
Identifying Relevant Resources and
Relevant Capabilities of Informal Processes
C. Timurhan Sungur
1
, Uwe Breitenb
¨
ucher
1
, Oliver Kopp
2
, Frank Leymann
1
and Andreas Weiß
1
1
Institute of Architecture of Application Systems, University of Stuttgart, Germany
2
Institute for Parallel and Distributed Systems, University of Stuttgart, Germany
Keywords:
Informal Processes, Unstructured Processes, Resource Discovery, Capability Discovery, Relevant Resources,
Relevant Capabilities.
Abstract:
Achieving goals of organizations requires executing certain business processes. Moreover, the effectiveness
and the efficiency of organizations are affected by how their business processes are enacted. Thus, increasing
the performance of business processes is in the interest of every organization. Interestingly, resources and
their capabilities impacting past enactments of business processes positively or negatively can similarly have
a positive or a negative impact in their future executions. Therefore, in our former work, we demonstrated
a systematic method for identifying such resources and capabilities of business processes using interactions
between resources of business processes without detailing the concepts required for this identification. In
this work, we fill this gap by presenting a conceptual framework including concepts required for identifying
resources possibly impacting business processes and capabilities of these resources based on their interactions.
Furthermore, we present means of quantifying the significance of resources and their capabilities for business
processes. To evaluate the identified resources and capabilities with their significance, we compare the results of
the case study on the Apache jclouds project from our former work with the data collected through a survey. The
results show that our system can estimate the actual values with 18% of a mean absolute percentage error. Last
but not least, we describe how the presented conceptual framework is implemented and used in organizations.
1 INTRODUCTION
During their lifetime, organizations typically work
to reach better states than their current ones, e.g.,
a more profitable state, a more knowledgeable state,
and a more competitive state. To reach these desired
states, organizations set and achieve their organiza-
tional goals [Etzioni, 1964]. Achieving these goals
requires organizations to conduct a set of value adding
activities in a certain order forming business processes
of that organization. Documenting business processes
supports humans when executing these processes, au-
tomating parts of executions, and improving these, as
many of these business processes are executed repeat-
edly. In case business processes contain repetitive
activities among different process enactments, busi-
ness experts can document these repeating activities
in business process models using activity-oriented ap-
proaches [Leymann and Roller, 2000, Weske, 2010].
These approaches enable modeling, executing, and im-
proving business processes based on their activities.
As activities and the order of them, i.e., the structure of
processes, do not change in different executions, busi-
ness process models can be used to prescribe their exe-
cution. In contrast to such structured processes, there
are business processes which do not follow a clearly
described sequence of activities, i.e., the activities and
their execution order are not or only less structured
in advance and evolve during execution. Thus, each
execution is different from others. Different business
process modeling and execution approaches have been
proposed to deal with semi-structured and unstructured
processes [Dustdar, 2004, Moody et al., 2006, Her-
rmann and Kurz, 2011, Sungur et al., 2014]. Semi-
structured and unstructured processes typically involve
activities for creating specific, individual knowledge
on runtime. Due to strongly varying ways to achieve
such goals, modeling unstructured processes based
on activities typically does not increase the perfor-
mance of these processes. Based on these proper-
ties, different works named these processes differently,
such as ad-hoc processes [Dustdar, 2004], unstruc-
tured processes [Di Ciccio et al., 2015], declarative
flows [van der Aalst et al., 2009], and informal pro-
Sungur, C., Breitenbücher, U., Kopp, O., Leymann, F. and Weiß, A.
Identifying Relevant Resources and Relevant Capabilities of Informal Processes.
DOI: 10.5220/0006300702950307
In Proceedings of the 19th International Conference on Enter prise Information Systems (ICEIS 2017) - Volume 2, pages 295-307
ISBN: 978-989-758-248-6
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
295

Figure 1: A simplified informal process model for a
bug fixing process.
cesses [Sungur et al., 2014]. In the following, we refer
to them as “informal processes”.
Organizations desire to increase their performance,
such as turnover, by improving the performance of
their business processes. Increasing performance of
activity-oriented processes has been on the focus of
the research community for a long time [van der Aalst,
2016]. However, there is a lack of detailed systematic
approaches for improving a business process contain-
ing negligible amounts of repeated activities shared
among its executions. Improving the performance of
unstructured processes involves allocating relevant ca-
pabilities provided by relevant resources. Documented
resources are resources, whose participation in infor-
mal processes is already known and documented. For
instance, an informal process for developing a open-
source software is initiated with a Git repository. In
this case, the Git repository is a documented resource
due to being prescribed upon the initialization. Rele-
vant resources are resources that interact with docu-
mented resources and other relevant resources in the
course of an informal process. For instance, each pull
request reviewer of a documented Git repository partic-
ipating in an informal process is relevant resource due
to interactions with a documented resource. Likewise,
a relevant capability is a capability of a relevant or a
documented resource of an informal process. Obvi-
ously, including certain relevant resources and capa-
bilities in informal processes may increase their per-
formance, such as including a person making frequent
contributions in an open-source software development
project. Thus, it is in the interest of organizations
to efficiently find appropriate relevant resources and
capabilities for enactments of such processes to opti-
mize their executions. Unfortunately, this cannot be
done a priori at design time since informal processes
strongly vary from enactment to enactment [Di Ciccio
et al., 2015]. Interestingly, previous enactments of
such processes may give hints on appropriate relevant
capabilities and resources that can be used.
In our previous work [Sungur et al., 2016], we
have demonstrated the extended Informal Process Ex-
ecution (InProXec) method enabling the identification
of relevant resources and relevant capabilities on a
case study. Identified relevant resources and relevant
capabilities are presented to business experts as rec-
ommendations at modeling time to enforce their deci-
sion making processes with the information gathered
from enactments of informal processes. Consequently,
these recommendations do not target at providing a
runtime support for human actors. In this work, we
complement this demonstration with the conceptual
foundations. Therefore, we present the following con-
tributions: (i) a conceptual framework for identifying
relevant resources and capabilities to support business
experts during modeling (Section 4), (ii) steps required
for enabling the generation of recommendations for
informal processes using the conceptual framework
presented (Section 4.1), and (iii) steps required for
generating recommendations for informal processes
using the conceptual framework (Section 4.2). In the
following sections, we firstly present a motivating sce-
nario (Section 2). After presenting the scenario, we
recap the InProXec method (Section 3). Then, we
present the contributions of this paper in Section 4.
Finally, we present related work in Section 5 and con-
clude in Section 6.
2 MOTIVATING SCENARIO
The motivating scenario is based on the Apache
jclouds project (https://jclouds.apache.org/) that ex-
poses typical characteristics of how people work. The
high-level goal of this project is developing Java li-
braries that unify access to functionalities of vari-
ous cloud service providers. To achieve this goal,
project members create an open-source project, in
which as many contributors as possible are desired.
