
Real-Time Data Harvesting Method for Czech Twitter
Pavel Kr
´
al
1,2
and V
´
aclav Rajtmajer
1
1
Dept. of Computer Science & Engineering, Faculty of Applied Sciences,
University of West Bohemia, Plze
ˇ
n, Czech Republic
2
NTIS - New Technologies for the Information Society, Faculty of Applied Sciences,
University of West Bohemia, Plze
ˇ
n, Czech Republic
Keywords:
Czech, Data, Harvesting, Social Media, Twitter.
Abstract:
This paper deals with automatic analysis of Czech social media. The main goal is to propose an approach to
harvest interesting messages from Twitter in Czech language with high download speed. This method uses
user lists to discover potentially interesting tweets to download. It is motivated by the fact that only about
20% of Twitter users are posting informative messages, whereas the remaining 80% not and that it is possible
to identify the “important” users by the user lists. The experimental results show that the proposed method
is very efficient because it harvests about 6 times more data than the other approaches. This approach should
be integrated into an experimental system for the Czech News Agency to monitor the current data-flow on
Twitter, download messages in real-time, analyze them and extract relevant events.
1 INTRODUCTION
Social media are virtual computer networks that al-
low individuals, companies, and other organizations
to create, share, view and analyze information mainly
in the form of short messages. The importance and
the size of the today’s social media are growing very
rapidly which is strictly related to the particular needs
of the automatic processing methods.
Twitter is a social net which uses very short mes-
sages limited by 140 characters. They are posted on-
line as status updates, so-called tweets. The tweets
can be accompanied by photos, videos, geolocation,
links to other users (words preceded by the sign @)
and trending topics (words preceded by the sign #).
The posted tweet can be liked, commented by the
other tweets, or redistributed by other users by for-
warding, so-called retweet. Due to its simplicity and
easy access, Twitter contains a very wide range of top-
ics from common every day conversations over sport
news to news about an ongoing disasters as earth-
quake, flood or typhoon. Twitter is without doubt
a very interesting source of on-line information which
can be used for further analysis and data-mining. In
this work, we focus on Twitter because of its large
size, significant amount of other existing work about
this network and particularly because of a number of
Twitter users post interesting news from various top-
ics in real-time.
We would like to use Twitter for automatic real-
time event detection because it will be very useful for
many journals and news agencies in order to discover
very quickly new interesting information. Particu-
larly, the Czech News Agency (
ˇ
CTK
1
) requires a sys-
tem to automatically harvest data from Czech Twitter
and to discover potential events. Several definitions
of events exist, however we will use the definition
from a Cambridge Dictionary. An event is defined
as “anything that happens, especially something im-
portant and unusual
2
”.
The first main task of this system consists in ana-
lyzing of Twitter stream and in harvesting of the ap-
propriate tweets in Czech language in real-time. The
second important task is the subsequent analysis of
the downloaded data and to discover in such data
new events. The main goal of this paper is to pro-
pose and implement a novel method to solve the first
task described above. Note, that the activity of the
Czech Twitter users is significantly lower than of the
other ones, which is particularly evident for English
or French. Therefore, it is not possible to use common
methods provided by Twitter API and a novel method
is necessary. The core of the proposed method con-
sists in using user lists to download a sufficient num-
ber of Czech tweets in real-time.
1
http://www.ctk.eu/
2
http://dictionary.cambridge.org/dictionary/british/event
Krà ˛al P. and Rajtmajer V.
Real-Time Data Harvesting Method for Czech Twitter.
DOI: 10.5220/0006212402590265
In Proceedings of the 9th International Conference on Agents and Artificial Intelligence (ICAART 2017), pages 259-265
ISBN: 978-989-758-220-2
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
259

The rest of the paper is organized as follows. Sec-
tion 2 is a short review of Twitter analysis methods.
The following section presents an architecture of the
whole event detection system. Section 4 describes in-
dividual components of this system. The proposed
method for tweet harvesting in the Czech language
with high speed is presented in Section 4.1.3. Sec-
tion 5 deals with the results of our experiments. In
the last section, we conclude the experimental results
and propose some future research directions.
