
Simulation of Language Evolution based on Actual Diachronic Change
Extracted from Legal Terminology
Makoto Nakamura
1
, Yuya Hayashi
2
and Ryuichi Matoba
2
1
Japan Legal Information Institute, Graduate School of Law, Nagoya University,
1 Furo-cho, Chikusa-ku, Nagoya, Aichi, 464-8601, Japan
2
National Institute of Technology, Toyama College, 1-2, Ebie-neriya, Imizu City, Toyama, 933-0293, Japan
Keywords:
Language Evolution, Simulation, Iterated Learning Model, Cognitive Bias, Statute, Legal Terminology.
Abstract:
Simulation studies have played an important role in language evolution. Although a variety of methodologies
have been proposed so far, they are typically too abstract to recognize that their learning mechanisms properly
reflect actual ones. One reason comes from the lack of empirical data recorded for a long period with explicit
description. Our purpose in this paper is to show simulation models adapt to actual language change. As
empirical diachronic data, we focus on a statutory corpus. In general, statutes define important legal terms
with explanatory sentences, which are also revised by amendment. We proposed an iterated learning model, in
which an infant agent learns grammar through his/her parent’s utterances about legal terms and their semantic
relations, and the infant becomes a parent in the next generation. The key issue is that the learning situation
about legal terms and their relations can be changed due to amendment. Our experimental result showed that
infant agents succeeded to acquire compositional grammar despite irregular changes in their learning situation.
1 INTRODUCTION
A goal of the study on language evolution, or evo-
lutionary linguistics, is to explain the origins of the
structure found in language (Hurford, 2002). This
study has been increasingly interdisciplinary, involv-
ing collaborations between linguists, philosophers,
biologists, cognitive scientists, robotics, mathemati-
cal and computational modelers (Lyon et al., 2007).
In particular, simulation studies have played an im-
portant role in the field of language evolution. A very
important function of simulation is to prove whether
a prediction actually and consistently derives from a
theory (Cangelosi and Parisi, 2002).
Although a variety of methodologies have been
proposed so far (Briscoe, 2002), they are typically too
abstract to recognize that their learning mechanisms
properly reflect the actual ones. Natural language,
however, is not such a simple phenomenon. Abstract
models could include only simple learning mecha-
nisms, which would be hard to deal with complicated
phenomena appearing in natural language. The main
challenge in language evolution is a lack of empiri-
cal data, that is, spoken language leaves practically
no traces. Therefore, it would be helpful if there are
language resources recorded in a long period with ex-
plicit description.
To solve this problem, we introduce a Japanese
statutory corpus. In particular, we focus on legal
terms defined in a provision, each of which consists of
a tuple of a legal term and its explanatory sentences.
Legal statutes are not only established but also of-
ten amended by changes in social situations. In some
cases, legal terms are also revised, added, and deleted,
depending on the scale of the amendment. Therefore,
an amendment to provisions for legal terms implies
a drastic change of the entire act. The terminology
for legal terms must deal with such temporal changes
that are dependent on amendment acts. Our purpose
in this paper is to show the simulation models for lan-
guage evolution properly deals with actual language
changes.
We employ simulation models for grammar
acquisition based on the iterated learning model
(ILM) (Kirby, 2002), which shows a process of gram-
matical evolution through generations. This approach
has often been used in simulation models concerning
language evolution (Nakamura et al., 2015). One im-
portant reason for this comes from its robustness for
syntactic learning from input sentences. As long as
it is learning from a single parent, an infant agent re-
ceives sentences derived from a consistent grammar;
Nakamura M., Hayashi Y. and Matoba R.
Simulation of Language Evolution based on Actual Diachronic Change Extracted from Legal Terminology.
DOI: 10.5220/0006291903430350
In Proceedings of the 9th International Conference on Agents and Artificial Intelligence (ICAART 2017), pages 343-350
ISBN: 978-989-758-219-6
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
343

it is possible to acquire a concise grammar.
This paper is organized as follows. In Section 2,
we explain how to extract data for actual language
changes from statutory texts. In Section 3, we intro-
duce ILMs and our proposed model, which are exam-
ined in Section 4. Finally, we conclude in Section 5.
2 DIACHRONIC CHANGES IN
LEGAL TERMS
In this section, we introduce diachronic changes in
legal terms. Section 2.1 explains how to extract legal
terms from statutory texts. Section 2.2 shows these
evolutionary changes with examples.
