
Concept-based Semantic Search over Encrypted Cloud Data
Fateh Boucenna
1,2
, Omar Nouali
1
and Samir Kechid
2
1
Security Division, CERIST: Research Center on Scientific and Technical Information, Algiers, Algeria
2
LRIA, USTHB: University of Sciences and Technology Houari Boumediene, Algiers, Algeria
Keywords:
Cloud Computing, Searchable Encryption, Data Privacy, Weighting Formula, Concept-based Retrieval,
Semantic Search, Ontology.
Abstract:
Cloud computing is a technology that allows companies and individuals to outsource their data and their ap-
plications. The aim is to take advantage from the power of storage and processing offered by such technology.
However, in order to preserve data privacy, it is crucial that all data must be encrypted before being outsourced
into the cloud. Moreover, authorized users should be able to recover their outsourced data. This process can
be complicated due to the fact that data are encrypted. The traditional information retrieval systems only
work over data in the clear. Therefore, dedicated information retrieval systems were developed to deal with
the encrypted cloud data. Several kinds of search over cloud data have been proposed in the literature such
as Boolean search, multi-keyword ranked search and fuzzy search. However, the semantic search is little
addressed in the literature. In this paper, we propose an approach called SSE-S that take into account the se-
mantic search in the cloud by using Wikipedia ontology to understand the meaning of documents and queries
with maintaining the security and the privacy issues.
1 INTRODUCTION
Cloud computing is a technology that allows compa-
nies and individuals to outsource their data to a re-
mote server. This technology is increasingly used
since its appearance. This is justified by the large
storage space and the enormous computational power
offered to users.
The data outsourced to the cloud are usually sen-
sitive and confidential (photos, emails, financial doc-
uments, etc.). The outsourced data must be protected
against possible external attacks and the cloud server
itself. For that, it is necessary to encrypt them by the
data owner before sending them to the cloud server.
Users tend to take advantage of the large storage
space offered by the cloud to store a huge number of
documents. However, This can complicate the user’s
task to retrieve a specific document. To overcome this
problem, the use of an information retrieval system
(IRS) becomes necessary into a cloud server.
Considering that the data hosted in the cloud
server are encrypted, therefore the classical informa-
tion retrieval is not feasible. For this reason that many
searchable encryption schemes have been proposed
in the literature (Song et al., 2000), (Curtmola et al.,
2006).
The common point between these approaches is
that the user sends an encrypted query (trapdoor) to
the cloud server, upon receiving this query, the server
searches into a collection of encrypted documents
(represented by an encrypted index) and returns to the
user a subset of relevant documents. However, it is
crucial that the search should not cause any informa-
tion leakage.
The first works that have been proposed in the
literature only support single keyword search (Song
et al., 2000). The downside is that a user cannot prop-
erly express his information need. Consequently, the
precision of the search is reduced.
To improve the search accuracy, Boolean search
over encrypted data have been proposed in the liter-
ature (Ballard et al., 2005). However, this improve-
ment still insufficient, given that building Boolean
queries by an inexperienced user is a difficult task.
After that, other works (Xu et al., 2012), (Li et al.,
2013), (Yu et al., 2013), (Wang et al., 2014), (Cao
et al., 2014) have turned to the use of several tech-
niques known in the information retrieval (IR) area as
the weighting formulas, similarity scores, vector rep-
resentation, etc.
It is noticed that the vast majority of the schemes
proposed in the literature is merely a syntactic search.
Boucenna, F., Nouali, O. and Kechid, S.
Concept-based Semantic Search over Encrypted Cloud Data.
In Proceedings of the 12th International Conference on Web Information Systems and Technologies (WEBIST 2016) - Volume 2, pages 235-242
ISBN: 978-989-758-186-1
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
235

These schemes are based only on the keywords of the
query sent by the user and returning documents con-
taining the query terms. However, this is not always
the best way to perform a search. The downside is
that if a user does not select the appropriate keywords
of the query, the server would not return the most per-
tinent documents. Indeed, the server ignores every
document not containing at least one query term, even
if it has a meaning close to that of the query. Conse-
quently, the search is not optimal. To overcome this
problem, it is necessary to introduce a semantic search
over encrypted cloud data.
There are few works in the literature that have
tried to address this problem by proposing semantic
search approaches. (Sun et al., 2013), (Yang, 2015)
have proposed approaches that exploit the technique
of expansion of the query (a single term query) by
inserting synonyms of the query term. These ap-
proaches have not solved the problems previously
posed. Their limit is that they do not use external
resources such as ontologies and thesauri. In addi-
tion, except synonymy, they do not exploit relation-
ships between terms (associative relation, homonym,
instance-of relation, related term, etc.).
In this paper, we present our proposed scheme.
