
Frame Selection for Text-independent Speaker Recognition
Abedenebi Rouigueb, Malek Nadil and Abderrahmane Tikourt
Applied Mathematics Laboratory, Ecole Militaire Polytechnique, Algiers, Algeria
Keywords:
Frame Selection, Frame Pruning, Speaker Identification, Speaker Recognition, Text-independent.
Abstract:
In this paper, we propose a set of criteria for the selection of the most relevant frames in order to improve
text-independent speaker automatic recognition (TISAR) task. The selection is carried out on the short term
Cepstral feature vectors such as PLP and MFCC and performed at the front end processing level. The proposed
criteria mainly attempt to select vectors lying far from the universal background model (UBM). Experiments
are conducted on the MOBIO database and show that the selection allows an improvement in complexity (time
and space) and in speaker identification rate, which is appropriate for real-time TISAR systems.
1 INTRODUCTION
Text-independent automatic speaker recognition
(TIASR) task consists in verifying or in identifying
the speaker identity using a segment of his speech
where the utterance content is free (Beigi, 2011; Kin-
nunen and Li, 2010). Although a wealth of research
works has addressed this problem throughout the last
40 years, it is still a challenging problem with many
potential applications.
Cepstral short-term features extracted from short
time frames of about 20-30 milliseconds in duration,
such as Mel frequency cepstral coefficients (MFCC)
and perceptual linear prediction (PLP) coefficients
(Kinnunen and Li, 2010), are widely used in TIASR
systems. This choice is in part justified by the non-
stationary nature of voice and the free speech as-
sumption. The order between the feature vectors (e.g
MFCC) is usually not utilized; the TIASR is merely
treated as a recognition problem of a set, and not a se-
quence, of the acoustic vectors coming from the test
utterance.
In typical TIASR systems, voice activity detection
(VAD) (Benyassine et al., 1997) is first applied for re-
moving non-speech frames. Unfortunately, due to the
high variability and the non deterministic nature of
noise, VAD cannot be perfectly achieved in all cases.
VAD is more critical for non-stationarynoise environ-
ments. Hence, some signal segments corresponding
to noise and not to speech might be left. For further
details about the challenges facing VAD techniques,
refer to (Ramrez et al., 2004). Moreover, the noise
cannot be completely filtered from the speech signal,
either because the signal is too much altered or be-
cause the noise type is unknown. For useful discus-
sions, see (Loizou, 2013).
In the TIASR context, different phonemes can be
pronounced within a given utterance where each one
produces about 5-10 Cepstral vectors. It has been
shown that nasal consonants and vowels are more
speaker-discriminative than the other phonemes like
stops. Indeed, the speaker discrimination quality de-
pends closely on the phonetic content. A quantitative
assessment of phoneme groups for speaker recogni-
tion is given in (Eatock and Mason, 1994).
To recap, acoustic vectors resulting from i) non-
speech segments, due to VAD failure; ii) severely
corrupted speech segments; or iii) less-discriminative
phonemes, are less relevant than those extracted from
enhanced speech frames of discriminative phoneme
group.
In light of the above-mentioned considerations,
the TIASR task can be perceived as a classification
problem of the acoustic vectors set resulting from the
test utterance where they are involved with different
degrees in the final decision.
In this paper, we aim at proposing selection meth-
ods of the most speaker discriminative acoustic vec-
tors (frames). It is obvious that front-end frame se-
lection leads to a significant reduction of the spatio-
temporal complexity since the recognition process is
achieved based only on a small subset of vectors. Our
concern is focused here on the assessment of the influ-
ence of the amount of the selected data on the speaker
Rouigueb, A., Nadil, M. and Tikourt, A.
Frame Selection for Text-independent Speaker Recognition.
DOI: 10.5220/0006392100510057
In Proceedings of the 14th International Joint Conference on e-Business and Telecommunications (ICETE 2017) - Volume 5: SIGMAP, pages 51-57
ISBN: 978-989-758-260-8
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
51

recognition accuracy using several criteria. The per-
formance is measured in terms of the selection task
time and the speaker identification rate in relation to
the percentage of the selected data.
