
A Smart Visual Information Tool for Situational Awareness
Marco Vernier
1
, Manuela Farinosi
2
and Gian Luca Foresti
1
1
Department of Mathematics and Computer Science, University of Udine, Udine, Italy
2
Department of Human Sciences, University of Udine, Udine, Italy
Keywords:
Twitter, Geo-data, Data-mining, Event Detection, Situation Awareness, Panoramic Image, Smart
Visualization.
Abstract:
In the last years, social media have grown in popularity with millions of users that everyday produce and share
online digital content. This practice reveals to be particularly useful in extra-ordinary context, such as during
a disaster, when the data posted by people can be integrated with traditional emergency management tools
and used for event detection and hyperlocal situational awareness. In this contribution, we present SVISAT,
an innovative visualization system for Twitter data mining, expressly conceived for signaling in real time a
given event through the uploading and sharing of visual information (i.e., photos). Using geodata, it allows
to display on a map the wide area where the event is happening, showing at the same time the most popular
hashtags adopted by people to spread the tweets and the most relevant images/photos which describe the event
itself.
1 INTRODUCTION
Social media, web 2.0 or web-enabled technologies
are built from the beginning to be socially used, ori-
ented around collaboration and sharing. These po-
tentialities are emphasized in extra-ordinary contexts,
when these tools provide a way for emergency man-
agement, allowing a real time information dissem-
ination to wider public, a better situational aware-
ness and an up-to-date picture of what is happening
on the ground during a crisis. New communication
technologies and, in particular, social media appli-
cations can enable people to more quickly share in-
formation and assist response and recovery, strength-
ening public resilience and potentially supporting the
work of Civic Protection, Red Cross, Fire Department
and other agencies (Foresti et al., 2015). Oftentimes,
citizens on the scene experience the event first-hand
and are able to provide updates more quickly than
disaster response organizations and traditional news
media (Procopio and Procopio, 2007), (Sweetser and
Metzgar, 2007), (Farinosi and Trere, 2014). This con-
tribution illustrates SVISAT, an innovative system for
Twitter data mining, expressly conceived for visualiz-
ing detected events in situational awareness applica-
tions (Martinel et al., 2015a). The paper is structured
as follows. In Section 1.2, we present the state-of-the-
art and the results emerged from previous research. In
Section 2, we illustrate the SVISAT system architec-
ture and explain in depth how the different modules
of the architecture work. In Section 3, we show first
experimental results emerged from the dataset and in
Section 4 we draw some conclusions.
1.1 Twitting the Emergency
In order to monitor the online conversation and con-
tent shared by users during a disaster and integrate
data sources for situational awareness, we decide to
focus on Twitter. This decision stems from many fac-
tors. First, given the instantaneous nature of commu-
nication on Twitter, the platform reveals to be particu-
larly suitable for real-time communications. Further-
more, the architecture and some specific features of
Twitter seem to facilitate widespread dissemination
of information. The conversations centered on a spe-
cific hashtag (#) promote focused discussions, even
among people who are not in direct contact with each
other. In addition, the choice to analyse Twitter is also
motivated by the prevailing public nature of the great
majority of the accounts (only a small percentage of
the accounts is private), a feature that distinguishes
this platform to other social networking sites (Bruns
and Burgess, 2013). On the one hand, this peculiarity
promotes public conversations, even among users that
were not previously in contact with each other. On the
other hand, it makes easier to conduct analysis that
aims to rebuild the spread of communication flows
238
Vernier, M., Farinosi, M. and Foresti, G.
A Smart Visual Information Tool for Situational Awareness.
