
Integrating a Survey Ontology into an Upper Level Ontology
Using the Data Collection Ontology (DCO) as the Basis for a Survey Ontology
Joel Cummings and Deborah Stacey
School of Computer Science, University of Guelph, Guelph, Ontario, Canada
Keywords:
Mid Level Ontology, Data Collection Ontology (DCO), BFO, Data Collection, OBO Foundry, Foundational
Ontology, Upper Level Ontology, Domain Ontology.
Abstract:
Capturing data in a step-by-step manner is generally completed using surveys that maintain some flow between
questions to capture data from a large number of respondents in a consistent manner. In other words capturing
data using surveys is a form of data collection that imposes a specific process to collect data. In this paper we
present the benefit of utilizing the mid-level Data Collection Ontology (DCO) to construct a survey ontology
that is domain independent and compare to an existing Survey Ontology (Fox M.S., 2016) implementation.
1 INTRODUCTION
Capturing data in a step-by-step manner is generally
completed using surveys that maintain some flow be-
tween questions to capture data from a large number
of respondents in a consistent manner. In other words
capturing data using surveys is a form of data collec-
tion that imposes a specific process that is used to cap-
ture data. This process enforces a particular flow for
the collection of data and provides a specific format
for each step that the captured data must meet in order
to be consistent. In the context of an ontology this is
an interesting problem in that ontologies are capable
of modelling such a solution but there are subtle com-
plexities we want to examine in developing a domain
agnostic survey ontology. For which we define do-
main agnostic as not containing any terms that would
be considered as specific to a particular domain or do-
mains. The notion of an ontology to model a survey
is not a unique idea or development (Fox M.S., 2016)
however, such designs face the issue of being applica-
ble to any domain or survey purpose. These ontolo-
gies are typically created at the domain level and as a
result include domain specific terms that does not al-
low for reuse. Reuse is one of the most important hall-
marks in ontology design (Gruber, 1995) and thus it is
arguably more important for surveys since questions
and response formats can be reused between surveys
and in the analysis of data.
Recently an ontology designed for surveys at a do-
main agnostic level was developed (Fox M.S., 2016)
which seeks to create a design that capture any sur-
vey regardless of domain. This ontology is a custom
design and itself does not reuse any existing ontolo-
gies (Fox M.S., 2016). This ontology will serve as
the baseline in our study of developing domain ag-
nostic, and therefore, reusable survey ontologies. Our
question or problem will be will does utilizing a high
level ontology design improve upon this existing Sur-
vey Ontology?
In this paper we present the benefit of utilizing the
mid-level Data Collection Ontology (DCO) to con-
struct a Survey Ontology that is domain independent.
We start by discussing the DCO as a base ontology,
then introduce our concept of a survey, and finally
we introduce the Survey Ontology as our comparison
point presenting our experiment and results.
2 BACKGROUND
The Data Collection Ontology (DCO) (Cummings
and Stacey, 2017) is based off of the Basic Formal
Ontology (BFO). The BFO was chosen for its sim-
plicity and relative popularity as well as its focus on
being domain agnostic (Cummings and Stacey, 2017).
The DCO serves to define data collection terminology
and relations within the BFO hierarchy to establish a
starting point for ontology developers that seek to col-
lect data of some kind. The DCO extends key classes
such as processes and continuants to provide neces-
sary classes that one would use in data collection. In
addition it includes a philosophy for data collection
to make use of First Order Logic and reasoning to es-
Cummings J. and Stacey D.
Integrating a Survey Ontology into an Upper Level Ontology - Using the Data Collection Ontology (DCO) as the Basis for a Survey Ontology.
DOI: 10.5220/0006582703100319
In Proceedings of the 9th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (KEOD 2017), pages 310-319
ISBN: 978-989-758-272-1
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Question Subject: Age
What is your age?*
When were you born?
____ years? Or ____ months?
A) 0-1
B) 2
C) 11-19
D) 20 -49
E) 50+
A) Baby
B) Child
C) Teen
D) Adult
E) Senior
YYYY-MM-DD
YYYY
A) 1960s
B) 1970s
C) 1980s
D) 1990s
Answer
Possibilities
* For future use of this question with
captured data, one also needs the
date a respondent took the survey,
otherwise the data will be out of
context.
Figure 1: An example of a single survey question.
tablish relationships and categories for captured in-
stances. It does this using best guesses or anecdotal
data to determine if the expected world view is seen
with the collected data. In the DCO these anecdo-
tal data or guesses are referred to as classifiers that
impose equivalence relations for expected values or
ranges on your captured instances such that they are
grouped by the reasoner. In addition assigned to cap-
tured instances are has expected type relations that
map to the expected type or category based on the
anecdotal evidence is compared with the reasoner as-
signed classifier. When the has expected type and the
classifier are out of sync an error exists with the data
or a world view issue exists. This affords the ability
to detect issues early on during data collection. In ad-
dition to its philosophy on reasoning the DCO is an
ontology that is focused on maintaining a small size
and not including domain specific classes or terminol-
ogy that may conflict with domain ontologies that uti-
lize it. These properties are what make the DCO more
suitable as a base for data collection when compared
to the BFO alone which focuses on the organization
of terms at a very high level into their place in space
time which can be overwhelming when constructing
an ontology for surveys.
