
A Flexible Mechanism for Data Confidentiality
in Cloud Database Scenarios
Eliseu C. Branco Jr.
1
, Jose Maria Monteiro
2
, Roney Reis
2
and Javam C. Machado
2
1
Computer Networks Course, University Center Estacio of Ceara, Fortaleza, Brazil
2
Department of Computer Science, Federal University of Ceara, Fortaleza, Brazil
Keywords:
Data Confidentiality, Cloud Database, Information Decomposition.
Abstract:
Cloud computing is a recent trend of technology that aims to provide unlimited, on-demand, elastic computing
and data storage resources. In this context, cloud services decrease the need for local data storage and the
infrastructure costs. However, hosting confidential data at a cloud storage service requires the transfer of
control of the data to a semi-trusted external provider. Therefore, data confidentiality is the top concern from
the cloud issues list. Recently, three main approaches have been introduced to ensure data confidentiality in
cloud services: data encryption; combination of encryption and fragmentation; and fragmentation. In this
paper, we present i-OBJECT, a new approach to preserve data confidentiality in cloud services. The proposed
mechanism uses information decomposition to split data into unrecognizable parts and store them in different
cloud service providers. Besides, i-OBJECT is a flexible mechanism since it can be used alone or together
with other previously approaches in order to increase the data confidentiality level. Thus, a user may trade
performance or data utility for a potential increase in the degree of data confidentiality. Experimental results
show the potential efficiency of the proposed approach.
1 INTRODUCTION
Cloud Computing moves the application software and
databases to large data centers, where data manage-
ment may not be sufficiently trustworthy. Cloud stor-
age is an increasingly popular class of services for
archiving, backup and sharing data. There is an im-
portant cost-benefit relation for individuals and small
organizations in storing their data using cloud stor-
age services and delegating to them the responsibil-
ity of data storage and management (Ciriani et al.,
2009). Despite the big business and technical advan-
tages of the cloud storage services, the data confiden-
tiality concern has been one of the major hurdles pre-
venting its widespread adoption.
The concept of privacy varies widely among coun-
tries, cultures and jurisdictions. So, a concise defini-
tion is elusive if not impossible (Clarke, 1999). For
the purposes of this discussion, privacy is “the claim
of individuals, groups or institutions to determine for
themselves when, how and to what extent the infor-
mation about them is communicated to others” (Ca-
menisch et al., 2011). Privacy protects access to the
person, whereas confidentiality protects access to the
data. So, confidentiality is the assurance that cer-
tain information that may include a subject’s iden-
tity, health, lifestyle information or a sponsor’s pro-
prietary information would not be disclosed without
permission from the subject (or sponsor). When deal-
ing with cloud environments, confidentiality implies
that a customer’s data and computation tasks are to
be kept confidential from both the cloud provider and
other customers (Zhifeng and Yang, 2013).
Recently, three main approaches have been intro-
duced to ensure the data confidentiality in cloud en-
vironments: a) data encryption, b) combination of
encryption and fragmentation (Ciriani et al., 2010),
and c) fragmentation (Ciriani et al., 2009). How-
ever, in this context, it is in fact crucial to guaran-
tee a proper balance between data confidentiality, on
one hand, and other properties, such as, data utility,
query execution overhead, and performance on the
other hand (Samarati and di Vimercati, 2010; Joseph
et al., 2013).
The first approach, denoted by data encryption,
consists in encrypting all the data collections. This
technique is adopted in the database outsourcing sce-
nario (Ciriani et al., 2010). Actually, encryption al-
gorithms presents increasingly lower costs. Cryptog-
raphy becomes an inexpensive tool that supports the
protection of confidentiality when storing or commu-
nicating data (Ciriani et al., 2010). However, deal-
Jr., E., Monteiro, J., Reis, R. and Machado, J.
A Flexible Mechanism for Data Confidentiality in Cloud Database Scenarios.
In Proceedings of the 18th International Conference on Enterprise Information Systems (ICEIS 2016) - Volume 1, pages 359-368
ISBN: 978-989-758-187-8
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
359

ing with encrypted data may make query processing
more expensive (Ciriani et al., 2009; Ciriani et al.,
2010). Some techniques have been proposed to en-
abling the execution of queries directly on encrypted
data (remember that confidentiality demands that data
decryption must be possible only at the client side)
(Samarati and di Vimercati, 2010). These techniques
associate with encrypted data indexing information
on which queries can be executed. The mainly chal-
lenger for indexing methods is the trade off between
precision and privacy: more precise indexes provide
more efficient query execution but a greater exposure
to possible privacy violations (Ceselli et al., 2005;
Samarati and di Vimercati, 2010). Besides, the so-
lutions based on an extensive use of encryption suffer
from significant consequences due to loss of keys. In
the real scenarios, key management, particularly the
operations at the human side, is a hard and delicate
process (Samarati and di Vimercati, 2010).
The second approach, called combination of en-
cryption and fragmentation, uses encryption together
with data fragmentation. It applies encryption only on
the sensitive attributes and splits the attributes with
sensitive association into several fragments, which
are stored by different cloud storage services (Ciri-
ani et al., 2010). In other words, sensitive associa-
tion constraints are solved via fragmentation, and en-
cryption is limited to those attributes that are sensitive
by themselves. Thus, a single cloud service provider
cannot join these fragments for responding queries.
Therefore, these techniques must also be accompa-
nied by proper query transformation techniques defin-
ing how queries on the original data are translated into
queries on the fragmented data. Besides, splitting the
attributes with sensitive association into some frag-
ment is a NP-hard problem (Samarati and di Vimer-
cati, 2010; Joseph et al., 2013).
The third approach, denoted by fragmentation,
does not use cryptography. In this approach, the sen-
sitive attributes remains under the client’s custody
while the attributes with sensitive association are split
into several fragments, which are stored by differ-
ent cloud storage services (Ciriani et al., 2009). It
is important to note that this approach has the same
drawbacks discussed previously (for the combination
of encryption and fragmentation approach) regarding
to query execution (Samarati and di Vimercati, 2010;
Joseph et al., 2013).
In this paper, we present i-OBJECT, a new ap-
proach to preserve data confidentiality in cloud stor-
age services. The science behind i-OBJECT uses con-
cepts of the Hegel’s Doctrine of Being. The pro-
posed approach is based on the information decompo-
sition to split data into unrecognizable parts and store
them in different cloud service providers. Besides, i-
OBJECT is a flexible mechanism since it can be used
alone or together with other previously approaches in
order to increase the data confidentiality level. Thus,
a user may trade performance or data utility for a po-
tential increase in the degree of data confidentiality.
