
Cross-Domain Recommendations with Overlapping Items
Denis Kotkov, Shuaiqiang Wang and Jari Veijalainen
University of Jyvaskyla, Dept. of Computer Science and Information Systems,
P.O.Box 35, FI-40014 Jyvaskyla, Finland
Keywords:
Recommender Systems, Cross-Domain Recommendations, Collaborative Filtering, Content-Based Filtering,
Data Collection.
Abstract:
In recent years, there has been an increasing interest in cross-domain recommender systems. However, most
existing works focus on the situation when only users or users and items overlap in different domains. In
this paper, we investigate whether the source domain can boost the recommendation performance in the target
domain when only items overlap. Due to the lack of publicly available datasets, we collect a dataset from
two domains related to music, involving both the users’ rating scores and the description of the items. We
then conduct experiments using collaborative filtering and content-based filtering approaches for validation
purpose. According to our experimental results, the source domain can improve the recommendation perfor-
mance in the target domain when only items overlap. However, the improvement decreases with the growth
of non-overlapping items in different domains.
1 INTRODUCTION
Recommender systems use past user behavior to sug-
gest items interesting to users (Ricci et al., 2011). An
item is a piece of information that refers to a tangible
or digital object, such as a good, a service or a process
that a recommender system suggests to the user in an
interaction through the Web, email or text message.
The majority of recommender systems suggest
items based on a single domain. In this paper, the
term domain refers to “a set of items that share certain
characteristics that are exploited by a particular rec-
ommender system” (Fern
´
andez-Tob
´
ıas et al., 2012).
These characteristics are items’ attributes and users’
ratings.
However, the single domain recommender sys-
tems often suffer from data sparsity and cold start
problems. In order to overcome these limitations it
is possible to consider data from different domains.
Recommender systems that take advantage of mul-
tiple domains are called cross-domain recommender
systems (Fern
´
andez-Tob
´
ıas et al., 2012; Cantador and
Cremonesi, 2014).
In this paper, we consider a cross-domain recom-
mendation task (Cantador and Cremonesi, 2014), that
requires one target domain and at least one source do-
main. The former refers to the domain that suggested
items are picked from, and similarly the latter refers
to the additional domain that contains auxiliary infor-
mation.
Cross-domain recommender systems can be clas-
sified based on domain levels (Cantador and Cre-
monesi, 2014):
• attribute level - items can be assigned to different
domains according to their descriptions. One may
contain jazz music, while another may consist of
pop audio recordings;
• type level - items may have different types, but
share common attributes. Movie and book do-
mains have common genres, such as drama, com-
edy and horror, while movies and books have dif-
ferent types;
• item level - items from different domains may
have completely different attributes and types.
Songs and books might not share any common at-
tributes;
• system level - items may belong to different rec-
ommender systems, have the same type and share
many common attributes. For example, movies
from IMDb
1
and MovieLens
2
may belong to dif-
ferent domains.
Depending on whether overlapping occurs in the
set of users or items (Cremonesi et al., 2011), there
1
http://www.imdb.com/
2
https://movielens.org/
Kotkov, D., Wang, S. and Veijalainen, J.
Cross-Domain Recommendations with Overlapping Items.
In Proceedings of the 12th International Conference on Web Information Systems and Technologies (WEBIST 2016) - Volume 2, pages 131-138
ISBN: 978-989-758-186-1
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
131

are four situations that enable cross-domain recom-
mendations: a) no overlap between items and users,
b) user sets of different domains overlap, c) item sets
overlap, and d) item and user sets overlap.
In this work, we investigate whether the source
domain improves the recommendation performance
in the target domain on system level in the situation
when only items overlap. The idea behind the paper
is as follows. Traditional cross-domain recommender
systems utilize overlapping users to discover addi-
tional interests of users, leading to the improvement
of the recommendation diversity. When the items
overlap, the source domain lets detect more accurate
similarities between items, which should positively
result in recommendation performance in the target
domain.
Due to the lack of publicly available datasets for
cross-domain recommender systems with overlapping
items (Berkovsky et al., 2008; Kille et al., 2013), we
collected data from Vkontakte
3
(VK) – Russian on-
line social network (OSN) and Last.fm
4
(FM) – mu-
sic recommender service. We then matched VK and
FM audio recordings and developed the cross-domain
recommender system that suggests VK recordings to
VK users based on data from both domains. Each au-
dio recording is represented by its metadata excluding
the actual audio file. VK recordings thus represent
the target domain, while the source domain consists
of FM recordings. VK and FM recordings share titles
and artists, but have different user ratings and other
attributes.
