
Effect of Typicality in Abstract Word Categories on N400 ERP
Mansoureh Fahimi
and Marc Van Hulle
Laboratory of Neuro- and Psychophysiology, KU Leuven University, Leuven, Belgium
1 OBJECTIVES
We investigate the effect of word typicality −the
degree of membership of a word to its superordinate
category− on the N400 event-related potential (ERP)
using a single-trial detection approach based on
spatiotemporal beamforming. Unlike the norm in
N400 studies, where mostly concrete categories are
used (imaginable objects), we considered a total of 6
basic categories: three abstract and unimaginable
(emotion, event, illness), one abstract yet clearly
imaginable (colour), and two concrete categories,
one coherent (mammals) and one incoherent
(furniture). Our results show that, independently of
word abstractness or concreteness, word typicality
has a clear effect on N400 both in terms of
amplitude and scalp localization, which in turn is
indicative of differences in difficulty of word
processing.
2 METHODS
Stimuli were developed to belong to 6 basic
categories. For each of the 6 categories, 15 word
stimuli were chosen, and a subsequent group of
about the same size chosen as “fillers” from random
categories of mainly concrete words (out of category
word-pairs). The typical and atypical category
members, and also the filler words (non-category
members), were matched for word length,
orthographic neighborhood size, and frequency of
occurrence, using the Dutch CLEARPOND software
(Marian et al., 2012).
Table 1: means (m) and standard deviation (std) of
considered word properties.
In-category Non-category
Word length m=6.7, std=2.2 m=6.7, std=1.5
Orth.Neighb. size m=2.6, std=3.6 m=1.7, std=2.2
Freq.of occurrence m=19.2, std=31.7 m=12.1, std=17.2
We recruited 17 volunteers to score, on a scale of
1-5, 90 words based on how typical they thought an
exemplar of each category was.
Table 2: Example words for each category.
typical atypical nonmember
gebeurtenis
feest kindertijd basketbal
(event)
(party) (childhood) (basketball)
kleur
blauw amber acteur
(color)
(blue) (amber) (actor)
meubel
stoel kapstok galerij
(furniture)
(chair) (coat rack) (gallery)
ziekte
epilepsie verslaving ooievaar
(illness)
(epilepsy) (addiction) (stork)
zoogdier
olifant vleermuis vuilnis
(mammal)
(elephant) (bat) (garbage)
emotie
droefheid verwarring vliegtuig
(emotion)
(sadness) (confusion) (plane)
The experimental paradigm was a simple word-
pair experiment (semantic priming). The prime word
was always chosen to be the label of the
superordinate category (i.e., the name of the
category). The target is randomly chosen to be either
a non-member (“filler”) or one of the 15 words
chosen as member of that category.
EEG data was recorded using 64 active Ag/AgCl
electrodes (SynampsRT, Compumedics, France),
according to the international 10-20 system. Two of
these electrodes served as ground (AFz) and
reference (FCz). The EEG signal was recorded at a 2
KHz sampling rate and downsampled to 250 Hz.
We recruited for our pilot study 12 subjects (5
males, two left-handed, average age was 21.6, std=
1.9). Ethical approval for this study was granted by
an independent ethical committee (“Commissie voor
Medische Ethiek” of UZ Leuven, our University
Hospital). This study was conducted in accordance
with the most recent version of the Declaration of
Helsinki.
Data Analysis
The EEG data was re-referenced offline from the
original ground and reference to a common average
reference (CAR), and filtered using a 4
th
order
Butterworth filter in the range of 0.1-30 Hz. A
second filtering in the range of 0.1 to 30 Hz was
applied to further demote possible remaining
artefacts. The data was epoched using windows
starting from 100ms prior to the presentation of the
stimulus of interest (target) until 1000ms post-onset.
The baseline was removed using the average signal
6
Fahimi, M. and Hulle, M.
Effect of Typicality in Abstract Word Categories on N400 ERP.
In Extended Abstracts (NEUROTECHNIX 2016), pages 6-8
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

in a 100ms interval prior to stimulus onset. Trials in
which the signal exceeded ±150µV where excluded
from the analysis. Trials in which mouse button
press responses were incorrect for non-member and
typical member targets were also omitted, yet
incorrect button press responses for atypical words
were not omitted.
