
Risk Early-Warning Model of High-Tech Entrepreneurial Enterprise
Based on BP Neural Network
Xiaofeng Li
1
, Wang Tian
1
and Ke Wu
2
1
Department of Management science, School of Business, Sichuan University, Chengdu 610064, P.R. China
2
Department of enterprise management, School of Business, Sichuan University, Chengdu 610064, P.R. China
{f_author, t_author}lixiaofeng@scu.edu.cn
Keywords: High-tech, Entrepreneurial enterprise, BP Neural network, Risk early warning.
Abstract: Entrepreneurship is a high-risk activity. In the entrepreneurial process, it may cause a significant loss or
even bankruptcy for entrepreneurial enterprise if entrepreneurial enterprise cannot prevent and control risk
effectively. Therefore, it is very necessary to use scientific and effective methods to estimate and control the
early risk of entrepreneurial enterprise. In this paper, the index system of the risk early warning of high-tech
entrepreneurial enterprise was built. Then based on artificial neural network theory, the BP neural network
model of high-tech entrepreneurial enterprise’s risk early warning was established, and the relevant
algorithm was proposed too. With good ability of fault-tolerance and adaptability, this model avoids the
subjectivity of the man-made interference in the course of risk early warning, which provides a new
approach for the risk early warning of high-tech entrepreneurial enterprise. The result of empirical research
indicates that the risk early warning model of high-tech entrepreneurial enterprise based on BP neural
network is strongly scientific, practical and effective, thus it is worthy being popularized and applied.
1 INTRODUCTION
With the development of society and technology,
people are paying more attention to the technology
content of the products, and more and more
scientists and technicians start their businesses on
high-tech projects. However, high-tech
entrepreneurship is an activity of high risk for the
entrepreneurs. The uncertainty of external
environment, the difficulty and complexity of the
project and the limitation of the entrepreneurs’
ability could possibly lead to a delay, a halt or a
failure. According to some references in the United
States, entrepreneurial success rate is less than 25%,
while high-tech entrepreneurial success rate is less
than 10% (Motiar Rahman, Kumaraswamy, 2003).
So, it is very necessary to build an efficient risk
early warning system of high-tech entrepreneurial
enterprise for the management of entrepreneurial
risk.
At present, entrepreneurship risk management
has attracted more and more scholars' attention.
Consequently, some achievements have been
obtained (Zhongrui Wang, Shaojun Ma, Yitian Xu,
2003; Yuhua Li, Hongwen Lang, 2004; Pena I,
2002; Shimizu, Katsuhiko, 2012). In those papers,
the risk early warning model of entrepreneurial
enterprise is built mainly by Fuzzy Evaluation
Method, ANN(Artificial Neural Network),
Multivariate Statistical Analysis and Zeta Model.
These methods need to rely on historical samples
and expert experience, the learning of early warning
knowledge is indirect and inefficient. Besides,
dynamic early warning capability is Inadequate. As
a result, the predictions are not perfect enough. So, it
is necessary to apply other technologies and analysis
methods to research the risk early warning of
entrepreneurial enterprise. Using the method of
ANN (Artificial Neural Network), this paper
establishes the BP neural network model of high-
tech entrepreneurial enterprise’s risk early warning.
The empirical research indicates that this model has
adaptive ability, learning ability and capability of
dealing with non-linear problems, which provides a
new approach for the risk early warning of
entrepreneurship.
The paper is organized as follows. In section 2,
the index system of the risk early warning of high-
tech entrepreneurial enterprise is built. In section 3,
the traditional BP artificial neural network is
introduced. In section 4, based on artificial neural
network theory, the BP neural network model of
13
Wu K., Tian W. and Li X.
Risk Early-Warning Model of High-Tech Entrepreneurial Enterprise based on BP Neural Network.
DOI: 10.5220/0006442900130018
In ISME 2016 - Information Science and Management Engineering IV (ISME 2016), pages 13-18
ISBN: 978-989-758-208-0
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
13

high-tech entrepreneurial enterprise’s risk early
warning is established. As an application of model,
we discuss a consumption level forecast problem in
section 5. Some concluding remarks are finally
given in section 6.
