content, including their type, at-
tributes/properties and preferred hosting do-
main;
– provenance and traceability information over
UGC and content;
• generating and publishing information according
to an explicit and public semantic specification
(i.e. ontology).
2.3.5 Policy Administration Point
Enables users to manage access policies over exist-
ing resources. The following features are added or
enhanced:
• access policies are specified by rules instead of di-
rectly assigning users to resources or placing users
in particular roles;
• proprietary access policies over resources im-
posed by closed domains are replaced by far more
flexible and expressive rules that capture the ra-
tionale behind a particular access policy beyond
current approaches;
• provides and promotes the means to create access
policies based not only on user attributes and re-
lationships, but also on resource attributes;
• provides and promotes the means to define more
complex access policies through semantic rea-
soning over contextual information and meta-
information.
2.3.6 Policy Recommendation Point
This component is a novelty in AAA systems. It rec-
ommends access policies that are applied to users and
resources. These are some of the envisaged responsi-
bilities and features:
• recommend access policies by combining col-
laborative, social content and semantic fil-
tering methods, allowing the recommendation
of known-unknown and unknown-unknown re-
sources to users;
• allow customising the recommendation process,
namely the weights for each filtering method.
This component proposal is addressed in the next
section.
3 PROPOSAL
The Policy Recommendation Point recommends
known-unknown and unknown-unknown resources to
users in a cross-domain perspective, by exploring the
information gathered by the system, namely user pro-
files, social network relationships, provenance and
traceability information.
Having an access policy definition based on sim-
ilarities between resources, users or domain knowl-
edge, is being half-way to enabling an automatic rec-
ommendation system based on information such as
FOAF profiles, interest topics and contexts to provide
the sharing of resources.
Traditionally, the responsibility of sharing re-
sources always comes down to the resource’s author,
based on his/hers restricted perception/knowledge of
the whole network of users and resources. Resource
access policy recommendation is a process that is in-
troduced to widen that vision by which a system noti-
fies the resource author when other users would prob-
ably benefit or rejoice from having access to a partic-
ular resource.
The access policy recommendation process aids
resource authors in granting or denying access to exis-
tent resources by making use of similarity factors be-
tween resources and social relationships, suggesting
which users should be given access to each resource.
It also eases resource authors’ task of sharing re-
sources by finding similar access policies that could
be reapplied to similar resources. It is envisaged that
recommendation can aid users in the access policy
management process regarding their resources, and
give other users access to resources that would not
have previously been accessible to them.
KMIS 2015 - 7th International Conference on Knowledge Management and Information Sharing
54
This is achieved by enriching and enhancing the
access policy recommendation process with existing
users’ and resources’ meta-information, and creating
a hybrid recommendation method capable of under-
standing not only the concepts of users and resources
but also provenance and traceability annotations gath-
ered from user actions.
A resource context is produced by the analysis of
each resource’s content and meta-information, while
a relationship context is created based on the exist-
ing relationship depth between users (Wasserman and
Faust, 1994), each user’s profile, linked resources and
consequent relationships.
One of the outcomes of this proposal is the cre-
ation of semantic rules that match similarities be-
tween contexts (Ghita et al., 2005). Therefore, for
every resource or relationship, a context is generated
and multiple contexts may exist for the same resource.
This PRP is responsible for:
• the implementation of a hybrid recommendation
engine;
• guiding users through the resource-sharing pro-
cess by suggesting access policies for their re-
sources:
– by evaluating feedback actions regarding the
acceptance or rejection of recommended re-
source sharing;
– avoiding rejected recommendations from being
recommended again;
• recommending known-unknown and unknown-
unknown resources.
3.1 Hybrid Recommendation Engine
When an application responsible for ensuring access
control is aware of all users’ resources and social rela-
tionships, such application is capable of recommend-
ing resources to new users that have recently became
part of the resource author’s social network.
