
Towards a Personal Identity Code Respecting Privacy
D. Migdal and C. Rosenberger
Normandie Univ., UNICAEN, ENSICAEN, CNRS, GREYC, 14000 Caen, France
Keywords:
Personal Information, Behavioural Biometrics, Privacy Protection.
Abstract:
Various applications on Internet require information on users, to verify their right to access services (verifi-
cation of identity proofs s.a. passwords), to avoid attacks (s.a. paedophilia, profile usurpations), or to give
trust to users (e.g. in social networks). In this paper, we introduce a method to generate (non-cryptographics)
identity-based signatures computed from 1) collection of data from user biometrics, computer configuration,
web browser fingerprinting, 2) data pre-processing, 3) protection of personal information through generation
of a binary code (our signature). We illustrate the benefits of the proposed method with preliminary results on
real personal information.
1 INTRODUCTION
Consumption of Internet services is nowadays sig-
nificant, whether it concerns social networks, e-
commerce, or online games. E.g. in 2016, 96%
of French criminal records queries have been done
through Internet (Sta, ). However, several personal
information can be collected during usage of Inter-
net services, either given by users (s.a. on social net-
works), or automatically collected. Internet services
collect more and more personal information linked
to users, sometimes for legitimate usage (s.a. fraud
detection, remote examinations), but also for non-
compliant uses with collection terms (s.a. sales to
other services, identity consolidation). Such informa-
tion might be linked to the user (s.a. biometrics data,
name, age), to the browser (s.a. version, type), to the
device (s.a. operating system, hardware, screen reso-
lution). The collection of such information, even in
a legitimate context, might enable user identification,
posing major privacy issues.
This paper main contribution is the proposal of a
method to generate binary codes linked to users iden-
tities. This code does not enable to retrieve informa-
tion used for its computation, but efficient compari-
son with other codes is possible through their Ham-
ming distances. We introduce the several computati-
ons steps of this code. Used informations go, from the
browser, to the user’s device. Collected information is
pre-processed, enabling the computation of the code
in the last step. Usage of such codes are not in the
scope of this article, however we briefly introduce few
interesting applications (authentication, attacks iden-
tification s.a. multi-accounts detection). This paper
is organized as follows. Section 2 introduces pre-
vious works on personal information collection and
usage. The proposed method is described in section
3. Section 4 introduces preliminary results on real in-
formation. We conclude and give some perspectives
in Section 5.
2 PREVIOUS WORKS
Browser Fingerprinting allows tracking user’s brow-
ser thanks to discriminant data a service can collect.
This is usually proposed to ”personalize services”
corresponding to users profile-type. Panopticlick (Ec-
kersley, 2010), IAmUnique (Laperdrix et al., 2016),
and UniqueMachine (Cao and Wijmans, 2017) web-
sites enable computation of browser fingerprints from
data collected by the website, generally through the
network and JavaScript API, to determine the finger-
print uniqueness among the previous computed. The
more the browser fingerprint is unique, the more the
service is able to discriminate the user. However,
browser fingerprint might vary, e.g. by changing of
browser, its configuration (Nikiforakis et al., 2015),
or device. The goal is not to identify users with assu-
rance, but to identify a set of browsing session belon-
ging to the same user, or type of users.
Information used for browser fingerprinting might
be linked, e.g. to the hardware (e.g. GPU (Cao and
Wijmans, 2017), screen), to the operating system, to
Migdal, D. and Rosenberger, C.
Towards a Personal Identity Code Respecting Privacy.
DOI: 10.5220/0006578902670274
In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018), pages 267-274
ISBN: 978-989-758-282-0
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
267
C
Press
T1
O
Press
T2
C
Release
T3
O
Release
T4
Time
Figure 1: Information captured in a keystroke dynamics sy-
stem when pressing C and O keys (Giot et al., 2011).
the browser, its configuration, installed fonts (Eckers-
ley, 2010; Laperdrix et al., 2016), browser history
(Weinberg et al., 2011), or blacklisted domains (Boda
et al., 2012).