The remainder of this paper is organized as fol-
lows. Section 2 presents related works and Section 3
discusses the utility of frame selection in TISAR sys-
tems. Section 4 shows the importance of the univer-
sal backgroundmodel in the state-of-the-artof TIASR
models. In Section 5 we present the proposed criteria,
experimentations and results are discussed in Section
6. We highlight the improvements done in relation to
our prior works in Section 7. Finally, conclusions and
future directions are given in Section 8.
2 RELATED WORKS
In TISAR systems, a test utterance signal is split into
a sequence of short-time frames and a features vector
is extracted from each frame. Data reduction is often
performed; it may be achieved by two complemen-
tary approaches: feature selection or vector (frame)
selection. A large number of works have addressed
the frame selection problem (also referred to as frame
pruning). For instance, silence frame removal and
VAD are usually applied at an early stage to remove
a part of irrelevant frames. In addition to the spatio-
temporal complexity reduction, an interesting frame
pruning technique must not compromise the recog-
nition performance. Beyond to silence removal and
VAD pruning, we present in this section some inter-
esting works found in the literature that have treated
the frame pruning problem using different criteria.
A test utterance is divided into multiple frames
(Besacier and Bonastre, 1998a) or multiple time-
frequency blocks (Besacier and Bonastre, 1998b) and
the final identification score is computed with a lim-
ited number of the obtained frames (blocks). A dis-
criminant function, estimated for each speaker, is
used to remove frames (or blocks) having a low log
likelihood ratio score of the speaker model against the
speakers’ background model. Authors have reported
that using only a 30% frame pruning can increase
significantly the identification rate where the exper-
iments are conducted on the TIMIT and NTIMIT cor-
pora.
In (Kinnunen et al., 2006), the number of vectors
of the utterance test is reduced by silence removable
and pre-quantization (PQ) in order to speed up the
identification process. Pre-quantization aims to keep
a subset of vectors using different PQ techniques as
random sub-sampling, averaging and decimation, see
(Kinnunen et al., 2006) for more details. McLaughlin
et al. have shown that the application of three sim-
ple PQ methods, prior to GMM (Gaussian Mixture
Model) matching, allows to compressing the test se-
quence by a factor of 20:1 without compromising the
verification accuracy (McLaughlin et al., 1999).
Recently, Almaadeed et al. have proposed a real-
time text-independent speaker identification system
where the consonant frames are filtered out and the
identification is based on the formants extracted from
vowels (Almaadeed et al., 2016).
3 FRAME SELECTION FOR
TISAR SYSTEMS
If we make a deep analysis of the most popular ac-
curate TIASR paradigms: ranging from the GMM-
UBM baseline (Reynolds et al., 2000) to the state-
of-the-art of the speaker verification I-vector con-
cept (Dehak et al., 2011) via the GMM supervector
(Campbell et al., 2006) and the joint factor analysis,
one can conclude that:
1. All these models make use of short term acous-
tic vector,particularly MFCC, where the utterance
vectors are seen as a set;
2. Some regions in the feature MFCC space are pe-
nalized more than others. For instance, in the
GMM-UBM baseline system, MFCC vectors with
a high density within the UBM class are disad-
vantaged in the likelihood decision ratio detector
(Reynolds et al., 2000). In the I-vector paradigm,
a GMM supervector, M, is first extracted using
the Bayesian MAP adaptation (Campbell et al.,
2006). Then, an I-vector of low dimension, w,
is computed such that M = m+ Tw where T is a
N × P rectangular mapping matrix and m is the
GMM supervectors mean. There is an alignment
between the entries of M and the mixture com-
ponents centers of the GMM-UBM model. The
significant dimension reduction (N << P) is fea-
sible because several entries of the vector M − m
are either zeros, or correlated.
