
Design and Evaluation of Automatic Workflow Scaling Algorithms for
Multi-tenant SaaS
Ankita Atrey, Hendrik Moens, Gregory Van Seghbroeck, Bruno Volckaert and Filip De Turck
INTEC-IBCN-iMinds, Ghent University, Gaston Crommenlaan, 9050, Gent, Belgium
Keywords:
Cloud Multi-tenancy, Cloud Simulation, Cloud Resource Provisioning, SLA Provisioning.
Abstract:
Current Cloud software development efforts to come up with novel Software-as-a-Service (SaaS) applications
are, just like traditional software development, usually no longer built from scratch. Instead more and more
Cloud developers are opting to use multiple existing components and integrate them in their application work-
flow. Scaling the resulting application up or down, depending on user/tenant load, in order to keep the SLA,
no longer becomes an issue of scaling resources for a single service, rather results in a complex problem of
scaling all individual service endpoints in the workflow, depending on their monitored runtime behavior. In
this paper, we propose and evaluate algorithms through CloudSim for automatic and runtime scaling of such
multi-tenant SaaS workflows. Our results on time-varying workloads show that the proposed algorithms are
effective and produce the best cost-quality trade-off while keeping Service Level Agreements (SLAs) in line.
Empirically, the proactive algorithm with careful parameter tuning always meets the SLAs while only suffering
a marginal increase in average cost per service component of ≈ 5 − 8% over our baseline passive algorithm,
which, although provides the least cost, suffers from prolonged violation of service component SLAs.
1 INTRODUCTION
Cloud computing has redefined the way in which
computing is perceived today and its use has in-
creased over the years. Clouds offer many benefits,
but achieving scalability and quality of such services
while achieving all Service Level Agreements (SLAs)
at a minimal cost is challenging.
With the increased use of multi-tenancy (W.Tsai
and Zhong, 2014), (sharing of virtualised resources
among multiple users, thereby increasing concur-
rency and lowering virtualisation overhead) and rising
popularity of cloud services for large user bases (e.g.
Dropbox, Office365 etc.), correctly and automatically
scaling these services to deal with current user de-
mand becomes very important. Besides this, the ma-
jority of the SaaS developers no longer develop their
applications from scratch, but utilize specialized ex-
isting (cloud-based) services in an application work-
flow. Examples of such re-usable service endpoints
are payment services, authorisation services, cloud
monitoring / profiling services, feedback services, etc.
In this work we assume that the resulting SaaS
product/application workflow will have to cater to a
Service Level Agreement (SLA) with regards to e.g.
response time. The issue we face when trying to
solve the SLA requirements of a multi-tenant work-
flow is that each service component in such a work-
flow, can have different SLA requirements, and can
behave differently when put under multi-tenant load.
Manual management of the upscaling or downscal-
ing (i.e. assigning more or fewer resources on of-
fering that service) of specific workflow components
based on monitored behavior may solve this, but is
a process which would have to be done continuously
and, due to the manual intervention, would be error-
prone. Therefore, in this work, we present an auto-
mated multi-tenant workflow SLA monitoring frame-
work, and algorithms which can automatically pro-
pose scaling specific service components up or down
based on their current SLA compliance.
The use case we are investigating in particular
(Fig. 1), is an elastic multi-tenant online collaborative
meeting room tool, consisting of workflows which
can, for ease of understanding, be simplified to three
service components namely encoders, decoders and
transcoders. Here, an interactive professional meet-
ing service is offered to a group of employees situ-
ated across the globe. Every stream consists of an
encoder, potentially a transcoder and a decoder, all of
which have different multi-tenant SLA requirements
in order to provide a flawless service (no A/V inter-
Atrey, A., Moens, H., Seghbroeck, G., Volckaert, B. and Turck, F.
Design and Evaluation of Automatic Workflow Scaling Algorithms for Multi-tenant SaaS.
In Proceedings of the 6th International Conference on Cloud Computing and Services Science (CLOSER 2016) - Volume 1, pages 221-229
ISBN: 978-989-758-182-3
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
221

Figure 1: Use-case: An online collaborative meeting room
with participants from across the globe.
ruptions, no stuttering, no connection loss, etc.). Note
that users can join or leave these meetings at any point
in time, leading to large fluctuations in terms of num-
ber of tenants currently using the system.
The algorithms proposed in this paper deal with
the situation where resource scaling must be per-
formed for each individual service component of the
overall application workflow. The runtime behavior
of each component is captured by a generic moni-
toring mechanism, and is used to keep track of how
this component is behaving based on its current ten-
ant load and assigned resources. Thus, we intend to
automatically intervene if the load on a particular ser-
vice is becoming too high for it to keep its SLA. Like-
wise, resource assignment should also be automati-
cally downscaled to save on resources and/or budget.
The rest of this paper is structured as follows. Re-
lated work is presented in Section 2, while Section 3
present the problem statement. Following this, Sec-
tion 4 introduces the SLA monitoring-based resource
provisioning algorithms. Section 5 discusses the
evaluation setup after which Section 6 discusses the
CloudSim evaluation results of the proposed heuristic
algorithms. Finally, Section 7 concludes.
2 RELATED WORK
A lot of work has been performed with regards to
Cloud resource provisioning strategies for IaaS (In-
frastructure as service), PaaS (Platform as a service)
and SaaS (Software as a service) providers. More-
over, research on multi-tenancy in cloud applications
(Guo et al., 2007) with SLA-driven simulations (An-
tonescu and Braun, 2014) is not uncommon today.