The goal is to solve the problems mentioned above by
performing a semantic search over encrypted cloud
data in which an external resource (Wikipedia on-
tology) is exploited. In addition, we will introduce
an improved version of our approach by proposing a
new weighting formula. Furthermore, an experimen-
tal study validates our proposed approach.
2 PROBLEM FORMULATION
2.1 Toward a Semantic Search
The majority of encryption searchable schemes over
cloud data proposed in the literature performs a
keyword-based search. Indeed, during the search pro-
cess, when the server receives a query, it tries to find
documents containing the query terms. Documents
not containing any query term will not be returned
despite they can be relevant.
Therefore, to get the more relevant documents, the
user is obliged to choose the right keywords when for-
mulating his query. However, this is not always easy,
especially for an inexperienced user. Consequently,
the search may become a tedious task for the system
users. In addition, many relevant documents not con-
taining any query term will not be returned to the user.
To illustrate the problem, let us take the following
example: Assuming we have two short documents
1
,
the first document deals with the London Stock Ex-
change
2
; whereas, the second one is about the Eng-
land football team
3
.
Document 1. The London Stock Exchange is a stock
exchange located in the City of London in the United
Kingdom. As of December 2014, the Exchange had
a market capitalization of US$6.06 trillion, making it
the third-largest stock exchange in the world by this
measurement.
Document 2. The England national football team
represents England and the Crown Dependencies of
Jersey, Guernsey and the Isle of Man for football
matches as part of FIFA-authorised events, and is
controlled by The Football Association, the governing
body for football in England.
If a user sends the query Economy of England, the
server will search for documents containing the terms
Economy and / or England in the documents collec-
tion. The server will surely find that the first docu-
ment does not contain any of these terms, so it ignores
this document. Contrariwise, it will find that the sec-
ond document contains the term England, so it will
return it. However, if we analyze the content of the
two documents, we will notice that the first document
is relevant, since its meaning is close to that of the
query, given that it talks about the London stock ex-
change which is strongly related to the economy of
England. Contrary to the second document that talks
about football in England and has no relationship with
economy. Therefore, this document is not supposed
to be relevant even if it has terms in common with the
query.
In order to solve the problem that we have faced
in the syntactic search. IR community has turned to
the use of techniques exploited in natural language
processing. Indeed, they have exploited external re-
sources such as thesauri and ontologies in order to un-
derstand the meaning of the queries sent by the users.
The goal is to improve the precision and recall of the
search by returning documents that have a meaning
close to that of the query rather than relying on the
syntax. This area of research is called semantic infor-
mation retrieval.
To the best of our knowledge, very few studies
(Sun et al., 2013), (Yang, 2015) have exploited the
semantic information retrieval over encrypted cloud
data. These works are based on the query expansion
technique by adding the synonyms of the query term.
The drawback of these schemes is that except the syn-
1
Extracted from Wikipedia
2
https://en.wikipedia.org/wiki/London Stock Exchange
3
https://en.wikipedia.org/wiki/
England national football team
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
236
onymy, other relationships between terms such as the
associative relationship, homonym, instance-of rela-
tionship, related term, etc. are not exploited. In sum-
mary, those techniques allow to improve recall, but
they are still far from the real semantic search.
Among the fields of semantic IR, we find, con-
textual IR, personalized IR, conceptual IR etc. Con-
trary to other fields of semantic search, machine learn-
ing and user profile are not used in conceptual IR.
Therefore, the server can learn nothing neither about
the user’s interest nor about the documents collection.
Consequently, the conceptual IR is the most appropri-
ate for the realization of an encrypted semantic search
scheme in cloud computing.
A concept is an idea grouping in the same cat-
egory, objects semantically close to each other (e.g.
stock market, economy, finance, currency). Concep-
tual IR is based on concepts rather than keywords in
the indexing and matching process. Therefore, it is
necessary to use external resources such as ontolo-
gies to achieve a mapping between keywords and con-
cepts. Conceptual IR allows to detach from the syn-
tactic aspect and go near the natural language. Con-
sequently, it is possible to perform a semantic guided
search rather than relying on the syntax of the query.
2.2 Threat Model
Security is a crucial aspect in cloud computing given
that the outsourced data are often personal or pro-
fessional. The cloud server is exposed to all kinds
of external attacks. Hence, it is necessary that every
data (document, Index, query) will be encrypted be-
fore sending it to the server.
In addition to that, the cloud server itself is curi-
ous and it can collect information about the content of
documents by statistical analyzes. Hence, the search
process should be secure and have to protect the data
privacy.
When designing a search scheme over encrypted
data, it is important to take into account the threats
discussed below. For this reason, security constraints
were elaborated by the IR community (Cao et al.,
2014), (Li et al., 2013).
Protected Content. It is necessary that all data
flowing through the cloud server will be encrypted.
Keyword Privacy. The proposed scheme must be
able to hide to the server the term distribution (The
frequency of a given term in each document of the
collection) and the inter-distribution (The distribution
of scores of terms in a given document). This is in
order to prevent the server to make a link between a
set of terms and a document.
