
AMBIT-SE: Towards a User-aware Semantic Enterprise Search Engine
Giacomo Cabri, Stefano Gaddi and Riccardo Martoglia
University of Modena and Reggio Emilia, Modena, Italy
Keywords:
User-awareness, Enterprise Search Engine, Information Retrieval, Text Analysis, Semantic Knowledge and
Similarity.
Abstract:
Search engines represent one of the most exploited tools both in our everyday life and in our work. In this
paper we propose a user-aware semantic enterprise search engine called AMBIT-SE. It is “enterprise” in the
sense that it is focused on the search in enterprise websites; the “semantic” aspect is related to the fact that
it exploits not an exact word match, but relies also on the meaning of the words by means of synonyms and
related terms; finally, to produce query results it takes into account also the user information, which turns out to
be very useful to improve the search. We explain how our system works and report the results of experiments
on different websites.
1 INTRODUCTION
In today’s enterprises the need for providing appropri-
ate means to search for specific information in inter-
nal and public repositories is more and more increas-
ing. This goal is twofold: from the one hand, enabling
employees to find the needed information in a short
time is not only useful to reduce the global time need
to carry out a task, but also to decrease the frustration
of long searches; on the other hand, precise and rel-
evant answers to customers that exploit the company
web sites for both searching for information and in-
teracting with the company can grant a high degree of
customer satisfaction.
In this context, two aspects that can improve the
relevance of the search results are semantics (Man-
gold, 2007) and user-awareness (Xiang et al., 2010).
Semantics can be useful to overcome the limitations
of a syntactic approach, which is often exploited but
leads to a reduced number of results. User-awareness
can be useful to tailor the search results on the base
of the context of the user that performs a query or a
request. As far as we know, there are no enterprise
search engine that exploits both aspects in a single
approach.
Starting from this consideration, this paper pro-
poses a user-aware semantic enterprise search engine
that was built with this goal in mind, describing in de-
tail its architecture and how it works. The search en-
gine is called AMBIT-SE (AMBIT Search Engine).
It is not a generic search engine, but a search en-
gine dedicated to an enterprise website. We exploit
semantic techniques to improve the search: instead
of a pure syntactic matching between the query key-
words and the words in the available documents, we
rely on their meaning and take into account synonyms
and related terms. Moreover, the main innovation of
our approach is to exploit user information to further
improve the search results. In fact, the approach we
propose takes advantage of textual information, cer-
tainly the primary component of the documents that
should be presented / suggested to users, and also one
of the main information characterizing user profiles
(think, for instance, to the contents of user browsing
history, to the description of users’ interests, and so
on).
Our innovative approach is based on text analy-
sis, semantic retrieval and user-aware techniques and
leads to the following achievements:
• its semantic features are powerful enough to pro-
vide enhanced searching effectiveness over stan-
dard search techniques;
• thanks to user awareness, search results actually
reflect the user’s preferences and needs;
• it is general, flexible and able to process multilin-
gual information;
• it is devised for IT SMEs, providing them with
easy-to-apply methods that do not require big in-
vestments or knowledge prerequisites, allowing
them to query for the information they need in the
way they are used to.
98
Cabri, G., Gaddi, S. and Martoglia, R.
AMBIT-SE: Towards a User-aware Semantic Enterprise Search Engine.
In Proceedings of the 12th International Conference on Web Information Systems and Technologies (WEBIST 2016) - Volume 2, pages 98-108
ISBN: 978-989-758-186-1
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

This paper is organized as follows. First, we
present an overview of the proposed search engine
(Section 2). Then, we explain how our approach an-
alyzes the documents that can be “searchable” by the
users (Section 3), and how it defines which documents
must be retrieved to satisfy the user’s query (Sec-
tion 4). We report the results of the experiments car-
ried out on our system (Section 5). Finally, before the
conclusions (Section 7) we report some related work
(Section 6).
2 SYSTEM OVERVIEW
In this section we present an overview of the proposed
semantic enterprise search engine. Figure 1 proposes
the workflow of AMBIT-SE, which is composed by a
series of coordinated offline and online processes.
First of all, AMBIT-SE performs a Document
analysis phase, in which any textual information
available in the documents that will need to be re-
trieved (e.g. web pages for a given site) and in the
documents useful to determine the user’s behaviour
and preferences (such as e-mails, web pages viewed,
profile information, past search queries, etc.) is ex-
tracted and processed. The workflow starts by using a
Web Crawler to retrieve the raw data of all the docu-
ments that must be searchable, such as the web pages
belonging to a portal. All of these files are then sub-
mitted to the actual analysis process, which consists
of the following steps:
1. The textual content of all files is extracted;
2. The language of each file is determined;
3. The content is divided into paragraphs, and each
paragraph is divided into lines of text;
4. Each line of text is divided into “Tokens” (single
terms);
5. The “Stem” (dictionary form of a term) and “Part
of speech” value (basic type of term) of each token
is determined;
6. Terms classified as nouns are preserved;
7. Nouns are processed with word sense disam-
biguation algorithms, in order to be able to com-
pute synonyms and related terms information
from a thesaurus;
8. The weight of each noun, corresponding to its
containing document, is calculated.
The data structure containing all the document
analysis results will be referred to as “Website(s) se-
mantic glossary”. At the same time, the documents
that constitute the user’s profile, such as all of the web
pages he has visited, are analyzed in the same way,
resulting in a “User semantic glossary”. Both glos-
saries are then compared with document similarity al-
gorithms (see “Semantic glossaries computation and
comparison” in the figure), and a “Profile ranking” is
determined, symbolizing how relevant the retrievable
documents are in relation to the user’s preferences.
The AMBIT-SE online phase allows users to
search through the retrievable data index with differ-
ent kinds of queries, resulting in a “Query ranking”.
The two rankings are then normalized and merged,
so that the final ranking of the retrieved files will
take into account both the query relevance and the
user’s preferences based on the results of the afore-
mentioned process.
