
Comparison of Surveillance Strategies to Identify Undesirable Behaviour
in Multi-Agent Systems
Sarah Edenhofer
1
, Christopher Stifter
1
, Sven Tomforde
1
, Jan Kantert
2
,
Christian M
¨
uller-Schloer
2
and J
¨
org H
¨
ahner
1
1
Organic Computing Group, University of Augsburg, Augsburg, Germany
2
Institute of Systems Engineering, Leibniz University Hannover, Hannover, Germany
Keywords:
Multi-Agent Systems, Trust, Cooperation, Coordination, Self-organising Systems, Organic Computing.
Abstract:
Open, distributed systems face the challenge to maintain an appropriate operation performance even in the
presence of bad behaving or malicious agents. A promising mechanism to counter the resulting negative
impact of such agents is to establish technical trust. In this paper, we investigate strategies to improve the
efficiency of trust mechanisms regarding the isolation of undesired participants by means of reputation and
accusation techniques. We demonstrate the potential benefit of the developed techniques within simulations
of a Trusted Desktop Computing Grid.
1 INTRODUCTION
Open distributed systems are characterised by the
possibility to join and leave at any time. This entails
the problem that the participating elements (i.e. the
agents) are not under control of a centralised entity –
consequently, their behaviour has to be considered as
black-box. These black-boxes can contribute to the
overall system’s goal, but they can also disturb the ef-
ficient operation by means of unintentionally wrong
or even intentionally malicious behaviour.
A basic mechanism to counter the resulting neg-
ative impact of such disturbances is the utilisation of
technical trust. Establishing trust relationships among
distributed agents that model the reliability and trust-
worthiness of interaction partners allows for isolat-
ing untrusted agents, see (Stegh
¨
ofer and Reif, 2012).
In this paper, we investigate techniques to improve
the efficiency of isolation mechanisms on the basis
of technical trust. Therefore, we introduce and com-
pare two novel strategies for distributed surveillance:
a reputation-based and an accusation-based strategy.
Within simulations of our application scenario, we
demonstrate the potential benefit of these strategies
and highlight that the duration until an effective isola-
tion of malicious elements takes place can be reduced
significantly.
The remainder of this paper is structured as fol-
lows: In Section 2, we introduce our application sce-
nario – the Trusted Desktop Grid (TDG) – and define
agents categories and their goals. Section 3 presents
the novel strategies to isolate malicious agents us-
ing reputation and accusation techniques. Afterwards,
Section 4 evaluates the approach using simulations of
the TDG. Section 5 discusses the achieved results and
derives a statement of which technique should be used
in which cases, we present related work in Section 6.
Finally, Section 7 summarises the paper and gives an
outlook to future work.
2 TRUSTED DESKTOP GRID
We use an open, distributed Trusted Desktop
Grid (TDG) as application scenario to show and prove
the effective application of distributed algorithms as
well as Organic Computing (M
¨
uller-Schloer et al.,
2011) methods. In this scenario, we use an open and
heterogeneous Multi-Agent System (MAS) and we do
not assume benevolence. The agents in the system
cooperate to gain an advantage. The mechanism de-
termining this cooperation is Trust. Because of the
openness of the system, different agents may try to
exploit it. They may be uncooperative, malfunction-
ing or even malicious.
An agent, which acts on behalf of the user, is sub-
mitting jobs it wants to have calculated (Klejnowski,
132
Edenhofer, S., Stifter, C., Tomforde, S., Kantert, J., Müller-Schloer, C. and Hähner, J.
Comparison of Surveillance Strategies to Identify Undesirable Behaviour in Multi-Agent Systems.
DOI: 10.5220/0005679201320140
In Proceedings of the 8th International Conference on Agents and Artificial Intelligence (ICAART 2016) - Volume 1, pages 132-140
ISBN: 978-989-758-172-4
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2014). Each job is assumed to be composed of sev-
eral independently processable work units (WU). The
agents are expected to volunteer their machines as
workers for other agents’ WU as well as to share their
resources.
2.1 Agent Goal
The benefit of an agent can be measured by its
speedup σ, informally speaking its benefit of having
its work processed distributively over having to pro-
cess all work on its own (in accordance with (Kle-
jnowski, 2014)). A job J is a set of WUs, which is re-
leased in time step t
rel
J
and completed in t
compl
J
, when
the last WU is finished.
The speedup σ in Equation 1 is a metric known
from multi-core systems. It is based on the assump-
tion that parallelisation helps to process a task (i.e. a
job) faster than processing it on a single core. σ is
the ratio of the time the agent would have needed to
process all WUs on its own to the real time it took to
calculate J distributedly in the system. This is why
the speedup can only be determined after the last re-
sult has been returned to the submitter.
