
CIAO-WPS
Automatic and Intelligent Orchestration of Geospatial Web Services using Semantic
Web (Web 3.0) Technologies
Chet Bing Tan, Geoff West, David A. McMeekin and Simon Moncrieff
Curtin University, Cooperative Research Centre for Spatial Information, Bentley, Australia
Keywords:
Semantic Web, Web 3.0, Ontologies, Metadata, Web Processing Services, WPS, CIAO-WPS.
Abstract:
Current geospatial datasets and web services are disparate, obscure and difficult to expose to the world. With
the advent of geospatial processes utilizing temporal data and big data, along with datasets continually increas-
ing in size, the problem of under-exposed datasets and web services is amplified. Current text search capabil-
ities do not sufficiently expose web services and datasets for use in on-the-fly geospatial use cases. End users
are required to know the exact location of these online resources, their format and what they do. For example,
to locate an OGC (Open Geospatial Consortium - http://www.opengeospatial.org)-compliant WPS (Web Pro-
cessing Service) that performs flood modelling, a Google Search for “Flood Modelling WPS” is insufficient
to find relevant results. This paper proposes the integration of semantic web concepts and technologies into
geospatial datasets and web services, making it possible to link these datasets and services via functionality,
the inputs required and the outputs produced. To do so requires the extensive use of metadata to allow for
a standardised form of description of their function. There are already ISO (International Organization for
Standardization - www.iso.org) standards in place (ISO 19115-1:2014) that specify the schema required for
describing geographic information and services. The use of ontologies and AI (Artificial Intelligence) then
allows for the intelligent determination of which web services and datasets to use, and in what order they are
to be used to achieve the desired final output. This research aims to provide a method to automatically and
intelligently chain together web services and datasets to assist in a geospatial analyst’s productivity. A sim-
ple prototype termed CIAO-WPS (Chet’s Intelligent, Automatically-Orchestrated Web Processing Services)
is created as a proof of concept, using the Python programming language. The prototype seeks to reinforce
ideas in regards to pathing and cost constraints, as well as explore overlooked designs.
1 INTRODUCTION
ACIL Tasman (ACIL Tasman, 2008) determined that
inefficient access to geospatial data is estimated to
have reduced the direct productivity impacts in certain
sectors by around $0.5 billion, and that reductions in
these inefficiencies will contribute to Australia’s eco-
nomic, social and environmental development goals.
This is not only due to the current exposure issues
of geospatial datasets and web services, but also the
manual processing and workflows involved in chain-
ing together these resources to achieve a task.
Current geospatial workflows that include geospa-
tial web services (for example, flood prediction within
a given area) are manual, requiring the chaining to-
gether and intervention between the running of pro-
cesses to be manually performed to ensure the rele-
vant output is generated. The possible introduction
of human error as a result of manually processing
and searching the datasets and/or web services also
increases the probability that the output generated is
based on out-dated or even irrelevant data.
There are currently many inefficiencies with pro-
cessing and using geospatial data. Yu and Liu (Yu
and Liu, 2013) have documented these similar ineffi-
ciencies in their attempts to implement a new system
that republishes real-world data as linked geo-sensor
data. Janowicz (Janowicz and Blomqvist, 2012) has
also observed in their survey of semantically-enabled
DSS (Decision Support Systems), that the users of
said system still require a lot of work in increasing
the efficiency and productivity of the intelligent sys-
tem. The research outcomes of this project aligns with
the conclusions of the survey.
The ability to automatically and intelligently or-
chestrate multiple geospatial web services to provide
intelligent and useful output from a complex user
Tan, C., West, G., McMeekin, D. and Moncrieff, S.
CIAO-WPS - Automatic and Intelligent Orchestration of Geospatial Web Services using Semantic Web (Web 3.0) Technologies.
In Proceedings of the 2nd International Conference on Geographical Information Systems Theory, Applications and Management (GISTAM 2016), pages 71-79
ISBN: 978-989-758-188-5
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
71

query will greatly assist a geospatial analyst’s effi-
ciency, accuracy and productivity. Being able to or-
chestrate geospatial datasets and WPS to achieve a
task will be adaptable to other fields as well. Integrat-
ing Semantic Web concepts and technologies into var-
ious non-geospatial datasets and Web Services will al-
low for automatic orchestration and hence, increased
productivity. As an example, Kauppinen (Kauppinen
et al., 2014) has documented how semantic technolo-
gies are being integrated within Brazilian Amazon
Rainforest data, that has led to increased productiv-
ity and efficiency in that area.