2.1 Extraction of Legal Terms
Figure 1 shows an excerpt from the act dealing with
the change of the term “Gas Business.” The amended
act is shown in Figure 2.
1
What are recognized as legal terms to be collected
depends on the purpose (Winkels and Hoekstra, 2012;
Nakamura et al., 2016). In this paper, we define le-
gal terms as those explicitly defined prior to use in a
statute, each of which consists of a tuple of a legal
term in the quotations and its explanation.
An article for definition of legal terms often con-
sists of a number of paragraphs, each of which defines
a legal term. They are described with boilerplate ex-
pressions including a legal term and its explanatory
sentence, which can be extracted with a set of regular
expression rules. The underlined phrases
2
in Figure 1
match one of the rules. As a result, the legal term
“Gas Business” and its explanation can be extracted.
A defined term also appears in parentheses fol-
lowing a phrase as its explanation in the main text.
Abbreviations of terms are often defined in parenthe-
ses. An example is shown in Figure 2, where the
term “Specified Gas Generating Facility” is defined
in parentheses. We extracted the explanation, the un-
derlined part
2
in Figure 2, from the beginning of the
definition to just before the beginning of the parenthe-
ses. Note that some explanatory sentences of a term
include other legal terms as its hypernym or hyponym,
which enables us to extract hyponymy relations be-
tween legal terms.
1
We referred to the Japan Law Translation Database
System (http://www.japaneselawtranslation.go.jp/) for the
English translation of these acts. When there is no trans-
lation for the acts or act titles in the website, we manually
translated them using the database.
2
The original statute does not include the underlines,
which were added by the author.
Gas Business Act (Act No. 51 of 1954)
✓ ✏
(Definitions)
Article 2 (1)
The term “Gas Business” as used
in this Act shall mean the business of supplying
gas via pipelines to meet general demand.
✒ ✑
Figure 1: Excerpt from the Gas Business Act (Act No. 51
of 1954).
Gas Business Act (Act No. 51 of 1954)
✓ ✏
[As of October 12, 1970]
(Definitions)
Article 2 (1) The term “General Gas Utility
Business” as used in this Act shall mean the
business of supplying gas via pipelines to meet
general demand (excluding, however, businesses
generating gas at a gas generating facility pre-
scribed in paragraph (3) and supplying such gas
via pipelines). (*snip*)
(3) The term “Community Gas Utility Busi-
ness” as used in this Act shall mean
the business
of generating gas at a simplified gas generating
facility specified by aCabinet Order (hereinafter
referred to as a “Specified Gas Generating Fa-
cility”) and supplying such gas via pipelines to
meet general demand at not less than 70 gas ser-
vice points within one housing complex.
(*snip*)
(5) The term “Gas Business” as used in this
Act shall mean a General Gas Utility Business
or Community Gas Utility Business.
✒ ✑
Figure 2: Excerpt from the Gas Business Act (Act No. 51
of 1954) as of October 12, 1970.
We successfully extracted legal terms, their ex-
planations, and their relations. We found 27,737
terms and 36,698 relations. The precision of the re-
lations was 88.0%, which might be improved with
additional regular expression rules (Nakamura et al.,
2016). The diachronic terminology shows legal terms
evolves reflecting the social change, although legal
documents are the most conservative in terms of lan-
guage change.
2.2 Example of Diachronic Change
We cite the Gas Business Act (Act No. 51 of 1954)
as an example to explain diachronic changes in le-
gal terms. As of 2013, this act has been amended
34 times, at least five of which include the revision
of terms and definitions in Articles 2 and 39-2. Fig-
ures 3(a) to 3(c) show the diachronic changes in the
ICAART 2017 - 9th International Conference on Agents and Artificial Intelligence
344

terms at three time points:
(1) At the new enactment, only two terms, “Gas Busi-
ness” and “Gas Facilities,” were defined in the
Gas Business Act (Act No. 51 of 1954), which
came into effect as of April 1, 1954 (Figure 3(a)).
(2) The term “Gas Business” was changed to “Gen-
eral Gas Utility Business,” which became a hy-
ponym of the newly defined term “Gas Business”
with the newly added term “Community Gas Util-
ity Business,” by the Act on the Partial Amend-
ment of the Gas Business Act (Act No. 18 of
1970), which came into effect as of October 12,
1970. Likewise, the term “Gas Supplier” and its
hyponyms “General Gas Utility” and “Commu-
nity Gas Utility” were defined. So was the term
“Specified Gas Generating Facility” as an isolated
term. Note that, unlike language changes as a nat-
ural phenomenon, the sense of legal terms was
forced to change on the enforcement date (Fig-
ure 3(b)).