Experimental results show the potential efficiency of
the i-OBJECT.
The remain of this paper is organized as follows.
Section 2 presents the proposed approach, called i-
OBJECT. Experimental results are presented in Sec-
tion 3. Next, Section 4 addresses related works. Fi-
nally, Section 5 concludes this paper and outlines fu-
ture works.
2 A DECOMPOSITION-BASED
APPROACH FOR DATA
CONFIDENTIALITY
The proposed approach for ensuring data confidentia-
lity in cloud environments, denoted i-OBJECT, was
designed for transactional data. In this environments,
reads are much more frequent than write operations.
Thus, i-OBJECT needs to be fast to decompose a
file and much faster to recompose a file stored in the
cloud.
The i-OBJECT approach was inspired by the Ger-
man philosopher Hegel’s work, according to which an
object has three fundamental characteristics (Hegel,
1991): quality, quantity and measure. From this idea,
we developed the concept of information object (see
Definition 1). From this concept, we have developed
the processes to: i) fragment a file in a sequence of
information objects and ii) decompose each informa-
tion object in its properties (quality, quantity and mea-
sure).
The i-OBJECT approach has three phases: data
fragmentation, decomposition and dispersion, which
will be discussed later. Figure 1 shows an overview
of the the i-OBJECT approach.
2.1 The Fragmentation Phase
In the fragmentation phase, the basic idea consists in
split an input file F in a sequence of n information
objects (see Definition 1). Then, we can represent a
file F as an ordered set {iOb j
1
, iOb j
2
, ··· , iOb j
n
} of
i-OBJECTs.
Definition 1 (i-OBJECT). An information object, i-
OBJECT for short, is a piece of 256 sequential bytes
from a file.
ICEIS 2016 - 18th International Conference on Enterprise Information Systems
360

Figure 1: i-OBJECT Approach Overview.
2.2 The Decomposition Phase
The decomposition phase receives as input a file
F, represented as an ordered set {iOb j
1
, iOb j
2
, ··· ,
iOb j
n
} of i-OBJECTs, and using the Hegel’s the-
ory (Hegel, 1991), according to which an object has
three fundamental characteristics (quality, quantity
and measure), decomposes F in three files: Fq.bin,
Fs.bin and Fm.bin, which represent, respectively, F’s
quality, quantity and measure.
In order to understand the decomposition phase,
it is necessary to formally define the quality, quan-
tity and measure properties. These definitions are pre-
sented next.
Definition 2 (Quality). Quality is the set of di-
verse bytes that composes a particular i-OBJECT. Let
iOb j
k
be an i-OBJECT, Q(iOb j
k
) denotes the quality
property of the iOb j
k
. Q(iOb j
k
) is a ordered vector
containing the m diverse bytes present in iOb j
k
. More
formally, Q(iOb j
k
) = {b
1
, b
2
, b
3
, ··· , b
m
} such that 1
6 b
i
6 256 and i 6= j → b
i
6= b
j
, where b
i
is a byte
present in iOb j
k
.
Definition 3 (Quantity). Quantity is an array con-
taining the number of times that each distinct byte
appears in a specific i-Object. Let iOb j
k
be an
i-OBJECT, S(iOb j
k
) denotes the quantity property
of the iOb j
k
. S(iOb j
k
) is a vector containing, for
each different byte b
j
(representing a ASCII Sym-
bol) present in Q(iOb j
k
) the number of times that
b
i
appears in iOb j
k
. More formally, S(iOb j
k
) =
{s
1
, s
2
, s
3
, ··· , s
m
} such that 1 6 s
i
6 256, where
s
i
represents the number of times that b
i
appears in
iOb j
k
.
Definition 4 (Measure). Measure is a two-
dimensional array containing, for each diverse
byte that composes a particular i-OBJECT, a vector
with the positions where this byte occurs in the
i-OBJECT. Let iOb j
k
be an i-OBJECT, M(iOb j
k
) de-
notes the measure property of the iOb j
k
. M(iOb j
k
) is
a two-dimensional array containing, for each differ-
ent byte b
j
present in Q(iOb j
k
), an array m
b
j
storing
the positions in which the byte b
j
appears in iOb j
k
.
More formally, M(iOb j
k
) = {m
b
1
, m
b
2
, ··· , m
b
m
},
such that, m = 256 and 1 6 size(m
b
i
) 6 256.
Given a file F, where F =
{iOb j
1
, iOb j
2
, ··· , iOb j
n
}. Initially, the decom-
position phase consists in extracting, for each
i-OBJECT iOb j
k
, where 1 6 k 6 n and iOb j
k
∈ F, its
properties: quality (Q(iOb j
k
)), quantity (S(iOb j
k
))
and measure (M(iOb j
k
)).
Next, the proposed approach combines the
quality values for all i-OBJECTs in the set
{iOb j
1
, iOb j
2
, ··· , iOb j
n
} and creates a file called
Fq.bin. After this, the i-OBJECT approach com-
bines the quantity values for all i-OBJECTs in the
set {iOb j
1
, iOb j
2
, ··· ,iOb j
n
} and creates a file de-
noted by Fs.bin. Finally, the proposed approach com-
bines the measure values for all i-OBJECTs in the
set {iOb j
1
, iOb j
2
, ··· , iOb j
n
} and creates a file called
Fm.bin (see Figure 1).