So MFCC vectors with a high likelihood within
the GMM-UBM componentscorrespondingto the
less-discriminative entries of M are penalized in
the decision function.
The frame selection can be interesting for TIASR
systems when the utterances duration is not very
short. In such situation, we need efficient algorithms
requiring low complexity in time and in memory
space. For example, TIASR running on smartphones
may be a typical case of use.
SIGMAP 2017 - 14th International Conference on Signal Processing and Multimedia Applications
52

From a geometric point of view, the feature MFCC
regions don’t hold the same quantity of the speaker-
dependent information. ALL accurate TIASR sys-
tems based on MFCC attempt, either in an explicit
or an implicit way, to determine the importance of
MFCC vectors according to their location. There-
fore, for an absolute research purpose, proposing new
selection criteria can be useful in order to develop
new features and models by the segmentation of the
MFCC space into regions according to their rele-
vance.
4 UNIVERSAL BACKGROUND
MODEL UTILITY
The concept of the universal background model is
successfully used in (Reynolds et al., 2000), in which
the verification task is seen as a test between the hy-
pothesis H0: X is uttered by the claimed speaker
against the alternative hypothesis H1: X is uttered by
an impostor. A GMM, commonly referred as GMM-
UBM model, is trained from a collection of data from
a large number of expected speakers and it is used to
fit the UBM density distribution. Few years later, the
GMM-UBM model has been very successful when
used in representing the speaker-independent infor-
mation rather than the alternative hypothesis H1. The
key idea consists in mapping a given utterance to a
fixed-size GMM supervector.
The GMM-supervector of an utterance is derived
via the MAP adaptation of the GMM-UBM distribu-
tion (Campbell et al., 2006). It has been shown that
the best overall performance is from adapting only the
mixture components means (centers) (Reynolds et al.,
2000) compared to weights and covariance matrices.
First, a GMM λ fitting the distribution of the utterance
MFCC vectors is estimated via the MAP adaptation.
Then, a GMM-supervectoris obtained by the concate-
nation of the mixture componentsmeans of λ. Indeed,
a GMM-supervector defines the overall location of the
components of λ in relation to the GMM-UBM refer-
ence model.
A GMM-supervector, M, is decomposed into two
components as follows M = m + Tw in the i-vector
model case. m itself is a GMM-supervector cor-
responding to the UBM class; it is discarded in
the recognition process since it represents speaker-
independent information.
GMM-UBM is used to make a mapping of an ut-
terance X to a supervector such as GMM supervector,
JFA factors, or i-vector. The location of the MFCC
vectors of an utterance in relation to the UBM is so
important in these new models. It is worth recalling
that the angle between two supervectors is a relevant
feature; many scoring functions are based on the co-
sine kernel (Dehak et al., 2011)
In this paper, we put forward the proposals
that high density regions in the UBM class con-
tain often MFCC vectors coming from several speak-
ers. Hence, these regions are less discrimina-
tive since they tend to model common information
as: non-speech segments, noisy speech, and non-
discriminative phonemes. In this sense, we suggest to
propose selection criteria by adopting the second in-
terpretation which consists in using UBM to estimate
the importance of MFCC regions.
5 PROPOSED CRITERIA
Let X = {x
1
,...,x
N
} be a set of N acoustic vectors ex-
tracted from a given utterance U, where each x
i
is a
D-dimensional cepstral vector (e.g MFCC, PLP ). For
the sake of simplicity, we propose to select a percent-
age of the vectors of X that maximize the proposed
criteria because they have not the same duration in
general. The proposed criteria are as follows.
1. Standard deviation (C
1
)
For a feature vector x= (x
1
,...,x
D
)
T
,C
1
measures
the dispersion of the different entries of x , it is
calculated as follows:
C
1
(x) =
s
1
D
D
∑
i=1
(x
i
−
x)
2
, (1)
where
x is the mean value of x entries (x =
Σ
D
i=1
x
i
/D).