The software is written in Java and exploits several
Open-source programs and libraries. The currently
supported languages for all operations are: English,
Italian, Spanish, German, French, Finnish, Dutch,
Polish.
The following sections (Section 3 for document
analysis and Section 4 for document retrieval) provide
in-depth information on each step of the text process-
ing pipeline, illustrating the theory behind them and
the techniques used to execute them.
3 DOCUMENT ANALYSIS
3.1 Crawling
At the beginning of the crawling process, the “Web
crawling” module creates a document data store
(“Raw document data” in Figure 1) containing the
raw data of the documents which will be analyzed by
the document analysis steps together with the details
about their source. In order to extract retrievable doc-
ument data we employ different type of crawlers:
• The Web Crawler handles HTTP and HTTPS, and
is used to crawl Internet, intranet and extranet
sites;
• The File Crawler handles local or remote file sys-
tems; It can retrieve local document data by crawl-
ing the local file system and the NFS and CIFS
mount points, and remote document data using the
following protocols: CIFS/SMB, FTP, FTPS.
The raw document data store contains, among the
others, the following fields for each of the documents:
Title, Content, URL, File Name, Meta Description,
Meta Keywords, Host name, Subdomain, Backlink
Count (i.e. number of incoming links). All of the
crawling operations are handled by the Open-source
AMBIT-SE: Towards a User-aware Semantic Enterprise Search Engine
99

Visited
URLs
Online&process (Document Re t rieval)
Query
Semantic query
processing
Offline&process (Document Analysis)
Semantic glossaries
computation and4
comparison
Normalization
1. <…>
2. <...>
...
1. <…>
2. <...>
...
Query
ranking
User4profile
ranking
1. <…>
2. <...>
...
Final
ranking
User
semantic glossary
Web
crawling
Home
URL(s)
Raw document
data
Websi te(s)4
semantic glossary
Figure 1: The main processes of the AMBIT-SE user-aware semantic enterprise search engine.
enterprise class search engine software, OpenSearch-
Server
1
.
3.2 Extraction, Language and
Paragraphs
In this further step the text contained within each doc-
ument needs to be extracted, an operation that can
vary greatly depending on the format of each doc-
ument; for instance, extracting text from an HTML
file implies excluding every tag, script and comment
within. Next, AMBIT-SE determines the language
of each file, because there are slight variations in
the workflow based on it. Then, the extracted con-
tent of each file is divided into paragraphs, and each
paragraph into lines of text; this will allow the final
ranking to show not only which documents the user
is most interested in, but also which paragraphs and
lines within have affected this result the most. In par-
ticular, the system will show a text snippet of the high-
est rated paragraph when presenting a document to
the user.
All of these preliminary operations are taken
care of by components of the Open-source software
GATE
2
.
3.3 Tokenization, Stemming and Parts
of Speech
The next analysis step is tokenization, i.e. the process
of breaking the stream of text up into terms, phrases,
symbols, or other meaningful elements called to-
kens. In this case, it is performed by a language-
independent Java function that implements methods
for finding the location of boundaries in text, and then
1
http://www.opensearchserver.com/
2
https://gate.ac.uk/
splits it accordingly in order to divide it into single
terms and symbols.
The list of tokens becomes input for the stem-
ming, which is the process of determining the dic-
tionary form, called stem, for a given term. Stem-
ming is language-dependent; in AMBIT-SE we sup-
port 17 languages: English, German, Arabic, Chi-
nese, Danish, Spanish, Finnish, French, Dutch, Hun-
garian, Italian, Norwegian, Portuguese, Romanian,
Russian, Swedish, Turkish. Also, stopwords are re-
moved.
In addition, the tokens are subjected to POS tag-
ging, where each term is marked as corresponding to
a particular Part Of Speech. Simply put, the tagger
identifies terms as nouns, verbs, adjectives, adverbs,
etc. Only the terms classified as nouns are considered
relevant, and will thus be preserved for the rest of the
procedure.
In this case, both stemming and POS tagging are
taken care of by TreeTagger
3
, a tool for annotating
text with part-of-speech and lemma information. To
make use of TreeTagger, the TT4J
4
(TreeTagger for
Java) Open-source wrapper is employed.
3.4 Term Weights
As in classic Information Retrieval (Baeza-Yates and
Ribeiro-Neto, 1999) the importance (weight) of each
term t in each document D of the document collection
D is estimated. We exploit tf-idf weighting, which is
the product of two statistics:
• TF: Term Frequency, which measures how fre-
quently a term occurs in a document. Since every
document D is different in length, it is possible
that a term t would appear much more times in
3
http://www.cis.uni-muenchen.de/
∼
schmid/tools/
TreeTagger/
4
https://reckart.github.io/tt4j/
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
100

long documents than in shorter ones. Thus, the
term frequency is divided by the document length
as a way of normalization:
tf(t, D) =
f(t, D)
len(D)
, (1)
where f(t, D) is the raw frequency of the term t
in the document D (number of times the term ap-
pears in the document), and len(D) is the total
number of terms in the document D;
• IDF: Inverse Document Frequency, which mea-
sures how important a term is. While comput-
ing TF, all terms are considered equally impor-
tant. However it is known that certain terms may
appear often but have little importance. Thus we
weigh down the frequent terms while scaling up
the rare ones, by computing the following:
idf(t, D) = log
N
|{D ∈ D : t ∈ D}|
, (2)
where N is the total number of unique documents
(among both the user’s and retrievable data col-
lections), and |{D ∈ D : t ∈ D}| is the number of
documents where the term t appears.