2 THE RISK EARLY WARNING
INDEX SYSTEM
High-tech entrepreneurial enterprise refers to new-
born enterprises engaged in the research and
development of the advanced technologies,
producing high-tech products and representing the
direction of future industrial development. High-tech
entrepreneurial enterprise is characterized by high
investment, high risk and high yields (Zhi Zhuo,
2006). Risk early warning of high-tech
entrepreneurial enterprise is to research on the
important indexes that reflect the operations of the
entrepreneurial enterprise by applying certain
methods and obtain the actual risk profile. To
achieve this, a risk early warning index system of
entrepreneurial enterprise is required in the first
place. There are many factors that influence normal
operation of the high-tech entrepreneurial enterprise
and the relations among the factors are complex. So,
the following principles should be followed:
(1) Comprehensive principle. The index system
should have a wide coverage and be able to
completely reflect the practical results and existing
problems of the risk early warning management.
(2) Sensitive principle. The index system is
required to reflect the risk precisely and sensitively
and embody the true state of the enterprise’s
operation in time.
(3) General principle. High-tech entrepreneurial
enterprise has different types of risk in different
growth periods, so the index system must have high
ability of generalization and be able to reflect the
most essential features.
(4) Measurable Principle. The index system is
required to be represented by precise and
quantitative numerical values which derive not only
from empirical research but also from expert
evaluation.
(5) Irrelevant principle. Cut down the relevant
relations and overlapping area between the indexes
as far as possible and reduce the correlation to a
minimum.
According to the principles above, the factors
that influence the normal operation of the enterprise
are classified into several parts that form the frame
of the index system. By sending questionnaires,
interviewing experts and referring to some literature
at home and abroad (Yanping Yang, 2005; Qun Xie,
Xiaozhe Yuan, 2006; Rennan. M, Schwartz .E,
2006; Fengchao Liu, Yuandi Wang, 2004), the
frame is subdivided, supplemented and deleted in
detail. Finally, the index system is built, as is shown
in table 1.
Table 1: The risk early-warning index system of High-
Tech entrepreneurial enterprise.
First-class index
Second-class index
environmental risk
industrial policy
legal environment
industrial status
technical risk
technical advancement
technical reliability
technical substitutability
ability of research and
development
market risk
market demand
market share
sales growth
competitor capability
barriers to entry
financial risk
fund-raising ability
sales profit rate
internal rate of return
financial management
capacity
human resources risk
employee overall quality
employee turnover rate
core Taff Turnover
possibility
management risk
management capability of
entrepreneurial team
stability of entrepreneurial
team
social resources of
entrepreneurial team
ISME 2016 - Information Science and Management Engineering IV
14
ISME 2016 - International Conference on Information System and Management Engineering
14
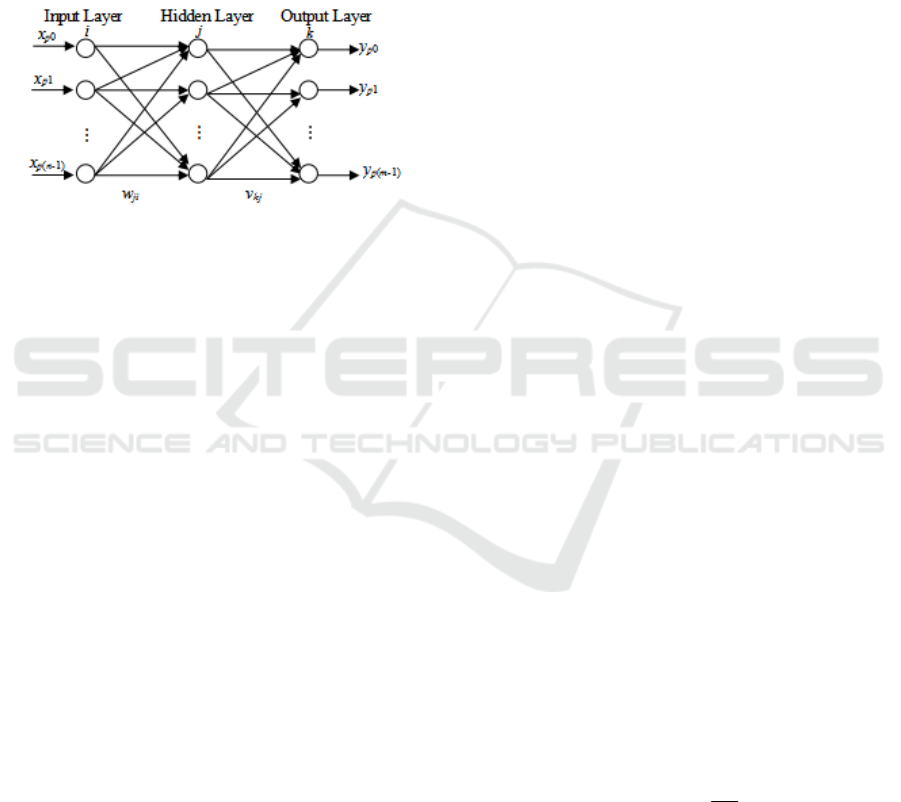
3 BP NEURAL NETWORK
ARCHITECTURE AND
ALGORITHM
A standard back propagation neural network is
shown in Figure 1. The first layer consists of n input
nodes. Each of the n input nodes is connect to each
of the r nodes in the hidden layer. The r output nodes
of the hidden layer are all connected to each of the m
node in the output layer.