Trapdoor Unlinkability. The proposed scheme
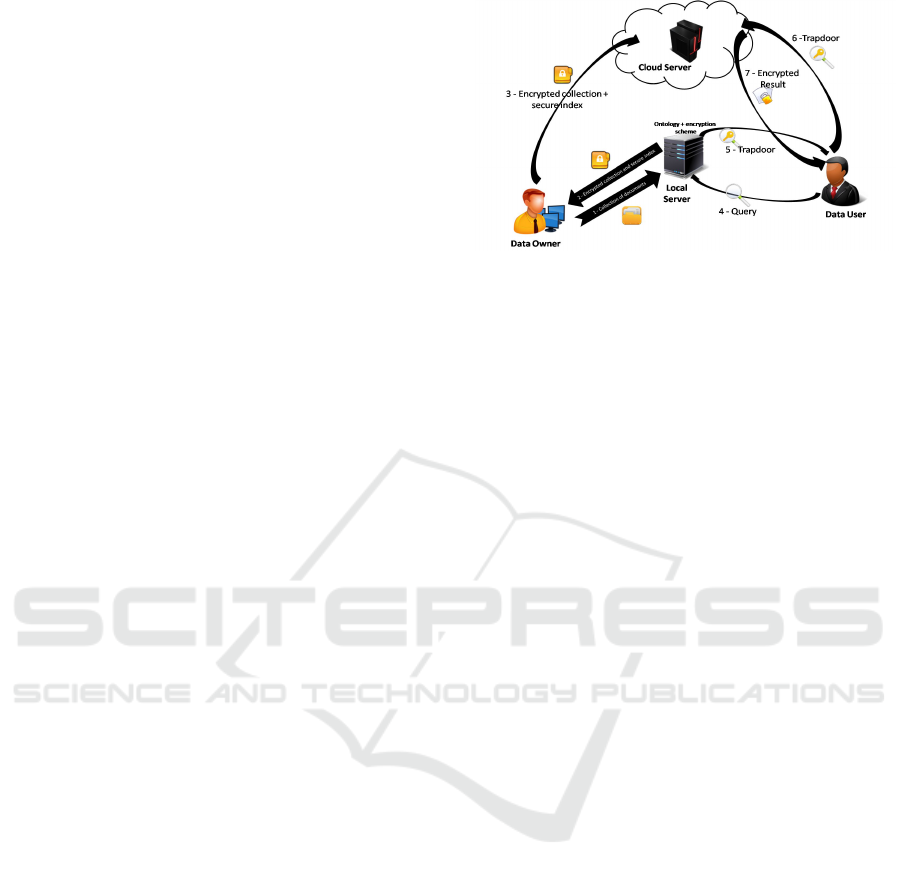
Figure 1: System model.
must be able to prevent the server to deduce the re-
lationship between a given set of encrypted queries.
Therefore, it is necessary that the encryption of a
query will be random enough.
Search Pattern. The proposed scheme must be
able to hide to the server the sequence of results re-
turned to a user during the search.
2.3 System Model
Our proposed scheme uses an ontology during the in-
dexing process. Indeed, after the creation of the in-
dex, each document will be represented by a vector of
terms. From those vectors, the data owner can con-
struct a concepts vector for each document using the
ontology. The whole concepts vectors corresponds to
the conceptual index of the collection. After creat-
ing the conceptual index, both the collection and the
index will be encrypted and sent to the cloud. Dur-
ing the search, an authorized user have to formulate
a query. Then, the concepts vector of the query will
be created using the ontology. After that, it will be
encrypted before sending it to the server. Upon re-
ceiving the encrypted query, the server calculates the
scalar product between each document vector and the
query vector. Finally, the server returns the most rel-
evant documents to the user (Figure 1).
2.4 Design Goals
Our goal is to propose a semantic searchable scheme
over encrypted cloud data. For that, an ontology has
been exploited during the indexing process of the doc-
uments and the queries.
Two majors contributions have been proposed in
our work:
1. Exploiting the semantic search over encrypted
cloud data.
2. Proposal of a new weighting formula to solve the
problem posed in (Egozi et al., 2011) (see section
3.2).
Concept-based Semantic Search over Encrypted Cloud Data
237

3 THE PROPOSED SCHEME
(SSE-S)
In this section, we present the Semantic Searchable
Encryption Scheme (SSE-S) that we have proposed.
For this, we first explain the ontology used in our
scheme. Then, we present the new weighting formula
that we have proposed. After that, we present the en-
cryption method exploited in the SSE-S approach. Fi-
nally, we present the details of the proposed scheme.
3.1 Wikipedia as Ontology
In order to understand the meaning of queries and
documents many researchers have operated exter-
nal resources such as dictionaries, thesauri, semantic
graphs and ontologies. In our work, we opted for the
use of an ontology due to its robustness and reliability.
