
An Ontology-based Collaboration Recommender System using Patents
Sandra Geisler
1
, Rihan Hai
1
and Christoph Quix
2
1
Databases and Information Systems, RWTH Aachen University, Germany
2
Fraunhofer-Institute for Applied Information Technology FIT, St. Augustin, Germany
Keywords:
Ontology Engineering, Patent Analysis, Ontology Matching.
Abstract:
Successful research and development projects start with finding the right partners for the venture. Especially
for interdisciplinary projects, this is a difficult task as experts from foreign domains are not known. Further-
more, the transfer of knowledge from research into practice is becoming more important in research projects
to enable the quick application of research results. This is in particular relevant for projects in medical engi-
neering. Patents and publications contain technical knowledge which can be exploited to find suitable experts.
Patents are usually more product-oriented as the inventors have to describe an application area and products
might be protected by patents. On the other hand, scientific publications represent the state-of-the-art in re-
search. The challenge is finding the right mixture of research- or application-oriented experts from different
domains. Hence, we propose a recommender system for experts for a certain topic based on patent topic
clustering, ontologies, and ontology matching, which maps patents to corresponding innovation fields. The
medical engineering domain serves as a first test bed, since projects in this area are highly interdisciplinary.
1 INTRODUCTION
Innovation drives research and industry. It is impor-
tant in both fields to be up-to-date to what will be
promising in the future. Especially, medical engi-
neering (ME) is an “innovative, strongly growing, and
promising industry in Germany”
1
. In ME, interdis-
ciplinary projects are very common as experts from
medicine, engineering, and other disciplines are re-
quired. Furthermore, this domain is highly dependent
on its innovative capabilities as product cycles are get-
ting shorter and shorter.
Ventures in research and industry rise and fall
with the expertise of the partners in the project team.
Hence, it is crucial for the success of innovative
projects and their proposals to find suitable part-
ners. Studies demonstrate, that collaboration be-
tween research institutions and companies are benefi-
cial for both, product and process innovations (Robin
and Schubert, 2013). Especially in interdisciplinary
projects, the search for experts in unfamiliar domains
is time consuming, cumbersome, and might not be as
successful as expected. Hence, to assist the process of
finding partners for a venture, a recommendation sys-
tem is desired which speeds up the search and helps
to discover collaboration opportunities.
1
http://www.bvmed.de/branchenbericht
Patents contain a wealth of technical information
used for the development of products, but are at the
same time hard to analyze as they are written using
special terminology (Aras et al., 2014; Zhang et al.,
2015). As patent inventors are not only experts in
their field, but also have a product-oriented view on
ME research, they constitute interesting projects part-
ners. Therefore, we propose an approach using patent
clustering, ontology mappings, and ontology match-
ing to recommend collaboration opportunities.
In the mi-Mappa project
2
, we aim at finding suit-
able experts for ME projects based on patents and
innovation fields. According to (Schl
¨
otelburg et al.,
2008), an innovation field in ME is defined as an area
which has significant innovation activity, future po-
tential, and a value chain as complete as possible. The
main innovation fields for ME comprise (Schl
¨
otelburg
et al., 2008; Deutsche Gesellschaft f
¨
ur Biomed. Tech-
nik im VDE, 2012): Imaging Techniques, Prothe-
ses and Implants, Medical Information Systems and
Telemedicine, Interventional Devices, Systems, and
Techniques, In-vitro Technology, Special Therapy
and Diagnostic Systems, and cross-sectional topics,
such as patient safety.
In this paper, we propose an approach that com-
bines two complementary ways: 1. We build a profile
2
http://www.dbis.rwth-aachen.de/mi-Mappa
Geisler, S., Hai, R. and Quix, C..
An Ontology-based Collaboration Recommender System using Patents.