Figure 1: A standard BP artificial neural network.
BP is a supervised learning algorithm for
multilayer networks (Naiyao Zhang, Pingfan Yan,
1998). The algorithm aims at minimizing the MSE
between the actual output of the network and the
desired output. Gradient descent search is user in
BP. In BP learning, a set of patterns of the form
<x
1
,…,x
n
, y
1
,…, y
m
>, where x
1
,…, x
n
are the
components of the input vector and y
1
,…, y
m
are the
components of the desired output vector, is
repeatedly given to the network until the learning of
weights converges (Liming Zhang, 1993).
If the BP neural network has N nodes in each
layer, The transfer function is the sigmoid function,
, the training samples involve M different patterns
(Xp, Yp), P=1,2,…M. Corresponding the Input
sample P, let netpj represent the input total of node j,
let O
pj
represent the output value, that is
The error between input values and output values
is as following:
The revise connection weights of BP neural
network are as following:
⎢
⎢
⎣
⎡
−
=
∑
.)(
;))((
nodesinputtheingcorrespondWnetf
nodesoutputtheingcorrespondOdnetf
kjpkpj
pjpjpj
δ
δ
Where η represents the learning rate, it can
increase convergence in speed, α represents the
momentum coefficient. The value of a is a constant,
it affects the connection weights of next step. Details
of the traditional BP artificial neural network
algorithm can be found in the original paper by
Jingwen Tian and Meiquan Gao (Naiyao Zhang,
Pingfan Yan, 1998).
The input/output problem of one set of samples is
changed by the traditional BP network model into a
nonlinear optimization
problem with a very common
algorithm---Gradient Descent. This traditional model
has strong ability of problem identification and can
reduce the errors to a minimum theoretically for the
simulation of complex and nonlinear models.
However, this traditional model still has some
drawbacks (Liqun Han, 2002), so we improve it and
put forward the BP neural network of self-adjusted
all parameters learning algorithm (Xiaofeng Li,
2003). The new algorithm can not only accelerate
the convergence speed of the network but also
optimize the network topology and enhance the
adaptability of the BP neural network.
4 THE MODEL ARCHITECTURE
OF EARLY RISK WARNING
4.1 The Risk Early Warning Index
Assignment Method
In section 2, the risk early warning index system of
high-tech entrepreneurial enterprise is built, but most
second-class indexes are hard to be represented
directly by numbers. We can adopt the fuzzy
statistical method to find out the functions and get
the valuations of these second-class indexes.
Comment set consisting of evaluation levels
in descending order is V= {excellent, fine, ordinary,
bad} = {A
1
, A
2
, A
3
, A
4
} = {1, 2, 3, 4}.
According to fuzzy statistics, the experts involved
in the evaluation are required to grade the indexes.
Next, we count the frequency m
it
of each index u
i
belonging to grade A
t.
Let us denote
n
m
it
t
i
=
)(
μ
)(t
i
μ
represents the degree of index u
i
belonging
to grade A
t.
Let us denote
(1) (4)
14
/
/
ii i
RA A
μμ
=++L
R
i
represents the value of index u
i.
∑
=
=
N
j
pjjipj
OWnet
0
)(
pjpj
netfO =
∑∑
−== 2/))((
2
pjpjp
OdEE
))1()(()( −−++= tWtWOtWW
jijipjpjjiji
αηδ
Risk Early-Warning Model of High-Tech Entrepreneurial Enterprise based on BP Neural Network
15
Risk Early-Warning Model of High-Tech Entrepreneurial Enterprise based on BP Neural Network
15

4.2 BP Neural Network Model
Architecture
Based on the traditional ANN (Artificial Neural
Network), the BP network model architecture of
early risk warning of high-tech entrepreneurial
enterprise is divided into three layers:
(1)Input layer: The input variables are the
second-class indexes of the index system (shown in
table 1), so there are 22 input layer nodes. Then, the
indexes are given values using the evaluation
method illustrated in section 4.1. These values
would be learning samples of the BP network.
