POS Tagging-probability Weighted Method for Matching the Internet
Recipe Ingredients with Food Composition Data
Tome Eftimov
1, 2
and Barbara Korou
ˇ
si
ˇ
c Seljak
1
1
Computer Systems Department, Jo
ˇ
zef Stefan Institute, Jamova cesta 39, 1000 Ljubljana, Slovenia
2
Jo
ˇ
zef Stefan International Postgraduate School, Jamova cesta 39, 1000 Ljubljana, Slovenia
Keywords:
Part of Speech Tagging, Probability Model, Information Retrieval, Food Composition Databases, Ingredient
Matching.
Abstract:
In this paper, we present a new method that can be used for matching recipe ingredients extracted from the
Internet to nutritional data from food composition databases (FCDBs). The method uses part of speech tagging
(POS tagging) to capture the information from the names of the ingredients and the names of the food analyses
from FCDBs. Then, probability weighted model is presented, which takes into account the information from
POS tagging to assign the weight on each match and the match with the highest weight is used as the most
relevant one and can be used for further analyses. We evaluated our method using a collection of 721 lunch
recipes, from which we extracted 1,615 different ingredients and the result showed that our method can match
91.82% of the ingredients with the FCDB.
1 INTRODUCTION
It is evidence based that a healthier diet is required to
prevent diet-related chronic diseases and to increase
the quality of life. However, to assess the quality
of a diet, advanced approaches still need to be de-
veloped. There is a lot of information about health-
ier diet and nutrition principles presented in different
forms, available in books, magazines, television pro-
grams and Internet. But from other side, people are
lacking of knowledge about all the nutrition princi-
ples and also lack of time and motivation to explore
the resources where this kind of information is pre-
sented.
A lot of free data sources that contain recipe
databases exist and can be used for nutritional assis-
tance or recommendation systems. For this purpose,
it is important to have accurate nutritional data for
recipes, but most of the recipes have no such data
available or have data of suspect quality. The most
important is that people need to understand the nu-
tritional value of the individual meals and also how
they reflect their nutritional needs with respect to their
lifestyle.
In the past, different technological solutions were
represented, dealing with problems to assess and im-
prove diets. They used the information from the
recipes and food composition data. Food composition
databases (FCDBs) provide detailed information on
nutritional composition of foods, usually from a par-
ticular country. They contain information for a huge
number of components including: energy, macronu-
trients and their components, minerals and vitamins.
Food composition data is used for planning diets with
specific nutrient composition in clinical practice and
for assessment of the nutritional value of the food
consumed by individuals and populations (H. Green-
field and D. Southgate, 2003).
Using all this information is useful to generate
a system that automatically calculates the nutritional
value of the recipe and than the recipe can be used in
planing the diet for some individuals or populations.
The main problem is that the information on the In-
ternet is incomplete - on the other side FCDBs are
lacking of recipes and as chemical analysis is costly,
we need to find a way of calculating nutritional values
for recipes from the Internet considering food com-
position data of recipe ingredients. One of the key
problems is a lack of structure in the names of the in-
gredients used in the recipes and a lack of structure
in the names of the food analyses from the FCDB.
To calculate the nutritional value of the recipe, we
need for each ingredient from the recipe to find the
perfect or the most relevant ingredient match from
the FCDB. For example, we can find ”chicken breast,
raw” in a recipe, and several food analyses in the
330
Eftimov, T. and Seljak, B..
POS Tagging-probability Weighted Method for Matching the Internet Recipe Ingredients with Food Composition Data.
In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2015) - Volume 1: KDIR, pages 330-336
ISBN: 978-989-758-158-8
Copyright
c
2015 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
FCDB, which can be ”chicken breast, cooked, salted”
or ”raw chicken breast” or other name that contain
”chicken breast”. This is the problem from which de-
pends how accurate will be the calculated nutritional
value for the recipe using the food composition data
presented into the FCDBs.
In this paper, we present an information retrieval
method, which is a probability weighted method that
enables us to perform a search and find the most rel-
evant match for each recipe ingredient in the FCDB.
After having the most relevant match, we can use the
data from the FCDB to calculate the nutritional value
of the recipe.
In Section II, we review appropriate related work.
Section III describes the problem in depth. In Sec-
tion IV, we present our solution and in Section V, the
evaluation and results are presented using real data.
Section VI provides the discussion of the results, the
benefits of our method and comparison with other ap-
proaches presented in the literature. In Section VII,
we conclude the paper by discussing the proposed
method and our plans for future work.
2 RELATED WORK
The task of matching text concepts to an entry in a
knowledge base is a very popular one and has been
addressed in many ways. In 1988, term-weighting
approaches in automatic text retrieval systems were
presented, which could be designed on a comparison
between the stored text and users’ information queries
(Salton and Buckley, 1988). Another approach is POS
tagging, which means automatic assignment of de-
scriptors, or tags, to input tokens, where the tags are
the appropriate grammatical descriptors to words in
text. POS taggers can be used for several purposes,
and one of them is for text indexing and retrieval,
which can benefit from POS information (Schmid,
1994; Tian and Lo, 2015). The task of matching con-
cepts in text has progressed a lot and there are dif-
ferent methods for automatic text retrieval systems.