2. Euclidean distance (C
2
)
C
2
measures the Euclidean distance between the
vector of interest xand the center of UBM, µ.
C
2
(x) = kx,µk =
q
Σ
D
i=1
(x
i
− µ
i
)
2
(2)
3. Probabilistic distance (C
3
)
A GMM, λ
ubm
, with K mixture components is
trained to approximate the UBM distribution.
C
3
(x) is inversely proportional to the likelihood
of UBM. We suggest:
C
3
(x) = −P
λ
ubm
(x) (3)
We have experimented the variants C
(1)
3
, C
(4)
3
,
C
(32)
3
, C
(64)
3
, C
(128)
3
, C
(256)
3
by setting K to 1, 4, 32,
64, 128, and 256, respectively, in λ
ubm
.
Frame Selection for Text-independent Speaker Recognition
53
4. Probabilistic distance with component selection
(C
4
)
The time cost of the evaluation of C
3
linearly in-
creases with the number of components in λ
ubm
,
K, because we need to compute the density of x
in each one of them.
Each component of λ
ubm
corresponds to a specific
sound or phoneme group. Obviously, some com-
ponents better describe speaker-dependent infor-
mation than others. C
4
constitutes an improve-
ment of C
3
, where the key idea consists in com-
posing a new GMM, λ
′
ubm
, only from the less-
discriminative components of λ
ubm
. Hence, we
gain in selection speed and possibly in accuracy.
Let λ
ubm
= {w
i
,m
i
,Σ
i
}
i=1..K
be a K-component
GMM-UBM which is estimated from the speech
of S speakers. First, we compute a confusion ma-
trix H where each cell H(s,k) represents the por-
tion of the likelihood of s which is expressed by
the component k. Formally, we have:
H(s,k) =
w
k
P(N(m
k
,Σ
k
);Xs)
∑
K
i=1
w
i
P(N(m
i
,Σ
i
);Xs)
, (4)
Xs is the data of speaker s. The sum of each row
of H is equal to 1. The standard deviation of the
column of index k measures the variability of the
component k. Low standard deviation means that
the speakers’ likelihood values are close to each
other and that the component k is consequently
less-discriminative.
In experiments, we have built λ
′
ubm
from a quar-
ter of the less-discriminative components of λ
ubm
.
We have experimented the variants C
(4)
4
, C
(32)
4
,
C
(64)
4
, C
(128)
4
by setting K to 4, 32, 64, 128, re-
spectively. For example, in C
(32)
4
, λ
′
ubm
contains
only the 08 less-discriminative components of the
32 components forming λ
ubm
. Thus, we suggest:
C
4
(x) = −P
λ
′
ubm
(x) (5)
6 EXPERIMENTS
6.1 Dataset
All of the results we report are on the MOBIO
database (McCool et al., 2012). Following the same
spirit as the NIST SRE, the Biometric Group at the
Idiap Research Institute organized the evaluation on
text-independent speaker recognition.
MOBIO is a bimodal (audio and video) database
recorded from 152 persons, 100 males and 52 females
with both native and non-nativeEnglish speakers. For
each individual, 12 sessions were captured where 192
utterances are recorded by mobile phone (NOKIA
N93i). MOBIO is a challenging database since the
data is acquired on mobile devices possibly with real
noise, and the speech segments can be very short (less
than 02 sec ). The average speech duration of MO-
BIO phrases is around 08 sec. MOBIO is designed
so that it contains realistic and common environmen-
tal variations associated with the usage of mobile de-
vices. More details on this dataset could be found in
(Khoury et al., 2013).
6.2 Methodology
We propose to evaluate the performance of the pro-
posed criteria inside a speaker identification system.
It is clear that useful information for the speaker iden-
tification task, is also useful for the speaker verifica-
tion task and vice-versa.