(2)Hidden layer: When it comes to the selection
of the number of hidden layer nodes, referring to the
BP neural network of self-adjusted all parameters
learning algorithm that is mentioned in paper [15],
we set the number of nodes large enough at the
beginning. Then, the network will learn by itself
until we get the appropriate number of nodes.
(3)Output layer: The early risk warning of high-
tech entrepreneurial enterprise is a process from
qualitative analysis to quantitative analysis and back
to qualitative analysis. This model converts the
qualitative to quantitative output. Then, we warn the
risks according to the comment set and output. The
risks are classified into four levels: safe, light,
serious, and dangerous. These levels can be
represented by the output vectors (1,0,0,0), (0,1,0,0),
(0,0,1,0), (0,0,0,1). So, the number of output layer
nodes is four.
4.3 BP Neural Network Model
Algorithm
The BP neural network model algorithm is as
follows:
Step 1: Give values to the indexes and input
them as variables to the neural network.
Step 2: Set the number of input nodes and
initialize the parameters (including the learning
accuracy
ε
, the prescribed number of iterative
steps M,the upper limit of hidden layer nodes,
learning parameter b, momentum coefficient a, the
number of initial hidden layer nodes a should be
large.)
Step 3: Input the learning samples and make the
values of sample parameters [0, 1].
Step 4: Give random numbers between -1 and 1
to the initial weighting matrix.
Step 5: Train the network with the modified BP
method.
Step 6: Judge whether or not the number of
iterative steps is exceeding the prescribed. If yes,
end; If no, go back to step 5 and continue learning.
Step 7: Collect the values of the indexes and
process these data to make them [0, 1].
Step 8: Input the processed data to the trained BP
neural network and get the output.
Step 9: Warn the risk early of the entrepreneurial
enterprise according to the output and the risk level
comment set.
5 EMPIRICAL RESEARCH
We select 17 high-tech entrepreneurial enterprises in
SiChuan high-tech industrial zone; Chi Tong Digital
LLC(Q1); DI Zhong Digital LLC (Q2); Guang Hua
Science and Technology LLC(Q3); Chen Jing
Electronics(Q4); Hui Jin Science and Technology
LLC(Q5); Gao De Software(Q6); Tian Sheng
Science and Technology LLC(Q7); Data System
LLC(Q8); Network Educational Technology(Q9);
Communication Technology Company(Q10); Kai
Yuan Information LLC (Q11); Hua Run Science and
Technology LLC(Q12); Bo Yu Tong Da LLC
(Q13); Global Technology (Q14);Traffic
Engineering Company(Q15); Internet of Energy
Company (Q16); Xing Ge Science and Technology
LLC(Q17); The experts are invited to evaluate the
operation risks of these entrepreneurial enterprises
by using Delphi method and AHP method. We come
to a conclusion: the risk level of Q1、Q2、Q7、
Q13 is ‘safe’; the risk level of Q3、Q4、Q8、
Q9、Q14 is ‘light’; the risk level of Q5、Q10、
Q11、Q15 is ‘serious’; the risk level of Q6、
Q12、Q16、Q17 is ‘dangerous’. We take 12
enterprises at the top of the list as the training
samples of BP network model and the last 5
enterprises as the prediction samples.
5.1 BP Neural Network Training
The BP neural network architecture is built by 22-
30-4 (The number of input layer nodes is 22, the
number of hidden layer nodes is 30, the number of
output layer nodes is 4). We initialize the network
(the upper limit ε=0.0002, learning rate, η=0.5,
Inertia Parameter a=0.1), give values to the indexes
of risk early warning of the 12 high-tech
entrepreneurial enterprises (Q
1
-Q
12
) and input the
processed data to the BP network model. Then the
network is trained by the modified BP learning
algorithm and the network architecture becomes 22-
15-14. At the same time, we get the optimized
network weight matrix.
ISME 2016 - Information Science and Management Engineering IV
16
ISME 2016 - International Conference on Information System and Management Engineering
16

5.2 Risk Early Warning
Now, it is time to early warn the risk of the
enterprises Q
13
、Q
14
、Q
15
、Q
16
、Q
17
utilizing the
trained neural network. Give values to the risk early
warning indexes of the 5 high-tech entrepreneurial
enterprises, input the processed data to the trained
BP neural network and get the output of risk early
warning. As is shown in
table 2 and table 3, the
predictions of BP neural network accord with the
practical ones completely, which indicates that this
risk early warning model feasible and effective.
Table 2: BP neural network output.