More precisely, we decided to use Wikipedia as
ontology. The choice of Wikipedia was guided by
its great richness of information given that it contains
more than four (4) million pages, in addition it con-
tains articles in all areas and most languages.
Lot of works have exploited Wikipedia as ontol-
ogy in order to calculate the semantic similarity be-
tween two given texts (Gabrilovich and Markovitch,
2006), (Egozi et al., 2011). Our scheme is based on
Gabrilovich’s approach (Gabrilovich and Markovitch,
2006) where the Wikipedia ontology is constructed as
follows:
1. Each Wikipedia page P
i
corresponds to a concept
C
i
(e.g. Data mining, Financial crisis).
2. Each concept C
i
is represented by a vector of
terms V
i
= {(T
1
,W
i1
),(T
2
,W
i2
),...,(T
n
,W
in
)} ex-
tracted from the corresponding Wikipedia article.
These terms are weighted using the TFIDF for-
mula.
The weight W
i j
of a term T
j
in the vector V
i
corre-
sponds to the association degree between the term
T
j
and the concept C
i
.
3. In order to accelerate the similarity calculation
process, an inverted index I
wiki
is constructed
where each term T
i
is represented by a set of con-
cepts V
0
i
to which it belongs, V
0
i
= {(C
1
, W
1i
), (C
2
,
W
2i
), ..., (C
m
, W
mi
)}.
4. The inverted index I
wiki
= {V
0
1
, V
0
2
, V
0
3
, ...,V
0
n
}
which is constructed of the set of concepts vec-
tors corresponds to Wikipedia ontology.
Before calculating the similarity between two doc-
uments, each of them must first be represented by a
vector of concepts as follows:
1. At first, a vector of terms D
i
= {(T
1
, W
0
i1
), (T
2
,
W
0
i2
), ..., (T
n
, W
0
in
)} must be constructed for each
document d
i
using the TFIDF formula.
2. Then, from the vector D
i
, a vector of con-
cepts D
0
i
= {(C
1
,S
0
i1
),(C
2
,S
0
i2
),...,(C
m
,S
0
im
)} will
be calculated by mapping between terms and con-
cepts through the Wikipedia ontology.
3. The score S
0
i j
assigned to a concept C
j
in the con-
cepts vector D
0
i
is calculated by the following for-
mula:
S
0
i j
=
∑
T
k
∈d
i
W
0
ik
.W
jk
(1)
where W
0
ik
is the weight of a term T
k
belonging to
the document d
i
and W
jk
is the association degree
between the term T
k
and the concept C
j
.
4. After that, Each document will be represented by
the top X (X = 100 is a good value) concepts that
have the highest scores.
5. Finally, the similarity between the two documents
is calculated by applying the scalar product be-
tween the two concepts vectors.
To implement our proposed scheme, We have con-
structed an ontology based on a version of Wikipedia
dated 12-Mar-2015 containing 4,828,395 pages.
3.2 Double Score Weighting Formula
Conceptual IR allows users to find relevant docu-
ments even if they do not contain query terms or
their synonyms. This is explained by the fact that the
search is guided by the meaning through the use of an
ontology.
Let us take the example given in (Egozi et al.,
2011): suppose that a user sends the query shipwreck
salvaging treasure and that the collection contains the
document entitled Ancient Artifacts Found below:
Ancient Artifacts Found. Divers have recovered
artifacts lying underwater for more than 2,000 years
in the wreck of a Roman ship that sank in the Gulf of
Baratti, 12 miles off the island of Elba, newspapers
reported Saturday.
A keyword-based search cannot find the document
above given that it has not any term in common with
the query. However, with the conceptual IR, this doc-
ument will be returned to the user given that the doc-
ument vector has concepts in common with the query
vector.
Nevertheless, it happens that a concept based
search returns documents containing terms in com-
mon with a query despite they are not relevant. To
illustrate that, an example was given in (Egozi et al.,
2011): if a user sends the query Estonia economy and
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
238

the collection contains the document entitled Olympic
News In Brief below:
Olympic News in Brief. Cycling win for Estonia.
Erika Salumae won Estonia’s first Olympic gold when
retaining the women’s cycling individual sprint title
she won four years ago in Seoul as a Soviet athlete
As keyword-based search, concept-based search
cannot ignore this document even if it is not relevant.
That is justified by the high frequency of the term Es-
tonia in the document and thus the vector representing
the document Olympic News In Brief contains many
concepts associated with the term Estonia. Similarly,
more than half of the concepts of the vector represent-
ing the query are associated with the term Estonia.
Therefore, there is many common concepts (34 con-
cepts were found in our experimentation) between the
document vector and the query vector. Consequently,
concept-based search returns the document Olympic
News In Brief in response to the query Estonia econ-
omy even if it is assumed not to be relevant.
