
Gait Recognition with Compact Lidar Sensors
Bence G´alai
1
and Csaba Benedek
1,2
1
Institute for Computer Science and Control, Kende u. 13-17, H-1111, Budapest, Hungary
2
P´eter P´azm´any Catholic University, Pr´ater utca 50/A, H-1083, Budapest, Hungary
{lastname.firstname}@sztaki.mta.hu
Keywords:
Gait Recognition, Lidar.
Abstract:
In this paper, we present a comparative study on gait and activity analysis using LiDAR scanners with different
resolution. Previous studies showed that gait recognition methods based on the point clouds of a Velodyne
HDL-64E Rotating Multi-Beam LiDAR can be used for people re-identification in outdoor surveillance sce-
narios. However, the high cost and the weight of that sensor means a bottleneck for its wide application in
surveillance systems. The contribution of this paper is to show that the proposed Lidar-based Gait Energy
Image descriptor can be efficiently adopted to the measurements of the compact and significantly cheaper
Velodyne VLP-16 LiDAR scanner, which produces point clouds with a nearly four times lower vertical res-
olution than HDL-64. On the other hand, due to the sparsity of the data, the VLP-16 sensor proves to be
less efficient for the purpose of activity recognition, if the events are mainly characterized by fine hand move-
ments. The evaluation is performed on five tests scenarios with multiple walking pedestrians, which have been
recorded by both sensors in parallel.
1 INTRODUCTION
A study in the 1960s (Murray, 1967) showed that peo-
ple can recognize each other by the way they walk.
Since then gait as a biometric feature has been ex-
tensively studied. Gait analysis may not be as much
accurate as fingerprint or iris recognition for people
identification, yet it has some benefits versus other
biometric modalities. In particularly, gait can be ob-
served from a distance, and people do not need to in-
teract with any devices, they can just walk naturally
in the field of interest. Since a single imaging sensor
is enough for recording gait cycles, gait analysis can
easily be adopted to surveillance systems.
Challenges with optical camera based gait recog-
nition methods may arise from various factors, such
as background motion, illumination issues and view-
dependency of the extracted features. Although view-
invariant (3D) descriptors can be obtained from multi-
camera systems, the installation and calibration of
such systems may be difficult for ad-hoc events. We
can find several approaches in the literature relying
on optical cameras, however their efficiency is usu-
ally evaluated in controlled test environments with
limited background noise or occlusions effects. The
number of practical applications where the circum-
stances satisfy these constraints is limited. In real-
istic surveillance scenarios we must expect multiple
people walking with intersecting trajectories in front
of a dynamic background. We need therefore view-
invariant, occlusion-resistant robust features which
can be evaluated in real time enabling immediate sys-
tem response.
A Rotating Multi-Beam (RMB) LiDAR sensor
can provide instant 3D data from a field-of-view of
360
◦
with hundreds of thousands of points in each
second. In such point clouds view invariance can be
simulated with proper 3D transformationsof the point
cloud of each person (Benedek et al., 2016), while oc-
clusion handling, background segmentation and peo-
ple tracking can also be more efficiently implemented
in the range image domain, than with optical im-
ages. (Benedek, 2014) showed that a 64-beam LiDAR
(Velodne HDL-64E) is able track several people in re-
alistic outdoor surveillance scenarios, and (Benedek
et al., 2016) showed that the same sensor is also ef-
fective in the re-identification of people leaving and
re-entering the field-of-view. However, the 64-beam
sensor is too heavy and expensive for wide usage in
surveillance systems. In this paper, we demonstrate
that even lower resolution, thus cheaper LiDAR sen-
sors are capable of accurate people tracking and re-
identification, which fact could benefit the security
sector, opening doors for the usage of LiDARs in fu-
426
GÃ ˛alai B. and Benedek C.
Gait Recognition with Compact Lidar Sensors.
DOI: 10.5220/0006124404260432
In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2017), pages 426-432
ISBN: 978-989-758-227-1
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Figure 1: Main features of the used RMB LiDARs, and po-
sitioning of the sensors in the experiments.
ture surveillance systems.
The rest of the paper is organized as follows: Sec-
tion 2. provides some information about related work
in the field of gait recognition, Section 3. presents
a brief introduction to our gait recognition method
using Rotating Multi-Beam LiDAR sensor. Section
4. gives quantitative results about the accuracy of
each sensor in the different gait sequences. In Section
5. experiments on activity recognition are presented.