As there are different cloud service providers in the
market, the project is divided into sub-projects to in-
tegrate these different providers. Thus, different de-
velopers are experienced and responsible for differ-
ent sub-projects. As the project is an open-source
project, external contributors, i.e., people who are not
part of the core project team, also participate in the
development. For instance, to integrate OpenStack
(https://www.openstack.org/), members of the Open-
Stack project create a sub-project implementing vari-
ous APIs in Java, e.g., APIs for storage services. Such
external experts contribute valuable knowledge about
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
296

Figure 2: A view on real world entities of interest.
the project parts, e.g., the computational service API
of OpenStack. Assigning the right resource to the right
job will likely increase the efficiency of the process
such as assigning a developer of the OpenStack stor-
age API to a process of fixing a bug of the OpenStack
storage API will reduce the time needed. Moreover,
certain types of interactions between resources imply
typical relevance relationships between them, e.g., a
“commit” interaction implies a relevance relationship
between the developer and the Git project containing
the source of OpenStack storage API. Thus, this devel-
oper is a relevant resource for the respective process.
During the lifetime of the software development
project, there are sub-processes that are executed re-
peatedly, such as reviewing code and fixing bugs. Each
such sub-process represents an example for an infor-
mal process, as they involve activities for creating
specific, individual knowledge at runtime. In case one
capability is used during one instance of these repet-
itive executions, it is likely that it will be used in a
later execution, too. Thus, such a capability can be
considered as relevant for that specific process and the
explicit inclusion of it can increase the efficiency of a
process. The sub-process of reviewing code contribu-
tions of external committers requires a coordination
capability, i.e., coordinating people during this revi-
sion process. In case this coordination capability is
used by one of the documented resources during the
enactment of sub-processes, this will imply that this
capability can be relevant for the future executions,
too. As a result, including such a relevant capability
provided by a resource will most likely increase the
efficiency of future executions of the same process.
In this work, we present a conceptual framework for
identifying relevant capabilities and resources by ana-
lyzing on interactions and capabilities of documented
resources.
3 FUNDAMENTALS
In the following paragraphs, we first describe the Infor-
mal Process Essentials (IPE) approach [Sungur et al.,
2014]. Hereafter, we describe the four-phased Infor-
mal Process Execution (InProXec) method [Sungur
et al., 2015a, Sungur et al., 2016] enabling the usage
of the IPE approach in organizations. In Fig. 2, we
recap a formal model including real world entities and
their relationships used in the InProXec method. All
concepts illustrated in Fig. 2 are based on our previous
work [Sungur et al., 2014, Sungur et al., 2015a, Sun-
gur et al., 2015b, Sungur et al., 2016]. We introduced
the concept of relevance relationships in our previ-
ous work [Sungur et al., 2016] but we did not detail
these. In the current work, we present a conceptual
framework generating relevance relationships.
Business processes have three dimensions: what,
who, and which [Leymann and Roller, 2000]. The
dimension “what” denotes activities of business pro-
cesses conducted by actors represented by the dimen-
sion “who”. To conduct activities, actors of business
processes exploit other organizational resources, i.e.,
the dimension “which”. In case of informal processes,
activities are typically not predictable during model-
ing time due to the dominant change in activities at
runtime. Moreover, modeling activities of informal
processes is in many cases more costly than the perfor-
mance increase provided by modeling. Thus, the IPE
approach focuses on modeling and automatically allo-
cating required resources of informal processes, i.e.,
the two dimensions “who” and “which”, to support
actors of processes and to reproduce desired outcomes
of business processes. To model these two dimensions,
business experts include resource definitions required
in informal process models, as illustrated in Fig. 2.
Each resource definition represents an organizational
resource such as human resources, material resources,
information resources, and IT resources. For instance,
a resource definition can represent a human resource
conducting required activities and a Git repository sup-
porting these activities. As shown in Fig. 2, instead
of directly referring to resources required in infor-
mal processes, business experts can model capabil-
ities required in informal processes. Organizational
capabilities represent abilities to perform a produc-
tive task using organizational resources. To guide re-
sources during process enactments towards desired
outcomes, business experts specify intentions of in-
formal processes. Each intention describes desired
outcomes of informal processes, e.g., a Java libraries
that unify access to functionalities of various cloud
service providers is the desired outcome of the moti-
vating scenario. Furthermore, intentions enable track-
ing the progress of informal processes, such as two
intentions completed out of three intentions implying
a certain degree of the progress in an informal process.
Resource definitions, capabilities, and intentions are
stored in informal process models, as illustrated in
Identifying Relevant Resources and Relevant Capabilities of Informal Processes
297

Fig. 2. A simplified example informal process model
of a process aiming at fixing a bug in the motivating
scenario is shown in Fig. 1 with its resource defini-
tions, capabilities, and the target intention. For fur-
ther details about the approach, we refer the readers
to [Sungur et al., 2014]. To enable the application
of the IPE approach in organizations, we presented
the InProXec approach [Sungur et al., 2015b]. In a
previous work [Sungur et al., 2016], we demonstrated
the application of an extended version of the InProXec
approach to identify relevant resources and relevant
capabilities of the motivating scenario. This previous
work focuses on the validation of the extended method
and does not describe the new concepts needed for the
identification of relevant resource and relevant capabil-
ities, which we address in the current work. Next, we
give an overview of the InProXec method with four
phases shown in Fig. 3.
Integrate Resources of Informal Processes (
P
1
).
The first phase of the InProXec method has three ob-
jectives: (i) making resources required visible in mod-
eling environments of informal processes, (ii) enabling
the automated allocation of these resources during in-
formal process model initialization, and (iii) enabling
the generation of recommendations for informal pro-
cesses. We have detailed means of achieving the ob-
jectives (i) and (ii) in our previous work [Sungur et al.,
2015b]. In the current work, we present the means
of achieving the objective (iii) in Section 4.1. The
phase
P
1
is a setup phase involving software devel-
opment activities and must be initially executed be-
fore other phases. The Informal Process Essentials
(IPE) approach focuses on modeling and automatically
allocating actors and supporting resources of actors.
Therefore, modeling environments of informal pro-
cesses need to present business experts available actors
and supporting resources of actors, i.e., resources of
interest. Presenting resources from different resource
domains requires understanding domain-specific re-
source definitions and transforming these into resource
definitions of modeling environments of informal pro-
cesses. To make organizational resources available in
modeling environments of informal processes, tech-
nical experts develop software components called do-
main managers (the first objective of P
1
).
Definition 1
(Domain Manager (DM))
.
Domain man-
agers are software components transforming domain-
specific resource representations into resource defini-
tions of modeling environments of informal processes.
For instance, a domain manager of IT resources
will create resource definitions for a new Git reposi-
tory and for existing ones. After implementing domain
managers, technical experts develop execution envi-
ronment integrators to enable the automated allocation
of resources for intentions of informal processes (the
second objective of P
1
).
Definition 2
(Execution Environment Integrator
(EEI))
.
Execution environment integrators are soft-
ware components capable of executing life-cycle op-
erations such as allocating and releasing resources
during the enactment of an informal process.
During resource allocations, EEIs convert resource
definitions into resource instances containing instance
descriptors. Each resource instance represents a
unique allocated resource. We refer to resource defini-
tions and instances in the following as resources if it
causes no confusion. Resource definitions are a part
of informal process models and are initialized upon
initialization of the models. During initialization of an
informal process model, a software component called
an Informal Process Essentials runtime allocates all
resources using available EEIs.
Definition 3
(Informal Process Essentials (IPE) Run-
time)
.
Informal Process Essentials runtimes are soft-
ware components managing life-cycles of informal pro-
cess instances using available execution environment
integrators for each modeled resources definition.