2 SHORT REVIEW OF TWITTER
ANALYSIS METHODS
Numerous studies have investigated Twitter, because
it offers many possibilities for data processing and
analysis. This social net can be used as a data source
of sentiment analysis and opinion mining as shown
for example in (Pak and Paroubek, 2010). The au-
thors have collected a sentiment analysis corpus from
Twitter and they have further built an efficient sen-
timent classifier on this data. Another work deal-
ing with sentiment analysis from Twitter is proposed
in (Kouloumpis et al., 2011). The authors show here
the importance of linguistic features for this task.
Twitter data can be further used for sociolog-
ical surveys as shown for instance in (Yardi and
Boyd, 2010). The authors have analyzed a group
polarization using the data collected from dynamic
debates. Another study analyzes Twitter commu-
nity (Java et al., 2009) to discover user activities.
A taxonomy characterizing the underlying intentions
of the users is presented.
Twitter can be also successfully used for event
detection as presented for instance in (Sakaki et al.,
2010; Earle et al., 2012). These approaches are gen-
erally based on the capturing of a presence or an in-
crease of particular key-words. For instance, an in-
crease of the words “earthquake” or “typhoon” is used
for disaster detection.
They were also proposed some more sophisticated
Twitter analysis approaches as for instance in (Li
et al., 2012). The authors propose a system called
Twevent, which first detects event segments and then,
they are clustered considering both their frequency
distribution and content similarity to discover events.
Wikipedia is used as a knowledge base to derive the
most interesting segments to describe the identified
events and to discover realistic events. The main ad-
vantage of this system from the previous ones is that
it is domain independent and therefore, it can iden-
tify all event types. The further event detection tech-
niques on Twitter are available in the survey (Atefeh
Figure 1: System architecture.
and Khreich, 2015).
Twitter analysis methods are focused particularly
on English (sometimes also on French or on Chinese)
and relatively few works are oriented to the other lan-
guages. Twitter activities of the users in such lan-
guages are very high and therefore the common har-
vesting methods provided by Twitter API are suffi-
cient to get a sufficient amount of the data for a further
analysis. We assume, that this fact explains that, to the
best of our knowledge, no special Twitter harvesting
method exists. Therefore, we will evaluate and com-
pare our proposed harvesting method with the stan-
dard ones provided by Twitter.
It is also worth of noting, that no other study about
automatic event detection on Czech Twitter exists.
3 SYSTEM DESCRIPTION
In order to show the whole problem, we first describe
a general architecture of the event detection system
and then, we detail the proposed method for fast har-
vesting of the Twitter data in Czech language.
The event detection system is composed of three
main functional units (Tweet Stream Analysis, Prepro-
cessing and Event Detection) which are further de-
composed into six tasks as depicted in Figure 1.
The first task, Data acquisition, is beneficial to
harvest on-line appropriate data from Twitter in Czech
language with high speed. Then, Spam filtering is
done to remove tweets with useless information (so
called “spam”). The third task is Lemmatization
ICAART 2017 - 9th International Conference on Agents and Artificial Intelligence
260

which is used for word normalization. The next step is
Non-significant word filtering. While the previous fil-
tering was at the tweet level, this one is at word level
and is used to remove non-significant words which
could decrease the detection performance. The next
step to discover events is Clustering. We group to-
gether the tweets with similar content using a cluster-
ing method. The final decision about an event is based
on the thresholding. The last step, Results represen-
tation, is used to show the detected event to the users
in an acceptable form.
All these steps are described below in details with
the particular focus on the data acquisition, which is
the main contribution of this paper.
4 METHOD DESCRIPTION
4.1 Data Acquisition
We summarize first our requirements to choose an op-
timal data acquisition method:
• working in real-time;
• downloading of the messages in Czech language;
• harvesting of a “sufficient” number of tweets for
a further processing (it means, from our point of
view, as much as possible);
• usage for free;
• downloading only informative messages (op-
tional).
We analyze in the following text the different pos-
sibilities of Twitter for data harvesting. We show for
all the methods the maximum download speed de-
fined by the Twitter constraints. Unfortunately, this
speed usually does not correspond to the real one, be-
cause the activity of the Twitter users is not sufficient
to fill these limits.