Keystroke dynamics is a behavioral biometric mo-
dality consisting in analyzing users’ way of typing
on a keyboard. This biometric information can be
computed easily on Internet using a simple JavaScript
code. Keystroke dynamics has been experimented for
the first time in 1980 in a study where seven secreta-
ries were asked to type three different texts (Gaines
et al., 1980). The results were promising, but lacked
a sufficient number of users involved in the database.
The first patent on keystroke dynamics was registe-
red in 1986 (Garcia, 1986). Other methods have been
defined during the last twenty years (Phoaha et al.,
2009). In previous references such as (Giot et al.,
2009), it has been shown that keystroke dynamics is
invariant to the keyboard type (laptop or terminal).
The use of mobile devices is not considered in this pa-
per but many methods exist to deal with this type of
capture (Dafer and El-Abed, 2017). The capture pro-
cess of keystroke dynamics is presented in Figure 1. It
consists in computing several features when the keys
are pressed and released (timestamp of the event, code
of the key, . . . ) provided by any Operating System
(OS). The feature extraction consists mainly in com-
puting different latencies and duration times between
each key. Figure 1 shows an example where the user
presses two keys of the keyboard. The user presses
”C” at T1, ”O” at T2 and releases ”C” at T3 and ”O”
at T4. Note that the following relation is always re-
spected: T 3 > T 1 and T 4 > T 2 (we always release
a key after pressing it), while the following condition
may not always be respected: T 2 > T 3 (because, as
in our example, a user may press another key before
releasing the previous one). We can extract three dif-
ferent types of latencies (T2-T1, T4-T3,T2-T3) which
we call PP (latency between two pressures), RR (la-
tency between two releases), RP (latency between one
release and one pressure) respectively and one type of
duration (T3-T1 or T4-T2) which we call PR (dura-
tion of a key press). The described process is repeated
for all the keys.
All these previous works are able to collect a lot
of personal data related to one specific user. The pro-
blem is that they are not protected, or only with a sim-
ple hashing function (that does not permit to compute
similarities between different signatures). We intend
to solve this problem.
3 PROPOSED METHOD
The goal of the proposed method is to compute a bi-
nary code linked to an user from personal information
(technical and biometrics). This code must answer se-
veral requirements:
• Non reversibility: the user binary code must not
give information about the collected personal in-
formation.
• Confidentiality: the attribute value cannot be
known, nor deducted, by the service.
• Similarity conservation: If users’ personal infor-
mation are similar, then their binary code must be
too (Hamming distance).
• Non-usurpation: a tiers cannot forge a code ena-
bling him/her to usurp legitimate users’ identity.
• Revocation: legitimate user must be able to revoke
an existing binary code.
In the scope of article, a trust score can be compu-
ted with the Hamming distance between the proof and
the commitment, both fixed-size binary vectors. The-
refore, we consider and detail the following personal
information modality:
• what the user is/knows to do: its behavioural bio-
metric;
• what the user has: its browser;
• where the user is: its physical and organizational
localization;
• ”what the user prefers”: personal machine confi-
guration.
Figure 2 introduces the general principal of the pro-
posed method. A password is used as a secret key
(Lacharme and Plateaux, 2011). In this case, Alice
by inputting her password consent to give the binary
code to the service. The different computation steps
are introduced later.
3.1 Collection of Personal Information
Nowadays, it is possible to collect a large number of
personal information. We detail the collected infor-
mation by categories.
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
268

Figure 2: Proposed method principle.
3.1.1 Browser
To authenticate the browser, a simple key, stored on
it is enough. The key, we named localkey, is an n-
bits value randomly generated upon first usage of the
browser. This key is then used to authenticate the
browser. For n big enough, the probability of col-
lisions is insignificant, and the exhaustive research,
hard. In the frame of the experience, n=64, for hig-
her security needs, the key size may be increase, e.g.
with n=512. The key might be stored in the browser
localStorage
1
, or, ideally, in a WebExtension simple-
storage. Nonetheless, it is possible for an attacker to
steal the key if he has access to the device, or to the
user session. The keys being randomly generated, the
theft of one do not compromise the others possessed
by the user. The key might be protected, e.g. with
encryption, or the fraudulent usage be detected, e.g.
with others personal information. However, this will
not be introduced in the frame of this article.