Conclusion is provided in Section 6.
2 RELATED WORK
Gait recognition has been extensively studied in the
recent years (Zhang et al., 2011). The proposed meth-
ods can be divided into two categories: model based
methods, which fit models to the body parts and ex-
tracts features and parameters like joint angles and
body segment lengths, and model free methods, where
features are extracted from the body as a whole ob-
ject. Due to the characteristics and the density of point
clouds generated by a Rotating Multi-Beam LiDAR
sensor, like the Velodyne HDL-64E or the VLP-16,
robust generation of detailed silhouettes are hard to
accomplish, so we decided to follow a model free ap-
proach as the model based methods need precise in-
formation on the shape of body parts, such as head,
torso, thigh etc. as described in (Yam and Nixon,
2009), which are often missing in RMB LiDAR-based
environments.
There are many gait recognition approaches pub-
lished in the literature which are based on point clouds
(Tang et al., 2014; Gabel et al., 2012; Whytock et al.,
2014; Hofmann et al., 2012), yet they use the widely
adopted Kinect sensor which has limited range and
a small field-of-view and is less efficient for applica-
tions in real life outdoor scenarios than LiDAR sen-
sors. Also the Kinect provides magnitudes higher
density than an RMB LiDAR, so the effectiveness of
these approaches are questionable in our case.
The Gait Energy Image (Han and Bhanu, 2006),
originally proposed for optical video sequences, is of-
ten used in its basic (Shiraga et al., 2016) or improved
version (Hofmann et al., 2012), since it provides a
robust feature for gait recognition. In (G´alai and
Benedek, 2015) many state-of-the-art image based
descriptors were tested for RMB LiDAR point cloud
streams, proposed methods for both optical images
(Kale et al., 2003) and point clouds were evaluated.
(Tang et al., 2014) uses Kinect point clouds and cal-
culates 2.5D gait features: Gaussian curvature, mean
curvature and local point density which are combined
into 3-channel feature image, and uses Cosine Trans-
form and 2D PCA for dimension reduction, but this
feature needs dense point clouds for curvature calcu-
lation, thus not applicable for RMB LiDAR clouds.
(Hofmann et al., 2012) adopts the image aggregation
idea behind the Gait Energy Image and averages the
pre-calculated depth gradients of a depth image cre-
ated from the Kinect points. This method proved to
be more robust for sparser point clouds, yet it was
outperformed by the Lidar-based Gait Energy Image,
which is described in Section 3. in detail.
2.1 Gait Databases
The efficiency of the previously proposed methods
are usually tested on public gait databases like the
CMU Mobo (Gross and Shi, 2001), the CASIA
(Zheng et al., 2011) or the TUM-GAID (Hofmann
et al., 2014) database. However these datasets were
recorded with only a single person present at a time,
with limited background motion and illumination is-
sues, which constraints are often not fulfilled in re-
alistic outdoor scenarios. To overcome the domina-
tion of such databases (Benedek et al., 2016) pub-
lished the SZTAKI-LGA-DB dataset recorded with
RMB LiDAR sensor in outdoor environments. Dur-
ing the experiments presented in Section 4 we fol-
lowed the same approach by recording the point cloud
sequences.