(Espadasa et al., 2013) have focused on under and
over-provisioning of resources in SaaS and its influ-
ence on cost-effectiveness. In their work, a multi-
tenant based resource allocation model has been de-
signed. Research done by (Bellenger et al., 2011)
discussed semi-automatic and automatic scaling. The
authors provide an overview of the pros and cons of
semi-automatic (users are forced to balance request-
ing more resources to avoid under-provisioning ver-
sus releasing resources to avoid over-provisioning)
versus automatic scaling (users follow workloads).
User satisfaction is the key concern of cloud ser-
vices, which, in certain situations, can be adversely
affected by SLA violations. (Morshedlou and Mey-
bodi, 2014) state that SLA violations depend on some
user characteristics, and eventually define two types
of user characteristics to reduce the impact of SLA vi-
olation. Another interesting work (L. Wu and Buyya,
2011), deals with algorithms for automated resource
provisioning of SaaS services based on their SLA.
This work was further extended to develop a method
for admission control (L. Wu and Buyya, 2012) of
user requests, thus facilitating prevention of addi-
tional user requests from being accepted which in turn
would lead to violating the SLA of the service. In
continuation to this, (L. Wu et al., 2014) also focused
on Customer Satisfaction Level (CSL) which depends
on the SLA violations. To improve CSL and re-
duce SLA violations, various algorithms are designed
based on resource reservation and request reschedul-
ing. The work presented in this paper differs from
all the works discussed above, owing to our focus on
workflows of service endpoints, each with indepen-
dent runtime behavior, but contributing to the overall
application workflow’s SLA adherence as well.
Various other studies (Taheri et al., 2014) (Glitho,
2011) show that auto-scaling for multimedia services
is an actively studied topic of research. A recent work
by (Soltanian et al., 2015) lay their focus on a very
specific sub-problem of scaling media services. This
work differs from the work presented in this paper as
our focus is to make generic and robust algorithms for
the entire service workflow spectrum.
3 PROBLEM DESCRIPTION
This section presents a concise model of multi-tenant,
multi-component SaaS workflows, with an introduc-
tion of its basic concepts followed by a formal de-
scription of the ARP-M (Automatic Resource Provi-
sioning under Multi-tenancy) problem. Table 1 sum-
marizes the notations used in the rest of the paper.
The basis of the issue at hand is the observation
that cloud-based SaaS applications currently are, a lot
of times, built as workflows of multiple existing ser-
vices (albeit with the necessary custom glue code to
tie all of them together). In multi-tenant usage sce-
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
222

Table 1: Summary of the notations used.
Item Definition
V The pool of VMs; ∀i,V
i
∈ V .
W Set of workflow requests; ∀j,W
j
∈ W .
D(t) Time varying distribution for varying worfklow requests.
C
k j
A service component for the workflow W
j
; ∀k,C
k j
∈ W
j
.
SLA
C
k j
status
The status (binary) of the SLA of C
k j
, i.e. met or broken.
N
i
running
Number of components currently running on VM V
i
.
N
i
max
Maximum number of components allowed on VM V
i
.
τ
Parameter controlling how quickly the Proactive algorithm
intervenes in terms of scaling resources up or down.
T
V
i
reserve
Time required for reservation of a new VM V
i
.
T
migrate
Time required for migrating a service component to V
i
.
P
V
i
reserve
Penalty incurred due to reservation of a new VM V
i
.
P
migrate
Penalty incurred owing to migrating components to V
i
.
narios, as is mostly the case when dealing with SaaS
applications, the performance and scalability of each
of these workflow service components can behave dif-
ferently when compared to the others, yet all of them
have an impact on the overall performance and scala-
bility of the SaaS application/workflow.
We hence define an application as a workflow
W
j
∈ W consisting of one or more components C
k j
∈
W
j
(see Fig. 2), each of which having a separate SLA
agreement which defines a.o. minimal resource re-
quirements (processing power, memory, storage, etc.)
in order to work according to its specifications. Ser-
vice components in such an application workflow,
pass their data along the workflow edges to the next
service component. In the case of streaming work-
flows, components receive streaming data from the
workflow components which serve as input, while
they themselves stream their output data to the work-
flow components following their execution. Again as
an example, if the workflow in Fig. 2 would be rep-
resenting a streaming workflow, C
21
would continu-
ously send/stream output data to C
31
and C
41
, who in
turn process that input data and stream it to C
51
. All
service endpoints are hence processing in parallel.
In this paper, and given our use case of online
collaborative audio/video meetings, we will focus on
streaming workflows, which process data as long as
the meeting is ongoing. It is important to note that
this type of workflow, for this type of use cases, does
not benefit from assigning more resources to them
than required, as one cannot ‘speed up’ the meeting.
As long as the performance SLAs of the constituent
services are met, the meeting service will perform
as envisioned for those participating in it (i.e. over-
allocating resources will not lead to shorter meeting
durations). To model this, the tenant requests follow
a time-varying distribution D(t).
We call the problem of automatically provisioning
resources for multi-tenant SaaS applications as Au-
tomatic Resource Provisioning under Multi-tenancy
(ARP-M) problem; defined formally as follows.
Problem. Given a VM pool V , a set of streaming
Figure 2: An application workflow W
1
composed of multi-
ple service components and inter-component data flows.
workflow requests W following a distribution D(t),
and the maximum number of requests allowed on each
VM N
i
max
| ∀V
i
∈ V , perform automatic resource pro-
visioning to keep the SLAs, SLA
status
= f alse, for all
the workflow components C
k j
| ∀k,C
k j
∈ W
j
,∀ j,W
j
∈
W , while retaining high cost-efficiency and quality of
service for multi-tenant SaaS.