This already happens on typically closed applica-
tions (e.g. Slideshare, Research Gate, etc.) but is still
not being used in a cross-domain perspective for all
user resources. Contrary to such closed environments,
this proposal consists on performing such task in a
cross-domain perspective.
The recommendation is enhanced with semantic
information for cross-domain web applications rely-
ing on an open and distributed social network based
on FOAF profiles, provenance and traceability infor-
mation.
Users’ public resources are used in the recommen-
dation process to enable associations between users,
between resources or between users and resources.
Despite already being publicly accessible, recommen-
dation of publicly accessible resources is performed
because other users that do not know of their exis-
tence can eventually have interest in them.
The proposed recommendation process consists of
a hybrid approach accomplished by the combination
of users’ profiles, resources’ meta-information, trace-
ability and provenance annotations, social network
analysis and domain knowledge.
The semantic filtering relates to problems as rec-
ommending known-unknown and unknown-unknown
resources that users had little or even no knowledge
about. The recommendation service is built on top of
these three filtering methods that are capable of deal-
ing with different sets of information.
The following methods are therefore suggested for
the PRP:
Content-based Filtering Method. Recommends
existing resources by comparing resource at-
tributes, content and meta-information to the
user’s profile attributes and topic preferences in
order to verify the resource’s relevancy to the
user. This relevancy is given by the similarity
between resource attributes and the user’s topic
preferences. The content-based filtering method
is enriched mainly by exploiting resources’
content, resources’ generated meta-information
and users’ interest topic preferences.
Collaborative Filtering Method. It recommends re-
sources based on the following pairs of con-
nections: (users, users), (resources, resources)
and (users, resources). This process is content-
agnostic, meaning that it only recommends re-
sources based such these collaboration patterns,
where similarities between users linked to re-
sources are used to infer other new possible con-
nections between users and resources. The col-
laborative filtering method uses information that
associates users’ actions to resources.
Context Filtering Method. Recommends resources
that match the proposed user’s topic preferences
or semantically related topics. This filtering
method expands the capabilities of the content-
based filtering method by introducing reasoning
over knowledge concepts. When the user con-
text and resource context match, the recommender
system recommends that resource to the user. In-
terest topics are semantically described, providing
not only hierarchical relations between topics but
also a graph of other connections between seman-
tic information. Contexts are obtained through the
usage of ontologies and semantic rules that pro-
vide grounding to this filtering method. The fil-
tering method is enriched by semantic informa-
Recommending Access Policies in Cross-domain Internet
55
tion derived from multiple domains, that include
users’ FOAF profiles, topic interests, social net-
work graphs, resources’ meta-information, prove-
nance and traceability annotations.
While the recommendation process runs continu-
ally, it is triggered by several changes in the system,
namely:
User-generated Content. When users create, edit or
change an existing resource, resource content is
analysed by specific meta-information generators
that generate semantic information. The recom-
mendation process is triggered because changes
in content might affect the result of the content-
filtering (i.e. new content can be added or re-
moved), collaborative-filtering (i.e. changing or
adding a resource increases the number of times
the resource has been accessed) and context-
filtering (i.e. changing content may derive new
context information) methods.
User-generated Actions. When users perform ac-
tions over resources, they are implicitly building
their profile. When their profile changes, it is nec-
essary to trigger a recommendation process be-
cause a change in a user profile might suggest ac-
cess to other resources as it influences the collab-
orative and context-filtering method. Notice that
revoking access permission might also be sug-
gested if the resource is evolved through time and
its applicability is over. In case the resource does
not change and if it has been shared before, it
makes no sense in revoking access rights because
the resource might have been duplicated by others
elsewhere.
Access Policy Modification. When users create,
change or remove access policies, the recom-
mendation process is triggered because other
users may now have access to resources that they
did not have before, which also influences the
collaborative-filtering method.