In the context of our problem we must introduce a
survey representation in the form of an ontology and
then discuss the Survey Ontology (Fox M.S., 2016)
in depth as that will be the basis for our experiment
which is to construct a domain agnostic design of the
Survey Ontology using the DCO. The next sections
will introduce the background of the Survey Ontology
problem and our solution.
2.1 Examining the Survey
Breaking a survey down as shown in Figure 1 illus-
trates the components of a survey, each of which can
be reused across surveys. From a high level, sur-
veys are a grouping of components that are executed
in a particular order which can be linked or taken
from other surveys. Additionally, the linkings be-
tween these components, allow for traceability across
questions to determine the origin, the uses cases, and
the popularity of each the components. Furthermore,
through the use of branching and conditional links
one can produce the flow of a survey that will result
in the capturing of respondent results as ontological
instances. It is this structure that we seek to model
when creating a survey ontology.
2.1.1 The Survey Ontology
The goal of the Survey Ontology is to develop a stan-
dard for a survey structure’s representation and allow
for communication over the Semantic Web (Fox M.S.,
2016). The Survey Ontology has the goal to enable
reuse of survey data for other purposes in future works
(Fox M.S., 2016). This purpose of the Survey Ontol-
ogy overlaps well with our problem and design inten-
tions of the DCO but closer to the domain level since
it is focused on survey which we consider as a form
of data collection but not data collection as a whole.
Finally, the Survey Ontology is recent but still under
construction making it a reasonable point of compar-
ison as it is in similar infancy to that of the DCO.
The Survey Ontology is focused on creating a
generic and reusable framework for producing sur-
veys and capturing survey answers. The work is based
off of early work that used XML to create a gen-
eral format for questions, answers, and survey logic
(Fox M.S., 2016). The main issue noted is that one of-
ten wants to compare questions as well as responses to
questions in surveys. More generally, analysis is of-
ten missed out in existing implementations (Fox M.S.,
2016). The Survey Ontology focuses on creating a
representation for the Semantic Web that allows for
questions, answers, and responses to be linked and
reused.
The Survey Ontology contains a number of classes
starting with Survey. The Survey class defines a re-
cursive structure of Survey Part instances that allow
surveys to be sectioned and broken down into smaller
chunks. Next it defines Question which in turn de-
fines the basic format including text, an identifier, and
a sequence. Question is then subclassed into sev-
eral types based on usecase. Survey Response and
Survey Answer are similar to Question in that they
define required components that focus on establish-
ing links between user responses, the Question they
are related to, as well as start times and end times so
surveyors can track when each component was used
(Fox M.S., 2016). The last key component is the Sub-

ject which serves to link questions and responses to a
general subject which serves two purposes. Firstly,
it allows for more semantic understanding of what a
Question or Response seeks to capture and secondly
it allows the use of more general relations since a re-
lation does not need to focus on describing the Sub-
ject it collects data on (Fox M.S., 2016). An exam-
ple would be surveytaker hasHadHeartAttack yes ver-
sus surveytaker hasAilment HeartAttack and assign-
ing the subject Heart Attack to the question being
asked i.e. surveyquestion hasSubject HeartAttack.
The structure of the ontology makes it clear
through its restrictions and relations that Answers,
Questions, Response Formats, and Surveys are linked
so that one can examine each component individually
while maintaining a connection to relevant compo-
nents so one can move between related classes. In
addition the Survey Ontology imposes some default
values (Fox M.S., 2016) and ranges for question sub-
types to enable faster construction. It also provides
the ability to produce some standard survey types
(Fox M.S., 2016).
A specific example of a survey question can be
seen in Figure 1 where we present questions for the
subject of age. We note that there are multiple ways
of asking the question of age and depending on the
way we ask the information we require to analyze and
make inferences changes. The first question we pose
is What is your age? where we note that during anal-
ysis one would also need to know when a respondent
answered the question in order for current age to be
determined. The second question we pose is When
were you born? where we can calculate age based on
the current date. However, both questions have the
same subject of age and that is one important compo-
nent of the Survey Ontology. The second area where
an ontology is important is with the different formats
that respondents can provide their responses in. In
other words, they are guided by the answer format of
which we provided 3 examples for the age question.
For comparative and analytical purposes the format
that is used is important as not all responses can be
converted depending on their format. For example if
age is provided in ranges it cannot be converted into
specific integer values, however, this conversion can
be done the opposite way. A survey ontology pro-
vides benefit through linking formats to responses,
questions, and subjects so that one is able to make
decisions about how to analyze their results.