IPE runtimes correspond to business process ex-
ecution engines of structured processes. We assume
that before applying the InProXec method an IPE run-
time already exists. Initializing an informal process
model successfully results in an informal process in-
stance. Informal process instances contain resource
instances. During enacting informal processes, new
intentions can emerge. These new intentions can be
addressed with an updated set of allocated resource
instances. Thus, the resources represented in infor-
mal process models and instances can vary. A valid
analysis on resources of informal processes should not
only consider resources addressed in informal process
models but, rather, all resources in informal process
instances of the process model. We refer to informal
process models and instances in the following as in-
formal processes as long as no confusion is possible.
To address the third objective of
P
1
, i.e., enabling the
generation of recommendations for informal process,
technical experts develop software components capa-
ble of analyzing interactions of resources participating
in informal processes and deriving recommendations
from these interactions. Informal process recommen-
dations include (i) relevant resources and capabilities
of informal process models and (ii) new informal pro-
cess models containing these identified resources and
capabilities. For this analysis, technical experts de-
velop software components collecting interactions of
resources participating in informal processes. More-
over, they create software components capable of in-
terpreting these interactions and generating informal
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
298
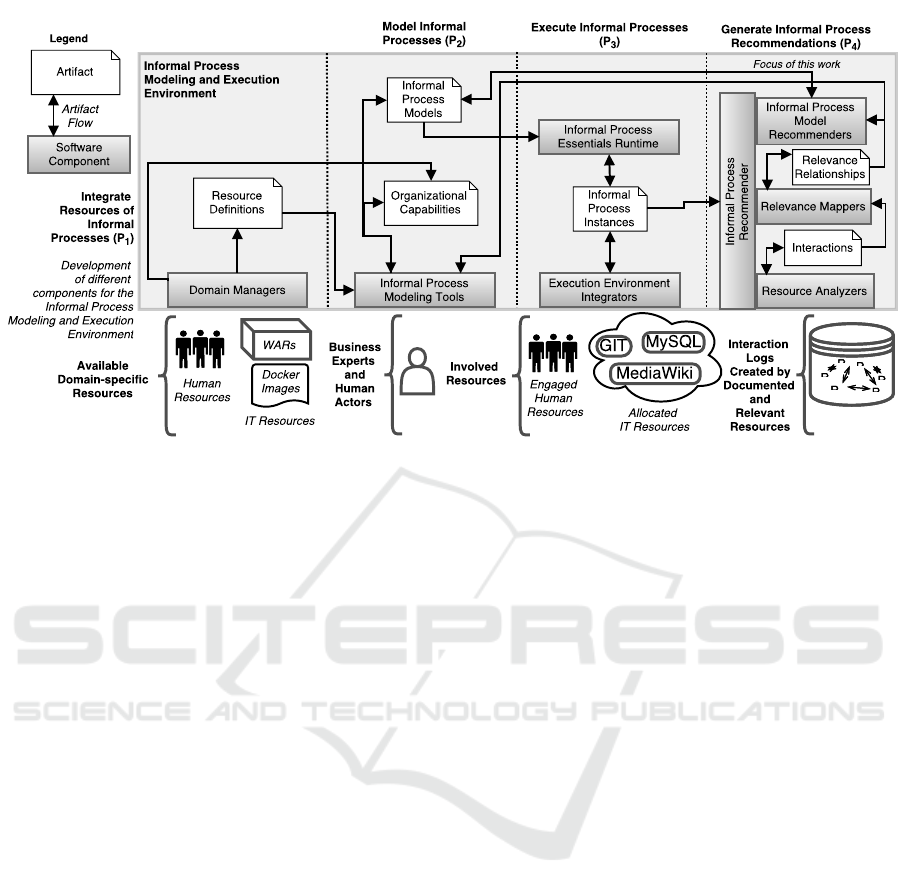
Figure 3: Phases of the InProXec method and its enabling system.
process recommendations. Business experts exploit
these recommendations to model more effective and
efficient informal process models during the phase
P
2
,
as presented in Fig. 3.
Model Informal Processes (
P
2
). The main objec-
tive of this phase is creating informal process models
achieving organizational intentions. For this purpose,
business experts model organizational capabilities pro-
vided by organizational resources, so that they can
add these into informal process models. For instance,
they specify a Java development capability provided
by a set of human resources. Hereafter, they specify
intentions of informal processes such as fixing a bug
in a software library. To specify the means of achiev-
ing these intentions, business experts define informal
process models using the resources integrated in
P
1
.
After creating models, business experts initialize cor-
responding process models as described in P
3
.
Execute Informal Processes (
P
3
). This phase has
the objective of initializing informal process models
and achieving organizational intentions specified in
P
2
. First, business experts select appropriate informal
process models based on the present organizational
context. Upon an initialization request, the IPE run-
time uses EEIs to allocate resources documented in
informal process models. For instance, they send an
invitation for participation to human resources defined
in the respective informal processes. In case they agree
on the participation, they are considered to be allocated.
Another example of a resource allocation is creating
a new Git repository on GitHub for an informal pro-
cess. Allocating all resources specified in an informal
process instance converts the state of the instance into
achieving, i.e., achieving intentions of the respective
informal process. During the state achieving, actors
of informal processes work towards the intentions of
informal processes using other supporting resources
collaboratively. As shown in Fig. 2, collaborations
result in interactions containing information about ac-
tual executions of informal processes. After achieving
intentions of informal processes, actors or business
experts stop informal process instances. Hereafter, the
employed IPE runtime deallocates resource instances
using available EEIs.
Generate Informal Process Recommendations (
P
4
).
The objective of this phase is generating informal
process recommendations from interactions occurring
among resources of informal processes. These recom-
mendations include resources and capabilities possibly
relevant for informal process models and new infor-
mal process models using these relevant resources and
capabilities. The starting point of generating recom-
mendations are the resources instances documented in
informal process instances, as shown in Fig. 3. Thus,
we start by defining “documented resources”.
Definition 4
(Documented Resource)
.
A documented
resource of an informal process model is a resource
instance allocated on purpose for an instance of the
process model during the process initialization or the
process enactment.