Social Network Changes. Whenever a user be-
comes part of or is removed from another user’s
social network. In fact, this process is quite simi-
lar to the addition of new resources because a new
user is actually a special case of a new resource
that is identified by a corresponding Uniform Re-
source Identifier (URI). As a result, the user’s con-
text might change, which would trigger the rec-
ommendation process. The inclusion of a new re-
lationship might change a user’s context, which
has an impact on the resources the user may have
access to.
3.2 Notifications & Feedback
When the recommendation process succeeds in rec-
ommending access to resources, the resource author
is notified with a message containing:
• the resource to be shared;
• the user to whom the resource is being shared;
• an explanation of why the resource is being rec-
ommended.
When a resource sharing is recommended, the
system checks with the resource’s author if he wishes
to assign the access privilege to the proposed user. If
the author wants to assign the privilege to the pro-
posed user, the PRP takes the necessary actions to
notify the proposed user. When authors accept re-
source sharing recommendations, these are translated
into access policies over resources.
The author may receive recommendation notifica-
tions of access policies granting access to users that
may not be part of his/hers social network. When
sharing is recommended to users outside the author’s
social network, the inclusion of that user in the au-
thor’s social network must be achieved prior to the
sharing act, otherwise sharing is not permitted. To this
end, the inclusion of a new relationship is proposed.
If accepted, the author’s FOAF profile is changed ac-
cordingly.
The proposed user who should be given access to
the resource also receives a notification message stat-
ing:
• that a resource exists that might be suitable for the
user;
• an explanation of why the resource is being rec-
ommended.
Each user receives a list of resources that were
shared with him/her, and a request to express whether
or not that resource is relevant to him/her, thus provid-
ing feedback to the recommender system. This feed-
back is captured in the form of traceability informa-
tion and will be used as supporting information.
3.3 Known-unknown and
Unknown-unknown Resources
In order for a system to be able to recommend the
sharing of known-unknown and unknown-unknown
resources, it must be possible to establish associa-
tions between resources, between users and between
users and resources that are not possible to establish
by means of content or collaborative analysis.
The semantic-filtering method uses ontologies to
map existing information and allow the inference of
KMIS 2015 - 7th International Conference on Knowledge Management and Information Sharing
56
new knowledge by providing associations between re-
sources that would not have been associated before.
Consider that resources (e.g. photos) have been
annotated for having recognised but not identified a
person that may or not be part of the resource au-
thor’s social network. This unidentified person rep-
resents any possible user that may be interested in
that resource, not because of any relationships with
the user but because that person was at the same time
and place where some photos were taken and could
eventually appear in one or more. It is possible to
narrow down the possibilities of people that could
be passers-by at that location and time if the recog-
nised but unidentified person is in the same context
on which the photos were taken, and as a result rec-
ommend the resource sharing to that unidentified user,
by using the following information:
• user profile;
• user contextual information:
– users’ geo-referenced position;
– users’ geo-referenced position’s time;
• resource creation time and location;
• provenance and traceability information from user
actions:
– event records of their physical performance
while practicing sports.
When the system discovers which unidentified
users were at the same time and place, by comparing
their location at a given time with the resource time
and location, the resource’s author is notified in order
to share those resources with those particular users.
This type of recommendation can only be derived
if different resources’ contexts are matched. In this
situation, time and location create the context for the
presented resources. Nevertheless, this is just an ex-
ample of a possible context. The conditions for speci-
fying contexts can be fully captured by ontologies and
semantic rules, thus being easily extended and reused
by multiple recommendation system.
4 EXPERIMENTS
The aim of the experiments was to prove that even
with a large dataset of information, semantic infor-
mation would improve existing algorithms. For that,
a larger set of information and a recommender system
are required.
The recommender engine should feature a hybrid
mechanism that makes use of collaborative, content
and semantic filtering techniques. Yet, these fea-
tures are not natively supported by mainstream rec-
ommender systems.
Mahout recommender engine is a framework that
provides advanced expansion features and makes use
of collaborative filtering but it does not provide con-
tent or semantic filtering techniques, as these must use
domain-specific approaches (Owen et al., 2011).