3.1.2 Localization
IP addresses are distributed by ranges, from IANA
2
to RIR
3
, from RIR to LIR
4
, and finally from LIR to
users. It is then possible to deduce from it the user
network, the administrative (e.g. county) or physical
(e.g. GPS position) localization. However, the TOR
network, a VPN, or a proxy might be used to masque-
rade the user IP address. Then, the network and loca-
tions deduced from the IP address would be the proxy,
VPN, or exit TOR nodes. In the scope of this article,
1
HTML5 feature
2
Internet Assigned Numbers Authority
3
Regional Internet Registry
4
Local Internet Registry
the administrative (country, region, county, town) and
physical (latitude and longitude) are extracted through
the Google MAP API from an address extracted from
the database dp-ip
5
. In a future work, it would be pos-
sible to deduce either the user’s ISP (Internet Service
Provider), or the structural localization among an en-
tity (e.g. company, university, research center, state
agencies), thanks to DNS, reverse DNS, WHOIS IP,
and WHOIS domain queries. It is also possible to
get more information about the IP address thanks to
DNSBL
6
.
3.1.3 Network Data
Data sent to the service by the communication pro-
tocols are discriminant and enable, by browser fin-
gerprinting techniques, user identification (Eckersley,
2010; Laperdrix et al., 2016). In the same way, such
data can be used for user authentication by compa-
ring them to enrolment data. As a consequence, this
modality cannot be used if the data are randomized
for each transaction. However, usurpation is trivial
for whom knows this data, e.g. for whom provide a
service to the user. Moreover, the usage of normali-
zed data, e.g. by user the TOR browser, increases the
collision probability. This modality gives little trust
in the user authentication, but enable to detect recep-
tion of unusual data. In the scope of this article, the
following fields are extracted from the HTTP header:
• User-Agent: arbitrary string defined by the brow-
ser;
• Accept, Accept-Language, Accept-Encoding: for-
mats, languages, and encoding preferences (va-
lues ∈ [0, 1]);
5
download.dp-ip.com/free/dbip-city-2017-05.csv.gz
6
DNS Blacklist
Towards a Personal Identity Code Respecting Privacy
269
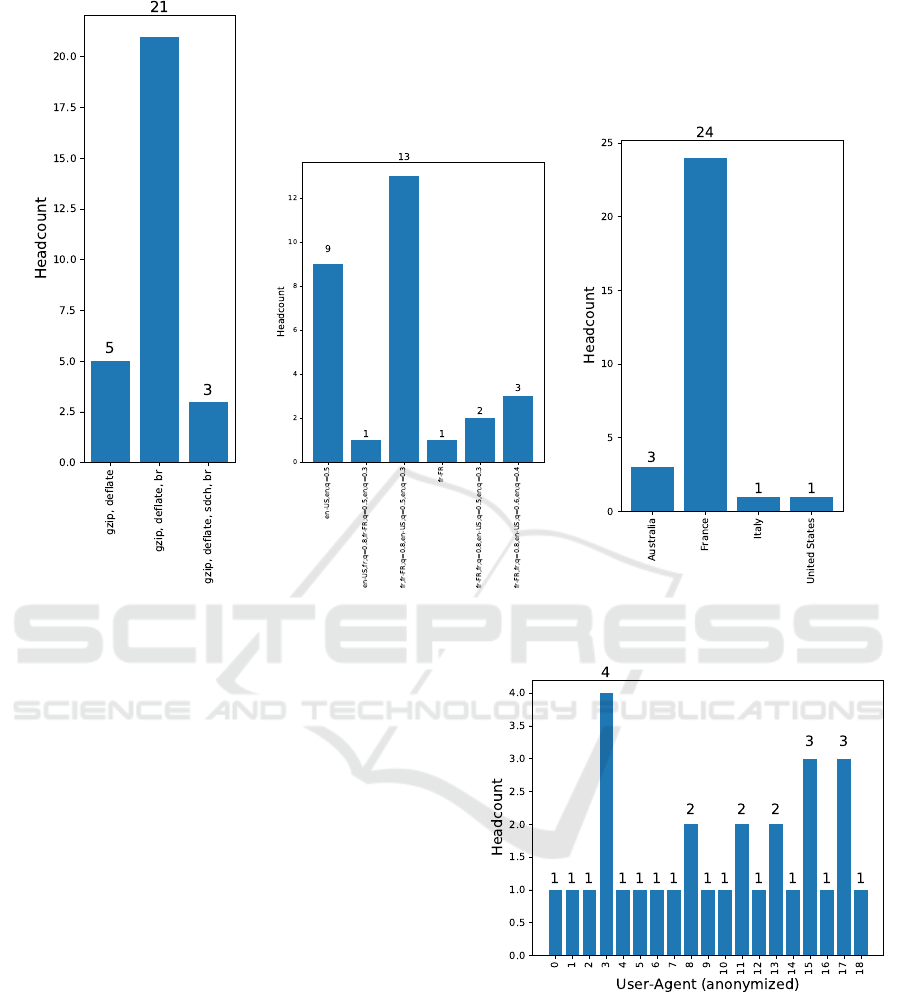
Figure 3: Personal information collection: distribution of some collected data (raw data).
• Referer: previous pages URL, sometimes rando-
mized, truncated, or removed;
• Cookie: cookies sent by the browser;