This generic structure of capturing survey data and
survey components is an example of where the DCO
could be used to speed up ontology development and
provide structure and components which is the moti-
vation for demonstrating this design through integrat-
ing the Survey Ontology into the DCO and secondly
creating a DCO variant of the Survey Ontology with
the same goal in mind.
3 EXPERIMENT
Through using DCO as the base for our problem we
can view our experiment as the application of the
DCO in a real world problem to build a domain ag-
nostic survey ontology. To do so we will establish
a comparison using the Survey Ontology (Fox M.S.,
2016) as the baseline of a good ontology and we hy-
pothesize that through using an upper level ontology,
in this case the DCO we will achieve a better result
through our evaluation methods, see Section 3.1.
Our experiment involves the working version of
the Survey Ontology (Fox M.S., 2016) (Fox, 2016)
in reconstructing the ontology as well as taking the
premise of the Survey Ontology and constructing a
survey ontology from the DCO point of view. We ac-
knowledge that the Survey ontology is not complete
but is recent (Fox, 2016) and provides a good exam-
ple for a use case of the DCO. We will take into con-
sideration its recency and incompleteness when doing
our full evaluation.
The three ontologies to be compared will be de-
fined below with names which will be used through-
out the remaining chapters. The rest of the chapter
will be dedicated to the complete design and terms of
each ontology. Due to the size of the ontologies they
are not presented here but can be downloaded from:
http://dx.doi.org/10.5683/SP/PFHFUQ
• Survey Ontology - This is the original unaltered
Survey Ontology as this writing (Fox, 2016). This
is main point of comparison as it establishes the
premise, design, and use cases of a Survey Ontol-
ogy.
• Integrated Survey Ontology - This the first of
the DCO based Survey Ontologies which inte-
grates all the terms into the DCO reusing equiva-
lent DCO classes and relations where applicable.
The Integrated Survey Ontology seeks to estab-
lish that it is possible to model any data collection
ontology within the DCO.
• DCO Survey Ontology - This is the DCO de-
signed and developed Survey Ontology, it does
not reuse all classes and terms, instead it takes
the premise of what a Survey Ontology should be
based on (Fox M.S., 2016) and implements the de-
sign from the DCO philosophy of data collection.
This would be the ontology that one developed

given the DCO and the requirements of a Survey
Ontology.
3.1 Evaluation Method
Traditional methods of evaluation are important for
comparison to existing ontology designs and iden-
tify key components in the ontology community about
what makes a reasonable design. There are sev-
eral different methods for evaluation (Bandeira et al.,
2016) with somewhat competing views. Therefore we
are choosing an aggregate method, the FOCA method
(Bandeira et al., 2016) which combines ideas of sev-
eral existing methods to derive evaluative measures
for ontology design. The FOCA method introduces
several measures as well as a framework for evaluat-
ing the measures making it possible for an ontology
developer of any experience level to evaluate their de-
sign. Secondly, it allows ontologies to be compared
regardless of their level or purpose making it suitable
to evaluate the DCO against even domain level on-
tologies as well as DCO derived ontologies with do-
main level ontologies.
3.2 The FOCA Methodology
FOCA has several parts to the methodology that in-
cludes determining the type of ontology, a question-
naire to evaluate components, a framework to fol-
low based on ontology type, and finally a statistical
model that calculates the quality of ontologies. Most
of these components are fairly common to the Ap-
plied Ontology community but previous methods lack
the questionnaire and framework which is why focus
will be placed on these components (Bandeira et al.,
2016). The FOCA method breaks down its ques-
tionnaire into relevant roles that separate measures
based on Ontological Commitments, Intelligent Rea-
soning, Efficient Computation, Human Expression,
and Substitution (Bandeira et al., 2016). Each of these
goals evaluates a particular part of the ontology and
has questions associated with them which will be de-
fined. Additionally, it groups questions based on the
following metrics: Completeness, Adaptability, Con-
ciseness, Consistency, Computational Efficiency, and
Clarity (Bandeira et al., 2016). These goals and met-
rics are found through many Applied Ontology com-
munities (Bandeira et al., 2016) which is why we feel
this method is a strong indicator of an ontologies qual-
ity.
To ensure readers who are unfamiliar with the
method have an understanding of what it evaluates we
will examine each question and how it will be evalu-
ated. Additionally, there are a few cases where we
Table 1: FOCA Goal 1.
ID Question Description/Evaluation Crite-
ria
Q1 Were the
competency
questions
defined?
If the ontology does not have
competency questions defined,
assign 0. If they do exist there
are three subquestions: Does the
document define the objective
of the ontology? Second: Does
the documentation define stake-
holders? Third: Does the docu-
ment define use cases? Each sub
question receives a grade of one
of: 0, 25, 50, 75, 100. The over-
all grade is the mean of the 3 sub
questions.
Q2 Were the
competency
questions
answered?
This grade is 0 if compe-
tency questions were not de-
fined. Otherwise determine if
the ontology has satisfied the
competencies. Grades: 0, 25,
50, 75, 100.