In (Mihalcea and Csomai, 2007), an automatic text
annotation system was presented, which combines
keyword extraction and word-sense disambiguation
to identify relevant links to Wikipedia pages. The
system is known as ”Wikify”, and involves automati-
cally extracting the most important words and phrases
in the document (keywords) and identifying for each
keyword the appropriate link to a Wikipedia article.
Another approach is the entity linking (EL), which is
the task of linking name mentions in text with their
referent entities in a knowledge base. One method
dealing with EL is presented in (Han et al., 2011),
which is a graph-based collective EL method, which
can model and exploit the global interdependence be-
tween different EL decisions. Also, there are ap-
proaches that are dealing with automatic ontology
based knowledge extraction, for example the Arte-
quakt project presented in (Alani et al., 2003) links a
knowledge extraction tool with an ontology to achieve
continuous knowledge support and guide information
extraction.
Technological solutions have been proposed to
improve recipe recommendations. The idea is to de-
sign systems that are able to provide meal recom-
mendations for individuals based on their nutritional
needs and lifestyle. One approach is presented in (J.
Freyne and S. Berkovsky, 2010), which give recom-
mendations of healthy recipes. In order to give rec-
ommendations, we need to calculate the nutritional
content of a recipe, which can be done using chemi-
cal analyses of final cooked dishes (Y.Pic
´
o, 2012) or
having a system that automatically calculate the nutri-
tional content of a recipe. In (M. Muller et al., 2012),
the authors presented a system that automatically cal-
culates the nutritional content of recipes sourced on
Internet. To match the ingredient to an appropriate
entry from the official nutritional table of the Ger-
man ministry for nutrition, agriculture and consumer
protection, the ingredient name is preprocessed by
removing the punctuations and converting to lower
case. Because the database search can return numer-
ous results and only a single item can be chosen, they
presented a system which can rank the list and the top
ranked item need to be used as appropriate match. To
learn the ranking function, they treated the problem as
two-class classification task where the negative class
is poor choices and the positive class is the correct
choice. To obtain the data, they asked 6 researches
to evaluate manually lists of ingredients for ambitious
ingredient descriptions. To learn from the data, they
extracted a number of features from the original in-
gredients name and the selected ingredients from the
database. At the end they performed penalised regres-
sion model, where the output is between -1 and 1 in-
citing the expected relevance of the ingredient to the
name. Using this method, 91.1% of the recipes they
used were matched completely and less than 1% have
more than one unmatched ingredient.
3 PROBLEM DEFINITION
The problem we want to address is to find the most
relevant match for the ingredients used in the recipes
using their name and the names of the food analyses
that are presented in the FCDBs.
POS Tagging-probability Weighted Method for Matching the Internet Recipe Ingredients with Food Composition Data
331
There are several issues that we need to consider
when we want to solve this problem. As we said be-
fore, there are a lot of online data sources which pro-
vide recipes. Some of them allow the users to log
into the system and to submit their own recipes, so
everyone can use it. The first issue is that people use
the human natural language, which is the main vehi-
cle through humans transmit and exchange informa-
tion, and write the name of the used ingredients in the
unstructured form. For example, in different recipes
we can find ”salt, iodised”, ”iodised salt” or ”salt-
iodised”. From this, we can conclude that the lack
of structured way of representation is presented, and
this happens because of the different ways of people
expression. Another issue is the ingredient synonymy
problem. So we need to match the synonyms to the
single term which is used in the databases. Some in-
gredients can have multiple matches in the food com-
position database. For example, if we are looking for
”salt”, we can find ”salt”, ”salt, table”, ”salt, iodised”
and many more. But all these matches may have very
different nutritional properties, so we need to chose
the most relevant one. Also, a very important fac-
tor when we want to calculate the nutritional proper-
ties is the preparation method of the ingredient. It is
different to have cooked or raw ingredient, for exam-
ple, ”smoked ham” and ”non-smoked ham”, ”chicken
breast, raw” and ”chicken breast, cooked”, because
they have different nutritional properties.
All of these issues need to be considered and need
to be solved when we want to find the relevant ingre-
dients matching, which can be used to calculate the
nutritional value of the recipes.
4 POS TAGGING-PROBABILITY
WEIGHTED METHOD
One method for ingredient matching is presented in
(M. Muller et al., 2012). The method treats the prob-
lem as two-class classification problem, which re-
quired evaluation by nutrition experts, and after that
they use a linear regression model to match the ingre-
dients.