2.2 Devices Used in Our Experiments
The LiDAR devices used here are the Velodyne HDL-
64E and VLP-16 sensors, shown in Fig. 1. The HDL-
64E sensor has a vertical field-of-view of 26.8° with
64 equally spaced angular subdivisions, and approx-
imately 120 metres range providing more than two
million points per second. The VLP-16 has 30° verti-
cal field-of-view, 2° vertical resolution and a range of
Gait Recognition with Compact Lidar Sensors
427
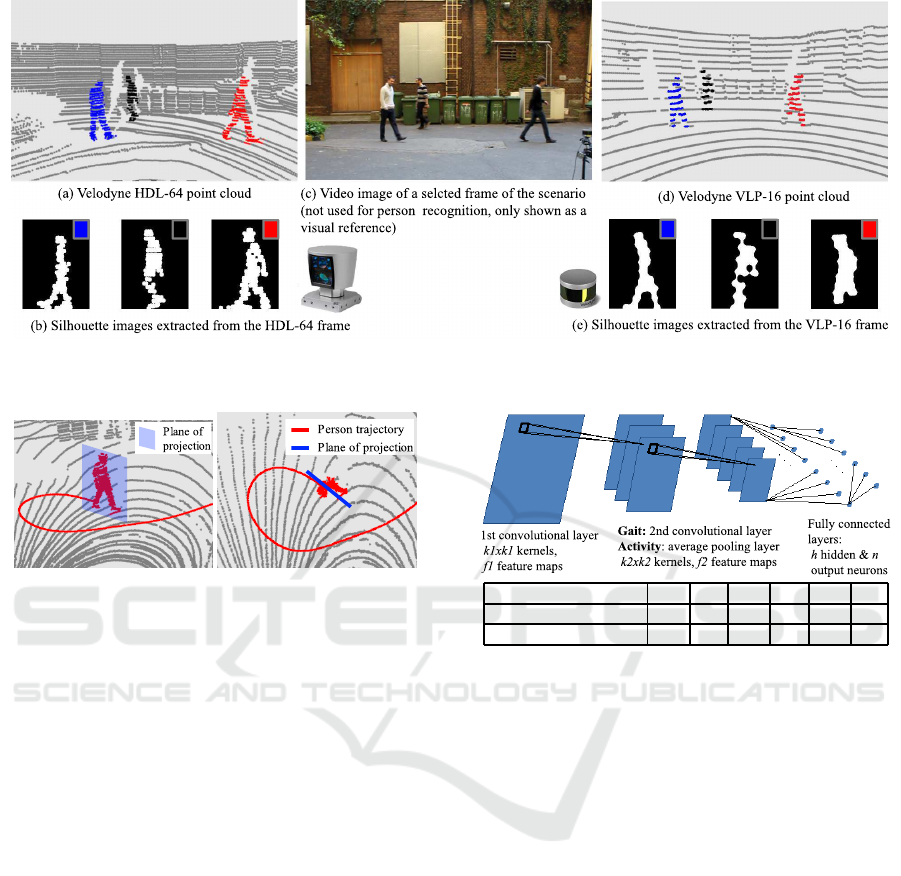
Figure 2: Point clouds captured with the HDL-64E (left) and VLP-16 (right) and the associated side-view silhouettes of the
three people present in the scene.
(a) (b)
Figure 3: The projection plane for LGEI generation from a)
side-view, b) top view.
100 metres. Both sensors have a rotational rate of 5
Hz - 20 Hz. During the experiments, the sensors were
positioned close to each other (Fig. 1, bottom), which
could capture the scenario in parallel with two similar
viewpoints (Fig. 2).
3 PROPOSED GAIT
RECOGNITON APPROACH
In this section we present a brief introduction to the
adopted gait recognition method, called the Lidar-
based Gait Energy Image (LGEI).
LGEI proved to be the most effective feature for
LiDAR-based gait recognition in (G´alai and Benedek,
2015). The LGEI adopts the idea of the Gait Energy
Image (Han and Bhanu, 2006), by averaging side-
view silhouettes in a full gait cycle, with some small
yet significant alternations.
First, an LGEI is generated by averaging 60 con-
secutive silhouettes, which is equivalent to nearly 3-4
gait cycles, as the frame rates of the considered RMB
LiDAR sensors are lower than in cases of optical cam-
eras.
Parameters k1 f1 k2 f2 h n
gait recognition 3 5 7 9 98 N
activity recongition 7 5 2 - 20 1
Figure 4: Structure of the used convolutional neural net-
works (CNN). By gait recognition, N is equal to the number
of people in the training set.
Second, since occlusions occur in the realistic out-
door scenarios of the experiments, each frame where
only partial silhouettes were visible are discarded.
This filtering step results in a drop of 10-12% of the
training and testing images, yet it can boost the per-
formance of the correct re-identifications.
Third for classification, the LGEI approach uses
the committee of a convolutional neural network
(CNN) and a multilayer perceptron (MLP). Although
the neural networks require in general large amounts
of input data, the designed convolutional network was
small enough, so that it could learn efficient biomet-
ric features based on a few thousand of input LGEIs
within the test set. For the multilayer perceptron, the
input data was preprocessed similarly to the approach
in (Han and Bhanu, 2006): principal component anal-
ysis and multiple discriminant analysis were applied
to the LGEIs to create the input for the MLP. Both the
CNN and the MLP used downscaled image maps of
20×15 pixels and both networks have an output layer
of N neurons, which is equal to the number of people
present in the scene.