Q3 Did the
ontology
reuse other
ontologies?
If the ontology reuses other on-
tology(s) assign 100, 0 other-
wise.
have altered the evaluation which will be explained
on a question by question basis. FOCA divides ques-
tions into major goals which is what we will use to
divide the questions into groups.
3.2.1 FOCA Goals and Questions Defined
Goal 1 centres around the ontology design ensuring
that one has competency questions defined and an-
swered, and that the ontology has some form of reuse.
See Table 1 for full descriptions.
Goal 2 centres around the ontologies design and
structure, specifically ensuring that a goal is met
based on its high level goal (domain or upper level on-
tology) and whether it is met with its class definitions.
For example, it ensures that if an ontology claims to
be upper level that it includes an inheritance structure
before it defines domain particular terms. Goal 2 also
checks the domain of the ontology, ensuring that it
does not define terms outside of the domain it claims
to represent. See Table 2 for full descriptions.
Goal 3 centres around looking through the ontol-
ogy and determining if it has contradictions or invalid
reuse of terms. Contradictions are issues where the
properties on relations (functional, transitive, reflex-
ive etc.) are not applicable to the term in the ontol-

Table 2: FOCA Goal 2.
ID Question Description/Evaluation Crite-
ria
Q4 Did the
ontology
impose a
minimal
ontological
commit-
ment?
Answer this if it is type 2 (do-
main ontology). Ensure that the
ontology does not define high
level abstractions and content
that is not specific to a domain.
i.e. a Facebook ontology does
not need to define a computer
system. Grades are 0, 25, 50,
75, 100.
Q5 Did the
ontology
impose a
maximal
ontological
commit-
ment?
Answer only if the ontology
is type 1 (high level ontol-
ogy). Ensure the ontology
defines high level abstractions
such that domain level ele-
ments have more general par-
ents. Grades are 0, 25, 50, 75,
100
Q6 Are the
ontology
properties
coherent
with the
domain?
Determine if the ontology con-
tains elements that are not co-
herent with te domain. For ex-
ample, a car ontology should
not contain lion. Grades 0, 25,
50, 75, 100.
ogy. Redundant axioms are cases where reuse should
not occur as a term with the same name has two dif-
ferent meanings. See Table 3 for full definitions.
Goal 4 centres around reasoning and reasoner per-
formance and this is where our first modification is
made. Question 10 (Q10) (Bandeira et al., 2016) is
based on the speed of ontological reasoning where it
uses the verification of stopping being a grade of 0,
any delay being a grade of 25, 50, or 75, and run-
ning quickly being 100, see Table 4. This does not
allow for easy comparison as quick is relative. Fur-
thermore, it does not consider the number of ontol-
ogy components (classes, relations, properties etc) or
the expected number of individuals which is impor-
tant where equivalence relations are used. For speed
our grade will be boolean, 0 for reasoner failure, or
100 for successful reasoning.
Goal 5 (see Table 5) centres around documenta-
tion that is internal to the ontology as well as ensur-
ing the modelled ontology is the same as what is de-
scribed in the design documentation. The evaluation
is straightforward but we make modification for clari-
fication purposes. Question 12 (Q12) (Bandeira et al.,
2016) is based on definitions and descriptions in the
ontology and scores based on language used with de-
ductions made for using a language other than En-
Table 3: FOCA Goal 3.
ID Question Description/Evaluation Crite-
ria
Q7 Are there
contra-
dictory
axioms?
Check if the classes and rela-
tions contradict the domain for
example if the hasSocialSecuri-
tyNumber is not functional this
would be a problem because
a person can only have one.
Based on the number of contra-
dictions give grades between 0,
25, 50, 75 or 100 if there are
none.
Q8 Are there
redundant
axioms?
Determine there are classes or
relations that model the same
thing with the same meaning
(ie.e using mouse for computer
hardware and the animal). If
there are many redundancies
grade 0, if there are some as-
sign one of 25, 50, 75 and 100
if there are no redundancies.
Table 4: FOCA Goal 4 (Bandeira et al., 2016).
ID Question Description/Evaluation Crite-
ria
Q9 Does the
reasoner
bring
modelling
errors?
Check if the reasoner returns er-
rors. If there are many errors
or the reasoner stops assign 0, if
there are some errors assign 25,
50, 75 and 100 if there are no
errors.
Q10 Does the
reasoner
perform
quickly?
Determine if the reasoner runs
quickly. If the reasoner stops as-
sign 0, if there is any delay as-
sign one of 25, 50, 75 or 100 if
it runs quickly.
glish, we are going to change this justification so that
as long as all terms are defined in English full score
is assigned and we will not deduct points for ontolo-
gies that include definitions in other languages even if
they do not cover all terms. The explanation in (Ban-
deira et al., 2016) gives the impression that one should
deduct for using other languages, this will not be case
in our evaluation.