In order to address the research question and illus-
trate the potential of additional data, we chose sim-
ple but popular recommendation algorithms to con-
duct experiments for validation: collaborative filter-
ing based on users’ ratings and content-based filtering
based on the descriptions of the items.
Our results indicate that the source domain can
improve the recommendation performance in the tar-
get domain. Furthermore, with the growth of non-
overlapping items in different domains, the improve-
ment of recommendation performance decreases.
This paper thus has the following contributions:
• we initially investigate the cross-domain recom-
mendation problem in the situation when only
items overlap;
• we collect a novel dataset to conduct the experi-
ments for addressing the research question.
The paper might be useful in real life scenarios.
For example, according to our results, the perfor-
mance of a recommender system lacking user rat-
3
http://vk.com/
4
http://last.fm/
ings to achieve an acceptable performance can be im-
proved using ratings collected from another recom-
mender system that suggests items of the same type.
However, the performance might decrease if the rec-
ommender systems do not have enough overlapping
items.
The rest of the paper is organized as follows. Sec-
tion 2 overviews related works. Section 3 describes
the datasets used to conduct experiments. Section 4 is
dedicated to recommendation approaches, while sec-
tion 5 describes conducted experiments. Finally, sec-
tion 6 draws final concussions.
2 RELATED WORKS
Most existing approaches consider additional infor-
mation about users to boost the recommendation per-
formance. For example, one of the first studies dedi-
cated to cross-domain recommender systems investi-
gated the effectiveness of source domains with over-
lapping users (Winoto and Tang, 2008). In the exper-
iment, undergraduates from a local university were
asked to rate items from different domains, such as
movies, songs and books. The authors measured rec-
ommendation performance in different domain com-
binations and concluded that source domains decrease
the recommendation performance, but may improve
the diversity of recommendations.
In contrast, other studies demonstrated that source
domains can boost the recommendation performance
in the target domain in situations when users or both
users and items overlap. For example, Sang demon-
strated the feasibility of utilizing the source domain.
The study was conducted on a dataset collected from
Twitter
5
and YouTube
6
. The author established rela-
tionships between items from different domains using
topics (Sang, 2014). Similarly to Sang, Shapira et al.
also linked items from different domains, where 95
participants rated movies and allowed the researches
to collect data from their Facebook pages. The re-
sults suggested that additional domains improve the
recommendation performance (Shapira et al., 2013).
Another study with positive results was conducted by
Abel et al. The dataset contained information related
to the same users from 7 different OSNs (Abel et al.,
2013). Sahebi et al. demonstrated the usefulness
of recommendations based on additional domains to
overcome cold start problem (Sahebi and Brusilovsky,
2013).
Most works on cross-domain recommender sys-
tems focus on the situation when users or both users
5
https://twitter.com/
6
https://www.youtube.com/
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
132
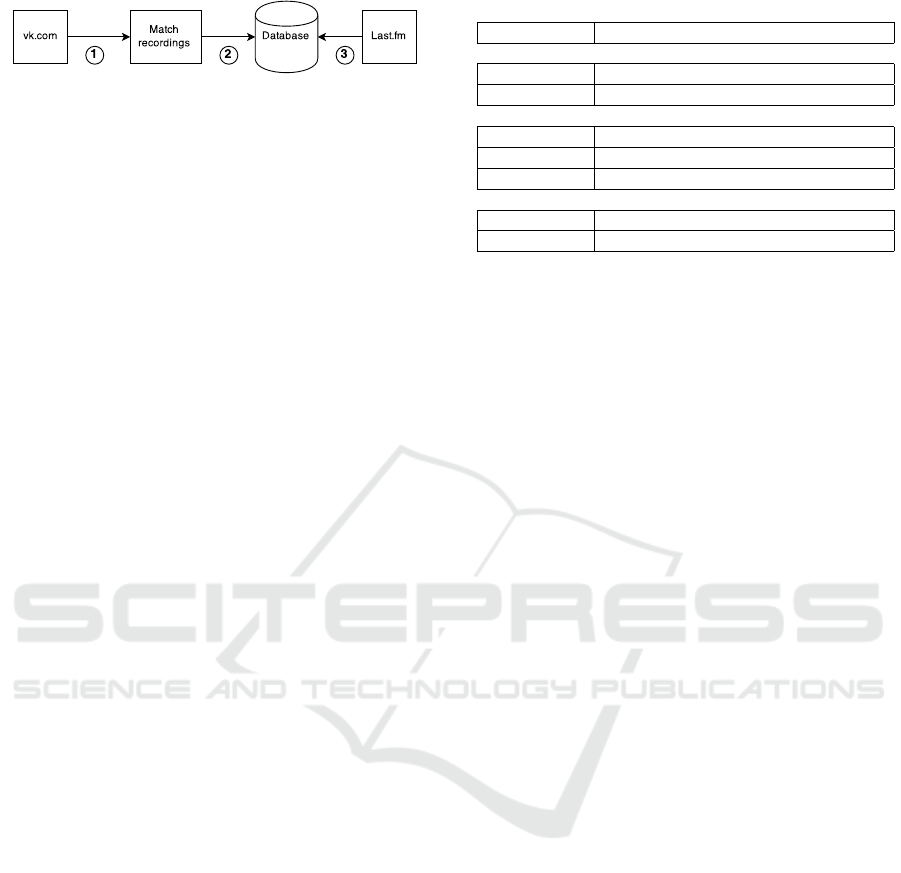
Figure 1: Data collection chart.