In order to provide this support with content and
semantic filtering techniques, Mahout’s recommenda-
tion process was modified to enable the aggregation
of similarities between items and between users, to-
gether with Mahout’s similarities generation.
Conducting the evaluation in a real world would
be time-consuming and would hence face cold-start
problems typically associated with collaborative fil-
tering techniques. For these reasons, it was decided
that the system should be evaluated according to an
existing dataset.
Several datasets used on the Second International
Workshop on Information Heterogeneity and Fusion
in Recommender Systems (Hetrec’2011), were anal-
ysed in order to prove their appropriateness to the de-
sired evaluation.
After a careful inspection of the content of the
LastFM dataset it was clear that it would provide
more useful information than the one in the Delicious
Dataset or MovieLens, thus promoting the content
and semantic filtering. For this reason, LastFM was
the chosen dataset for the experiments as it suits the
evaluation needs, considering a carefully planned in-
terpretation and mapping to the ontology used in the
system. The LastFM dataset is further enhanced with
data from the Freebase and Music Brainz datasets.
Due to the lack of integration and explicit seman-
tics of the source datasets, it is necessary to derive
and integrate the implicit semantics from the existing
datasets into a domain ontology. The mapping stage
is responsible for converting the source datasets into
a domain ontology. This mapping process is depicted
in Figure 3. The dotted lines represent mappings from
the source datasets to the domain ontology.
Each lastfm:User individual/instance gives origin
to a domain:User individual. Listen and Tag actions
are combined into the general domain’s Action be-
cause Mahout recommender system does not distin-
guish between different types of user actions. Each
LastFM Musical Artist individually originates a do-
main’s Musical Artist.
The original lastfm:Tag individuals are interpreted
as domain Musical Genres’ individuals. This is the re-
sult of users’ manual tagging of each Musical Artist.
Yet, while these users’ actions complement the Musi-
cal Artists with associations to Musical Genres, the
Recommending Access Policies in Cross-domain Internet
57
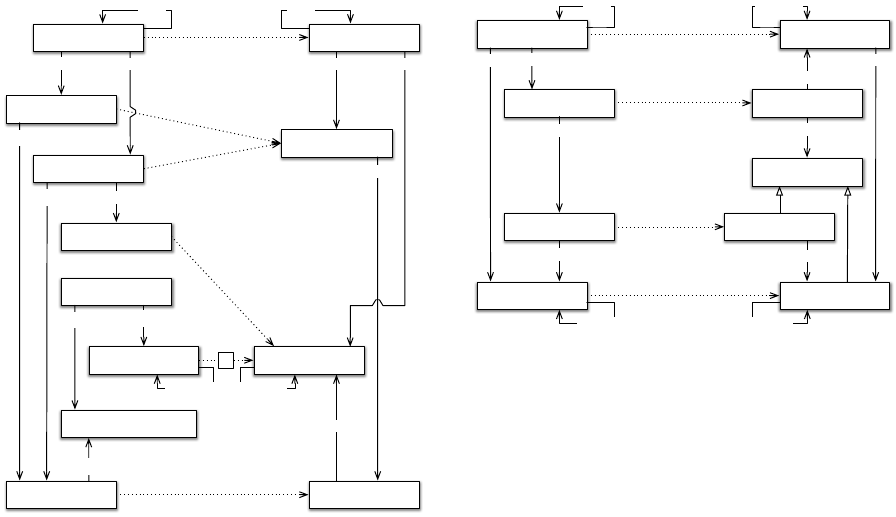
knows
lastfm:TagAction
lastfm:MusicalArtist
domain:MusicalGenre
over
domain:MusicalArtist
lastfm:ListenAction
knows
lastfm:Tag
over
over
domain:Action
freebase:MusicalArtist
freebase:MusicalGenre
hasSubGenre
over
hasSubGenre
musicbrainz:MusicalArtist
sameAs
has
hasMusicalGenre
a)
sameAs
performs
performs
likes
performs
lastfm:User domain:User
Figure 3: Source Datasets to Domain Ontology Mapping.
original LastFM dataset does not provide informa-
tion about each Musical Artist and their related Mu-
sical Genres. In order to simulate the generation
of semantic information, when UGC is captured, an
enrichment process is performed for providing an
association between domain:MusicalArtist and do-
main:MusicalGenre.