In order to illustrated how an i-OBJECT iOb j
k
is
decomposed into its three basic properties (Q, S and
M) consider the following example, denoted Example
1. Example 1: Consider an i-OBJECT iOb j
k
con-
taining the following text:
"Google dropped its cloud computing prices
and other vendors are expected to follow
suit, but the lower pricing may not be
the key for attracting enterprises to the
cloud. When Enterprises comes to cloud,
they’re more concerned about privacy
and security"
Note that iOb j
k
contains 31 diverse bytes, where each
byte represents a ASCII symbol. So, the quality
property of the iOb j
k
is a vector with 31 elements,
as follows: Q(iOb j
k
) = { 32(space), 34(”), 39(’),
44(,) 46(.), 69(E), 71(G), 87(W), 97(a), 98(b), 99(c),
100(d), 101(e), 102(f), 103(g), 104(h), 105(i), 107(k),
108(l), 109(m), 110(n), 111(o), 112(p), 114(r),
115(s), 116(t), 117(u), 118(v), 119(w), 120(x), 121(y)
} Thereby, the quantity property of the iOb j
k
is also a
vector with 31 elements: S(iOb j
k
) = { 40, 2, 1, 2, 1, 1,
1, 1, 8, 3, 13, 10, 28, 2, 4, 6, 11, 1, 7, 4, 12, 21, 9, 18,
10, 21, 8, 2, 2, 1, 5 } It’s important to note the relation-
ship between quality and quantity properties. Note
that, for example, the character “space” (ASCII 32),
the first element in Q(iOb j
k
), denoted by Q(iOb j
k
)
1
,
appears 40 times in the iOb j
k
, and the character “y”
(ASCII 121), the last element in Q(iOb j
k
), denoted
by Q(iOb j
k
)
31
, occurs 5 times in the iOb j
k
. In this
A Flexible Mechanism for Data Confidentiality in Cloud Database Scenarios
361

scenario, the measure property of the iOb j
k
is a two-
dimensional array containing 31 arrays, as follows:
M(iOb j
k
) = {{ 7, 15, 19, 25, 35, 42, 46, 52, 60, 64,
73, 76, 83, 89, 93, 97, 103, 111, 115, 119, 122, 126,
130, 134, 145, 157, 160, 164, 171, 176, 188, 194, 197,
204, 212, 217, 227, 233, 245, 241 }, { 0, 255}, { 209
}, · · · , { 114, 129, 208, 253, 240 }} Observe that, for
example, the character “y” (ASCII 121), the 31st ele-
ment in Q(iOb j
k
), occurs 5 times (Q(iOb j
k
)
31
= 5) in
the iOb j
k
, in the positions 114, 129, 208, 253 and 240,
which are represented by the last array in M(iOb j
k
).
The Algorithm 1 illustrates how a file F is decom-
posed in the files F
q
.bin, F
s
.bin and F
m
.bin. The Algo-
rithm 2 shows how the files F
q
.bin, F
s
.bin and F
m
.bin
are used to recompose the file F.
The decomposition algorithm (Algorithm 1) is
performed in two stages. The first step (lines 1 to 17)
obtains the information of the bytes ordinal positions
(M) of iOb j
k
(Q) and stores it in a two-dimensional
vector temp [256] [256] (line 12), where the first di-
mension of the vector represents the decimal value of
the byte and the second dimension is a list of the po-
sitions occupied by the byte’s occurrence in iOb j
k
.
The second step of the process (lines 18 to 41) gener-
ates three vectors containing the Q and S information,
where each element of these sets is represented by one
bit, and a byte vector M, which contains the positions
grouped in ascending order of Q elements. In groups
with more than one element, the two last elements are
made to reverse its positions to indicate the end of the
group.
The recomposition algorithm (Algorithm 2) receives
as input the files F
q
.bin, F
s
.bin and F
m
.bin and restores
the original file F. The files are read sequentially in
blocks of 256 bits (Q and S) and 256 bytes (M) (lines
4 to 6) so that the rebuilding of elements Q, S and M
starts. The algorithm goes through the sample space
of Q elements (0 to 255), identifying bytes exist in
iOb j
k
(line 11) and if they occur one time or more
than once (S) (line 15) to then retrieve positions oc-
cupied by these bytes and insert them in vector iOb j
k
(rows 18 and 22).
2.3 The Dispersion Phase
In the dispersion step, the files F
q
.bin, F
s
.bin and
F
m
.bin are spread across different cloud storage ser-
vice providers. So, i-OBJECT requires that these
three files are isolated between themselves.
Algorithm 1: Decomposition function.
input : File F
output : File Fq.bin, Fs.bin, Fm.bin
1 F unction − Decomposition(F );
2 begin
3 IOb j = Read(F, 256);
4 CreateFile(Fq.bin, F s.bin, Fm.bin);
5 Temp[256][256];
6 while IOb j not null do
7 byte = 0; cont = 0; f req[] = 0;
8 for pos = 0 to 255 do
9 byte = IOb j[pos];
10 f req[byte] ++;
11 cont = f req[byte];
12 Temp[byte][cont] = pos;
13 end for
14 CreateQSM(Temp, f req);
15 IOb j = Read(F, 256);
16 end while
17 end
18 F unction −CreateQSM(Temp[256][256], f req[256]);
19 begin
20 Q[256] = 0; S[256] = 0; M[256] = 0;
21 pos = 0; postemp = 0; cont = 0; cont2 = 0;
22 for byte = 0 to 255 do
23 if f req[byte] ≥ 1 then
24 Q[byte] = 1;
25 if f req[byte] ≥ 2 then
26 S[cont2] = 1;
27 postemp = Temp[byte][ f req[byte]];
28 Temp[byte][ f req[byte]] =
Temp[byte][ f req[byte] − 1];
29 Temp[byte][ f req[byte] − 1] = postemp;
30 end if
31 for cont = 1 to f req[byte] do
32 M[pos] = Temp[byte][cont];
33 pos ++;
34 end for
35 cont2 ++;
36 end if
37 end for
38 Append(Fq.bin, Q);
39 Append(Fs.bin, S);
40 Append(Fm.bin, M);
41 end
3 DATA CONFIDENTIALITY
CONSIDERATIONS
The data confidentiality in the proposed approach
stems from the fact that the files Fq.bin, Fs.bin and
Fm.bin are stored in different cloud providers, which
are physically and administratively independent. Ac-
cording to (Resch and Plank, 2011), physical data
dispersion in different storage servers, along with
the careful choice of the number of servers and the
amount of fragments needed for restore the original
ICEIS 2016 - 18th International Conference on Enterprise Information Systems
362
Algorithm 2: Recomposition function.