σ =
∑
J
(t
compl
sel f
−t
rel
sel f
)
∑
J
(t
compl
dist
−t
rel
dist
)
(1)
In short, we can write σ
:
=
t
sel f
t
dist
with t
sel f
being the
time it would require an agent to process all WUs of
a job without cooperation, i.e. sequentially. t
dist
is the
time it takes until all WUs are computed distributedly
and the last result is returned to the submitting agent.
If no cooperation partners can be found, agents need
to calculate their own WUs. This results in a speedup
value equal to one. In general, we assume that agents
behave selfishly and only cooperate if they can expect
an advantage, i.e. σ > 1.
2.2 Worker and Submitter Component
Each agent is free do decide which agent it wants
to give its WUs to and for which agents it wants to
work for. Therefore, every agent has a submitter and
a worker component.
The submitter component is the scheduler of the
agent and responsible for distributing WUs. If an
agent receives a job J from the user consisting of
multiple WUs, it creates a list of suited workers, i.e.
workers it trusts. It then asks workers from this list
to cooperate and calculate WUs, until either no more
WU or no more workers are left. If all workers were
asked and still unprocessed WUs remain, the agent
calculates them on its own.
The worker component decides whether an agent
wants to work for a certain submitter. When the agent
receives a request to process a WU, it calculates its
expected reward for accepting and rejecting the WU.
If the reward of accepting the WU prevails, the agent
takes the WU, puts it in its own working queue, where
the WU remains until the agent starts to process it, i.e.
until the other WU in the queue were processed. Af-
terwards, it transfers the result back to the submitter
where the result is validated (Klejnowski, 2014). A
job is completed, if all WUs were returned to the sub-
mitter.
2.3 Global Goal
The global goal—also referred to as the system
goal—is to enable and encourage agents to cooper-
ate and thereby achieve the best possible average σ.
The systems’ focus is coordination, i.e. shaping the
environment in a way that allows for cooperation and,
thereby, leads to optimising the global goal.
2.4 Agent Types
In the context of our TDG, such disturbances are, for
example, agents that return wrong results, or agents
that refuse to work for other agents while submitting
WU to them. Behaviour like this can lead to a lower
system-speedup. In the following, we discuss differ-
ent types of agents, each behaving differently.
Adaptive Agents are cooperative. They work for
other agents which have good reputation in the sys-
tem. If, for example, the WU-queue of this agent
is saturated to capacity, the agent may reject another
WU.
Altruistic Agents accept every job, regardless of the
circumstances and cooperation-partners.
Freeriders do not work for other agents and reject
all work requests. However, they ask other agents to
work for them. This increases the overall system load
and can decrease the benefit for well-behaving agents.
Egoists only pretend to work for other agents. They
accept most work requests but return fake results.
This wastes the time of other agents. If results have to
be validated, the average σ is decreased.
Sloppy Agents are cooperative but do only accept a
certain percentage of WU offered to them (Edenhofer
et al., 2015), expressed by the acceptance rate α.
2.5 Trust Metric
To overcome the problems of open, distributed MAS,
that we just described and to optimise the global goal,
we introduce a trust metric (Klejnowski et al., 2010),
Comparison of Surveillance Strategies to Identify Undesirable Behaviour in Multi-Agent Systems
133

justifying the name Trusted Desktop Grid. Agents get
ratings for their actions from their particular interac-
tion partners, representing the amount of trust earned
through this interaction.
An agent a has multiple ratings with values be-
tween −1 and 1 that it gets from other agents. The
amount of ratings k is limited to implement oblivion.
The global average of all ratings for one single agent
is called reputation. For further details see (Kantert
et al., 2015). These ratings allow to make estimations
about the future behaviour of an agent, based on its
previous actions. In our system, agents get a posi-
tive rating, if they work for other agents and a nega-
tive rating, if they reject or cancel work requests (Kle-
jnowski, 2014).
As a result, we can isolate malevolent agents and
minimise the negative impact of malicious agents (cf.
robustness in Section 2.3).
2.6 Trust Communities
To further increase the robustness and performance
of the system, we introduced an agent organisation
called Trust Community (TC). A TC consists of vari-
ous agents which greatly trust each other. The agents
are aware of their membership. A so-called Trusted
Community Manager (TCM) is elected by the agents.
It maintains the TC, preserves and optimises the com-
position and stability of the system. It is capable of
inviting members to the TC, excluding members from
the TC or assigning roles to the members for admin-
istrative reasons (for further details see (Klejnowski,
2014)). The election of the TCM can either depend
on the ID of the agent (the agent with the highest
or lowest ID is elected for TCM), or the reputation
(members with a high trust rating are more likely to
be elected as TCM).