DOI: 10.5220/0005680402360245
In Proceedings of the 11th Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2016) - Volume 3: VISAPP, pages 238-247
ISBN: 978-989-758-175-5
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reser ved

within the platform. Finally yet importantly, this char-
acteristic makes the use of the tweets for research pur-
poses less critical from an ethical point of view. The
analysis of the 2011 floods in Queensland conducted
by (Bruns et al., 2012) provides a detailed mapping of
the general dynamics of the Twitter use during emer-
gency and offers useful general indications. Their
findings highlight that the space-time variables rep-
resent a crucial element to obtain relevant data and
improve situational awareness during disasters. For
instance, the physical distance of the Twitter users
from the site of the catastrophe can reflect a differ-
ent type of needs to be met and a different perception
of danger. In addition, given that a social platform
like Twitter is structurally connected to forms of ac-
tivation just in time, the time variable plays a funda-
mental role. Previous research demonstrates that im-
mediately after the event there is a greater presence of
forms of instinctive response, while tweets contain-
ing links to official news sources tend to arrive later
(Hughes and Palen, 2009), (Latonero and Shklovski,
2010), (Sakaki et al., 2010), (Vieweg et al., 2010),
(Cameron et al., 2012). Moreover, it is worth to note
that the behaviour of Twitter users during emergen-
cies depends strongly on the type of phenomenon: for
instance, the grassroots reaction to a flood will not be
the same as the response to an earthquake. Moreover,
the geography of the area, along with the type of hu-
man settlement affected by the event can have a clear
impact on the number of tweets (the major clusters
for example are the most densely populated by people
connected to the network). One of the first attempt
to exploit Twitter data streams in order to track and
filtering information that is relevant for emergency
broadcasting services during incidents is represented
by Twitcident (Abel et al., 2012). Adopting seman-
tic filtering strategies, which includes tweet classifi-
cation, named entity recognition, and linkage to re-
lated external online resources, it monitors emergency
broadcasting services and automatically collects and
filters tweets whenever an incident occurs. Another
attempt to use real-time Twitter data for event detec-
tion is that proposed by (Sakaki et al., 2010), mainly
based on the application of Kalman filtering and par-
ticle filtering, widely used for location estimation in
pervasive computing. Their method aims to analyse
tweets for estimating the epicentre of earthquakes, ty-
phoon trajectories and traffic jams and to develop a
reporting system useful to notify people promptly of
a dangerous event. TEDAS (Li et al., 2012) aims to
detect a new event and identify its importance. It
extracts location data from tweets and classify and
rank tweets. SABESS (Klein et al., 2012), combin-
ing structural and content analysis approach, is able
to identify reliable tweets and detect emergencies.
Adopting scenario-based design methods and a geo-
visual analytics approach, Sense-Place2 uses tweets
and their geographic information to create place-time-
theme indexing schemes and create a systems for
geographically-grounded situational awareness.
Tweedr (Ashktorab et al., 2014) adopts a variety
of classification techniques (sLDA, SVM, and logistic
regression) in conjunction with conditional random
fields, in order to extract informative data and iden-
tify tweets which report damages. On the contrary
of the previous systems, SVISAT allows to detect
in real-time if a certain event is occurring and iden-
tify the geographical area and the trend hashtags used
to signal what is happening. Based on state-of-the-
art clustering algorithms, SVISAT aggregate tweets,
which refer to a given event. A real-time analysis
of the Twitter stream is performed and the results are
showed on a geographical map (e.g. Figure 1) which
allows knowing the hyperlocal situation to the emer-
gency operators. Moreover, to give them a more pre-