(3) As of the enforcement of the Act for the Partial
Revision of the Electricity Business Act and the
Gas Business Act (Act No. 92 of 2003), the num-
ber of terms defined in the Gas Business Act was
increased to 15 (Figure 3(c)). In the period be-
tween (2) and (3), the terms “Class-I Gas Equip-
ment,” “Class-II Gas Equipment” and “Wholesale
Supply” were defined, but deleted later. In addi-
tion, the term “Intra-Area Wheeling Service” was
replaced with “Wheeling Service.” These were
basically eliminated by social selection.
3 ITERATED LEARNING
MODELS
In this section, we introduce iterated learning mod-
els for learning grammar in the environment of legal
terms. First, we briefly explain Kirby’s ILM (KILM).
Next, we introduce the modification for taking cogni-
tive biases into account. Finally, we make some minor
changes to adapt the model to the new environment.
3.1 KILM
Kirby (Kirby, 2002) introduced the notions of com-
positionality and recursion as fundamental features of
grammar, and showed that they make it possible for a
human to acquire compositional language. Figure 4
illustrates KILM. In each generation, an infant can
acquire grammar in his/her mind given sample sen-
tences from his/her mother. After growing up, the
infant becomes the next parent to speak to a new-
born baby with his/her grammar. As a result, infants
can develop more compositionalgrammar through the
generations. Note that the model focuses on the gram-
mar change in multiple generations, not on that in one
generation. Also, Kirby adopted the idea of two dif-
ferent domains of language (Bickerton, 1990; Chom-
sky, 1986), namely, I-language and E-language; I-
language is the internal language corresponding to
a speaker’s intention or meaning, while E-language
is the external language, that is, utterances. In his
model, a parent is a speaker agent and his/her infant
is a listener agent. The speaker agent gives the lis-
tener agent a pair of a string of symbols as an utter-
ance, and a predicate-argument structure (PAS) as its
meaning. A number of utterances would form com-
positional grammar rules in a listener’s mind, through
the learning process. This process is iterated genera-
tion by generation, and converges to a compact, lim-
ited number of grammar rules.
According to KILM, the parent agent gives the in-
fant agent a pair of a string of symbols as an utter-
ance, and PAS as its meaning. The agent’s linguistic
knowledge is a set of a pair of a meaning and a string
of symbols, as follows.
S/love( john,mary) → hjsbs, (1)
where the meaning, i.e., the speaker’s intention, is
represented by a PAS love(john, mary) and the string
of symbols is the utterance “hjsbs”; the symbol ‘S’
stands for the category Sentence. The following rules
can also generate the same utterance.
S/love(x,mary) → h N/x sbs
N/ john → j,
(2)
where the variable x can be substituted for an arbitrary
element of category N.
The infant agent has the ability to generalize
his/her knowledge with learning. This generaliz-
ing process consists of the following three opera-
tions (Kirby, 2002): chunk, merge, and replace.
Chunk. This operation takes pairs of rules and looks
for the most-specific generalization.
S/love( john, pete) → ivnre
S/love(mary, pete) → ivnho
⇒
S/love(x, pete) → ivn N/x
N/ john → re
N/mary → ho.
(3)
Merge. If two rules have the same meanings and
strings, replace their non-terminal symbols with
one common symbol.
Simulation of Language Evolution based on Actual Diachronic Change Extracted from Legal Terminology
345

(a) Legal terms and relations in the Gas Business Act (Act No. 51 of 1954)
(b) Legal terms and relations as of enforcement of the Act on the Partial Amendment of the Gas
Business Act (Act No. 18 of 1970)
(c) Legal terms and relations as of enforcement of the Act for the Partial Revision of the Elec-
tricity Business Act and the Gas Business Act (Act No. 92 of 2003)
Figure 3: Dynamics of definitions in the Gas Business Act.
Figure 4: Iterated learning model.
Replace. If a rule can be embedded in another rule,
replace the terminal substrings with a composi-
tional rule.
In Kirby’s experiment (Kirby, 2002), a constant
number of predicates and object words (five for exam-
ple) are employed. Also, two identical arguments in
a predicate like love(john, john) are prohibited. Thus,
there are 100 distinct meanings (5 predicates × 5 pos-
sible first arguments × 4 possible second arguments)
in a meaning space.