4.1.1 Search API
This API is a part of Twitter REST API. It allows
queries against the indices of recent or popular tweets
and behaves similarly to, but not exactly like the
search feature available in web clients. This API
searches against a sampling of “recent” tweets pub-
lished in the past 7 days and its maximum download
speed is 72,000 tweets/hour. The query can be re-
stricted by several constraints as for instance by a ge-
olocation or by a target language.
Another important property is that this API is fo-
cused on relevance and not on completeness. This
means that some tweets and users may be missing
from the search results. The first approach, which
is further evaluate and compare, uses this API and is
hereafter referred as Search API method.
4.1.2 Streaming API
This API is intended to monitor (or process) tweets in
real-time. Three different streams with three different
connection types exist, however only Public stream
can be suitable for our task. It allows to get public
data from different users about different topics, while
the other two ones (User or Site) analyze only the data
from specific users.
From the point of view the connection type, we
can use only Filter connection, because Sample pro-
vides a sample from all the data and Firehose which
provides all possible data, is not free of charge. The
query can be, as in the case of the Search API, re-
stricted by several constraints (e.g. geolocation or tar-
get language). The maximum download speed of this
method is unfortunately not given. The second eval-
uated approach uses this API and is hereafter entitled
as Filtered Streaming API method.
4.1.3 UserList
Design of this method is motivated by the two follow-
ing facts:
• our preliminary studies have shown that the meth-
ods provided by Twitter API are not very suitable
for our task;
• about 20% of Twitter users are posting informa-
tive tweets, whereas the remaining 80% not (Naa-
man et al., 2010).
UserList is a Twitter possibility to allow each user
to create 20 lists with an option to store up to 5,000
users into one list. These lists can be used to show all
tweets that these users have posted and this procedure
can be used with Twitter API to get all published data
from 100,000 particular users.
The proposed method uses these list for acquisi-
tion of the significant amount of tweets in a given lan-
guage (in Czech in our case, however the method is
general enough to handle the other ones). The down-
loaded messages should contain valuable information
for data-mining and further analysis as for instance
potentials events.
Our issue is now to select the representative users
in order to detect appropriate tweets. Our system is
designed for general event detection. Therefore it
must cover the all Twitter topics by active authors
from all fields. We use a small sample of interest-
ing people provided by Czech News Agency and this
sample is automatically extended by our algorithm.
Real-Time Data Harvesting Method for Czech Twitter
261
The algorithm to complete the UserList is based
on the assumption that:
• We have already a representative group of the
users (sample provided by
ˇ
CTK);
• this set covers a representative part of our domain
of interest;
• their followers would be the users with similar in-
terests.
Therefore, we get by the Twitter API detailed in-
formation about all the followers of our initial group.
Then, we filter out all foreign (no Czech) users and we
continue with the first step. Our algorithm is stopped
when a requested number of the users is explored.
For every user u, it is then computed a rank R
u
which is based on its number of followers Fn and the
number of submitted tweets T n as follows:
R
u
= w.Fn + (1 −w).T n (1)
where w is the importance of both criteria and was
set experimentally to 0.5.
Our list is sorted by this rank and the “best”
100,000 users are added to our twitter lists for a fur-
ther processing.
Twitter “ecosystem” is very dynamic and it
evolves very quickly. Therefore, this list must be pe-
riodically updated to keep actual information.
Our proposed method then harvests the data from
this representative list of the 100,000 users via Twit-
ter API. This method is hereafter referred as UserList
method. It is also worth of noting that this method is
language independent.
4.2 Pre-processing
4.2.1 Spam Filtering
As already stated, this task is realized in order to re-
move tweets with useless information. These tweets
are filtered with a manually defined set of rules (or
with a list of entire tweets). Table 1 shows some ex-
amples of whole tweets. The rules are based on the
predefined patterns.
Of course, this simple method does not filter all
useless tweets. However, we assume that they will not
be detected as events by our detection algorithm due
to their not significant amount. Therefore, it is not
necessary for the current system to implement more
sophisticated filtering algorithm.
4.2.2 Lemmatization
Lemmatization consists in replacing a particular (in-
flected) word form by its lemma (base form). It de-
creases the number of features of the system and is
Table 1: Examples of tweets to filter.