cise and accurate situational awareness of the event,
the system is able to show, through an innovative web
visualization user interface, the images attached on
each users post combined with a panoramic image of
the same area where the image has been taken. As re-
ported in (Johnston and Marrone, 2009), (Bruns et al.,
2012), (Gupta et al., 2013), during an emergency
event, users share on social platforms significant pho-
Figure 1: A map projection with the most popular hashtags
used by Twitter users during recent emergencies in Italy.
A Smart Visual Information Tool for Situational Awareness
239
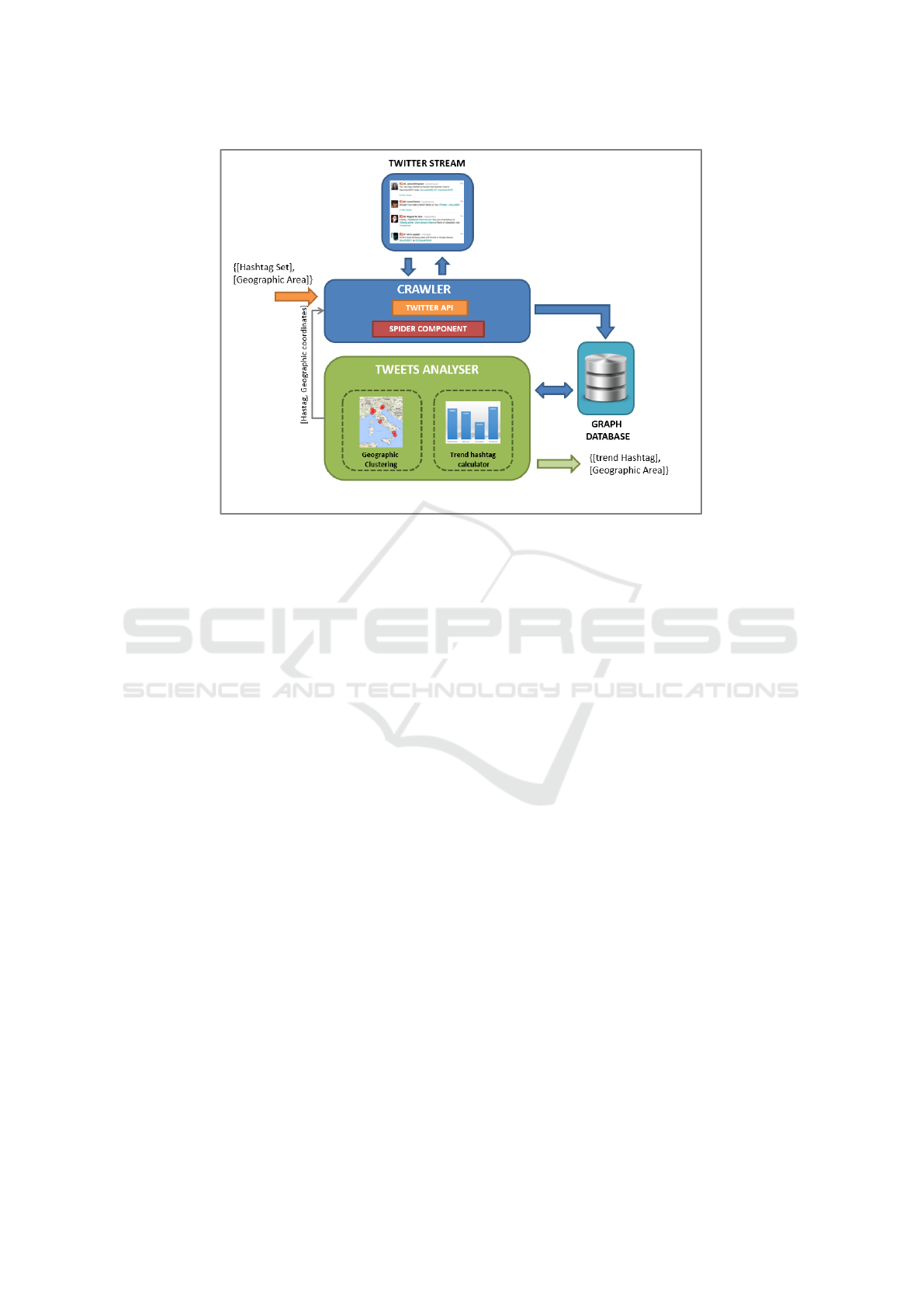
Figure 2: SVISAT system overview. The system is composed by the crawler module, the graph database and the tweets
analyser module.
tos regarding the event itself. For this purpose, a
data collecting module for image and GPS informa-
tions retrieval is proposed. It exploits the GPS coor-
dinates of the users posts to create a 360
◦
panoramic
view of the selected area extracting each single im-
age frame from the Google Street View servers. The
panoramic image is dynamically created using state-
of-the-art computer vision algorithms (Martinel et al.,
2014). As a result, the panoramic image and the post
image are displayed to the operators using an innova-
tive graphical user interface.
2 SVISAT SYSTEM
2.1 System Overview
SVISAT system (Figure 2) analyzes in real-time the
Twitter stream to detect and highlight a geographical
area where an event of interest is occurring. More-
over, the system is able to retrieve the trend hashtags
and the related tweets posted by the users to signal
the event. The system adopts a hierarchical structure
(level l
0...n
) and works as follows.
At the first level of the hierarchy, a defined ge-
ographical area A
1
and a set of K hashtags is input
by the system operators. These items can be decided
depending on the user needs and context. Then, to
perform the analysis, the next layers of the hierarchy
exploit three modules: (i) the crawler, (ii) a graph
database and (iii) the tweets analyser. The crawler
module is in charge of extract data from the Twit-
ter stream and save them to a graph database. Only
tweets containing at least one of the K hashtags are
saved. In early stage, all the geo-located tweets be-
longing to a time window of T sec are analysed.
Groups of tweets are created using state-of-art clus-
tering algorithms. If the total amount of tweets be-
longing to a certain cluster is higher than a thresh-
old depending on the area size, then, the analysis is
moved to the next level. The threshold is automat-
ically computed by the system on the basis of the
number of tweets and the number of persons living
in the observed area. Once a certain area oversees the
threshold, a trend hashtag identification is performed.
Then, the trend hashtag is used in the next level of the
hierarchy together with the previous K ones. By per-
forming such an action, we extract the most accurate
tweets. The system keeps on analyzing the localized
Twitter stream using the same criteria. By going down
in the hierarchy, the system is able to restrict, hence to
better identify, the geographic area from where tweets
of interest are coming. Once the last level of the hi-
erarchy is reached, the system has actually found the
area where the event of interest is occurring. As a fi-
nal stage, the system shows, on a map, the area where
the emergency event is occurring and the list of the as-
sociated trend hashtags and the related tweets. Such
information can be used to increase the reliability and
efficiency of the whole situational awareness service.
VISAPP 2016 - International Conference on Computer Vision Theory and Applications
240

2.2 The Crawler
The crawler is composed of a spider component,
which uses the unofficial Twitter4J
1
Java libraries to
retrieve streaming tweets from Twitter. It filters and
selects tweets considering as input the pre-defined set
of K hashtags. Only tweets containing at least one
of these hashtags are extracted and saved into a graph
database. Moreover, giving in input to the spider a
geographical area, the system is able to retrieve only
geo-located tweets posted by users.