4 RESULTS
Our comparison for the Survey Ontology variants will
be from the structural perspective since any docu-
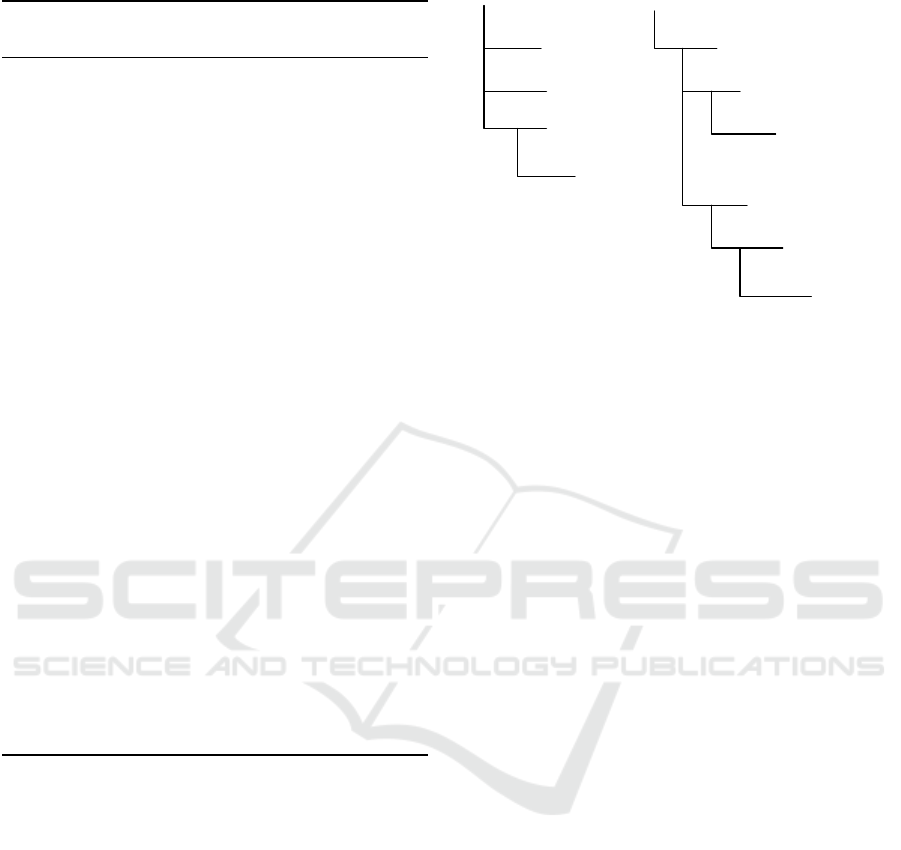
Table 5: FOCA Goal 5.
ID Question Description/Evaluation Crite-
ria
Q11 Is the doc-
umentation
consistent
with the
modelling?
Determine if there are defini-
tions in the ontology. If there
are none assign 0. Check that
each class and relation has a def-
inition and it is to the same de-
tail as the document. Secondly,
determine if the documentation
explains each term and justifies
it. For each sub question assign
25, 50, 75, or 100. Calculate the
mean of the two sub questions.
Q12 Were the
concepts
well written
Determine if the classes or re-
lations are written in an under-
standable and correct form (ac-
cording to English or another
language). If the ontology is
difficult to understand or full of
poorly written terms assign 0. If
there are a mix of languages, as-
sign one of 25, 50, 75. If the
ontology is well written and one
language as used assign 100.
Q13 Are there
annota-
tions in the
ontology
bringing the
concepts
definitions?
In this question check exist-
ing annotations being the defini-
tions of the modelled concepts.
If there are no annotations as-
sign 0. If there are some an-
notations assign 25, 50, or 75.
If all classes have annotations
have annotations, assign 100.
mentation evaluated in the FOCA methodology is not
something that DCO will provide benefit to. Addi-
tionally, this is something that can easily be changed
by the Survey Ontology developers through releasing
an additional document with competency questions
and updating the ontology file. Furthermore, it is the
structural differences and reuse differences that form
the advantage of DCO. These differences are reflected
in the scoring with improvement seen from the Sur-
vey Ontology to the Integrated Survey Ontology and
further improvement seen from the Integrated Survey
Ontology to the DCO Survey Ontology. These results
can be seen in Tables 7, 8, 9, 10, and 11 at the end of
this paper.
The major advantages are seen in the reuse ques-
tion (Q3) and again in Q5 where the DCO’s reuse
avoids redefining common terms and relations while
providing a structure for domain specific terms to
have parents. Furthermore, there are no terms in the
Survey Ontology
owl:Thing
Feature
Interval
SurveyThing
Question
owl:Thing
entity
classifier
Response
Independent
Continuant
Subject
Question
DCO Survey Ontology
Figure 2: An example of the Structural Differences between
the Survey Ontology and the DCO Survey Ontology.
