
ResPred: A Privacy Preserving Location Prediction System Ensuring
Location-based Service Utility
Arielle Moro and Beno
ˆ
ıt Garbinato
Institute of Information Systems, University of Lausanne, Lausanne, Switzerland
Keywords:
Location Prediction, Location Privacy-preserving Mechanism, Threat Model, Inference Attack, Location-
based Services.
Abstract:
Location prediction and location privacy has retained a lot of attention recent years. Predicting locations is the
next step of Location-Based Services (LBS) because it provides information not only based on where you are
but where you will be. However, obtaining information from LBS has a price for the user because she must
share all her locations with the service that builds a predictive model, resulting in a loss of privacy. In this
paper we propose ResPred, a system that allows LBS to request location prediction about the user. The system
includes a location prediction component containing a statistical location trend model and a location privacy
component aiming at blurring the predicted locations by finding an appropriate tradeoff between LBS utility
and user privacy, the latter being expressed as a maximum percentage of utility loss. We evaluate ResPred from
a utility/privacy perspective by comparing our privacy mechanism with existing techniques by using real user
locations. The location privacy is evaluated with an entropy-based confusion metric of an adversary during a
location inference attack. The results show that our mechanism provides the best utility/privacy tradeoff and a
location prediction accuracy of 60% in average for our model.
1 INTRODUCTION
In recent years, predicting future locations of users
has become an attractive topic for both the research
community and companies. Location prediction can
boost the creation of new Location-Based Services
(LBS) in order to help users in their daily activities.
For example, a LBS could send personalized infor-
mation to users, such as the menu of different restau-
rants the users could like in the vicinity of a location
in which they will probably be at a specific time, e.g.,
Monday between 11:30 and 12:00 am. In order to ob-
tain future locations of a user, a LBS needs to build
a predictive model containing spatial and temporal
information. However, this leads to a first location
privacy issue because the user must send all her raw
locations to a third-party entity as described in Fig-
ure 1 (a). In this architecture, the LBS, which can
be malicious, is installed on the mobile device of the
user and gathers all user locations. To preserve loca-
tion privacy, the idea is to create a location predictive
model in a trusted component that can be stored at the
operating system level of the mobile device. In this
context, the trusted component itself will provide the
future locations of the user to the LBS as depicted in
Figure 1 (b). Even after a large number of requests
performed by the LBS, it should not be able to recon-
struct the entire predictive model of the user but may
have a good partial view of her model. As a result,
this is a undeniable second location privacy issue. It
has been demonstrated in the literature that sharing
accurate locations has a real cost for a user because a
potential adversary cannot only discover a lot of sen-
sitive information related to the user but also identify
her by just performing simple location attacks as de-
scribed by Krumm in (Krumm, 2007). In addition,
the authors of (Zang and Bolot, 2011) show that a few
number of user’s locations only might highly compro-
mise the location privacy of a user.
Because of the availability of different positioning
systems on mobile devices, LBS are very convenient
for daily activities. Consequently, users cannot com-
pletely avoid using LBS. However, users must know
that it is fundamental to preserve their privacy when
they are using LBS. Currently, users can only enable
or disable the access to locations for specific applica-
tions and sometimes reduce the precision of the loca-
tions obtained with a positioning system. These op-
tions depend on the operating system itself. These
simple choices are not adapted to the context of our
work because we want to preserve the location pri-
vacy of the user at a higher level, which is a loca-
Moro, A. and Garbinato, B.
ResPred: A Privacy Preserving Location Prediction System Ensuring Location-based Service Utility.
DOI: 10.5220/0006710201070118
In Proceedings of the 4th International Conference on Geographical Information Systems Theory, Applications and Management (GISTAM 2018), pages 107-118
ISBN: 978-989-758-294-3
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
107
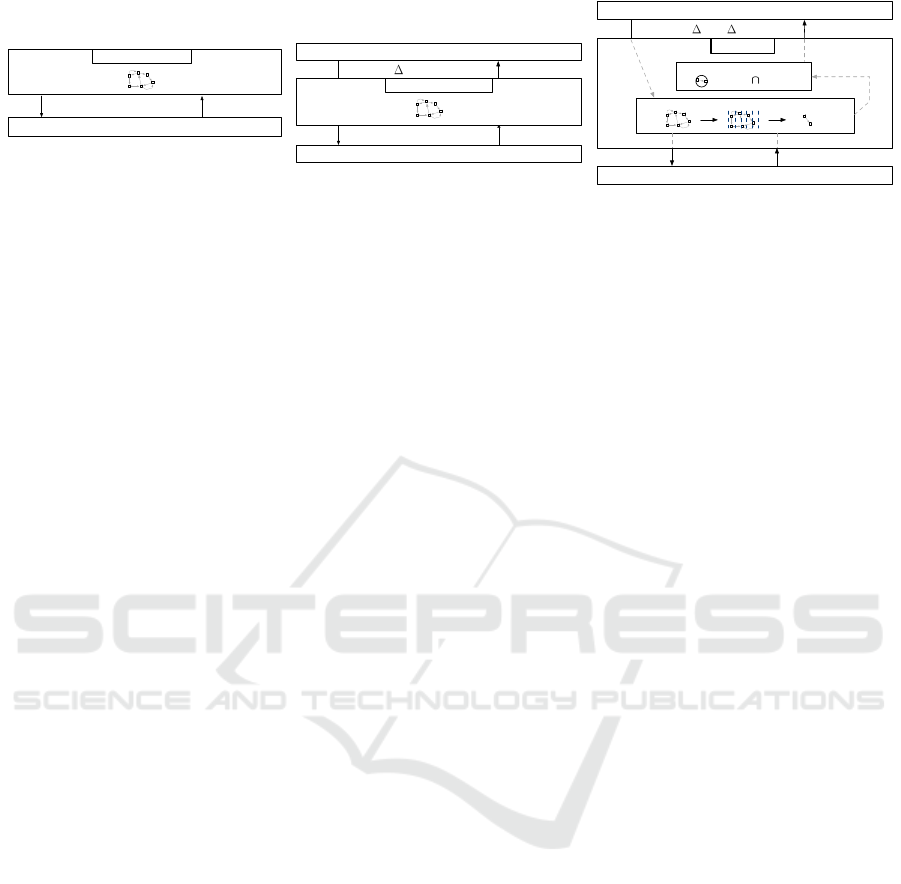
Location-based service
Positioning system
predictLoc( tfuture)
Positioning system
Location-based service
loccurrent
getCurrentLoc()
Location-based service
Positioning system
Location trend model
Location-privacy process
ResPred system
=> LBS utility User privacy
(a) First architecture (b) Second architecture (c) Third architecture including ResPred system
Location prediction service
locpredicted
loccurrent
getCurrentLoc()
predictLoc( tfuture, rutility)
locpredicted
getCurrentLoc()
loccurrent
Figure 1: Problem/contribution overview through three different system architectures.
tion prediction level. In order to protect raw loca-
tions of a user, some existing Location Privacy Pre-
serving Mechanisms (LPPMs) can be applied, such as
spatial perturbation, spatial cloaking, sending dummy
locations as well as spatial rounding, as discussed
in (Krumm, 2007; Gambs et al., 2011; Agrawal and
Srikant, 2000; Gruteser and Grunwald, 2003; Kido
et al., 2005). Nevertheless, these mechanisms may
quickly decrease the utility level of a LBS as the level
of protection increases, up to the point when the LBS
becomes unusable.