In other words, a documented resource is not lim-
ited to the resources represented in informal process
models but, rather, they include all allocated resources
during the course of different process enactments. Doc-
umented resources provide a basis for identifying rel-
evant resources of informal processes. Furthermore,
Identifying Relevant Resources and Relevant Capabilities of Informal Processes
299
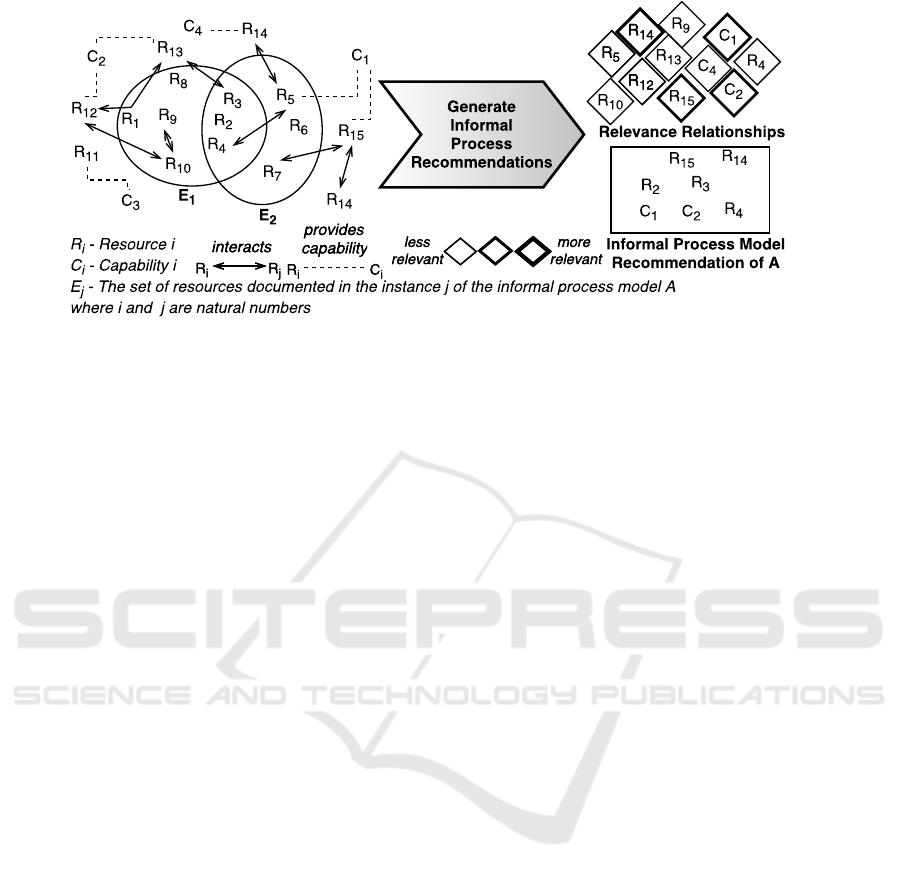
Figure 4: An illustration of generating informal process recommendations.
the definition of relevant resources is built on top of
documented resources:
Definition 5
(Relevant Resource)
.
A relevant resource
of an informal process is a resource instance interact-
ing directly or indirectly with a documented resource.
Indirectly means that there is an interaction path from
a documented resource including other resources until
the relevant resource is interacted with.
In Fig. 4, we present two informal process in-
stances
E
1
and
E
2
. According to the definition of
documented resources, all resources in two circles
are documented resources, i.e.,
R
1
–
R
10
. Moreover,
all resources communicating with these are relevant
resources, such as
R
15
. By communicating with the rel-
evant resource
R
15
, the resource
R
14
becomes relevant.
To define relevant capabilities, we exploit relevant re-
sources, as follows:
Definition 6
(Relevant Capability)
.
A relevant capa-
bility of an informal process is an existing or a derived
capability of a relevant or a documented resource.
In Definition 6 existing capabilities refer to mod-
eled capabilities of resources during
P
2
. For instance,
in Fig. 4,
C
1
is a relevant capability as it is a capa-
bility of both
R
15
and
R
5
. The derived capabilities
are capabilities created using different properties of
resource interactions, such as type and frequency of
an interaction. An example of such a capability is
a coordination capability derived using reviews of a
pull request, which are interpreted as coordination
of pull requests of a software project. To fulfill the
objective of generating informal process recommenda-
tions, relevant resources and relevant capabilities are
needed to be identified. Therefore, during
P
4
, software
components built in
P
1
collect interactions of relevant
resources and, hereafter, interpret these interactions to
assign different degrees of relevance for relevant re-
sources and capabilities. Using these assigned degrees,
software components built in
P
1
create informal pro-
cess model recommendations. Informal process model
recommendations contain relevant resources and capa-
bilities found previously and are based on the original
informal process model. Next, we present a concep-
tual framework (Section 4) for enabling the generation
recommendations for informal processes (Section 4.1)
and generating the recommendations (Section 4.2).
4 CONCEPTUAL FRAMEWORK
FOR GENERATING INFORMAL
PROCESS
RECOMMENDATIONS
In this section, we present key concepts used to gen-
erate informal process recommendations. Interacting
resources build a unweighted bi-directional resource-
interaction graph where resources are nodes of the
graph and interactions are the edges connecting these
nodes, as shown in Fig. 4. The shortest path between
two resources in a graph is the path with the least num-
ber of edges connecting the two resources. In a graph,
the distance between two resources is the number of
edges in the shortest path connecting these. Based on
this distance definition, we define the distance of a
relevant resource as follows:
Definition 7
(Distance of a Relevant Resource)
.
The
distance of a relevant resource to a documented re-
source is the number of edges in the shortest path
connecting these resources.
In Fig. 4, the distance of
R
14
is 2 due to the inter-
actions between
R
7
/R
15
and
R
15
/R
14
. According to
Definition 7, the documented resource used to identify
a relevant resource is the starting point for calculating
the distance of a relevant resource. As shown in Fig. 3,
we initially exploit information available in interac-
tions to identify relevance relationships containing rel-
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
300

evant resources and relevant capabilities. Therefore,
resource interactions over different mediums need to
be investigated, e.g., physical interactions, emails, Git
commits, and Wiki edits. To collect interactions of a
documented resources, we employ resource analyzers:
Definition 8
(Resource Analyzer)
.
Resource analyz-
ers are software components mapping resource in-
stances to a set of interactions of a certain type oc-
curred in a certain time span.
Technical experts create resource analyzers to en-
able the generation of informal process recommenda-
tions, as detailed in Section 4.1. Resource analyzers
are used to collect interactions of documented and
relevant resources recursively, i.e., they collect first
resources in distance 1 and, then, 2 until the given
distance. Moreover, they collect interactions in cer-
tain time spans to limit the collected interactions to
the interactions happened during executions of infor-
mal processes. For instance, a resource analyzer of a
GitHub repository can collect interactions of the last
three months from this repository to identify devel-
opers working on it during execution of a bug fixing
process spanning the previous three months. Hereafter,
each of the developers found can be further investi-
gated with their corresponding resource analyzers to
collecting further interactions resolving in additional
relevant capabilities and relevant resources, such as
additional GitHub repositories. Each interaction col-
lected by resource analyzers contains a relevant re-
source and relevant capabilities of an informal pro-
cess model. To associate these relevant resources and
capabilities with informal process models, relevance
relationships are used.
Definition 9
(Relevance Relationships)
.
A relevance
relationship specifies the degree of relevance of a re-
source or a capability with an informal process model.
A relevance relationship is considered as an asso-
ciation with informal process models, because these
relationships rely on interactions of documented and
relevant resources of informal process models. The
degree of the relevance of a resource or a capability
depends on different factors such as (i) the type, the fre-
quency, and contents of an interaction, (ii) the degree
of relevance of a relevant resource providing a relevant
capability, and (iii) the distance of a relevant resource.
Thus, each relevance relationship contains the degree
of a relevance derived using interactions, i.e., the cor-
relation coefficient of the relevance relationship. A
relevance relationship implies either (i) a positive rele-
vance, (ii) an irrelevance, or (iii) a negative relevance,
that is (i) a positive correlation coefficient, (ii) a zero
correlation coefficient, and (iii) a negative correlation
coefficient, respectively. A positive relevance means
that a resource definition should be included in an in-
formal process model. An irrelevance means that the
considered resource has no impact on the informal
process. In contrast, a negative relevance means, a
resource definition should not be included in a process
model. To generate recommendations for informal
processes (Section 4.2), relevance relationships are
identified. Thus, there is a need for a means of deter-
mining relevance relationships using existing entities
such as interactions or other relevance relationships.
Therefore, we employ relevance mappers:
Definition 10
(Relevance Mapper)
.