Algorithm 1: Crawler algorithm example.
Data: k hashtags, GPS Coordinates
{{lon1,lat1},{lon2,lat2}}
Result: list of tweets
1 while !stop do
2 i) Extract all tweets from Twitter stream
containing at least one of the keywords
belonging to K set;
3 ii) Save retrieved tweets on the graph database;
4 end
2.2.1 Input Hashtag Selection
To perform the real-time tweets analysis and detect
the trend hashtags and the geographical area of a
given event of interest, the proposed system gets in in-
put a set of K hashtags considered as relevant for the
type of event of interest. All the geo-located tweets,
containing at least one of the keywords belonging to
the K set, are saved on the graph database and then
analysed from the tweets analyser component. Since
through the Twitter APIs is not possible to detect if
a word is or not a hashtag, we save the entire text
of the tweet into the graph database. Then, we ver-
ify if a certain word constitutes a hashtag. To create
the sets of K hashtags we used a modified version
of the proposed crawler to analyse off-line dataset
of tweets related to a specific emergency topics (e.g.
earthquakes, floods etc.). For this purpose, we used
the official Twitter APIs which allow to analyse ret-
rospective data giving as input significant user-input
keywords. The APIs returns all the retrieved tweets in
a JSON format including all the information related to
the tweets as the timestamp, the tweet id, the user id,
the geo-located information and so on. All retrieved
tweets are then saved on the graph database and anal-
ysed in order to search the most relevant hashtags.
To achieve this goal we compute the histogram of the
most used hashtags shared in each post and we con-
sidered the three most adopted keywords by the Twit-
1
http://twitter4j.org/en/index.html.
ter users as the most significant for the event of inter-
est.
2.2.2 Geo-located Tweets Selection
The crawler software is able to automatically retrieve
geo-located tweets posted by users. Thanks to the fea-
tures provided by the Twitter APIs in use, the collec-
tion of geo-located tweets can be achieved giving in
input two GPS coordinates of latitude and longitude
lon1, lat1, lon2, lat2. As a result, a bounding box is
created and the geo-located tweets belonging to the
bounding box, are extracted and saved by the crawler
into the graph database.
2.3 The Graph Database
The crawler module analyses all the tweets retrieved.
However, the amount of data might be unmanageable
to be analyzed in real time if a volatile memory is
used. So, to allow a real-time analysis of the data and
avoid the consuming of a large amount of memory, we
save the data on a graph database. A graph database
is more flexible than the relational ones, hence it al-
lows a better data management and analysis. More-
over, to perform a better trend hashtags analysis, the
system requires an off-line analysis of the tweets. For
this purpose, we used a Neo4J
2
graph database. It
is highly scalable and robust graph database mainly
adopted to address possible memory limitations of the
system. The graph data model allows finding inter-
connected data much faster and in a much more scal-
able manner as compared to the relational data model.
2.4 The Tweets Analyser Module
The tweets analyser module considers all the data ex-
tracted and saved by the crawler module on the Neo4j
graph database.
Algorithm 2: Tweets analyser algorithm example.
Data: Tweets from graph database
Result: geographical area, trend hashtags, list of
tweets
1 while time t < T minutes && n < 0 do
2 i) get tweets from graph database;
3 ii) create cluster of geo-located tweets;
4 if totaltweets > λ then
5 i) get new geo-coordinates;
6 ii) search trend hashtag;
7 end
8 end
2
http://neo4j.com/.
A Smart Visual Information Tool for Situational Awareness
241

It analyses the tweet stream acquired in a temporal
window of T minutes. The analysis is carried out to
identify the area from which most of the tweets are
posted, as well as, the relative trend hashtag. This
analysis is performed by the Tweets clustering and the
Trend hashtag sub-modules.
2.4.1 Tweets Clustering
The goal of tweets clustering is to detect in real-time
the geographical area where a given event of inter-
est is occurring and to obtain relevant grassroots data
for the emergency management. For this purpose, we
take into account those tweets that contain data re-
garding the location of the users. As previously ex-
plained, the tweets research and analysis is organized
into a hierarchical structure. We start from a given
geographical area A
1
and go down to the hierarchy in
order to obtain accurate information regarding a cer-
tain event. For what concerns the first level of anal-
ysis (wide geographical areas), we include into the
dataset also tweets no-georeferred but which contain
in the text the name of a location preceded by a hash-
tag (i.e., #Udine). To reach this goal, we used gisg-
raphy
3
geocoder webservices to match the GPS coor-
dinates of a given locations. To perform the subdivi-
sion in regions of a given geographical area, among
all the available clustering systems ranging from neu-
ral learning-based ones (Martinel et al., 2015c) to de-
cision forests (Martinel et al., 2015b) and Support
Vector Machines (Garcia et al., 2014), we used the
k-means algorithm (Moore, 2001). It is a quantiza-
tion vector method often used for cluster analysis in
data mining. Considering as input r observations it
allows to create k clusters. The result is a partitioning
of a space into regions based on the closeness of input
points (Voronoi diagram). The k number of clusters
is related to the dimension of the geographic area in
which the analysis is performed and decreases until
the last hierarchical level of the system is reached.