Intend to solve the ingredient matching problem
with food composition data, we looked for the exist-
ing ontologies in this domain (LIRMM, 2015; On-
tology, 2015), and we have found that there are fo-
cused on food recipes, ingredients and nutrients, but
an information about the structure of the ingredient
name is still missing. An ingredient name is repre-
sented by noun, and it can be additional explain with
the form of the ingredient (adjective) and the cook-
ing process (verb), which are very important and need
to be considerate in case when we want to calculate
the nutritional value. Have in mind the importance of
the nouns, adjectives and verbs presented in the in-
gredient name, the Part Of Speech tagging (POS tag-
ging) is one technique that can be used for ingredient
matching with food composition data (A. Voutilainen,
2003).
Our method is a probability method with which
we assign a weight on each matching and we consid-
ered the match with the highest weight as the most rel-
evant one. First, for each ingredient from the recipe,
we use POS tagging, also called grammatical tag-
ging or word-category disambiguation, to identify the
nouns, verbs and adjectives. The nouns carry the
most of the information of the name, the adjectives
explain the ingredient in most specific form, for ex-
ample ”frozen”, ”fresh”, and the verbs are at the most
cases related with the preparation method, for exam-
ple ”cooked”, ”drained” etc. Then, we search the
FCDB for the ingredient with a simple SQL search
using the provided nouns from the ingredient name
in the recipe. For each found name as a result of the
SQL search, we also perform POS tagging to identify
the nouns, verbs and adjectives. Next, we define an
event (X) which is the similarity between the ingredi-
ent name from the recipe and each of the food names
that are returned from the SQL search of the FCDB.
At the end, the weight we assign to the matching pairs
is the probability of the event.
Let D
1
be the name of a single ingredient from
the recipe, and D
2
is the single food name which is a
result from the SQL search of the FCDB. Let’s define,
N
i
= {nouns extracted f rom D
i
},
V
i
= {verbs extracted f rom D
i
},
A
i
= {ad jectives extracted f rom D
i
}, (1)
where i = 1, 2.
To find the probability of the similarity between the
ingredient name from the recipe and the food name
from the FCDB, we present the event as a product of
three other events.
X = N ·V · A, (2)
where N is the similarity between the nouns which are
in N
1
and N
2
, V is the similarity between the verbs
which are in V
1
and V
2
and A is the similarity between
the adjectives which are in A
1
and A
2
.
Because all these events are independent, the proba-
bility of the event X can be find as
P(X) = P(N) · P(V ) · P(A). (3)
Now, we need to define the probabilities of each of
the events, N, V and A. Because we want to find the
similarity between two sets, it is logical to use the Jac-
card index, J, which is used in statistic for comparing
KDIR 2015 - 7th International Conference on Knowledge Discovery and Information Retrieval
332

the similarity and diversity of sample sets (R. Real
and J. M. Vargas, 1996). For this purpose, we use the
modification of the Jaccard index in combination with
Laplace probability estimate. We do this because in
some ingredients description the additional informa-
tion provided by the adjectives or verbs can be miss-
ing, but we can also find the relevant match into the
FCDB, so we will have non-zero probabilities. The
probabilities of the events can be find as
P(N) =
|N
1
∩ N
2
| +1
|N
1
∪ N
2
| +2
=
J(N
1
, N
2
) +
1
|N
1
∪N
2
|
1 +
2
|N
1
∪N
2
|
P(V ) =
|V
1
∩V
2
| +1
|V
1
∪V
2
| +2
=
J(V
1
, V
2
) +
1
|V
1
∪V
2
|
1 +
2
|V
1
∪V
2
|
P(A) =
|A
1
∩ A
2
| +1
|A
1
∪ A
2
| +2
=
J(A
1
, A
2
) +
1
|A
1
∪A
2
|
1 +
2
|A
1
∪A
2
|
. (4)
We obtained the probability of the event X, substitut-
ing the relations (4) into the relation (3), which is the
weight we assigned to each matching pair and at the
end, the pair with the highest weight is the most rele-
vant found match.
Important aspect of the ingredient matching is also
pre-processing. First each ingredient name without
the difference from where is it, we converted in a
lower case letters and also we removed the punc-
tuations. For the nouns, we use lemmatisation to
avoid the difference between the singular and the plu-
ral form of the noun (J. Plisson et al., 2004). Be-
cause, there are names that contain ”without skin” and
some other ”skinless”, or ” with salt” and ”salted”,
we mapped all of these phrases using rules which we
created manually, and are specific for this area. In
Figure 1, the architecture of the proposed method is
presented.
5 EVALUATION AND RESULTS
We performed the evaluation of the method by two
experiments. The first experiment is not the proper
evaluation of the method, but an illustration of the
problem that we are trying to solve, while the second
one is the matching between the Internet extracted in-
gredients and the food composition data.
The data we used for evaluation is a collection of
721 recipes written in English, from which we ex-
tracted 1,615 different names of ingredients. We col-
lected it using an HTML parser and a free recipes web
site (AllRecipes, 2015). For each of the recipes, we
considered only the names of the ingredients, while
the quantity-unit pair associated with the ingredient
was ignored, as our global goal was to find the ingre-
dients matching.