Relevance map-
pers are software components enriching a set of rele-
vance relationships using (i) interactions collected by
resource analyzers and (ii) existing relevance relation-
ships identified by other relevance mappers.
For instance, a relevance mapper converts an inter-
action between a Git repository and a developer into
a relevance relationship containing the relevant Git
resource with a positive correlation coefficient. In case
such a relevance relationship is already present, the
relevance mapper updates the correlation coefficient
of the corresponding relevance relationship. Technical
experts build these relevance mappers to enable the
generation of recommendations for informal processes,
as shown in Fig. 3 and detailed in Section 4.1.
To calculate the correlation coefficients of rele-
vance relationships, we created the following require-
ments: A relevance mapper can calculate the correla-
tion coefficient of a relevance relationship using dif-
ferent information sources, such as interaction types,
interaction contents, and identified relevance relation-
ships. For instance, a commit interaction implies a
higher relevance in a development project than an
email interaction (the type of an interaction). More-
over, the number of lines committed is also impor-
tant during the calculation of correlation factors (the
contents of an interaction). Thus, such different in-
formation sources should have effect in the calculated
correlation coefficients (
Rq
1
). Furthermore, different
information sources can imply the relevance or the
irrelevance of the same relevant resource or the same
relevant capability. For instance, multiple commits
made by the same developer will increase the rele-
vance of the respective developer. Thus, the resulting
correlation coefficient of relevant resource or a rele-
vant capability should represent an aggregated value
calculated based on different information sources (
R
2
).
Typically, relevant resources with a larger distance
are less relevant for a specific informal process. For
instance, in an informal process a Git repository is
included. Moreover, this Git repository is updated by a
relevant human resource, who works on another repos-
itory, which is less relevant than the human resource
Identifying Relevant Resources and Relevant Capabilities of Informal Processes
301

used to identify the latter repository. Thus, relevant
resources with a larger distance and their relevant ca-
pabilities should be less relevant (Rq
3
).
Based on these requirements, we designed the func-
tion presented in Eq. (1) within the range of
R
. The
function maps either a relevant resource or a relevant
capability (
rc
) based on the interactions (
I
) and rele-
vance relationships (
R
) to a new correlation coefficient
(
cc(rc,I ∪ R)
). The function iterates through interac-
tions and relevance relationships and relies on other
functions depending on an interaction or a relevance re-
lationship, that are, a relevance factor (
rFactor(rc,ir)
)
and the distance (
d(rc,ir)
) of the relevant capability.
Consequently, the value of the correlation coefficients
depend on interactions and relevance relationships
(
I ∪ R
) of a relevant resource or relevant capability
(rc) given.
cc(rc,I ∪ R) =
∑
ir∈I∪R
rFactor(rc,ir)
d(rc,ir)
(1)
where
cc(rc,I ∪ R) ∈ R
,
rFactor(rc,ir) ∈ R
, and
d(rc,ir) ∈ Z
+
.
To align the variable impact of different types of in-
teractions or relevance relationships used to calculate
a new correlation coefficient, we use the function rel-
evance factor (
rFactor(rc,ir)
). Interestingly, contents
of interactions or relevance relationships can be consid-
ered during the calculation of values of
rFactor(rc,ir)
for each interaction or relevance relationships, too.
As a consequence of considering contents, an interac-
tion or a relevance relationship can map to a relatively
smaller or a larger value. For instance, a relevance
mapper of a GitHub interactions can analyze collected
interactions representing issues in the time span of
an informal process instance. Furthermore, the rele-
vance mapper can map to a higher or a smaller value
based on the contents of issues, such as by doing a
topic analysis and matching these with intentions of an
informal process instance [Li and Yamanishi, 2003].
Consequently, different issues created out of the scope
of an informal process instance are eliminated. Such
interactions typically exist within the interactions con-
taining unstructured text resulting in ambiguous in-
terpretations. In contrast, the meaning of structured
interactions is typically unambiguous and represents
typically a certain productive or unproductive activ-
ity, such as a Git commit interaction. In relevance
relationships, we represent (i) resources conducting
productive and unproductive activities and (ii) capa-
bilities of these resources with different correlation
coefficients. Moreover, based on the sign of a
rFactor
,
the next calculated value of a correlation coefficient is
either higher or lower. To this end, a negative relevance
factor will imply unproductive activities deduced using
certain types of interactions or relevance relationships,
such as spam emails. Thus, the equation satisfies
Rq
1
.
Furthermore, the summation of calculated values for
each different interaction or relevance relationship re-
sults in a correlation coefficient representing different
these. Consequently, the equation fulfills
Rq
2
. More
distanced relevant resources and their capabilities re-
sult in a smaller correlation coefficient and, thus, are
less relevant using the variable (
d(rc,ir)
) in the equa-
tion. Consequently, Rq
3
is satisfied.
In our previous work [Sungur et al., 2016], we
presented a case study validating the conceptual frame-
work presented here using the Apache jclouds project
described in the motivating scenario. Thereby, we used
our implementation of the framework
1
for generating
relevance relationships and new informal process mod-
els based on the relationships. During the generation
of relevance relationships, we validated that the equa-
tion does not depend on the order of interactions given
by making multiple runs on the same interaction sets
with different orderings. Furthermore, recently, we
evaluated the equation presented in Eq. (1) empirically
by comparing the correlation coefficients of the rele-
vance relationships of resources generated in the case
study with a set of correlation coefficients collected in
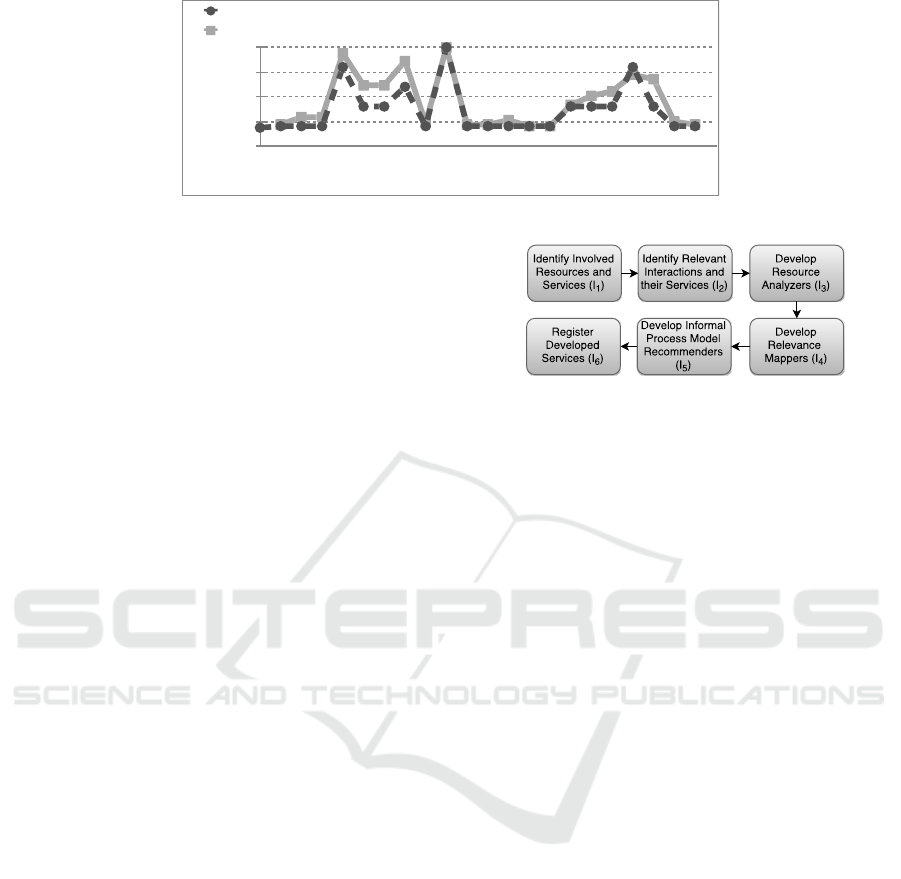
a survey with 13 experienced GitHub users.