In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2015) - Volume 2: KEOD, pages 389-394
ISBN: 978-989-758-158-8
Copyright
c
2015 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
389
of the expert, which includes her publications, web-
sites, and other business related information. This
comprises the identification of the inventor with a cor-
responding author of scientific publications. If we
find a corresponding author, we can match her pub-
lications to innovation fields to identify her special-
ization areas. We can use classification terms present
in publication databases and semi-automatic ontology
matching to create the mappings. 2. If an inventor
could not be identified as an author of scientific pa-
pers, the patents are clustered by topic and these top-
ics are finally mapped to innovation fields using on-
tology matching.
In the following section, we will discuss existing
works in patent analysis and collaboration recommen-
dations. A full description of our approach is given in
Section 3. Finally, Section 4 concludes the paper.
2 RELATED WORK
Collaboration/Expert Recommender Systems.
The process of finding collaboration opportunities
often involves a manual process. For example, prede-
fined criteria are analyzed, and scores are calculated
and weighted based on these criteria (Geum et al.,
2013; Awasthi et al., 2015). Partners in supply chains
can be found by using supervised and unsupervised
learning, statistics, and analyzing criteria (Wu and
Barnes, 2011). In the field of finding partners
for R&D projects, no related semi-automatic or
automatic approach could be found.
Systems to find experts for a certain topic are
based on self-disclosure (personal information main-
tained manually), authored documents, or social net-
work activity (Wang et al., 2013). The systems can
also be categorized into expert profiling and expert
finding (Balog and De Rijke, 2007). The most re-
cent works are using algorithms from social network
analysis, such as the link analysis algorithms PageR-
ank or HITS (Rafiei and Kardan, 2015; Wang et al.,
2013) and graph-based algorithms (Rani et al., 2015).
We will concentrate on expert finding using authored
documents (e.g., patents & publications) as we do
not need (yet) a complete profile of a researcher.
Many document-based Expert Recommender Sys-
tems (ERS) are only using enterprise-level documents
and are restricted to employees in the same company.
In contrast, we propose a document-based approach
which uses information from any publications and
patents available. The DEMOIR approach (Yimam-
Seid and Kobsa, 2003) also uses ontologies and do-
main models for expert finding, but they use them to
model the expertise only.
Patent Analysis using Ontologies. The usefulness
of ontologies has also been recognized for the patent
domain, especially for patent search (Bonino et al.,
2010). The PatExpert system, for example, uses a
network of ontologies and knowledge bases to enable
patent search, classification, and clustering (Wanner
et al., 2008). Trappey et al. propose a system that cal-
culates the conditional probability that, given a spe-
cific text chunk is present in the document, the chunk
is mapped to a specific concept of a given ontol-
ogy (Trappey et al., 2009). Patent similarity is then
based on the number of common matched concepts.
This approach restricts the clustering to the terms of
the ontology which might lead to missing important
terms not present in the ontology.
Patent Clustering. An overview of patent docu-
ment contents can be retrieved by clustering. Tseng et
al. propose a full-text patent clustering methodology
which includes document clustering, term clustering,
and multi-stage clustering to avoid skewed distribu-
tion among clusters (Tseng et al., 2007). TF or IDF
(see section 3.2) filtered terms are clustered accord-
ing to their co-occurrence. Moreover, each cluster
obtains a summary title by statically calculating the
most frequent terms in the clusters with correlation
coefficient method. A bibliometric approach based on
co-citation analysis is introduced in (Mogee and Ko-
lar, 1999). The co-cited documents are linked under
the assumption that they share the subject matter. The
result of the approach also indicates core competen-
cies in the corresponding industrial field. However,
using co-citation to group patents may lead to super-
ficial results due to the lack of internal knowledge of
the patents (Yoon and Park, 2004). Another drawback
is that patents without references are excluded from
this approach. Trappey et al. describe a methodol-
ogy to cluster patents in three steps. First they extract
the key phrases of a patent, i.e., they use an ontology-
based, statistical method to extract key phrases which
represent an important topic in the document. After-
wards they build Technology Clusters of these key
phrases using an non-exhaustive overlapping cluster
algorithm proposed by Chen and Hu (Trappey et al.,
2010; Chen and Hu, 2006). By calculating the cumu-
lative weights for the key phrases of a document, they
can determine the Technology Cluster for a patent. In
the last step, they use the same clustering technique to
cluster the patent documents.