Then, tf-idf is calculated as:
tfidf(t, D,D ) = tf(t, D) · idf(t,D) (3)
3.5 Semantic Analysis and Thesauri
One of the main features of AMBIT-SE is the abil-
ity to exploit the semantics of the text, going be-
yond standard syntactical search engines. In partic-
ular, we want to extend the search to synonyms and
related terms of a given term. To handle this, we ex-
ploit WordNet
5
, a large lexical database where nouns,
verbs, adjectives and adverbs are grouped into sets
of cognitive synonyms (synsets), each expressing a
distinct concept. Synsets are interlinked by means
of conceptual-semantic and lexical relations, result-
ing in a network or meaningfully related words and
concepts. WordNet superficially resembles a the-
saurus, in that it groups words together based on
their meanings. However, WordNet interlinks not just
word forms, but specific senses of words. Therefore,
AMBIT-SE first performs Word Sense Disambigua-
tion (WSD) of the text.
Before discussing WSD, let us briefly discuss the
structure of WordNet in order to explain how knowing
the synset(s) associated with a text will allow to easily
compute its synonyms and related terms. Synonyms
5
https://wordnet.princeton.edu/
Bookkeeping,
clerking
Acc oun ting,0
acc ountancy
Cost
acc ounting
Inventory
acc ounting
Single-entry
bookkeeping
Double-entry
bookkeeping
Hyponyms
Hypernym
Figure 2: Hypernym/hyponym hierarchy example.
are basically terms associated to the same synset; re-
lated terms are typically represented by their hyper-
nyms and hyponyms. In linguistics, a hyponym is a
term whose semantic field is included within that of
another term, its hypernym. In simpler terms, a hy-
ponym shares a type of relationship with its hyper-
nym; on the other hand, a hyponym is a term whose
semantic field is more specific than its hypernym. The
semantic field of a hypernym, also known as a super-
ordinate, is broader than that of a hyponym. Figure 2
shows a small example: the terms “bookkeeping” and
“clerking” are synonyms, i.e. they belong to the same
synset. Terms “accounting” and “accountancy” con-
stitute their hypernym, while possible hyponyms are
“single-entry bookkeeping” and “double-entry book-
keeping”. By expliting this information, we will allow
users looking for “accounting” information to eas-
ily retrieve documents containing different but related
words like “bookkeeping”.
Please also note that, while the original WordNet
is strictly in English, our goal was to provide multilin-
gual semantic coverage. To this end, we also exploit
the custom WordNet versions available for the dif-
ferent languages that have been collected, extracted
and normalized in the Open Multilingual WordNet
6
project. In addition, we exploit the automatically ex-
tracted data from Wiktionary and the Unicode Com-
mon Locale Data Repository. This allows compar-
isons between different languages, as terms are repre-
sented by corresponding WordNet synset codes.
Getting back to WSD, to identify which sense of
word (i.e. meaning) is used in a sentence, the ex-
ploited algorithm evaluates the similarity between the
synsets a of each term to be disambiguated and the
synsets b of the other nearby terms. The (Leacock
and Chodorow, 1998) metric is used: this measure re-
lies on the length of the shortest path between two
synsets for their measure of similarity. We limit our
attention to hyponymy/hypernymy links and scale the
path length by the overall depth T of the taxonomy.
Path length similarity between synset a and synset
b is computed using the formula:
sim
ab
= max
p
[−log (N
p
/2T )], (4)
6
http://compling.hss.ntu.edu.sg/omw/
AMBIT-SE: Towards a User-aware Semantic Enterprise Search Engine
101

Table 1: A small excerpt of semantic glossary (per-
document view).
!"#$%&'()
*&+%)
,-'.&(.)
(/)
0&123(4(/516/7)
OP0001%
bookkeeping%
00619230-n%
0.333%
0.135%
OP0005%
accounting%
00618734-n,%
13354985-n%%
1%
1.098%
%
…%
…%
…%
…%
…%
%
where N
p
is the number of nodes in path p from a to
b, and T is the maximum depth of the taxonomy.
The result of the process is a disambiguation score
dis assigned to each synset code belonging to each
term: it is normalized between 0 and 1, and it rep-
resents the chances of that term having that sense in
that context. Only the synsets whose disambiguation
score exceeds a given threshold th
d
, i.e. dis > th
d
,
will be kept and stored as the result of the analysis.
3.6 Semantic Glossaries
The result of the analysis of the documents is stored
in a structure we call semantic glossary. In particu-
lar, the analysis of all the retrievable documents in the
collection is stored in the “Website(s) semantic glos-
sary”, while the analysis of the documents associated
with the user profile (i.e. visited URLs, etc.) is stored
in the “User semantic glossary”; the two glossaries
share the same structure. Each glossary is composed
of two “views” which store:
• all the terms (and their synsets) in the documents
with their statistics (global view);
• the terms occurrences (and their synsets) in
each document with their statistics (per-document
view).
In particular, the glossary global view is an alpha-
betical sort of all the extracted terms, while the glos-
sary per-document view is a list of all the term oc-
currences in the documents, sorted by the document
ID, together with their statistics. A small excerpt of a
glossary per-document view is shown in Table 1: the
columns include the document ID (“Document”), the
contained term (“Term”), the WordNet synset code(s)
(“Synsets”) as derived from WSD, and the term fre-
quency (“tf”) and tf-idf weights as described in Sec-
tion 3.4.
As we will see in the next section devoted to doc-
ument retrieval, by means of the stored synset and
weight information, the content of the glossary allows
the similarity functions of AMBIT-SE to draw use-
ful knowledge from both the semantic (i.e. synonyms
and related terms computation) and the text retrieval
fields.
4 DOCUMENT RETRIEVAL
The final goal of the document retrieval process in
AMBIT-SE is to effectively answer a given query Q
submitted by a user U; to this end, it takes into ac-
count all the semantic and user profile information
available in the semantic glossaries produced by the
analysis process and generates a ranking of the avail-
able documents.
The computation of the document ranking is based
on ad-hoc similarity metrics:
• the similarity between the main terms of the avail-
able documents and those specified in the query;
• the similarity between the documents’ terms and
those associated with the user profile (e.g. past
navigated documents).