To advance automated and intelligent orchestra-
tion, certain features and specifications must be added
to the current WPS standard to allow for machine in-
terpretation of these Web Services, to be able to ef-
fectively and reliably determine which Web Services
are appropriate for completing a given task. Critical
information that paves the way for automatic orches-
tration are currently not defined in the WPS specifica-
tion and this research aims to set an example for the
addition of metadata and functions that allow for au-
tomatic orchestration as the next logical step for WPS.
This paper explores automated orchestration
methods of web services and data from multiple, dis-
parate sources; in contrast to the current widespread
method of supplying all the data and services to the
end user and leaving it to them to manually analyse
and process the vast amounts of varying kinds of data,
and determine what processing needs to be executed.
Natural language processors and ontologies are pro-
posed to build the required Artificial Intelligence to
automatically chain together the resources to produce
useful output for the end user.
2 BACKGROUND
In the last decade, the Web has been moving to-
wards Service-Oriented Computing architecture sup-
porting automated use (Ameller et al., 2015) (Huhns
and Singh, 2005). This architecture aims to build a
network of interoperable and collaborative applica-
tions, independent of platform, called services (Pa-
pazoglou and Georgakopoulos, 2003) (Pugliese and
Tiezzi, 2012). The geospatial world is also mov-
ing away from the traditional desktop application
paradigm to processing and accessing data on-the-fly
from the Web using Web Processing Services, as out-
lined by Granell et al. (Granell et al., 2012). As Web
Service technology has matured in recent years, an
increasing amount of geospatial content and process-
ing capabilities are available online as Web Services
(Zhao et al., 2012). These Web Services enable inter-
operable, distributed, and collaborative geoprocessing
to significantly enhance the abilities of users to col-
lect, analyze and derive geospatial data, information,
and knowledge over the Internet (Zhao et al., 2012).
Current geospatial workflows and processes rely
on manual human intervention in searching for the
relevant and/or required datasets and Web Services
(Granell et al., 2012). These workflows also require
human analysis of the output at each stage of process-
ing, and manual determination of which Web Process-
ing Service to use next on the data to achieve the final
required output (Granell et al., 2012). This has been
observed to lead to inefficiencies in the accuracy and
currency of the data as we are relying on a human user
to search for these ill-exposed datasets and Web Ser-
vices. For example, a human user will tend to have a
bias towards a dataset or Web Service that he/she has
used before, regardless of the currency of the data or
the frequency of updating of the data, a phenomenon
known as the Mere-repeated-exposure paradigm (Za-
jonc, 2001). Geospatial Web Services and datasets
that may be vital in contributing to the final result
may also be left unexposed due to current search tech-
nologies not being able to expose Web Services suffi-
ciently. The way that Web Services are searched for is
by functional and non-functional requirements as well
as interactive behaviour (Wu, 2015a), which require
more than simple keyword matching, as per current
search algorithms.
2.1 The Semantic Web (Web 3.0)
The Semantic Web aims to create a web of infor-
mation that is machine-readable and not just human-
readable (Berners-Lee et al., 2001). This allows ma-
chines to automatically find, combine and act upon
information found on the Web (Pulido et al., 2006).
The objective of the Semantic Web is accom-
plished by integrating semantic content into web
pages that helps describe the contents and context of
the data in the form of metadata (data about data)
(Handschuh and Staab, 2003). This greatly improves
the quality of the data so that a machine is able to un-
derstand what the data is for, what it can be used for
and what other things are linked to it (Harth, 2004)
(Berners-Lee et al., 2001). This allows the machine
to process and use the data, instead of the current
paradigm of relying on a human to interpret, process
and understand data.
Ontologies are a core component of the Semantic
Web, and are required by machines to be able to in-
telligently reason and infer data (Pulido et al., 2006).
An ontology is a set of data elements within a domain
that are linked together to denote the types, proper-
GISTAM 2016 - 2nd International Conference on Geographical Information Systems Theory, Applications and Management
72

ties and relationships between them (Beydoun et al.,
2014). Ontologies contribute to resolve semantic het-
erogeneity by providing a shared comprehension of a
given domain of interest (Nacer and Aissani, 2014).
In knowing the relationships that exist between data,
search can be expanded to incorporate relationships
that exist between the data as well as traditional string
matching. The search is now a semantically intelli-
gent search.