The geo-located information is exploited to clus-
ter tweets. Let x
p
= [lat, lon]
T
be the p-th tweet repre-
sented by latitude and longitude GPS coordinates. Let
A
(t)
i
be the i-th cluster at iteration t. Given an initial
set of k means m
(t)
1
, . . . , m
(t)
k
, each of which is a 2D
vector of GPS coordinates. The algorithm proceeds
by alternating between two steps:
i) Assignment Step - Assign each observation to
the cluster whose mean yields the least within-area
sum of squares (WASS). Since the sum of squares in
our case is the squared Geographical distance (GD),
this is intuitively the “nearest” mean,
3
http://www.gisgraphy.com
A
(t)
i
= {x
p
: kx
p
−m
(t)
i
k
2
≤ kx
p
−m
(t)
j
k
2
∀ j, 1 ≤ j ≤ k}
(1)
where each x
p
is assigned to exactly one A
i
even
if it could be assigned to two or more of them.
ii) Update step - Calculate the new means to be
the centroids of the observations in the new clusters.
This is done as:
m
(t+1)
i
=
1
|A
(t)
i
|
∑
x
j
∈A
(t)
i
x
j
(2)
Since the arithmetic mean is a least-squares es-
timator, this also minimizes the within-area sum of
squares (WASS) objective. The algorithm converges
when the assignments no longer change. Since both
steps optimize the WASS objective, and there only ex-
ists a finite number of such partitioning, the algorithm
must converge to a (local) optimum.
Now, while the clustering proceeds, we have to de-
termine when to move down to the next level of the hi-
erarchy. To do this, we first let N(A
(t)
i
) be the number
of tweets posted from area A
(t)
i
at time t and D(A
(t)
i
)
the number of persons in it. If the amount of tweets
posted from a particular area is higher than a fixed
threshold λ, then, the system performs a trend hashtag
identification using the tweets posted only from such
area. λ has been selected through cross-validation. In
such a case lambda values with a step of 0.05 have
been drawn from the [0, 1] range. However, the num-
ber of tweets posted from a particular area heavily de-
pends on the number of persons in it. To overcome
this issue, we rescale the number of tweets as:
N(A
(t)
i
)
D(A
(t)
i
)
(3)
before applying the threshold.
Once the area is detected, the next step tries to fo-
calize and move the research on it in order to retrieve
more accurate tweets related to the event of interest.
To achieve this, the trend hashtags identification pro-
cedure is proposed.
2.4.2 Trend Hashtag Identification
All the hashtags posted from the area identified by the
tweets clustering sub-module are used to compute a
histogram. The R most frequent hashtags are consid-
ered as the trend hashtags. We select the R hashtags
such that they form a disjoint set with the original K
ones. The just retrieved R set of hashtags is then used
as an input to the crawler software to optimize the re-
search. As a result we collect more accurate tweets
which contain at least one of the new hashtags con-
tained in R. This process continues until the last hier-
archical level of the system is reached.
VISAPP 2016 - International Conference on Computer Vision Theory and Applications
242

Figure 3: The graphical interface of the proposed web tool application to display the post image retrieved from Twitter and
the panoramic image created using Google Street View Images.
2.5 SVISAT Web Visualization Tool
Interface
As presented in the previous sections, the proposed
application is able to discover the geographical area
where a given event is occurring. To reach this goal,
the geo-located tweets and their hashtags are anal-
ysed. Nevertheless, to give the emergency operators
a more accurate situational awareness of the event in
progress, an innovative interface for web visualization
is proposed (Figure 3). It aims to visualize in real-
time all the images related to a given event posted by
the user on Twitter. Moreover, to give the operators a
more accurate view of the interested area, the posted
images are combined in a 360
◦
panoramic image view
of the specific location.
To implement all the proposed features, this tool
has been subdivided in two main modules: the Data
Collecting module and the Panoramic Building mod-
ule (Figure 4).
2.5.1 Data Collecting Module
The Data Collecting Module is in charge of the re-
trieval the images linked to each post shared by users
on Twitter. Considering that the images have been al-
ready previously stored on the graph database by the
crawler module, to perform this operation a simple
raw database request is applied. Moreover, the mod-
Figure 4: An overview of the SVISAT system architecture.
ule is in charge also to retrieve the GPS coordinates
included on each post, which are then exploited by the
following Panoramic Image Builder module to create
the 360
◦
panoramic image view of the given location
of interest.