In order to understand the origin of this problem,
we have analysed the concepts representing the doc-
ument Olympic News In Brief and the concepts rep-
resenting the query Estonia economy. We have also
analysed the concepts associated with the terms Econ-
omy and Estonia separately.
On the one hand, we have noticed that eight (8)
of the top ten concepts representing the document
Olympic News In Brief are part of the top 10 con-
cepts associated with the term Estonia. That is justi-
fied by the high frequency of the term Estonia in the
document Olympic News In Brief which increases the
scores of the concepts associated with this term when
applying the formula (1). On the other hand, even
if the frequencies of the query terms are similar, we
noticed that the majority of the concepts representing
the query are associated with the term Estonia rather
than the term Economy. That is due to the fact that
the concepts associated with the term Estonia have
greater weights, and thus most of these concepts will
be selected to represent the query.
In order to represent documents and queries by
the most appropriate concepts, we have proposed a
new weighting formula that we called Double Score
Weighting Formula which allows to represent a docu-
ment (or a query) by a set of concepts strongly associ-
ated with the general meaning of the document rather
than representing it by concepts associated with terms
that have the highest frequencies.
In Wikipedia ontology, each term is associated
with a set of concepts. Thus, to represent a document
by the most appropriate concepts, our idea is to se-
lect the concepts that are associated with the greatest
number of terms of the document. For example, if
we have the query Estonia Economy, for representing
this query, it is more advantageous to choose a con-
cept associated with both Estonia and Economy than
choosing a concept only associated with the term Es-
tonia, even if the second concept has a greater score.
We have proposed a new weighting formula to be
able to represent a document by concepts that are as-
sociated with its general meaning. Below we present
the steps needed to represent a document by the most
appropriate concepts:
1. Construct a weighted terms vector for the docu-
ment by applying the TFIDF formula.
2. Get all concepts associated with each term of the
document vector constructed above by using the
Wikipedia ontology.
3. For each of these concepts, attribute two scores as
follows:
(a) The first score is the number of terms (without
redundancy) of the document associated with
this concept, this score is called the primary
score (S
p
).
(b) The second score is the TFIDF weight of the
concept in the document, this score is called the
secondary score (S
s
) and is calculated by the
formula 1.
4. Sort the concepts with regard to their primary
scores then based on their secondary scores in the
case of equality.
(S
p1
,S
s1
) > (S
p2
,S
s2
) ⇒
(S
p1
> S
p2
) ∨ ((S
p1
= S
p2
) ∧ (S
s1
> S
s2
)) (2)
5. Keep the top Y (Y = 100 is a good value) concepts
with their scores to represent the document.
We applied our method on the first example to calcu-
late the similarity between the document Ancient Ar-
tifacts Found and the query shipwreck salvaging trea-
sure. We have found that there are thirteen (13) com-
mon concepts between the top 100 concepts repre-
senting the document and the top 100 concepts repre-
senting the query rather than one (1) concept when ap-
plying Gabrilovich’s method. Thus, as Gabrilovich’s
method, our method is able to retrieve relevant doc-
uments even if they have no term in common with
the query. Besides, our method is more efficient
than the Gabrilovich’s method concerning such docu-
ments (13 concepts in our method versus 1 concept in
Gabrilovich’s method).
Similarly, we applied our method on the second
example to calculate the similarity between the doc-
ument Olympic News In Brief and the query Estonia
Economy. We have not found any common concept
Concept-based Semantic Search over Encrypted Cloud Data
239

between the top 100 concepts representing the docu-
ment and the top 100 concepts representing the query
rather than thirty-four (34) concepts when applying
Gabrilovich’s method. Thus, our weighting method
has corrected the problem encountered when applying
Gabrilovich’s method. More precisely, Our method is
able to ignore irrelevant documents even if they have
terms in common with the query.
3.3 The Encryption Method Used
It is necessary to encrypt the index of the collection
(set of concepts vectors representing the documents)
built by the data owner as well as users’ queries be-
fore sending them to the cloud server. The SSE-
S scheme that we have proposed uses the same en-
cryption method proposed in (Cao et al., 2014). Our
choice was guided by the reliability and the robust-
ness of this encryption method. in addition, the data
structure used in our scheme to represent documents
and queries (concepts vector) is compatible with this
encryption method.
The encryption key proposed in the MRSE scheme
(Cao et al., 2014) which we used in our SSE-S scheme
is composed of one vector S of size (m +U + 1) and
two (m + U + 1) ∗ (m + U + 1) invertible matrices
({M1,M2}), with m is the total number of concepts.
The encryption process is done in three (3) steps
(extension, splitting and multiplication) as follows:
1. At first, U + 1 dimensions are added to each docu-
ment vector D
i
of size m. The value 1 is assigned
to the (m + 1)
th
dimension. Whereas, a random
value ε
j
i
is assigned to the (m + j + 1)
th
dimen-
sion (where j ∈ [1,U]). The U last dimensions
correspond to dummy keywords.