Put simply, the Semantic Web aims to create a web
of knowledge and information that is both machine
and human-readable (Pulido et al., 2006)(Berners-
Lee et al., 2001). This consequently allows the ca-
pability for machines to automatically find, combine
and act upon information found on the Semantic Web.
There are currently well-defined, open standards
in place for moving towards Web 3.0, where resources
and ontologies are shared (World Wide Web Consor-
tium, 2001). The advantage of this is that there is
no reinvention of the wheel, however there is still
significant development required in integrating Se-
mantic Web techniques into spatial applications. To
aid in the movement towards semantic spatial data
manipulation, the OGC has established standards for
storing, discovering and processing geospatial infor-
mation (Janowicz et al., 2010). Having these stan-
dards (W3C -World Wide Web Consortium and OGC
- Open Geospatial Consortium) to work with creates
the ability to simplify any data collected from multi-
ple sources that are usually stored in their own unique
proprietary formats, and create a standardised format
of the spatial data and processes for use both in re-
search and in industry.
2.2 The OGC WPS Standard
Web Processing Services, as their name suggests, pro-
vide services over the Internet to consumers, be it data
access or processing. They are client-side platform-
independent and have standardized input and output
protocols so that consumers are able to utilize these
Web Services (Wu, 2015b).
It is not uncommon for a company website to be
converted into an interactive, completely-automated,
web-based application (such as those for stock trad-
ing, electronic commerce, on-line banking, travel
agencies, etc) (Kov
´
acs and Kutsia, 2012). It is worth
noting that to achieve reliable application develop-
ment, appropriate specification and verification tech-
niques and tools are required. Systematic, formal ap-
proaches to the analysis and verification of a web ser-
vice or application can deal with the problems of this
particular domain by automated and trustworthy tools
that also incorporate semantic aspects (Kov
´
acs and
Kutsia, 2012).
In the geospatial world, the OGC is the main stan-
dards body for geospatial data and technology. The
standard published by the OGC in regards to Web
Processing Services is currently in its second itera-
tion (v2.1), that brings about enhanced features to im-
prove the functionality of web services, especially in
regards to asynchronous operation and error handling.
However there has been little work on the orches-
tration of Web Services. This research requires the
adding of functionality to the standard.
The OGC WPS standard sets out the groundwork
for exposing features, inputs and outputs and process-
ing of a geospatial web service (Lopez-Pellicer et al.,
2012). Loosely defined, it simply describes the syntax
and minimal requirements of a geospatial Web Pro-
cessing Service.
An example of a WPS is a service that provides
polygon intersection capabilities. A user provides two
or more polygons as input to the WPS and receives a
polygon of their intersections as output, or a NULL
value if the polygons provided do not intersect. The
WPS is specific as to what format and coordinate ref-
erence systems are used in the polygons that it pro-
cesses.
Using and extending the WPS specification for or-
chestration within a workflow is not a foreign con-
cept in the geospatial community. For example, a
partially manual system of orchestrating PyWPS (A
Python implementation of WPS) within Taverna has
been proposed to assist in their efforts to assess mod-
elling in urban areas (De Jesus et al., 2012). This
workbench for mapping business processes and work-
flows to chains of web services to complete geospatial
tasks shows promise and feasibility.
By integrating Semantic Web concepts in the form
of ontologies and metadata tags, as well as improve-
ments and expansion of the OGC WPS standard (and
possibly other open standards as seen fit), it is possi-
ble to expose all these useful datasets and Web Ser-
vices that the user hasn’t considered through better
metadata and linking them through ontologies. The
use of Semantic Web technologies allows us to look
for meaning, rather than simple keyword matching.
While this has been achieved to a certain degree
in generic, publically-available search engines such
as Google by utilizing semantic analysis algorithms
(Cilibrasi and Vit
´
anyi, 2007), there has been little de-
velopment in the geospatial area.