• DNT, Connection, Upgrade-Insecure-Requests:
other parameters.
Figure 3 shows the distribution of some network
and browser data for different users. We can see cle-
arly some differences for each user even if most of
them are french. Figure 4 shows the distribution of
the User-agent value that are very discriminant among
users.
3.1.4 Biometric Data
User behavioural biometric can be analysed from
keyboard and mouse actions, captured by JavaScript
events in the browser. In the scope of this article, the
user keystroke is computed from the 20 most frequent
digrammes: ”r ”, ”te”, ”nt”, ”, ”, ”n ”, ”en”, ” s”,
”le”, ” l”, ” c”, ”de”, (’arrowleft’, ’arrowright’), ”
p”, ” d”, ”on”, ”t ”, ”es”, ”s ”, ”e ”, (’backspace’,
’backspace’). The following durations are measured:
• P
1
R
1
: first character pressure;
• P
2
R
2
: second character pressure;
• P
1
P
2
: between the two characters push;
Figure 4: Personal information collection: distribution of
the user agent (raw data).
• R
1
R
2
: between the two characters release;
• R
1
P
2
: between the first character release and the
second push;
• P
1
R
2
: between the first character push and the se-
cond release.
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
270

3.2 Data Pre-processing
To obtain, for each modality, a fixed-size real vector
(required for the protection scheme), collected data
are converted to real vectors then appended. The dis-
tance between two vectors might be influenced by ex-
tremes values, they are consequently normalized.
3.2.1 Browser
Localkey (n-bits key) is converted into a n-bits vec-
tor. Thus, the 16-bits localkey ”0x0123”, is converted
into [0,0,0,0, 1,0,0,0, 0,1,0,0, 1,1,0,0].
3.2.2 Localisation
An IP address is converted in a vector composed by:
• a vector composed by the IP address bits divided
by 2
32−p−1
with p (bit weight);
• a vector composed by the 128/2
k
first bits of the
locality name’s md5 hash with k=1 for ”country”,
k=2 for ”region”, k=3 for ”county”, and k=4 for
”town”;
• a vector composed of 3 angles ∈ [−90; +90] re-
presenting the GPS localization’s latitude (lat),
and the longitude l (lng1, lng2); lng1 and lng2 are
equal to:
sign(α) ∗ ||α| − (|α| > 90) ∗ 180|
with α = l for lng1 and α = rot90(l) = (l −
90)%360 − 180 for lng2. These angles in degree
are normalized by the following formula:
angle
∗
= (angle + 90)/180
As for example, the IP adress ”127.0.0.1” is
converted in [0, 0.5, 0.25, 0.125, 0.0625, 0.03125,
0.015625, 0, 0.0078125, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4.6566 ∗ 10
−10
].