The vectors selection module is integrated in the
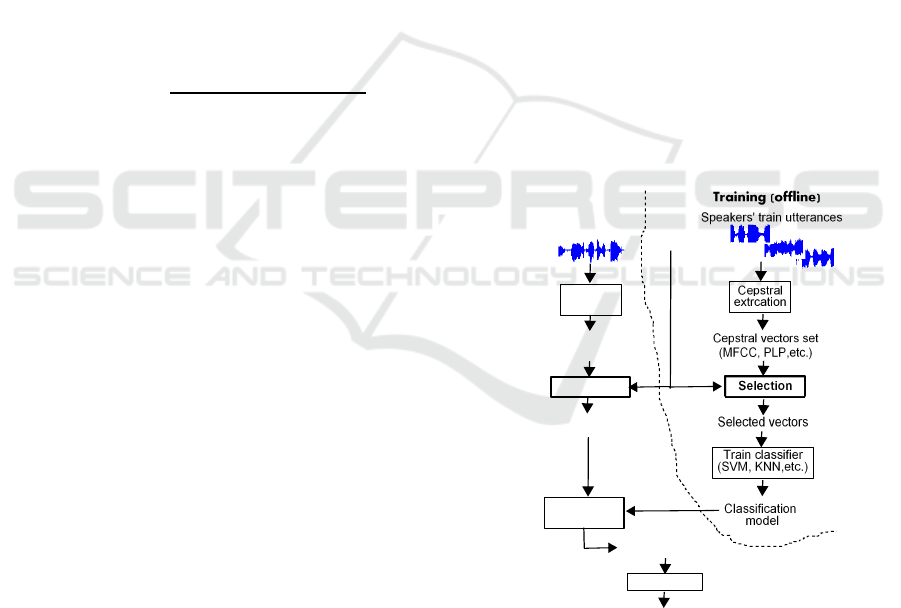
identification system as illustrated in Figure 1. A per-
centage of cepstral vectors of each training or test ut-
terance that maximize the selection criterion are used
for identification. The selection module may use the
parameters of the GMM-UBM model.
Cepstral
extrcation
Train classifier
(SVM, KNN,etc.)
Cepstral vectors set
(MFCC, PLP,etc.)
Selected vectors
Cepstral vectors set
(MFCC, PLP,etc.)
Selected vectors
Selection
Classification
model
Vectors
classification
Majority vote
Decision
U is uttered by S
Vectors classes
UBM GMM
Test utterance,U
Speakers' train utterances
Cepstral
extrcation
Training (offline)
Testing (online)
Selection
Figure 1: Cepstral data selection for speaker identification.
The objective of the experimentation is to study the
identification performance as function of the follow-
ing parameters.
1. The percentage of selected data, θ ∈ [1,..,100];
2. The selection criterion,C ∈ {C
1
,C
2
, variants ofC
3
and C
4
}
SIGMAP 2017 - 14th International Conference on Signal Processing and Multimedia Applications
54

3. The classifier used, Cl ∈ { SVM , KNN }.
For a given combination (θ, C, and Cl), an iden-
tification experiment is carried out using 20 speakers
where 10 and 30 utterances are used in test and train-
ing (resp.) for each speaker. Speakers and utterances
involved in experiments are drawn randomly from the
whole MOBIO corpus. Then, the following perfor-
mance measures are computed:
• The identification rate :
τ =
number o f correct identification trials
number o f alltrials = 20∗ 30 = 600
;
• The time required for vectors selection of the test
utterances, T
sel
;
• The time required for vectors classification of the
test utterances, T
cl
.
6.3 Experimental Results & Discussions
In this section, we present experiments and results ob-
tained in order to observe the influence of the selec-
tion parameters over the identification performance.
Each identification experiment is conducted as shown
in subsection 6.2.
The first set of experiments examine the variation
of the identification rate, τ, as function of the selection
criterion, C, and percentage, θ. Used features consist
of 19 MFCCs acoustic vector, computed with a frame
shift of 10 ms and a frame size of 25 ms. The identifi-
cation rate curves when SVM (resp. KNN) is applied
are depicted in Figure 2 (resp. 3).