Domain’s Musical Genre individuals are obtained
by the union of any Freebase Musical Genre:
• whose description matches LastFM’s Tag’s value
by using a reconcile process. In the end of this
process, 4698 of the initial 11946 tags were cor-
rectly reconciled to their semantic equivalent do-
main Musical Genre;
• that are tagged against the Musical Artist. Free-
base’s and LastFM’s Musical Artist are not di-
rectly associated. Nevertheless, when a Music
Brainz Musical Artist is the same for both Free-
base and LastFM, one may conclude they are the
same.
A transitive property “hasSubGenre” is added to
the domain ontology to relate sub-genres. This “has-
SubGenre” relation provides the necessary informa-
tion for semantic filtering recommendation.
The process of generating the recommendation’s
dataset consists in obtaining the following sets of in-
formation from the system’s ontology, to comply with
the recommendation model presented in Figure 3.
The specific domain ontology is translated to a
domain:MusicalGenre
domain:MusicalArtist
domain:User
knows
domain:Action
performs
over
likes
hasSubGenre
hasMusicalGenre
foaf:Person
foaf:knows
provo:Activity
prv:DataItem
over
performedBy
domain:MusicalGenre
domain:MusicalArtist
hasMusicalGenre
hasSubGenre
likes
Figure 4: Domain Ontology to System Ontology Mapping.
generic ontology that is used by the system. The map-
ping between both ontologies is depicted in Figure 4.
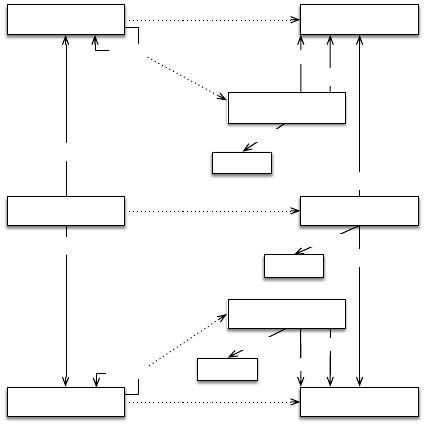
Mahout’s recommendation process recognises
users, items, and similarities between users or be-
tween items, user actions and their weights.
Because Mahout’s recommender system does not
recognise or handle ontologies, a mapping between
the system’s ontology and Mahout’s recommender
model is necessary. It converts the system’s ontol-
ogy data into a format that the recommendation en-
gine can use (cf. Figure 5).
According to Figure 5, it is possible to derive the
following concepts:
User. Derived from the foaf:Person concept. Each
“foaf:Person” from the system’s ontology is
mapped to “rec:User” in the recommendation
dataset.
Item. Derived from the “prv:DataItem concept”.
Each “prv:DataItem” is mapped from the system’s
ontology to the “rec:Item” concept in the recom-
mendation dataset.
Actions. Derived from the “provo:Activity” concept.
Each “provo:Activity” from the system’s ontology
is mapped into a rec:Action in Mahout’s. For each
mapped activity, respective relationships with the
user (“performedBy” property) and items (“over”
property) are created.
User/User Similarities. Derived from the
“foaf:knows” property. Each “foaf:knows”
property originates a “rec:UserSimilarity”
individual.
Item/Item Similarities. Derived from the “isSimi-
larTo” property. This similarity set is the outcome
of the semantic filtering approach.