Algorithm 1: POS tagging-probability weighted method.
1: for each ingredient name in recipe do
2: - set matching pairs = null
3: - set counter = 1
4: - ingredient name pre-processing
5: - extract the sets of nouns N
1
, verbs V
1
, and
adjectives A
1
using POS tagging
6: - query the FCDB using the set of provided
nouns N
1
7: for each food name from the result of search-
ing the FCDB do
8: - food name pre-processing
9: - extract the sets of nouns N
2
, verbs V
2
,
and adjectives A
2
using POS tagging
10: - calculate P(X) = P(N)P(V )P(A)
11: - matching pairs[counter] = P(X )
12: - counter = counter + 1
13: end for
14: - return the most relevant match,
max(matching pairs)
15: end for
We used the EuroFIR FCDB as our database. Eu-
roFIR AISBL is an international, non-profit Associa-
tion under the Belgian law (EuroFIR, 2015). Its pur-
pose is to develop, publish and exploit food compo-
sition information and to promote international stan-
dards to improve data quality, storage and access.
EuroFIR presented data model for food composition
data management and data interchange. The EuroFIR
FCDB contains analyses from several European coun-
tries.
We extracted 44,033 English names of foods anal-
yses, which exist in the EuroFIR database. Before
we start with the evaluation, we preprocessed the in-
gredients names from the recipes and the food names
from the EuroFIR FCDB. First, we removed the punc-
tuations from them, and then we converted them in
lower-case letters.
5.1 Experiment 1
The first experiment we made is the ingredients
matching for one recipe and it is not the proper evalu-
ation of the method, but an illustration of the problem
that we are trying to solve. We used the recipe for
”World’s Best Lasagna”, extracted from (AllRecipes,
2015). The result of the ingredients matching is pre-
sented in the Figure 2. Using the information pre-
sented in the Figure 2, for the recipe that contains 20
ingredients, we were unable to find match only for
POS Tagging-probability Weighted Method for Matching the Internet Recipe Ingredients with Food Composition Data
333
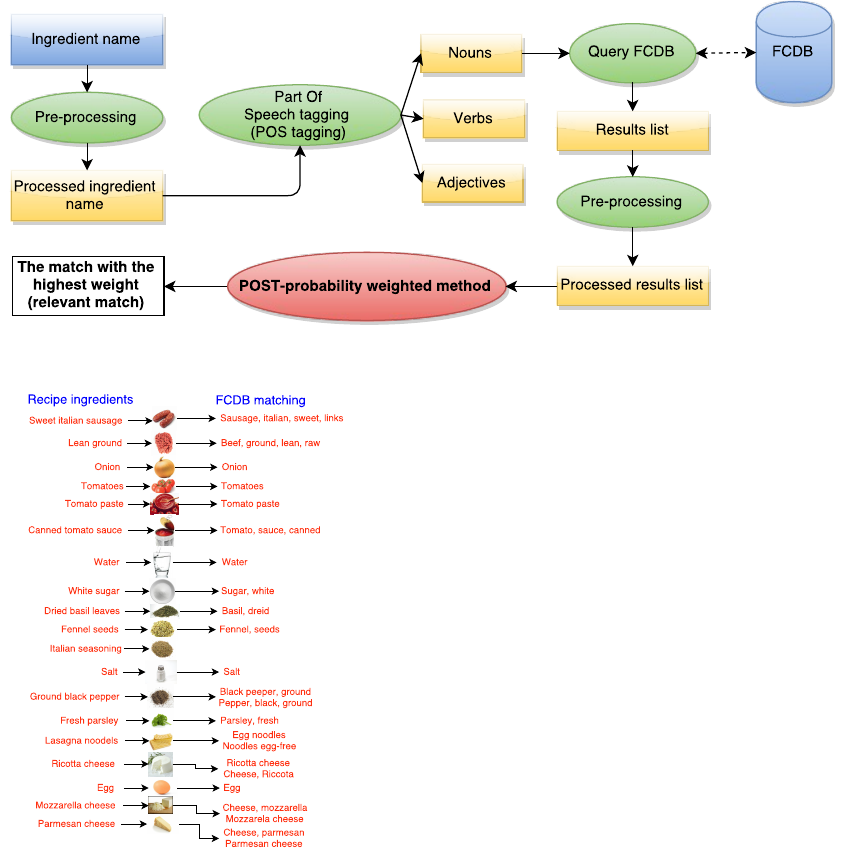
Figure 1: Architecture of the method.