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
428

Tanh activation function was used whose output
is in the [-1,1] domain, thus for the ith person in a
test scenario the network’s output should be 1 for the
associated neuron and -1 for all others. In the recog-
nition phase the trained networks produce output vec-
tors o
cnn
and o
mlp
∈ R
N
in the [-1,1] domain, for the
output of the CNN-MPP committee we then take the
vector o = max(o
cnn
, o
mlp
). For a givenG probe LGEI
we then calculate i
max
= argmax
i
(o) and sample G is
recognized as person i
max
, if o
i
max
> 0, otherwise we
mark G as unrecognized.
The structure of the convolutional network can be
seen in Figure 4. We note here that (Wolf et al., 2016)
also uses CNN for gait analysis, and the authors of
(Shiraga et al., 2016) use CNNs with the Gait Energy
Image inputs for classification. However, the struc-
tures of their networks is larger than the one presented
here, and they also rely on a much larger dataset of
optical image data (Makihara et al., 2012) for GEI
generation and training.
For LGEI generation the point clouds of each per-
son are projected to a plane tangential to the person’s
trajectory (see Fig. 3) and morphological operations
are applied to obtain connected silhouettes. Naturally
in the VLP-16 sequences, even more steps of morpho-
logical post processing operations are needed to ob-
tain connected silhouette blobs, thus in terms of level
of details, the quality of the VLP-16 feature maps
are notably lower than experienced with the HDL-
64E point clouds. Three silhouettes extracted from a
sample frame are shown in Figure 2. for visual com-
parison. In both the HDL-64 and VLP-16 cases, the
projected silhouette images are upscaled to 200× 150
pixels. In the post processing phase, the HDL-64E
feature map undergoes a single dilation step with a
kernel of 5× 5 pixels. The same kernel is used ini-
tially for the VLP-16 silhouettes, which is followed
by five cycles of alternately applying dilation and ero-
sion kernels with a size of 3× 5.
We can visually compare the LGEIs extracted
from the HDL-64 and VLP-16 sequences in Fig. 5
and 6. Most important differences can be observed
in the arm and leg regions, where the low-resolution
sensor can only preserve less details. On the other
hand, the main silhouette shape and the characteristic
posture still remains recognizable even on the VLP-
(a) Person1 (b) Person2 (c) Person3
Figure 5: HDL64-LGEI sample images.
(a) Person1/a (b) Person2/a (c) Person3/a
(d) Person1/b (e) Person2/b (f) Person3/b
Figure 6: VLP16-LGEI samples: images in the same col-
umn correspond to the same person.
16 measurement maps, which fact can be confirmed
by comparing different LGEIs of the same subjects in
Fig. 6.
4 EXPERIMENTS ON GAIT
RECOGNITION
Our tests set consists of five scenarios containing mul-
tiple pedestrians walking in a courtyard. Each sce-
nario was recorded by both the HDL-64 and VLP-
16 sensors in parallel (see Fig. 2). In the sequences
N3/1, N3/2, and N3/3 the same three test subjects
were walking in the field of view with intersecting
trajectories, and the VLP-16 sensor has been placed
a several metres closer to the walking area than the
HDL-64. Sequences F4 and F5 represent similar sce-
narios with four and five people, respectively, but the
two devices were placed here in approximately equal,
and relatively far distances from the moving people.
A snapshot from the sensor configuration capturing
the F4 and F5 sequences is shown in Fig. 1.
Similarly to (Benedek et al., 2016), we divided
the captured sequences into distinct parts, for training
and test purposes, respectively. In the near-to-sensor
setting scenario (N3) the three sections are evaluated
with cross validation, e.g. by testing the recognition
on the N3/2 part, the training set was generated from
the N3/1 segment (corresponding result is shown in
Table 1, 1st row) and so on. On the other hand, the
F4 and F5 sequences were split into two parts, and in
both cases, the first segments were used for training
and the second ones for testing the recognition per-
formance.
For the gallery set generation, k = 100 random key
frames were selected from the training sequences, and
the training LGEIs were calculated from the l = 60
Gait Recognition with Compact Lidar Sensors
429

Table 1: Rates of correct re-identifications with the HDL-
64E and VLP-16 sensors in five sequences. The scenarios
N3/1, N3/2 and N3/3 were recorder while three people were
walking near to the sensor, F4 and F5 with four and five
people respectively far from the sensor.