In this paper, we present a privacy preserving lo-
cation prediction system called ResPred, res and pred
mean respect (i.e., respect the privacy of users) and
prediction respectively. This system allows LBS to re-
quest future location of users. For instance, a LBS can
display information containing future public trans-
portation departures located in the vicinity of the pre-
dicted location returned by ResPred on the mobile de-
vice of the user in advance. Figure 1 (c) presents the
ResPred system that contains two components: one
component focuses on the location prediction and the
second on the location privacy. We assume that the
ResPred system is created at the operating system
level of the mobile device and that the ResPred sys-
tem and the positioning system are trusted. The sys-
tem includes a location prediction component based
on a statistical location trend model and a location
privacy component helping to blur the predicted lo-
cations by finding an appropriate tradeoff between
the LBS utility and the user privacy preference ex-
pressed as a maximum percentage of utility loss. We
also assume that the LBS is untrusted, which indicates
that it is a possible adversary. As depicted in Fig-
ure 1 (c), the LBS requests the future location of the
user by indicating a time duration between the cur-
rent time and the time of the desired predicted loca-
tion and the system returns a predicted location that
will be found by exploring the location trend model
and protected by our LPPM. The predicted location
is more specifically transformed according to the re-
quired utility level of the LBS and the maximum util-
ity level that the user is willing to sacrifice in order
to protect her location privacy. We evaluate our sys-
tem from a utility/privacy perspective, which is the
crucial aspect of our approach. In addition, we com-
pute the location prediction accuracy of the location
trend model. We chose real mobility traces com-
ing from two datasets, thePrivaMov dataset described
in (Ben Mokhtar et al., 2017) and a private dataset col-
lected by a researcher in Switzerland. The first part of
the utility/privacy evaluation consists in assessing the
utility level of our LPPM and two other well-known
mechanisms described in the literature, namely the
rounding and the Gaussian perturbation. The sec-
ond part of the utility/privacy evaluation focuses on
the measurement of the confusion level of an adver-
sary performing a location attack on the received pre-
dicted locations from the ResPred system. The met-
ric used to evaluate this confusion level is based on
the well-known Shannon entropy. The results show
that our location privacy preserving mechanism pro-
vides the best utility/privacy tradeoff compared to the
other evaluated mechanisms as well as a good loca-
tion prediction accuracy for the analyzed users. The
contributions of this paper are listed below.
• We describe a system, called ResPred, allowing
LBS to request future location of a user.
• We present a statistical model containing location
trends of a user per time slice, helping to extract
short, mid and long-term predicted locations.
• We describe a LPPM enabling to reach an appro-
priate utility/privacy tradeoff.
• We use real user locations to assess our system
and, more specifically, its two components.
The paper is organized as follows: in Section 2 we
begin with the description of the system model con-
taining the formal definitions used in the paper. Sec-
tion 3 presents the problem addressed in this paper,
while the ResPred system is described in Section 4.
Then, we present the evaluation of the system from a
utility/privacy perspective in Section 5. In addition,
we also evaluate the location prediction accuracy of
GISTAM 2018 - 4th International Conference on Geographical Information Systems Theory, Applications and Management
108

the location trend model of the ResPred system. We
detail the closest work to the two main subjects of this
paper in Section 6, which are the location privacy as
well as the location prediction. Finally, we highlight
the most important findings of the paper and discuss
future work in Section 7.
2 SYSTEM MODEL
This section focuses on describing the key defini-
tions used to present our system. In order to fa-
cilitate the analysis of locations of a user, the time
is discretized. We also introduce Regions Of Inter-
est (ROIs) on which the location predictive model is
based. Finally, we present the threat model that de-
scribes the context used to evaluate the location pri-
vacy.
2.1 User and Locations
We consider that a user is moving on a geodesic space
and is owning a mobile device that is able to de-
tect her locations as well as when they are captured
via a positioning system, e.g., GPS, WiFi or radio
cells. A location is described as a triplet loc = (φ, λ,t)
where φ and λ are the latitude and longitude of the lo-
cation in the geodesic space, and t is the time when
the location was obtained from the positioning sys-
tem. Locations are formally represented as a se-
quence L = hloc
1
, loc
2
, ·· · , loc
n
i. A subsequence of
successive location of L is described as follows l
sub
i
=
hloc
1
, loc
2
, ·· · , loc
m
i in which the first location of this
subsequence is noted l
sub
i
.loc
f irst
and the last location
is l
sub
i
.loc
last
. We can express the latitude, longitude
and time of a location loc
i
by directly writing loc
i
.φ,
loc
i
.λ and loc
i
.t respectively.
2.2 Temporal Discretization
In order to discretize time, we compute n slices gen-
erated according to the chosen temporal granular-
ity and time span, e.g., every 20 minutes during
one week. A time slice is a triplet defined as fol-
lows ts = (t
starting
,t
ending
, index) where t
starting
(Mon-
day - 7:00 am) and t
ending
(Monday - 7:20 am) rep-
resent the starting time and ending time of the time
slice and index is its unique identifier ranging be-
tween 1 and n (n represents the total number of
computed time slices). For instance, if we gener-
ate all time slices having a duration of 20 minutes
during a period of 1 week, we will obtain 504 time
slices. All the possible time slices are represented as
a sequence called timeslices, such that timeslices =
hts
1
,ts
2
, ·· · ,ts
n
i. In addition, we introduce a func-
tion called convert(hloc
1
, loc
2
, ·· · , loc
m
i) translating
a sequence of one or several successive locations into
a sequence of one or several successive time slices
called timesliceTab, m being the total number of lo-
cation(s) to convert. This sequence is described as
follows: timesliceTab = hts
1
,ts
2
, ·· · ,ts
n
i in which n
is the total number of successive time slices.
2.3 Regions of Interest
A region of interest (ROI) is defined as a circular area
visited by a user during a certain period of time, which
is a quadruplet of the form roi = (φ, λ, ∆r, visits).
Items φ and λ are the coordinates of the center of
the ROI in a geodesic space. ∆r is the radius of the
ROI and visits is a sequence of subsequences of L
such as visits = hl
sub
1
, l
sub
2
, ··· , l
sub
m
i in which each
subsequence of successive locations is contained in L
such that ∀l
sub
i
∈ visits, l
sub
i
⊂ L and l
sub
i
.loc
last
.t <
l
sub
i+1
.loc
f irst
.t. Each visit of a ROI has a duration
equal or greater than a threshold, called ∆t
min
, such
as ∀l
sub
i
∈ visits, l
sub
i
.loc
m
.t −l
sub
i
.loc
1
.t >= ∆t
min
. In
addition, all locations of the visits are contained in
the ROI spatially described by the first three items
of it, i.e., latitude, longitude and radius. The set
containing all ROIs of a user can be noted as fol-
lows: rois = {roi
1
, roi
2
, ··· , roi
n
}. The last and im-
portant characteristic of the ROI is that there is no
spatial intersection between ROIs. This means that,
if two ROI candidates intersect during the discovery
process of ROIs, they will be merged and a new ROI
is created from these two ROI candidates.