In summary, all of the approaches may cover a
part of our approach, but we present a novel approach
which combines the use of patent analysis, cluster-
ing, ontology design, and ontology matching to rec-
ommend experts for a R&D collaboration.
KEOD 2015 - 7th International Conference on Knowledge Engineering and Ontology Development
390
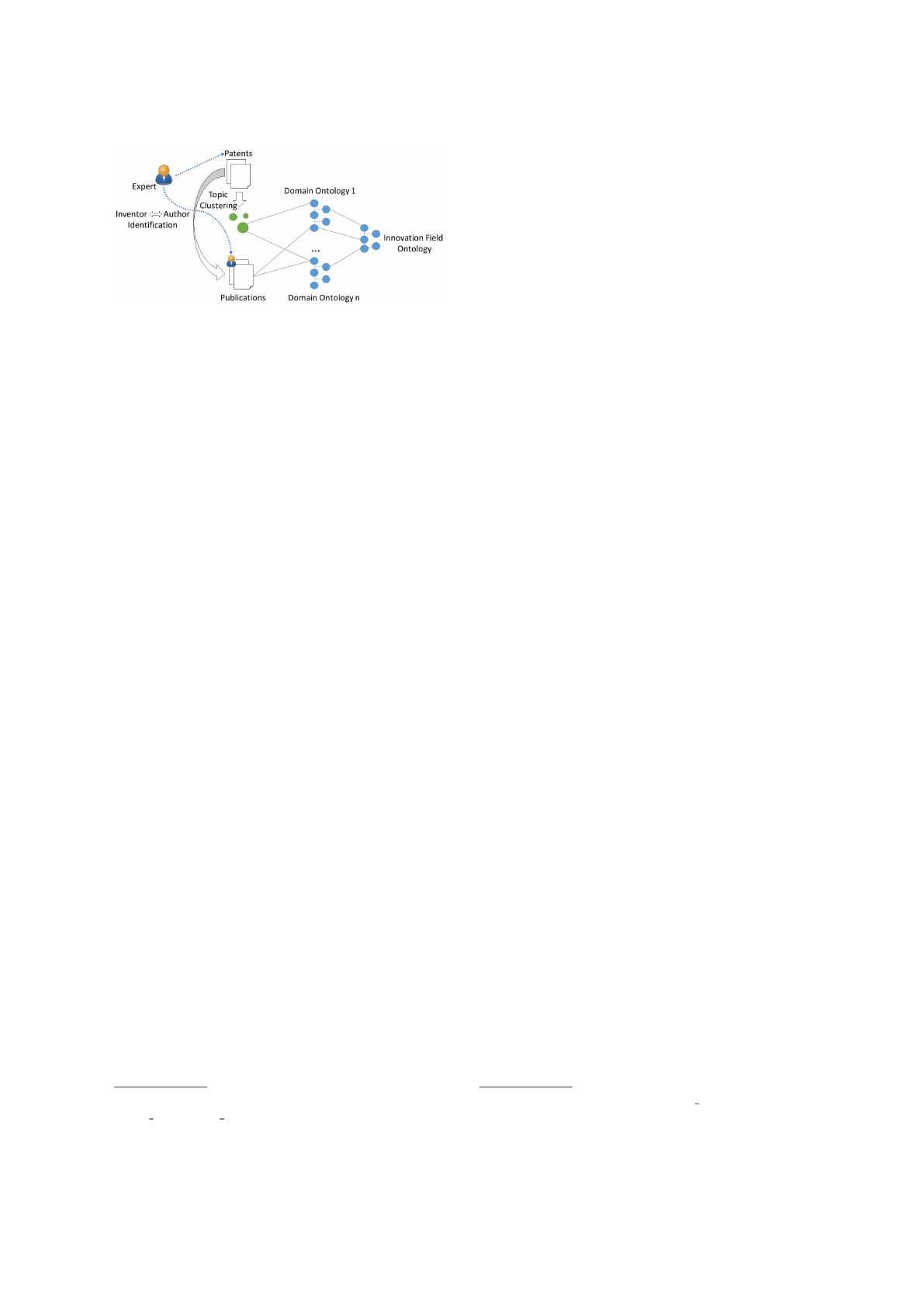
Figure 1: Architecture to map patents to innovation fields.