and items of several domains overlap (Cantador and
Cremonesi, 2014). However, to the best of our knowl-
edge, the efforts on the impact of source domains on
the target domain with only overlapping items involv-
ing a real cross-domain dataset is very limited.
3 DATASETS
Due to the lack of publicly available datasets for
cross-domain recommender systems with overlapping
items (Berkovsky et al., 2008; Kille et al., 2013) we
collected data from VK and FM. The construction of
the dataset included three phases (Figure 1): 1) VK
recordings collection, 2) duplicates matching, and 3)
FM recordings collection.
3.1 VK Recordings Collection
The VK interface provides the functionality to add
favorite recordings to users’ pages. By generating
random user ids we collected disclosed VK users’
favorite audio recordings using VK API. Our VK
dataset consists of 97, 737 (76, 177 unique) audio
recordings added by 864 users.
Each VK user is allowed to share any audio or
video recording. The interface of the OSN provides
the functionality to add favorite recordings to the
users page. VK users are allowed not only to add
favorite audio recordings to their pages, but also to
rename them. The dataset thus contains a noticeable
number of duplicates with different names. To assess
this number we randomly selected 100 VK recordings
and manually split them into three categories:
• correct names - the name of the recording is cor-
rectly written without any grammatical mistakes
or redundant symbols;
• misspelled names - the name is guessable, even
if the name of the recording is replaced with
the combination of artist and recording name or
lyrics;
• meaningless names – the name does not contain
any information about the recording. For exam-
ple, “unknown” artist and “The song” recording.
Out of 100 randomly selected recordings we detected
14 misspelled and 2 meaningless names. The example
can be seen from table 1.
Table 1: Examples of recordings.
Artist name Recording name
Correct names
Beyonce Halo
Madonna Frozen
Misspelled
Alice DJ Alice DJ - Better of Alone.mp3
Reamonn Oh, tonight you kill me with your smile
l Lady Gaga Christmas Tree
Meaningless
Unknown classic
Unknown party
3.2 Duplicates Matching
In order to match misspelled recordings, we de-
veloped a duplicate matching algorithm that detects
duplicates based on recordings’ names, mp3 links
and durations. The algorithm compares recordings’
names based on Levenshtein distance and the number
of common words excluding stop words.
We then removed some popular meaningless
recordings such as “Unknown”, “1” or “01”, because
they represent different recordings and do not indicate
users’ preferences. Furthermore, some users assign
wrong popular artists’ names to the recordings. To re-
strict the growth of this kind of mistakes, the matching
algorithm considers artists of the duplicate recordings
to be different. By using the presented matching ap-
proach, the number of unique recordings decreased
from 76, 177 to 68,699.
3.3 FM Recordings Collection
In order to utilize the source domain we collected
FM recordings that correspond to 48, 917 selected
VK recordings that were added by at least two users
or users that have testing data. Each FM record-
ing contains descriptions such as FM tags added by
FM users. FM tags indicate additional information
such as genre, language or mood. Overall, we col-
lected 10, 962 overlapping FM recordings and 20, 214
(2, 783 unique) FM tags.
It is also possible to obtain FM users who like a
certain recording (top fans). For each FM recording,
we collected FM users who like at least one more FM
recording from our dataset according to the distribu-
tion of VK users among those recordings. In fact,
some unpopular FM recordings are missing top fans.
We thus collected 17, 062 FM users, where 7, 083 of
them like at least two recordings from our database.
In this work, we constructed three datasets. Each
of them includes the collected FM data and different
parts of the VK data:
Cross-Domain Recommendations with Overlapping Items
133

• 0% - the dataset contains only overlapping record-
ings rated by VK and FM users;
• 50% - the dataset contains overlapping recordings
and the half of randomly selected VK recordings
that do not correspond to FM recordings;
• 100% - the dataset contains all collected VK and
FM recordings.