θ : data percentage
0 10 20 30 40 50 60 70 80 90 100
τ : identification rate
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
c
1
c
2
c
3
1
c
3
32
c
3
128
c
3
256
c
4
4
c
4
32
c
4
64
c
4
128
Figure 2: Accuracy as function of criteria and data percent-
age using SVM classifier.
While the difference between criteria in terms of τ
for both figures is not large, C
4
variants performed
slightly better than the rest. This seems logical since
C
4
attempts to keep only vectors having low likeli-
hood in the less-discriminative mixture components
of the GMM-UBM model.
The high rates obtained by C
2
and C
1
3
are surpris-
ing and prove that the GMM-UBM distribution has
roughly a hyper-spherical form which is much dense
around the center.
θ : data percentage
0 10 20 30 40 50 60 70 80 90 100
τ : identification rate
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
c
1
c
2
c
3
1
c
3
32
c
3
128
c
3
256
c
4
4
c
4
32
c
4
64
c
4
128
Figure 3: Accuracy as function of criteria and data percent-
age using KNN classifier.
θ data percentage
0 10 20 30 40 50 60 70 80 90 100
Classification time (sec)
0
1000
2000
3000
4000
5000
6000
7000
8000
c
1
c
2
c
3
1
c
3
32
c
3
128
c
3
256
c
4
4
c
4
32
c
4
64
c
4
128
Figure 4: Classification time, T
cl
,as function of data per-
centage, θ.
θ data percentage
0 10 20 30 40 50 60 70 80 90 100
Selection time (sec)
0
5
10
15
20
25
30
c
1
c
2
c
3
1
c
3
32
c
3
128
c
3
256
c
4
4
c
4
32
c
4
64
c
4
128
Figure 5: Selection time, T
sel
,as function of data percentage,
θ.
When examining the variations of τ of all criteria in
both figures 2 and 3, one can clearly see three distinct
regions of θ, as follows:
a) θ ∈ [0% − 5%]: the identification rates obtained
are too poor because the selected data are not suf-
ficient in amount for the recognition task;
b) θ ∈ [5%− 25%]: the highest rates are achieved in
this interval;
c) θ ∈ [25%−100%]: a continuous deterioration of τ
is seen by the increasing of θ value. Acoustic vec-
tors minimizing the proposed criteria don’t hold
enough of speaker-dependent information, their
incorporation in the recognition task leads to a de-
creasing in performance.
In Figure 4, we show the classification time (for
Frame Selection for Text-independent Speaker Recognition
55

600 identification test trials) using SVM. The time
curves are quite identical for all criteria and seem to
have a quadratic augmentation. Indeed, the classifica-
tion time depends mainly on the data percentage, θ.
In Figure 5, we show the selection time. As expected,
the fastest criteria are C
1
, C
2
, C
1
3
, C
1
4
because few op-
erations are needed to evaluate them. The test time in-
cludes principally selection and classification. There-
fore, for a global comparison, C
2
,C
1
3
,C
1
4
, represent a
good trade-off between accuracy and complexity. We
deduce that taking θ in [10% 25%] is interesting in the
MOBIO corpus case.
Table 1: Best identification rates using PLP, MFCC+∆ fea-
tures.
PLP MFCC+∆
SVM KNN SVM KNN
τ 0.9550 0.8900 0.9775 0.8550
C
∗
,θ
∗
C
1
3
,3% C
1
3
,3% C
256
4
,18% C
256
3
,15%
Table 2: The influence of the intersession variability.(C =
C
1
3
, classifier=SVM).
sessions τ
∗
,θ
∗
sessions τ
∗
,θ
∗
1 0.990, 07% 7 0.990, 10%
2 0.990, 20% 8 0.990, 07%
3 0.995, 04% 9 1.000, 04%
4 0.990, 12% 10 0.990, 10%
5 1.000, 07% 11 1.000, 16%
6 0.990, 14% 12 1.000, 07%
all(1-12) 0.95, 16%
The same set of experiments is achieved on the PLP,
MFCC+delta features. We have noticed the same be-
havior for both cases where the best results are ob-
tained by setting θ ≤ 20%, see Table 1.