CIAO-WPS - Automatic and Intelligent Orchestration of Geospatial Web Services using Semantic Web (Web 3.0) Technologies
73
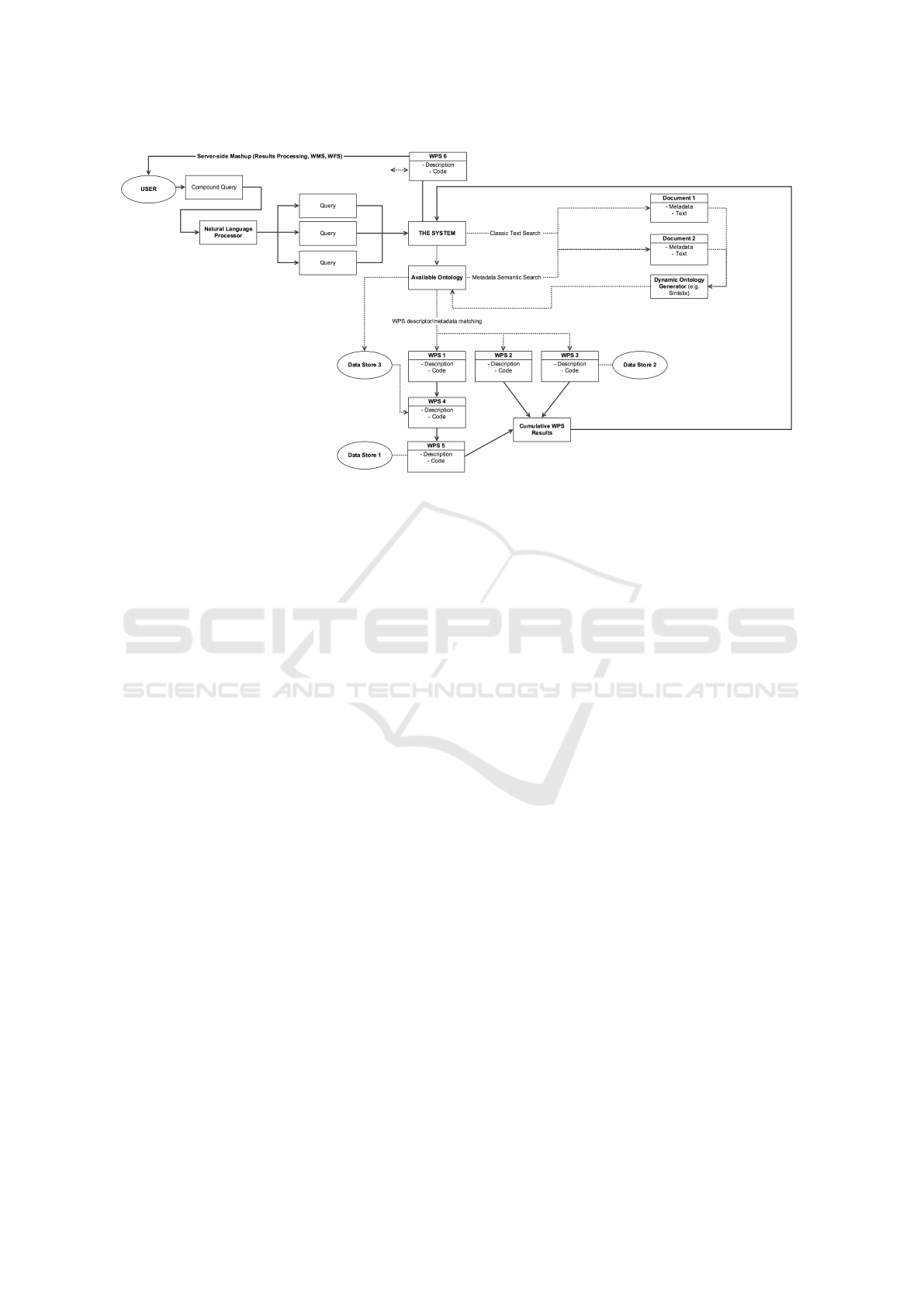
Figure 1: A system flow diagram of how a user query is processed through CIAO-WPS.
3 APPROACH
To automate the orchestration process, there are sev-
eral essential aspects that must be developed to assist
in this regard.
Firstly, NLP (Natural Language Processing)
methods require investigation to determine the mean-
ing of a user query and semantically search for infor-
mation using ontologies. In situations where a rel-
evant ontology is not available, a classic text search
may be executed and an ontology dynamically gener-
ated on-the-fly from the search results using an off-
the-shelf product. In this scenario, ontologies may be
used akin to a workflow, where information and pro-
cess interdependencies are linked.
Secondly, Artificial Intelligence is explored that
utilizes ontologies to determine what Web Services
and datasets are required to generate an accurate re-
sult to the user’s query. Ontologies may then be
used to link together the functions, inputs and out-
puts of the web resources allowing the AI solution to
determine which order the web services will run in
to achieve an output that will satisfy the end user’s
query.