DCO based survey ontologies that have owl:Thing as
a parent (see Figure 2). Classes always have some
parent either through the BFO or through the DCO’s
own terms. This creates familiar hierarchies allow-
ing developers less familiar with the domain to un-
derstand where terms exist in the larger world view.
The FOCA scores for documentation or compe-
tency questions are not an area where the DCO pro-
vides benefit but it did avoid issues regarding dupli-
cate object and data properties since existing terms
were reused instead of being defined helping to avoid
potential error. Results for Q1 and Q2 (Table 7) pre-
sented no major differences due to the fact that all
documentation was based on the Survey Ontology
so any issues regarding competency questions were
carried through. The major difference is seen with
Q3 where the DCO based variants see improvement
in score due to their reuse of a higher level ontol-
ogy, the DCO which in turn reuses the BFO. Goal
2 (Table 8) presents some notable changes beginning
with Q5 where improvements are seen due to the
fact that DCO includes hierarchies for terms which
FOCA states is important for non-application ontolo-
gies or Type 1 ontologies (Bandeira et al., 2016).
Since the goal of each of these ontologies is to es-
tablish a high level domain that is not application spe-
cific they should define terms in a hierarchy to place
them within the larger world. This is where major ad-
vantages start to be seen with DCO since it allows
people new to the survey domain to place particu-
lar terms and those familiar with BFO will have an
even easier time with the basic structure. There are
no differences for axioms or redundancies therefore
Goal 3 does not present anything significant between
ontology implementations (Table 9). Goal 4 (Table
10) presented only one improvement over the Sur-
vey Ontology since it defines a relation that is used

as both an object relation and a data relation. How-
ever due to equivalences in relation purpose these re-
lations were not migrated to the DCO variants which
provided benefit in scoring as the error was no longer
present. Goal 5 (Table 11) is based on components
where again we see little difference with the only be-
ing no domain specific content in the DCO Survey
Ontology.
With success demonstrated using the traditional
FOCA method we consider the structural numbers of
each ontology and contrast them with our criteria for
choosing an ontology which will be outlined below.
This is the criteria that was used when choosing a
foundational ontology to base the DCO on.
The first criteria we want to define is based on the
number of terms and relations in the ontology, where
we prefer to have fewer of each for two main reasons.
Firstly, upper level ontologies are meant to be derived
into a domain level ontology and thus will have more
terms and relations added over time and large ontolo-
gies introduce performance penalties potentially re-
sulting in an ontology that is intractable for a reasoner
(Horrocks, 2005). Secondly, in terms of understand-
ability, the fewer terms a person must know to use an
ontology the easier it is to get started. Additionally,
it will reduce reliance on documentation and expert
knowledge making it easier to design and organize
derived ontologies. Furthermore large ontologies may
deter usage of the ontology altogether.
The second criteria we care about is usage and
popularity. Popularity of an upper level ontology is
important when considering its purpose for unifying
ontologies (Herre, 2010). We want to look at what
people are using to see what is working and how many
domains are being captured by the upper level ontol-
ogy. If only one domain is using a particular ontology
it is possible that it has not met the needs of others.
Additionally greater popularity increases the likeli-
hood that ontology developers will have experience
with the ontology.
Finally, we move on to a more formal definition
for upper level ontologies which is used for the pur-
pose of ensuring that the base is kept generic, again
to satisfy our definition. Thus we say an upper level
ontology must be free from any domain specific terms
or relations. We are not interested in ontologies that
take the role of defining thousands of terms to satisfy
a large number of domains since it is unlikely such an
ontology could satisfy each domain realistically.
Starting with the first criteria we compared on-
tology sizes. The sizes are summarized in Table 6.
As one would expect the class count is larger in both
versions of the DCO based Survey Ontology variants,
however, what is noted is that in both derived forms
the number of relations were dramatically reduced.
Therefore when looking at both classes and relations
the size difference is insignificant. This means any
implementation is not too large by our standards and
this is because when the world of ontologies is consid-
ered as a whole, ontologies with thousands of classes
are not uncommon making a difference in size of 70
relatively small and unlikely to deter ontology devel-
opers.
When looking at relations one can see the dra-
matic effect reuse makes. For object relations the De-
rived Survey Ontology added only 25 of the 41 rela-
tions defined in the Survey Ontology. The other rela-
tions had equivalents that already existed in the DCO.
Similarly, the Derived Survey Ontology adds only 21
of the 26 data properties again using equivalents de-
clared in the DCO. Therefore in terms of growth the
DCO maintains a small number of relations through
reuse of major data collection requirements such as
time, units, and data structures.
Our second criteria involves looking at domain
specific content. We note that the Survey Ontology in-
cludes domain specific content as of this writing but
we acknowledge that it is not tied into the structure
of the ontology and could be removed without major
refactoring. Therefore, we will not dive deeply into
this criteria as it is not something the DCO will af-
fect.