The advantage of a TC organisation is that agents
can reduce security measures such as replication of
WU and are able to gain a better speedup. Members
of a TC can better resist attacks because they can al-
ways decide to just cooperate inside the community
and ignore the environment. Attacks within the TC
are managed by the TCM. It is capable of monitoring
a subset of the agents and, eventually, excludes them
in case of misbehaviour.
3 STRATEGIES
As described in Section 2.6, the TCM has the abil-
ity to monitor the TC members. Total surveillance is
neither desirable nor possible in an open, distributed
system with autonomous agents. Therefore, the TCM
Figure 1: The Round-Robin Strategy with step-width = 2
and S = 30 %, i.e. 3 of 9 agents are chosen (represented by
dark grey) and these agents are shifted by 2 each time step.
Figure 2: The Lottery-Based Strategy with S = 30 %. At
each timestep, 3 out of 9 agents are chosen (dark grey) as a
disjoint set to the agents chosen before (striped) until every
agent has been chosen once.
can only monitor a certain percentage of all TC mem-
bers at each time, expressed by the surveillance rate
S . It can use different surveillance strategies pre-
sented in this section to choose these S % of agents,
which we refer to as the chosen agents.
Accusation-based Strategy - An agent can be ac-
cused by another agent in case of an incident, for ex-
ample if it returns a fake result. The TCM is more
likely to observe an agent with more accusations than
an agent with less (or zero) accusations. For further
details see (Edenhofer et al., 2015).
Reputation-based Strategy - Here, an agent is more
likely to be monitored if its reputation is low in com-
parison to the other TC members’ reputation. This
concept can be realised by using, e.g. a roulette-wheel
approach that considers the available reputation val-
ues.
Random-based Strategy - The agents that are ob-
served are chosen randomly from all agents available
in each time step. Each agent has the same probability
to be selected.
Round-Robin-based Strategy - For this strategy, we
consider all TC-members as elements in a sorted list.
The chosen agents are the first S % elements in the
first time step. In the second time step, the chosen
agents are the next S % elements, shifted by step-
width. This is illustrated in Figure 1: the chosen
agents (dark grey) in t
1
are a
1
, a
2
and a
3
, in t
2
these
are a
3
, a
4
and a
5
, because the selection is shifted by
the step-width = 2.
Lottery-based Strategy - The agents that should be
observed are randomly chosen in each time frame but
ICAART 2016 - 8th International Conference on Agents and Artificial Intelligence
134

no repetition is allowed until all agents have been ob-
served. In Figure 2, we can see that in t
1
agents a
1
, a
4
and a
7
are selected (dark grey). In t
2
, these agents
cannot be chosen again (striped), a
2
, a
3
and a
9
are
chosen. In this example, the remaining three agents
a
5
, a
6
and a
8
would be the chosen ones in t
3
, in t
4
any
agent can be selected again.
The accusation-based and reputation-based strate-
gies use additional knowledge about the agents (i.e.
their previous incidents, respectively their reputation-
value). We call these strategies quality-based. In con-
trast to that, we call the other three strategies quantity-
based, since their success highly depends on the pa-
rameter assignment of S (cf. Section 4). It should fur-
ther be noted that the knowledge acquisition equals
computational costs.
4 EVALUATION
We evaluated the performance of the surveillance
strategies using two performance metrics: the number
of exclusions (from a TC) and the average residence
time. The residence time of an agent a (t
res
a
) is the time
the agent spends inside the TC (see Equation 2), from
joining the TC (t
join
) to being excluded (t
exclusion
).
t
res
a
= t
exclusion
−t
join
(2)
During our experiments, we iterated over the parame-
ters listed in Table 1.
Table 1: Parameter for the evaluation.
parameter abbreviation
incidents before exclusion ibe
forgiveness z
acceptance (rate) α
surveillance (rate) S
ibe determines the number of incidents one agent
can commit before being excluded from the TC. In
most cases we use a value of 2 for this, because this
“three strikes” approach is a compromise between
giving autonomous agents the chance to improve their
behaviour on the one hand and having a healthy TC
on the other hand. All incidents have a timeout (in
ticks) called forgiveness z. Our experiments compare
z = 250, 1000, 5000, 10000. Lower values do not re-
sult in a significant number of exclusions, because the
older incidents are forgiven too fast. Higher values
result in some sort of saturation and add no value to
the system – resulting in a decreased efficiency. The
acceptance rate α of the Sloppy Agents (SLA) ranges
from 50% to 90%, increased by 10. With lower val-
ues, the probability that an agent is invited into a TC
is too low. A value of 100% would equal the strategy
performed by Altruistic Agents (ALT).
As discussed in Section 3, we are interested in
rather low surveillance rates. Most comparisons are
using a S of 10% and 30%, though we will also have
a look at a low S of 2%, 5% and 8%. All simulations
lasted 200000 ticks with 100 agents each (30 SLA and
70 ALT). If an agent was excluded from a TC, it was
blacklisted for the remaining runtime and therefore
could not get excluded twice from the same TC. In
most upcoming sections we only allowed for one TC
during our experiments. Thereby we wanted to en-
sure a controlled environment. Nevertheless, we will
discuss some results with multiple TC in Section 4.3.