Finally, we identify enhancements for the OGC’s
open standard for WPS by adding functionality and
supporting metadata to allow for automatic orchestra-
tion by the AI system developed under this research.
An overview of such a proposed system can be
seen in Figure 1.
The user firstly feeds a complex query in natu-
ral language to the system. The query is then bro-
ken down to simple, modular queries for ease of un-
derstanding using the NLP. These individual queries
are then searched for in any available ontologies, and
if the available ontologies are not available, the dy-
namic ontology generator is used to create ontolo-
gies on-the-fly using documentation and expert do-
main knowledge from trusted sources, obtained via
classic text search from the Internet. Alternatively a
system can also be put in place to query the user for
additional information and details that will help com-
plete the search.
With multiple ontologies on-hand and ready-to-
use, information in regards to the user’s original query
can be searched within the ontologies to obtain links
for, and between datasets and relevant web services.
Using rules of inference and logic processing via AI,
we are able to obtain a chain of Web Services and
datasets in order to satisfy the user query. The se-
quence in which these datasets and Web Services are
invoked in is also important; this is catered for by
the AI. Multiple pathing and costing options can also
be provided for the user to determine the most cost-
efficient path to the end result (processing time or
payment to use). An example of how multiple paths
may lead to the same outcome is shown in Figure 2.
The end result, however, may not always be in the
most relevant form to be utilized by the user. If that
is the case, we can rely on Web Services to transform
the final output to a more usable form. For example,
a table of rainfall predictions is not as readily-usable
to a human user in comparison to a percentage chance
of rain in an area, drawn on a map using a WFS (Web
GISTAM 2016 - 2nd International Conference on Geographical Information Systems Theory, Applications and Management
74
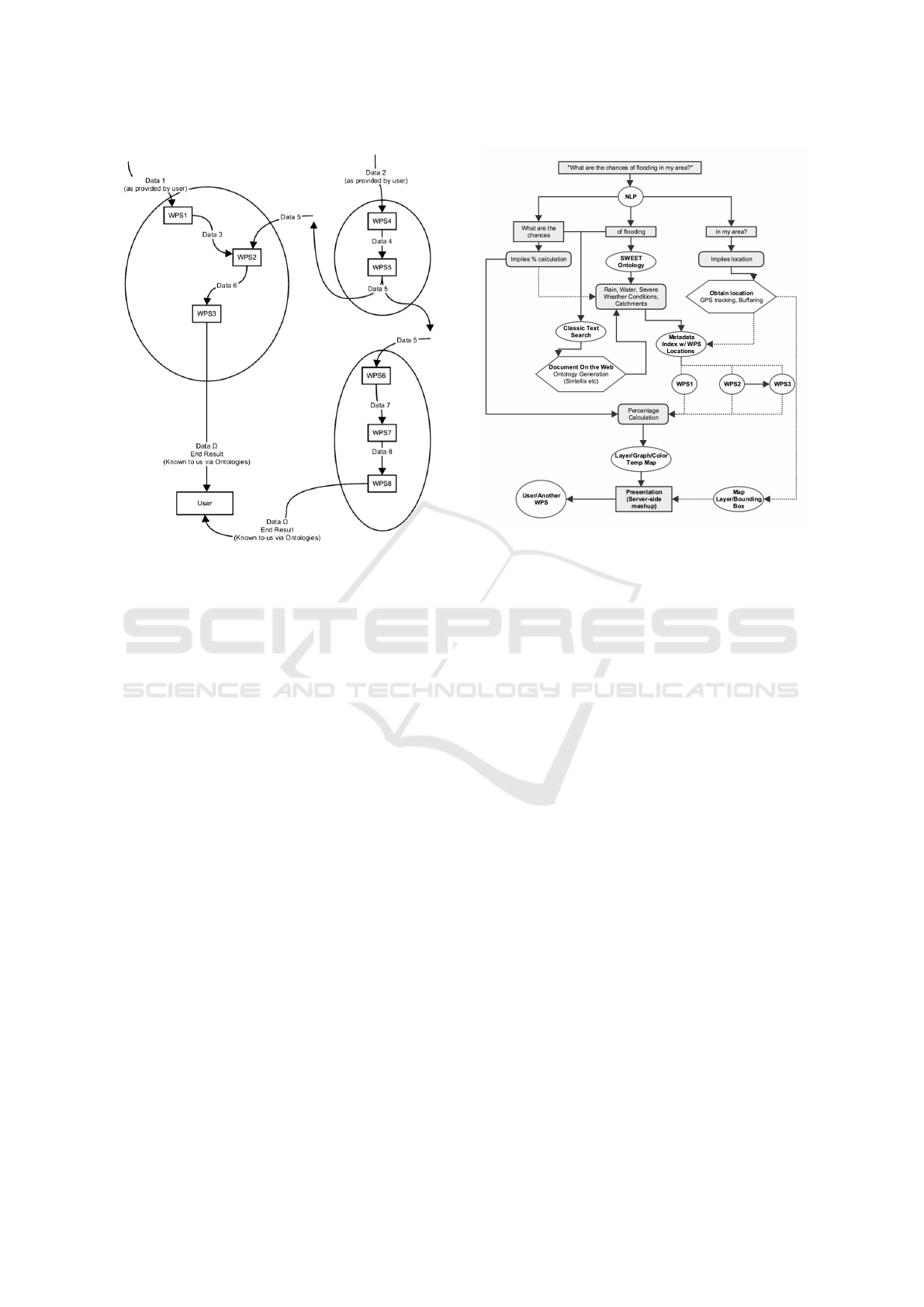
Figure 2: Different paths for the same outcome.