3 APPROACH
Based on the processed information type, patent anal-
ysis can be categorized into quantitative and qualita-
tive approaches
3
, which we both utilize in our ap-
proach. Qualitative approaches extract patent meta-
data, e.g., inventors, references, affiliation, while
quantitative methods process the full-text, such as
claims and abstracts of patent documents. The goal
of the overall approach, depicted in Figure 1, is to
map inventors of a patent and subsequently the cor-
responding patents to innovation fields. We propose
to do this in two different, but supplementary ways:
1. Match inventors with publication authors. 2. Clus-
ter patents based on the topics they cover. For both
approaches, we preselect patents based on a search
with keywords extracted from the description of the
intended project. The resulting patents can be used
to initialize the clustering. In both approaches the re-
sults (publications or topics) will be matched to ex-
isting medical ontologies. If a mapping between the
matched medical terms and concepts of an innovation
field exists, a link between patent inventor and inno-
vation fields has been found.
In the following, we detail the two process flows.
Subsequently, we describe the design of the utilized
ontologies and the matching in the ontology network.
3.1 Inventor-Author-Identification
It is first assumed, that an inventor may be also work-
ing as a researcher and is publishing scientific arti-
cles in the same domain. We map inventors to au-
thors, because articles published in journals or con-
ferences are often classified by publishers and pub-
lication databases. Those classifications usually use
terms which are easier to harvest and match to do-
main ontologies than the abstract International Patent
Classification (IPC) or similar classifications. Very
promising are bibliographic search engines such as
3
http://www.wipo.int/sme/en/documents/
patent information fulltext.html
Web of Science, or PubMed, which offer classifica-
tion of papers according to well known medical tax-
onomies. We will search the bibliographic databases
by author name using a corresponding API. For au-
thor identification, we use a multi-step process that
uses clustering techniques and statistics to determine
the highest probability of an author being the same
person as an inventor of a certain patent. We extract
the keywords and classification terms from the meta-
data of the papers and match them with medical on-
tologies which in turn will be mapped to an innovation
field ontology.
3.2 Topic Clustering
A study showed that 70-90% of technological knowl-
edge is only published in patents
4
. Hence, it can
be assumed that there exist inventors who have only
published patents and an alternative way of mapping
patents and inventors to an innovation field has to be
found for those persons. We propose to use topic clus-
tering of the patents to do so. This second approach
can also be used to verify the results of the first ap-
proach.
In patent analysis, classifications such as the
IPC are often too broad for specific analytical us-
age (Tseng et al., 2007) and more detail-oriented cat-
egorizations are needed. Clustering methods group
objects such that the similarity between objects in the
same cluster is greater than the similarity of objects in
different clusters. The similarity is usually measured
in terms of their relative position in an n-dimensional
space using Euclidean or Manhattan distances.
We utilize a set of common preprocessing tech-
niques to facilitate feature extraction, indexing, and
clustering. These comprise, amongst others, docu-
ment parsing, tag removal, tokenization, and lower-
casing. Additional steps, such as stemming, pruning,
and stopword removal, help to reduce the term set size
and increase its quality, improving clustering accu-
racy (Gonc¸alves et al., 2010). In each document, only
the key terms are selected to present the features of
the document, utilizing Inverse Document Frequency
(IDF) and Term Frequency (TF) within certain thresh-
olds. These terms are weighed based on TF ˆ IDF,
followed by calculating the similarity using cluster-
ing algorithms. Documents are usually merged to
clusters successively (hierarchical clustering) or dis-
tributed to certain clusters defined in the beginning
(partition clustering). We use both kinds of distance-
based clustering in our approach, including K-means
4
http://www.integrityip.com/Patent Library/
Community/Other/GlobalPatentSources.pdf
An Ontology-based Collaboration Recommender System using Patents
391

and K-medoid algorithms with pre-chosen centroids
from the query results.