For the evaluation, we used the average of 40 runs
(respectively the average of 10 runs with multiple TC)
of one setup, as well as the standard-deviation.
In Section 4.1, we show the results for the
quantity-based strategies, the results for quality-based
strategies are introduced in Section 4.2, followed by
the results for multiple TC in Section 4.3.
4.1 Quantity-based Strategies
In this section, we compare the three quantity-based
strategies, i.e. random-based, round-robin-based, and
lottery-based, with each other. For the round-robin-
based strategy, we use a step-width of 2. Using differ-
ent step-widths does not yield a better performance.
The three strategies (cf. Figure 3) have pretty much
the same performance. Both the number of exclu-
sions and t
res
show the same trend and very sim-
ilar values. If S is increased to 30%, more agents
are excluded. Furthermore, t
res
is lower than with
S = 10% (with smaller standard deviation). The sim-
ilarity between the strategies exists with S = 10% as
well as with S = 30%. Given that these strategies per-
form that similar is due to their simplicity, we will
only use the random-based strategy for comparison
with the quality-based strategies in the following sec-
tions. Therefore, Figure 4 shows the performance of
the random-based strategy at different z levels. At
z = 250, there are nearly no exclusions and if there
are some, t
res
is pretty bad. The performance gets
better the higher z.
4.2 Quality-based Strategies
In this section, we show the evaluation of the
accusation-based and the reputation-based strategy.
Figures 6, 7 and 8 show the results for the reputation-
based strategy. Figure 6 shows the performance with
different values for z at different S levels: 10% in (a)
- (d) and 30% in (e) - (h). Similar to the random-based
Comparison of Surveillance Strategies to Identify Undesirable Behaviour in Multi-Agent Systems
135
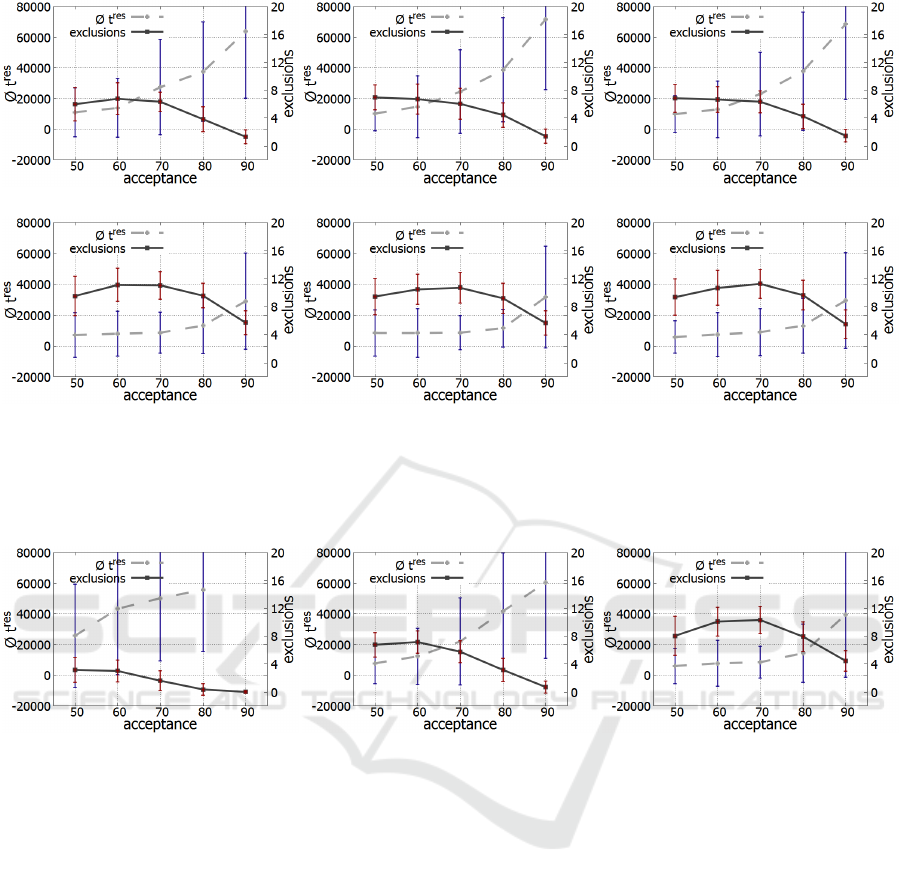
(a) Random-based with S = 10% (b) Round-robin-based with S = 10% (c) Lottery-based with S = 10%
(d) Random-based with S = 30% (e) Round-robin-based with S = 30% (f) Lottery-based with S = 30%
Figure 3: Comparison of the quantity-based strategies at z = 10000. From left to right: results of random-, round-robin-,
lottery-based strategy. The influence of S can be seen with S = 10% (top) and S = 30% (bottom). The x-axis shows the
acceptance rate α, the left y-axis and the dashed line show t
res
, the right y-axis and the thicker solid line show the number
of exclusions.