Tweet English translation
Automatically created messages
P
ˇ
ridal jsem novou fotku
na Facebook.
I have added a new photo
on Facebook.
L
´
ıb
´
ı se mi video
@YouTube.
I like @YouTube movie.
Ozna
ˇ
cil(-a) jsem video
@YouTube.
I have marked @YouTube
movie.
(Everyday) useless tweets created by the users
Dobr
´
e r
´
ano! Good morning!
Jdu ob
ˇ
edvat, dobrou chu
ˇ
t. I’m going to have lunch,
enjoy your meal.
successfully used in many natural language process-
ing tasks. We assume that lemmatization can improve
the detection performance of our method. It can be
useful particularly in clustering to group together ap-
propriate words.
Following the definition from the Prague De-
pendency Treebank (PDT) 2.0 (Zeman et al., 2014)
project, we use only the first part of the lemma. This
is a unique identifier of the lexical item (e.g. infini-
tive for a verb), possibly followed by a digit to disam-
biguate different lemmas with the same base forms.
For instance, the Czech word “t
ˇ
reba”, having the iden-
tical lemma, can signify necessary or for example de-
pending on the context. This is in the PDT notation
differentiated by two lemmas: “t
ˇ
reba-1” and “treba-
2”. The second part containing additional information
about the lemma, such as semantic or derivational in-
formation, is not taken into account in this work.
4.2.3 Non-Significant Word Filtering
Non-significant words (also sometimes called stop
words) are considered words with high frequencies
which have in a sentence rather grammatical meaning
as for instance prepositions or conjunctions. In this
version, the filtering is based on a manually defined
list. We plan to implement more sophisticated method
based on Part-of-Speech (POS) tags in the further ver-
sion. However, we assume that this improved removal
will play marginal role for event detection.
4.3 Event Detection
4.3.1 Clustering
After getting the data we are facing the problem of
extracting events. We use a clustering technique for
this purpose. Consider that we get in real-time the fil-
tered and lemmatized tweets which can represent (due
to the UserList method) very probably the events.
We transform every tweet into a binary representa-
tion using a bag of words method, which represents
ICAART 2017 - 9th International Conference on Agents and Artificial Intelligence
262
its unique location in n-dimensional space. Then the
clustering algorithm is as follows:
1. take an (unprocessed) tweet;
2. calculate the cosine distance between a vector rep-
resenting this tweet and all the others;
3. choose a closest tweet (or cluster of tweets if any)
and group them together (the maximum allowed
distance is given by the threshold T h);
4. repeat the two previous operations (go to step 1)
till all tweets are processed.
The clusters created by this algorithm represent
the events. Of course, the clustering does not guaran-
tee that the created clusters represent only the events.
This should be done by the pre-processing:
• UseList data acquisition method harvests partic-
ularly informative tweets which contains mainly
the events;
• Spam filtering step removes several useless tweets
(no events).
We also define a parameter T which indicates a time
period for the clustering. We assume that different
events will be produced at different “speed” (different
activities of Twitter users). For instance, information
about the winner of the football championship can be
quicker (more contributions in a short period) than in-
formation about a new director of some company.
It is worth of noting, that we have also consid-
ered a gradient of the frequencies in some event clus-
ters. Unfortunately, this improvement did not work
because of the small activity of the users on Czech
Twitter.
4.3.2 Results Representation
The results of the clustering are thus the groups of
tweets with some common words. This group is rep-
resented by the most significant tweet. This tweet is
defined as a message with the maximum of common
words and the minimum of the other words. This rep-
resentation is used due to the effort to use an answer
in natural language, instead of a list of key-words or
a phrase.
5 EXPERIMENTAL RESULTS
This section describes the experiments realized to
evaluate the proposed tweet harvesting method based
on user lists. The global functionality of the proposed
event detection system is also evaluated here. This
evaluation was done off-line.
5.1 Evaluation of the Data Acquisition
5.1.1 Comparison of the Czech and French
Twitter Activity
In the first experiment, we would like confirm our
claim that the activity of the Czech Twitter is sig-
nificantly lower than in the case of the other lan-
guages. We have chosen French Twitter and Search
API method (see Section 4.1.1) for such comparison.