Moreover, it is common in patent analysis that a
patent includes multiple features, claims, or inventors.
Hence, the non-exhaustive overlapping clustering al-
gorithm (Trappey et al., 2010) is adopted in our ap-
proach. Finally, each cluster receives a title generated
based on the top k frequent terms (Yang et al., 2000).
Furthermore, as performance is an issue in full text
analysis of a large document collection, we apply the
text analysis only to a part of each patent document
(e.g., the first part of the abstract, claims, or introduc-
tion). It has been proven that such an approach may
achieve better performance than using full texts (Fall
et al., 2003).
3.3 Ontologies
Selection of Existing Domain Ontologies. Our ap-
proach is heavily relying on the mappings to medical
ontologies and subsequently from medical ontologies
to the innovation field ontology. A plethora of medi-
cal ontologies exist. Hence, we have to analyze which
set of ontologies covers as many terms as possible,
describing the innovation fields.
We made a first analysis by searching for ontolo-
gies in the Bioportal
5
search engine using terms
describing innovation fields. The Bioportal search
engine is the most comfortable and comprehensive
search engine in the life science domain. In addi-
tion, it offers several useful tools, e.g., an ontology
recommendation tool based on keywords or full-texts.
Moreover, we used the Ontology Lookup Service
6
and the Ontobee
7
search engine to have a broad
overview. For the search, 174 terms from the six inno-
vation fields extracted from the reports (Schl
¨
otelburg
et al., 2008; Deutsche Gesellschaft f
¨
ur Biomed.
Technik im VDE, 2012) have been used. The
most promising four ontologies found were the Na-
tional Cancer Institute (NCIT) Thesaurus, the Sys-
tematized Nomenclature of Medicine - Clinical Terms
(SNOMEDCT), MeSH, and the Robert Hoehndorf
Version of MeSH (RHMeSH). For these we did a cov-
erage analysis presented in Figure 2. The coverage is
the percentage of the innovation field terms present in
each of the ontologies.
Note that no ontology really outperforms the oth-
ers and that the overall coverage is very low. Hence,
we decided to analyze the coverage by adding one
ontology after another, to see the gain of adding fur-
ther ontologies. We used the most promising ontolo-
5
http://bioportal.bioontology.org
6
http://www.ebi.ac.uk/ontology-lookup
7
http://www.ontobee.org
0
10
20
30
40
50
60
70
Imaging
Techniques
Prostheses &
Implants
Telemedicine Operative &
Interventional
Dev. and Sys.
In-Vitro
Diagnostics
Special
Therapies &
Diagnosis Sys.
Complete
NCIT SNOMEDCT MeSH RHMeSH
Figure 2: Coverage of search terms in selected ontologies.
0
10
20
30
40
50
60
70
Imaging
Techniques
Prostheses &
Implants
Telemedicine Operative &
Interventional
Dev. and Sys.
In-Vitro
Diagnostics
Special
Therapies &
Diagnosis Sys.
Complete
NCIT NCIT + MeSH NCIT + MeSH + SNOMEDCT NCIT + MSH + SNOMEDCT + RHMeSH
Figure 3: Coverage based on combination of ontologies.