(a) Random-based, z = 250, S = 30. (b) Random-based, z = 1000, S = 30. (c) Random-based, z = 5000, S = 30.
Figure 4: Random-based strategy with S = 30, ibe = 2 and z = 250, 1000, 5000. The x-axis shows the acceptance rate α, the
left y-axis and the dashed line show t
res
, the right y-axis and the thicker solid line show the number of exclusions.
strategy the performance increases with increasing z.
Be aware that t
res
is not meaningful, if the number
of exclusions is almost zero (cf. for example with Fig-
ure 6 (a)). If z is further increased to 10000, the out-
come stagnates. Changing S from 10% to 30% does
not yield a huge improvement in performance. If we
lower S (cf. Figure 7), we eventually see a drop in
performance at S = 2. An increase of the ibe value
creates a lower outcome (cf. Figure 8).
For the accusation-based strategy we show the re-
sults for different values for z at S = 10. The strat-
egy shows very similar values to the reputation-based
strategy, while showing the same trends if varying the
parameters.
4.3 Evaluation With Multiple TC
During the above mentioned evaluations we only al-
lowed for one TC. In Figure 9, we show the results
of the accusation- and reputation-based strategy, if
multiple TC are allowed. The trends – with differ-
ent parameter assignments – already described remain
valid. If we compare the values of the accusation-
based strategy to those of the reputation-based one,
we can see that the results of the reputation-based
strategy are significantly better.
5 DISCUSSION
As mentioned in Section 4, our experiments iterated
over the parameters listed in Table 1. As we can see
ICAART 2016 - 8th International Conference on Agents and Artificial Intelligence
136
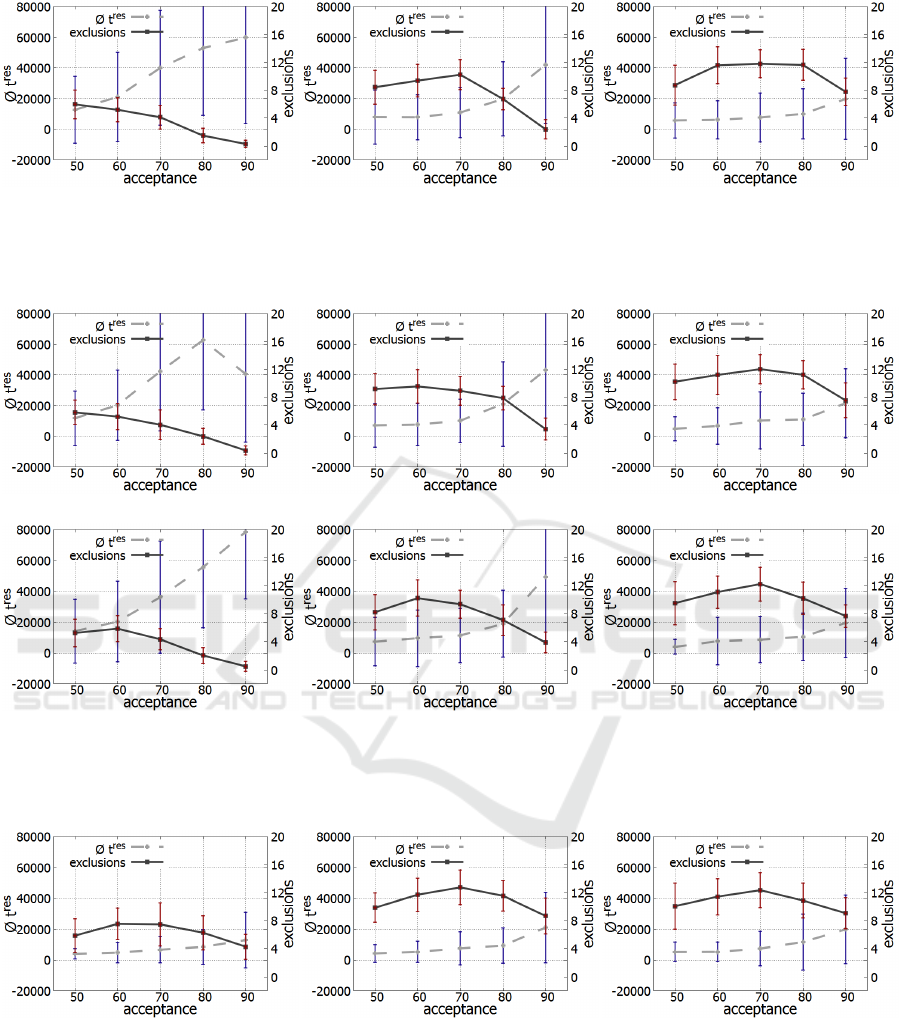
(a) Accusation-based with z = 250 (b) Accusation-based with z = 1000 (c) Accusation-based with z = 5000
Figure 5: Comparison of the accusation-based strategy’s performance with different values for z (left to right) at S = 10. The
x-axis shows the acceptance rate α, the left y-axis and the dashed line show t
res
, the right y-axis and the thicker solid line
show the number of exclusions.