Figure 2: Ingredients matching for ”World’s best Lasagna”.
one ingredient ”Italian seasoning”. The problem hap-
pened because ”seasoning” is not annotated here as
noun, so we can not continue with the search in the
FCDB. We used here the POS tagging which is the
part of R programming language. This kind of prob-
lem can be solved using some other implementation
of POS tagging or some post-processing methods. For
other ingredients, we found 18 perfect matches, and
for one ingredient, ”lasagna noodles”, we found most
similar match, which is the up close to it, and this hap-
pened because ”lasagne noodles” is not presented in
the FCDB.
We need to mention here that this experiment was
carried out without finding the synonyms and map-
ping the special definite rules.
5.2 Experiment 2
Using the 721 lunch recipes, we extracted 1,615 dif-
ferent names of the ingredients that appear in these
recipes. In Figure 3, the word cloud of the names of
the ingredients found in the recipes is presented. For
each ingredient name, using the probability weighted
model we found a match in the FCDB that can be in
one of the four categories (perfect match, very simi-
lar match, similar match, and incorrect match), which
we used for evaluation and we manually added to
each matching pair. A perfect match is with the same
meaning as the ingredient name. A very similar match
is the most similar and strongly related to the ingredi-
ent name. A similar match is weakly related with the
ingredient name. And an incorrect match is incorrect
and it can not be used for further analyses. The last
two categories appear according to some specific in-
gredients typical for some cultures and the coverage
of the FCDB.
In Figure 4, the pie chart of matching the Inter-
net recipe ingredients with food composition data is
presented.
Using the probability weighted model for match-
ing the ingredients, we found 1,210 perfect matches
(74.92%), 273 very similar matches (16.90%), 78
similar matches (4.84%) and 54 incorrect matches
(3.34%). Let we use the pair (D
ingredient
; D
FCDB
) to
describe the match we found, where D
ingredient
is the
ingredient name from the recipe and the D
FCDB
is
the name from the FCDB. For example, some perfect
matches are (black olives; olives black), and (fresh
ginger; ginger, fresh), very similar matches are (fresh
cilantro; spices, coriander seed (cilantro)), and (un-
cooked egg noodles; egg noodles), similar match is
(dry penne pasta; pasta, without egg, dry), and incor-
rect matches are (angel hair pasta; cake, angelfood,
KDIR 2015 - 7th International Conference on Knowledge Discovery and Information Retrieval
334

salt
garlic
onion
ground-black-pepper
olive-oil
water
vegetable-oil
soy-sauce
all-purpose-flour
pepper
garlic-powder
butter
white-sugar
brown-sugar
cheddar-cheese
cornstarch
mozzarella-cheese
worcestershire-sauce
milk
ketchup
green-bell-pepper
dried-oregano
green-onions
parmesan-cheese
cayenne-pepper
black-pepper
eggs
sesame-oil
red-onion
fresh-mushrooms
ground-beef
chicken-broth
freshly-ground-black-pepper
celery
honey
lemon-juice
paprika
red-pepper-flakes
skinless,-boneless-chicken-breast-halves
tomato
hot-pepper-sauce
chili-powder
egg
pork-spareribs
carrots
eggs,-beaten
lean-ground-beef
swiss-cheese
bacon
ground-cumin
onions
tomatoes
fresh-parsley
barbeque-sauce
dried-thyme
fresh-cilantro
red-bell-pepper
fresh-ginger-root
mayonnaise
sour-cream
ground-ginger
active-dry-yeast
garlic-salt
pizza-sauce
green-onion
peanut-oil
warm-water
condensed-cream-of-mushroom-soup
fresh-ginger
kosher-salt
zucchini
balsamic-vinegar
crumbled-feta-cheese
mushrooms
onion-powder
tomato-sauce
beef-broth
ground-nutmeg
monterey-jack-cheese
sesame-seeds
sweet-onion
cooking-spray
mushrooms,-drained
rice-vinegar
sugar
tomato-paste
broccoli-florets
carrot
condensed-cream-of-chicken-soup
egg,-beaten
fresh-rosemary
orange-juice
pepperoni
cold-water
curry-powder
dijon-mustard
dried-basil
ground-cinnamon
hamburger-buns
lime-juice
oyster-sauce
red-pepper
baby-back-pork-ribs
beef-short-ribs
black-olives
butter,-melted
dried-parsley
dry-bread-crumbs
ground-turkey
pork-tenderloin
cider-vinegar
dry-sherry
green-bell-pepper,-seeded
pre-baked-pizza-crust
prepared-mustard
ricotta-cheese
unbaked-pie-crust
vinegar