The key issue in ILM is to create a poverty of stim-
ulus, which explains the necessity of universal gram-
mar (Chomsky, 1980). Kirby (Kirby, 2002) modeled
it as learning through bottlenecks, which are rather
necessary for the learning. As long as an infant agent
is given all sentences in the meaning space during
learning, he/she does not need to make a composi-
tional grammar; he/she would just memorize all the
meaning-sentence pairs. Therefore, agents are given
a part of sentences in the whole meaning space. The
total number of utterances the infant agent receives
during learning is parameterized. Since the num-
ber of utterances is limited, the infant agent cannot
learn the whole meaning space; thus, to obtain the
whole meaning space, the infant agent has to gen-
eralize his/her own knowledge by self-learning, i.e.,
chunk, merge, and replace. The parent agent receives
a meaning selected from the meaning space, and ut-
ters it using his/her own grammar rules. When the
parent agent cannot make an utterance because of a
lack of grammar rules, he/she invents a new rule. This
process is called invention. Even if the invention does
not work to complement the parent agent’s grammar
rules, he/she utters a randomly composed sentence.
3.2 Meaning Selection ILM with
Cognitive Biases (MSILMB)
The iterated learning model has been expanded for
examining the relationship between language acqui-
sition and cognitive biases. Several studies have sug-
gested that cognitive biases work effectively in the
first language acquisition (Imai and Gentner, 1997;
Markman, 1990). Cognitive bias, which is common to
all human beings, involves systematic errors in judg-
ment and decision-making due to cognitive limita-
tions, motivational factors, and/or adaptations to nat-
ural environments (Wilke and Mata, 2012).
These biases work in a joint attention framework
where two individuals, a parent and an infant, share a
state of an environment. For example, the parent and
infant are looking at a rabbit which are eating car-
rots, and the parent utters ‘Gavagai.’ In this situation,
ICAART 2017 - 9th International Conference on Agents and Artificial Intelligence
346

Figure 5: Learning Process on Meaning Selection ILM.
the infant cannot infer the meaning of ‘Gavagai’ log-
ically, i.e., there are many possibilities of its mean-
ing, such as a rabbit, a white animal or an action of
eating. This problem is well known as Gavagai prob-
lem (Quine, 1960). The learning environment of in-
fants in first language acquisition is very close to this
situation. However, they overcome this problem, and
acquire their first language at an overwhelming pace.
For this infants’ phenomenal learning, several studies
have suggested that the infants infer meanings effi-
ciently to limit possibilities in a situation using con-
straints, that is cognitive biases, and identify a mean-
ing of the utterance (Imai and Gentner, 1997; Hansen
and Markman, 2009).
The Meaning Selection ILM (MSILM) (Sudo
et al., 2016) employs the notion of a joint attention
frame in KILM. Figure 5 shows an image of the learn-
ing process on MSILM, in which both parent and in-
fant agents share a situation. The parent agent selects
a part of the situation (M
x
) which contains multiple
meanings {M
1
,... ,M
N
}, and utters U about it to the
infant agent. Once receiving the utterance, he/she
infers its meaning from the presented situation, and
learns a pair of the utterance U and its meaning M
y
.
Thus, the infant agent does not always infer the same
pair as the parent’s knowledge, that is, the infant agent
would acquire the grammar rule S/M
y
→ U, while the
parent’s utterance was derived from his/her knowl-
edge of S/M
x
→ U.
Some cognitive biases have been employed to
MSILM, and their effectiveness was verified on sim-
ulation of the first language acquisition (Sudo et al.,
2013). Hereafter, we call MSILM with cognitive bi-
ases MSILMB, which employed the following biases:
Symmetry Bias: When the predicate p → q is true,
the symmetry bias allows humans to mislead q →
p being also true. A pair of p and q is put as a
pair of label and object (Imai and Gentner, 1997),
a pair of meaning and utterance (Matoba et al.,
2010) and so on. If an infant agent can gener-
ate the same utterance as the parent agent’s, and
its meaning is found in the presented meaning,
he/she connects the utterance and the meaning.
Otherwise, the infant agent selects one out of the
presented meanings randomly.
Mutual Exclusivity Bias: This is the assumption
that only one label can be applied to each object
in early word learning (Markman, 1990). If an in-
fant agent has already acquired the grammar rule
S/M → U
1
, he/she dose not connect the meaning
M to any other utterances. In other words, if the
infant agent can generate the utterance of a pre-
sented meaning M
′
in a situation with his/her ac-
quired grammar and the generated utterance is not
the same as the parent agent’s, the infant agent de-
selects M
′
from the candidate of the meaning of
the parent agent’s utterance.