input : File Fq.bin, Fs.bin, Fm.bin
output : File F
1 F unction − Recomposition(F);
2 begin
3 CreateFile(F);
4 Q[256] = Read(Fq.bin, 256);
5 S[256] = Read(Fs.bin, 256);
6 M[256] = Read(F m.bin, 256);
7 while Q not null do
8 ordem = 0; cont = 0; pos = 0;
9 for bit = 0 to 255 do
10 if Q[bit] 6= 0 then
11 pos ← M[ordem];
12 IOb j[pos] ← CodASCII(Q[bit]);
13 ordem ++;
14 if S[cont] = 1 then
15 while M[ordem] > pos do
16 pos ← M[ordem];
17 IOb j[pos] ← CodASCII(Q[bit]);
18 ordem ++;
19 end while
20 pos ← M[ordem];
21 IOb j[pos] ← CodASCII(Q[bit]);
22 ordem ++;
23 end if
24 cont ++;
25 end if
26 end for
27 Append(F, IOb j);
28 Q[256] = Read(Fq.bin, 256);
29 S[256] = Read(Fs.bin, 256);
30 M[256] = Read(F m.bin, 256);
31 end while
32 end
files, reduces the chances of an attacker and is enough
to make a system safe. So, in i-OBJECT, the de-
gree of data confidentiality is based on the difficulty
of the attackers to reconstruct the i-OBJECTS from
one of these three files, Fq.bin, Fs.bin or Fm.bin. Be-
sides, i-OBJECT is a flexible mechanism since it can
be used alone or together with other previously ap-
proaches (such as encryption algorithms like AES,
DES or 3-DES) in order to increase the data confi-
dentiality level.
4 EXPERIMENTAL EVALUATION
In order to show the potentials of i-OBJECT, several
experiments have been conducted. The main results
achieved so far are presented and discussed in this
section. Thus, we first provide information on how
the experimentation environment was set up. There-
after, empirical results are quantitatively presented
and qualitatively discussed.
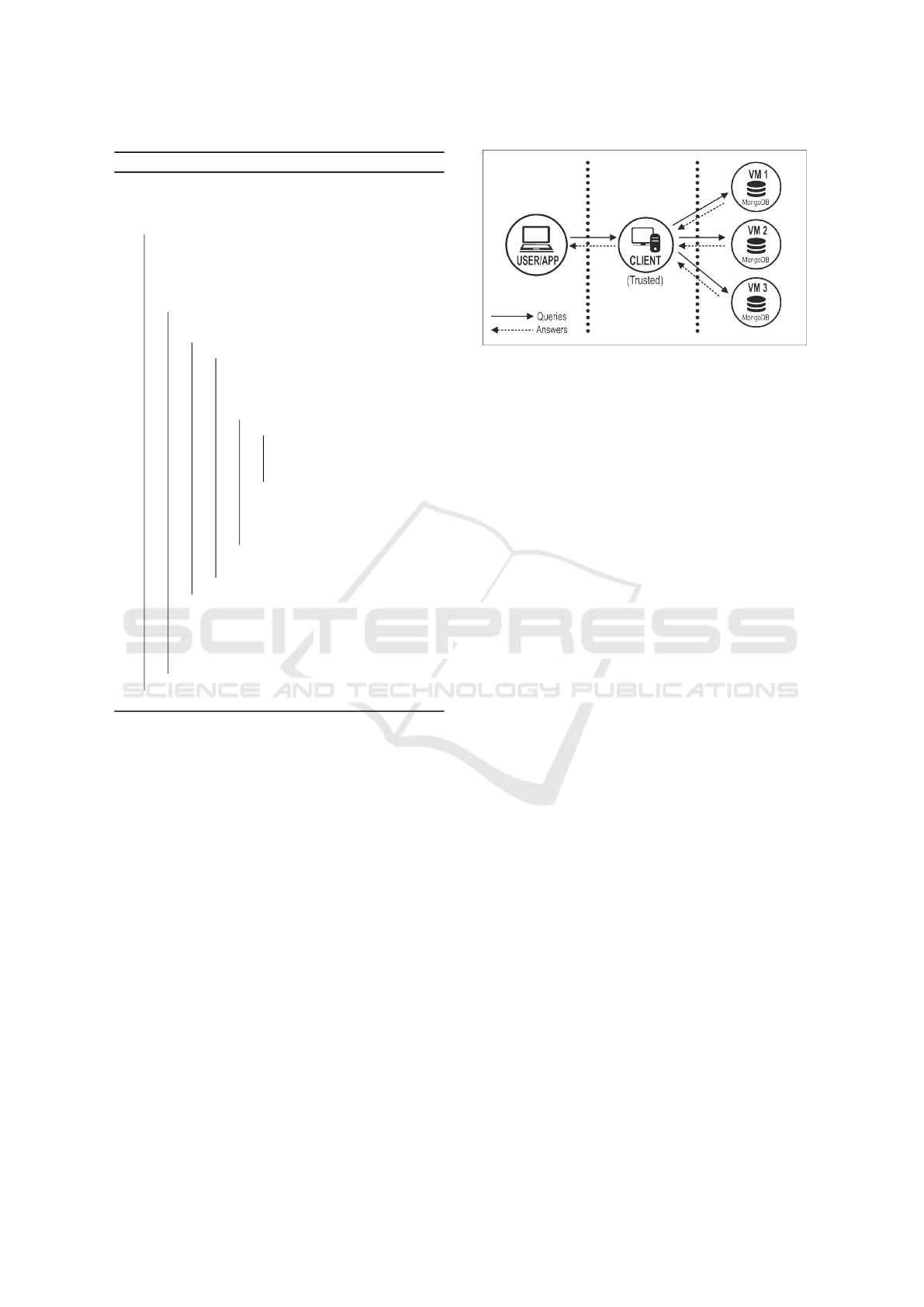
Figure 2: Experimental Architecture.
4.1 Experimental Setup
We implemented i-OBJECT and the other data confi-
dentiality approaches using C and Java. In order to
run these approaches we have used a private cloud
computing infrastructure based on OpenStack. Fig-
ure 2 shows the architecture used in the experiments,
which contains two kinds of virtual machines: the
client node and the data storage nodes. The client, a
Trusted Third Party (TTP), runs the i-OBJECT algo-
rithms: decomposition and recomposition. The data
storage nodes (called VM1, VM2 and VM3) emulate
three different cloud storage service providers. We
assume that the data nodes provide reliable content
storage and data management but are not trusted by
the client to maintain data privacy.
Each data storage node has the following config-
uration: Ubuntu 14.04 operating system, Intel Xeon
2.20 GHz processor, 4 GB memory and 50 GB disk.
The client is a Intel Xeon 2.20 GHz processor, 4 GB
memory and 40 GB disk capacity, running a Windows
Server 2008.
Besides this, each data storage node has a Mon-
goDB instance with default settings. MongoDB is
an open source, scalable, high performance, schema-
free, document oriented database. We opted to use
the MongoDB because it is one of the most used
database in cloud computing environments and exists
opportunities for improvement its security and pri-
vacy. MongoDB supports a binary wire-level protocol
but doesn’t provide a method to automatically encrypt
data. This means that any attacker with access to the
file system can directly extract the information from
the files (Okman et al., 2011).