beer
boneless-pork-loin-roast
country-style-pork-ribs
dry-mustard
fish-sauce
fresh-basil
heavy-cream
pastry
red-wine-vinegar
teriyaki-sauce
white-vinegar
broccoli
cooked-ham
distilled-white-vinegar
hoisin-sauce
italian-seasoning
lemon,-juiced
oil
white-wine
yellow-onion
apple-cider-vinegar
baking-powder
barbecue-sauce
bay-leaves
bread-flour
buttermilk
canola-oil
dried-rosemary
dry-onion-soup-mix
evaporated-milk
extra-virgin-olive-oil
fresh-spinach
liquid-smoke-flavoring
more
orange-zest
chicken-stock
chili-sauce
fresh-chives
fresh-lemon-juice
ground-chicken
ground-white-pepper
lettuce
low-sodium-soy-sauce
melted-butter
peanut-butter
potatoes,-peeled
romaine-lettuce
toasted-sesame-seeds
baking-soda
beef-chuck-roast
bok-choy
cabbage
coarsely-ground-black-pepper
cornmeal
cream-cheese,-softened
eggs,-lightly-beaten
fresh-thyme
ground-cloves
half-and-half
ham
margarine
prepared-yellow-mustard
provolone-cheese
red-wine
seasoned-salt
avocado---peeled,-pitted
brown-rice
celery-salt
chinese-five-spice-powder
coconut-milk
corn-tortillas
cucumber
dried-cranberries
enchilada-sauce
fresh-broccoli
garlic,-peeled
ginger
ground-coriander
heavy-whipping-cream
italian-seasoned-bread-crumbs
lemon-zest
lime,-juiced
panko-bread-crumbs
plain-yogurt
pork-baby-back-ribs
potatoes,-peeled-and-cubed
red-bell-peppers
red-potatoes
refrigerated-pizza-dough
rice-wine
rice-wine-vinegar
salami
salsa
skinless,-boneless-chicken-breast
steak-sauce
sun-dried-tomatoes
white-wine-vinegar
whole-chicken
artichoke-hearts,-drained
baby-back-ribs
black-beans,-rinsed-and-drained
bulk-italian-sausage
butter,-softened
cajun-seasoning
carrots,-peeled
cauliflower
celery-seed
cooked-chicken
egg-whites
flour-tortillas
fresh-lime-juice
fresh-mint
frozen-spinach,-thawed-and-drained
garam-masala
ground-pork
ground-turmeric
herbes-de-provence
hot-chile-paste
hot-sauce
hot-water
iceberg-lettuce
jalapeno-pepper
lemon-pepper
maple-syrup
molasses
pepperoni-sausage
pork-chops
prepared-horseradish
reduced-sodium-soy-sauce
refrigerated-crescent-rolls
roma-(plum)-tomatoes
romano-cheese
sharp-cheddar-cheese
shortening
shrimp,-peeled-and-deveined
spaghetti
taco-seasoning-mix
uncooked-long-grain-white-rice
walnuts
water-chestnuts,-drained
yellow-cornmeal
applesauce
black-olives,-drained
blue-cheese,-crumbled
bread-crumbs
bulk-pork-sausage
cashews
cherry-tomatoes,-halved
chile-garlic-sauce
coarse-grain-brown-mustard
condensed-tomato-soup
cooked-white-rice
dark-soy-sauce
dried-tarragon
dry-milk-powder
dry-ranch-style-dressing-mix
egg,-lightly-beaten
eggplant
flour
fresh-asparagus
fresh-bread-crumbs
fresh-dill
frozen-bread-dough,-thawed
garbanzo-beans,-drained-and-rinsed
garlic-cloves
green-bell-peppers
ground-allspice
ground-thyme
hickory-flavored-barbeque-sauce
italian-cheese-blend
jalapeno-pepper,-seeded
lime
mexican-cheese-blend
monosodium-glutamate
oil-for-deep-frying
pecans
pineapple
pineapple,-drained
plum-sauce
pork-loin
poultry-seasoning
ranch-dressing
red-bell-pepper,-seeded
refrigerated-pizza-crust
sea-salt
seasoned-bread-crumbs
seasoning-salt
shallot
skinless,-boneless-chicken-breast-half
steak-seasoning
tomato-juice
tomatoes-with-green-chile-peppers
tomatoes,-drained
white-pepper
whole-cloves
yellow-bell-pepper
asiago-cheese
baby-spinach-leaves
bay-leaf
bean-sprouts
beef-bouillon-granules
beef-brisket
black-beans,-drained
black-peppercorns
boneless-beef-short-ribs
boneless-chicken-breast-halves,-cooked
boneless-country-style-pork-ribs
boneless-pork-loin-chops
burgundy-wine
cherry-tomatoes
chile-paste
chile-sauce
chinese-rice-wine
colby-monterey-jack-cheese
condensed-cream-of-celery-soup
crumbled-gorgonzola-cheese
cubed-cooked-chicken
cubed-cooked-ham
curry-paste
dark-sesame-oil
deep-dish-frozen-pie-crusts
dried-marjoram
dry-white-wine
eggs,-well-beaten
english-muffins
fennel-seed
feta-cheese
firm-tofu,-drained-and-cubed
flank-steak
french-fried-onions
fresh
fresh-coriander
fresh-corn-kernels
fresh-curry-leaves
fresh-green-chile-peppers
frozen-green-peas,-thawed
frozen-puff-pastry,-thawed
garlic,-pressed
granulated-garlic
grapeseed-oil
green-chile-peppers
ground-lamb
ground-sirloin
hamburger-buns,toasted
heinz-tomato-ketchup
honey-mustard
italian-style-salad-dressing
kikkoman-soy-sauce
lean-ground-turkey
lemon
lettuce-leaves