These biases work as “one utterance to one mean-
ing (symmetry bias),” and “one meaning to one utter-
ance (mutual exclusivity bias),” i.e., the effect of these
biases gives a one-to-one relation between a meaning
and an utterance to the infant agent under a multiple
cognition environment like a joint attention frame.
3.3 Our Model
We basically employ MSILMB in infant agents’
learning process. We assume that a parent-infant pair
shares their situation in the environment.
Our model differs from the former one (Sudo
et al., 2013) as follows:
• The situation can be changed about a set of legal
terms and their relations by amendment from gen-
eration to generation. Some terms and relations
remain the same, while the others are deleted,
newly added, or replaced with others.
• The actual meaning space is a subset of the
whole meaning space; speakers can only speak a
scene of the actual situation, while they randomly
choose a meaning from the whole meaning space
in the former model.
• The number of utterances varies depending on the
situation. It is calculated as (the size of the whole
meaning space in generation)/2.
4 EXPERIMENTS
4.1 Experimental Settings
Our experiments aim to examine whether KLIM and
MSILMB properly work in actual situations over the
diachronic change. In order to reproduce the actual
Simulation of Language Evolution based on Actual Diachronic Change Extracted from Legal Terminology
347

diachronic change, we pick up legal terms defined
in the Gas Business Act (Act No. 51 of 1954) from
the Japanese statutory corpus. In the situation, agents
have knowledge about objects corresponding to legal
terms and their relations. One generation in the simu-
lation corresponds to a year in the actual world.
We defined three predicates; one represents a
state of isolation is
isolated, and the others are
for hyponymy relations, that is, is
hypernym of and
is hyponym of. The number of objects n varies along
with amendments. Therefore, the size of the whole
meaning space is calculated as (2 predicates for hy-
ponymy relations × n possible first arguments ×
(n− 1) possible second arguments + 1 predicate for
a state of isolation × n possible arguments). Table 1
shows the size of the whole meaning space, the size
of actual meaning space and the number of utterances
in each generation, which corresponds to years after
enforcement of the act.
In KILM, agent’s linguistic knowledge is evalu-
ated by expressivityand the numberof grammar rules.
Expressivity is defined as how much of the whole
meaning space the agent can utter with his/her gram-
mar rules. In MSILMB, it is important how much
the infant agent acquired language close to the parent
agent’s. Therefore, to evaluate the similarity between
two languages, we employed the language influence
rate, which is based on similarity between two char-
acter strings. The language influence rate is calculated
at the end of each generation by comparing between
the enumerations of sentences whom both parent and
infant agents can utter with their grammar rules (See
(Nakamura et al., 2015) for more details of the lan-
guage influence rate, which is called language dis-
tance).
An utterance is expressed with a string of 10 types
of letters. Agents can invent an utterance by invention
in a range of 2 to 4 letters. A trial of the simulation
stops at the 60th generation, which is the span be-
tween the enforcement of the Gas Business Act and
that of the last amendment act with a 10-year-blank
for learning.
We compare experimental results of KILM and
MSILMB; in the former, since infants receive a pair
of a meaning and a string of symbols from parents,
agents are expected to acquire compositional gram-
mar. Meanwhile in the latter, infants receives only a
string of symbols, which implies they need to infer
what parents talk about. The learning is more diffi-
cult, but its learning environment is close to the actual
one.
4.2 Experimental Results
We show experimental results in Figure 6, in which
all the lines are plotted by average of 100 trials.
Figure 6(a) shows the rate of actual meanings
infants can utter by generation. This shows how
much agents can represent actual situations using
their grammar rules. Note that the actual meaning
space is a subset of the whole meaning space. For ex-
ample, in the generations from 1 to 16 corresponding
to Figure 3(a), there are only two actual situations, de-
noted by the meanings: is
isolated(GasBusiness) and
is isolated(GasFacilities). If the parent agent utters
both of them in the limited number of utterances, that
is 3, his/her infant can learn both utterances. In addi-
tion, if those utterances share a common substring in
different meanings, the infant can extract a composi-
tional rule denoting is
isolated(X) by chunking.
Overall, since this process is common in KILM
and MSILMB, the result shows almost the same.
Since the number of utterances is much more than that
of the actual meanings, infant agents are likely to lis-
ten to all kinds of utterances for the actual meanings
in a generation.