2.4 Threat Model
We consider a threat model that takes into account a
honest but curious adversary in the form of a LBS us-
ing ResPred. The LBS will try to infer future loca-
tions of the user based on a location history gathered
by requesting ResPred. This location history contains
all predicted locations sent by ResPred and consists
in its unique background knowledge on which the lo-
cation attack will be performed. This history is not
complete because we consider that the LBS will not
request ResPred constantly but a limited number of
times in a random manner during a certain time slice
or by following the usual use of the LBS by the user,
e.g., everyday at the end of the afternoon. The honest
but curious behavior of the LBS also means that it will
not try to break the sharing protocol or obtain the lo-
cation predictive model of the system ResPred. In ad-
dition, we consider that the LBS always gives adapted
parameters to its service to the ResPred system, more
ResPred: A Privacy Preserving Location Prediction System Ensuring Location-based Service Utility
109
specifically the values of the parameters ∆t
f uture
and
∆r
utility
as depicted in Figure 1 (c) or Figure 2.
3 PROBLEM STATEMENT
Considering that a LBS wants to estimate the future
location of a user, it needs to create a predictive model
of the user. In order to reach this goal, the LBS will
constantly collect locations of the user to update her
model as shown in Figure 1 (a). However, the location
privacy of user is entirely compromised because all
her raw locations are regularly shared with the LBS.
This means that all sensitive information related to the
user is given to a third-party entity. For example, the
LBS can discover the following sensitive information
related to the user from her raw locations: her home
and work places but also her likes and dislikes about
religion and/or politics.
The first solution is to delegate the creation of the
predictive model to a service at the operating system
level that we consider as trusted, as shown in Figure 1
(b). In this context, the only service that has access
to the raw locations of the user coming from the po-
sitioning system is the dedicated service. The latter
provides predicted locations to the LBS that needs
them to operate properly. Although the location pri-
vacy of the user is increased in this context, there is
still a location privacy issue about the predicted lo-
cations shared with the LBS. Because of all the pre-
dicted locations gathered by the LBS, the latter can
always infer precise location habits of the user, espe-
cially when it is requesting the trusted service for the
same future time every day for instance.
Consequently, the challenge is to protect as much
as possible the location privacy of the user in the con-
text of the sharing of her predicted locations with a
LBS. Although there exist various LPPMs in the lit-
erature, they do not necessarily meet the utility re-
quirement of a LBS. This means that they can easily
compromise the proper functioning of the LBS until
reaching the point it becomes unusable for the user.
For example, the location information provided by
the LBS can be inaccurate or simply erroneous be-
cause the precision of the prediction has been made
too low by the LPPM. As a result, the user might stop
using the LBS. As discussed in the introduction, our
approach consists in building a system, including a lo-
cation predictive model as well as an adapted LPPM,
that takes into account the utility requirement of the
LBS and the utility/privacy tradeoff expressed by the
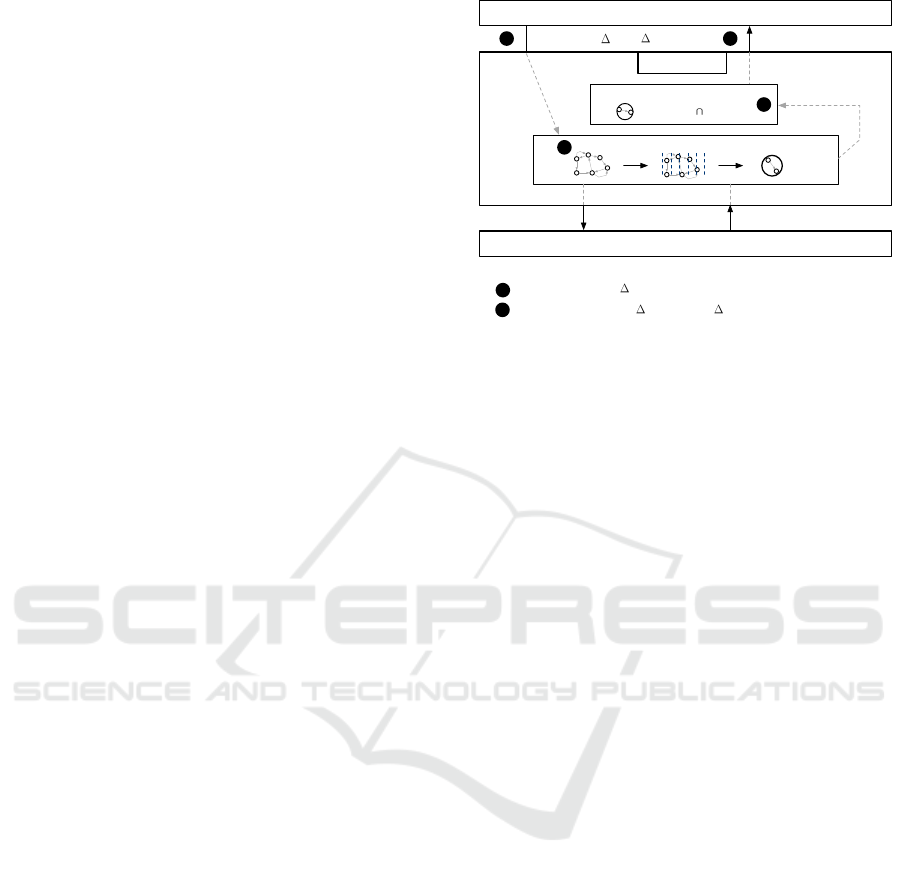
user as indicated in Figure 1 (c) or Figure 2.
Location-based service
Positioning system
Location trend model
Location-privacy process
predictLoc( tfuture, rutility)
1
getCurrentLoc() loccurrent
predictLoc(loccurrent, tfuture) = tmpLocpredicted
2
3
2
3
ResPred system
=> LBS utility User privacy
protect(tmpLocpredicted, pmaxUtilityLoss, rutility) = locpredicted
4
locpredicted
Figure 2: ResPred system overview.
4 SYSTEM OVERVIEW
As described in Figure 2, ResPred contains two com-
ponents. The first component focuses on location pre-
diction, while the second component relates to loca-
tion privacy. Consequently, the first component is re-
sponsible for the prediction of the future location of
the user and includes her predictive location model,
called location trend model. The second component
aims at protecting the predicted location computed by
the first component and uses a LPPM called utility
privacy tradeoff LPPM.
A request of a LBS consists in asking where a user
will be in the future. As described in Equation 1,
the LBS requests the future location by specifying
the time duration expressed by ∆t
f uture
in seconds
from the current time, e.g., 7200 seconds (2 hours)
from now. The LBS also indicates its required util-
ity ∆r
utility
that allows it to operate properly. For in-
stance, if a LBS must call a taxi for a user in advance,
the LBS will indicate an utility of a short distance in
meters, such as 500 meters. A long distance could
compromise the use of the taxi service itself and the
related LBS because it could display inaccurate infor-
mation to the user. The returned value is a location
expressed by a pair loc
predicted
= (φ, λ).
predictLoc(∆t
f uture
, ∆r
utility
) = loc
predicted
(1)
To summarize, ResPred will answer the following
question: Where will be the user in ∆t
f uture
second(s)
from now?