Feature Service) or WMS (Web Map Service) derived
from the table data to show different rainfall chances
in different areas of the map via heat layers.
4 USE CASE SCENARIO
A typical scenario that shows how CIAO-WPS may
be utilized is shown in Figure 3. The following para-
graphs will guide the reader through the diagram.
In this example, the user feeds a complex, natural-
language query into the system. NLP breaks the query
down into three separate sections. “What are the
chances”, “of flooding” and “in my area”.
Based on “in my area”, CIAO-WPS realizes the
statement implies location of the user and therefore
the first step would be to obtain the location of the
user as this will provide very important context for
the other queries. This could use simple GPS on the
user’s smart phone/device.
With an ontology such as the SWEET (Semantic
Web for Earth and Environmental Technology) ontol-
ogy readily available to CIAO-WPS, the system looks
up “flooding” within the ontology, that will give links
to elements such as “rain”, “water”, “severe weather
condition”. These elements will further give links to
information such as links to BOM (Bureau of Mete-
orlogy) severe weather warning services or flood pre-
diction Web Services, for example. As for the “in my
Figure 3: A sample use case scenario of CIAO-WPS.
area” section, the location of the user becomes ex-
tremely important at this point as CIAO-WPS will fo-
cus on the vicinity of the user.
“What are the chances” prompts CIAO-WPS that
this is most likely a percentage/likelihood calculation.
This contextual information is fed into the search for
related Web Services and datasets.
With the query broken down, CIAO-WPS will at-
tempt to use traditional text-search tools or further
delve into more specialized ontologies to obtain more
information and methodologies to obtain the relevant
Web Services and datasets. This in turn could re-
veal more critical information such as workflows that
provide a more authoritative source of guidance as
to what Web Services and what datasets to access in
what order.
Using AI and OWL-DL, CIAO-WPS attempts to
obtain a path that fits in with user-defined restrictions
and will fulfill the user’s query. If a section or piece
of information along the path is unavailable, CIAO-
WPS will notify the user and fallback into a semi-
supervised mode, in which the user may provide the
needed information or direct which path CIAO-WPS
should take.
In this case, we assume that all information is ob-
tained successfully within the user’s set parameters.
The results are accumulated by CIAO-WPS. However
what the system has obtained is simply polygons in
the vicinity with a percentage chance of flooding at-
tached.
This would not be useful to the user and therefore
CIAO-WPS - Automatic and Intelligent Orchestration of Geospatial Web Services using Semantic Web (Web 3.0) Technologies
75

CIAO-WPS draws the polygons on a map, while col-
oring in the chances of flooding with different inten-
sities using a heat scale. This is much more useful to
a human user than presenting the user with a table of
numbers and coordinates for the edges of the polygon.
5 PROTOTYPE
A proof-of-concept model of CIAO-WPS has been
built, with focus mainly on the chaining of WPS via
metadata added outside of the OGC WPS standard.
An Agile approach has been used for software devel-
opment used in developing CIAO-WPS, prototypes
and proof-of-concepts of modules of the system are
continuously built and discarded to serve as reality
and logic checkers for the research. At the moment
the working proof-of-concept is currently available at
http://research.haxx.net.au/cwps
The prototype was created in Python using classes
to serve as “dummy” WPS with input and output for-
mats and their parameters. Additional information
such as response time and algorithmic complexity
were added as well to explore these ideas further.