The statistics of the datasets are presented in ta-
ble 2. The number of VK users varies in different
dataset, due to the lack of ratings after removing non-
overlaping VK recordings.
4 RECOMMENDATION
APPROACHES
In order to emphasize the importance of additional
data we implemented simple, but popular collabora-
tive filtering and content-based filtering algorithms.
4.1 Item-based Collaborative Filtering
Each recording is represented as a vector in the mul-
tidimensional feature space, where each feature is a
user’s choice. VK recording is represented as follows:
i
vk
j
= (u
vk
1, j
, u
vk
2, j
, ..., u
vk
n, j
), where u
vk
k, j
equals to 1 if VK
user k picks VK recording j and 0 otherwise. The
representation changes if we consider the FM users:
i
vk, f m
j
= (u
vk
1, j
, u
vk
2, j
, ..., u
vk
n, j
, u
f m
1, j
, u
f m
2, j
, ..., u
f m
n, j
).
In order to rank items in the suggested list we
use sum of similarities of recordings (Ekstrand et al.,
2011):
score(u
vk
k
, i
vk
j
) =
∑
i
vk
h
∈I
u
vk
k
sim(i
vk
j
, i
vk
h
), (1)
where I
u
vk
k
is the set of items picked by u
vk
k
user. We
use conditional probability as similarity measure (Ek-
strand et al., 2011):
p(i
j
, i
h
) =
Freq(i
j
∧ i
h
)
Freq(i
j
) · Freq(i
h
)
α
, (2)
where Freq(i
j
) is the number of users that liked item
i
j
, while Freq(i
j
∧i
h
) is the number of users that liked
both items i
j
and i
h
. The parameter α is a demping
factor to decrese the similarity for popular items. In
our experiments α = 1.
It is worth mentioning that item vectors based on
FM users contain remarkably more dimensions than
vectors based on VK users. In order to alleviate the
problem we compared recordings using the following
rule:
sim(i
j
, i
h
) =
p(i
vk
j
, i
vk
h
), ∃i
vk
j
∧ ∃i
vk
h
∧
(@i
f m
j
∨ @i
f m
h
)
p(i
f m
j
, i
f m
h
), ∃i
f m
j
∧ ∃i
f m
h
∧
(@i
vk
j
∨ @i
vk
h
)
p(i
vk, f m
j
, i
vk, f m
h
), ∃i
vk
j
∧ ∃i
vk
h
∧
∃i
f m
j
∧ ∃i
f m
h
. (3)
We compare items in each pair using only do-
mains that contain users’ ratings for both items.
4.2 Content-based Filtering
In a content-based approach similarly to an item-
based approach each recording is represented as a
vector, but each dimension corresponds to an attribute
of the item. In our case, these attributes are VK FM
artists and FM tags. It is worth mentioning that FM
and VK artists correspond to each other.
An audio recording thus is represented as follows:
i
a
j
= (a
1, j
, a
2, j
, ..., a
d, j
), where a
k, j
equals to 1 if the
recording i
j
is performed by the artist a
k
and 0 oth-
erwise. The user then can be represented similarly:
u
a
j
= (a
1, j
, a
2, j
, ..., a
d, j
), where a
k, j
equals to 1 if user
k picks the recording perfromed by the artist a
k
and 0
otherwise.
The representation chages if we consider FM tags:
i
t
j
= (w
1, j
, w
2, j
, ..., w
q, j
), where w
k, j
corresponds to
the term frequencyinverse document frequency (Lops
et al., 2011). The user vector then is denoted as fol-
lows: u
t
j
= (t
1, j
,t
2, j
, ..., t
q, j
), where t
k, j
is a number of
recodings that have tag t
k
and are picked by user u
j
.
The recommender system compares audio record-
ings’ vectors and a user vector using cosine similar-
ity (Ekstrand et al., 2011). First, the suggested list
is sorted according to the similarity based on artists.
Second, list fragments that consist of items with the
same artists’ similarity are sorted according to the FM
tag similarity.
5 EXPERIMENTS
In this section, we conduct experiments to demon-
strate whether the source domain improves the rec-
ommendation performance in the target domain when
only items overlap.
5.1 Evaluation Metrics
We used precision@K, recall@K, mean average pre-
cision (MAP) and normalized discounted cumula-
tive gain (NDCG) to evaluate our approaches (Zhao,
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
134

Table 2: The Statistics of the Datasets.