The weight of each user action, item similarity
and user similarity is obtained by the number of rep-
KMIS 2015 - 7th International Conference on Knowledge Management and Information Sharing
58
weight
foaf:Person
foaf:knows
provo:Activity
rec:User
prv:DataItem rec:Item
weight
rec:ItemSimilarity
rec:UserSimilarity
weight
weight
over
performedBy
isSimilarTo
weight
over
rec:Action
weight
secondUser
firstUser
secondItem
firstItem
performedBy
Figure 5: System Ontology to Recommendation Dataset
Mapping.
etitions that occur during the mapping process. The
resulting dataset represents the input data for the rec-
ommender system.
5 EVALUATION
This evaluation suite gathers measurements of the
recommendation evaluation execution under different
runtime configurations. Some of the most relevant
configurations are shown.
This section describes each configuration’s exper-
iment and respective results. Experiments are charac-
terised according to the following dimensions:
• the recommendation dataset;
• the process of generating the training model and
relevant items;
• the process of generating and aggregating similar-
ities;
• the recommendation engine configurations (e.g.
AT).
Each experiment has its own configuration of
these dimensions. The experiments were conducted
for a top AT of 25, 50 and 150.
Each configuration evaluation consists in the cal-
culation of average precision, recall and f1.
Experiment’s results are compared to those of an
initial baseline experiment that is obtained by using
the dataset with the simplest possible configuration.
Baseline configurations were created using Ma-
hout’s algorithms without injecting any extra similar-
ities in the process, as depicted in Table 1 as configu-
ration C1.
The configurations derived from the C1 base-
line configuration are configured with an item-based
boolean recommender that uses the Log-Likelihood
Similarities algorithm as shown in Table 1.
By using the baseline recommender configuration
solely with semantic similarities (i.e. C105), preci-
sion and recall values drop when compared to the
baseline (i.e. C1).
Yet, when aggregating both the recommender sys-
tem similarities and the semantic similarities, using
an approach without averaging both similarity sets
weights (i.e. C104), it produces much better results:
precision is about six per cent higher, recall around
twenty-nine per cent and f1 about ten per cent higher
than the baseline and the normalised averaged ap-
proaches (i.e. C109 and C110) with union or average
intersection.
Using a normalised approach with intersection
provides worse results than a non-normalised union
of all results.
Based on these results, it is possible to conclude
that an item-based boolean recommendation is better
when enriched with semantic similarities compared to
the baseline configuration.
6 CONCLUSIONS
The access policy recommendation process aids re-
source authors in granting or denying access to ex-
isting resources by making use of similarity factors
between resources and social relationships and sug-
gesting which users should be given access to each
resource.
As any other recommendation process, the one
proposed is based upon three main parts: users, re-
sources and associations between users and resources.
Yet, provenance and traceability annotations, users’
social awareness, list of interest topics, resources’ and
users’ context are used in the recommendation pro-
cess to infer users’ interest in resources.
The addition of a semantic-filtering method that
is capable of using contextual semantic information
to the existing recommendation engine proved to en-
hance the results, even though it was achieved by only
using a minimal subset of information that a semantic
system can have.
The results demonstrate that introducing similar-
ities calculated from content and semantic informa-
tion into a collaborative filtering technique – either fo-
cusing on social networking, user profiles or resource
Recommending Access Policies in Cross-domain Internet
59

Table 1: Experiments Configuration and Results.
Similarity Prediction Aggregation Measures
Configuration ID
Log-Likelihood
Semantic
User/Item-Based
Boolean/Weighted
Normalised/Std.