Lastly, is usage and popularity. Both ontologies
are in their infancy, however, the DCO’s base provides
familiarity since any OBO user or developer is already
familiar with our design to an extent. An OBO user
would already know of the basic design, classes, and
how the ontology is structured since it based on the
BFO. To use the DCO they would only need to learn
about Subjects, Classifiers, and Datums. We argue
this provides significant benefit in terms of usage and
popularity since the core of the ontology is well es-
tablished. The Survey Ontology does not have this
advantage since it uses no base ontology and defines
terms exclusively in its own hierarchy. This would
mean developers would need to completely learn the
structure before use.
4.1 FOCA Evaluation Table Notation
Defined
Here are some brief definitions for table components
so one can more easily navigate the results. Ma-
jor differences between versions are bolded to show
changes across the variants. All Justifications are pre-
sented in the same order as the score columns mean-
ing the first justification for a question refers to the
Survey Ontology while the last justification refers

to the DCO Survey Ontology. Any dashes present
means refer to the row above for explanation. See
below for more terminology.
SO refers to the Survey Ontology’s score, ISO
refers to the Integrated Survey Ontology’s score, DSO
refers to the DCO Survey Ontology’s score. For
Question ids when a dash proceeds the number it
refers to the subsection question in FOCA for exam-
ple, Q1-2 refers the second subquestion of question 1.
N/A manes the question was not scored.
4.2 Evaluating Ontology Hypotheses
We also define several hypotheses about DCO vari-
ants that are presented below. These are properties an
ontology developed using the DCO will present with.
The first hypothesis states that we expect overlap
in terms meaning that the DCO should contain terms
and relations that can be used by the Survey Ontology
variants. Overlap is found through integration of the
Survey as a Process which uses the control flow for
repeating, and branching directly. Similarly, Ques-
tions, Answers, and Person are considered Subjects
as they are what is studied in Surveys. Relations for
time were used directly in place of those defined in the
Survey Ontology itself demonstrating direct overlap.
Therefore we can say that our hypothesis is true that
there is domain overlap with the DCO components.
The second hypothesis states that we expect terms
to be at a lower level. We note that none of the terms
placed into the DCO derived Survey Ontology were
placed at a level in the hierarchy that was above any
existing DCO term meaning there were no terms that
were of greater generality than those defined in the
DCO. Therefore our hypothesis is true.
Lastly, we are concerned with coverage meaning
we do not want terms defined outside of the DCO’s
hierarchy and in the construction of the Survey Ontol-
ogy derivatives it was the case that all terms fit within
the DCO hierarchy meaning nothing was subclassed
as owl:Thing. Therefore this hypothesis was true.
4.3 Survey Ontology Evaluation
Conclusions
The Survey Ontology implementations meet our hy-
potheses. Therefore, with the greater scores of the
FOCA evaluation and no major detriment to our cri-
teria we can determine that DCO provided some no-
table improvements with reuse especially though re-
lations which we were able to reduce as well as
through the hierarchies and organizational benefits to
the classes of the Survey Ontology. Within DCO we
Table 6: Survey Ontology Sizes Compared.
Measure SO ISO DSO DCO
Base
Class Count 37 102 107 73
Object Rela-
tion Count
41 50 34 25
Data Relation
Count
26 33 16 12
Table 7: Goal 1 Questions and Justifications for Survey On-
tologies.
Q SO ISO DSOJustification
Q1 0 0 0 No competency questions are
defined in the Survey Ontology.
Q1 Subquestions
Q1-
1
100 100 100 The document does contain the
ontology objective which is to
“represent the logic of the Sur-
vey, including contingent ques-
tions and repeated sections”
(Bandeira et al., 2016) .
Q1-
2
100 100 100 Yes, the scenarios are cases
when you would normally use
an XML or other Survey repre-
sentation.
Q1-
3
100 100 100 Yes, the stakeholders are de-
fined throughout the document
making it obvious who would
be interested in such an ontol-
ogy.
Q2 0 0 0 There were no competency
questions in the ontology or in
the document.
Q3 0 100 100
No the ontology does not
reuse other ontologies. The
ontology does however,
reuse the schema:Person
class.
Yes, the DCO and the BFO
are reused.
-
used Subjects, and Processes to describe Survey On-
tology terms so they could be understood and moti-
vated at a higher level and as a result reused defini-
tions and relations imposed on those classes to reduce
the amount of restrictions that needed to be created.

Table 8: Goal 2 Questions and Justifications for Survey On-
tologies.
Q SO ISO DSOJustification
Q4 N/A N/A N/A Not Applicable, all ontologies
are Type 1
Q5 25 75 75
The Survey Ontology pro-
vides very little in the way
of abstraction by going from
owl:Thing to SurveyThing.
It does not define the time
or space a survey is repre-
sented in. Additionally, the
ontology incorporates terms
such as schema:Person as
owl:Thing as well as Popu-
lation and Interval.
The Integrated Survey On-
tology does define hierar-
chies for each of its objects
with Surveys represented as
Processes and SurveyParts
being Process Parts and all
objects organized according
to their place in time. No
objects are derived directly
from owl:Thing.