4 RESOURCE PROVISIONING
ALGORITHMS
In this section, we describe our proposed monitor-
ing driven resource provisioning heuristics for meet-
ing the SLAs while maintaining high cost efficiency.
As mentioned in Sec. 3, the SLAs of the workflows
depend on the SLAs/run-time behavior of each of its
constituent service components. This is characterized
by the number of component instances N
i
running
, si-
multaneously running on the respective provisioned
resources ∀V
i
∈ V and the maximum number of com-
ponent instances N
i
max
that can be served by the re-
sources reserved for the components at any given
time. Additionally, the number of the tenant requests
follows a time-varying distribution D(t).
Next, we briefly describe the building blocks of
our algorithms: (a) a SLA Monitoring module and (b)
a VM Allocation module.
• SLA Monitoring: Each component C
k j
of a
workflow W
j
∈ W running on a VM V
i
∈ V , is
associated with a binary variable, SLA
status
, which
assumes the value of False if SLAs are met and
True otherwise. Mathematically,
SLA
status
=
(
f alse, if N
i
running
≤ N
i
max
true, otherwise
Keeping track of the SLA status for each compo-
nent (whether it is broken or not) is the main task
of this module. This monitoring capability plays
a central role in the design of the more involved
Design and Evaluation of Automatic Workflow Scaling Algorithms for Multi-tenant SaaS
223

proposed heuristics, i.e., the reactive algorithm
(Alg. 3) and the proactive algorithm (Alg. 4).
• VM Allocation: This module facilitates on de-
mand creation of new VM instances based on a
specific VM template from the pool of VMs V .
The VM allocations under the passive algorithm
are performed in the beginning, and remain fixed
throughout, whereas are continuously updated for
the reactive and the proactive algorithms.
4.1 Workflow Deployment Algorithm
Algorithm 1 describes the pseudo-code for the de-
ployment of streaming workflows. As mentioned in
Sec. 3, the user/tenant requests follow a time-varying
distribution D(t). Now, if the incoming requests at
time t + 1 are greater than those at time t (line 7),
then additional workflows are created and assigned to
the VMs (depending on the resource provisioning al-
gorithms, lines 8–13), otherwise the additional work-
flows are canceled and the corresponding resources
on the VMs that were hosting these workflows freed
(lines 14–24). Note that, irrespective of the resource
provisioning algorithm, each of the service compo-
nents C
k j
| 1 ≤ k ≤ |W
j
|, of the incoming user/tenant
workflow requests W
j
, are assigned to separate VMs
V
i
| 1 ≤ i ≤ |W
j
|, that are currently accepting requests,
from the VM pool V . Once these VMs reach their
capacity, then depending upon the protocols of the re-
source provisioning algorithms new VMs are either
reserved / not reserved and the pointer to the currently
active VMs altered/unchanged respectively.
4.2 Passive Algorithm
In this algorithm, all the resources with different prop-
erties (storage, CPU, memory etc.) are reserved in
the beginning of the application session. Note that in
this algorithm, no new VM reservations happen even
if ∀V
i
∈ pre-reserved V the capacity is reached, i.e.
N
i
running
> N
i
max
, in which case the SLAs violate.
This algorithm will achieve good results in terms
of Cost and keeping SLAs, only if the request rate is
near-constant and the number of requests can fit in the
pre-reserved resources. The moment more requests
arrive, the SLAs will start to violate and remain vio-
lated. The cost, however, will naturally remain fixed.
4.3 Reactive Algorithm
Contrary to the passive algorithm, here new VM
reservations are triggered once the number of compo-
nents N
i
running
running on a VM V
i
exceeds its maxi-
mum permissible limit N
i
max
(line 6). If the workflow
Algorithm 1: Workflow Deployment Algorithm.
Require: V , N
i
max
| ∀V
i
∈ V , W ∼ D(t), provisionType,τ
Ensure: SLA
status
, AvgCost, Cost
1: numRunning ← 0
2: for each V
i
∈ V do
3: N
i
running
← 0
4: for t = 0 to t
max
do
5: SLA
status
← f alse, AvgCost ← 0, Cost ← 0
6: W
t
∼ D(t); numDeploy ← |W
t
| − numRunning
7: if numDeploy ≥ 0 then
8: if provisionType = Passive then
9: PassiveDeploy(W
t
,V )
10: else if provisionType = Reactive then
11: ReactiveDeploy(W
t
,V )
12: else
13: ProactiveDeploy(W
t
,V , τ)
14: else
15: for each W
j
∈ W
t
do
16: Cost
j
← 0
17: for each C
k j
∈ W
j
do
18: Cancel C
k j
and free its resources on V
i
19: N
i
running
← N
i
running
− 1
20: Cost
j
← Cost
j
− (M
i
+C
i
+ S
i
)
21: if N
i
running
≤ N
i
max
then
22: SLA
status
← f alse
23: Cost ← Cost +Cost
j
24: AvgCost ← AvgCost +Cost
j
/|W
j
|
25: AvgCost ← AvgCost/|W
t
|
26: numRunning ← numRunning +numDeploy
Algorithm 2: Passive Algorithm.