Figure 6(b) shows expressivity in the whole mean-
ing space by generation. The thin solid line de-
notes the border of compositionality, which is calcu-
lated as (Size of actual meaning space)/(Size of the
whole meaning space). If the expressivity exceeds
it, the grammar is regarded as compositional. In
the early generations, expressivity in the both models
shows around 0.3, because there are 2 actual mean-
ings against 6 possible patterns. After the first amend-
ment at the 17th generation, the expressivity suddenly
dropped down. This is because the number of possi-
ble meaning patterns rose from 6 to 120 due to the
growing number of legal terms from 2 to 8.
Figure 6(c) shows the normalization by the num-
ber of actual meanings for Figure 6(b). Therefore, the
value less than 1 implies agents do not learn composi-
tional grammar, which suggests that agents can utter
little other than what they heard until the 31st genera-
tion. This is because agents receive 60 utterances for
10 actual meaning patterns. In other words, they are
not exposed to poverty of stimulus, which is supposed
to promote learning compositional grammar. As a re-
sult, they just seem to memorize all the utterances
from their parents during the 17th to 31st generation.
We can see if agents learn compositional gram-
mar by checking the number of grammar rules they
acquired. Figures 6(d) and 6(e) show the number of
rules by generation in KILM and MSILMB, respec-
tively. Note that decreasing sentence rules and in-
creasing word rules imply that acquired grammar is
ICAART 2017 - 9th International Conference on Agents and Artificial Intelligence
348
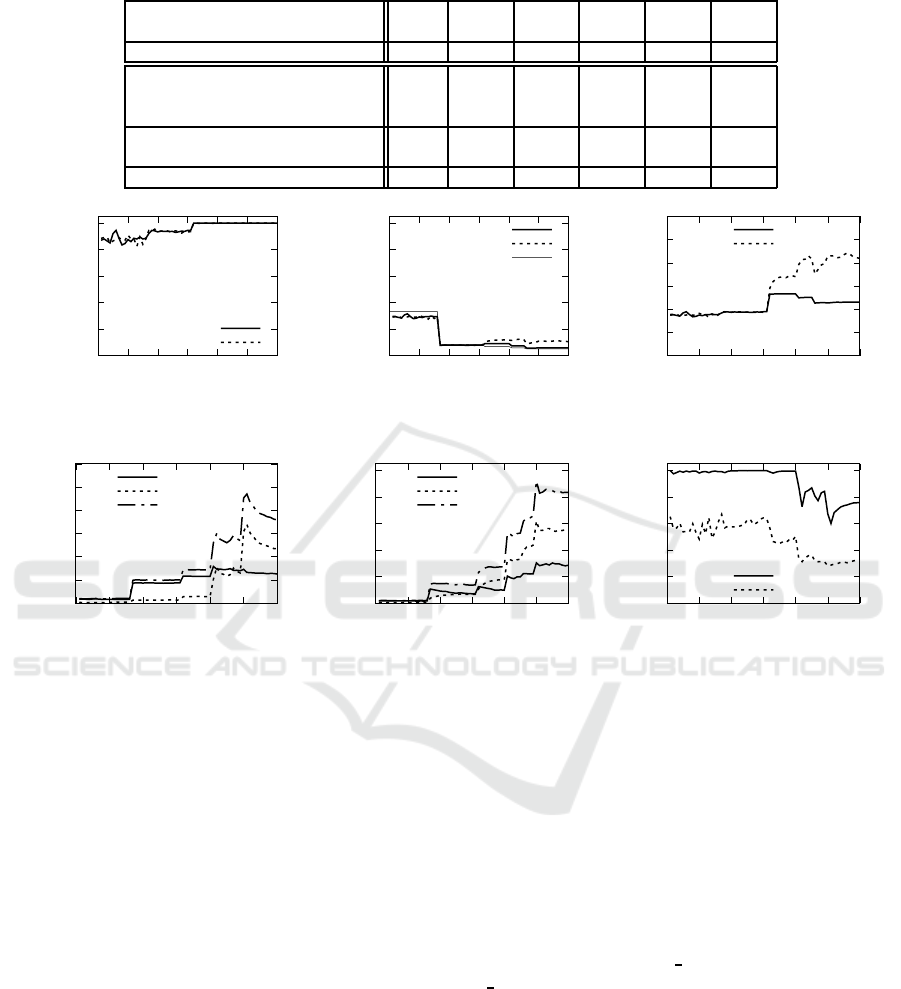
Table 1: Number of utterances based on meaning space in each generation.