(a) Rep.-based with z = 250, S = 10% (b) Rep.-based with z = 1000, S = 10% (c) Rep.-based with z = 5000, S = 10%
(d) Rep.-based with z = 250, S = 30% (e) Rep.-based with z = 1000, S = 30% (f) Rep.-based with z = 5000, S = 30%
Figure 6: Comparison of the reputation-based strategy’s performance with different values for z (left to right) at different S
levels: (a) - (d) 10%, (e) - (h) 30%. The x-axis shows the acceptance rate α, the left y-axis and the dashed line show t
res
,
the right y-axis and the thicker solid line show the number of exclusions.
(a) Reputation-based with S = 2% (b) Reputation-based with S = 5% (c) Reputation-based with S = 8%
Figure 7: Reputation-based strategy with z = 10000 at different S levels: 2%, 5%, 8% (left to right). The x-axis shows the
acceptance rate α, the left y-axis and the dashed line show t
res
, the right y-axis and the thicker solid line show the number
of exclusions.
in all figures, the performance of the strategies de-
pends on the value for α. An increasing α has two
major effects: First, the number of SLA in the TC
gets higher. This simply leads to more exclusions.
Second, the higher α, the less incidents. This means,
the time between two incidents of the same agent in-
creases. Eventually, this time is too long in relation
to the current z. Therefore, the older incidents are
Comparison of Surveillance Strategies to Identify Undesirable Behaviour in Multi-Agent Systems
137

(a) Rep.-based with ibe = 0 (b) Rep.-based with ibe = 1 (c) Rep.-based with ibe = 2 (d) Rep.-based with ibe = 3
Figure 8: Comparison of the reputation-based strategy’s performance with z = 5000, S = 10 and different ibe values: 0, 1, 2, 3
(left to right). The x-axis shows the acceptance rate α, the left y-axis and the dashed line show t
res
, the right y-axis and the
thicker solid line show the number of exclusions.
(a) Accusation-based, z = 250 (b) Accusation-based, z = 1000 (c) Accusation-based, z = 5000
(d) Reputation-based, z = 250 (e) Reputation-based z = 1000 (f) Reputation-based z = 5000
Figure 9: Comparison of the accusation-based ((a) - (c)) and the reputation-based strategy ((d) - (f)) with different values for
z (left to right: 250, 1000, 5000) at S = 10, if multiple TC are allowed. The x-axis shows the acceptance rate α, the left y-axis
and the dashed line show t
res
, the right y-axis and the thicker solid line show the number of exclusions.
already forgiven when the agent commits another vi-
olation. This second effect seems to dominate when-
ever the performance drops although α is increasing
(for example at around 70% in Figure 4 (c)).
In Figures 4, 5, 6, and 9, we compare the perfor-
mance for varying z. The results have in common
that at z = 250 the performance is pretty bad, but
progressively getting better with increasing z. This,
again, is due to z being too small: when the last in-
cident, which is necessary to exclude an agent, is ob-
served, the first incident is already forgiven. For the
same reasons the performance gets worse with higher
ibe (cf. Figure 8): the higher the value of ibe, the
longer z must be. In case of increasing z, the out-
come stagnates at around z ≈ 5000. A higher z has
no additional benefit, because all agents are already
excluded at lower z values.
Additionally, we showed the impact of different
S levels in Figures 3, 6, and especially 7. It is plau-
sible that the performance gets better with higher S ,
particularly resulting in a higher number of exclu-
sions. If S is too low, it takes too long to repeat-
edly observe every SLA and consequently, again, z
is too low. The outcome stagnates with increasing S ,
because there are no more agents to exclude. This
stagnation arises at different S for the quantity-based
and quality-based strategies. This is due to the way
these groups of strategies choose the agents they ob-
serve: the quantity-based strategies choose indepen-
dently from the agent’s identity. This means, the S %
agents are chosen from the total number of agents of
the TC. In contrast, if using a quality-based strategy,
the S % agents are primarily chosen from the SLA
subset of agents.