light-soy-sauce
limes
marinara-sauce
mustard-powder
onions,-coarsely
parsley
peanuts
peeled-and-deveined-shrimp
pesto
pitted-kalamata-olives
pork-tenderloins
portobello-mushroom-caps
prepared-pizza-crust
prime-rib-roast
red-cabbage
roast-beef
roma-tomatoes
rubbed-sage
self-rising-flour
shallots
snap-peas
snow-peas
spaghetti-sauce
spicy-brown-mustard
spinach
sugar-snap-peas
tarragon-vinegar
tuna,-drained
unbaked-pie-crusts
unbaked-pizza-crust
uncooked-white-rice
vegetable-broth
white-bread
whole-wheat-bread
alfredo-sauce
american-and-cheddar-cheese-blend
american-cheese
angel-hair-pasta
apple
apple-jelly
apple-juice
as-desired
banana
basil
beef-bouillon
beef-chuck-flanken
beef-sirloin-steak
beef-stock
bell-pepper
blue-cheese
brandy
bread
brioche
brown-gravy-mix
canned-tomatoes
cannelloni-noodles
chili-oil
coconut-oil
cold-milk
cooking-oil
couscous
cream-cheese
crumbled-feta
cumin-seed
cumin-seeds
deli-ham
dried-chives
dried-dill-weed
dry-oatmeal
dry-polenta
extra-firm-tofu
firm-tofu
flaked-coconut
flounder
frozen-peas
ginger-paste
ice-water
instant-rice
kaiser-rolls
kale
linguine
longhorn
onion-salt
peeled-potatoes
pita-breads
porter-beer
potatoes
ranch-style-beans
rice-flour
salt,
softened-butter
tortilla-chips
yeast
almond-meal
arugula
bagel
beef-frankfurters
bell-peppers
bitter-ale
breadcrumbs
brown-ale
buds
capers
chicken
chicken-bouillon-powder
cilantro
clams
corn
corn-bread-mix
corn-oil
cumin
dark-beer
dark-rum
dill
dry-grits
dry-lentils
dry-red-wine
egg-yolk
farfalle-pasta
fennel
fine-salt
flank
fresh-basil-leaves
fresh-okra
garlic,
ginger-ale
glaze:
halibut
imitation-crab-meat
lamb-ribs
lard
leeks
onion,-halved
oregano
panko
port
radish
raisins
red
root-beer
rum
sake
salsa,
sunflower-seeds
surimi
tamari
thighs*
tilapia
tuna
turnips
white-rice
whole-milk
Figure 3: Word cloud of the ingredients.
Figure 4: Pie chart of ingredients matching.
commercially prepared), and (dried onion flakes; ce-
real flakes with dried fruits, type Muesli). The perfect
and very similar matches are 91.82% together. They
can be used to calculate the nutritional properties on
a recipe.
The experiment is done with preprocessed data.
6 DISCUSSION
There are some benefits in our method, comparing it
with the method that is used to find the most relevant
match in (M. Muller et al., 2012). In order to find the
most relevant match, they treated the problem as two-
class classification problem and to obtain labeled data
they asked 6 human assessors to manually evaluate
list of ingredients for ambiguous ingredient names.
This process ended with 1,515 positively classified in-
stances to which they added the same number again
of negatively classified instances. Instead of manu-
ally collecting list of ingredients that are positively
classified, our method can be used as pre-processing
task, and for each of the ingredient can return the rele-
vant ingredient or a list of relevant ingredients, if there
are few matching pairs with the maximum weight
for the same ingredient. After that, this data can be
used for building models, starting with feature selec-
tion and then solving two-class or multi-class classi-
fication problems. So our method is a benefit to the
method proposed in (M. Muller et al., 2012) and can
be used as pre-processing step to find the list of in-
gredients for each ingredient without using the man-
ually evaluation by human assessors. Another benefit
is that our method also returned the most similar in-
gredient that exist in the FCDB and does not require
labeled data for supervised learning, the poor choices
that appeared are consequence from some ingredients
typical for some culture or missing chemical analy-
ses in the FCDB. Also, there are a lot of websites on
which we can find recipes by the ingredients we have
(MyFridgeFood, 2015; RecipeMatcher, 2015; Super-
cook, 2015), but using them we can select from a list
of ingredients they have, and in the most cases they
have only the basic name of the ingredients, without
the possibility of using the additional information (the
form of the ingredient, or the cooking process). Us-
ing them the result is more general, and if we use our
method to search the recipe database, the result will
contain only the most specific recipes.