Figure 4: The Bioportal Recommender Tool.
gies identified before and started with the NCI The-
saurus. Figure 3 shows the results. It can be noted,
that we gain about 10% coverage using all ontolo-
gies. The biggest gain is achieved after adding the
MeSH ontology. An analysis with the same terms us-
ing the Bioportal Recommender tool as depicted in
Figure 4 delivers a similar result. The Recommender
tool analyzes the annotations which can be found us-
ing the given terms. The coverage is calculated tak-
ing into account amongst others the mappings to and
synonyms from other ontologies, and the size of the
ontologies (Jonquet et al., 2010). Hence, it is not di-
rectly comparable to the manually created coverage
result described above. There are two recommended
ontology sets ranked highest: The first comprises the
NCIT, MeSH, and the Computer Retrieval of Infor-
mation on Scientific Projects (CRISP) and resulted in
a coverage of 83.6% and an overall result of 68.9%.
The second is congruent with our selection: NCIT,
MeSH, and SNOMEDCT and resulted in a coverage
KEOD 2015 - 7th International Conference on Knowledge Engineering and Ontology Development
392

of 84.6% and an overall score of 68.9%. Further-
more, all the ontologies have to be assessed accord-
ing to their quality. A detailed quality analysis will be
made using acknowledged quality criteria (Vrande
ˇ
ci
´
c,
2009; Gomez-Perez, 2004). We are still in the process
of finding a suitable tool, such as the Ontology Pit-
fall Scanner (OOPS!)
8
(Poveda-Villal
´
on et al., 2012),
which will assist us in this regard.
Requirements Analysis & Design of the Innovation
Field Ontology. To reach our goal to map publica-
tions and clusters to innovation fields, we also need
a new ontology which only represents the innova-
tion fields and important terms describing them. To
that end, we will make a detailed requirements anal-
ysis including interviews with domain experts, anal-
ysis of existing ontologies, and an intensive litera-
ture research. Where applicable, we will stick to the
NeOn methodology (Su
´
arez-Figueroa, 2010) and es-
pecially for the requirements analysis, the creation
of an Ontology Requirements Specification Docu-
ment (Su
´
arez-Figueroa et al., 2009) will be useful. In
a first step, we have already extracted a preliminary
selection of 174 terms (the same terms as for ontology
search), which corresponds to the scenario “Reusing
and reengineering non-ontological resources” of the
NeOn methodology. The terms can be used to make
a first draft of a preliminary ontology which is veri-
fied during an expert interview. The ontology design
will be accompanied by its evaluation using the crite-
ria and tools mentioned above.
3.4 Ontology Matching & Mappings
To identify which collaboration partner is working in
which innovation field, we have to integrate all the in-
formation we gathered so far. We need to map the
cluster terms and the publications, respectively, to the
domain ontologies. The mappings between the do-
main ontologies and the innovation field ontology can
be established during design time, because it is not
expected that they will change frequently. Ontology
matching systems (e.g., our tool GeRoMeSuite (Ken-
sche et al., 2007)) will be used to identify a first set
of mappings. Additionally, existing mappings created
by the BioPortal can be used to infer further mappings
to the innovation field ontology.
Bioportal also provides prepared mappings be-
tween ontologies. It creates the mappings either using
the LOOM algorithm, the Unified Medical Language
System (UMLS) concept unique identifiers (CUI),
and the Open Biological and using Biomedical On-
8
http://oops.linkeddata.es
tologies (OBO) xref properties
9
(Ghazvinian et al.,
2009). These mappings can be retrieved via a REST
API offered by the BioPortal website. Afterwards, a
domain expert verifies the detected mappings.
If necessary, the creation of mappings between
publication classifications and domain ontologies can
be prepared during design time. We will also use
the semi-automatic matching process described be-
fore. More challenging is the creation of mappings
between the clusters and the domain ontologies. This
has to be done during run time, as the cluster terms
are not known in advance. We plan to use also the
matching algorithms provided by GeRoMeSuite for
this step.
4 CONCLUSION
We have presented an innovative ontology-based
approach for recommending experts for research
projects in ME. We are making extensive use of ontol-
ogy engineering in our approach, e.g., analysis, cre-
ation, and matching of ontologies, defining require-
ments for ontologies, and evaluation of ontologies.
Also techniques from other areas, such as text min-
ing and patent analysis, are included in our approach.
Our current work focuses on the modeling of the on-
tologies and the selection of the clustering methods.