First, we have discovered that, it is not possible
to use language constraints to obtain only the Czech
tweets. Unfortunately, the Czech constraint is missing
and there is available only “sk” field which contains
Czech and Slovak tweets together.
Therefore, we have decided to filter tweets accord-
ing to geolocation. We have chosen a square region,
covering most of the territories of the Czech Republic
and France, as our area of interest. We have analyzed
the download rate in interval from 22 to 29 August
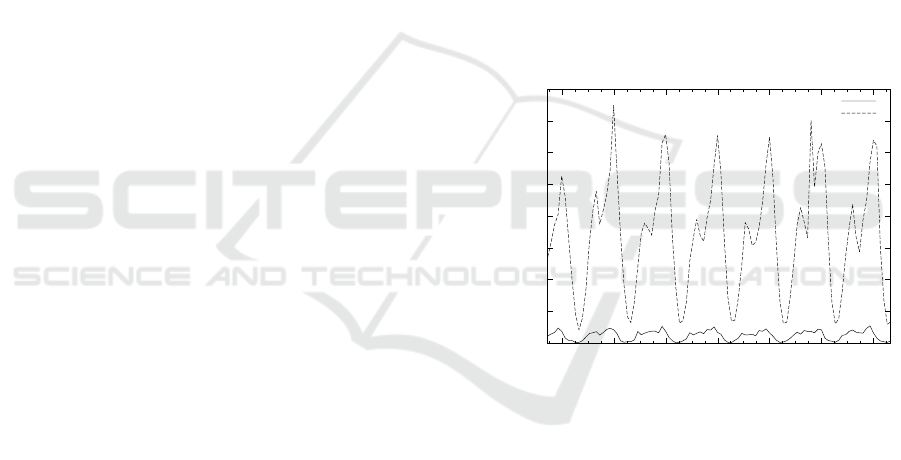
2015. Figure 2 shows the results of this analysis.
0
2000
4000
6000
8000
10000
12000
14000
16000
08-23 08-24 08-25 08-26 08-27 08-28 08-29
Download speed [tweet/hour]
Time
Czech Republic
France
Figure 2: Comparison of the Czech and French Twitter ac-
tivity.
This figure shows that the activity of French Twit-
ter is more than 10 × higher than the Czech Twitter.
The average of the Czech download rate is about 495
tweets/hour. However, after a detailed examination,
we have identified that only less than 20% of tweets
are written in Czech languages.
Unfortunately, this number is insufficient for
a successful further analysis as for instance for event
detection in real-time. Therefore, we must analyze
the other approaches for data acquisition.
5.1.2 Comparison of the Different Data
Acquisition Methods
In this experiment, we compare the download speed
of two standard methods provided by the Twitter
API (namely Search API and Filtered Streaming API
Real-Time Data Harvesting Method for Czech Twitter
263

Figure 3: Event detection example (time period T = 2h and acceptance threshold T h = 0.5). The rectangle on the right
contains six tweets that were saved by our acquisition method. The left “bubbles” show the results of our clustering (two
groups containing three and two tweets). The representative tweets are chosen (marked by the bold text on the left side) to be
presented to the user.
methods - see Sections 4.1.1 and 4.1.2, respectively)
with the proposed UserList approach (see Sec. 4.1.3).
We have thus executed all these methods in the same
two day period and then we have calculated the aver-
age value for one hour.
Table 2: Comparison of the download speed of the different
methods on the Czech Twitter.
Method Tweets no. / hour
Search API 43.5
Filtered Streaming API 56.6
UserList (proposed) 330.3
The results of this experiment are shown in Ta-
ble 2. This table shows that the proposed method
provides about 6 times more data than the standard
methods provided by Twitter API. Based on these re-
sults we have chosen the UserList approach to inte-
grate into our event detection system.
5.2 Event Detection
We have used 15,856 tweets downloaded by UserList
approach to evaluate the detection performance of our
system. We have executed the event detection algo-
rithm with different values of the acceptance thresh-
old (T h ∈ [0; 1]) and analyzed the results. The analy-
sis of the resulting clusters has shown that for results
with T h > 0.5 the algorithm still detects the major-
ity of events correctly (high precision). However, the
main interest is to have the recall as high as possi-
ble. The precision is not so important, because of the
possibility of manual filtering of incorrectly detected
events. Therefore, we set in our system a slightly
lower acceptance threshold which causes to detect
more events with some false positives.