In order to evaluate the i-OBJECT efficiency, we
have used a document collection, synthetically cre-
ated, which contains files (documents) with different
sizes. Each file has four parts (or attributes), which
have the same size. These attributes are: curriculum
vitae (A1), paper text (A2), author photo (A3) and pa-
per evaluation (A4).
A Flexible Mechanism for Data Confidentiality in Cloud Database Scenarios
363
4.2 Test Results
In this section, we present the results of the exper-
iments we carried out. For evaluate the i-OBJECT
efficiency, we have used two metrics: the input and
output times. The input time is defined as the total
amount of time spent to process a file F and gener-
ates the data that will be send to the cloud storage ser-
vice providers. The output time is defined as the to-
tal amount of time spent to process the data received
from the cloud storage service providers in order to
remount the original file F. It is important to highlight
that the time spend in the communication process, to
send and receive data to the cloud providers do not
composes neither the input nor the output time. We
have evaluated different file sizes (2
18
, 2
20
and 2
22
bytes). For each distinct file size, we have used 10
files and computes the average time for decomposes
and recomposes these files. To validate the i-OBJECT
approach, we have evaluated four different scenarios,
which will be discussed next.
4.2.1 Scenario 1: Encryption Algorithms
The first scenario was running with the aim of com-
pare the most popular symmetric cryptographic algo-
rithms: AES, DES and 3-DES. It is important to note
that, in this experiment, the Input Time matches the
Encryption Time (the spent time to encrypt a file F)
and Output Time matches the Decryption Time (time
necessary to decrypt a file F).
So, in this scenario, the client receives a file F
from the user, encrypt it, generating a new file F
e
, and
sends F
e
to VM1. Figure 3 shows the encryption time
for the algorithms AES, DES and 3-DES. Next, the
client receives the encrypted file F
e
from VM1, de-
crypt it, generating the original file F and sends F to
the user. Figure 4 shows the decryption time for the
algorithms AES, DES and 3-DES. Note that, for files
with size of 2
16
bytes these three algorithms presented
the same encryption time, while AES and DES pre-
sented the same decryption time. However, for files
with sizes of 2
18
, 2
20
, and 2
30
bytes AES outperforms
DES and 3-DES, for both encryption and decryption.
4.2.2 Scenario 2: Data Confidentiality
Approaches
In the second scenario, we compared the i-OBJECT
approach with the three main approaches to ensure the
data confidentiality in cloud environments: a) data en-
cryption, b) combination of encryption and fragmen-
tation, and c) fragmentation (see Section 1) (Samarati
and di Vimercati, 2010; Joseph et al., 2013).
2
16
2
18
2
20
2
30
0
50
100
150
4
10
40
58
4
12
43
84
4
14
52
135
File Size (bytes)
AES
DES
3-DES
Figure 3: Scenario 1: Encryption Time.
2
16
2
18
2
20
2
30
0
50
100
150
200
4
10
38
87
4
13
46
129
5
14
54
180
File Size (bytes)
AES
DES
3-DES
Figure 4: Scenario 1: Decryption Time.
In order to run the approaches (b), combination of
encryption and fragmentation, and (c), fragmentation,
it is necessary to define which attributes are sensitive,
besides to identify the sensitive association between
attributes. Moreover, splitting the attributes with sen-
sitive association into some fragment is a NP-hard
problem (Samarati and di Vimercati, 2010; Joseph
et al., 2013).
Thus, we have assumed that each document has
four attributes: curriculum vitae (A1), paper text
(A2), author photo (A3) and paper evaluation (A4).
Besides, we supposed that there is a set C of sensi-
tive association constraints, with the following con-
straints: C
1
={A1}, C
2
= {A2}, C
3
= {A2, A4}, C
4
=
{A1, A3}. So, the attributes A
1
and A
3
are consid-
ered sensitive and must be encrypted in approaches
ICEIS 2016 - 18th International Conference on Enterprise Information Systems
364
2
18
2
20
2
22
0
50
100
150
200
12
48
188
16
40
160
12
34
130
8
28
100
File Size (bytes)
i-OBJECT
Data Encryption (AES)
Encryption/Fragmentation
Fragmentation
Figure 5: Scenario 2: Input Time.
2
18
2
20
2
22
0
50
100
150
4
16
52
16
40
152
12
34
126
8
28
100
File Size (bytes)
i-OBJECT
Data Encryption (AES)
Encryption/Fragmentation
Fragmentation
Figure 6: Scenario 2: Output Time.
(b) and (c). The constraint C
3
= {A2, A4} indicates
that there is a sensitive association between A2 and
A4. The constraint C
4
= {A1, A3} indicates that there
is a sensitive association between A1 and A3, and
these attributes should be stored in different servers
in the cloud. Based on the set C of confidentiality
constraints, a set P of data fragments was generated,
as following: i) the approach (b), combination of en-
cryption and fragmentation, produced the fragments
P
1
={A1,A4} and P
2
= {A2,A3}; and ii) the approach
(c), fragmentation, formed the fragments P
3
= {A1,
A3}, P
4
= {A2} and P
5
= {A4}.
It is important to emphasize that the time neces-
sary to define the set of fragments (fragments schema)
for splitting the attributes with sensitive association,
that is a NP-hard problem, was not considered in this
experiment. Furthermore, for the approach (a), data
encryption, we have used the AES algorithm, since it
presented best results in the first scenario.
In this experiment, we considered performance
with respect to the following metrics: (i) Input Time
and (ii) Output Time. These metrics change a little
according to the used data confidentiality approach.
Input Time is computed as following:
• Approach (a), data encryption: time to encrypt a
file F using AES, generating a file F
e
. The file F
e
will be send to VM1;
• Approach (b), combination of encryption and
fragmentation: time to encrypt A
1
and A
3
, plus
the time to generates P
1
and P
2
. Where, A
1
and
P
1
will be send to VM1, while A
3
and P
2
will be
send to VM2.
• Approach (c), fragmentation: the time to gener-
ates P
3
, P
4
and P
5
. Where, P
3
will be send to
VM1, P
4
to VM2 and P
5
to VM3.