Year From 1954 1970 1985 1994 1999 2003
To 1969 1984 1993 1998 2002 2014
Generation 1-16 17-31 32-40 41-45 46-49 50-60
Number of objects 2 8 10 13 14 15
Number of isolated objects 2 2 1 1 3 2
Number of hyponymy relations 0 8 12 18 16 20
Size of the whole meaning space 6 120 190 325 378 435
Size of the actual meaning space 2 10 13 19 19 22
Number of utterances 3 60 95 163 189 218
0
0.2
0.4
0.6
0.8
1
0 10 20 30 40 50 60
Expressivity
in the actual meaning space
Generation
KILM
MSILMB
(a) Expressivity in the actual meaning
space
0
0.2
0.4
0.6
0.8
1
0 10 20 30 40 50 60
Expressivity
in the whole meaning space
Generation
KILM
MSILMB
Actual Space
(b) Expressivity in the whole meaning
space
0
0.5
1
1.5
2
2.5
3
0 10 20 30 40 50 60
Normalized expressivity
Generation
KILM
MSILMB
(c) Normalized expressivity
0
10
20
30
40
50
60
0 10 20 30 40 50 60
Number of rules
Generation
S
W
S+W
(d) Number of grammar rules in KILM
(S: sentence, W: word)
0
20
40
60
80
100
0 10 20 30 40 50 60
Number of rules
Generation
S
W
S+W
(e) Number of grammar rules in
MSILMB (S: sentence, W: word)
0
0.2
0.4
0.6
0.8
1
0 10 20 30 40 50 60
Language influence rate
Generation
KILM
MSILMB
(f) Language influence rate
Figure 6: Experimental Results.
compositional. During the 17th to 31st generation,
agents in KILM keep around 10 sentence rules for
10 actual meanings, while those in MSILMB seem
to have a decreasing number of sentence rules. The
same can be seen during the 32nd to 40th genera-
tion. Since the symmetry bias works well, agents
make similar utterances regard to have similar mean-
ings. Furthermore, the mutual exclusivity bias pre-
vent agents from making inconsistent rules, which fa-
cilitates acquisition of compositional grammar. As a
result, the normalized expressivity of MSILMB ex-
ceeds that of KILM from the 32nd generation due to
high compositionality.
Learning compositional grammar enables agents
to represent even inexperienced situations. From this
viewpoint, as far as seeing Figure 6(b), neither KILM
nor MSILMB is enough for representing the whole
meaning space. This is because the learning period in
60 generations is too short.
The problem of MSILMB is that grammatical
learning is far from matching actual meanings. In
fact, it is not always true that similar utterances have
similar meanings. Figure 6(f) shows the language in-
fluence rate by generation. KILM keeps higher than
MSILMB in the influence rate, which denotes agents
in KILM are more likely to speak similar language
to their parents. This is characteristics of MSILMB,
in which learning compositionality takes priority over
interpretation of utterances. For example in the sit-
uation of Figure 3(a), when a parent agent utters
“
bus
” and “
fac
” for is isolated(GasBusiness) and
is
isolated(GasFacilities), his/her infant agent may
misunderstand the former utterance corresponds to
the latter meaning, and vice versa. This phenomenon
could cause the decrease of the language influence
rate.
Through the experiments, we showed agents in
MSILMB properly acquired compositional grammar
in the actual situation of language change. An excerpt
of grammar rules that the infant agent acquired at the
60th generation in a trial is shown in Equation (4).
Simulation of Language Evolution based on Actual Diachronic Change Extracted from Legal Terminology
349

S/x
0
(x
1
,x
2
) → C
10
/x
0
C
16
/x
1
C
17
/x
2
C
10
/is
hypernym of → ei
C
10
/is
hyponym of → a
C
16
/CommunityGasUtilityBusiness → e
C
16
/LargeVolumeGasBusiness → e
C
17
/GasBusiness → febja
S/isolate(x
1
) → e C
11
/x
1
C
11
/GasFacilities → hbfj
C
11
/WheelingService → hieb,
(4)
where S, C
10
, C
11
, C
16
and C
17
are non-terminal sym-
bols as a category name, and x
0
, x
1
and x
2
are vari-
ables.