Both similarities are based on a general document
similarity formula which we will detail in the follow-
ing section; finally, in Section 4.2 we will analyze
some further aspects regarding AMBIT-SE query pro-
cessing.
4.1 Document Similarity Computation
Building on previous research on text retrieval for
specific subject areas as software engineering (Berga-
maschi et al., 2015; Martoglia, 2011), bibliographi-
cal (Beneventano et al., 2015) and user-centric data
(Martoglia, 2015), we define the following document
similarity formula:
DSim(D
x
,D
y
) =
∑
t
x
i
∈D
x
T Sim(t
x
i
,t
y
¯
j(i)
) · w
x
i
· w
y
¯
j(i)
,
(5)
where:
t
y
¯
j(i)
= argmax
t
y
j
∈D
y
(T Sim(t
x
i
,t
y
j
)),
w
x
i
= t f
x
i
· id f
i
,
w
y
¯
j(i)
= t f
y
¯
j(i)
· id f
¯
j(i)
and T Sim is a term similarity formula (see follow-
ing) taking into account the semantic information ex-
tracted from the semantic glossary. Simply put, the
similarity DSim(D
x
,D
y
) between two documents D
x
and D
y
is determined by summing the maximum term
similarity score T Sim(t
x
i
,t
y
¯
j(i)
) between each pair of
terms belonging to different documents, multiplied by
the tf-idf weights of both.
We now proceed to define T Sim(t
i
,t
j
) between
two terms t
i
and t
j
. In our semantic framework, t
i
and
t
j
can be:
• Synonyms, i.e. t
i
SYN t
j
, if a common synset a
is stored in the semantic glossary for both terms,
i.e. ∃a ∈ t
i
∩t
y
(note that this case includes equal
terms);
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
102
• Related, i.e. t
i
REL t
j
, if the synset similarity
sim
ab
between two synsets a ∈ t
i
and b ∈ t
j
(Eq. 4)
exceeds a given threshold th
s
, i.e. ∃a ∈ t
i
,b ∈
t
j
|sim
ab
> th
s
;
• Unrelated, otherwise.
The corresponding term similarity scores are as-
signed as follows:
T Sim(t
i
,t
j
) =
1, if t
i
SYN t
j
r, if t
i
REL t
j
0, otherwise
, (6)
where r is an arbitrary value between 0 and 1. Please
note that synonym and related term information can
be computed offline for all the documents in the col-
lection and in the user profile.
By applying Eq. 5 to the query Q and to each re-
trievable document D
x
of the user profile U, we ob-
tain a “query ranking” and a “user profile ranking”,
respectively, of retrievable documents D
y
in the col-
lection. The two rankings are then normalized and
merged in a final ranking taking into account both the
user’s request and preferences.
4.2 Further Query Processing Aspects
Besides the techniques and features described in de-
tail in the previous sections, AMBIT-SE also offers
administrators the following ways to customize query
processing and presentation of results:
• Text Snippets, showing a custom-sized highest
rated portion of each document in the presented
ranking, plus any amount of surrounding text nec-
essary to reach the desired size; also, the tag used
to highlight words in results listings is parametra-
ble;
• Boosting Subqueries, to tweak the relevance score
of documents. For instance, a website administra-
tor could specify certain group of words, i.e. those
describing a new product, whose weight will be
promoted when found in both the user query and
a given retrievable document. The subqueries can
both bolster or lower a document’s score;
• Autocomplete, offering the most relevant sugges-
tions to the user on the basis of the semantic glos-
sary terms.
5 EXPERIMENTAL EVALUATION
This section illustrates and analyzes the results of sev-
eral tests performed on different kinds of websites.
Precision
0
1
10
Recall
Interp.2precision
0
1
10
Recall
Figure 3: Effects of interpolated precision on the P-R curve.
Since the description of the underlying index struc-
tures supporting semantic search is outside of the
scope of this paper, we will focus on effectiveness
analysis; anyway, please note that the current proto-
type has a response time of 40 ms on average on a
standard single-node configuration.
5.1 Ranked Evaluation Method
The measures used for evaluation are precision and
recall, turned into measures of ranked lists by com-
puting them for each top k set of results, obtaining
a precision-recall curve (Baeza-Yates and Ribeiro-
Neto, 1999).
In particular, we compute the interpolated preci-
sion as:
P
interp
(r) = max
r
0
≥r
P(r
0
) (7)
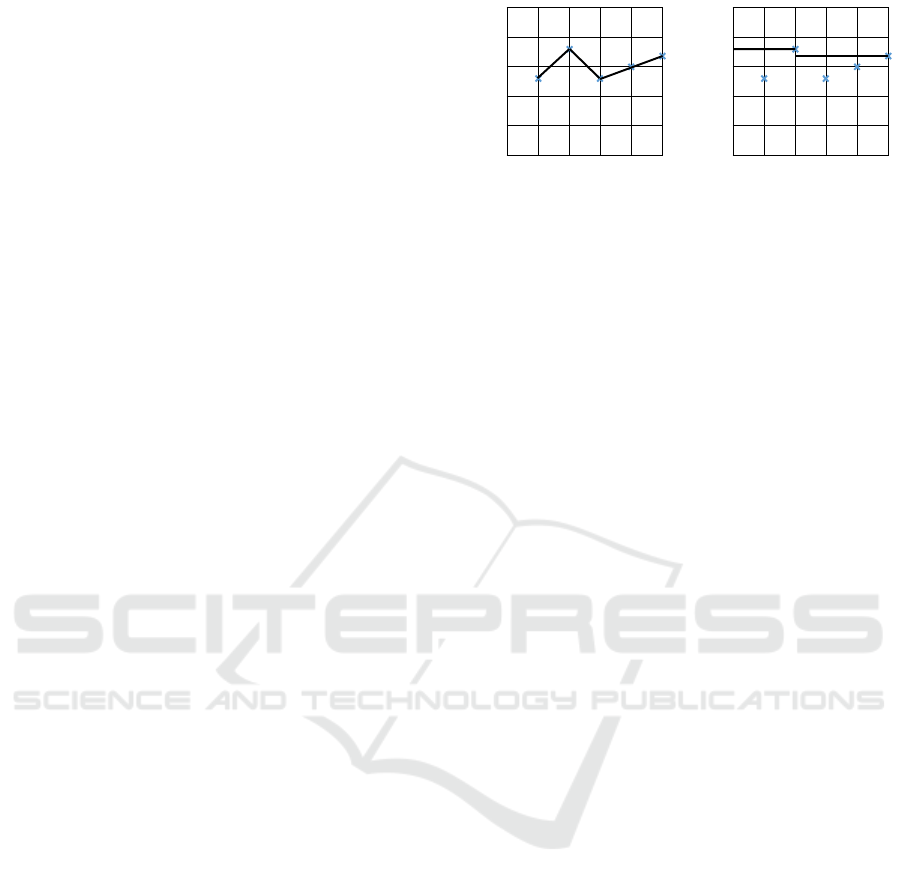
The interpolated precision at a certain recall level r is
defined as the highest precision found for any recall
level r
0
≥ r (see Figure 3).