Comparing the accusation- with the reputation-
based strategy is especially interesting if we allow for
multiple TC (cf. Section 4.3 and Figure 9). While
the results are pretty similar if only one TC is al-
lowed (cf. Figures 5 and 6 (a) - (c)), we can see a
significant advantage of the reputation-based strategy
over the accusation-based one in regards to both the
number of exclusions and t
res
. This is particularly
ICAART 2016 - 8th International Conference on Agents and Artificial Intelligence
138

true for higher α. If multiple TC are allowed, an ex-
cluded agent cannot join the same TC again, but is
allowed to join any other (this is also the reason why
there are more exclusions, considering the changed
value range in Figure 9). To explain why reputation-
based performs better than accusation-based, we have
to consider the peculiarities of these two strategies.
Both use a form of history when judging which agents
should be observed: the accusation-based strategy
is more likely to observe agents which accumulated
more accusations in the past than agents that did not
do so. The reputation-based strategy is more likely to
observe agents with a low reputation (relative to the
other TC members). If an agent is excluded from a
TC, its accusations are reset: the TCM of the new TC,
where this agent becomes a member, does not know
about former accusations in other TC. In contrast to
that, when the TCM uses the reputation-based strat-
egy, there is already some information available for
the TCM in form of the agent’s reputation. Therefore,
from the moment the agent enters the new TC, it is
already more likely to be observed. Thus, the results
focussing on the number of exclusions as well as t
res
of the reputation-based strategy are superior to those
of the accusation-based strategy.
6 RELATED WORK
Our application scenario described in Section 2 is a
Desktop Grid System. We model our grid nodes as
agents, which can be seen as black boxes. Thereby,
we cannot observe the internal state. Thus, their ac-
tions and behaviour can only be predicted with un-
certainty (Hewitt, 1991). Our TDG supports Bag-of-
Tasks application (Anglano et al., 2006). A classifi-
cation and taxonomy of Desktop Grid Systems can be
found in (Choi et al., 2007), respectively (Choi et al.,
2008).
Desktop Grid Systems are used to share resources
between multiple administrative authorities. One ex-
ample for a peer-to-peer based system is the Share-
Grid Project (Anglano et al., 2008). A second ap-
proach is the Organic Grid, a peer-to-peer based
approach with decentralised scheduling (Chakravarti
et al., 2004). Compared to our system, these ap-
proaches assume benevolence (Wang and Vassileva,
2004), i.e. that there are no malicious agents partic-
ipating and misbehaving. Another approach is the
open source Berkeley Open Infrastructure for Net-
work Computing Project (BOINC) (Anderson and
Fedak, 2006) or XtremWeb (Fedak et al., 2001),
which aims at setting up a Global Computing ap-
plication and “harvest[ing] the idle time of Inter-
net connected computers which may be widely dis-
tributed across the world, to run a very large and
distributed application” with an ad-hoc verification
process for participating computers. We introduce a
trust metric (see Section 2.5) with a reputation sys-
tem to cope with the problem of misbehaving agents.
A panoramic view on computational trust in Multi
Agent Systems can be found in (Ramchurn et al.,
2004), (Castelfranchi and Falcone, 2010), or (Sabater
and Sierra, 2005). Sabotage-tolerance and distributed
trust management in Desktop Grid Systems was eval-
uated in (Domingues et al., 2007). Here, mechanisms
for sabotage detection are presented, but proposed for
a paradigm of volunteer-based computing. Trust is
also used in other disciplines such as philosophy (Kar-
lins and Abelson, 1959), psychology (Hume, 1739),
or sociology (Buskens, 1998).
7 CONCLUSION
In this paper, we presented several strategies to find
and exclude malicious or bad behaving agents from
open, distributed multi-agent systems. We have to
differentiate between quantity-based strategies (such
as the random-based, the round-robin-based, and the
Lottery-based strategy) and quality-based strategies
(like the accusation-based and the reputation-based
strategy). To show the advantages and disadvantages
of these strategies, we implemented them in our appli-
cation scenario, the Trusted Desktop Grid (TDG). In
several evaluations we showed the influence of the pa-
rameters acceptance rate (how many work units does
one agent accept?), surveillance rate (how much bud-
get do we have for surveillance, how many agents
can we observe within a certain period of time?), the
forgiveness (when will a former incident be forgot-
ten?), as well as the incidents before exclusion. We
found out that in most cases (especially at low surveil-
lance levels) the quality-based strategies perform bet-
ter than the quantity-based strategies. For future work
we plan to further improve the TDG and the surveil-
lance in multi-agent systems, e.g. by establishing a
dynamic surveillance. This means, the choice of the
current strategy used for surveillance will depend on
a dynamically changing surveillance budget to make
the system more realistic and life-like.
REFERENCES
Anderson, D. and Fedak, G. (2006). The Computational and
Storage Potential of Volunteer Computing. In Proc. of
CCGRID 2006, pages 73–80. IEEE.