The last set of experiments aims to explore the in-
fluence of selection towards the session differences.
The intersession variability is well-known to be a
hard problem; several works focused on this chal-
lenge could be found in the literature.
We recall that 12 different sessions are recorded
for each person in MOBIO. We can notice in Table
2 that τ, when it is computed for each session sepa-
rately (training and test utterances coming from the
same session), is almost equal to 1, this corresponds
to the first 12 cases. On the other hand, τ of the ’all
sessions’ case (majority of utterances come from dif-
ferent sessions) is significantly low, see the last line in
Table 2. This observation proves that after achieving
data selection, the majority of the identification fail-
ures are due to the multi-session problem. Therefore,
session compensation is still needed to address this
problem.
7 PRIOR WORK
In this paper, we attempted to extend our previous
work (Tikourt et al., 2015) dealing with MFCC se-
lection. In short, the major improvements are sum-
marized in Table 3.
Table 3: Improvements.
previous work current work
features MFCC MFCC, PLP,
∆MFCC
sel. criteria C
1
,..,C
3
C
1
,..,C
4
classifier SVM SVM, KNN
# speaker 10 20
# training utter. 10 10
# test utter. 10 30
session exploration no yes
In addition to SVM, we propose to apply the KNN
classifier, because this last one is non-parametric, ro-
bust and able to separate classes with non-linear com-
plex boundaries. The suggested improvements aim
partly to consolidate results about MFCC selection
obtained in our previous work (Tikourt et al., 2015).
8 CONCLUSIONS AND FUTURE
DIRECTIONS
In this paper, we have described a set of criteria pro-
posed to select the most relevant short-term feature
vectors for the text-independent recognition task.
A universal background model is used for rep-
resenting the speaker-independent information, and
hence it can be used as a framework for the selec-
tion purpose. The general idea consists in selecting
vectors having a low likelihood in the UBM class.
Speaker identification experimental tests on the
MOBIO corpus are presented. Results show that the
relevant speaker information is contained in less of
20% of data maximizing the criteria. Not only us-
ing the vectors that minimize the criteria increases
the complexity in time and space, but also reduces the
identification rate.
The findings of this study show that the distance
Euclidean from the UBM center, and the minus-
likelihood in the one-component Gaussian of UBM
are efficient. This supports the idea that UBM has ap-
proximately a hyper-spherical distribution form, such
as a multivariate normal distribution with equal vari-
ances.
It is obvious that an efficient frame pruning speeds
up the recognition computational process since a
small percentage of data is kept for speakers model
matching. Nevertheless, the recognition performance
SIGMAP 2017 - 14th International Conference on Signal Processing and Multimedia Applications
56

is enhanced only if a good trade-off between the
frame pruning and the speaker modeling is made. On
the one hand, pruning the irrelevant frames causes a
loss in speaker information, but it makes easier the
task of fitting the speakers’ models to data. On the
other hand, using all the frames preserves the entire
speaker information, but it makes the model estima-
tion inaccurate and more complex. This work and
the review of the literature have led us to conclude
that for TISAR systems an efficient frame pruning,
if it is combined with a suitable modeling, may speed
up significantly the recognition task without too much
compromising (even improving) the accuracy. In this
optic, frame pruning is an important approach to de-
sign real-time TISAR systems.
The majority of related works attempt to remove
some kinds of the irrelevant frames using specific cri-
teria based on the silence, the noise, the phonetic
information, or the correlation between successive
frames. The main contribution of this work consists
in applying the UBM model to prune all the irrelevant
frames at once whatever the kind.
To further our research we plan to use this find-
ing inside a verification TISAR system. Moreover,
developing efficient frame pruning techniques could
be used as a basis to propose new features (e.g super-
vectors) or models by setting more of importance to
vectors maximizing the selection criteria.