LCMV Beamformer for Single-trial ERP
Detection
The linearly constrained minimum variance (LCMV)
beamformer (van Vliet et. Al 2016) is a
spatiotemporal filter that relies on spatial- and
temporal templates of the ERP collected during a
training session (using a proportion of the dataset for
training). These templates are formed by subtracting
the average EEG recordings of two experimental
paradigms both in time (between 350 and 500ms after
stimulus onset) and space (electrodes). As our experi-
ment involved three possible outcomes (typical, atypi-
cal, and nonmember), we used trials of nonmember
and typical targets to maximize the N400 effect. This
template is optimized two satisfy two criteria: a)
maximal correlation with the actual amplitude of our
component of interest (here N400) and b) minimal
correlation with interfering signals, such as noise or
other ERP components. The template is then applied
to each epoch separately (single trial) and the
beamformer returns a single value, which indicates
the presence of an N400 response for that epoch.
Statistical Analysis
Since we have unbalanced data, a linear mixed effect
model was used with N400 response (the output
resulting of the beamformer, cf. supra) as an indepen-
dent variable, and with the following fixed effects for
several analyses: relatedness (whether or not our
target was a member of the category, irrelevant of
typicality), typicality (labels of the targets divided into
typical, atypical, and nonmembers), and concreteness
(labels of the targets divided based on whether they
are members of the concrete or the abstract category).
Random effects were targets, primes and subjects.
Repeated measures analysis of variance (ANOVA)
was performed on the outcomes of the linear mixed
effect model. A significance level of 5% was adopted
for all analyses.
3 RESULTS
Beamformer Results
Out of the 64 recording channels, we selected a total
of 31 channels. Given that only a percentage of the
data should be used for training our beamformer
template, we needed to choose a proportion of the
data, where randomly chosen trials would still show
consistent beamformer templates across replications.
When we used 60 percent of the data (which is, 30%
of the typical and unrelated trials respectively), we
achieved an overall stability in both the spatial and
temporal templates. Note that we do not use trials
with atypical targets to develop the beamformer,
because they are expected to be in between the two
extreme cases of typical and unrelated, but also
because atypical trials in general were less
prominent than typical and unrelated ones. To assure
statistical stability across replications, we formed the
beamformer in 100 iterations and analyzed the mean
and variance for the spatial and temporal templates.
An example of both templates is shown in fig. 1.
Figure 1: Spatial (left) and temporal (right) beamformer
templates.
The first hypothesis we tested was on the general
relatedness (target versus nontarget). A one-way
ANOVA of general relatedness (including typical
and atypical members) against unrelated members
revealed a significant difference (p=0.00175,
F=5.6743). When looking for effects of typicality
versus atypicality versus nonmember, a significant
difference of (p=0.0008435, F=4.8172) was found,
both when all groups were included, but also when
the group ‘colour’ was excluded from the analysis
(p=0.004236, F=3.1828). Further pairwise
comparison of the groups revealed a significant
difference between typical versus atypical exemplars
of the categories (p= 0.002725, F=3.7217). An