4.1 Location Prediction Component
The location prediction component contains a predic-
tive model that represents the location trends of a user
organized per time slice. As mentioned in Section 2,
GISTAM 2018 - 4th International Conference on Geographical Information Systems Theory, Applications and Management
110

TS1 TS2 TS3 TS4 TS5 …
…
ROI discovery Temporal and spatial matching Location trend model
1
1
2
2
3
3
4
4
5
5
6
6
1
2 2
2
2
2
3
6
3
Figure 3: From ROIs to location trend model.
time is discretized into time slices during a given pe-
riod of time, such as 504 time slices during one week
(i.e., the duration of one time slice is 20 minutes). A
location trend model is an array in which each cell
contains all the possible ROIs or successive ROIs vis-
ited during a specific time slice. Figure 3 describes the
creation process of the location trend model. Firstly,
the ROI discovery process enables to discover all the
ROIs of a user by analyzing the raw locations of the
user. Secondly, all raw locations are marked with a
specific ROI and a specific time slice as specified in
the Temporal and spatial matching step. This step
helps to pre-process the locations for the creation of
the location trend model. Finally, we discover the
structure of the location trend model in which we col-
lect all the ROIs or successive ROIs visited during
each time slice. Since the location trend model is a
statistical model, each visited ROI or successive vis-
ited ROIs stored for a given time slice have a visit
counter. This enables to highlight the location habits
of the user per time slice, i.e., the ROIs or succes-
sive ROIs that are the most visited by the user during
a time slice. In addition, this allows the component
to find the predicted locations to answer the LBS re-
quests.
As depicted in Figure 2, the location trend model
will have to solve the following request expressed in
Equation 2 and return a temporary predicted location
tmpLoc
predicted
. The latter is not the final predicted
location sent to the LBS at the end of the process be-
cause tmpLoc
predicted
must be protected by the LPPM
of the location privacy component.
predictLoc(loc
current
, ∆t
f uture
) = tmpLoc
predicted
(2)
In order to find the tmpLoc
predicted
, the location
prediction component starts by searching the target
time slice corresponding to the time slice that in-
cludes the future time computed by adding the ∆t
f uture
duration to the current timestamp, i.e., loc
current
.t.
After having found this target time slice, the lo-
cation trend model is analyzed to find the location
trends corresponding to the target time slice expressed
as ROI(s). The tmpLoc
predicted
is a triplet such as
tmpLoc
predicted
= (φ, λ, ∆r). Item ∆r is a radius that
is the accuracy of the temporary predicted location.
There are two cases now to compute the items of the
tmpLoc
predicted
. Firstly, if the analysis highlights that
the most likely visited location in the target time slice
corresponds to one ROI, the temporary predicted lo-
cation has the same latitude, longitude and radius as
those of the ROI. Secondly, if the analysis shows that
the most likely visited locations are two or several
successive ROIs, the component merges all the ROIs
into one single ROI and computes a new latitude, a
new longitude and a new radius, which correspond
to the items of the tmpLoc
predicted
. In addition, it is
important to note three specific location prediction
scenarios that can occur during the prediction pro-
cess. The best scenario is that the component finds
the most likely ROI or successive ROIs to compute
the tmpLoc
predicted
by exploring the location trends of
the target time slice. Secondly, it can happen that all
ROIs or successive ROIs have the same visit counter
value. In this context, the last visited ROI or suc-
cessive ROIs are used to compute the tmpLoc
predicted
.
Finally, it is also possible that there is no ROI or suc-
cessive ROIs recorded for the target time slice. For
this unique and specific problem, the component ex-
plores previous time slices until finding a visited ROI
or successive ROIs to compute the tmpLoc
predicted
.
4.2 Location Privacy Component
The goal of the location privacy component is to pro-
tect as much as possible the temporary predicted loca-
tion found by the location prediction component. The
LPPM that will be applied on the tmpLoc
predicted
de-
pends on two aspects: the LBS utility ∆r
utility
given
by the LBS and the user privacy preference given by
the user expressed as a maximum utility loss percent-
age ∆p
maxUtilityLoss
. This means that the LBS can
provide useful and relevant information in a radius,
which is the LBS utility in meters, around a reference
location. Beyond this distance, there is no guarantee
that the LBS is able to operate properly or to provide
a reliable information to the user. For example, if the
LBS is an application of a taxi company and asks a
predicted location, at the end of day when the user
usually requests the LBS for a taxi, in order to antic-
ipate the user’s request, the LBS will indicate a close
utility in meters in order to not be far from the user in
a future time. The maximum utility loss is expressed
as a percentage that clearly indicates the maximum
utility that the user is willing to sacrifice in order to
protect her location privacy. Consequently, its value
is a percentage ranged between 0 included and 1 not
included. 0 is included and means that the user sim-
ply does not want to lose any LBS utility. 1 is not in-
cluded because this would mean that the LBS cannot
work properly if this value is reached. Equation 3 de-
scribes the request handled by the component includ-
ResPred: A Privacy Preserving Location Prediction System Ensuring Location-based Service Utility
111
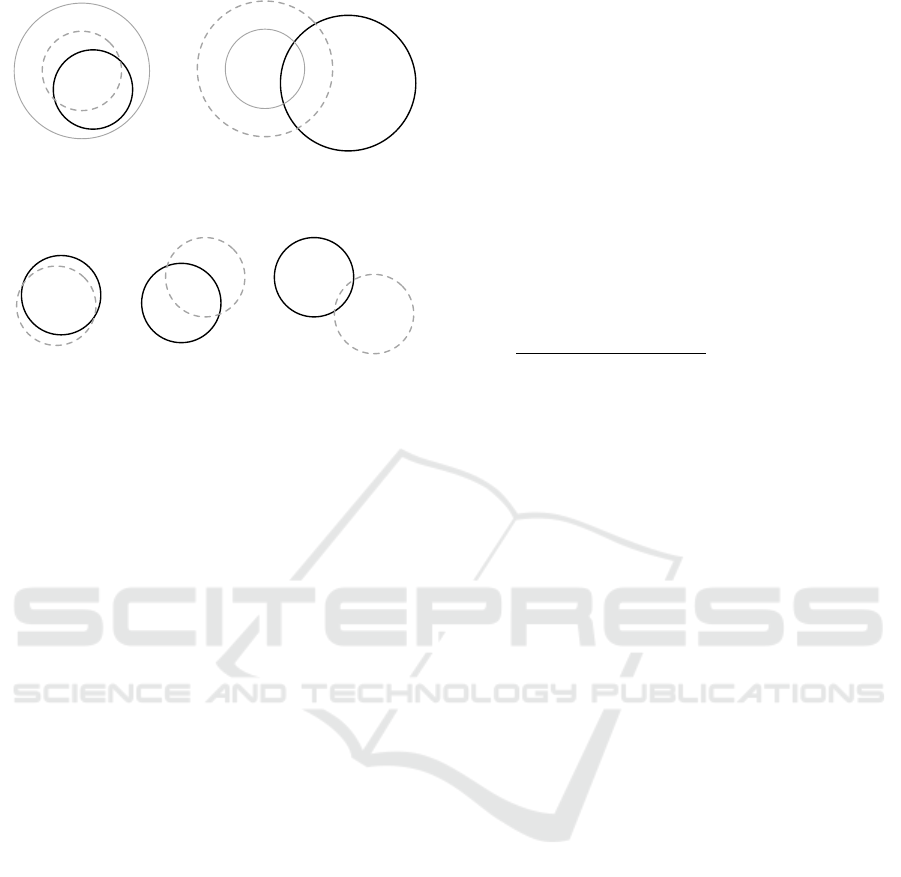
x
x
x
x
r
r
r
r
r
r
r
r
r
r
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
r
r
r
r
r
r
Figure 4: Computing new coordinates when the radius of
the reference zone is adjusted, i.e., greater or smaller than
the radius of tmpLoc
predicted
.