Union
Union Average
Intersection Average
AT
Precision
Recall
F1
C1 L - I B - - - - 25 0,0814 0,4969 0,1399
C1 L - I B - - - - 50 0,0345 0,6086 0,0654
C1 L - I B - - - - 150 0,0193 0,6677 0,0376
C104 L S I B S UN - - 25 +0,0605 +0,2874 +0,1005
C104 L S I B S UN - - 50 +0,0143 +0,1988 +0,0266
C104 L S I B S UN - - 150 +0,0054 +0,1496 +0,0103
C105 - S I B - - - - 25 -0,0018 -0,0427 -0,0045
C105 - S I B - - - - 50 -0,0078 -0,1516 -0,0149
C105 - S I B - - - - 150 -0,0059 -0,2095 -0,0116
C109 L S I B N - UA - 25 +0,0456 +0,2011 +0,0750
C109 L S I B N - UA - 50 +0,0143 +0,1974 +0,0266
C109 L S I B N - UA - 150 +0,0055 +0,1530 +0,0105
C110 L S I B N - - IA 25 +0,0455 +0,2000 +0,0748
C110 L S I B N - - IA 50 +0,0143 +0,1973 +0,0266
C110 L S I B N - - IA 150 +0,0055 +0,1527 +0,0105
content – it is possible to improve recommendation
results.
In (Said et al., 2011) the authors used the Movie-
Lens dataset for measuring the system’s recommen-
dation performance, using a mean average precision
measure. Their precision values for an AT of 50 vary
from 0.0272 to 0.0687, which are on par with the
values obtained by the experiments conducted with
the baseline configuration for the same AT (0.0255
to 0.0345). In the conducted experiments precision
barely drops below 0.0500 hitting a maximum of
around 0.0800 for a top AT value of 25, which is bet-
ter than the best values (0.0699, AT=5) observed by
the authors in (Said et al., 2011). This proves that
precision measures produce quite small results but yet
good enough for providing comparison between dif-
ferent systems in an evaluation phase.
The usage of similarities produced from semantic
content injected in collaborative-filtering techniques,
shows that precision values higher than ten per cent
are easily achievable. Provenance and traceability in-
formation, together with enriched semantic informa-
tion, can indeed make the resource recommendation
better.
In summary, the proposed system architecture
provides the following features and functionalities:
• the resource author is recommended with new
access policies that would facilitate sharing re-
sources with other users;
• it allows discovering resources that users did not
even known existed;
• users can be given a list of resources which match
their interests or contexts, even though specific
names and content are not shown unless the au-
thor gives them permission to access it, i.e. the
resource author will know which user is request-
ing access but the requesting user does not know
who is the author;
• semantically enhanced recommendations, allow-
ing the creation of contexts (e.g. time and space)
for resources and users.
The adoption of a hybrid access-policy-
recommendation engine enables the enrichment
of access policy recommendations by using addi-
tional information provided by the system.
Captured provenance and traceability information
are used together with the user’s social networks and
resources’ contents as to automatically propose which
access policies should be added to a certain resource.
KMIS 2015 - 7th International Conference on Knowledge Management and Information Sharing
60
ACKNOWLEDGEMENTS
This work is supported by FEDER Funds through
the “Programa Operacional Factores de Competitivi-
dade - COMPETE” program and by National Funds
through “Fundac¸
˜
ao para a Ci
ˆ
encia e a Tecnologia
(FCT)” under the project Ambient Assisted Living for
All (AAL4ALL - QREN 13852).
REFERENCES
Adomavicius, G. and Alexander, T. (2011). Context-Aware
Recommender Systems. In Ricci, F., Rokach, L.,
Shapira, B., and Kantor, P. B., editors, Media, chap-
ter 7, pages 217–253. Springer US.
Bettencourt, N. and Silva, N. (2010). Recommending Ac-
cess to Web Resources based on User’s Profile and
Traceability. In the Tenth IEEE International Con-
ference on Computer and Information Technology,
CIT’10, pages 1108–1113, Bradford, UK. IEEE.
Convery, S. (2007). Network Authentication, Authoriza-
tion, and Accounting: Part One: Concepts, Ele-
ments and Approaches. The Internet Protocol Jour-
nal, 10(1):2–11.