• i-OBJECT Approach: time to decompose a file
F into F
q
.bin, F
s
.bin and F
m
.bin. Where, F
q
.bin
will be send to VM1, F
s
.bin to VM2 and F
m
.bin
to VM3;
Output Time is computed as following:
• Approach (a), data encryption: time to decrypt a
file F
e
using AES, generating the original file F;
• Approach (b), combination of encryption and
fragmentation: time to decrypt A
1
and A
3
, plus
the time to join A
1
, A
3
, P
1
and P
2
in order to re-
mount the file F;
• Approach (c), fragmentation: the time to join P
3
,
P
4
, P
5
and the sensitive attributes stored in the
client;
• i-OBJECT Approach: time to recompose a file F
from F
q
.bin, F
s
.bin and F
m
.bin.
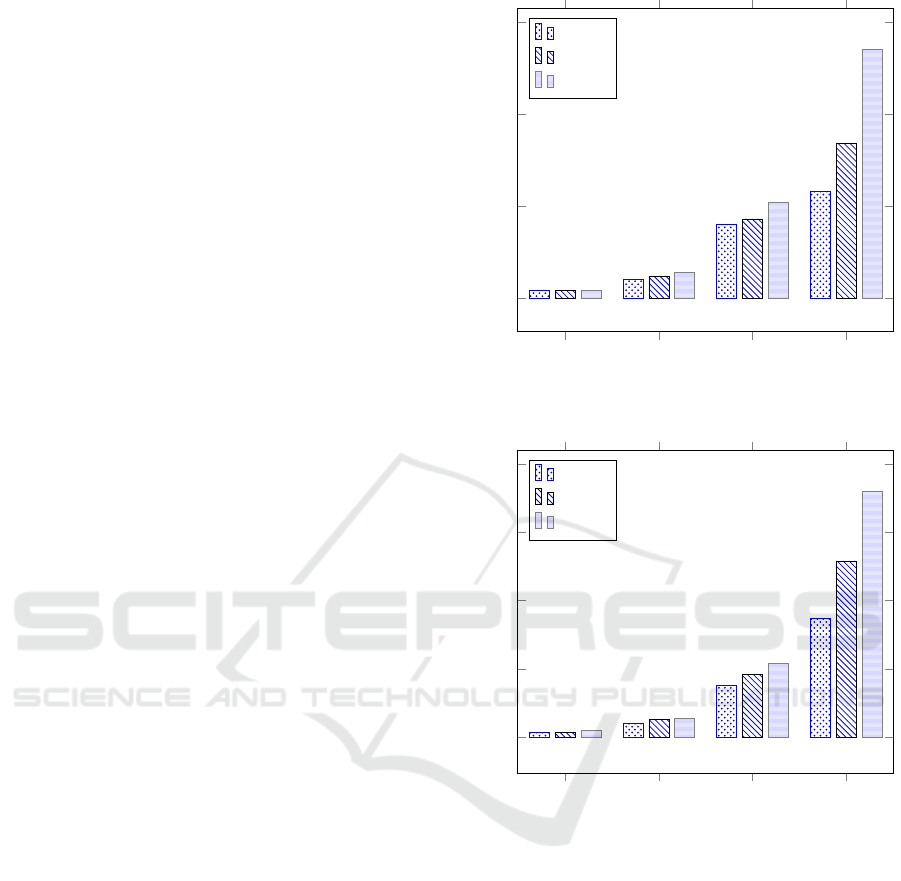
Figure 5 shows the input time for the evaluated
approaches. Note that i-OBJECT approach has a per-
formance slightly worse than Data Encryption (AES).
Fragmentation approach outperforms the other ap-
proaches, for all file sizes. On the other hand, the last
two approaches, Encryption/Fragmentation and Frag-
mentation, need to define the set of fragments (frag-
mentation schema) for splitting the attributes with
sensitive association. However, how we have used a
fixed example, the time necessary to define the frag-
mentation schema was not computed. In part, this
explains the better results obtained by these two ap-
proaches.
Figure 6 shows the output time for the evaluated
approaches. Note that i-OBJECT outperforms all the
other approaches, for all file sizes. It is important to
A Flexible Mechanism for Data Confidentiality in Cloud Database Scenarios
365

2
18
2
20
2
22
0
100
200
12
48
188
20
68
240
12
48
188
16
58
214
File Size (bytes)
i-OBJECT
Encrypt+i-OBJECT
Frag+i-OBJECT
Encrypt/Frag+i-OBJECT
Figure 7: Scenario 3: Input Time.
2
18
2
20
2
22
0
50
100
150
4
16
52
16
32
104
12
40
148
14
36
126
File Size (bytes)
i-OBJECT
Encrypt+i-OBJECT
Frag+i-OBJECT
Encrypt/Frag+i-OBJECT
Figure 8: Scenario 3: Output Time.
highlight, for the file size of 2
22
bytes, i-OBJECT is
88s slower than the Fragmentation approach in the in-
put phase, that is, to process and a file F before send-
ing it to the cloud storage service provider. However,
for the same file size, i-OBJECT is 48s faster than the
Fragmentation approach. So, for a complete cycle of
file write and read, i-OBJECT is just 40s slower than
the Fragmentation approach. Then, if the user writes
F one time and reads F two times, i-OBJECT is 8s
faster than Fragmentation approach. Thus, i-OBJECT
outperforms all the other previous approach in sce-
narios where the number of reads is at least twice
larger than the number of writes, which is expected
real databases and cloud storage environments.
2
18
2
20
2
22
0
50
100
150
200
250
12
48
188
20
64
220
16
56
200
16
60
212
File Size (bytes)
i-OBJECT
i-OBJECT+AES(F
q
)+AES(F
s
)
i-OBJECT+AES(F
q
)
i-OBJECT+AES(F
s
)
Figure 9: Scenario 4: Input Time.
2
18
2
20
2
22
0
20
40
60
80
4
16
52
16
28
72
12
20
64
12
20
64
File Size (bytes)
i-OBJECT
i-OBJECT+AES(F
q
)+AES(F
s
)
i-OBJECT+AES(F
q
)
i-OBJECT+AES(F
s
)
Figure 10: Scenario 4: Output Time.
4.2.3 Scenario 3: Using i-OBJECT Together
with Previous Approaches
In the third scenario, we evaluated the use of i-
OBJECT together with previous approaches. We be-
lieve that i-OBJECT can be used together with other
data confidentiality approaches in order to improve
their data confidentiality levels.