x
x
x
x
x
x
p
r
p
p
p
p
p
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
r
r
r
r
r
r
r
r
Figure 5: Three possible random generations of new coor-
dinates (position x in gray) according to a high maximum
utility loss percentage.
ing the LBS utility ∆r
utility
and the maximum utility
loss percentage ∆p
maxUtilityLoss
.
protect(tmpLoc
predicted
, ∆p
maxUtilityLoss
, ∆r
utility
)
= loc
predicted
(3)
The location privacy preserving mechanism works
in the following manner. The component firstly
creates a reference zone zone
re f
that has a lati-
tude and a longitude corresponding to those of the
tmpLoc
predicted
and a radius equals to the LBS util-
ity ∆r
utility
.
The goal of the component is now to change the
latitude and the longitude of the tmpLoc
predicted
by
computing new coordinates. The component will cre-
ate a new zone, called zone
new
, which is a zone having
the new generated latitude and longitude as coordi-
nates and a radius equals to the LBS utility ∆r
utility
. In
order to compute these new coordinates, the compo-
nent firstly generates a random angle that indicates the
direction of the new coordinates. Then, a latitude and
a longitude are generated randomly in the direction of
the angle between 0 and a threshold value correspond-
ing to the case where there cannot have any intersec-
tion between zone
re f
and zone
new
, i.e., 2 × ∆r
utility
.
Now the component must carefully check if the pro-
tected percentage of the zone
re f
is not greater than
the maximum utility loss percentage indicated by the
user, i.e., p
maxUtilityLoss
. In order to check this condi-
tion, the component computes the area of the intersec-
tion between the reference zone zone
re f
and the new
zone zone
new
. The area of this intersection is divided
by the area of the zone
re f
in order to obtain a released
percentage p
released
, which is shared with the LBS. Fi-
nally, the component computes the protected percent-
age that is equal to: p
protected
= 1 − p
released
. The new
coordinates are validated only if p
protected
is lower or
equal to the maximum utility loss percentage given by
the user. If it is not the case, new coordinates are gen-
erated until meeting this condition. When this condi-
tion is met, loc
predicted
is created with a latitude and
a longitude corresponding to the new coordinates and
is sent to the LBS. Therefore, there is a clear link be-
tween the utility that the user is willing to lose and her
location privacy because the greater the p
maxUtilityLoss
,
the better the user protects her location privacy. Equa-
tion 4 summarizes the checking of this condition. The
function area enables to compute the area of the ele-
ments passed as parameters.
1 −
area(zone
re f
∩ zone
new
)
area(zone
re f
)
<= ∆p
maxUtilityLoss
(4)
This means that the location privacy component
tries to find an appropriate tradeoff between LBS util-
ity and the location privacy preference chosen by the
user. In order to illustrate the process, Figure 4 de-
picts the impact of the change of the radius of the ref-
erence zone
re f
in the case where the tmpLoc
predicted
has a radius greater than ∆r
utility
and in the case where
tmpLoc
predicted
has a radius smaller than ∆r
utility
. The
tmpLoc
predicted
is the gray circle with the dotted lines,
the zone
re f
is the gray circle and the dark circle is the
zone
new
. The center of the zone
new
corresponds to the
location that is sent to the LBS by ResPred. The let-
ters r indicate the zone that is released to the LBS,
while the letters p describe the zone that is protected.
In addition, Figure 5 depicts three possible random
generations of new coordinates according to a maxi-
mum utility loss percentage that is really high. The
resulting value of the process of this component is the
predicted location loc
predicted
, which is also returned
to the LBS as described in Equation 3 and in Figure 2.
5 EVALUATION
The main goal of the evaluation is to assess our sys-
tem from a utility and a location privacy perspective.
In order to reach this goal, we ran several experiments
taking into account different LBS scenarios and dif-
ferent LPPMs including our mechanism and existing
ones. In addition, we also compute the location pre-
diction accuracy of the location trend model.
5.1 Dataset
We chose real user locations of two datasets: Priva-
Mov dataset described in (Ben Mokhtar et al., 2017)
and a very detailed dataset of one user. From these
GISTAM 2018 - 4th International Conference on Geographical Information Systems Theory, Applications and Management
112

two datasets, we extracted locations of users that
were captured via different positioning system such
as GPS, radio cells as well as WiFi. We performed
an analysis in order to select the best users of Pri-
vaMov for our evaluation. This selection was based
on the quality of the user datasets. This quality was
assessed by computing the percentage of hours dur-
ing one day having at least one location, called daily
percentage later. In order to properly fill the location
trend model, we need very rich user datasets without
important gaps in terms of days. More specifically,
a user is selected if the average of all her daily per-
centages is greater or equal to 0.4, if her dataset dura-
tion in terms of days was greater or equal to 30 days
and lower than 250 days and if all weekdays (from
Monday to Sunday) have at least one daily percent-
age. Seven users only of the PrivaMov dataset met all
these conditions. Consequently, we evaluated eight
users in total, i.e., seven users from PrivaMov and one
user from the private dataset. The average of the dura-
tion of all evaluated user datasets is 115 days and the
average of the number of locations of all evaluated
user datasets is 7’580’391.
5.2 LBS Scenarios
We decided to define two LBS scenarios for the evalu-
ation. The first scenario is a public transportation LBS
that provides next departure information of bus, metro
and train in advance. The information is displayed
on the mobile of the user just before the usual check-
ing of the public transportation departures by the user.
The second scenario is a taxi LBS that calls a taxi in
advance for the user by following the usual use of the
service by the user. We assume that the LBS knows
the usage habits of the service by the user but it does
not obviously know the location of the user in the fu-
ture. That is why these two LBS must use our Re-
sPred system to obtain it. As depicted in Figure 2, an
LBS can request a user’s location in the future, e.g., 2
hours from now. For each scenario, we chose an array
of target time slices for which the predicted locations
must be computed. The parameters of these two LBS
scenarios are defined in Section 5.4.
5.3 Existing Location Privacy
Preserving Mechanisms
In order to properly assess the LPPM of our system,
we selected two existing LPPMs from the literature.
We compare them with our mechanism from the util-
ity/privacy perspective whose metrics are detailed in
Section 5.6. We chose the spatial rounding presented
in (Krumm, 2007; Agrawal and Srikant, 2000) as well
as the Gaussian perturbation described in (Armstrong
et al., 1999). The spatial rounding works with a grid
that discretizes the space in which the user is moving.