0% 50% 100%
VK FM VK FM VK FM
Users 661 7,083 850 7,083 864 7,083
Ratings 14,207 40,782 62,435 40,782 96,737 40,782
Items 4,605 4,605 39,831 4,605 68,699 4,605
Artists 1,986 1,986 19,930 1,986 31,861 1,986
Tags - 20,167 - 20,167 - 20,167
2013), as these metrics are the most popular in infor-
mation retrieval. Precision@K, recall@K and mean
average precision (MAP) are used to assess quality of
recommended lists with binary relevance. Binary rel-
evance requires each item to be relevant or irrelevant
for a particular user. As in our case a user can only
indicate relevance of a recording by adding it to her
page, we regarded added recordings as equally rele-
vant for a user. We regarded the rest recordings as
irrelevant. Precision@K and recall@K for a specific
user are calculated as follows:
P
u
@K =
r
u
(K)
K
, (4)
R
u
@K =
r
u
(K)
r
u
, (5)
where r
u
(K) is the number of items relevant for user
u in the first K results, while r
u
indicates the number
of relevant items in the list recommended to user u.
Overall precision@K and recall@K are average val-
ues.
Precision@K =
1
||U||
∑
u∈U
P
u
@K, (6)
Recall@K =
1
||U||
∑
u∈U
R
u
@K, (7)
where U is a set of evaluated users. MAP then can be
calculated in the following way:
MAP =
1
||U||
∑
u∈U
1
r
u
h
∑
i=1
r
u,i
· P
u
@i
!
, (8)
where r
u,i
= 1 if an item at position i in the recom-
mended list is relevant for user u and r
u,i
= 0 other-
wise. In our experiments h was set to 30.
We also evaluated our approaches using NDCG
(J
¨
arvelin and Kek
¨
al
¨
ainen, 2002). The metric consid-
ers positions of items in recommended lists and multi-
ple levels of relevance. We employed NDCG to mea-
sure the quality of recommendations with binary rel-
evance. The metric is calculated as follows:
NDCG
u
@K = Z
n
·
K
∑
i=1
(
2
r
u,i
− 1, i = 1
2
r
u,i
−1
log
2
(i)
, i > 1
, (9)
NDCG@K =
1
||U||
∑
u∈U
NDCG
u
@K, (10)
where Z
n
is the normalization constant.
5.2 Results
Following the datasets sampling strategy in (Ekstrand
et al., 2011), we split each of our datasets into training
and test datasets. In particular, we selected 40% of
the users who rated the most VK recordings, and then
chose 30% of their ratings as the testing dataset. We
then regarded the rest ratings as the training dataset.
We used offline evaluation to compare results of
proposed methods with baselines. The recommender
system suggested 30 popular VK recordings to each
testing VK user excluding recordings that the user has
already added in the training set. In each approach the
recommendation list consists of the same items. We
chose popular items for evaluation, due to the high
probability that users have seen them already.
In this study, we demonstrate the performance
improvement resulting from the source domain with
three simple but popular algorithms: (1) POP, (2) Col-
laborative Filtering (CF), and (3) Content-based Fil-
tering (CBF). In particular, POP is a non-personalized
recommendation algorithm, which orders items in the
suggested list according to their popularity in the VK
dataset. For the CF and the CBF algorithms, we ob-
tained two performance results based on only VK and
VK+FM data.
• POP - ordering items according to their popular-
ity using the VK dataset.
• CF(VK) - item-based collaborative filtering using
the VK dataset.
• CF(VK+FM) - item-based collaborative filtering
using VK and FM datasets.
• CBF(VK) - content-based filtering using the VK
dataset.
• CBF(VK+FM) - content-based filtering using
VK and FM datasets.
Figures 2, 3 and 4 demonstrate the experimental
results based on three datasets presented in Section 3.