Require: V , N
i
max
| ∀V
i
∈ V , W ∼ D(t)
Ensure: SLA
status
, AvgCost, Cost
1: procedure PASSIVEDEPLOY(W
t
,V )
2: for each W
j
∈ W
t
do
3: Cost
j
← 0
4: for each C
k j
∈ W
j
do
5: Deploy C
k j
on a pre-reserved VM V
i
6: N
i
running
← N
i
running
+ 1
7: if N
i
running
≤ N
i
max
then
8: Cost
j
← Cost
j
+ M
i
+C
i
+ S
i
9: else
10: SLA
status
← true
11: Cost ← Cost +Cost
j
12: AvgCost ← AvgCost +Cost
j
/|W
j
|
13: AvgCost ← AvgCost/|W
t
|
request W
j
triggered the reservation process, then l
(1 ≤ l ≤ |W
j
|) new VMs are instantiated from the VM
pool V to cater to the |W
j
| service components of this
request. Since, SLAs are not being monitored con-
tinuously and new reservations are triggered only af-
ter violations in SLAs are detected, i.e., N
i
running
>
N
i
max
;∀i | 1 ≤ i ≤ |W
j
|, the SLAs of all the service
components remain violated for the time required to
reserve new VMs and the time required to migrate
them from the old VM to the new one. Additionally,
a penalty proportional to the duration for which the
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
224

Algorithm 3: Reactive Algorithm.
Require: V , N
i
max
| ∀V
i
∈ V , W ∼ D(t)
Ensure: SLA
status
, Cost, AvgCost, AvgPen, AvgSLABrkD
1: SLABrkD ← 0, AvgSLABrkD ← 0
2: procedure REACTIVEDEPLOY(W
t
,V )
3: for each W
j
∈ W
t
do
4: Cost
j
← 0, Pen
j
← 0
5: for each C
k j
∈ W
j
do
6: if N
i
running
+ 1 > N
i
max
then
7: SLA
status
← true
8: Identify VM V
l
, with N
l
running
< N
l
max
9: Deploy C
k j
on VM V
l
10: N
l
running
← N
l
running
+ 1
11: Cost
j
← Cost
j
+ M
l
+C
l
+ S
l
12: SLABrkD ← SLABrkD + T
V
l
reserve
+ T
migrate
13: Pen
j
← Pen
j
+ P
V
l
reserve
+ P
migrate
14: else
15: N
i
running
← N
i
running
+ 1
16: Cost
j
← Cost
j
+ M
i
+C
i
+ S
i
17: Cost ← Cost +Cost
j
; Penalty ← Penalty +Pen
j
18: AvgCost ← AvgCost +Cost
j
/|W
j
|
19: AvgPen ← AvgPen+ Pen
j
/|W
j
|
20: AvgSLABrkD ← SLABrkD/|W
j
|
21: AvgCost ← AvgCost/|W
t
|; AvgPen ← AvgPen/|W
t
|
22: AvgSLABrkD ← AvgSLABrkD/|W
t
|
SLAs were violated is also added to the costs, over-
and-above the usual VM utilization costs (line 13).
This algorithm reacts to the detection of violation
in SLAs, and thus would suffer from small episodes
of SLA violations. Although the SLAs would be met
for a large portion of the time, there will be a surge in
costs (owing to penalties) when the SLAs are broken.
4.4 Proactive Algorithm
In this algorithm, the SLA monitoring module contin-
uously monitors the number of service components
N
i
running
and checks how far this is from the maximum
permissible limit N
i
max
, for each VM V
i
∈ V . To ad-
dress the limitations mentioned in the reactive algo-
rithm the proactive algorithm incorporates the use of
a parameter τ. The parameter τ facilitates the reserva-
tion of a new VM V
l
and the migration of the service
components from V
i
to V
l
, to be performed while there
is still room for more components to be executed on
the VM V
i
without breaking the SLAs.
Using this algorithm, the SLAs of all the com-
ponents remain broken for the time required to re-
serve new VMs and migrate them from the old VM
to the new one respectively, discounting the time du-
ration corresponding to the start of the reservation
process and the time instant at which the SLA actu-
ally got violated. Thus, with a careful selection of τ,
T
reserve
+ T
migrate
would get subsumed by the differ-
ence in the time instant at which the SLAs actually
got violated and the time instant at which the reser-
Algorithm 4: Proactive Algorithm.
Require: V , N
i
max
| ∀V
i
∈ V , W ∼ D(t)
Ensure: SLA
status
, Cost, AvgCost, AvgPen, AvgSLABrkD
1: SLABrkD ← 0, AvgSLABrkD ← 0
2: procedure PROACTIVEDEPLOY(W
t
,V , τ)
3: for each W
j
∈ W
t
do
4: Cost
j
← 0, Pen
j
← 0
5: for each C
k j
∈ W
j
do
6: N
i
running
← N
i
running
+ 1
7: if N
i
running
= bτ.N
i
max
c + 1 then
8: Identify VM V
l
, with N
l
running
< N
l
max
9: StartV M
V
l
← t
10: if N
i
running
> N
i
max
then
11: if t − StartV M
V
l
< T
V
l
reserve
+ T
migrate
then
12: SLA
status
← true
13: extraDelay ← T
V
l
reserve
+ T
migrate
−t + StartV M
V
l
14: SLABrkD ← SLABrkD + extraDelay
15: Pen
j
← Pen
j
+
extraDelay
T
V
l
reserve
+T
migrate
(P
reserve
+ P
migrate
)
16: Deploy C
k j
on VM V
l
17: N
l
running
← N
l
running
+ 1; N
i
running
← N
i
running
− 1
18: Cost
j
← Cost
j
+ M
l
+C
l
+ S
l
19: else
20: Cost
j
← Cost
j
+ M
i
+C
i
+ S
i
21: AvgCost ← AvgCost +Cost
j
/|W
j
|
22: AvgPen ← AvgPen+ Pen
j
/|W
j
|
23: AvgSLABrkD ← SLABrkD/|W
j
|
24: AvgCost ← AvgCost/|W
t
|, AvgPen ← AvgPen/|W
t
|,
AvgSLABrkD ← AvgSLABrkD/|W
t
|
vation process was triggered. This will result in the
SLAs to be always met while the waiting time on
VMs that need to be started will also be 0. If the pa-
rameter τ is too low, additional VMs will be reserved
rapidly which will in turn drive up the cost. Likewise,
if the parameter τ is too high, we will spend some
extra time to instantiate new VMs. Similar to Alg. 3
penalties are added over-and-above the usual VM uti-
lization costs. Note that since we preach maximum
resource utilization, although new VM reservations
are triggered once the above condition is met, the ser-
vice components are migrated only after the VMs cur-
rently running them are fully utilized.