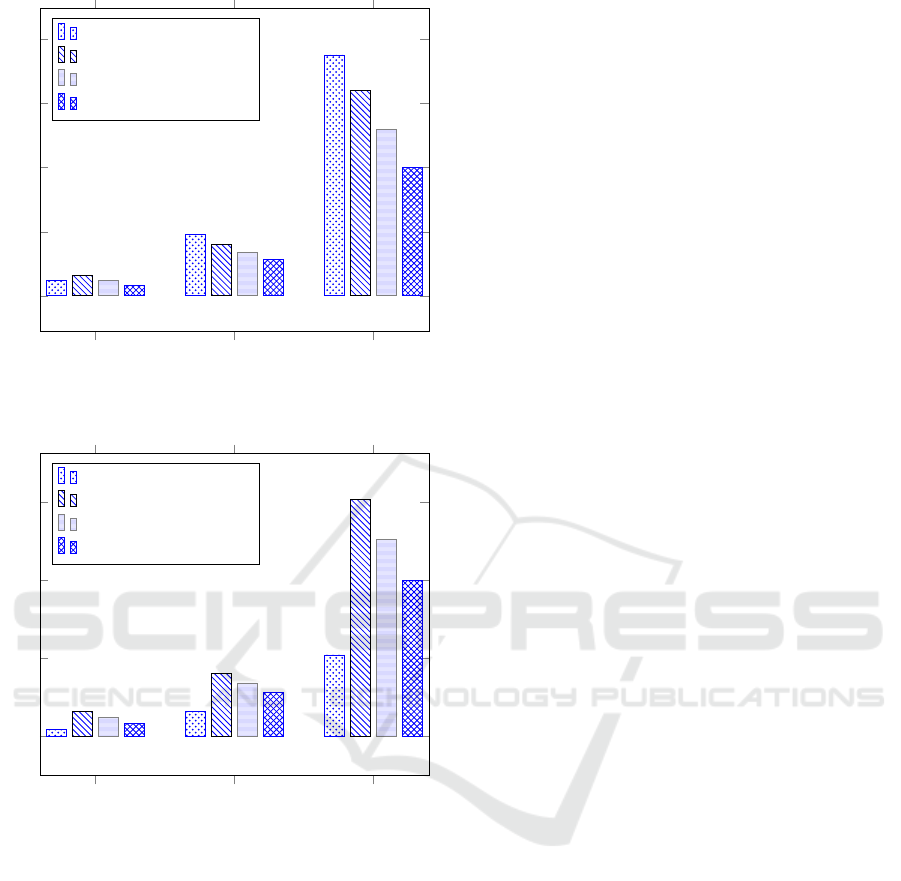
Figure 7 shows the input time for the evaluated
approaches. In this chart, the first bar shows the in-
put time to i-OBJECT (that is, the time to decompose
a file F); the second bar represents the input time to
apply the Data Encryption approach and, after that,
the i-OBJECT (that is, the time to encrypt a file F,
producing a new file F
e
, plus the time to decompose
ICEIS 2016 - 18th International Conference on Enterprise Information Systems
366

F
e
); the third bar indicates the input time to apply the
Encryption/Fragmentation approach and, next, the i-
OBJECT; finally, the fourth bar denotes the input time
to apply the Fragmentation approach and then the i-
OBJECT. Then, we can argue that i-OBJECT is a
flexible approach, in the sense that it can be used to-
gether with previous approaches, in order to improve
their data confidentiality level. The results presented
in Figure 7 show that this strategy provides a small in-
crease in the input time, while providing a high gain
in the data confidentiality. Figure 8 shows that the
output time overhead has a similar behavior that input
time.
4.2.4 Scenario 4: Improving Data
Confidentiality in i-OBJECT
In the fourth scenario, we evaluated some strategies
to improve the data confidentiality in the i-OBJECT
approach. The first strategy consists in encrypt the
files F
q
.bin and F
s
.bin, the second strategy consists
in encrypt only the file F
q
.bin and the third strategy
consists in encrypt just the file F
s
.bin.
Figure 9 and Figure 10 show, respectively. the in-
put and output time with and without the use of these
strategies. Note that the strategy of encrypting just the
file F
q
.bin provides a low overhead, while greatly in-
creases the data confidentiality level of the i-OBJECT
approach.
4.2.5 Storage Space Considerations
In the i-OBJECT approach, a file F is decomposed
into three files (Fq.bin, Fs.bin and Fm.bin), which
are dispersed (sent) to three different cloud providers.
The experimental results showed that the size of these
files represent, respectively, 12.5%, 12.5% and 90%
of the original file size. So, adding these values, the
propposed approach provides an overhead of 15% in
the disk space utilization. This drawback is mini-
mized since the cloud storage services are designed
to store a large quantity of data.
5 RELATED WORK
A significant amount of research has recently been
dedicated to the investigation of data confidentiality in
cloud computing environment. Most of this work has
assumed the data to be entirely encrypted, focusing
on the design of queries execution techniques (Ciriani
et al., 2010). In (Ceselli et al., 2005) the authors dis-
cuss different strategies for evaluating the inference
exposure for encrypted data enriched with indexing
information, showing that even a limited number of
indexes can greatly favor the task for an attacker wish-
ing to violate the data confidentiality provided by en-
cryption.
The first proposal proposing the storage of plain-
text data, while ensuring a series of privacy con-
straints was presented in (Aggarwal, 2005). In this
work, the authors suppose data to be split into two
fragments, stored on two honest-but-curious service
providers, which never exchange information, and re-
sorts to encryption any time these two fragments are
not sufficient for enforcing confidentiality constraints.
In (Ciriani et al., 2009; Ciriani et al., 2010), the au-
thors address these issues by proposing a solution that
first split the data to be protected into several (possibly
more than two) different fragments in such a way to
break the sensitive associations among attributes and
to minimize the amount of attributes represented only
in encrypted format. The resulting fragments may
be stored at different servers. The proposed heuristic
to design these fragments present a polynomial-time
computation cost while is able to retrieve solutions
close to optimum. In (Xu et al., 2015), the authors
propose an efficient graph search based method for
the fragmentation problem with confidentiality con-
straints, which obtains near optimal designs.
The work presented in (Ciriani et al., 2009) pro-
poses a novel paradigm for preserving data confiden-
tiality in data outsourcing which departs from en-
cryption, thus freeing the owner from the burden of
its management. The basic idea behind this mech-
anism is to involve the owner in storing the sensi-
tive attributes. Besides, for each sensitive association,
the owner should locally store at least an attribute.