The rationale for interpolation is that the user is
willing to look at more records if both precision and
recall get better. The interpolated precision is mea-
sured at 11 recall levels of 0.0, 0.1, 0.2, ..., 1.0 (0, 10,
20, ..., 100 percent), then the arithmetic mean of the
obtained values is calculated (Bernardi, 2011).
5.2 Experimental Setting
Four heterogenous business-relevant websites were
selected for evaluation purposes; for each one of
them, an appropriate information need was estab-
lished by examining common searches performed in
the past.
• http://www.cobat.it/, a relatively small Italian
website that provides information and services for
disposing and recycling four problematic waste
categories: batteries and accumulators, tires, elec-
tric and electronic devices, and photovoltaic pan-
els. The established information need is to re-
trieve documents pertaining to the disposal of bat-
teries and accumulators.
AMBIT-SE: Towards a User-aware Semantic Enterprise Search Engine
103

Query&
Our&results!
Google!
Base&
Stem&
Stem&
+&
SynRels&
Stem&
+&
Prof&
Stem&
+&
Prof&
+&
SynRels&
Stem&
+&
HetProf&
Stem&
+&
HetProf&
+&
SynRels&
Q1&
0,54529!
0,53914!
0,55451!
0,63225!
0,80148!
0,56444!
0,75783!
0,53006!
Q2&
0,04242!
0,31009!
0,12454!
0,38424!
0,47474!
0,35351!
0,29737!
0,21818!
Q3&
0,32958!
0,32906!
0,48566!
0,43939!
0,80014!
0,45455!
0,73826!
0,39610!
Q4&
0,00000!
0,10909!
0,12542!
0,24242!
0,39882!
0,24242!
0,32553!
0,06061!
Q5&
0,08684!
0,08678!
0,13376!
0,38678!
0,46167!
0,34444!
0,24239!
0,08392!
Average&
0,20083!
0,27483!
0,28478!
0,41702!
0,58737!
0,39187!
0,47227!
0,25777!
!
!"!
!"#
!"$
!"%
!"&
!"'
!"(
!")
!"*
!"+
#"!
!"! !"# !"$ !"% !"& !"' !"( !") !"* !"+ #"!
Pre cision
Recall
,-./ 01/2 01/23430567/8.
01/23439:; <3430567/8. 01/2343=/19:;<3430567/8. >;;?8/
Figure 4: Test results for http://www.cobat.it/.
• http://evergreensmallbusiness.com/, an English
Blog that publishes different kinds of information
and advice for small businesses, all classified in
categories such as business taxes, management,
personal finance, etc. The established information
need is to retrieve articles pertaining to bookkeep-
ing.
• http://truegoods.com/, an English Indie online
shop that specializes on healthy and natural prod-
ucts. The established information need is to re-
trieve information on products belonging to the
pet-care category.
• http://www.gruppozatti.it/, an Italian authorized
car dealer which sells several brands of both new
and used cars. The established information need
is to retrieve different information about cars be-
longing to the used category.
For each information need, several plausible
queries were submitted to the system (we selected five
representative ones for this evaluation). We employ
different setups in order to evaluate the impact of the
different features of AMBIT-SE, as described below:
• Base: baseline setting, i.e. simple syntactical
search for exact keywords;
• Stem: Stemming and stopword removal are per-
formed;
• SynRels: Synonyms and related terms are also
taken into account, both for the query and when
processing the user profile documents, if present;
• Prof: a User Profile containing only documents
Query&
Our&results!
Google!
Base&
Stem&
Stem&
+&
SynRels&
Stem&
+&
Prof&
Stem&
+&
Prof&
+&
SynRels&
Stem&
+&
HetProf&
Stem&
+&
HetProf&
+&
SynRels&
Q1&
0,28400!
0,28003!
0,37134!
0,53033!
0,56539!
0,47710!
0,51782!
0,51363!
Q2&
0,00000!
0,11039!
0,32255!
0,06818!
0,49271!
0,07025!
0,38474!
0,09091!
Q3&
0,36519!
0,41652!
0,37863!
0,45101!
0,50202!
0,40363!
0,45740!
0,45990!
Q4&
0,09091!
0,09091!
0,35949!
0,09091!
0,55438!
0,09091!
0,42646!
0,15909!
Q5&
0,00000!
0,01653!
0,27722!
0,06061!
0,41804!
0,02597!
0,36979!
0,00000!
Average&
0,14802!
0,18287!
0,34185!
0,24021!
0,50651!
0,21357!
0,45124!