The experience of the participants on using GitHub
in our survey varies between 6 months to 72 months
with an average of 34 months. We provided each
participant numbers and types of interactions of 21
resources identified in our case study. For instance,
we presented a GitHub user with 10 commits and 2
pull requests. More specifically, we presented 1069
interactions in 8 different types collected during our
case study distributed to 21 different resources. Fur-
thermore, each expert evaluated each resource with
the same interactions twice to be able to check the
quality of given answers. Based on this list and on the
experience of participants, we asked each participant
to assign an integer value between 1 (not relevant) and
5 (relevant) for each resource listed. Consequently, in
our comparison we had to map from the automatically
generated values onto the scale of 1 to 5, as the actual
value of the positive correlation coefficient is in range
of
R
. Different interpretations of different types of
interactions result in a standard deviation between 0
and 0.19 for the values of different resources assigned
by participants. Moreover, the statistical correlation
coefficient between the automatically generated values
and the average of the user assigned values is 0.93
meaning that the generated results and collected re-
sults have a strong linear positive correlation. Individ-
ually considered, the statistical correlation coefficient
1
https://gitlab.com/timur87/informal-process-
recommender
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
302
cc(rc,ir)
!
"#$%
$#%
&#'%
%
Relevant.Resources
()*+,-./-001234546-*4728-0)492:6+,2*;42/-9429*)712,-<<472*+2*;426-5342="#%>
(846-342+:2*;427-*-2/+004/*472?52-29)6841
Figure 5: Comparison of correlation coefficients derived by experienced GitHub users and generated automatically.
between the generated values and each data set pro-
vided by each participant vary between 0.79 and 0.98.
Furthermore, the root mean square error and mean ab-
solute percentage error values [Armstrong, 1978] are
0.62 and 18%, respectively.
Fig. 5 presents a comparison of the generated val-
ues and the average of the values provided by partic-
ipants. Moreover, the results differ at certain points.
This is firstly because of the assigned relevance fac-
tors (
rFactor(rc,ir)
) representing the increase rate of
correlation coefficient per interaction did not meet the
consensus of the participants, which can resolved by
changing the assigned relevance factors. Secondly, the
results provided by human resources are positive inte-
gers between 1 and 5 resulting in a lower precision. In
contrast, the correlation coefficient generated based on
the conceptual framework is with a higher precision.
Relevance relationships are already recommenda-
tions by themselves through presenting relevant ca-
pabilities and resources and their degree of relevance
during
P
2
. Using relevance relationships, its possible
to create informal process model recommendations,
that is, new informal process models based on relevant
resources and capabilities. For instance, in case a rel-
evance relationship with a correlation coefficient 0.9
between a developer and an informal process model
exists, an informal process model recommendation
contains this relevant resource. As presented in Fig. 3,
to automate generating informal process model recom-
mendations from relevance relationships, we introduce
the concept of informal process model recommenders,
which are developed during
P
1
of our method (Fig. 3).
Definition 11
(Informal Process Model Recom-
mender)
.
An informal process model recommender
generates a new informal process model using rele-
vance relationships.
During
P
2
, generated recommendation models are
presented to business experts. Finally, we introduce the
concept of informal process recommenders orchestrat-
ing resource analyzers, relevance mappers, and infor-
mal process model recommenders to generate informal
process recommendations.
Figure 6: Detailed steps of enabling the generation of
recommendations for informal processes.
Definition 12
(Informal Process Recommender)
.
An
informal process recommender generates informal pro-
cess recommendations, i.e., relevance relationships
and informal process model recommendations, using
resource analyzers, relevance mappers, and informal
process model recommenders.
In the following subsections, we describe necessary
steps for enabling the generation of recommendations
for informal processes (Section 4.1) and generating
recommendations for informal processes (Section 4.2)
using the conceptual framework in organizations.
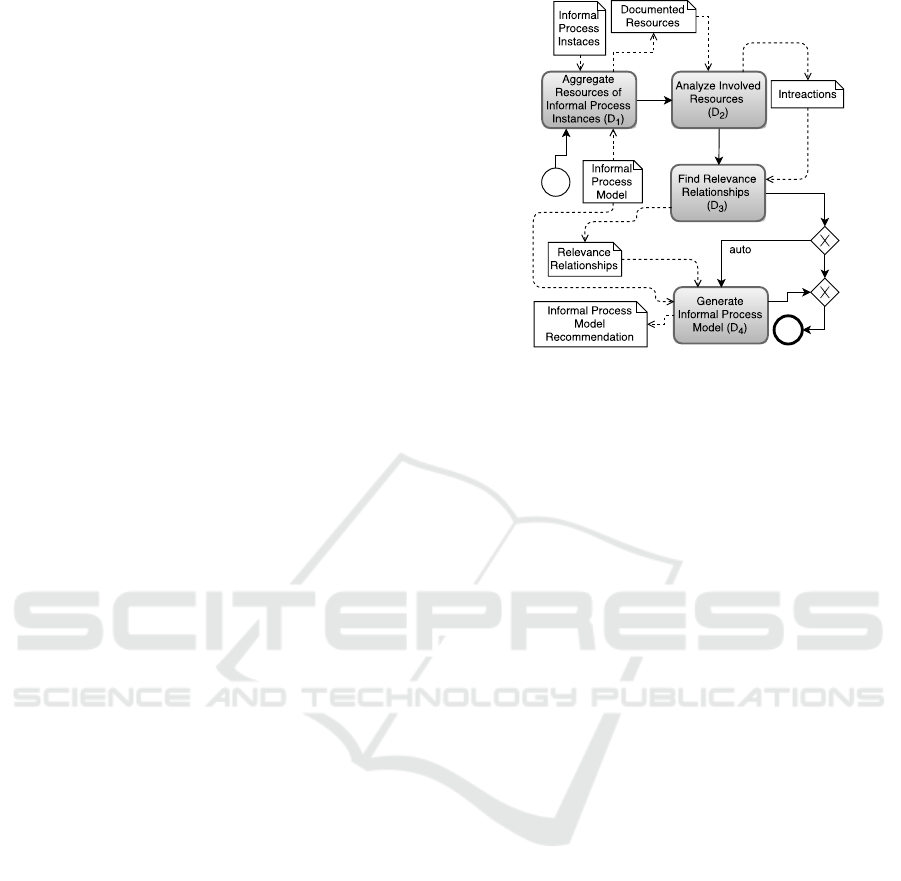
4.1 Enabling the Generation of
Recommendations for Informal
Processes using the Conceptual
Framework
This section presents the additional steps executed in
Fig. 6, i.e.,
I
2
–
I
6
, after executing the existing step
I
1
to achieve the objective of enabling the generation of
recommendations for informal processes of the phase
P
1
of the InProXec method. As organizations are liv-
ing organisms, resources playing a role in informal
processes change continuously. Thus, steps presented
in this section can be executed repeatedly during the
lifetime of an organization to adapt newly emerging
intentions of informal processes. We validated the fol-
lowing steps in the context of a case study presented
in our former work [Sungur et al., 2016].