The following GPS localization (135, 0) is converted
in [0.5, 0.75, 0.25].
3.2.3 Network Data
Referer, User-Agent, Connection and Cookie are con-
verted into histograms, vectors giving for each cha-
racter its headcount. Only the ASCII characters
∈ [0x20,0x7F[, so 95 characters, are considered.
Accept, Accept-Encoding, and Accept-Language are
converted into vectors giving the preference for each
format, encoding, and language from a predefined
list. An additional value indicates the presence of
spaces after comma in the field. DNT and Upgrade-
Unsecure-Requests are converted into a 1-integer vec-
tor, equals to 1 if setted, 0 otherwise. The predefined
lists are:
• Accept: ”text/html”, ”application/xhtml+xml”,
”application/xml”, ”image/webp”, ”image/jxr”;
• Accept-Encoding: ”gzip”, ”deflate”, ”br”, ”sdch”;
• Accept-Language: ”fr”, ”fr-FR”, ”en-US”, ”en”.
As for exemple, the following User-Agent va-
lue ”Browser/1.0 (Operating System; rv:1.0) En-
gine/20170701 Browser/1.0” is converted by consi-
dering only characters in [a-z] by [1, 0, 0, 0, 5, 0, 2,
0, 2, 0, 0, 0, 1, 3, 2, 1, 0, 6, 3, 2, 0, 1, 2, 0, 1, 0]. The
Accept-Language ”fr;q=0.8, fr-FR;q=0.5, en-US” is
described by [0.8, 0.5, 1, 0, 1]. The DNT value ”1”
is converted in [1].
3.2.4 Biometric Data
The collected durations are converted into a vector
giving, for each considered digram, the means of
the 6 durations. These average values are conver-
ted in milliseconds, limited by 1000 then divided by
1000. Figure 5 presents the signature values after
pre-processing (here 1218 values). This step permits
to protect the semantic content of the signature, we
propose to enhance this protection thanks a dedicated
process presented in the next section.
Figure 5: Example of raw values after pre-processing (1218
real values).
3.3 Data Protection
The issue we want to address in this work is the
possibility to answer to Internet services applications
(s.a. authentication, attacks detection) while preser-
ving the user privacy. From the personal information
collected, we aim at generating a binary signature as
dynamical user characteristics having lost its seman-
tic description. Finally, the service is able to exploit
this signature without knowing the information used
to generate it.
Biohashing is a well-known algorithm in biometrics.
It enables a biometric data transformation when repre-
sented by a fixed-size real vector. It allows the gene-
ration of a binary model called BioCode having a size
Towards a Personal Identity Code Respecting Privacy
271

Figure 6: Personal information collection questionnaire’s screens.
inferior or equal to the original size. This transforma-
tion is non-reversible and allows to keep input data si-
milarity. This algorithm originally has been proposed
for face and fingerprints by Teoh et al. in (Teoh et al.,
2004). Biohashing algorithm can be used on every
biometric modality, or personal information, that can
be represented by a fixed-size real vector. This trans-
formation requires a secret linked to the user. In our
case, this could be a password input by the user (La-
charme and Plateaux, 2011). The BioCode compari-
son is realized by the computation of the Hamming
distance. The BioHashing algorithm transforms a pa-
rameter vector T = (T
1
,...T
n
) into a binary model
called BioCode B = (B
1
,...B
m
), with m ≤ n, as fol-
lows:
1. m random orthonormal vectors V
1
,...,V
m
of
length n are generated from a secret used as a
seed for random draw (typically with the Gram
Schmidt algorithm).
2. For i = 1, .. ., m, compute the dot product x
i
=<
T,V
i
>.
3. BioCode computation B = (B
1
,..., B
m
) with the
quantization process:
B
i
=
0 if x
i
< τ
1 if x
i
≥ τ,
Where τ is a given threshold, generally equals to
0.
The algorithm performance is granted by the dot
product with orthonormal vectors, as detailed in (Teoh
et al., 2008). The quantization process guarantees the
data non-reversibility (even if n = m), as each input
coordinate T is a real value, when the BioCode B is
binary. We propose the use of this transformation to
protect personal information.