5 EVALUATION SETUP
5.1 Media Workflows
The media workflow illustrated in Fig. 3, repre-
sents a streaming workflow with three components
namely encoder, transcoder and decoder. In stream-
ing workflows service components continuously re-
ceive streaming data from other components which
serve as their input, while they themselves stream
their output data to other workflow components fol-
lowing their execution. Note that even though much
Design and Evaluation of Automatic Workflow Scaling Algorithms for Multi-tenant SaaS
225

Figure 3: Media workflow with three components: Encoder,
Transcoder and Decoder. Each component has a personal
SLA and runs on a VM, made available from a VM pool.
more elaborate workflows exist, this particular work-
flow has been chosen to showcase the strength of the
presented algorithms in an easy-to-grasp manner.
5.2 Evaluation Scenario
The media workflow discussed in the previous sec-
tion is instantiated by multiple users/tenants and sub-
mitted to the CloudSim simulator. To showcase our
simulation results, we assign the streaming workflow
requests (D(t)) to follow a normal distribution. We
generate 200 user requests following a normal distri-
bution, with the time 12 noon set as the mean and 3.5
hours to be the standard deviation. In the beginning
of the day requests come in slowly but gradually these
requests increase and reach a peak during the mid day.
For each user/tenant request a new instance of the
workflow W
j
is created and the constituent service
components C
k j
,∀k | C
k j
∈ W
j
are provisioned on dif-
ferent VMs V
i
, available from the VM pool V (the
choice of VM and how this VM pool grows / shrinks
is driven depending on the choice of the algorithm).
5.3 Evaluation Metrics
We consider the following metrics:
• SLA Status: The SLA status for each service
component C
k j
, of each instance of a workflow
W
j
, running on a VM V
i
, is defined as a binary
variable which assumes the value of f alse if the
SLAs are met, and true otherwise.
• Average SLA Break Duration: The average
SLA break duration is defined as the amount of
time the SLA
status
of a service component is bro-
ken over its runtime duration on average. Thus,
for a simulation with w workflow requests W
j
∈
W | 1 ≤ j ≤ w, c service components each C
k j
∈
W
j
| 1 ≤ k ≤ c, and T
C
k j
slabreak
being the duration for
which the SLAs remain broken for a component
C
k j
, we mathematically state the following:
1
w
w
∑
j=1
1
c
c
∑
k=1
(T
C
k j
slabreak
)
(1)
• VM Cost: The VM cost is defined as the sum of
all costs related to resource usage when running
Table 2: Parameterized VM Templates.
Template Storage CPU RAM Monthly Cost
Template
01
4 GB 40 MIPS 128 GB $3.94
Template
02
8 GB 80 MIPS 256 GB $7.88
the components of streaming workflows. Thus,
for a simulation with w workflow requests, each
one with c components, and M
k
, S
k
, C
k
, represent-
ing, memory, storage and CPU costs respectively
for a component C
k
, we mathematically state the
VM cost and the average VM cost as follows:
w
∑
j=1
c
∑
k=1
(M
k
+ S
k
+C
k
)
(2)
1
w
w
∑
j=1
1
c
c
∑
k=1
(M
k
+ S
k
+C
k
)
(3)
• Penalty: The extra cost incurred over-and-above
the normal resource utilization costs accounts for
the incurred penalty. The penalty is mainly due to
the side-effects of breaking SLAs, and includes
the cost spent on components (in SLA break
state), while waiting for (1) a new VM reservation
P
reserve
and (2) migration of components from one
VM to another P
migrate
. We mathematically state
the Penalty and the average Penalty as follows:
w
∑
j=1
c
∑
k=1
(P
reserve
k
+ P
migrate
k
)
(4)
1
w
w
∑
j=1
1
c
c
∑
k=1
(P
reserve
k
+ P
migrate
k
)
(5)
5.4 CloudSim Extensions
The proposed algorithms are implemented and evalu-
ated using the CloudSim (Calheiros et al., 2011) event
based simulator. To showcase the effectiveness of our
algorithms under the proposed evaluation scenario,
we implemented the following extensions:
• SLA Monitor: For each instantiation of the me-
dia workflow, the monitoring module checks the
SLAs of all the service components (encoder,
transcoder and decoder), to see whether they hold
under the current deployment scenarios. The
SLAs of various components are continuously
monitored by a Monitor event, to facilitate trig-
gering of certain actions based on a threshold τ.