2.5.2 Panoramic Building Module
The Panoramic Building module is in charge first to
extract a set of frame images from Google Street View
servers and then to create the 360
◦
panoramic image
view of the given location. To perform this task, the
module exploits the GPS coordinates of the location
that are directly provided by the Data Collecting Mod-
ule. Next, to retrieve each single image from Google
A Smart Visual Information Tool for Situational Awareness
243

https://maps.googleapis.com/maps/api/stre-
etview?size=640x640&location=46.414382,10
.013988&heading=151.78&pitch=-0.76
Figure 5: An example of HTTP GET request to Google
Street View servers.
Server, the Google Street View Image APIs are used
which allow retrieving a single frame image through a
simple HTTP GET request (see the example in Figure
5).
The HTTP GET request needs in input different
parameters that can be used to setup the quality of the
images to retrieve. For example, the size, the pitch,
the zoom, as well as the latitude and the longitude
coordinates are the main parameters that can be reg-
ulated to retrieve the street view images of the given
location. Moreover, the heading is the parameter that
allows moving the camera on the left or right direction
along the vertical-axis. In this way, by moving the
camera of 40 degrees to the right (or to the left), it is
possible to retrieve nine images (Figure 6). The pair-
wise images are overlapped of about 40% thus allow-
ing the stitching operations to create the panoramic
image view. In figure 6 the nine images of a specific
location in Genoa (Italy) retrieved from Google Street
View Server are displayed as a running example.
Figure 6: Nine images of a specific location in Genoa (Italy)
retrieved from Google Street View Server.
To create the panoramic image view, the first step
consists in detecting robust image features that can be
used for alignment purposes. For this scope, as sug-
gested in (Martinel et al., 2013), SURF features (Bay
et al., 2008) have been adopted. Next, the features
matching between two different images is performed
by RANSAC. A small subset of the matching fea-
tures is randomly chosen as in (Martinel and Mich-
eloni, 2014), then the corresponding homography is
computed and the projection error on the remaining
features is measured. Finally, the process is iterated
several times and the homography with the minimum
error is chosen to create the final panoramic image.
3 EXPERIMENTAL RESULTS
3.1 Evaluation Protocol
In order to test our system, we have used as run-
ning example some floods occurred in Italy. To cor-
rectly identify the type of event we used as input
to our system a set of primary hashtags opportunely
selected and considered as representative for floods.
Our set was composed by K = 3 hashtags, namely
#emergenza, #allertameteo and #maltempo (in En-
glish #emergency, #weatheralert, #badweather). The
K set of hashtags has been retrieved by considering
the analysis performed on a dataset of about 300.000
tweets posted by users during past flood events (i.e.,
the flood occurred in Sardigna on the 8th November
2013 and in Genoa on 4th November 2011). This
analysis has been conducted using the algorithm pro-
posed in 2.2.1 and the histogram has been computed
(Figure 7).
Assuming the Italian country as the A
1
input ge-
ographical area we set the k clustering parameter to
8. This value has been calculated considering the to-
tal geographical area of Italian country in relation to
the dimension of the Italian regions. Considering the
total population of Liguria, the threshold λ has been
set to 0.2. This value has been selected through cross-
validation. The number of persons present in a par-
ticular area has been retrieved from the ISTAT dataset
on the Italian population. T has been set to 900s: con-
sidering that a flood event is different from other kind
of catastrophic events, such as earthquakes, which are
characterized by an expected and sudden shock, we
assume a time window T of 900s as sufficient to test
our system. The algorithm has been tested on a Linux
Desktop PC equipped with an Intel I7 processor and
8GB Ram installed.
Figure 7: Input hashtags selection. The most popular hash-
tags adopted by the Twitter users during previous floods
events in Italy are computed to individuate the K set of input
hashtags.
VISAPP 2016 - International Conference on Computer Vision Theory and Applications
244

3.2 Dataset
In order to test our system we do not analyse event
in real-time, but we use data collected from Twit-
ter during the time of 2014 floods in Genoa. More
precisely, between the 9th and 10th of October, over
about 700.000 tweets have been retrieved from Italy.
These have been used to evaluate our system. About
21% of them was referring to the flood disaster in
Genoa while 7% of them include geo-located infor-
mation.
3.3 Test on Real Data
Considering the level l
0
of our hierarchical structure,
in a first stage, we activated our system to collect and
analyse tweets data from 12.00 a.m. of 9th October
2014. We subdivided the temporal time in windows
[t
1
− t
x
] of 900s. At that time the situation was quite
calm and there weren’t events worthy of special at-
tention. Around 10:00 p.m. - and respectively at the
window time t
39
- the system detects a quantitative
increase of tweets which moves the attention to a spe-
cific geographical area - Liguria (level l
1
). From a
content analysis of these tweets emerged that the most
popular hashtag adopted by users was #Liguria. Carry
on with the analysis, the system automatically moved
the research in that geographical area adding to the K
keywords set the new hashtags just retrieved. Respec-
tively at time window t
44
(23.30pm) of the level l
1
the
system detected another increasing of tweets from the
area of Genoa and province (level l
2
). Once again the
trend hashtags resulted to be #allertameteoLIG. As a
result, the system moved the research into the selected
area and in the second moment to the city of Genoa
(level 3). At this level, the hashtags evaluation gave
as a result a new trend hashtag #Genoa respectively at
t
49
and t
50
. At level l
3
the hashtags analysis on the t
52
and t
53
returned the keyword #bisagno.