In Figure 4, we see a dummy WPS that is a Fire
Modelling WPS, with appropriate metadata in its Get-
Capabilities section and its input (US date in the for-
mat mm/dd/yyyy). It outputs a polygon in vector for-
mat of the predicted fire area. This WPS has metadata
that states that it has a high cost but a quick response
time and a relatively simple algorithmic complexity.
In Figure 5, we see another dummy WPS that also
Figure 4: Dummy Fire Modelling WPS 1.
performs fire predictions, with appropriate metadata
in its GetCapabilities section and its input (US date in
the format mm/dd/yyyy), similar to the first fire mod-
elling WPS. It outputs a polygon in vector format of
the predicted fire area. The metadata of this version
states that it has no cost but a slower response time
and a relatively more complex algorithmic complex-
ity. In Figure 6, we see a dummy WPS that is a date
Figure 5: Dummy Fire Modelling WPS 2.
Figure 6: Dummy Date Format Conversion WPS.
format conversion WPS, with appropriate metadata
in its GetCapabilities section and its input (American
GISTAM 2016 - 2nd International Conference on Geographical Information Systems Theory, Applications and Management
76

date in the format mm-dd-yyyy). It outputs an Amer-
ican date in the format mm/dd/yyyy.
In Figure 7, we see a dummy WPS that is a re-
gional date conversion WPS, with appropriate meta-
data in its GetCapabilities section and its input (Aus-
tralian date in the format dd-mm-yyyy). It outputs an
Figure 7: Dummy AUS to US Date Conversion WPS.
Figure 8: CIAO-WPS Proof-of-concept Search Interface.
American date in the format mm-dd-yyyy.
The interface for this proof-of-concept can be ob-
served in Figure 8, where the user wants to do “fire
modelling”, but only has an Australian date in the for-
mat dd-mm-yyyy as input.
Finally in Figure 9 we have the results displayed.
CIAO-WPS does a custom-tuned BFS (Breadth-First
Search) to explore successful paths and choose the
path that satisfies the user’s constraints. At this stage,
the prototype will reveal multiple options for shortest,
simplest, cheapest and most responsive paths. This
idea translates to a semi-supervised operation in the
final system.
6 CONCLUSION AND FUTURE
PLANS
This paper has proposed the workings of a system in
development that aims to automate the orchestration
of WPS intelligently using Semantic Web techniques
and concepts. The proof of concept shows the meta-
data required for orchestration that is not present in
the WPS 2.1 standard. The advantages that CIAO-
WPS hopes to achieve are increased productivity and
efficiency, reduced manpower in locating resources,
reduction and possible elimination of the manual, hu-
man analysis and linking of related datasets and WPS.
CIAO-WPS, throughout its development, strives to
improve itself from other attempts of orchestration by
adding automation and intelligence.
Future plans for CIAO-WPS is the full integration
and use of ontologies in the decision-making process
of choosing paths and the order in which Web Ser-
vices are run. Using OWL-DL will allow for more
complex constraints such as file server location re-
strictions. Further improvements to the search algo-
rithm are also planned for better efficiency when large
numbers of WPS are involved. This ensures consis-
tent response times for users in time-demanding ap-
plications. Finally, a learning algorithm that ranks
paths based on past successful queries will also be ex-
plored.
ACKNOWLEDGEMENT
The work has been supported by the Cooperative Re-
search Centre for Spatial Information, whose activi-
ties are funded by the Business Cooperative Research
Centres Program.
CIAO-WPS - Automatic and Intelligent Orchestration of Geospatial Web Services using Semantic Web (Web 3.0) Technologies
77

Figure 9: CIAO-WPS Proof-of-concept Results.
REFERENCES
ACIL Tasman (2008). The Value of Spatial Information -
The impact of modern spatial information technolo-
gies on the Australian economy. Technical report.
Ameller, D., Burgu
´
es, X., Collell, O., Costal, D., Franch,
X., and Papazoglou, M. P. (2015). Development of
service-oriented architectures using model-driven de-
velopment: A mapping study. Information and Soft-
ware Technology, 62:42–66.
Berners-Lee, T., Hendler, J., and Lassila, O.(2001). The
Semantic Web. Scientific American, May 2001:28–37.