Sequence HDL-64 VLP-16
N3/1 96% 81%
N3/2 85% 84%
N3/3 93% 81%
F4 79% 68%
F5 93% 54%
consecutive silhouette images. As for the probe set,
200 seed frames were selected from the test set, and
each of the 200 test LGEIs were matched indepen-
dently to the trained models.
For each test scenario, the accuracy rates of cor-
rect re-identification with both sensors are shown in
Table 1. As expected, the tests with HDL-64 data out-
perform the VLP-16 cases due to the 4-times larger
vertical resolution of the point clouds, however in the
near-to-sensor configuration (N3 sequences), the per-
formance of the compact VLP-16 LiDAR can still be
regarded as quite efficient (above 80%). On the other
hand, for the far-from-sensor (F4 and F5) cases, the
tests with the VLP-16 sensor yielded notably lower
scores, which observation is the consequence of the
poor measurement density from the subjects at larger
distances. To demonstrate the differences between the
data of the two sensor configurations, we show in Fig.
7. two worst case silhouette examples from the far
and near scenarios, respectively. While in the near-
to-sensor example, the shape of the extracted human
body is strongly distorted, the silhouette blob is at
least still connected. On the other hand, in the far-
from-sensor sequences there are many silhouette can-
didates, which cannot be connected even by applying
several morphological operations, and consist of dis-
connected floating blobs. We can conclude from these
experiences, that the VLP-16 sensor can indeed be ap-
plicable in future surveillance systems, however the
appropriate positioning of the sensor is a key issue, as
the performancequickly depreciates by increasing the
distance.
1
.
5 EXPERIMENTS ON ACTIVITY
RECOGNITION
Apart from person identification, the recognition of
various events can provide valuable information in
1
Demo videos of person tracking with various Velo-
dyne sensors can be found in our website: http://web.eee.
sztaki.hu/i4d/demo
surveillance persontracking.html
(a) (b)
Figure 7: Worst-case VLP-16 silhouettes in: a) far, b) near
sensor setting recordings.
surveillance systems. For activity recognition the
averaging idea of Gait Energy Image can also be
adopted: (Benedek et al., 2016) introduced two fea-
ture images: the Averaged Depth Maps (ADM), and
the Averaged eXcluse-OR (AXOR) images. Each fea-
ture image was generated based on 40 consecutive
LiDAR frames (from sequences with 10fps), which
was the average duration of the activities of interest.
Frontal silhouette projections were used in this case,
since activities were better observed from a frontal
point of view. Apart from normal walk, five events for
recognition have been selected: bend, check watch,
phone call, wave and wave two-handed (wave2) ac-
tions.
Recording the motion of limbs in 3D is essential
in the recognition of the above typical events. Since
binarized silhouettes do not provide enough details
for automatic analysis, depth maps were derived from
the point clouds for capturing the appearance of the
body. The ADM feature has been obtained by av-
eraging the consecutive depth maps during the ac-
tion, similarly to GEI calculation. An activity can
also be described from it’s dynamics, highlighting the
parts where the frontal depth silhouettes change sig-
nificantly in time. Thus a second feature map has been
introduced, so that for each consecutive frontal sil-
houette pairs the exclusive-OR (XOR) operator was
applied capturing the changes in the contour, and by
averaging the consecutive XOR images the AXOR
map was derived. For recognition two convolutional
neural network were used, one for the ADM and one
for the AXOR image.
We have performed the activity recognition exper-
iments with both LiDARs in the near-to-sensor con-
figuration. Fig. 8. shows two ADM examples – one
for the bending and one for the two handed waving
(wave2) action – where the qualities of the VLP-16
feature maps are similar to the HDL-64 cases. In
general, the bending action could be efficiently de-
tected by the VLP-16 sensor, but the remaining activ-
ities often struggled with the issues of low resolution.