As the chart figure 9 shown, the number of geo-
located tweets decreases until the system goes down
Figure 8: A map showing the different hierarchy levels of
the SVISAT system.
to the lowest level of the system hierarchy. It is worth
nothing to observe how the most retrieved hashtags
refer to the name of geo-located places (region, cities
and so on). Nevertheless other hashtags as #pro-
tezionecivile, #emergenza etc. are often adopted to
signal the flood event analysed.
Figure 9: The three most popular hashtags calculated for
each level of the SVISAT system.
4 CONCLUSIONS
The first tests of SVISAT system are very promising.
The content produced by common users of the Twit-
ter social platform represents a useful source of infor-
mation in extra-ordinary context and potentially can
be a precious resource for emergency management
operators. Tweets, especially those geo-referred, are
in fact a valuable tool for event detection and situa-
tional awareness. The findings show that trend hash-
tags represent geographical references in the early
levels, while become more descriptive in the other
levels. This kind of systems can be applied not only
to emergency management but also to more general
topics and analysis focused on detecting some hyper-
local perceptions shared by people on Twitter plat-
form (see, for example, political trends, brand repu-
tation, sentiment analysis and so on). At the moment
the major limitation of the system is that Twitter al-
lows to do only 150 queries per hour. Another lim-
itation is that only a small number of Twitter users,
both in ordinary and extra-ordinary situations, de-
cide to make visible their localization and share geo-
located information. This practice limits the possi-
bility to create a more robust and quantitative rele-
vant dataset and so to obtain more data useful to de-
tect a certain emergency event. Another relevant is-
sue is that, even social media plays a vital role during
real world events, they can be adopted also by ma-
licious people to spread rumours and fake news. In
the case of Hurricane Sandy, for example, there were
more than 10,000 unique tweets containing fake im-
ages about the disaster and the 86% of them were
A Smart Visual Information Tool for Situational Awareness
245

retweets (Gupta et al., 2013). To develop a more
robust system, it is therefore pivotal to implement a
module for the automatic real-time picture recogni-
tion (e.g., (Martinel and Foresti, 2012; Martinel et al.,
2015d; Martinel et al., 2015e)) on Twitter. In this way,
the outputs of the system will be more trustworthy
and useful in providing reliable information about the
event.
REFERENCES
Abel, F., Hauff, C., Houben, G.-j., Tao, K., and Stronkman,
R. (2012). Semantics + Filtering + Search = Twit-
cident Exploring Information in Social Web Streams
Categories and Subject Descriptors. In 23rd ACM
Conference on Hypertext and Social Media, HT’12,
pages 285–294.
Ashktorab, Z., Brown, C., and Culotta, A. (2014). Tweedr:
Mining Twitter to Inform Disaster Response. In S.R.
Hiltz, M.S. Pfaff, L. Plotnick, and P.C. Shih, edi-
tor, Proceedings of the 11th International ISCRAM
Conference, number May, pages 354–358, University
Park, Pennsylvania, USA.
Bay, H., Ess, A., Tuytelaars, T., and Van Gool, L. (2008).
Speeded-Up Robust Features (SURF). Computer Vi-
sion and Image Understanding, 110(3):346–359.
Bruns, A. and Burgess, J. (2013). Crisis Communication
in Natural Disasters: The Queensland Floods and
Christchurch Earthquakes.
Bruns, A., Burgess, J., Crawford, K., and Shaw, F. (2012). #
qldfloods and @ QPSMedia : Crisis Communication
on Twitter in the 2011 South East Queensland Floods.
Number Cci. ARC Centre of Excellence for Creative
Industries and Innovation, Brisbane.
Cameron, M. a., Power, R., Robinson, B., and Yin, J.
(2012). Emergency situation awareness from twitter
for crisis management. Proceedings of the 21st inter-
national conference companion on World Wide Web -
WWW ’12 Companion, page 695.
Farinosi, M. and Trere, E. (2014). Challenging main-
stream media, documenting real life and sharing with
the community: An analysis of the motivations for
producing citizen journalism in a post-disaster city.
Global Media and Communication, 10(1):73–92.
Foresti, G., Farinosi, M., and Vernier, M. (2015). Situa-
tional awareness in smart environments: socio-mobile
and sensor data fusion for emergency response to dis-
asters. Journal of Ambient Intelligence and Human-
ized Computing, 6(2):239–257.