• Resource Provisioner: The resource provision-
ing module has been extended to implement all
monitoring based multi-tenant resource provi-
sioning algorithms (as defined in Sec. 4).
• Request Generator: extends the Cloudlet class
to support real-time streaming workflows and
generates user/tenant workflow requests based on
a normal distribution until a client event stops it.
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
226
0
10
20
30
40
50
60
70
80
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Average SLA Broken Duration (in sec)
Parameter for Proactive Algorithm
Figure 4: Variation in the average SLA break duration ver-
sus τ for the Proactive algorithm.
6 EVALUATION RESULTS
As mentioned in Sec. 4, the time required to reserve
new VMs differs significantly from the time required
to migrate one component from an existing VM in-
stance to another. To this end, we define two vari-
ables, T
V
i
reserve
and T
migrate
, that determine the duration
for instantiating/reserving new VMs and the duration
for migrating components to existing VMs respec-
tively. For the simulations, the values of T
V
i
reserve
and
T
migrate
were defined as uniform distributions between
[60s,75s] and [0.5s,2s] respectively.
The costs for the VM templates used, were param-
eterized based on the Amazon EC2 image c3.8xlarge,
with a monthly price of 1.680 to provide 32 Million
instructions per second (MIPS), 60 GB of RAM and
320 GB of storage. This cost was divided equally
between secondary-storage, main-memory and CPU,
and the converted unit prices (per MB/hour and
MI/hour) were used to calculate the costs for the VM
templates used in this paper. The computed costs for
each VM template are mentioned in Table 2.
All the simulations were executed using the
CloudSim simulator and the proposed extensions, on
an Intel(R) Core i5 4-core machine with 1.7 GHz
CPU and 8 GB RAM running Linux Ubuntu 15.04.
We first analyze the results obtained under the
proactive algorithm with the variation in the param-
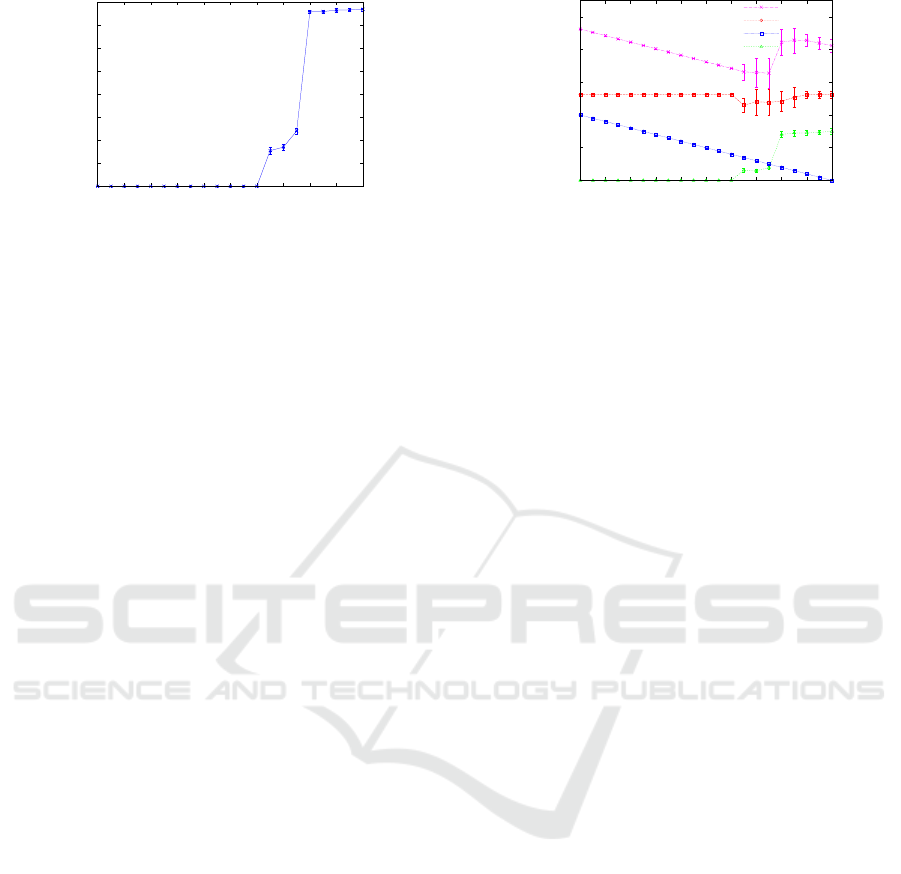
eter τ from 0 → 1. It is evident from Fig. 4 that the
SLAs of the components are met for τ ≤ 0.6. Once the
value of τ crosses 0.6, the average SLA break duration
starts increasing. This increase is at first gradual till
τ ≤ 0.75, after which it starts increasing rapidly.
The average penalty incurred, due to the time re-
quired for a new VM reservation T
V
i
reserve
(P
V
i
reserve
) and
for migration of components T
migrate
(P
migrate
), dur-
ing the time when SLAs for the components are bro-
ken, portrays a similar pattern as depicted by the SLA
break duration (Fig. 4). Thus, with respect to min-
0
0.1
0.2
0.3
0.4
0.5
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Average Cost (in $)
Parameter for Proactive Algorithm
TotalCost
VMCost
PenaltyVMReserve
PenaltySLABreak
Figure 5: Variation in the average cost versus τ for the
Proactive algorithm.
imizing the SLA violation duration and minimizing
the average penalty, the range 0 ≤ τ ≤ 0.75 is consid-
ered to be optimal.