0,24471!
!
!"!
!"#
!"$
!"%
!"&
!"'
!"(
!")
!"*
!"+
#"!
!"! !"# !"$ !"% !"& !"' !"( !") !"* !"+ #"!
Pre cision
Recall
,-./ 01/2 01/23430567/8.
01/23439:; <3430567/8. 01/2343=/19:;<3430567/8. >;;?8/
Figure 5: Test results for http://evergreensmallbusiness.com/.
relevant to the information need is used to perform
searches;
• HetProf: a Heterogeneous User Profile containing
documents relevant to the information need and
an equal number of irrelevant documents is used
to perform searches;
• Google: queries are run through the Google
search engine restricted to the considered docu-
ment set, for reference.
Please note that the first baseline is also represen-
tative of the document retrieval techniques commonly
exploited by most commercial systems (see also re-
lated works).
5.3 Test Results
Figures 4 to 7 show a table containing the eleven-
point interpolated average precision values of all the
query results, and the corresponding average P-R
curve, for each of the considered websites.
Let us start by analyzing the http://www.cobat.it/
results (Figure 4). As expected, Google results fall be-
tween our Base and Stem setups, because Google pro-
grammatically establishes whether to use stemming
or not on a document by document basis: in this in-
stance, unconditional stemming was more effective.
Synonyms and related terms didn’t have a big effect
on their own, especially for Q1 and Q2, because they
already yielded very good results without, so the ad-
ditional records retrieved actually lowered precision
and thus decreased the score for the second query.
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
104

Query&
Our&results!
Google!
Base&
Stem&
Stem&
+&
SynRels&
Stem&
+&
Prof&
Stem&
+&
Prof&
+&
SynRels&
Stem&
+&
HetProf&
Stem&
+&
HetProf&
+&
SynRels&
Q1&
0,04849!
0,02857!
0,29184!
0,54697!
0,60435!
0,53496!
0,59215!
0,27273!
Q2&
0,08089!
0,21579!
0,26412!
0,62044!
0,71850!
0,61004!
0,76318!
0,18182!
Q3&
0,00000!
0,00000!
0,13943!
0,00000!
0,46807!
0,00000!
0,42199!
0,00000!
Q4&
0,00000!
0,39532!
0,33033!
0,67354!
0,49408!
0,66602!
0,49147!
0,00000!
Q5&
0,00000!
0,00000!
0,04206!
0,00000!
0,52799!
0,00000!
0,52095!
0,00000!
Average&
0,02588!
0,12794!
0,21355!
0,36819!
0,56260!
0,36221!
0,55795!
0,09091!
!
!"!
!"#
!"$
!"%
!"&
!"'
!"(
!")
!"*
!"+
#"!
!"! !"# !"$ !"% !"& !"' !"( !") !"* !"+ #"!
Pre cision
Recall
,-./ 01/2 01/23430567/8.
01/23439:; <3430567/8. 01/2343=/19:;<3430567/8. >;;?8/
Figure 6: Test results for http://truegoods.com/.
But on the other hand, they benefited Prof and Het-
Prof setups greatly, because of the large number of
keywords contained within the documents associated
to the user profiles: for instance, the use of semantics
allowed to match different but very related terms like
“battery” and “accumulator”, a match that would go
unnoticed in a syntactic search.
Going to the second website (Figure 5), Google
obtained better results than both our Base and Stem
setups, especially because of the greater precision
achieved in Q1 and Q3; but the use of synonyms
and related terms made up for it with much better
results in Q2, Q4 and Q5, by exploiting a number
of terms correlations such as between “money” and
“bookkeeping”. Indeed, Q1 and Q3 are simple one-
word queries that will find matches in any of the rel-
evant documents, while Q2, Q4 and Q5 are longer
and less direct, and thus harder to satisfy for a search
engine without additional information in the form of
synonyms and related terms. This is also apparent by
taking a look at the results of the Prof and HetProf
setups, which greatly improve in their SynRels varia-
tion.
Looking at the graph in Figure 6, Google yielded
good results up to the 0,4 recall mark, where the curve
plummets to 0,0 precision, meaning most of the rel-
evant documents were not retrieved; this is proba-
bly due to indexing issues with this specific website.
Our results in this instance are a good example of
how computationally determined input, in the form of
word stems, synonyms, related terms and profile doc-
uments, can turn an apparently impossible query into
a manageable one. Google and the Base setup could
Query&
Our&results!
Google!
Base&
Stem&
Stem&
+&
SynRels&
Stem&
+&
Prof&
Stem&
+&
Prof&
+&
SynRels&
Stem&
+&
HetProf&
Stem&
+&
HetProf&
+&
SynRels&
Q1&
0,92350!
0,91351!
0,91351!
0,91243!
0,90953!
0,89566!
0,88889!
0,46875!
Q2&
0,00000!
0,00000!
0,65483!
0,00000!
0,80483!
0,00000!
0,64045!
0,09869!
Q3&
0,00000!
0,00000!
0,00000!
0,00000!
0,00000!
0,00000!
0,00000!
0,01818!
Q4&
0,00000!
0,00000!
0,00817!
0,00000!
0,02893!
0,00000!
0,01035!
0,00000!
Q5&
0,00000!
0,92603!
0,82039!
0,92460!
0,84677!
0,91804!
0,80909!
0,00000!
Average&
0,18470!
0,36791!
0,47938!
0,36741!
0,51801!
0,36274!
0,46976!
0,11712!
!
!"!
!"#
!"$
!"%
!"&
!"'
!"(
!")
!"*
!"+
#"!
!"! !"# !"$ !"% !"& !"' !"( !") !"* !"+ #"!
Pre cision
Recall
,-./ 01/2 01/23430567/8.