Garcia, J., Martinel, N., Foresti, G. L., Gardel, A., and
Micheloni, C. (2014). Person Orientation and Fea-
ture Distances Boost Re-identification. In Inter-
national Conference on Pattern Recognition, pages
4618–4623. IEEE.
Gupta, A., Lamba, H., Kumaraguru, P., and Joshi, A.
(2013). Faking Sandy: characterizing and identify-
ing fake images on Twitter during Hurricane Sandy.
Proceedings of the 22nd International Conference on
World Wide Web, pages 729–736.
Hughes, A. and Palen, L. (2009). Twitter adoption and
use in mass convergence and emergency events. In-
ternational Journal of Emergency Management, 6(3-
4):248–260.
Johnston, L. and Marrone, M. (2009). Twitter user becomes
star in US Airways crash, in New York Daily News.
Klein, B., Laiseca, X., Casado-Mansilla, D., L
´
opez-De-
Ipi
˜
na, D., and Nespral, A. P. (2012). Detection
and extracting of emergency knowledge from twitter
streams. In Lecture Notes in Computer Science (in-
cluding subseries Lecture Notes in Artificial Intelli-
gence and Lecture Notes in Bioinformatics), volume
7656 LNCS, pages 462–469.
Latonero, M. and Shklovski, I. (2010). ”Respectfully Yours
in Safety and Service”: Emergency Management &
Social Media Evangelism. In Proceedings of the
7th International ISCRAM Conference, number May,
pages 1–10.
Li, R., Lei, K. H., Khadiwala, R., and Chang, K. C. C.
(2012). TEDAS: A twitter-based event detection and
analysis system. In Proceedings - International Con-
ference on Data Engineering, pages 1273–1276.
Martinel, N., Avola, D., Piciarelli, C., Micheloni, C.,
Vernier, M., Cinque, L., and Foresti, G. L. (2015a).
Selection of Temporal Features for Event Detection in
Smart Security. In International Conference on Image
Analysis and Processing, pages 609–619.
Martinel, N., Das, A., Micheloni, C., and Roy-Chowdhury,
A. K. (2015b). Re-Identification in the Function Space
of Feature Warps. IEEE Transactions on Pattern Anal-
ysis and Machine Intelligence, 37(8):1656–1669.
Martinel, N. and Foresti, G. L. (2012). Multi-signature
based person re-identification. Electronics Letters,
48(13):765.
Martinel, N. and Micheloni, C. (2014). Sparse Matching
of Random Patches for Person Re-Identification. In
International Conference on Distributed Smart Cam-
eras, pages 1–6.
Martinel, N., Micheloni, C., and Foresti, G. L. (2013). Ro-
bust Painting Recognition and Registration for Mobile
Augmented Reality. IEEE Signal Processing Letters,
20(11):1022–1025.
Martinel, N., Micheloni, C., and Foresti, G. L. (2015c).
Evolution of Neural Learning Systems. System Man
and Cybernetics Magazine, pages 1–6.
Martinel, N., Micheloni, C., and Foresti, G. L.
(2015d). Saliency Weighted Features for Person Re-
identification. In European Conference Computer Vi-
sion Workshops and Demonstrations, pages 191–208.
Martinel, N., Micheloni, C., Piciarelli, C., and Foresti,
G. L. (2014). Camera Selection for Adaptive Human-
Computer Interface. IEEE Transactions on Systems,
Man, and Cybernetics: Systems, 44(5):653–664.
Martinel, N., Piciarelli, C., Micheloni, C., and Foresti, G. L.
(2015e). A Structured Committee for Food Recogni-
tion. In International Conference on Computer Vision
Workshops.
VISAPP 2016 - International Conference on Computer Vision Theory and Applications
246

Moore, a. (2001). K-means and Hierarchical Clustering.
Statistical Data Mining Tutorials, pages 1–24.
Procopio, C. H. and Procopio, S. T. (2007). Do You Know
What It Means to Miss New Orleans? Internet Com-
munication, Geographic Community, and Social Cap-
ital in Crisis.
Sakaki, T., Okazaki, M., and Matsuo, Y. (2010). Earthquake
shakes Twitter users: real-time event detection by so-
cial sensors. In WWW ’10: Proceedings of the 19th in-
ternational conference on World wide web, page 851.
Sweetser, K. D. and Metzgar, E. (2007). Communicating
during crisis: Use of blogs as a relationship manage-
ment tool. Public Relations Review, 33(3):340–342.
Vieweg, S., Hughes, A. L., Starbird, K., and Palen, L.
(2010). Microblogging during two natural hazards
events: what twitter may contribute to situational
awareness. In CHI 2010: Crisis Informatics April
1015, 2010, Atlanta, GA, USA, pages 1079–1088.
A Smart Visual Information Tool for Situational Awareness
247