→
D
i
= {D
i
,1,ε
1
i
,ε
2
i
,ε
3
i
,...,ε
U
i
}
Moreover, a query vector (which is also of size
m) is multiplied by a random parameter r. Then,
a dimension with a random value t is added to
the obtained vector. After that, U dimensions are
added to this vector. a value α
j
is assigned to the
(m + j +1)
th
dimension (with α
j
∈ {0, 1}).
→
Q = {r.Q,t, α
1
,α
2
,α
3
,...,α
U
}/α
j
∈ {0, 1}
2. After that, each document vector
→
D
i
is split into
two vectors {
→
D
0
i
,
→
D
00
i
}, and each query vector
→
Q
is split into two vectors {
→
Q
0
,
→
Q
00
}. The vector S
is used as a splitting indicator. Indeed, if the j
th
element of S is equal to 0 then
→
D
0
i
[ j] and
→
D
00
i
[ j]
will have the same value as
→
D
i
[ j] and each of the
two elements
→
Q
0
[ j] and
→
Q
00
[ j] will have a random
value such that their sum is equal to
→
Q[ j]. In the
case where the j
th
element of S is equal to 1, we
follow the same principle, except that the docu-
ment vector and the query vector are switched.
3. Finally, both M
1
and M
2
matrices are used to fi-
nalize the encryption of each document vector as
follows: I
i
= {M
T
1
.
→
D
0
i
,M
T
2
.
→
D
00
i
} and for the en-
cryption of each query vector as follows: T
q
=
{M
−1
1
.
→
Q
0
,M
−1
2
.
→
Q
00
}
When applying the scalar product between a doc-
ument vector and a query vector we obtain:
I
i
.T
q
= {M
T
1
.
→
D
0
i
,M
T
2
.
→
D
00
i
} × {M
−1
1
.
→
Q
0
,M
−1
2
.
→
Q
00
}
=
→
D
0
i
×
→
Q
0
+
→
D
00
i
×
→
Q
00
= {D
i
,1,ε
1
i
,ε
2
i
,...,ε
U
i
} × {r.Q,t, α
1
,α
2
,...,α
U
}
= r.D
i
.Q +
U
∑
j=1
ε
j
i
.α
j
+t
The random parameters {ε
j
i
,α
j
,t,r} are used to
hide the real similarity score between a document and
a query. However, the alternative similarity scores
are useful to sort documents by relevance as has been
proved in (Cao et al., 2014).
In our scheme, each document or query is repre-
sented by a concepts vector of size m (where m is the
total number of concepts). The j
th
field of the vector
is a couple of scores (SP
j
i
,SS
j
i
) where the first one is
the primary score of the concept C
j
in the document
d
i
and the second one represents its secondary score.
Thus, in order to the encryption method presented be-
low becomes operational in our approach, it is nec-
essary that the parameters ε
j
i
,α
j
,t will be as couple
of values. Namely ε
j
i
= (ε
0 j
i
,ε
00 j
i
), α
j
= (α
0 j
,α
00 j
) and
t = (t
0
,t
00
) where α
0 j
= α
00 j
. Whereas, the parameter
r still as a single value.
3.4 Semantic Searchable Encryption
Scheme (SSE-S)
Our proposed scheme is composed of five (5) func-
tions and two main phases. We start by presenting the
five functions of our scheme:
• KeyGen. The data owner randomly generates a
secret key SK = {S,M
1
,M
2
}, where S is a vector
of size (m +U + 1) and (M
1
,M
2
) are two invert-
ible matrices of size (m +U + 1) × (m +U + 1)
(see section 3.3).
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
240

• BuiltOnto. The ontology is built from Wikipedia.
For that, English Wikipedia pages are indexed,
where each page is represented by a vector of
weighted terms by applying the TFIDF formula;
each page corresponds to a concept; an inverted
index of Wikipedia I
wiki
is created where each
term is represented by a vector of weighted con-
cepts (see section 3.1).
• BuiltIndex (F, SK). At first, a vector of terms is
constructed for each document of the collection F
by applying the TFIDF formula; then, using the
Wikipedia ontology, a vector of concepts is built
for each document by applying the double score
formula (see section 3.2); finally, each vector of
concepts is encrypted by the secret key SK (see
Section 3.3). The set of the encrypted vectors con-
stitutes the index I
0
of the collection F.
• Trapdoor (W , SK). At first, a vector of terms is
constructed from the query keywords, where the
i
th
field of the vector is set to 1 if the query con-
tains the corresponding term, otherwise it is set to
0; after that, a vector of concepts is constructed
to represent the query, by using the Wikipedia on-
tology and applying the double score formula (see
section 3.2); finally, the vector of concepts is en-
crypted by the secret key SK (see Section 3.3).