The remainder attributes are stored, in the clear, at
the server side. With this fragmentation process, an
original relation R is then split into two fragments,
called F
o
and F
s
, stored at the data owner and at the
server side, respectively. (Wiese, 2010) extends the
“vertical fragmentation only” approach and proposes
use horizontal fragmentation to filter out confidential
rows to be securely stored at the owner site. (Krishna
et al., 2012) proposes an approach based on data frag-
mentation using graph-coloring technique wherein a
minimum amount of data is stored at the owner. In
(Rekatsinas et al., 2013) the authors present SPARSI,
a theoretical framework for partitioning sensitive data
across multiple non-colluding adversaries. They in-
troduce the problem of privacy-aware data partition-
ing, where a sensitive dataset must be partitioned
among k untrusted parties (adversaries). The goal is
to maximize the utility derived by partitioning and
distributing the dataset, while minimizing the total
amount of sensitive information disclosed. Solving
A Flexible Mechanism for Data Confidentiality in Cloud Database Scenarios
367

privacy-aware partitioning is, in general, NP-hard, but
for specific information disclosure functions, good
approximate solutions can be found using relaxation
techniques.
In (Samarati and di Vimercati, 2010) the authors
discuss the main issues to be addressed in cloud stor-
age services, ranging from data confidentiality to data
utility. They show the main research directions be-
ing investigated for providing effective data confiden-
tiality and for enabling their querying. The survey
presented in (Joseph et al., 2013) addressed some ap-
proaches for ensuring data confidentiality in untrusted
cloud storage services. In (Samarati, 2014), the au-
thors discuss the problems of guaranteeing proper
data security and privacy in the cloud, and illustrate
possible solutions for them.
6 CONCLUSION AND FUTURE
WORK
Experimental results showed the efficiency of i-
OBJECT, which can be used with any kind of file and
is more suitable for files larger than 256 bytes, files
with high entropy and environments where the num-
ber of read operations exceeds the number of writes.
As a future work, we intend realize a detailed analy-
sis of the i-OBJECT security and evaluate i-OBJECT
performance with other data types and using differ-
ent cloud configurations, including public and mixed
clouds.
REFERENCES
Aggarwal, C. C. (2005). On k-anonymity and the curse
of dimensionality. In Proceedings of the 31st inter-
national conference on Very large data bases, pages
901–909. VLDB Endowment.
Camenisch, J., Fischer-Hbner, S., and Rannenberg, K.
(2011). Privacy and identity management for life.
Springer.
Ceselli, A., Damiani, E., De Capitani di Vimercati, S., Jajo-
dia, S., Paraboschi, S., and Samarati, P. (2005). Mod-
eling and assessing inference exposure in encrypted
databases. ACM Transactions on Information and Sys-
tem Security (TISSEC), 8(1).
Ciriani, V., De Capitani Di Vimercati, S., Foresti, S., Jajo-
dia, S., Paraboschi, S., and Samarati, P. (2009). Keep a
few: Outsourcing data while maintaining confidentia-
lity. In Proceedings of the 14th European Conference
on Research in Computer Security, ESORICS’09,
pages 440–455, Berlin, Heidelberg. Springer-Verlag.
Ciriani, V., Vimercati, S. D. C. D., Foresti, S., Jajodia,
S., Paraboschi, S., and Samarati, P. (2010). Combin-
ing fragmentation and encryption to protect privacy in
data storage. ACM Trans. Inf. Syst. Secur., 13(3):22:1–
22:33.
Clarke, R. (1999). Introduction to dataveillance and infor-
mation privacy, and definition of terms.
Hegel, G. (1991). The encyclopedia logic (tf geraets, wa
suchting, hs harris, trans.). Indianapolis: Hackett, 1.
Joseph, N. M., Daniel, E., and Vasanthi, N. A. (2013). Ar-
ticle: Survey on privacy-preserving methods for stor-
age in cloud computing. IJCA Proceedings on Amrita
International Conference of Women in Computing -
2013, AICWIC(4):1–4. Full text available.
Krishna, R. K. N. S., Sayi, T. J. V. R. K. M. K., Mukka-
mala, R., and Baruah, P. K. (2012). Efficient privacy-
preserving data distribution in outsourced environ-
ments: A fragmentation-based approach. In Pro-
ceedings of the International Conference on Ad-
vances in Computing, Communications and Informat-
ics, ICACCI ’12, pages 589–595, New York, NY,
USA. ACM.
Okman, L., Gal-Oz, N., Gonen, Y., Gudes, E., and
Abramov, J. (2011). Security issues in nosql
databases. In Trust, Security and Privacy in Com-
puting and Communications (TrustCom), 2011 IEEE
10th International Conference on, pages 541–547.
Rekatsinas, T., Deshpande, A., and Machanavajjhala,
A. (2013). Sparsi: Partitioning sensitive data
amongst multiple adversaries. Proc. VLDB Endow.,
6(13):1594–1605.
Resch, J. K. and Plank, J. S. (2011). Aont-rs: blending se-
curity and performance in dispersed storage systems.
In Proceedings of FAST-2011: 9th Usenix Conference
on File and Storage Technologies,February 2011.
Samarati, P. (2014). Data security and privacy in the cloud.
In Information Security Practice and Experience -
10th International Conference, ISPEC 2014, Fuzhou,
China, May 5-8, 2014. Proceedings, pages 28–41.
Samarati, P. and di Vimercati, S. D. C. (2010). Data protec-
tion in outsourcing scenarios: Issues and directions. In
Proceedings of the 5th ACM Symposium on Informa-
tion, Computer and Communications Security, ASI-
ACCS ’10, pages 1–14, New York, NY, USA. ACM.
Wiese, L. (2010). Horizontal fragmentation for data
outsourcing with formula-based confidentiality con-
straints, pages 101–116. Springer.
Xu, X., Xiong, L., and Liu, J. (2015). Database fragmen-
tation with confidentiality constraints: A graph search
approach. In Proceedings of the 5th ACM Conference
on Data and Application Security and Privacy, CO-
DASPY ’15, pages 263–270, New York, NY, USA.
ACM.
Zhifeng, X. and Yang, X. (2013). Security and privacy in
cloud computing. Communications Surveys & Tutori-
als, IEEE, 15(2):843–859.
ICEIS 2016 - 18th International Conference on Enterprise Information Systems
368