01/23439:; <3430567/8. 01/2343=/19:;<3430567/8. >;;?8/
Figure 7: Test results for http://www.gruppozatti.it/.
not retrieve any records for Q3, Q4 and Q5, since they
don’t include terms that match exactly the ones found
in the relevant documents; the Stem setup made Q4
into a succesful query, and the SynRels setup did the
same for Q3 and Q5, especially in conjunction with
Prof and HetProf (among the exploited terms corre-
lations, the very frequent one between “pet” and “an-
imal”).
Our final test (Figure 7) considers a site whose
pages contain very little text, thus providing a differ-
ent task w.r.t. the others. As in most cases, Google
delivered good results only for Q1, the easiest query.
Much like the previous websites, a lot of complex
queries did not yield satisfactory results for Google
or Base; instead, the Stem setup and the SynRels setup
provide a lot of benefits for Q5 and Q2, while Q3 and
Q4 were apparently too difficult even with the addi-
tional input. Anyway, we see that, on mean, the effect
of the semantics and of the user profile is evident from
the results even in this specific setting.
6 RELATED WORK
In this section we report some work related to the
presented user-aware semantic enterprise search en-
gine. In Figure 8 we propose an analysis of the ex-
isting approaches (both academic and commercial),
classifying them on the base of two aspects: the user-
awareness and the semantics. As mentioned, most ap-
proaches do not consider together these aspects and/or
not strictly belonging to the enterprise search engine
AMBIT-SE: Towards a User-aware Semantic Enterprise Search Engine
105

User/Context Awareness
Semantic Analysis
Syntactic
Semantic
Non-aware
Aware
- Alfresco
- Solr
- …
User-aware
- AMBIT-SE
Context-aware:
- IBM Content Analytics
- Hyvonen et al., 2003
- Expert System
- Thesprasith and Jaruskulchai, 2014
- Haslhofer et al., 2013
- Carpineto and Romano, 2012
- Heflin and Hendler, 2000
Context aware:
- Coveo
- Falcarin et al., 2013
- Liu et al., 2004
- Cabri et al., 2003
Figure 8: A quadrant for user-aware semantic approaches.
category, so we will discuss related work in three sep-
arate subsections: semantic approaches, user-aware
approaches and enterprise search engines.
6.1 Semantic Approaches
A broad range of methods for semantic document
retrieval has been developed in the context of the
Semantic Web, as discussed in (Mangold, 2007), a
survey which covers approaches that exploit domain
knowledge to process search requests; the authors
present a large variety of domain knowledge utiliza-
tion that comprise automatic query expansion and
ontology-driven document retrieval.
The relative ineffectiveness of information re-
trieval systems is largely caused by the inaccuracy
with which a query formed by a few keywords
models the actual user information need; one well
known method to overcome this limitation is auto-
matic query expansion, whereby the user’s original
query is augmented by new features with a simi-
lar meaning (Carpineto and Romano, 2012). Differ-
ently from our approach, complex query expansion
techniques such as the ones discussed usually require
different parameters to be specified (as also stated
in (Abdou and Savoy, 2008)). Generally, there is no
single theory capable of finding the most appropriate
values (Abdou and Savoy, 2008) and therefore a long
process of manual tuning becomes necessary.
An increasing number of document retrieval sys-
tems make use of ontologies to help users clarify
their information needs and come up with semantic
representations of documents. In (Haslhofer et al.,
2013), a Simple Knowledge Organization System
(SKOS) based term expansion and scoring technique
that leverages labels and semantic relationships of
SKOS concept definitions is proposed.
Focusing on the necessity of manual intervention,
typical semantic retrieval techniques obtain good ef-
fectiveness levels only on manually annotated collec-
tions and/or with explicit user intervention. In (Thes-
prasith and Jaruskulchai, 2014), a query expansion
technique works on MEDLINE documents which
have been manually assigned to controlled MeSH
(Medical Subject Headings) vocabularies. The ad-
vanced indexing and retrieval method we propose for
AMBIT-SE, instead, exploits the semantics of the text
while remaining completely automatic.
6.2 User-aware Approaches
Several works in the literature have highlighted the
benefits of managing context information and/or pro-
posed techniques and applications exploiting context-
awareness capabilities (Bolchini et al., 2011; Liu
et al., 2004; Cabri et al., 2003). In particular, a few
works are directed towards context modeling, repre-
sentation, and effective handling. For instance, (Bol-
chini et al., 2011) proposes to design a context man-
agement system which is not application-dependent,
while (Villegas and Mller, 2010) reports the result of
a study on various context modeling and management
approaches. (Liu et al., 2004) proposes a method to
derive a user profile based on the search history and
on pre-determined category hierarchies. On the other
hand, standard search engines such as Google typi-
cally provide only very simple IP-address based lo-
calization of search results. Most of these approaches,
including the ones discussed above in the literature,
primarily focus on specific aspects such as external
user information or location, do not consider the se-
mantics of the context and/or rely on manual work in
order to classify and categorize users and documents.
6.3 Enterprise Search Engines
There is certainly a vast offer of enterprise search en-
gines on the market and in the literature.
The great majority of products does not exhibit
a strong focus on ontology-based semantic analysis,
relying instead on syntactic and hand-coded rules.
Some examples include Alfresco
7
, Solr
8
.
There are, of course, exceptions to this rule, such
as: the SHOE project (Heflin and Hendler, 2000),
which requires a domain-ontology where document
types correspond to ontology concepts; Expert Sys-
tem’s Cogito
9
, which provides automated disam-
biguation, classification, entity extraction, and meta-
7
http://www.alfresco.com/
8
http://lucene.apache.org/solr/
9
http://www.expertsystem.com/it/cogito/
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
106

data. However, these systems have no notion of user
context. The same can’t be said for Coveo
10
, a tool
specifically oriented to exploit contextual knowledge
for dealing with information related to customers and
agents. No semantic information, however, is ex-
ploited.