Ghita, S., Nejdl, W., and Paiu, R. (2005). Semantically
Rich Recommendations in Social Networks for Shar-
ing, Exchanging and Ranking Semantic Context. So-
cial Networks, 3729:293–307.
Linden, G., Smith, B., and York, J. (2003). Amazon.com
recommendations: item-to-item collaborative filter-
ing. IEEE Internet Computing, 7(1):76–80.
MacKinnon, K. A. (2012). User Generated Content vs. Ad-
vertising: Do Consumers Trust the Word of Others
Over Advertisers? The Elon Journal of Undergrad-
uate Research in Communications, 3(1):14–22.
Nair, S. (2013). XACML Reference Architecture.
http://developers.xiomatics.com/blog/index/entry/
xacml-reference-architecture.html. Accessed on May
3, 2015.
Nimmons, S. (2012). Policy Enforcement Point Pattern.
http://stevenimmons.org/2012/02/policy-enforcement-
point-pattern/. Accessed on May 4, 2015.
Owen, S., Anil, R., Dunning, T., and Friedman, E. (2011).
Mahout in Action. Manning.
Parducci, B. and Lockhart, H. (2013). eXtensible Access
Control Markup Language (XACML) Version 3.0.
Technical Report January, OASIS.
Resnick, P., Kuwabara, K., Zeckhauser, R., and Friedman,
E. (2000). Reputation Systems. Communications of
the ACM, 43(12):45–48.
Ruohomaa, S., Kutvonen, L., and Koutrouli, E. (2007).
Reputation Management Survey. In Second Interna-
tional Conference on Availability, Reliability and Se-
curity, ARES’07, Vienna, Austria.
Said, A., Kille, B., De Luca, E. W., and Albayrak, S. (2011).
Personalizing Tags: A Folksonomy-like Approach for
Recommending Movies. In Proceedings of the Second
International Workshop on Information Heterogene-
ity and Fusion in Recommender Systems, HetRec’11,
pages 53–56, Chicago, IL, USA. ACM.
Schafer, J. B., Konstan, J. A., and Riedl, J. (2001).
E-Commerce Recommendation Applications. Data
Mining and Knowledge Discovery, 5(1):115–153.
Shardanand, U. and Maes, P. (1995). Social Informa-
tion Filtering: Algorithms for Automating “Word of
Mouth”. In the Proceedings of the ACM Confer-
ence on Human Factors in Computing Systems, editor,
Katz, I R and Mack, R and Marks, L and Rosson, M B
and Nielsen, J, volume 1 of CHI ’95, pages 210–217.
ACM Press/Addison-Wesley Publishing Co.
Speier, C., Valacich, J. S., and Vessey, I. (1999). The Influ-
ence of Task Interruption on Individual Decision Mak-
ing: An Information Overload Perspective. Decision
Sciences, 30(2):337–360.
Stephen, L., Dettelback, W., and Kaushik, N. (2008). Mod-
ernizing Access Control with Authorization Service.
Oracle - Developers and Identity Services, (Novem-
ber).
Vollbrecht, J. R., Calhoun, P. R., Farrell, S., Gommans, L.,
Gross, G. M., de Bruijn, B., de Laat, C. T., Holdrege,
M., and Spence, D. W. (2000). AAA Authorization
Framework [RFC 2904]. The Internet Society.
Wasserman, S. (2012). The Amazon Effect. http://www.
thenation.com/print/article/168125/amazon-effect.
Accessed on April 27, 2015.
Wasserman, S. and Faust, K. (1994). Social Network Anal-
ysis: Methods and Applications. Structural analysis
in the social sciences. Cambridge University Press, 1
edition.
Westerinen, A. and Schnizlein, J. (2001). Terminology for
Policy-Based Management [RFC 3198]. The Internet
Society.
Yavatkar, R., Pendarakis, D., and Guerin, R. (2000).
A Framework for Policy-based Admission Control
[RFC2753]. The Internet Society.
Recommending Access Policies in Cross-domain Internet
61