From the figures we can observe that:
1. The source domain can improve the recommenda-
tion performance in the target domain when only
items overlap. For the 0% dataset, the CF algo-
rithm achieves 0.0216, 0.0273, 0.0139 and 0.0287
Cross-Domain Recommendations with Overlapping Items
135
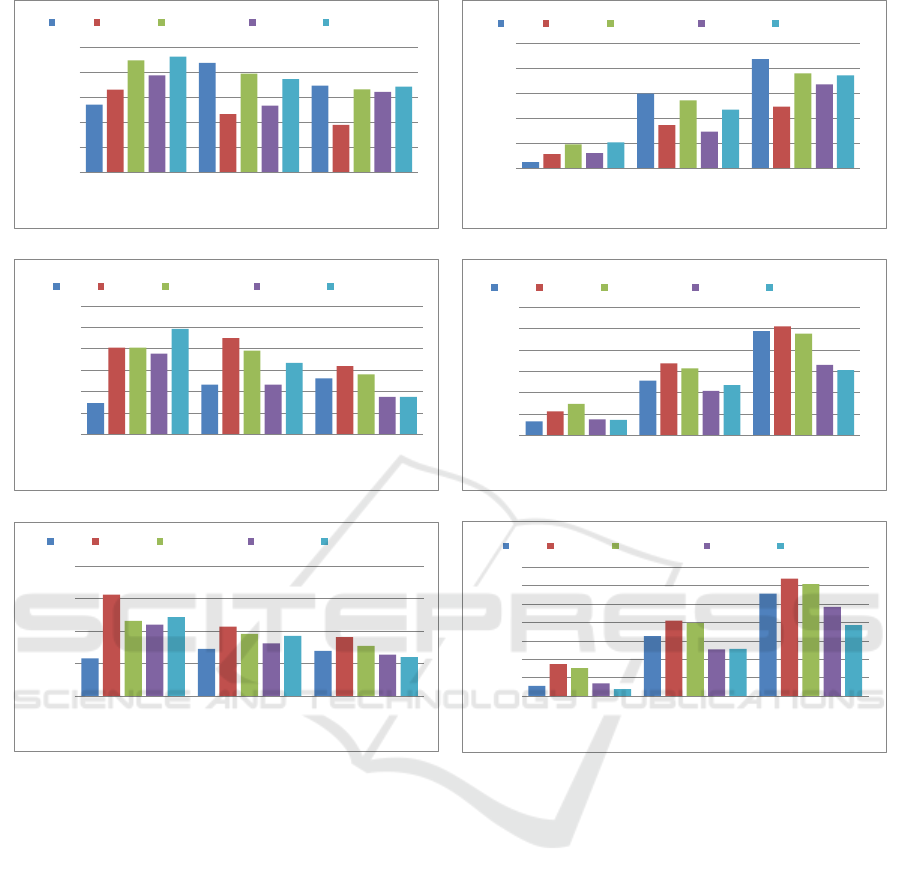
0,01
0,015
0,02
0,025
0,03
0,035
5
10
15
K
POP
CF(VK)
CF(VK+FM)
CBF(VK)
CBF(VK+FM)
(a) Precision@K (0%)
0,01
0,02
0,03
0,04
0,05
0,06
5
10
15
K
POP
CF(VK)
CF(VK+FM)
CBF(VK)
CBF(VK+FM)
(b) Recall@K (0%)
0,015
0,017
0,019
0,021
0,023
0,025
0,027
5
10
15
K
POP
CF(VK)
CF(VK+FM)
CBF(VK)
CBF(VK+FM)
(c) Precision@K (50%)
0,002
0,004
0,006
0,008
0,01
0,012
0,014
5
10
15
K
POP
CF(VK)
CF(VK+FM)
CBF(VK)
CBF(VK+FM)
(d) Recall@K (50%)
0,015
0,02
0,025
0,03
0,035
5
10
15
K
POP
CF(VK)
CF(VK+FM)
CBF(VK)
CBF(VK+FM)
(e) Precision@K (100%)
0,002
0,003
0,004
0,005
0,006
0,007
0,008
0,009
5
10
15
K
POP
CF(VK)
CF(VK+FM)
CBF(VK)
CBF(VK+FM)
(f) Recall@K (100%)
Figure 2: Precision@K and Recall@K for experiments conducted using datasets with different fractions of non-overlapping
items.
in terms of precision@10, recal@10, MAP and
NDCG@10 based on VK dataset, while these
numbers are 0.0297, 0.0372, 0.0179 and 0.0387
based on VK+FM dataset, making the improve-
ment of 37.5%, 36.3%, 28.8% and 34.8%, respec-
tively. Similar improvements can be observed for
the CBF algorithm.
2. The improvement declines with the growth of
non-overlapping items in different domains. For
example, the improvement of CBF in terms of
NDCG@10 decreases as follows: 20.1%, 5.4%
and 5.0% using 0%, 50% and 100% datasets,
respectively. For the CF algorithm, the declin-
ing trend is even sharper. The source domain
decreases the performance of the CF algorithm
by 11.8% and 7.0% in terms of NDCG@5 and
NDCG@10 respectively using 100% dataset. A
similar trend can be observed for other numbers
of first K results and evaluation metrics.
3. CF(VK) and CBF(VK) perform worse than POP
in different cases, especially using the dataset
that contains only overlapping recordings (0%).
CF(VK) algorithm outperforms the popularity
baseline with the increase of non-overlapping
recordings. CF(VK) achieves 0.0139, while POP
outperforms them with the number 0.0180 in
terms of MAP using 0% dataset. For 100%
dataset the situation is opposite. POP achieves
0.0029, while CF(VK) reaches 0.0031. POP out-
performs CBF(VK) algorithm in most cases. For
0% and 100% datasets, CBF(VK) performs 1.9%
and 8.4% worse than POP in terms of MAP, re-
spectively.