Performance is an issue for text clustering, as we want
to have an interactive system.
The work is still in an early stage and we have to
see how the integration of text clustering, topic mod-
eling, patent analysis, and ontology matching per-
forms. The various techniques are also challenging
tasks if they are considered separately, but the com-
bination of the techniques may show an innovative
method for exploring unknown research fields. Our
approach is not limited to the field of ME; however,
the availability of a huge number of ontologies in the
life sciences contributes to our approach.
ACKNOWLEDGEMENTS
This work has been supported by the Klaus Tschira
Stiftung gGmbH in the context of the mi-Mappa
project (http://www.dbis.rwth-aachen.de/mi-Mappa/,
project no. 00.263.2015). We would like to thank
our partners in the mi-Mappa project for their fruitful
ideas. We would further like to thank Tanja Schmelter
for her work on ontology analysis.
9
http://www.bioontology.org/wiki
An Ontology-based Collaboration Recommender System using Patents
393
REFERENCES
Aras, H., Hackl-Sommer, R., Schwantner, M., and Sofean,
M. (2014). Applications and challenges of text mining
with patents. In Proc. Intl. Workshop on Patent Mining
and its Applications. Stiftung Univ. Hildesheim.
Awasthi, A., Adetiloye, T., and Crainic, T. G. (2015). Col-
laboration partner selection for city logistics planning
under municipal freight regulations. Applied Mathe-
matical Modelling.
Balog, K. and De Rijke, M. (2007). Determining expert pro-
files (with an application to expert finding). In IJCAI,
volume 7, pages 2657–2662.
Bonino, D., Ciaramella, A., and Corno, F. (2010). Re-
view of the state-of-the-art in patent information and
forthcoming evolutions in intelligent patent informat-
ics. World Patent Information, 32(1):30–38.
Chen, Y.-L. and Hu, H.-L. (2006). An overlapping cluster
algorithm to provide non-exhaustive clustering. Eu-
rop. J. of Operational Research, 173(3):762–780.
Deutsche Gesellschaft f
¨
ur Biomed. Technik im VDE
(2012). Empfehlungen zur Verbesserung der In-
novationsrahmenbedingungen f
¨
ur Hochtechnologie-
Medizin. Technical report, VDE.
Fall, C. J., T
¨
orcsv
´
ari, A., Benzineb, K., and Karetka, G.
(2003). Automated categorization in the international
patent classification. In ACM SIGIR Forum, vol-
ume 37, pages 10–25. ACM.
Geum, Y., Lee, S., Yoon, B., and Park, Y. (2013). Identify-
ing and evaluating strategic partners for collaborative
r&d: Index-based approach using patents and publi-
cations. Technovation, 33(6):211–224.
Ghazvinian, A., Noy, N., and Musen, M. (2009). Creating
mappings for ontologies in biomedicine: simple meth-
ods work. In AMIA Ann. Symp. Proc., pages 198–202.
Gomez-Perez, A. (2004). Ontology evaluation. In Staab,
S. and Studer, R., editors, Handbook on Ontologies,
pages 250–273. Springer.
Gonc¸alves, C. A., Gonc¸alves, C. T., Camacho, R., and
Oliveira, E. C. (2010). The impact of pre-processing
on the classification of medline documents. In PRIS,
pages 53–61.
Jonquet, C., Musen, M. A., and Shah, N. H. (2010). Build-
ing a biomedical ontology recommender web service.
J. Biomedical Semantics, 1(S-1):S1.
Kensche, D., Quix, C., Li, X., and Li, Y. (2007). GeRoMe-
Suite: A system for holistic generic model manage-
ment. In Proc. VLDB, pages 1322–1325.
Mogee, M. E. and Kolar, R. G. (1999). Patent co-citation
analysis of eli lilly & co. patents. Expert Opinion on
Therapeutic Patents, 9(3):291–305.
Poveda-Villal
´
on, M., Su
´
arez-Figueroa, M. C., and G
´
omez-
P
´
erez, A. (2012). Validating ontologies with oops!