Identify Involved Resources and Services (
I
1
): At
first, business experts and technical experts identify
possible actors of informal processes and their sup-
porting resources in the context of organizational in-
tentions using their experience on the past and present
Identifying Relevant Resources and Relevant Capabilities of Informal Processes
303
informal processes. They work together, as both or-
ganizational knowledge of business experts and IT
knowledge of technical experts are required. Addi-
tionally, they can make interviews with human actors
of informal processes to identify further resources in-
volved in informal processes, if it is needed.
Identify Relevant Interactions and their Services
(
I
2
): Using the resources determined in
I
1
, technical
experts and business experts identify resource inter-
actions providing information about the relevance of
resources and their capabilities, i.e., relevant inter-
actions, in the context of organizational intentions.
Finding relevant interactions is followed by identify-
ing services capable of delivering these interactions,
e.g., GitHub and MediaWiki services.
Develop Resource Analyzers (
I
3
): To generate rec-
ommendations for informal processes (Section 4.2),
initially, interactions containing documented and rele-
vant resources should be collected. To collect interac-
tions identified previously in
I
2
, technical experts cre-
ate resource analyzers. Resource analyzers use the se-
lected interaction services such as the GitHub service
from
I
2
to collect interactions containing documented
and relevant resources. Moreover, each resource an-
alyzer converts different addressing schemes used in
different kinds of interactions into a system-specific
format of the corresponding execution environment of
informal processes. Each resource analyzer typically
addresses a certain type of resources, such as human
resources, and a certain interaction service, such as
GitHub to assign a single responsibility to each ana-
lyzer.
Develop Relevance Mappers (
I
4
): After having a
mechanism to collect interactions using resource ana-
lyzers, technical experts proceed with developing ser-
vices for interpreting these interactions. Depending on
the selected resources in
I
1
, selected interactions in
I
2
,
and their services, technical experts develop relevance
mappers to generate relevance relationships containing
relevant resources and relevant capabilities.
Develop Informal Process Model Recommenders
(
I
5
): Additionally, to automate creating informal pro-
cess model recommendations, technical experts can
develop informal process model recommenders, which
incorporate relevance relationships to provide im-
proved informal process models containing relevant
resources and capabilities. During this step, techni-
cal experts define a specific threshold value to elim-
inate certain relevant resources and capabilities. For
instance, involving a contributor who made just one
commit, i.e., having a low correlation coefficient, can
be more costly than the value he adds. This threshold
is set for eliminating such cases.
Figure 7: Generating recommendations for informal
processes.
Register Developed Services (
I
6
): After creating
resource analyzers, relevance mappers, and informal
process model recommenders, technical experts regis-
ter these to an informal process recommender (Defini-
tion 12) to enable an automated discovery (
I
6
). Con-
sequently, the infrastructure is ready to generate the
recommendations in P
4
.
4.2 Generating Recommendations for
Informal Processes using the
Conceptual Framework
Generating recommendations for informal processes
happens first after executing the steps described previ-
ously. The steps shown in Fig. 7 are executed by an
informal process recommender automatically during
P
4
of the InProXec method. As resources of the re-
spective informal process may not be accessible after
its finalization, this phase needs to be executed before
finalizing informal process instances. We validated the
presented steps in the context of a case study presented
in our former work [Sungur et al., 2016].
Aggregate Resources of Informal Process Instances
(
D
1
): As shown in Fig. 7, the generation process is
initiated with an informal process model and its corre-
sponding instances. In case multiple informal process
instances are provided as input, a merger component
aggregates all documented resources contained in dif-
ferent process instances. Duplicate resource instances
are eliminated to avoid extra computational effort, that
is collecting the same interactions more than once for
the same resource instance.
Analyze Documented Resources (
D
2
): After the ag-
gregation, the set of documented resources go through
resource analyzers developed during
I
3
to collect the
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
304

relevant interactions identified in
I
2
, such as Git com-
mits and pull requests.
Find Relevance Relationships (
D
3
): After collect-
ing interactions in
D
3
, relevance mappers created in
I
4
derive relevance relationships containing relevant
resources and relevant capabilities. Derived relevance
relationships are passed through relevance mappers
iteratively. Thus, in case relevance mappers deduce a
specific relevance relationship more than once, they
update the correlation coefficient of the relationship.
Generate Informal Process Model (
D
4
): The out-
put of
D
3
is a set of relevance relationships, as pre-
sented in Fig. 7. Afterwards, the business expert can
either decide to stop with identified relevance relation-
ships or to continue with automatic generation of an in-
formal process model recommendation. Informal pro-
cess model recommenders exploit relevance relation-
ships to generate a new informal process model, i.e.,
an informal process model recommendation, based on
a provided informal process model.
In
P
2
, business experts can use either (i) generated
relevant resources and relevant capabilities contained
in relevance relationships or (ii) generated informal
process model recommendations. The first option pro-
vides business experts more flexibility and the second
one has the advantage of causing less effort as it re-
duces the steps to be taken by business experts in
P
2
.
Although informal process model recommendations
may reduce the effort of business experts, they need
to be assessed by business experts before they can be
used. Thus, in both cases business experts evaluate
generated recommendations.
5 RELATED WORK
The approach presented has commonalities with Ex-
pert Finding Systems (EFS) [Schall, 2009,Balog et al.,
2006], as EFSs typically address finding the right peo-
ple for certain topics. In the context of our work, the
concept of resource differs and is not restricted to hu-
man resources, i.e., experts. Thus, our approach does
not only recommend experts but also other support-
ing relevant resources, e.g., a specific Wiki resource.
Begel et al. [Begel et al., 2010] present a framework
called Codebook creating a graph of interrelated re-
sources using interactions of people, work items, files,
and source code. Although Codebook is capable of
finding different type of interrelated relevant resources,
the framework does not address the degree of resource
relevance and relevant capabilities. Dorn et al. [Dorn
et al., 2011] proposed a skill-dependent recommenda-
tion model for finding experts with a better connectiv-
ity and matching skills. In this work, we also rely on
interactions between resources to make recommenda-
tions. However, we do not specify how the correlation
among resources are calculated, but rather we leave
that as an extension point depending on the context
of the problem and specific resource interactions. As
future work, we will exploit existing research in these
area, such the work of Dorn et al. [Dorn et al., 2011]
and the work of Campbell et al. [Campbell et al., 2003],
to improve relevance mappings.
The method presented makes no assumptions on
the existence of reusable structured activities or a busi-
ness process execution engine executing these activi-
ties defined in an automated fashion. In case structured
activities and a business process engine are present in
the environment, business process mining approaches
can be exploited to improve business process execu-
tions [van der Aalst, 2016]. Different approaches
provide recommendations for future resource alloca-
tions of business processes using event logs of pro-
cess executions [Arias et al., 2016,van der Aalst and
Song, 2004, Yang et al., 2012]. These approaches fo-
cus on interactions between allocated resources and
business process execution engines. In contrast, our
approach focuses on every meaningful resource inter-
action including interactions with business process exe-
cution engines. Our approach provides no replacement
for such activity-oriented approaches, but it stands
rather complementary. Dorn and Dustdar [2011] pre-
sented an activity recommendation system relying on
message-exchanges for unstructured processes. Fur-
thermore, Folino et al. [Folino et al., 2014,Folino et al.,
2015b, Folino et al., 2015a] present means of identify-
ing activities of informal processes using a clustering
based discovery approach on event logs.