5 CONCLUSION
In this paper, we introduced a diachronic legal ter-
minology to simulation models to confirm proposed
models properly deal with natural language phenom-
ena. Legal terms are defined in statutes, in which they
are added, deleted, or replaced with others reflecting
social change. Therefore, the change of legal terms
and their relations is unstable and not coherent.
We used KILM and MSILMB for learning com-
positional grammar under the environment. As a re-
sult, KILM showed agents acquired less composi-
tional grammar due to a difficult learning environ-
ment. Meanwhile in MSILMB, agents succeeded to
deal with the environment, although their grammar is
less influenced on their parents’ one.
Our achievement could contribute to not only lan-
guage evolution, but also some novel field of language
processing, because it is a part of huge and complex
problem of creation of systems with learning (self-
learning) abilities to the reactions in previously un-
known situations. For example, it would be useful for
creation of constantly expending library of actions for
robots working on another planets.
Integration of language evolutionand legal knowl-
edge is a challenging theme. Our analysis of the statu-
tory corpus revealed that statutes are excellent data
for pursuing actual language change. Although we,
in this paper, chose the Gas Business Act by chance,
further analysis would lead to synthetic characteris-
tics of legal terms.
ACKNOWLEDGEMENT
This work was partly supported by JSPS KAKENHI
Grant Numbers JP15K00201, JP15K16013.
REFERENCES
Bickerton, D. (1990). Language and Species. University of
Chicago Press.
Briscoe, E. J., editor (2002). Linguistic Evolution through
Language Acquisition: Formal and Computational
Models. Cambridge University Press.
Cangelosi, A. and Parisi, D., editors (2002). Simulating the
Evolution of Language. Springer, London.
Chomsky, N. (1980). Rules and Representations. Basil
Blackwell, Oxford.
Chomsky, N. (1986). Knowledge of Language:Its Nature,
Origin, and Use. Praeger, New York.
Hansen, M. B. and Markman, E. M. (2009). Children’s use
of mutual exclusivity to learn labels for parts of ob-
jects. Developmental Psychology, 45(2):592–596.
Hurford, J. R. (2002). The Roles of Expression and Repre-
sentation in Language Evolution. In The Transition to
Language, pages 311–334. Oxford University Press,
Cambridge.
Imai, M. and Gentner, D. (1997). A cross-linguistic study
of early word meaning: Universal ontology and lin-
guistic influence. Cognition, 62(2):169–200.
Kirby, S. (2002). Learning, bottlenecks and the evolution
of recursive syntax. In Briscoe, T., editor, Linguistic
Evolution through Language Acquisition: Formal and
Computational Models, chapter 6. Cambridge Univer-
sity Press.
Lyon, C., Nehaniv, C., and Cangelosi, A., editors
(2007). Emergence of Communication and Language.
Springer.
Markman, E. M. (1990). Constraints children place on word
meanings. Cognitive Science, 14(1):57–77.
Matoba, R., Nakamura, M., and Tojo, S. (2010). Efficiency
of the symmetry bias in grammar acquisition. Infor-
mation and Computation, 209(3):536–547.
Nakamura, M., Matoba, R., and Tojo, S. (2015). Simulation
of Emergence of Local Common Languages Using It-
erated Learning Model on Social Networks. Inter-
national Journal on Advances in Intelligent Systems,
8(3&4):374–384.
Nakamura, M., Ogawa, Y., and Toyama, K. (2016). De-
velopment of Diachronic Terminology from Japanese
Statutory Corpora. Journal of Open Access to Law,
4(1):16 pages.
Quine, W. V. O. (1960). Word and Object. MIT Press.
Sudo, H., Matoba, R., Cooper, T., and Tsukada, A. (2016).
Effect of the Symmetry Bias on Linguistic Evolution.
Artificial Life and Robotics, 21(2):207–214.
Sudo, H., Matoba, R., Hagiwara, S., Nakamura, M., and
Tojo, S. (2013). Knowledge Revision based on Ef-
ficacy of Cognitive Biases in First Language Acquisi-
tion. In Proceedings of the 30th Annual Meeting of the
Japanese Cognitive Science Society, pages 343–349.
Wilke, A. and Mata, R. (2012). Cognitive Bias. Encyclope-
dia of Human Behaviour, 1:531–535.
Winkels, R. and Hoekstra, R. (2012). Automatic Extraction
of Legal Concepts and Definitions. In Legal Knowl-
edge and Information Systems - JURIX 2012: The
Twenty-Fifth Annual Conference, pages 157–166.
ICAART 2017 - 9th International Conference on Agents and Artificial Intelligence
350