In Knowledge Engineering and Knowledge Manage-
ment, pages 267–281. Springer.
Rafiei, M. and Kardan, A. A. (2015). A novel method for
expert finding in online communities based on concept
map and pagerank. Human-centric Computing and
Information Sciences, 5(1):1–18.
Rani, S. K., Raju, K., and Kumari, V. V. (2015). Expert
finding system using latent effort ranking in academic
social networks. Intl. J. of Information Technology
and Computer Science, 2:21–27.
Robin, S. and Schubert, T. (2013). Cooperation with public
research institutions and success in innovation: Ev-
idence from france and germany. Research Policy,
42(1):149–166.
Schl
¨
otelburg, C., Weiß, C., Hahn, P., Becks, T., and
M
¨
uhlbacher, A. C. (2008). Identifizierung von Innova-
tionsh
¨
urden in der Medizintechnik. Technical report,
Bundesministeriums f
¨
ur Bildung und Forschung.
Su
´
arez-Figueroa, M. C. (2010). NeOn Methodology for
building ontology networks: specification, schedul-
ing and reuse. PhD thesis, Universidad Politecnica
de Madrid.
Su
´
arez-Figueroa, M. C., G
´
omez-P
´
erez, A., and Villaz
´
on-
Terrazas, B. (2009). How to write and use the on-
tology requirements specification document. In Proc.
OTM 2009, pages 966–982. Springer.
Trappey, A. J., Trappey, C. V., Hsu, F.-C., and Hsiao, D. W.
(2009). A fuzzy ontological knowledge document
clustering methodology. IEEE Trans. on Systems,
Man, and Cybernetics, Part B, 39(3):806–814.
Trappey, C. V., Trappey, A. J., and Wu, C.-Y. (2010). Clus-
tering patents using non-exhaustive overlaps. System
Science and System Engineering, 19(2):162–181.
Tseng, Y.-H., Lin, C.-J., and Lin, Y.-I. (2007). Text mining
techniques for patent analysis. Information Process-
ing & Management, 43(5):1216–1247.
Vrande
ˇ
ci
´
c, D. (2009). Ontology evaluation. In Staab, S. and
Studer, R., editors, Handbook on Ontologies, chap-
ter 13, pages 293–313. Springer.
Wang, G. A., Jiao, J., Abrahams, A. S., Fan, W., and Zhang,
Z. (2013). Expertrank: A topic-aware expert finding
algorithm for online knowledge communities. Deci-
sion Support Systems, 54(3):1442–1451.
Wanner, L., Baeza-Yates, R., Br
¨
ugmann, S., Codina, J., Di-
allo, B., Escorsa, E., Giereth, M., Kompatsiaris, Y.,
Papadopoulos, S., Pianta, E., et al. (2008). Towards
content-oriented patent document processing. World
Patent Information, 30(1):21–33.
Wu, C. and Barnes, D. (2011). A literature review of
decision-making models and approaches for partner
selection in agile supply chains. Purchasing and Sup-
ply Management, 17(4):256–274.
Yang, Y., Ault, T., Pierce, T., and Lattimer, C. W.
(2000). Improving text categorization methods for
event tracking. In Proc. of the 23rd Intl. Annual ACM
SIGIR Conf., pages 65–72. ACM.
Yimam-Seid, D. and Kobsa, A. (2003). Expert-finding sys-
tems for organizations: Problem and domain analysis
and the demoir approach. J. of Organizational Com-
puting and Electronic Commerce, 13(1):1–24.
Yoon, B. and Park, Y. (2004). A text-mining-based patent
network: Analytical tool for high-technology trend.
The Journal of High Technology Management Re-
search, 15(1):37–50.
Zhang, L., Li, L., and Li, T. (2015). Patent mining: A sur-
vey. ACM SIGKDD Expl. Newsletter, 16(2):1–19.
KEOD 2015 - 7th International Conference on Knowledge Engineering and Ontology Development
394