• Search (T , I
0
, K). Upon receipt of the encrypted
query T (represented by a vector of concepts), the
cloud server calculates the scalar product between
each document vector and the query vector (the
result is a couple of scores). Then, it sorts the doc-
uments on the basis of primary scores and possi-
bly secondary scores in case of equality (by using
the formula 2). Finally, the server returns to the
user the Ids of top k relevant documents.
The search process consists of two main steps:
• Initialization Phase. In this phase, the data
owner prepares the search environment as fol-
lows:
1. At first, he calls KeyGen to generate a secret
key SK that is shared with authorized users by
using a secure communication protocol.
2. Then, he calls BuiltOnto to construct an on-
tology from Wikipedia. This ontology will be
stored in a local server and will be accessible
by the authorized users.
3. Finally, the data owner calls BuiltIndex to con-
struct a secure index from a collection of doc-
uments. The secure index as well as the col-
lection of documents (encrypted by another en-
cryption algorithm like AES) will be outsourced
in the cloud server.
• Retrieval Phase. This is the phase where an au-
thorized user performs a search as follows:
1. At first, an authorized user calls Trapdoor to
build an encrypted query.
2. Upon the server receives the encrypted query, it
launches the search process, and returns to the
user the Ids of top k relevant documents.
4 RESULT AND COMPARISON
Yahoo! Answers
4
is a website that allows users to
ask questions or answer to questions asked by other
users. A data collection was collected from the Ya-
hoo! Answers corpus. This collection is composed
of 142,627 questions and 962,232 answers. We have
performed our experiments on the collection Yahoo!
Answers where questions represent the queries and
answers represent the documents.
We have tested 1150 random selected queries
to compare our proposed scheme (SSE-S) with two
other schemes. Namely, we have compared the
SSE-S scheme with the MRSE scheme (Cao et al.,
2014) which uses a conventional search and with
Gabrilovich’s scheme (Gabrilovich and Markovitch,
2006) adapted for an encrypted search.
Each scheme returns one hundred (100) docu-
ments in response to a received query. we calcu-
lated the sum of relevant documents retrieved in each
scheme according to the number of queries. Figure 2
shows that our proposed scheme (SSE-S) gives bet-
ter results than the MRSE scheme (60% of improve-
ment) due to a concept-based search, and it gives bet-
ter results than the Gabrilovich’s scheme (36% of im-
provement) due to the use of double score formula.
This clearly demonstrates that conceptual search (GS,
SSE-S) increases the recall compared to conventional
search (MRSE). Moreover, our experiments confirm
that the proposed double score formula is more ef-
ficient than TFIDF formula used in Gabrilovich’s
scheme.
Then, in order to test the quality of the results re-
turned by each scheme, we assume that the Detailed
answers are better than the short ones. Thus, to mea-
sure the quality of the retrieved documents, we added
a filter that ignores documents having a size less than
a certain threshold α. We have gradually increased
the value of this threshold as, α = 0 in the first fifty
(50) queries, then α = 10 at the fifty (50) queries
that follow, then α = 20 in the third group of the
fifty (50) queries and so on. Figure 3 shows that the
results returned in SSE-S scheme are better quality
4
https://answers.yahoo.com/
Concept-based Semantic Search over Encrypted Cloud Data
241
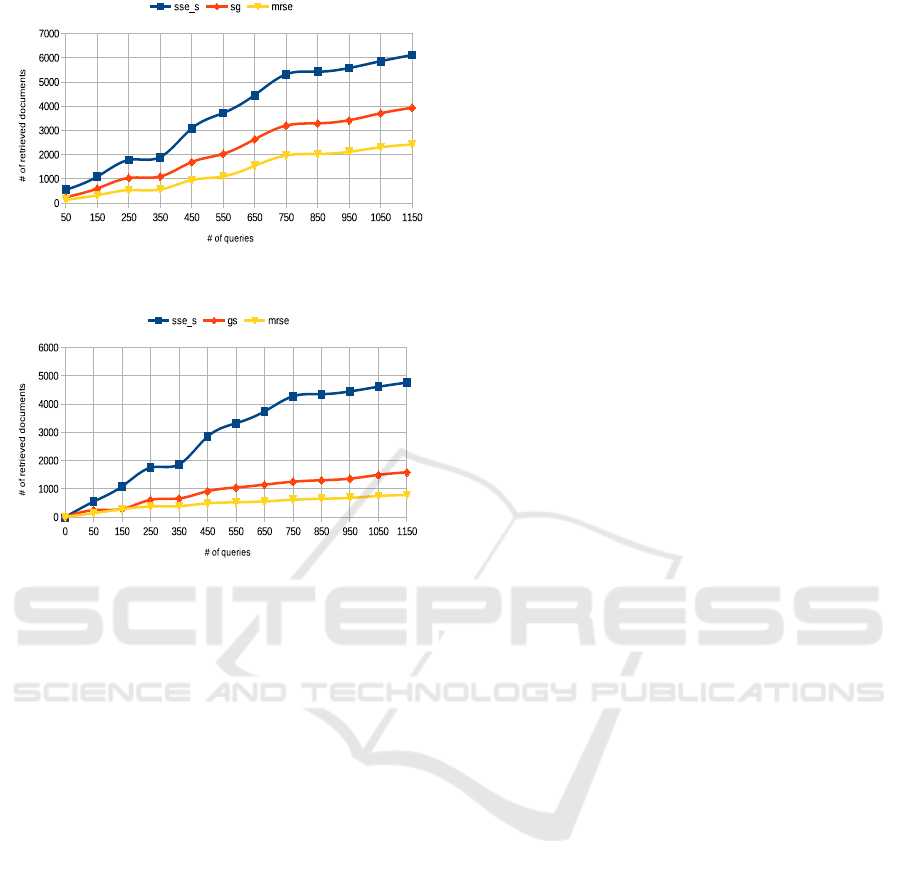
Figure 2: Number of retrieved documents according to the
number of queries in three different approaches.