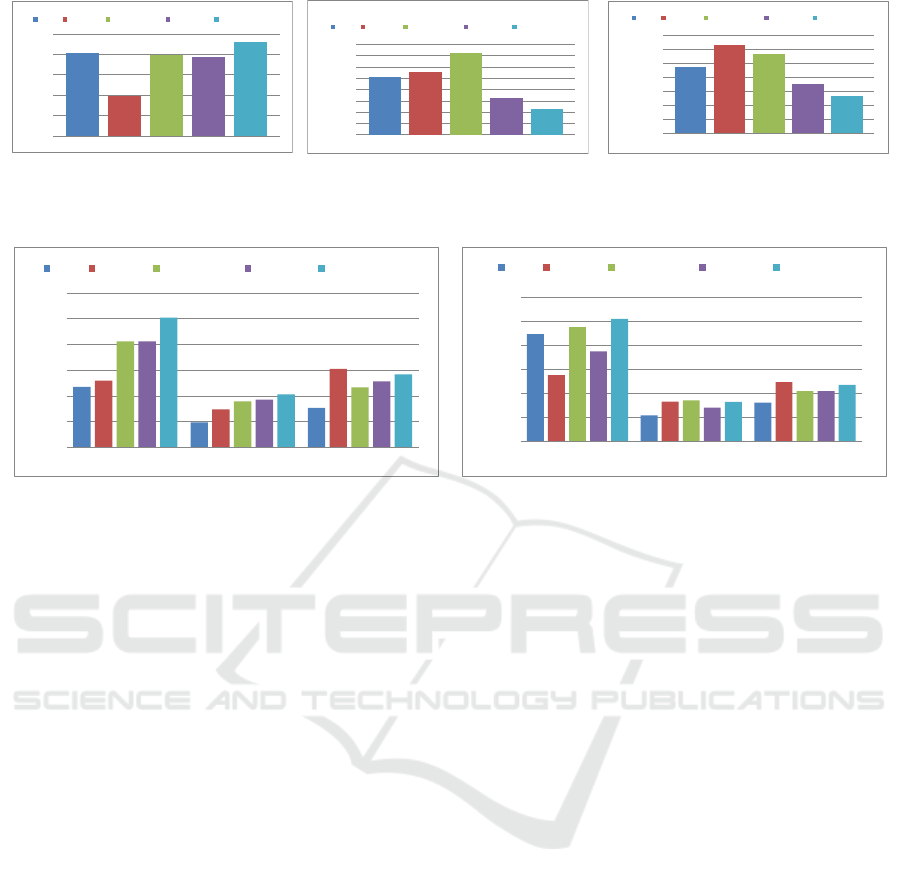
Observation 1 illustrates the global correlation of
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
136
0,01
0,012
0,014
0,016
0,018
0,02
POP
CF(VK)
CF(VK+FM)
CBF(VK)
CBF(VK+FM)
(a) MAP (0%)
0,003
0,0032
0,0034
0,0036
0,0038
0,004
0,0042
0,0044
0,0046
POP
CF(VK)
CF(VK+FM)
CBF(VK)
CBF(VK+FM)
(b) MAP (50%)
0,002
0,0022
0,0024
0,0026
0,0028
0,003
0,0032
0,0034
POP
CF(VK)
CF(VK+FM)
CBF(VK)
CBF(VK+FM)
(c) MAP (100%)
Figure 3: MAP (30 recommendations) for experiments conducted using datasets with different fractions of non-overlapping
items.
0,015
0,02
0,025
0,03
0,035
0,04
0,045
0%
50%
100%
POP
CF(VK)
CF(VK+FM)
CBF(VK)
CBF(VK+FM)
(a) NDCG@5
0,015
0,02
0,025
0,03
0,035
0,04
0,045
0%
50%
100%
POP
CF(VK)
CF(VK+FM)
CBF(VK)
CBF(VK+FM)
(b) NDCG@10
Figure 4: NDCG@K for experiments conducted using datasets with different fractions of non-overlapping items.
users’ preferences in different domains (Winoto and
Tang, 2008; Fern
´
andez-Tob
´
ıas et al., 2012). Al-
though, the data belongs to different domains, users’
ratings from the source domain indicate similarities
between items that improve the recommendation per-
formance in the target domain.
Observation 2 supports the claim (Fern
´
andez-
Tob
´
ıas et al., 2012), that the improvement cased by
the source domain rises with the growth of the overlap
between target and source domains. The decrease in
the recommendation performance of the CF algorithm
with the FM data is caused by the different lengths of
item vectors in source and target domains, where vec-
tors of FM items contain significantly more dimen-
sions than vectors of VK items.