Similar to the Integrated
Survey Ontology, the DCO
Survey Ontology also de-
fines a hierarchy for survey
terms.
Q6 0 0 100
The ontology does include
elements that are not coher-
ent with the domain such
as Disorder and Medication
which are not elements of all
surveys.
-
The DCO Survey Ontology
only includes relevant terms
for the Survey domain.
5 CONCLUSIONS
We have presented two ontologies derived from the
Survey Ontology each with benefits over the other it-
eration. Based on the design of using an upper level
the FOCA evaluation has shown benefit in reuse and
in defining more general hierarchies to help ontology
developers place domain specific terms within the hi-
Table 9: Goal 3 Questions and Justifications for Survey On-
tologies.
Q SO ISO DSOJustification
Q7 100 100 100 There are no contradictory ax-
ioms.
Q8 100 100 100 There are no redundant terms in
the ontology.
Table 10: Goal 4 Questions and Justifications for Survey
Ontologies.
Q SO ISO DSOJustification
Q9 75 100 100
There is one error with a
redeclaration of targetProp-
erty as both an object prop-
erty and a data property.
There are no errors in the
ISO.
-
Q10 100 100 100 Yes the reasoner completed and
did so at an average of just under
500ms based on our testing.
erarchy and providing a place for non-survey terms
within the ontology.
Lastly, we presented a working example of the
DCO in the case of integrating an existing ontology
showing that its possible to take an existing ontology
and map it into the DCO if one is part way through de-
velopment and still see benefit and secondly that the
DCO is capable of integrating a separate philosophy
into its design and that it is of a high enough level to
not encumber such an integration.
6 FUTURE WORK
A useful addition to any Survey Ontology would be
an Analysis Ontology that focuses on tools that are
used to analyze the results of captured survey data.
This might be integrated into the DCO or the DCO
Survey Ontology itself whichever way the developer
sees fit. The ontology should focus on utilizing and
mapping data between survey instances so that reuse
can be conducted using similar surveys from different
studies to pool data instead of continually recapturing
the same or similar data.
A major goal of this ontology would be to cre-
ate some form of mapping of compatible answer for-
mats. As an example using our questions in Figure 1 it
would be possible to map the age in years or months
to the ranges such that 6 months would map to 0-1

Table 11: Goal 5 Questions and Justifications for Survey
Ontologies.
Q SO ISO DSOJustification
Q11 50 50 50 The documentation explains
each term very well along with
examples how it will work
which results in a Score of 100.
However, the definitions in the
document are not the same as
those in the ontology so we
award a Score of 50.
Q11 Subquestions
Q11-
1
0 0 0 No, the definitions in the ontol-
ogy are not the same as some
detail is missing and not all have
annotations in the modelling.
Q11-
2
100 100 100 Yes, the terms and the design
of the ontology are well docu-
mented and explained.
Q12 100 100 100 The annotations are well written
and easy to understand with no
errors.
Q13 50 50 100
Not all elements were an-
notated. Many of the object
and data relations were not
annotated. Classes that were
not annotated include: Fea-
ture, Interval, SurveyThing,
Mental Disorder, Physi-
cal Disorder, Medication,
Confidence QT, ExcuseQT,
FrequencyQT, satisfac-
tionQT, YearQT, YesNoQT,
TextQEQ, Experience State-
ment, Intrinsic Statement,
and Non Repeated Survey
Part.
All Elements were trans-
ferred over along with anno-
tations, therefore the miss-
ing annotations were in-
cluded.
All elements were annotated
with descriptions and pur-
poses.
years and 5 years would map to 2-10 years etc. Al-
lowing this type of mapping to be inferred by a rea-
soner would allow for users to compare two similar
surveys and determine if and for which responses can
the data can be pooled and reused for a further study.
REFERENCES
Bandeira, J., Bittencourt, I. I., Espinheira, P., and Isotani, S.
(2016). Foca: A methodology for ontology evaluation.
arXiv preprint arXiv:1612.03353.
Cummings, J. and Stacey, D. (2017). The mid level data col-
lection ontology(dco). Proceedings of KEOD 2017.
Fox, M. (2016). Enterprise integration laboratory
eil. http://www.eil.utoronto.ca/. (Accessed on
04/23/2017).
Fox M.S., K. M. (2016). An ontology for surveys. Proceed-
ings of the Association for Survey Computing, 7.
Gruber, T. R. (1995). Toward principles for the design of
ontologies used for knowledge sharing. Int. J. Hum.-
Comput. Stud., 43(5-6):907–928.
Herre, H. (2010). General Formal Ontology (GFO):
A Foundational Ontology for Conceptual Modelling,
pages 297–345. Springer Netherlands, Dordrecht.
Horrocks, I. (2005). Description logics in ontology applica-
tions. In International Conference on Automated Rea-
soning with Analytic Tableaux and Related Methods,
pages 2–13. Springer.