Fig. 5 presents the results on average cost incurred
with varying τ. The red line represents the average
VM cost (Eq. 3), which is almost constant with the
variation in τ. The green line represents the average
penalty incurred due to SLA violation of one or more
endpoints, which has already been analyzed above.
The penalty incurred due to the proactive reservations
of VMs is depicted by the blue line. It is evident from
Fig. 5 that this penalty linearly decreases with increas-
ing τ, with its maximum value when τ = 0 and mini-
mum value when τ = 1. The total cost represented by
the purple line, is the sum of the VM cost and the two
penalties discussed above. It is evident that the total
cost first linearly decreases till τ = 0.65, becomes al-
most constant till τ = 0.75 and then starts to increase
rapidly with the increase in τ. Thus, with respect to
minimizing the total cost, 0.65 ≤ τ ≤ 0.75 serves as
the optimal range for parameter τ.
Next, we compare the total and the average cost
for the proposed algorithms – (1) passive, (2) reactive
and (3) proactive. Note that the proactive algorithm
will use τ = 0.60 for all the following comparisons.
Fig. 6 portrays the variation in total cost with the
time of day for the three proposed algorithms. It is
not surprising to see that the passive algorithm pos-
sesses the least total cost. Since, no new VM reserva-
tions happen, even when N
i
running
exceeds N
i
max
, the
VM costs are kept at a bare minimum. On the other
hand, since new VM reservations happen for both re-
active and proactive algorithms, the costs are natu-
rally higher here. The costs for the reactive algorithm
are higher, at certain times, when compared to the
proactive algorithm owing to the penalties occurred
due to breaking the SLAs. Note that, although the
costs incurred by the reactive and the proactive algo-
rithm are higher when compared to that of the passive
algorithm, this cost is warranted (i.e. it is not due to
sub-optimal utilization of VM resources, but should
be seen as a necessity in attaining the workflow SLAs
Design and Evaluation of Automatic Workflow Scaling Algorithms for Multi-tenant SaaS
227
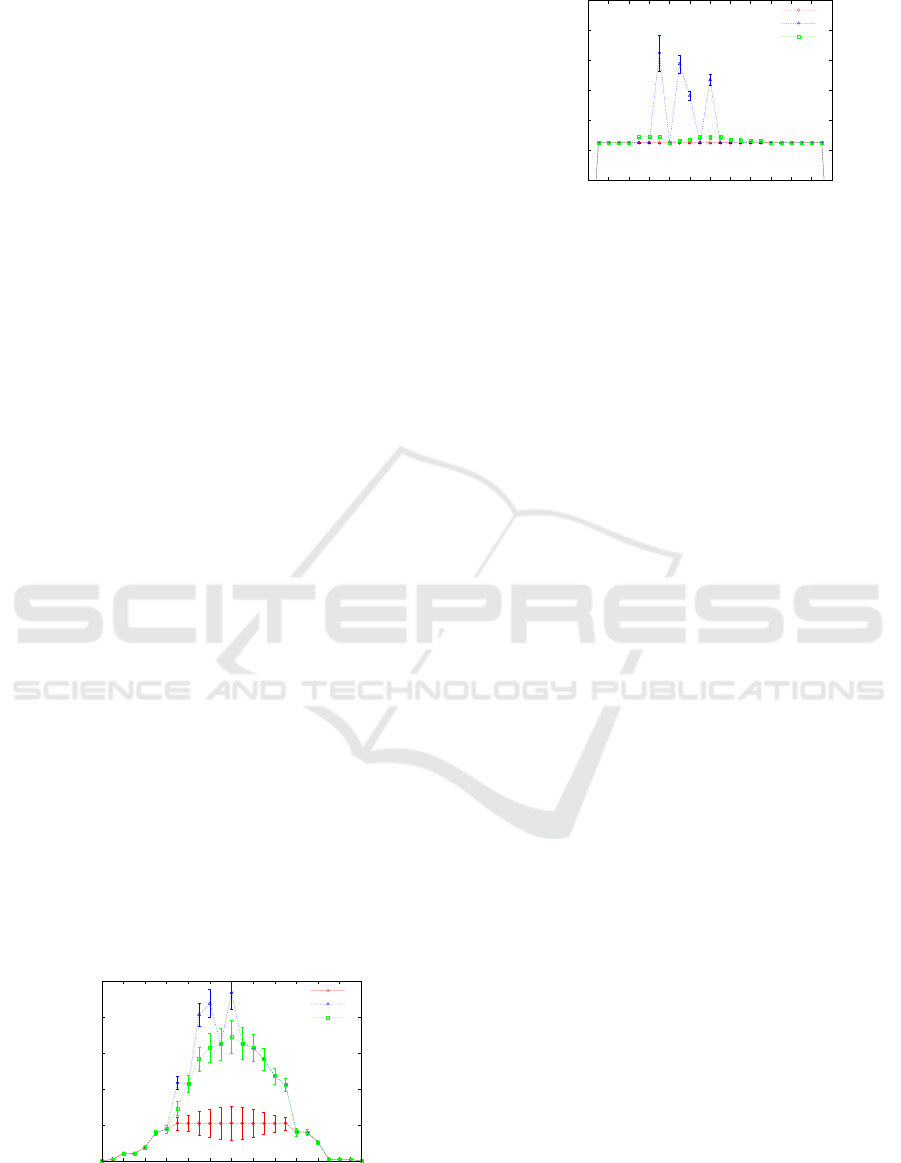
for the given number of multi-tenant requests).