Figure 9. highlights this phenomenon: 10 consecu-
tive frames of a waving activity are shown. We can
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
430
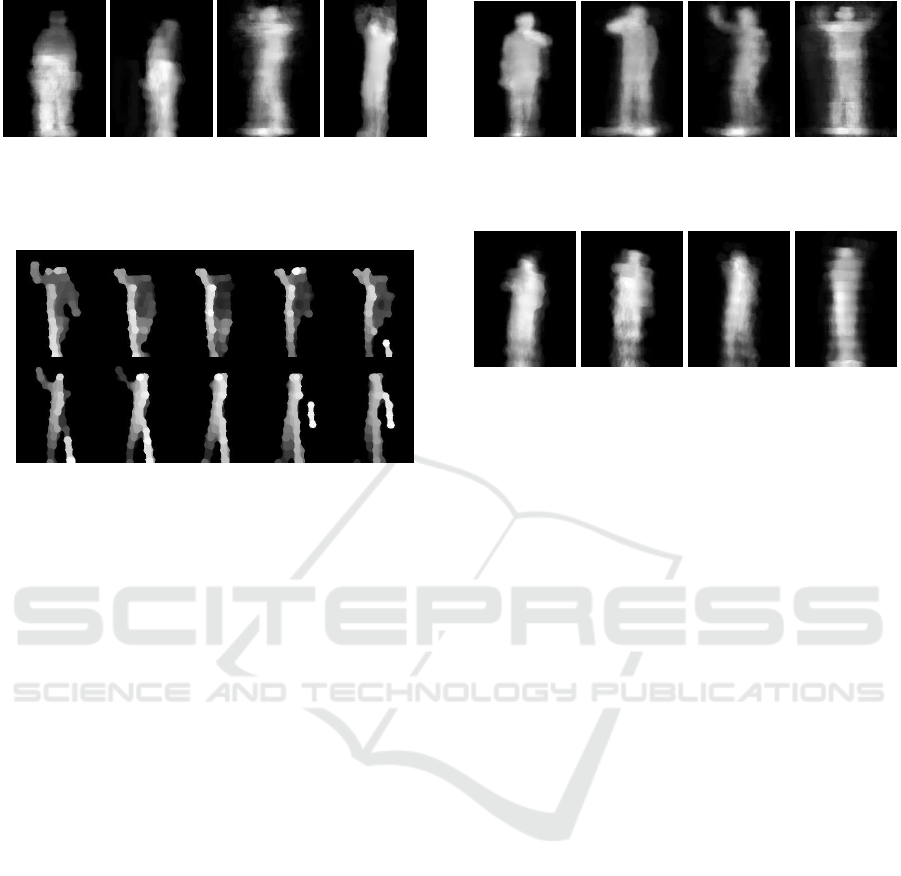
(a) HDL-64 (b) VLP-16 (c) HDL-64 (d) VLP-16
Figure 8: Good quality Averaged Depth Maps (ADM) for
bend (a-b) and wave2 (c-d) actions with the two Lidar sen-
sors.
Figure 9: 10 consecutive frames of a waving activity
recorded by the VLP-16 sensor.
see that the waving hand randomly disappears and re-
appears throughout the frames, thus in the averaging
step it may be canceled out without causing charac-
teristic patterns in the ADM and AXOR images. In
Figures 10. and 11. we can see ADMs of four activi-
ties of interest derived from the measurements of the
HDL-64 and the VLP-16 sensors respectively. The
loss of important details between each pair of corre-
sponding HDL-64 and VLP-16 sample images is vis-
ible in the figures, these VLP-16 ADMs are difficult
to distinguish even by human observers. While the
measured recognition rates were above 85% in the
HDL-64 sequences (Benedek et al., 2016), we have
concluded hereby that for reliable recognition of pre-
cise hand movements in the ADM/AXOR feature im-
age domain, the 2
◦
vertical resolution of the basic
VLP-16 sensor is less efficient. However, as the ten-
dency in the compact sensor development indicates
the increase of the vertical resolution parameter ver-
sus the field of view (the newest model of the com-
pany reaches 1.33
◦
resolution within a 20
◦
FoV), the
doors for this particular application will be soon open
for compact Lidar sensors as well.
6 CONCLUSION
We showed that the gait recognition task can be effi-
ciently approached with lowresolution RMB LiDARs
like the VLP-16 sensor. The proposed gait recogni-
tion method was able to achieve a relatively high ac-
(a) watch (b) phone (c) wave (d) wave2
Figure 10: Reference ADMs generated from HDL-64E
clouds.
(a) watch (b) phone (c) wave (d) wave2
Figure 11: Low quality ADM samples generated from VLP-
16 clouds for the actions of Fig. 10.
curacy, since it uses the motion of the whole body
as descriptor. We also showed that the distance of
the VLP-16 sensor from the walking people largely
influence the results, but with precise positioning of
the device could accomplish similar performance to
ones acquired from the HDL-64. On the other hand,
various activity recognition functions based on prin-
cipally hand movements face limitations by the low
density VLP-16 point clouds, and we experienced
larger gaps in recognition performance between the
two sensors. This work was supported by the e Na-
tional Research, Development and Innovation Fund
(NKFIA #K-120233). C. Benedek also acknowledges
the support of the J´anos Bolyai Research Scholarship
of the Hungarian Academy of Sciences.