4 EXPERIMENTS
In this section, we first detail the used experimental
protocol. Second, some preliminaries results are gi-
ven to show the binary code computation benefits.
4.1 Experimental Protocol
An acquisition campaign as be organized in march
2017 in the trust.greyc.fr website. The participants
have been recruited from the GREYC laboratory and
the engineering school ENSICAN, broadcast lists.
Thus, collected data come from an unique place, in-
deed the majority of the participants are localized in
Caen, use the same networks (ENSICAN and UNI-
CAEN), and thus have the same IP address. Mo-
reover, the use of GREYC and ENSICAEN devices
make the participants configuration, and network data
quite similar. With only 22 participants, mostly loca-
ted in Caen, the sample is not representative, but ena-
bles a first experimentation of the personal identity
code. During the acquisition, participants are invited
to answer to 8 questions on privacy, then to copy an
extract of the Universal Declaration of Human Rights
(see 6). To prevent any influence for the keystroke dy-
namics, participants are informed of the information
collection only from the step 5, where they are invi-
ted to give the authorization to use personal informa-
tion for research purposes. All the collected data are
stored in the browser sessionStorage and are submit-
ted only after user validation through the confirmation
page, resuming the collected information types, and
detailing collected information. Once the data sub-
mitted, a localkey is generated and stored inside the
browser localStorage, to recognize the browser upon
multiples submissions. The localkey is also printed
to users so that they can exercise their right of data
access and correction.
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
272

4.2 Experimental Results
From the 29 collections, from 22 users (8 have been
made by the same user in different contexts), we es-
timate in which proportion these information enable
to compute users similarity. Figure 7 presents the dis-
tribution of BioCodes comparisons for all users using
different collected information and the total. In green,
are represented intra-users comparisons between Bio-
Codes and in blue inter-users comparisons. The distri-
bution of BioCodes generated by taking into account
only localization (Figure 7 (a)) show some errors to
discriminate users. Indeed, the same user provided
some information at different localizations (someti-
mes more similar to other users). The BioCode ge-
nerated using the PHP environment and the total, per-
mits to clearly discriminate users from each others.
Figure 8 shows two distance matrices. The first (a)
compare pre-processed data (without any protection)
with the cosine distance (1 − cos(A,B), if A and B
are two real vectors. In this figure, we can notice two
things. The first is that the signatures 4 and 5 are jud-
ged very similar. This is in fact the same user in the
same context. The only difference is in the keystroke
dynamics. Signatures 3 to 10 have been generated
by the same user, but in different contexts (s.a. Wifi,
browser), the similarity is more contrasted. The se-
cond important observation is the relative similarity of
the signatures 4 and 5 with others signatures. This can
be explained as these signatures have been acquired
inside the laboratory with devices with similar con-
figurations and IP address. Figure 8 (b) represents
the distances between BioCodes (protected signatu-
res) with, for each user, an unique secret key. With
the protection and these keys, we highlight the simi-
larity between users. For binary codes linked to sig-
natures 3 to 10, we identify a similarity between then
with variations depending on the similarity of perso-
nal information. This demonstrates the capacity of the
proposed method to produce an exploitable code for
personal information similarity computation.
Regarding the requirements previously announ-
ced, it is easy to verify their accordance. The
BioHashing algorithm used to compute the binary Bi-
oCode allows non-reversibility and the capability to
compute the similarity of users identity. The data con-
fidentiality is obtained with this last transformation
and a secret key usage (here a password). An impos-
tor would not be able to generate such binary code
without knowing the secret key, and using the same
device. An impostor, at better, replays an existing
data. However, the protection of the communica-
tion channel, and of the data on the service-side solves
(a)
(b)
(c)
Figure 7: Distribution of BioCode comparisons for all
users: (a) localisation BioCode, (b) PhP environment Bio-
Code, (c) total BioCode. In green, are represented intra-user
comparisons and in blue inter-users comparisons.
this problem. The code revocation is trivial by
changing the secret key (i.e. here, the password).