REFERENCES
Almaadeed, N., Aggoun, A., and Amira, A. (2016).
Text-independent speaker identification using vowel
formants. Journal of Signal Processing Systems,
82(3):345–356.
Beigi, H. (2011). Fundamentals of Speaker Recognition.
Springer Publishing Company, Incorporated.
Benyassine, A., Shlomot, E., Su, H. Y., Massaloux, D.,
Lamblin, C., and Petit, J. P. (1997). Itu-t recommenda-
tion g.729 annex b: A silence compression scheme for
use with g.729 optimized for v.70 digital simultaneous
voice and data applications. Comm. Mag., 35(9):64–
73.
Besacier, L. and Bonastre, J. F. (1998a). Frame pruning for
speaker recognition. In Acoustics, Speech and Signal
Processing, 1998. Proceedings of the 1998 IEEE In-
ternational Conference on, volume 2, pages 765–768
vol.2.
Besacier, L. and Bonastre, J. F. (1998b). Time and fre-
quency pruning for speaker identification. In Proceed-
ings. Fourteenth International Conference on Pat-
tern Recognition (Cat. No.98EX170), volume 2, pages
1619–1621 vol.2.
Campbell, W. M., Sturim, D. E., and Reynolds, D. A.
(2006). Support vector machines using GMM super-
vectors for speaker verification. IEEE Signal Process.
Lett., 13(5):308–311.
Dehak, N., Kenny, P., Dehak, R., Dumouchel, P., and Ouel-
let, P. (2011). Front-end factor analysis for speaker
verification. Audio, Speech, and Language Process-
ing, IEEE Transactions on, 19(4):788–798.
Eatock, J. P. and Mason, J. S. D. (1994). A quantita-
tive assessment of the relative speaker discriminating
properties of phonemes. In Proceedings of ICASSP
’94: IEEE International Conference on Acoustics,
Speech and Signal Processing, Adelaide, South Aus-
tralia, Australia, April 19-22, 1994, pages 133–136.
Khoury, E., Vesnicer, B., and Franco-Pedroso, e. a. (2013).
The 2013 speaker recognition evaluation in mobile en-
vironment. Idiap-RR Idiap-RR-32-2013, Idiap.
Kinnunen, T., Karpov, E., and Franti, P. (2006). Real-time
speaker identification and verification. IEEE Trans-
actions on Audio, Speech, and Language Processing,
14(1):277–288.
Kinnunen, T. and Li, H. (2010). An overview of text-
independent speaker recognition: From features to su-
pervectors. Speech Commun., 52(1):12–40.
Loizou, P. C. (2013). Speech Enhancement: Theory and
Practice. CRC Press, Inc., Boca Raton, FL, USA, 2nd
edition.
McCool, C., Marcel, S., Hadid, A., and et al. (2012). Bi-
modal person recognition on a mobile phone: us-
ing mobile phone data. Idiap-RR Idiap-RR-13-2012,
Idiap.
McLaughlin, J., Reynolds, D. A., and Gleason, T. P. (1999).
A study of computation speed-ups of the gmm-
ubm speaker recognition system. In EUROSPEECH.
ISCA.
Ramrez, J., Segura, J. C., Bentez, C., Torre, A. D. L., and
Rubio, A. (2004). Efficient voice activity detection al-
gorithms using long-term speech information. Speech
Communication, 42:3–4.
Reynolds, D. A., Quatieri, T. F., and Dunn, R. B. (2000).
Speaker verification using adapted gaussian mixture
models. In Digital Signal Processing, page 2000.
Tikourt, A., Rouigueb, A., and Djeddou, M. (2015). Ef-
ficient data selection criteria for speaker recognition.
In 3rd Inter. Conf. on Signal, Image, Vision and their
Applications, Guelma, Algeria.
Frame Selection for Text-independent Speaker Recognition
57