These preliminary results were shown and dis-
cussed with our client who is ready to test this ex-
perimental version of the system. It is clear that the
current version will already help to the reporters to re-
duce their work with manual checking of the available
data sources.
One sample of the results is depicted in Figure 3.
This figure shows that six tweets are saved by our ac-
quisition method (right rectangle). They are then clus-
tered into two groups containing three and two tweets
(left “bubbles”). Finally, one representative tweet is
chosen from both clusters to be presented to the user
(bold text left).
6 CONCLUSIONS AND
PERSPECTIVES
The main goal of this paper was to propose an ap-
ICAART 2017 - 9th International Conference on Agents and Artificial Intelligence
264

proach to harvest messages from Twitter in Czech
language with high download speed. The proposed
method uses user lists to discover potentially interest-
ing tweets to harvest. We have experimentally shown
that the proposed method is very efficient because it
harvests about 6 times more data than the two other
approaches provided by the Twitter API. This method
will be integrated into our event detection system. We
have also experimentally shown that the results of the
event detection are promising because the algorithm
detects a significant amount of potential events.
The proposed harvesting method is language in-
dependent. Therefore, the first perspective consists in
evaluation of this method on other (particularly Euro-
pean) languages. Another perspective is a thorough
evaluation of the event detection method. We would
like also improve this method using more sophisti-
cated semantic similarity functions. Another perspec-
tive is an adaptation and evaluation of the whole de-
tection system to the other languages.
ACKNOWLEDGEMENTS
This work has been partly supported by the project
LO1506 of the Czech Ministry of Education, Youth
and Sports and by Grant No. SGS-2016-018 Data and
Software Engineering for Advanced Applications.
REFERENCES
Atefeh, F. and Khreich, W. (2015). A survey of techniques
for event detection in Twitter. Computational Intelli-
gence, 31(1):132–164.
Earle, P. S., Bowden, D. C., and Guy, M. (2012). Twitter
earthquake detection: earthquake monitoring in a so-
cial world. Annals of Geophysics, 54(6).
Java, A., Song, X., Finin, T., and Tseng, B. (2009). Why we
Twitter: An analysis of a microblogging community.
In Advances in Web Mining and Web Usage Analysis,
pages 118–138. Springer.
Kouloumpis, E., Wilson, T., and Moore, J. D. (2011). Twit-
ter sentiment analysis: The good the bad and the omg!
Icwsm, 11:538–541.
Li, C., Sun, A., and Datta, A. (2012). Twevent: segment-
based event detection from tweets. In Proceedings of
the 21st ACM international conference on Information
and knowledge management, pages 155–164. ACM.
Naaman, M., Boase, J., and Lai, C.-H. (2010). Is it re-
ally about me?: message content in social awareness
streams. In Proceedings of the 2010 ACM conference
on Computer supported cooperative work, pages 189–
192. ACM.
Pak, A. and Paroubek, P. (2010). Twitter as a corpus for
sentiment analysis and opinion mining. In LREc, vol-
ume 10, pages 1320–1326.
Sakaki, T., Okazaki, M., and Matsuo, Y. (2010). Earthquake
shakes Twitter users: real-time event detection by so-
cial sensors. In Proceedings of the 19th international
conference on World wide web, pages 851–860. ACM.
Yardi, S. and Boyd, D. (2010). Dynamic debates: An analy-
sis of group polarization over time on Twitter. Bulletin
of Science, Technology & Society, 30(5):316–327.
Zeman, D., Du
ˇ
sek, O., Mare
ˇ
cek, D., Popel, M., Ra-
masamy, L.,
ˇ
St
ˇ
ep
´
anek, J.,
ˇ
Zabokrtsk
`
y, Z., and Haji
ˇ
c, J.
(2014). Hamledt: Harmonized multi-language depen-
dency treebank. Language Resources and Evaluation,
48(4):601–637.
Real-Time Data Harvesting Method for Czech Twitter
265