The mechanism transforms raw coordinates of a loca-
tion into new coordinates corresponding to the nearest
vertex of the square or rectangle that is a grid’s cell in
which the raw location is. The spatial Gaussian per-
turbation is a mechanism that adds spatial noise to the
latitude and the longitude of a raw location according
to a certain mean and a standard deviation. All these
parameters are presented in next section.
5.4 Experimental Settings
The experimental settings of the utility/privacy eval-
uation as well as location prediction accuracy evalua-
tion are detailed in this section.
5.4.1 ROI Discovery
In order to discover the ROIs of a user, we use a spe-
cific part of a discovery process of Zones of Inter-
est (ZOIs) described in (Kulkarni et al., 2016). The
∆d
max
is equal to 60 meters and ∆t
min
has a value of 10
minutes. We follow the creation process of clusters,
which are called ROIs in this paper, without creat-
ing any cluster groups or ZOIs similarly to (Kulkarni
et al., 2016). After discovered all clusters, we merge
them if an intersection occurs between two clusters
and we repeat this merging process until reaching a
stable cluster set in which there is no more intersec-
tion. We do not filter out the ROIs that are not fre-
quently and/or not recently visited because we want
to keep a high number of ROIs describing the mobil-
ity of the user, in order to properly fill the location
trend model.
5.4.2 Location Trend Model
The location trend model is created with time slices
having a duration of 20 minutes during a period of
one week, resulting in 504 time slices for one week.
We chose this time slice duration by exploring the en-
tropy level of each time slice cell of the location trend
model and finding that it was the best time slice dura-
tion for the location prediction goal.
Table 1: List of parameters used for each LBS scenario.
Parameter/LBS scenario Public transportation LBS scenario Taxi LBS scenario
LBS utility distance 1000 meters 500 meters
Number of target time slices 10 4
Frequency of requests 100 100
Random repartition of predicted locations 0 and 1 0 and 1
5.4.3 LBS Scenarios
A scenario corresponds to a specific type of LBS as
ResPred: A Privacy Preserving Location Prediction System Ensuring Location-based Service Utility
113

described in Table 1: the public transportation LBS
and the taxi LBS. Firstly, each LBS has its own utility
distance and a specific number of target time slices.
For example, the target time slices of the public trans-
portation LBS are in the morning, i.e., from 7:00 to
7:20 am, and at the end of the afternoon, i.e., from
5:00 to 5:20 pm, every working day. Regarding the
taxi LBS, the target time slice are in the evening
Thursday from 10:00 to 10:20 pm, Friday from 11:00
to 11:20 pm, and Saturday from 4:00 to 4:20 pm and
from 11:00 to 11:20 pm. We distribute the total num-
ber of location prediction requests, called frequency
in Table 1, which are 100 in total, per target time slice
for each LBS scenario. The distribution of the total
number of location prediction requests can be equal
for all the target time slices, i.e., 10 (100 divided by
10) for each target time slice. Or the process can
also randomly distribute the 100 predicted location
requests per target time slice meaning that some time
slices can have more predicted locations than others.
These scenarios are the same for all evaluated users.
5.4.4 Location Privacy Preserving Mechanisms
As mentioned previously, we chose two LPPMs: the
grid-based rounding and the Gaussian perturbation in
addition to our proposed LPPM. For the utility pri-
vacy tradeoff LPPM included in ResPred, we selected
four values for ∆p
maxUtilityLoss
: 0.2, 0.4, 0.6 and 0.8.
Regarding the grid-based rounding, we decided to
have a difference of 0.005, 0.05 and 0.5 between two
successive latitudes or longitudes to create each cell
of the grid. The values of the grid-based parame-
ters are ranged from approximately 380 to 38000 me-
ters. Finally, we chose 4 standard deviations that are
0.0005, 0.005, 0.05 and 0.5 for the Gaussian pertur-
bation, the mean being the latitude or the longitude of
the raw location. The values of the Gaussian pertur-
bation parameters are ranged from approximately 55
to 66500 meters.
5.5 Location Prediction Accuracy
We decide to evaluate the location prediction accu-
racy of the location trend model by performing the
following steps. Firstly, the dataset of each user must
be divided into two datasets according to the total
number of locations: a training set of 60% and a test
set of 40%. We discover the ROIs and we create
the location trend model of a user with her training
dataset. Secondly, the evaluation process is the fol-
lowing: we start by selecting 200 unique locations
in the test set. For each selected location of the test
set, we convert its timestamp into a target time slice.
Then, we find the most likely visited ROI or succes-
sive ROIs of the target time slice by exploring the
location trend model, which is the same process ex-
plained in Section 4.1. We consider that the predic-
tion is correct for this location only if the latter is con-
tained in the ROI or the merged ROI computed from
the successive found ROIs. If there is no ROI for the
target time slice, we simply do not take the prediction
into account. At the end, we compute a ratio that is
the number of correct predictions out of the number of
predictions that returned a value after having explored
the model.
5.6 Utility/Privacy Metrics
The metrics presented in this section enables to evalu-
ate the utility as well as the location privacy of all pre-
dicted locations of a user shared with a LBS and, con-
sequently, to highlight the LPPM that gives the best
utility/privacy tradeoff.
5.6.1 Utility Metric
The utility metric allows us to evaluate if a predicted
location sent to the LBS meets the utility require-
ment of the LBS given at the beginning of the pro-
cess by the LBS itself. We define a reference zone
zone
re f
that has a center corresponding to the center
of the tmpLoc
predicted
and a radius that has the value
of ∆r
utility
. We also create a zone to check zone
toCheck
having a center that is the coordinates of the predicted
zone loc
predicted
and a radius equals to the value of
∆r
utility
. The utility is validated if there is an inter-
section between the zone
re f
and the zone to check
zone
toCheck
. Equation 5 describes the two possible re-
sults of the utility metric.
res
utility
=
(
0, if zone
re f
∩ zone
toCheck
=
/
0
1, if zone
re f
∩ zone
toCheck
> 0
(5)
Then we compute the utility average of a target
time slice by dividing the number of predicted loca-
tions that meet the utility condition by the total num-
ber of predicted locations sent to the LBS for this tar-
get time slice. Finally, we calculate the average of the
utility results obtained for all the target time slices in
order to obtain the utility result of the scenario.
5.6.2 Location Privacy Metric
The location privacy metric corresponds to a metric
that evaluates the degree of confusion of an adversary,
the LBS in our case, during a location attack on the
predicted locations received from ResPred. The met-
ric is based on the Shannon entropy that can compute
GISTAM 2018 - 4th International Conference on Geographical Information Systems Theory, Applications and Management
114
(a) Temporary predicted location
(b) Gaussian perturbation
(parameter: 0.005)
(c) Rounding mechanism
(rounded to 2 decimals)
(d) Utility privacy tradeoff LPPM
(parameter: 0.9)
Figure 6: Visual description of the impact of the different LPPMs on a temporary predicted location.
a level of uncertainty as described in (Shokri et al.,
2011). As mentioned in Section 2.4, the location at-
tack performed by an adversary consists in trying to
discover one location amongst all of the predicted lo-
cations sent by ResPred for a specific target time slice
considering that the adversary knows how the time
is discretized in our location trend model. The goal
of a LPPM is to confuse the adversary in order to
reduce its probability of finding one single location
for a target time slice. In order to compute the loca-
tion privacy, we will create a grid that discretizes the
space and compute the density proportion p
density
of
each visited cell of this grid. The density proportion
p
density
is the number of predicted locations out of the
total number of predicted locations visited per visited
cell of the grid during the target time slice. Each cell
of the grid is a rectangle of approximately 100 meters
per 180 on an average, i.e., a difference of 0.001 be-
tween two successive latitudes or longitudes. Equa-
tion 6 describes the computation of the location pri-
vacy for a specific target time slice in which i is the
index of the i
th
visited cell by the user, n is the total
number of visited cells by the user during the target
time slice. A low entropy result means a low con-
fusion of the adversary, while a high entropy result
means a high uncertainty.
res
locationPrivacy
= −
n
∑
i=1
p
density
i
log
2
p
density
i
(6)
Finally, we compute an average result for each
scenario in the same way as for the utility metric (de-
scribed at the end of the previous section).