Vasconcelos et al. [Vasconcelos et al., 2001]
present necessary elements and their relationships to
model organizational goals, resources, processes, and
their associations. However, their work does not aim
at improving these processes but enables traceability
between goals, processes, and resources. Adaptive
Case Management [Herrmann and Kurz, 2011] and
Case Handling [van der Aalst et al., 2005] offer the
notion of case to avoid context tunneling and rigid ac-
tivity structures. During the execution of a case, actors
can collect relevant information in a case and reuse
this information in the future. Using the case data, the
documented information and actors can be captured.
In contrast, the concept of resource in our approach is
more generic enabling the identification of any kind of
relevant resources.
Identifying Relevant Resources and Relevant Capabilities of Informal Processes
305

6 CONCLUSION AND OUTLOOK
In this work, we presented a conceptual framework for
identifying resources and capabilities that may be rele-
vant for future executions of business processes. Iden-
tified resources and capabilities are associated with
values representing their degree of relevance to busi-
ness processes. To evaluate our approach, we con-
ducted a survey and compared the collected data in the
survey with the automatically generated results. More-
over, we presented steps for enabling the generation
of recommendations for informal processes and neces-
sary steps involved during the automated generation
of recommended resources and capabilities.
In the future, we will investigate further empirical
evaluation methods for the system presented, such as
the application of recall and precision metrics from
the field of information retrieval. Moreover, we will
develop additional interaction interpreters based on
existing approaches, such as expert finding systems.
We will additionally present the implementation of new
types of resources that are allocated during enactments
of business processes in an ad-hoc fashion based on
emerging requirements of human actors.
ACKNOWLEDGMENTS
This work has been partially supported by Graduate
School of Excellence advanced Manufacturing Engi-
neering (GSaME), DFG Cluster of Excellence in Sim-
ulation Technology (EXC 310/2), and SmartOrchestra
(Research Grant 01MD16001F, BMWi).
REFERENCES
Arias, M. et al. (2016). A framework for recommending
resource allocation based on process mining. In BPM
2015, number 256 in LNBIP. Springer.
Armstrong, J. S. (1978). Long-range Forecasting: From
Crystal Ball to Computer. John Wiley & Sons Inc.
Balog, K., Azzopardi, L., and de Rijke, M. (2006). Formal
models for expert finding in enterprise corpora. In
SIGIR ’06, pages 43–50. ACM.
Begel, A., Khoo, Y. P., and Zimmermann, T. (2010). Code-
book: discovering and exploiting relationships in soft-
ware repositories. In ICSE ’10, volume 1, pages 125–
134. ACM.
Campbell, C. S., Maglio, P. P., Cozzi, A., and Dom, B.
(2003). Expertise identification using email communi-
cations. In CIKM ’03, pages 528–531. ACM.
Di Ciccio, C., Marrella, A., and Russo, A. (2015).
Knowledge-intensive processes: Characteristics, re-
quirements and analysis of contemporary approaches.
JoDS, 4(1):29–57.
Dorn, C. and Dustdar, S. (2011). Supporting dynamic,
people-driven processes through self-learning of mes-
sage flows. In CAiSE 2011, volume 6741 of LNCS,
pages 657–671. Springer.
Dorn, C., Skopik, F., Schall, D., and Dustdar, S. (2011).
Interaction mining and skill-dependent recommenda-
tions for multi-objective team composition. DKE,
70(10):866 – 891.
Dustdar, S. (2004). Caramba—a process-aware collaboration
system supporting ad hoc and collaborative processes
in virtual teams. DPD, 15(1):45–66.
Etzioni, A. (1964). Modern Organizations. Prentice Hall.
Folino, F., Guarascio, M., and Pontieri, L. (2014). Mining
predictive process models out of low-level multidimen-
sional logs. In CAiSE 2014, pages 533–547. Springer.
Folino, F., Guarascio, M., and Pontieri, L. (2015a). Min-
ing multi-variant process models from low-level logs.
In BIS 2015, volume 208 of LNBIP, pages 165–177.
Springer.
Folino, F., Guarascio, M., and Pontieri, L. (2015b). On the
discovery of explainable and accurate behavioral mod-
els for complex lowly-structured business processes.
In ICEIS 2015, pages 206–217. SCITEPRESS.
Herrmann, C. and Kurz, M. (2011). Adaptive case manage-
ment: Supporting knowledge intensive processes with
it systems. In S-BPM ONE 2011, volume 213 of CCIS,
pages 80–97. Springer.
Leymann, F. and Roller, D. (2000). Production Workflow:
Concepts and Techniques. Prentice Hall PTR.
Li, H. and Yamanishi, K. (2003). Topic analysis using a
finite mixture model. IPM, 39(4):521 – 541.
Moody, P., Gruen, D., Muller, M., Tang, J., and Moran, T.
(2006). Business activity patterns: A new model for
collaborative business applications. IBMSJ, 45(4):683–
694.
Schall, D. (2009). Human Interactions in Mixed Systems -
Architecture, Protocols, and Algorithms. PhD thesis,
TU Wien.
Sungur, C., Dorn, C., Dustdar, S., and Leymann, F. (2015a).
Transforming collaboration structures into deployable
informal processes. In ICWE 2015, volume 9114 of
LNCS, pages 231–250. Springer.
Sungur, C. T., Binz, T., Breitenb
¨
ucher, U., and Leymann, F.
(2014). Informal Process Essentials. In EDOC 2014,
pages 200–209. IEEE.
Sungur, C. T., Breitenb
¨
ucher, U., Leymann, F., and Wet-
tinger, J. (2015b). Executing informal processes. In
iiWAS ’15, pages 54:1–54:10. ACM.
Sungur, C. T. et al. (2016). Identifying relevant resources and
relevant capabilities of collaborations - a case study. In
EDOCW 2016, pages 1–4. IEEE.
van der Aalst, W. (2016). Process Mining: Data Science in
Action. Springer.
van der Aalst, W., Pesic, M., and Schonenberg, H. (2009).
Declarative workflows: Balancing between flexibility
and support. CSRD, 23(2):99–113.
van der Aalst, W. and Song, M. (2004). Mining social
networks: Uncovering interaction patterns in business
processes. In BPM 2004, volume 3080 of LNCS, pages
244–260. Springer.
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
306

van der Aalst, W., Weske, M., and Gr
¨
unbauer, D. (2005).
Case handling: a new paradigm for business process
support. DKE, 53(2):129 – 162.
Vasconcelos, A. et al. (2001). A framework for modeling
strategy, business processes and information systems.
In EDOC 2001, pages 69–80.
Weske, M. (2010). Business Process Management: Concepts,
Languages, Architectures. Springer.
Yang, H., Wen, L., Liu, Y., and Wang, J. (2012). An approach
to recommend resources for business processes. In
OTM 2012, volume 7567 of LNCS, pages 662–665.
Springer.
Identifying Relevant Resources and Relevant Capabilities of Informal Processes
307