We are also working on food image recognition,
in order to identify the ingredients in recipes, which is
more realistic and challenging task, but the approach
is beyond the scope of the paper.
7 CONCLUSION
We presented a method, that can be used for match-
ing the recipe ingredients with food composition data.
Using this method, we can weight each match be-
tween the ingredient name from recipe and food anal-
yses names from FCDBs and then the match with
the highest weight is used as the most relevant one.
Having this information, we will be able to calculate
the nutrition value of each of the recipe which is pre-
sented, because for each ingredient used in the recipe
we can find the nutritional properties from a FCDBs.
Also, this method can be used to weight the ingredi-
ents matching, and the weighted data can be used to
help more other models, which can be obtained using
data mining approaches. This method can be used to
explore what is missing in the FCDBs, and this infor-
mation can be addressed to the chemical laboratories
in order to perform food composition data analyses.
POS Tagging-probability Weighted Method for Matching the Internet Recipe Ingredients with Food Composition Data
335
We plan to implement this method into a system
which will be used for computing the nutritional value
of recipes, and to compare the accuracy of the ob-
tained values comparing them with the values from
the chemical analyses, which are obtained by chem-
ical analyses of the dishes prepared using the same
recipes.
ACKNOWLEDGEMENTS
This work was supported by the project ISO-FOOD,
which received funding from the European Union’s
Seventh Framework Programme for research, techno-
logical development and demonstration under grant
agreement no 621329 (2014-2019).
REFERENCES
Alani, H., Kim, S., Millard, D. E., Weal, M. J., Hall, W.,
Lewis, P. H., and Shadbolt, N. R. (2003). Automatic
ontology-based knowledge extraction from web doc-
uments. Intelligent Systems, IEEE, 18(1):14–21.
AllRecipes. Allrecipes website. http://allrecipes.com/. Ac-
cessed: 2015-05-04.
A. Voutilainen (2003). Part-of-speech tagging. The Oxford
handbook of computational linguistics, pages 219–
232.
EuroFIR. Eurofir website. http://www.eurofir.org/. Ac-
cessed: 2015-05-04.
Han, X., Sun, L., and Zhao, J. (2011). Collective entity
linking in web text: a graph-based method. In Pro-
ceedings of the 34th international ACM SIGIR con-
ference on Research and development in Information
Retrieval, pages 765–774. ACM.
H. Greenfield and D. Southgate (2003). Food composi-
tion data: production, management, and use. Food
& Agriculture Org.
J. Freyne and S. Berkovsky (2010). Intelligent food plan-
ning: personalized recipe recommendation. In Pro-
ceedings of the 15th international conference on In-
telligent user interfaces, pages 321–324. ACM.
J. Plisson, N. Lavrac, and D. Mladenic (2004). A rule based
approach to word lemmatization. Proceedings of IS-
2004, pages 83–86.
LIRMM. Lirmm. http://data.lirmm.fr/ontologies/food/. Ac-
cessed: 2015-05-04.
Mihalcea, R. and Csomai, A. (2007). Wikify!: linking doc-
uments to encyclopedic knowledge. In Proceedings of
the sixteenth ACM conference on Conference on infor-
mation and knowledge management, pages 233–242.
ACM.
M. Muller, M. Harvey, D. Elsweiler, and S. Mika (2012). In-
gredient matching to determine the nutritional proper-
ties of internet-sourced recipes. In Pervasive Comput-
ing Technologies for Healthcare (PervasiveHealth),
2012 6th International Conference on, pages 73–80.
IEEE.
MyFridgeFood. Myfridgefood website. http:// myfridge-
food.com/. Accessed: 2015-08-20.
Ontology, B.-F. Bbc - food ontology. http://www.bbc.co.uk/
ontologies/fo/. Accessed: 2015-05-04.
RecipeMatcher. Recipematcher website. http://
www.recipematcher.com/. Accessed: 2015-08-20.
R. Real and J. M. Vargas (1996). The probabilistic basis
of jaccard’s index of similarity. Systematic biology,
pages 380–385.
Salton, G. and Buckley, C. (1988). Term-weighting ap-
proaches in automatic text retrieval. Information pro-
cessing & management, 24(5):513–523.
Schmid, H. (1994). Probabilistic part-of-speech tagging us-
ing decision trees. In Proceedings of the international
conference on new methods in language processing,
volume 12, pages 44–49. Citeseer.
Supercook. Supercook website. http://
www.supercook.com/. Accessed: 2015-08-20.
Tian, Y. and Lo, D. (2015). A comparative study on the
effectiveness of part-of-speech tagging techniques on
bug reports. In Software Analysis, Evolution and
Reengineering (SANER), 2015 IEEE 22nd Interna-
tional Conference on, pages 570–574. IEEE.
Y.Pic
´
o (2012). Chemical analysis of food: Techniques and
applications. Academic Press.
KDIR 2015 - 7th International Conference on Knowledge Discovery and Information Retrieval
336