5.7 Results
The average of the location prediction accuracy of the
location trend model for all evaluated users is equal to
60%. In addition, we obtain a minimum and a max-
imum location prediction accuracy of 16% and 90%
respectively.
ResPred: A Privacy Preserving Location Prediction System Ensuring Location-based Service Utility
115

Table 2: Utility / location privacy results.
LPPM/Result Utility result Location privacy result
Utility privacy tradeoff LPPM 1.0 2.81
Grid-based rounding 0.62 0
Gaussian perturbation 0.50 2.78
Regarding the utility/privacy tradeoff evaluation,
we firstly compute the average of the utility results of
all LBS scenarios per user and, secondly, we calculate
average utility results of all users. We do exactly the
same for the location privacy results. The results are
summarized in Table 2. We can clearly see that our
LPPM, i.e, the utility/privacy tradeoff LPPM, has the
best utility/privacy tradeoff because the utility result
and the location privacy result reach the highest val-
ues. This means that our LPPM meets the LBS utility
requirements and is also able to protect the location
privacy of the user according to her privacy prefer-
ence. Although the Gaussian perturbation has also a
high location privacy result, a reasonable utility re-
sult is not reached. The location privacy result of the
grid-based rounding is equal to 0 indicating that the
adversary has no confusion because the modified lo-
cations, i.e., predicted locations, are always the same
for a target time slice. The Gaussian perturbation has
the advantage of blurring the location via a single pa-
rameter expressing a distance, while the grid-based
mechanism requires the creation of a grid that can
take a substantial time and its exploration before be-
ing able to blur a location. Although our mechanism
must check a location privacy condition, it computes
the new coordinates within a reasonable time.
Finally, we can see the blurring impact of the dif-
ferent LPPMs on a temporary predicted location in
Figure 6. In Figure 6 (a), we can see the center as
well as the radius of a temporary predicted location,
both depicted with a marker and a circle. In Figure 6
(b) and (d), 100 new locations, depicted with new
markers, are created according to the corresponding
LPPM. Regarding the rounding, the coordinates have
only been rounded to two decimals in the figure but
in the context of the evaluation with a spatial grid, we
would have obtained 100 times the same location be-
cause the structure of the grid is fixed and the nearest
location is always the same for a single location to
blur.
6 RELATED WORK
The related work below tackles the two main subjects
of the paper that are the following: the description
of existing LPPMs as well as the different predic-
tive models presented in the literature that are used
to compute future user locations.
6.1 Location Privacy Preserving
Mechanisms
In a location prediction context, we consider that we
need to protect the predicted location that is sent to a
LBS as mentioned in Section 3. To reach this goal,
there exist various mechanisms to protect the pre-
dicted location, such as applying a spatial perturba-
tion (Agrawal and Srikant, 2000; Armstrong et al.,
1999; Gambs et al., 2011), using a spatial cloaking
mechanism (Gruteser and Grunwald, 2003), sending
dummy locations (Kido et al., 2005) or using a round-
ing mechanism (Agrawal and Srikant, 2000; Krumm,
2007).
Applying a spatial perturbation enables to spa-
tially modify a location as mentioned by several au-
thors in (Armstrong et al., 1999; Gambs et al., 2011).
As described in these papers, we can add spatial noise
to the coordinates of a location. However, the more
noise is added to the location sent to the LBS in-
creases, the more the LBS utility decreases in our
context because a LBS may provide information that
is not related to the raw predicted location, depend-
ing on the level of protection. In the case of the
spatial cloaking presented by Gruteser and Grunwald
in (Gruteser and Grunwald, 2003), the predicted lo-
cation should only be sent if the user is considered
as k-anonymous, meaning that the user cannot be dis-
tinguishable from at least k − 1 other users. This tech-
nique is unfortunately not realistic in our context and
not easy to implement especially in the case where
the mobility models of users are not centralized or
shared in a common server. As detailed in (Kido et al.,
2005), sending dummy locations is interesting in or-
der to add noise if and only if multiple predicted lo-
cations can be sent to a LBS. However in our system,
it is impossible to use this LPPM because only one
predicted location must be sent to a LBS as an answer
to a predictive request supported by ResPred. Utiliz-
ing a rounding mechanism, as described in (Agrawal
and Srikant, 2000; Krumm, 2007), can be considered
because the predicted location is changed into a new
location corresponding to a nearest reference point.
If we consider that space is discretized and described
with multiple reference points (the vertices of each
cell of a grid for instance), the mechanism consists in
modifying a location into a new location correspond-
ing to the nearest reference vertex of the cell in which
the location is as indicated in the papers cited previ-
ously. Cryptography techniques could be also used
to protect locations sent to third parties as mentioned
in (Hendawi and Mokbel, 2012) but our work is not
focused on this kind of privacy/security strategies. To
summarize and according to the best of our knowl-
GISTAM 2018 - 4th International Conference on Geographical Information Systems Theory, Applications and Management
116

edge, there is no LPPM that can find an appropriate
tradeoff between the utility and the privacy in a loca-
tion prediction context. For our utility/privacy evalu-
ation, we chose the closest LPPMs to our work, that
are the rounding and the spatial perturbation as de-
tailed in the previous section.
6.2 Location Prediction Requests and
Models
As detailed in the complete survey in (Hendawi and
Mokbel, 2012), various techniques exist to predict fu-
ture locations of users. In the literature, there ex-
ist different location predictive models for different
types of location prediction requests, such as predict-
ing a future location based on a time duration (Jeung
et al., 2008; Sadilek and Krumm, 2012), predicting
the next location that will probably be reached by a
user (Gambs et al., 2012; Gid
´
ofalvi and Dong, 2012;
Ying et al., 2011), etc. Some location prediction-
based papers focus on other location-based predictive
requests, such as the prediction of the staying time in
a particular ROI or when the user will reach or leave
a ROI (Gid
´
ofalvi and Dong, 2012), the prediction of
the number of users reaching a specific zone (Chapuis
et al., 2016) and much more. Other remaining works
are focused on range queries that enable to identify if
one or multiple user(s) will be in a specific area dur-
ing a specific time window. In (Xu et al., 2016), the
authors describe a way to prune an order-k Markov
chain model in order to efficiently compute long-term
predictive range queries.