Figure 3: Number of retrieved documents according to the
number of queries when applying a filter.
than the results returned in both MRSE scheme and
Gabrilovich’s scheme. Indeed, our proposed scheme
improves the quality of the returned results by 67%
compared to the Gabrilovich’s scheme and 84% com-
pared to MRSE scheme.
5 CONCLUSIONS
In this paper, we identified the problems of conven-
tional information retrieval that is exploited in most
of the search approaches over encrypted cloud data.
To fix these problems, we have proposed a searchable
encryption scheme called SSE-S. Indeed, the use of
a concept-based search allows a significant enhance-
ment of the recall by retrieving pertinent documents
even if they do not have any common term with the
query. Moreover, the use of the proposed double score
formula rather than TFIDF formula allows to ignore
irrelevant documents that contain terms in common
with the query. Finally, We validated our scheme by
an experimental study, where we have compared our
scheme with other schemes proposed in the literature.
REFERENCES
Ballard, L., Kamara, S., and Monrose, F. (2005). Achieving
efficient conjunctive keyword searches over encrypted
data. In Information and Communications Security,
pages 414–426. Springer.
Cao, N., Wang, C., Li, M., Ren, K., and Lou, W. (2014).
Privacy-preserving multi-keyword ranked search over
encrypted cloud data. Parallel and Distributed Sys-
tems, IEEE Transactions on, 25(1):222–233.
Curtmola, R., Garay, J., Kamara, S., and Ostrovsky, R.
(2006). Searchable symmetric encryption: improved
definitions and efficient constructions. In Proceedings
of the 13th ACM conference on Computer and com-
munications security, pages 79–88. ACM.
Egozi, O., Markovitch, S., and Gabrilovich, E. (2011).
Concept-based information retrieval using explicit se-
mantic analysis. ACM Transactions on Information
Systems (TOIS), 29(2):8.
Gabrilovich, E. and Markovitch, S. (2006). Computing se-
mantic relatedness of words and texts in wikipedia-
derived semantic space. In IJCAI, volume 7, pages
1606–1611. Citeseer.
Li, K., Zhang, W., Tian, K., Liu, R., and Yu, N. (2013). An
efficient multi-keyword ranked retrieval scheme with
johnson-lindenstrauss transform over encrypted cloud
data. In Cloud Computing and Big Data (CloudCom-
Asia), 2013 International Conference on, pages 320–
327. IEEE.
Song, D. X., Wagner, D., and Perrig, A. (2000). Practical
techniques for searches on encrypted data. In Secu-
rity and Privacy, 2000. S&P 2000. Proceedings. 2000
IEEE Symposium on, pages 44–55. IEEE.
Sun, X., Zhu, Y., Xia, Z., Wang, J., and Chen, L. (2013). Se-
cure keyword-based ranked semantic search over en-
crypted cloud data.
Wang, B., Yu, S., Lou, W., and Hou, Y. T. (2014).
Privacy-preserving multi-keyword fuzzy search over
encrypted data in the cloud. In INFOCOM, 2014 Pro-
ceedings IEEE, pages 2112–2120. IEEE.
Xu, J., Zhang, W., Yang, C., Xu, J., and Yu, N. (2012).
Two-step-ranking secure multi-keyword search over
encrypted cloud data. In Cloud and Service Comput-
ing (CSC), 2012 International Conference on, pages
124–130. IEEE.
Yang, Y. (2015). Attribute-based data retrieval with se-
mantic keyword search for e-health cloud. Journal of
Cloud Computing, 4(1):1–6.
Yu, J., Lu, P., Zhu, Y., Xue, G., and Li, M. (2013). Toward
secure multikeyword top-k retrieval over encrypted
cloud data. Dependable and Secure Computing, IEEE
Transactions on, 10(4):239–250.
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
242