5 CONCLUSION AND
PERSPECTIVES
In this paper, we propose a method enabling to com-
pute a personal code linked to an user while re-
specting their privacy. This code incorporates diffe-
rent information linked to the browser, keystroke dy-
namics, or localization. We showed on a preliminary
dataset composed of 29 collections that it was pos-
Towards a Personal Identity Code Respecting Privacy
273

(a)
(b)
Figure 8: Information comparison between the pre-
processed data (a) and after protection (b). In coordinates,
the compared entries’ number. Blue for an high similarity,
red for low.
sible to obtain a binary code similar for a same user
in spite of differences of contexts. Many applications
are conceivable from this work s.a. user authentica-
tion, multi-account identifications. These applicati-
ons constitute this study perspectives.
ACKNOWLEDGMENTS
Authors would like to thank the Normandy Region for
the financial support of this work.
REFERENCES
Tableau de bord des services pu-
blics numriques dition 2017.
http://www.modernisation.gouv.fr/ladministration-
change-avec-le-numerique/par-des-services-
numeriques-aux-usagers/tableau-de-bord-des-
services-publics-numeriques-edition-2017.
Boda, K., F
¨
oldes,
´
A., Guly
´
as, G., and Imre, S. (2012). User
tracking on the web via cross-browser fingerprinting.
Information Security Technology for Applications, pa-
ges 31–46.
Cao, S. Y. and Wijmans, E. (2017). Browser fingerprinting
via os and hardware level features. Network & Distri-
buted System Security Symposium, NDSS, 17.
Dafer, M. and El-Abed, M. (2017). Evaluation of keystroke
dynamics authentication systems: Analysis of physi-
cal and touch screen keyboards. In Developing Next-
Generation Countermeasures for Homeland Security
Threat Prevention, pages 306–329. IGI Global.
Eckersley, P. (2010). How unique is your web browser?
Privacy Enhancing Technologies, 6205:1–18.
Gaines, R., Lisowski, W., Press, S., and Shapiro, N. (1980).
Authentication by keystroke timing: some prelimi-
nary results. Technical report, Rand Corporation.
Garcia, J. D. (1986). Personal identification apparatus. US
Patent 4,621,334.
Giot, R., El-Abed, M., Hemery, B., and Rosenberger, C.
(2011). Unconstrained keystroke dynamics authen-
tication with shared secret. Computers & Security,
30(6):427–445.
Giot, R., El-Abed, M., and Rosenberger, C. (2009). Greyc
keystroke: a benchmark for keystroke dynamics bio-
metric systems. In Biometrics: Theory, Applications,
and Systems, 2009. BTAS’09. IEEE 3rd International
Conference on, pages 1–6. IEEE.
Lacharme, P. and Plateaux, A. (2011). Pin-based cancelable
biometrics. International Journal of Automated Iden-
tification Technology (IJAIT), 3(2):75–79.
Laperdrix, P., Rudametkin, W., and Baudry, B. (2016).
Beauty and the beast: Diverting modern web brow-
sers to build unique browser fingerprints. Security and
Privacy (SP), pages 878–894.
Nikiforakis, N., Joosen, W., and Livshits, B. (2015). Priva-
ricator: Deceiving fingerprinters with little white lies.
Proceedings of the 24th International Conference on
World Wide Web, pages 820–830.
Phoaha, V. V., Phoha, S., Ray, A., Joshi, S. S., and Vuyyuru,
S. K. (2009). Hidden markov model (hmm)-based
user authentication using keystroke dynamics. patent.
Teoh, A., Ngo, D., and Goh, A. (2004). Biohashing: two
factor authentication featuring fingerprint data and to-
kenised random number. Pattern recognition, 40.
Teoh, A. B., Kuan, Y. W., and Lee, S. (2008). Cancellable
biometrics and annotations on biohash. Pattern Re-
cognition, 41:2034–2044.
Weinberg, Z., Chen, E. Y., Jayaraman, P. R., and Jackson,
C. (2011). I still know what you visited last summer:
Leaking browsing history via user interaction and side
channel attacks. Security and Privacy (SP).
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
274