On the other hand, there also a small number of
systems which exploit, even if in a sometimes lim-
ited way, semantic and context information. The On-
togator system (Hyvonen et al., 2003), which is part
of an image management and retrieval system, pro-
vides an interactive recommendation system which
allows the user to browse images based on ontolog-
ical properties. To exploit user contexts, it introduces
views to the ontology that rely on different concept
hierarchies, called “facets”. Each view represents a
specific information-need. IBM’s Content Analytics
with Enterprise Search
11
exploits a framework called
Unstructured Information Management Architecture
(UIMA), in order to build analytic applications and to
find meanings, relationships and relevant facts hidden
in unstructured text. Context information is provided
by means of manual annotations. These approaches
require manual intervention on the documents and/or
adopt a still limited notion of context, i.e. they do not
exploit all of the data potentially available on the user,
such as the contents of any web page visited, attach-
ment downloaded, etc.
7 CONCLUSIONS
In this paper we have presented AMBIT-SE, a se-
mantic enterprise search engine that takes advan-
tage of user-awareness. To this purpose, the en-
gine exploits textual information (coming from sev-
eral sources) about the user, and builds a User se-
mantic glossary, which is exploited to enable effec-
tive user-aware searches on the retrievable informa-
tion, stored in the Website semantic glossary. We have
tested it with different real websites; the results show
that our combined exploitation of synonyms, related
terms and user information leads to very good per-
formance, much better than standard syntactic (enter-
prise) search engines.
With regard to future work, we aim at further op-
timizing the employed similarity metrics and testing
our approach with a wider range of websites. Indeed,
the reported experiments consider a good number of
cases with different features, but more tests can be
useful to further confirm the validity of our approach.
10
http://www.coveo.com/
11
https://www.ibm.com/
ACKNOWLEDGEMENTS
This work was supported by the project “Algo-
rithms and Models for Building context-dependent
Information delivery Tools” (AMBIT) co-funded by
Fondazione Cassa di Risparmio di Modena (SIME
2013.0660).
REFERENCES
Abdou, S. and Savoy, J. (2008). Searching in medline:
Query expansion and manual indexing evaluation. Inf.
Process. Manage., 44(2):781–789.
Baeza-Yates, R. A. and Ribeiro-Neto, B. (1999). Mod-
ern Information Retrieval. Addison-Wesley Longman
Publishing Co., Inc., Boston, MA, USA.
Beneventano, D., Bergamaschi, S., and Martoglia, R.
(2015). Exploiting semantics for searching agricul-
tural bibliographic data. Journal of Information Sci-
ence.
Bergamaschi, S., Martoglia, R., and Sorrentino, S. (2015).
Exploiting semantics for filtering and searching
knowledge in a software development context. Knowl-
edge and Information Systems, 45(2):295–318.
Bernardi, R. (2011). Digital libraries: Ranked evaluation.
Bolchini, C., Orsi, G., Quintarelli, E., Schreiber, F. A.,
and Tanca, L. (2011). Context modeling and con-
text awareness: steps forward in the context-addict
project. Bulletin of the Technical Committee on Data
Engineering, 34:47–54.
Cabri, G., Leonardi, L., Mamei, M., and Zambonelli,
F. (2003). Location-dependent Services for Mo-
bile Users. IEEE Transactions on Systems, Man,
and Cybernetics-Part A: Systems And Humans,
33(6):667–681.
Carpineto, C. and Romano, G. (2012). A survey of auto-
matic query expansion in information retrieval. ACM
Comput. Surv., 44(1):1:1–1:50.
Haslhofer, B., Martins, F., and Magalh
˜
aes, J. a. (2013).
Using skos vocabularies for improving web search.
In Proceedings of the 22Nd International Conference
on World Wide Web, WWW ’13 Companion, pages
1253–1258.
Heflin, J. and Hendler, J. (2000). Searching the web with
shoe. In Artificial Intelligence for Web Search. Papers
from the AAAI Workshop.
Hyvonen, E., Saarela, S., and Viljanen, K. (2003). Ontoga-
tor: combining view- and ontology-based search with
semantic browsing. In Proceedings of XML Finland.
Leacock, C. and Chodorow, M. (1998). Combining local
context and wordnet similarity for word sense identi-
fication. In WordNet: An electronic lexical database.
Liu, F., Yu, C., and Meng, W. (2004). Personalized web
search for improving retrieval effectiveness. IEEE
Trans. on Knowl. and Data Eng., 16(1):28–40.
Mangold, C. (2007). A survey and classification of semantic
search approaches. In Semantics and Ontology.
AMBIT-SE: Towards a User-aware Semantic Enterprise Search Engine
107

Martoglia, R. (2011). Facilitate IT-Providing SMEs in Soft-
ware Development: a Semantic Helper for Filtering
and Searching Knowledge. In SEKE, pages 130–136.
Martoglia, R. (2015). Ambit: Semantic engine foundations
for knowledge management in context-dependent ap-
plications. In SEKE, pages 146–151.
Thesprasith, O. and Jaruskulchai, C. (2014). Query ex-
pansion using medical subject headings terms in the
biomedical documents. In Intelligent Information and
Database Systems - 6th Asian Conference, ACIIDS
2014, Bangkok, Thailand, April 7-9, 2014, Proceed-
ings, Part I, pages 93–102.
Villegas, N. M. and Mller, H. A. (2010). Managing dy-
namic context to optimize smart interactions and ser-
vices. In Chignell, M., Cordy, J., Ng, J., and Yesha, Y.,
editors, The Smart Internet, volume 6400 of Lecture
Notes in Computer Science, pages 289–318. Springer
Berlin Heidelberg.
Xiang, B., Jiang, D., Pei, J., Sun, X., Chen, E., and Li, H.
(2010). Context-aware ranking in web search. In Pro-
ceedings of the 33rd International ACM SIGIR Con-
ference on Research and Development in Information
Retrieval, SIGIR ’10, pages 451–458.
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
108