REFERENCES
Benedek, C. (2014). 3D people surveillance on range data
sequences of a rotating Lidar. Pattern Recognition
Letters, 50:149–158. Special Issue on Depth Image
Analysis.
Benedek, C., G´alai, B., Nagy, B., and Jank´o, Z. (2016).
Lidar-based gait analysis and activity recognition in
a 4D surveillance system. IEEE Transactions on Cir-
cuits and Systems for Video Technology. To appear.
Gabel, M., Renshaw, E., Schuster, A., and Gilad-Bachrach,
R. (2012). Full body gait analysis with Kinect. In
International Conference of the IEEE Engineering in
Medicine and Biology Society (EMBC).
G´alai, B. and Benedek, C. (2015). Feature selection for
lidar-based gait recognition. In International Work-
shop on Computational Intelligence for Multimedia
Understanding (IWCIM), pages 1–5.
Gait Recognition with Compact Lidar Sensors
431

Gross, R. and Shi, J. (2001). The CMU Motion of Body
(MoBo) Database. Technical Report CMU-RI-TR-01-
18, Robotics Institute, Pittsburgh, PA.
Han, J. and Bhanu, B. (2006). Individual recognition using
gait energy image. IEEE Trans. Pattern Analysis and
Machine Intelligence, 28(2):316–322.
Hofmann, M., Bachmann, S., and Rigoll, G. (2012). 2.5D
gait biometrics using the depth gradient histogram en-
ergy image. In Int’l Conf. on Biometrics: Theory, Ap-
plications and Systems (BTAS), pages 399–403.
Hofmann, M., Geiger, J., Bachmann, S., Schuller, B., and
Rigoll, G. (2014). The TUM gait from audio, image
and depth (GAID) database: Multimodal recognition
of subjects and traits. J. Vis. Comun. Image Repre-
sent., 25(1):195–206.
Kale, A., Cuntoor, N., Yegnanarayana, B., Rajagopalan, A.,
and Chellappa, R. (2003). Gait analysis for human
identification. In Audio- and Video-Based Biometric
Person Authentication, volume 2688 of Lecture Notes
in Computer Science, pages 706–714. Springer.
Makihara, Y., Mannami, H., Tsuji, A., Hossain, M., Sug-
iura, K., Mori, A., and Yagi, Y. (2012). The OU-ISIR
gait database comprising the treadmill dataset. IPSJ
Trans. on Computer Vision and Applications, 4:53–
62.
Murray, M. P. (1967). Gait as a total pattern of movement.
American Journal of Physical Medicine, 46(1):290–
333.
Shiraga, K., Makihara, Y., Muramatsu, D., Echigo, T., and
Yagi, Y. (2016). Geinet: View-invariant gait recog-
nition using a convolutional neural network. In 2016
International Conference on Biometrics (ICB), pages
1–8.
Tang, J., Luo, J., Tjahjadi, T., and Gao, Y. (2014). 2.5D
multi-view gait recognition based on point cloud reg-
istration. Sensors, 14(4):6124–6143.
Whytock, T., Belyaev, A., and Robertson, N. (2014). Dy-
namic distance-based shape features for gait recogni-
tion. Journal of Mathematical Imaging and Vision,
pages 1–13.
Wolf, T., Babaee, M., and Rigoll, G. (2016). Multi-view gait
recognition using 3d convolutional neural networks.
In IEEE International Conference on Image Process-
ing (ICIP), pages 4165–4169.
Yam, C.-Y. and Nixon, M. S. (2009). Gait Recognition,
Model-Based, pages 633–639. Springer US, Boston,
MA.
Zhang, Z., Hu, M., and Wang, Y. (2011). A survey of ad-
vances in biometric gait recognition. In Biometric
Recognition, volume 7098 of Lecture Notes in Com-
puter Science, pages 150–158. Springer Berlin Hei-
delberg.
Zheng, S., Zhang, J., Huang, K., He, R., and Tan, T. (2011).
Robust view transformation model for gait recogni-
tion. In International Conference on Image Process-
ing (ICIP).
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
432