The main focus of our paper, in terms of predic-
tion, is to comnpute a future location of a user based
on a time duration from the current time. In the litera-
ture, it is shown that some predictive models can work
better for near location predictions and others are
more suited for distant location predictions. In (Je-
ung et al., 2008), the authors present a hybrid predic-
tion model for moving objects. For near location pre-
dictions, their model uses motion functions, while for
distant location predictions, their model computes the
predicted location based on trajectory patterns. The
structure in which they store the trajectory patterns
of a user is a trajectory pattern tree. However, they
do not evaluate their model with real mobility traces.
Their predictive model is close to our location trend
model because they use the notion of patterns based
on spatial clusters to fill their model. Nevertheless,
the structure of their final model is clearly not the
same as ours because they create a trajectory pattern
tree. Sadilek and Krumm propose a method to predict
long-term human mobility in (Sadilek and Krumm,
2012) up to several days in the future. Their method,
which can highlight strong pattern of users, uses a
projected eigendays model that is carefully created by
analyzing the periodicity of the mobility of a user as
well as other mobility features. This work highlights
that it is crucial to extract strong patterns for long-
term predictions. The location trend model we pro-
pose in the ResPred system is close to the model pre-
sented by Sadilek and Krumm. However, our model
is different in that it is based on ROIs and not on raw
locations and takes less features into account.
7 CONCLUSION
In this paper, we presented a system called ResPred
that enables to compute predicted locations of a user
for LBS. This system contains two components. The
first component focuses on location prediction by in-
cluding a predictive model based on location trends
expressed as ROI(s). The second component aims at
protecting the location privacy of the user by find-
ing an appropriate tradeoff between a utility speci-
fied by the LBS and a location privacy preference in-
dicated by the user that is expressed as a maximum
utility loss percentage. The results clearly show that
our LPPM provides the best utility/location privacy
tradeoff compared to two other existing LPPMs. In
addition, the location trend model is promising if we
look at the location prediction accuracy results, espe-
cially in the context of location prediction according
to a certain time duration in the future. Future work
will consist in extending the evaluation to more users
by finding a dataset having rich user datasets, which
is a real need for the research community. We will
also design other inference attacks in order to evalu-
ate the location privacy and maybe compare the com-
puting cost of the different LPPMs. And finally, we
will compare the location trend model to other exist-
ing close models for similar requests regarding short,
mid and long-term location predictions.
REFERENCES
Agrawal, R. and Srikant, R. (2000). Privacy-preserving data
mining. In ACM Sigmod Record, volume 29, pages
439–450. ACM.
Armstrong, M. P., Rushton, G., and Zimmerman, D. L.
(1999). Geographically masking health data to pre-
serve confidentiality. Statistics in Medicine, vol.
18:497–525.
Ben Mokhtar, S., Boutet, A., Bouzouina, L., Bonnel, P.,
Brette, O., Brunie, L., Cunche, M., D ’alu, S., Pri-
mault, V., Raveneau, P., Rivano, H., and Stanica, R.
(2017). PRIVA’MOV: Analysing Human Mobility
ResPred: A Privacy Preserving Location Prediction System Ensuring Location-based Service Utility
117

Through Multi-Sensor Datasets. In NetMob 2017, Mi-
lan, Italy.
Chapuis, B., Moro, A., Kulkarni, V., and Garbinato, B.
(2016). Capturing complex behaviour for predicting
distant future trajectories. In Proceedings of the 5th
ACM SIGSPATIAL International Workshop on Mobile
Geographic Information Systems, pages 64–73. ACM.
Gambs, S., Killijian, M.-O., and N
´
u
˜
nez del Prado Cortez,
M. (2011). Show me how you move and i will tell you
who you are. Trans. Data Privacy, 4(2):103–126.
Gambs, S., Killijian, M.-O., and Nu
˜
nez Del Prado Cortez,
M. (2012). Next place prediction using mobility
Markov chains. In MPM - EuroSys 2012 Workshop
on Measurement, Privacy, and Mobility - 2012, Bern,
Switzerland.
Gid
´
ofalvi, G. and Dong, F. (2012). When and where next:
individual mobility prediction. In Proceedings of the
First ACM SIGSPATIAL International Workshop on
Mobile Geographic Information Systems, pages 57–
64. ACM.
Gruteser, M. and Grunwald, D. (2003). Anonymous usage
of location-based services through spatial and tempo-
ral cloaking. In Proceedings of the 1st international
conference on Mobile systems, applications and ser-
vices, pages 31–42. ACM.
Hendawi, A. M. and Mokbel, M. F. (2012). Predictive
spatio-temporal queries: A comprehensive survey and
future directions. In Proceedings of the First ACM
SIGSPATIAL International Workshop on Mobile Ge-
ographic Information Systems, MobiGIS ’12, pages
97–104, New York, NY, USA. ACM.
Jeung, H., Liu, Q., Shen, H. T., and Zhou, X. (2008). A
hybrid prediction model for moving objects. In Data
Engineering, 2008. ICDE 2008. IEEE 24th Interna-
tional Conference on, pages 70–79. Ieee.
Kido, H., Yanagisawa, Y., and Satoh, T. (2005). An anony-
mous communication technique using dummies for
location-based services. In Proceedings of the In-
ternational Conference on Pervasive Services 2005,
ICPS ’05, Santorini, Greece, July 11-14, 2005, pages
88–97.
Krumm, J. (2007). Inference attacks on location tracks. In
Proceedings of the 5th International Conference on
Pervasive Computing, PERVASIVE’07, pages 127–
143, Berlin, Heidelberg. Springer-Verlag.
Kulkarni, V., Moro, A., and Garbinato, B. (2016). A mo-
bility prediction system leveraging realtime location
data streams: poster. In Proceedings of the 22nd An-
nual International Conference on Mobile Computing
and Networking, pages 430–432. ACM.
Sadilek, A. and Krumm, J. (2012). Far out: Predicting long-
term human mobility. In AAAI.
Shokri, R., Theodorakopoulos, G., Le Boudec, J.-Y., and
Hubaux, J.-P. (2011). Quantifying location privacy.
In Proceedings of the 2011 IEEE Symposium on Secu-
rity and Privacy, SP ’11, pages 247–262, Washington,
DC, USA. IEEE Computer Society.
Xu, X., Xiong, L., Sunderam, V., and Xiao, Y. (2016).
A markov chain based pruning method for predic-
tive range queries. In Proceedings of the 24th ACM
SIGSPATIAL International Conference on Advances
in Geographic Information Systems, GIS ’16, pages
16:1–16:10, New York, NY, USA. ACM.
Ying, J. J.-C., Lee, W.-C., Weng, T.-C., and Tseng, V. S.
(2011). Semantic trajectory mining for location pre-
diction. In Proceedings of the 19th ACM SIGSPATIAL
International Conference on Advances in Geographic
Information Systems, pages 34–43. ACM.
Zang, H. and Bolot, J. (2011). Anonymization of location
data does not work: A large-scale measurement study.
In Proceedings of the 17th Annual International Con-
ference on Mobile Computing and Networking, Mobi-
Com ’11, pages 145–156, New York, NY, USA. ACM.
GISTAM 2018 - 4th International Conference on Geographical Information Systems Theory, Applications and Management
118