In observation 3, the non-personalized algorithm
POP outperforms both the personalized algorithms
in different cases. CF algorithm performs worse
than POP due to data sparsity, which is alleviated by
adding more VK recordings to the dataset. Low per-
formance of CBF is caused by the poor quality of item
descriptions, as in the VK dataset items are described
with artists only.
Figures 2, 3 and 4 demonstrate four evaluation
metrics that are not always consistent. However, the
described observations can still be notices.
6 CONCLUSION
In this paper we investigated cross-domain recom-
mendations in the situation when only items overlap
on system level. We collected data from VK and FM
and built three datasets that contain different fractions
of non-overlapping items from source and target do-
mains. We then conducted experiments using collab-
orative filtering and content-based filtering algorithms
to demonstrate the importance of additional data.
According to our results, the source domain can
boost the recommendation performance in the target
domain when only items overlap resulting from the
correlation of users’ preferences among different do-
mains (Winoto and Tang, 2008). However, similarly
to (Fern
´
andez-Tob
´
ıas et al., 2012) our results indi-
cated that the more items overlap in source and target
domains with respect to the whole dataset the higher
the improvement.
ACKNOWLEDGEMENT
The research at the University of Jyv
¨
askyl
¨
a was per-
formed in the MineSocMed project, partially sup-
ported by the Academy of Finland, grant #268078.
Cross-Domain Recommendations with Overlapping Items
137

REFERENCES
Abel, F., Herder, E., Houben, G.-J., Henze, N., and Krause,
D. (2013). Cross-system user modeling and personal-
ization on the social web. User Modeling and User-
Adapted Interaction, 23(2-3):169–209.
Berkovsky, S., Kuflik, T., and Ricci, F. (2008). Mediation
of user models for enhanced personalization in recom-
mender systems. User Modeling and User-Adapted
Interaction, 18(3):245–286.
Cantador, I. and Cremonesi, P. (2014). Tutorial on cross-
domain recommender systems. In Proceedings of the
8th ACM Conference on Recommender Systems, Rec-
Sys ’14, pages 401–402, New York, NY, USA. ACM.
Cremonesi, P., Tripodi, A., and Turrin, R. (2011). Cross-
domain recommender systems. In Data Mining Work-
shops (ICDMW), 2011 IEEE 11th International Con-
ference on, pages 496–503.
Ekstrand, M. D., Riedl, J. T., and Konstan, J. A. (2011).
Collaborative filtering recommender systems. Foun-
dations and Trends in Human-Computer Interaction,
4(2):81–173.
Fern
´
andez-Tob
´
ıas, I., Cantador, I., Kaminskas, M., and
Ricci, F. (2012). Cross-domain recommender sys-
tems: A survey of the state of the art. In Spanish
Conference on Information Retrieval.
J
¨
arvelin, K. and Kek
¨
al
¨
ainen, J. (2002). Cumulated gain-
based evaluation of ir techniques. ACM Transactions
on Information Systems, 20(4):422–446.
Kille, B., Hopfgartner, F., Brodt, T., and Heintz, T. (2013).
The plista dataset. In Proceedings of the 2013 Inter-
national News Recommender Systems Workshop and
Challenge, NRS ’13, pages 16–23, New York, NY,
USA. ACM.
Lops, P., de Gemmis, M., and Semeraro, G. (2011).
Content-based recommender systems: State of the
art and trends. In Recommender Systems Handbook,
pages 73–105. Springer US.
Ricci, F., Rokach, L., and Shapira, B. (2011). Introduction
to Recommender Systems Handbook. Springer US.
Sahebi, S. and Brusilovsky, P. (2013). Cross-domain collab-
orative recommendation in a cold-start context: The
impact of user profile size on the quality of recommen-
dation. In User Modeling, Adaptation, and Personal-
ization, volume 7899 of Lecture Notes in Computer
Science, pages 289–295. Springer Berlin Heidelberg.
Sang, J. (2014). Cross-network social multimedia comput-
ing. In User-centric Social Multimedia Computing,
Springer Theses, pages 81–99. Springer Berlin Hei-
delberg.
Shapira, B., Rokach, L., and Freilikhman, S. (2013). Face-
book single and cross domain data for recommenda-
tion systems. User Modeling and User-Adapted Inter-
action, 23(2-3):211–247.
Winoto, P. and Tang, T. (2008). If you like the devil wears
prada the book, will you also enjoy the devil wears
prada the movie? a study of cross-domain recommen-
dations. New Generation Computing, 26(3):209–225.
Zhao, Y.-L. (2013). Community Learning in Location-
based Social Networks. Thesis. Ph.D.
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
138