ANOVA analysis of the effect of concreteness
versus abstractness on the N400 amplitude was also
significant (p=0.002589, F=3.0919). Note that this
result also holds when we eliminate the group
‘colour’ from the analysis (p=0.0045245, F=2.5084),
which shows that our results apply to both cases of
using only abstract unimaginable groups, and when
the abstract category includes both imaginable and
unimaginable words.
Effect of Typicality in Abstract Word Categories on N400 ERP
7
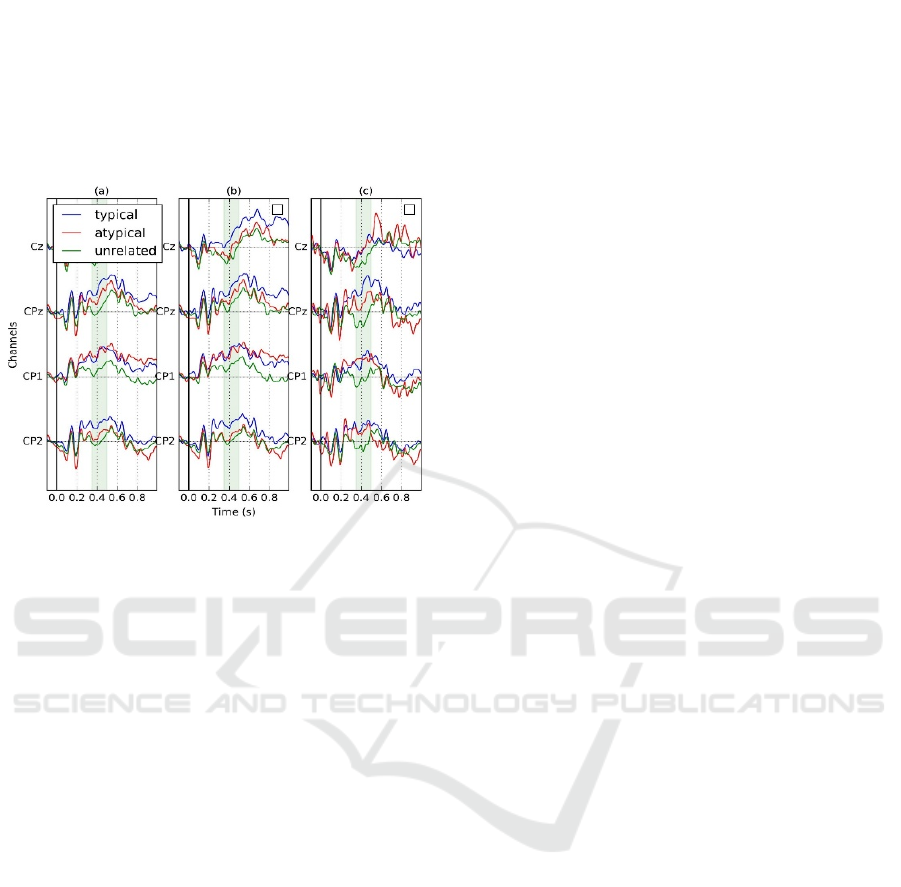
ERP Analysis
The ERPs of four centrally located (Cz, CPz, CP1,
CP2) electrodes are plotted in fig. 2. They show a
clear distinction between the two different groups of
categories, contrary to the lateralized electrodes
where the abstract and concrete categories resulted
in slightly distorted ERPs.
Figure 2: ERP plots of subjects for a) both categories,
b) only abstract categories and c) only concrete categories.
4 DISCUSSION
In this study we have investigated the effect of an
atypical member of a category on the N400 ERP for
both abstract and concrete word categories. We
observed a bigger N400 effect for trials with less
clear examples of a given category, in accordance
with the prototype hypothesis (Rosch, 1975).
However, this hypothesis was previously tested
mostly for categories of imaginable, concrete words,
such as vegetables, flowers, or birds (Fujihara et. Al,
1998). Categories of abstract concepts were given
less attention. Here, we evaluated the prototype
hypothesis using three abstract categories (illness,
event, and emotion) and one abstract- but still
imaginable category. The typicality effect was
observed in N400 ERP in both the abstract and the
concrete categories. The latter has been shown in
previous studies (Fujihara et. Al, 1998), but not for
the abstract categories. Also it has been shown that
the N400 effect is generally larger for concrete
versus abstract word-pairs (Kounios and Holcomb,
1994, Tolentino and Tokowicz, 2009). In our study
we also found a significant difference between the
two groups, both when the comparison was only
between abstract, unimaginable words versus
concrete ones, and when the abstract category
included imaginable words.
ACKNOWLEDGEMENTS
Mansoureh Fahimi is supported by Hermes Fund, National
Fund for Scientific Research Flanders (SB/151022).
MMVH is supported by PFV/10/008, IDO/12/007,
IOF/HB/12/021, G088314N, G0A0914N, IUAP P7/11,
AKUL 043.
REFERENCES
Fujihara, N., Nageishi, Y., Koyama, S., & Nakajima, Y.,
1998. Electrophysiological evidence for the typicality
effect of human cognitive categorization. Int. J.
Psychophys., 29(1), 65-75.
Kounios, J., & Holcomb, P. J., 1994. Concreteness effects
in semantic processing: ERP evidence supporting
dual-coding theory. J. Exp. Psychol.: Learning,
Memory, and Cognition, 20(4), 804.
Marian, V., Bartolotti, J., Chabal, S., & Shook, A., 2012
CLEARPOND: Cross-linguistic easy-access resource
for phonological and orthographic neighborhood
densities. PloS one, 7(8), e43230.
Rosch, E., 1975. Cognitive representations of semantic
categories. J. Exp. Psychol.: General, 104(3), 192.
Tolentino, L. C., & Tokowicz, N., 2009. Are pumpkins
better than heaven? An ERP investigation of order
effects in the concrete-word advantage. Brain and
Llanguage, 110(1), 12-22.
Van Vliet, M., Chumerin, N., De Deyne, S., Wiersema, J.
R., Fias, W., Storms, G., & Van Hulle, M. M., 2016
Single-Trial ERP Component Analysis Using a
Spatiotemporal LCMV Beamformer. IEEE BME,
63(1), 55-66.
NEUROTECHNIX 2016 - 4th International Congress on Neurotechnology, Electronics and Informatics
8