Comparison of Surveillance Strategies to Identify Undesirable Behaviour in Multi-Agent Systems
139

Anglano, C., Brevik, J., Canonico, M., Nurmi, D., and Wol-
ski, R. (2006). Fault-aware Scheduling for Bag-of-
Tasks Applications on Desktop Grids. In Proc. of
GRID 2006, pages 56–63. IEEE.
Anglano, C., Canonico, M., Guazzone, M., Botta, M., Ra-
bellino, S., Arena, S., and Girardi, G. (2008). Peer-to-
Peer Desktop Grids in the Real World: The ShareGrid
Project. Proc. of CCGrid 2008, pages 609–614.
Buskens, V. (1998). The Social Structure of Trust. Social
Networks, 20(3):265 – 289.
Castelfranchi, C. and Falcone, R. (2010). Trust Theory:
A Socio-Cognitive and Computational Model, vol-
ume 18. John Wiley & Sons.
Chakravarti, A. J., Baumgartner, G., and Lauria, M. (2004).
Application-Specific Scheduling for the Organic Grid.
In Proc. of GRID 2004 Workshops, pages 146–155,
Washington, DC, USA. IEEE.
Choi, S., Buyya, R., Kim, H., and Byun, E. (2008). A
Taxonomy of Desktop Grids and its Mapping to State
of the Art Systems. Technical report, Grid Comput-
ing and Dist. Sys. Laboratory, The University of Mel-
bourne.
Choi, S., Kim, H., Byun, E., Baik, M., Kim, S., Park, C.,
and Hwang, C. (2007). Characterizing and Classifying
Desktop Grid. In Proc. of CCGRID 2007, pages 743–
748.
Domingues, P., Sousa, B., and Moura Silva, L. (2007).
Sabotage-Tolerance and Trustmanagement in Desktop
Grid Computing. In Future Gener. Comput. Syst. 23,
7, pages 904–912.
Edenhofer, S., Stifter, C., J
¨
anen, U., Kantert, J., Tomforde,
S., H
¨
ahner, J., and M
¨
uller-Schloer, C. (2015). An
Accusation-Based Strategy to Handle Undesirable Be-
haviour in Multi-Agent Systems. In 2015 IEEE Eighth
International Conference on Autonomic Computing
Workshops (ICACW).
Fedak, G., Germain, C., Neri, V., and Cappello, F. (2001).
Xtremweb: A Generic Global Computing System. In
Cluster Computing and the Grid, 2001. Proceedings.
First IEEE/ACM International Symposium on, pages
582–587.
Hewitt, C. (1991). Open Information Systems Semantics
for Distributed Artificial Intelligence. Artificial intel-
ligence, 47(1):79–106.
Hume, D. (1739). A Treatise of Human Nature. (Oxford
Clarendon Press.
Kantert, J., Edenhofer, S., Tomforde, S., and M
¨
uller-
Schloer, C. (2015). Representation of Trust and Repu-
tation in Self-Managed Computing Systems. In IEEE
13th International Conference on Dependable, Au-
tonomic and Secure Computing, DASC 2015, pages
1827–1834, Liverpool, UK. IEEE.
Karlins, M. and Abelson, H. (1959). Persuasion: How
Opinions and Attitudes are Changed. Springer Pub.
Co.
Klejnowski, L. (2014). Trusted Community : A Novel Mul-
tiagent Organisation for Open Distributed Systems.
PhD thesis, Leibniz Universit
¨
at Hannover.
Klejnowski, L., Bernard, Y., H
¨
ahner, J., and M
¨
uller-
Schloer, C. (2010). An Architecture for Trust-
Adaptive Agents. In Proc. of SASO Workshops, pages
178–183.
M
¨
uller-Schloer, C., Schmeck, H., and Ungerer, T. (2011).
Organic Computing - A Paradigm Shift for Complex
Systems. Springer.
Ramchurn, S. D., Huynh, D., and Jennings, N. R. (2004).
Trust in Multi-agent Systems. Knowl. Eng. Rev.,
19(1):1–25.
Sabater, J. and Sierra, C. (2005). Review on computational
trust and reputation models. Artificial Intelligence Re-
view, 24(1):33–60.
Stegh
¨
ofer, J.-P. and Reif, W. (2012). Die Guten, die B
¨
osen
und die Vertrauensw
¨
urdigen Vertrauen im Organic
Computing. Informatik-Spektrum, 35(2):119–131.
Wang, Y. and Vassileva, J. (2004). Trust-Based Community
Formation in Peer-to-Peer File Sharing Networks. In
Proc. on Web Intelligence, pages 341–348.
ICAART 2016 - 8th International Conference on Agents and Artificial Intelligence
140