To substantiate the above argument, we also com-
pare the variation in the average cost, with the time
of day for the proposed algorithms. It is evident from
Fig. 7 that the average cost of all the three algorithms
are almost similar at majority of the time instances.
Note that the portrayed costs also include the penal-
ties incurred, if any. At certain instances, the average
cost of the reactive algorithm is the highest, which
is the result of the penalties incurred due to the VM
reservation process starting only after the SLAs are
broken. Since the proactive algorithm, triggers the
new VM reservation process prior to detecting viola-
tion in the SLAs, the penalties incurred for this algo-
rithm are significantly lower when compared to that of
the reactive algorithm. The only penalty incurred on
the proactive algorithm is due to the pre-reservation
of VMs, which is optimized for τ = 0.60 as discussed
above. The costs for the proactive algorithm are al-
most similar to that of the passive algorithm, while
being marginally higher only at certain times.
To summarize, the proactive algorithm with τ in
the range 0.60 ≤ τ ≤ 0.75 serves as the best possible
trade-off for minimizing the costs while also keeping
the SLAs of the components in line.
7 CONCLUSIONS
In this paper we have proposed algorithms that al-
low automatic scaling of SLA-bound SaaS workflows
consisting of multiple (SaaS) service endpoints based
on monitored application multi-tenancy (where client
request rates can highly fluctuate based on the time
of day). The effectiveness of these algorithms was
demonstrated using a simulated use case of a profes-
sional cloud-based A/V collaboration service. These
algorithms kept track of the SLAs of each workflow
component and, for the most advanced proactive al-
gorithm, reserved new VMs before SLAs were to be
broken, thus, providing the best possible trade-off be-
tween cost efficiency and quality-of-service.
0
15
30
45
60
75
0 2 4 6 8 10 12 14 16 18 20 22 24
Cost (in $)
Time of Day (in hours)
Passive
Reactive
Proactive
Figure 6: Comparing variation in the total cost versus the
time of day for the passive, reactive and proactive algorithm.
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0 2 4 6 8 10 12 14 16 18 20 22 24
Average Cost (in $)
Time of Day (in hours)
Passive
Reactive
Proactive
Figure 7: Comparing variation in the average cost versus the
time of day for the passive, reactive and proactive algorithm.
Future work will see us extending our algorithms
with more advanced issues like dealing with service
robustness and resource/connection failures. Another
line of research will involve mapping SaaS applica-
tions and workflows to the TOSCA standard, thus en-
abling their standardization and use of management
plans (Binz et al., 2014) for automatic scaling.
ACKNOWLEDGEMENTS
This research is partly funded by the IWT SBO De-
CoMAdS project.
REFERENCES
Antonescu, A. F. and Braun, T. (2014). Sla-driven simu-
lation of multi-tenant scalable cloud-distributed enter-
prise information system. In ARMS-CC.
Bellenger, D., Bertram, J., Budina, A., Koschel, A., Pfan-
der, B., and Serowy, C. (2011). Scaling in cloud envi-
ronments. In WSEAS.
Binz, T., Breitenb
¨
ucher, U., Kopp, O., and Leymann, F.
(2014). Advanced Web Services, chapter TOSCA:
Portable Automated Deployment and Management of
Cloud Applications.
Calheiros, R. N., Ranjan, R., Beloglazov, A., Rose, C. A.
F. D., and Buyya, R. (2011). Cloudsim: A toolkit for
modeling and simulation of cloud computing environ-
ments and evaluation of resource provisioning algo-
rithms. Softw. Pract. Exper., 41(1).
Espadasa, J., Molinab, A., Jimneza, G., Molinab, M., Ram-
reza, R., and Conchaa, D. (2013). A tenant-based
resource allocation model for scaling software-as-a-
service applications over cloud computing infrastruc-
tures. FGCS, 29(1).
Glitho, R. H. (2011). Cloud-based multimedia conferenc-
ing: Business model, research agenda, state-of-the-
art. In CEC.
Guo, C. J., Sun, W., Huang, Y., and Gao, B. (2007). A
framework for native multi-tenancy application devel-
opment and management. In CEC.
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
228

L. Wu, S. K. G. and Buyya, R. (2011). Sla-based resource
allocation for software as a service provider (saas) in
cloud computing environments. In CCGrid.
L. Wu, S. K. G. and Buyya, R. (2012). Sla-based admission
control for a software-as-a-service provider in cloud
computing environments. JCSS, 78(5).
L. Wu, S. K. G., Versteeg, S., and Buyya, R. (2014). Sla-
based resource provisioning for hosted software-as-
a-service applications in cloud computing environ-
ments. IEEE TSC, 7(3).
Morshedlou, H. and Meybodi, M. (2014). Decreasing im-
pact of sla violations:a proactive resource allocation
approach for cloud computing environments. IEEE
TCC, 2(2).
Soltanian, A., Salahuddin, M. A., Elbiaze, H., and Glitho,
R. (2015). A resource allocation mechanism for video
mixing as a cloud computing service in multimedia
conferencing applications. In CNSM.
Taheri, F., George, J., Belqasmi, F., Kara, N., and Glitho, R.
(2014). A cloud infrastructure for scalable and elastic
multimedia conferencing applications. In CNSM.
W.Tsai and Zhong, P. (2014). Multi-tenancy and sub-
tenancy architecture in software-as-a-service (saas).
In SOSE.
Design and Evaluation of Automatic Workflow Scaling Algorithms for Multi-tenant SaaS
229