Beydoun, G., Low, G., Garc
´
ıa-S
´
anchez, F., Valencia-
Garc
´
ıa, R., and Mart
´
ınez-B
´
ejar, R. (2014). Identifi-
cation of ontologies to support information systems
development. Information Systems, 46:45–60.
Cilibrasi, R. L. and Vit
´
anyi, P. M. B. (2007). The Google
Similarity Distance. IEEE Transactions On Knowl-
edge And Data Engineering, 19(3):370–383.
De Jesus, J., Walker, P., Grant, M., and Groom, S. (2012).
WPS orchestration using the Taverna workbench: The
eScience approach. Computers and Geosciences,
47:75–86.
Granell, C., D
´
ıaz, L., Tamayo, A., and Huerta, J. (2012).
Assessment of OGC Web Processing Services for
REST principles. International Journal of Data
Mining, Modelling and Management (Special Issue
on Spatial Information Modelling, Management and
Mining).
Handschuh, S. and Staab, S. (2003). CREAM: CREAting
Metadata for the Semantic Web. Computer Networks,
42(5):579–598.
Harth, A. (2004). An integration site for Semantic Web
metadata. Web Semantics: Science, Services and
Agents on the World Wide Web, 1(2):229–234.
Huhns, M. N. and Singh, M. P. (2005). Service-Oriented
Computing: Key Concepts and Principles Service-
Oriented Computing: Key Concepts and Principles.
IEEE Internet Computing, 9(1):75–81.
Janowicz, K. and Blomqvist, E. (2012). The Use of Se-
mantic Web Technologies for Decision Support - A
Survey. Semantic Web Journal, 5(3):177–201.
Janowicz, K., Schade, S., Keßler, C., Mau
´
e, P., and Stasch,
C. (2010). Semantic Enablement for Spatial Data In-
frastructures. Transactions in GIS, 14(2):111–129.
Kauppinen, T., Mira De Espindola, G., Jones, J., S
´
anchez,
A., Gr
¨
aler, B., and Bartoschek, T. (2014). Linked
Brazilian Amazon Rainforest Data. Semantic Web,
5(2):151–155.
Kov
´
acs, L. and Kutsia, T. (2012). Special issue on Auto-
mated Specification and Verification of Web Systems.
Journal of Applied Logic, 10(1):1.
Lopez-Pellicer, F. J., Renter
´
ıa-Agualimpia, W., B
´
e, R. N.,
Muro-Medrano, P. R., and Zarazaga-Soria, F. J.
(2012). Availability of the OGC geoprocessing stan-
dard: March 2011 reality check. Computers and Geo-
sciences, 47:13–19.
Nacer, H. and Aissani, D. (2014). Semantic web ser-
vices: Standards, applications, challenges and solu-
tions. Journal of Network and Computer Applications,
44:134–151.
Papazoglou, M. and Georgakopoulos, D. (2003). Introduc-
tion: Service-oriented computing. Communications of
the ACM - Service-oriented computing, 46(10):24–28.
Pugliese, R. and Tiezzi, F. (2012). A calculus for orches-
tration of web services. Journal of Applied Logic,
10(1):2–31.
Pulido, J. R. G., Ruiz, M. A. G., Herrera, R., Cabello, E.,
Legrand, S., and Elliman, D. (2006). Ontology lan-
guages for the semantic web: A never completely up-
dated review. Knowledge-Based Systems, 19(7):489–
497.
World Wide Web Consortium (2001). W3C Semantic Web
FAQ.
Wu, Z. (2015a). Service Discovery. In Service Computing
- Concept, Method and Technology, chapter 4, pages
79–104.
Wu, Z. (2015b). Service-Oriented Architecture and Web
Services. In Service Computing - Concept, Method
and Technology, chapter 2, pages 17–42.
GISTAM 2016 - 2nd International Conference on Geographical Information Systems Theory, Applications and Management
78

Yu, L. and Liu, Y. (2013). Using Linked Data in a het-
erogeneous Sensor Web: challenges, experiments and
lessons learned. International Journal of Digital
Earth, 8(1):17–37.
Zajonc, R. B. (2001). Mere Exposure: A Gateway to the
Subliminal. Current Directions in Psychological Sci-
ence, 10(6):224–228.
Zhao, P., Lu, F., and Foerster, T. (2012). Towards a Geopro-
cessing Web. Computers and Geosciences, 47:1–2.
CIAO-WPS - Automatic and Intelligent Orchestration of Geospatial Web Services using Semantic Web (Web 3.0) Technologies
79