High-tech
Entrepreneurial
Enterprise
Network Reasoning Output
Q
13
(0.9985 0.0023 0.0362 0.0078)
Q
14
(-0.0059 0.9911 0.0038 0.0011)
Q
15
(0.0131 –0.0016 1.0005 0.0077)
Q
16
(0.2201 0.0415 –0.0562 0.9991)
Q
17
(-0.0072 0.0035 0.0009 0.9589)
Table 3: BP neural network reasoning.
High-tech
Entrepreneurial
Enterprise
Network
Predictions
Practical Risk
Level
Q
13
Safe Safe
Q
14
light light
Q
15
Serious Serious
Q
16
Dangerous Dangerous
Q
17
Dangerous Dangerous
6 CONCLUSIONS
From the analysis above, we come to the following
conclusions.
(1)This paper builds a risk early warning model
of high-tech entrepreneurial enterprise by taking
advantage of the self-organization ability, self-
adjustment ability and self-learning ability of BP
neural network. This model has a good effect on the
risk early warning of these enterprises. The
influence of human factors and fuzzy randomness
brought by human evaluation can be eliminated,
which makes the evaluations more objective and
accurate.
(2)This paper takes the values of the risk early
warning indexes as the learning samples of the
model. These samples will dynamically learn
evaluating and reasoning by themselves. With time
passing and samples increasing, further study and
dynamic tracking will be carried out.
(3)Nonlinear functions that applies to the
complex, nonlinear and dynamic economy system
are used in BP neural network, which gets rid of the
linear analysis tools in classical economics and
provides more accurate information. So, this method
has great advantage over the traditional ones and
provides an effective path for risk early warning of
entrepreneurial enterprises.
ACKNOWLEDGEMENTS
This research was supported by the national social
science foundation of China, No.16BGL024.
REFERENCES
Fengchao Liu, Yuandi Wang, 2004. Evaluation Mode of
Risk Investment Based on Principal Component
Analysis. Science & Technology Progress and Policy,
(3): 65-67.
Liming Zhang, 1993. Artificial neural network model and
its application, Fudan University Press. Shanghai, 1st
edition.
Liqun Han, 2002. Artificial neural network theory,
designing and application. Chemical Industry Press.
Beijing, 2
nd
edition.
Martin T. Hagan, Howard B. Demuth, Mark Beale, 1996.
Neural Network Design, PWS Publishing Company,
Thomson Learning.
Motiar Rahman, M., Kumaraswamy, M., 2003. Risk
management trends in the construction industry:
moving towards joint risk management. Engineering
Construction and Architectural Management, 9(2):
131-151.
Naiyao Zhang, Pingfan Yan, 1998. Neural Networks and
Fuzzy Control, Tsinghua University Press. Beijing, 1
nd
edition.
Pena I, 2002. Intellectual Captital and Business Venture
Success. Journal of Intellectual capital, (3): 180-198.
Qun Xie, Xiaozhe Yuan, 2006. A review of the evaluation
system of venture investment projects. Science and
Technology Management Research, (8): 182-187.
Rennan. M, Schwartz. E, 2006. Evaluating National
Resource Investments. Journal of Business, 58(1):
135-157.
Shimizu, Katsuhiko, 2012. Risks of Corporate
Entrepreneurship: Autonomy and Agency Issues.
Organization Science, 23(1): 194-206.
Xiaofeng Li, 2003. The establishment of forecasting
model based on BP neural network of self-adjusted all
parameters. Forecasting, 20(3): 69-71.
Risk Early-Warning Model of High-Tech Entrepreneurial Enterprise based on BP Neural Network
17
Risk Early-Warning Model of High-Tech Entrepreneurial Enterprise based on BP Neural Network
17

Yanping Yang, 2005. Risk law of high-technology venture
investment. Science and Management of S.& T., (03):
78-82.
Yuhua Li, HongWen Lang, 2004. Research on fuzzy
overall evaluation model for investment risks in high-
tech projects. Journal Harbin Univ .Sci.& Tech, 9(1):
72-75.
Zhi Zhuo, 2006. Research on risk management theory,
China Financial Press. Beijing, 1st edition.
Zhongrui Wang, Shaojun, Yitian Xu, 2003. On the method
of fuzzy and synthetic judgment to judge the risk of
high-tech projects. Journal of Shihezi University
(Philosophy and Social Science), 3(3): 59-62.
APPENDIX
Xiaofeng Li (1972-), male, post doctoral, research
interests include entrepreneurial management,
project management, etc.
[E-Mail:] Lixiaofeng@scu.edu.cn
ISME 2016 - Information Science and Management Engineering IV
18
ISME 2016 - International Conference on Information System and Management Engineering
18
