
Constructive Privacy for Shared Genetic Data
Fatima-zahra Boujdad and Mario Sudholt
IMT Atlantique, 4 rue Alfred Kastler, Nantes, France
Keywords:
Genetic Data, Privacy, Outsourcing, Watermarking, Fragmentation, Encryption.
Abstract:
The need for the sharing of genetic data, for instance, in genome-wide association studies is incessantly gro-
wing. In parallel, serious privacy concerns rise from a multi-party access to genetic information. Several
techniques, such as encryption, have been proposed as solutions for the privacy-preserving sharing of genomes.
However, existing programming means do not support guarantees for privacy properties and the performance
optimization of genetic applications involving shared data. We propose two contributions in this context.
First, we present new cloud-based architectures for cloud-based genetic applications that are motivated by the
needs of geneticians. Second, we propose a model and implementation for the composition of watermarking
with encryption, fragmentation, and client-side computations for the secure and privacy-preserving sharing of
genetic data in the cloud.
1 INTRODUCTION
Information about the human genome has become
highly valuable for development of new treatments
of genetic-based diseases. Advanced sequencing
technologies (NGS) (Behjati S, 2013) have made it
much easier to obtain complete genetic data of human
beings. However, in general genetic samples are not
sufficiently available to genetic research. Indeed, ge-
netic research has often be conducted collaboratively
between several (groups of) geneticians. Doing so,
more meaningful sizes of genetic cohorts can be es-
tablished and allow for accurate results. For instance,
Genome Wide Association Studies (GWAS) use two,
if possible, large sets of genetic data (e.g., in the form
of positions from genomes (Cousin et al., 2006)), case
data which belongs to subjects of the studied dise-
ase and control data that is obtained from healthy do-
nors. Control data is particularly difficult to obtain
because it has to be provided on a voluntary basis by
healthy individuals. This is one case in which resear-
chers want to share and work on the already available
corresponding data.
Though sharing in this fashion seems to be straig-
htforward, the very private aspect of genetic informa-
tion (Erlich and Narayanan, 2014) pushes genetici-
ans to protect their collected data and hence, ham-
per the practical and flexible sharing of genetic data.
Instead of sharing raw data, genetic research often re-
lied on public aggregated data, e.g., allele frequency,
in a false belief that this procedure was privacy-
preserving. However, since the attack by Homer and
et al. (Homer et al., 2008), the aggregated informa-
tion has been retired from public access
1
. In fact,
the attack shows how to infer a specific individual
presence in a study based on those aggregated data
only. This clearly threatens the privacy of patients.
As a consequence, sharing of genetic data, notably via
cloud-based services is very limited currently and per-
formed using very restrictive queries on genetic data-
bases.
Secure and privacy-preserving sharing of high vo-
lumes of genetic data constitute a very active rese-
arch field nowadays. Data is shared using a client/-
server architecture where the server is often a cloud
provider storing and processing, e.g., homomorphi-
cally encrypted data (Lu et al., 2015; Zhang et al.,
2015), which enables computations to be directly per-
formed on encrypted data; another architecture con-
sists in the collaboration between different biomedical
sites which make use of multi-party computation pro-
tocols. However, the corresponding approaches, e.g.,
(Liina Kamm et al., 2013; Tang et al., 2016), only
handle a limited number of sites in the scenario and
are yet to be extended so to handle realistic scenarios
for a wider sharing of genetic data.
Some approaches have proposed the combi-
nation of different privacy-enhancing techniques,
e.g., homomorphic encryption, multi-party compu-
1
http://help.gwascentral.org/data/download/
Boujdad, F. and Sudholt, M.
Constructive Privacy for Shared Genetic Data.
DOI: 10.5220/0006765804890496
In Proceedings of the 8th International Conference on Cloud Computing and Services Science (CLOSER 2018), pages 489-496
ISBN: 978-989-758-295-0
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
489
tation protocols to provide secure sharing of gene-
tic data (McLaren et al., 2016). The combination
of data fragmentation and client-side computations
has been proposed in the context of an outsourcing
schema (Wang et al., 2009). It locally stores identi-
fying genome components, i.e., SNPs, while compu-
tations on the common and publicly known parts of
the human genome are outsourced. Combining dif-
ferent techniques for security purposes has also been
explored for other related purposes. For instance, in
(Ciriani et al., 2010), a combination of encryption and
fragmentation is used to protect outsourced databases.
For multimedia data, (Bouslimi et al., 2016) suggest a
combination of encryption and watermarking to trans-
mit images through an untrusted network securely.
A crucial result of the current situation is that the
secure and privacy-related handling of shared data re-
quires different technologies to be composed in or-
der to handle realistic collaboration scenarios. Howe-
ver, no such general compositional approach for the
sharing of genetic data exists. In particular, while the
existing approaches focus on confidentiality proper-
ties, ownership and integrity properties have received
few attention.
We build on ideas from the PRIVGEN project
2
, in
which researchers in genetics and computer science
study new approaches for distributed analyses over
shared genetic data. In this paper, we provide a com-
positional approach supporting ownership and inte-
grity properties by extending the approach by (Cher-
rueau et al., 2015) to genetic data scenarios. Cherru-
eau et al. allow the composition of encryption, data
fragmentation and localized computations to establish
confidentiality of sensitive data. Concretely, we pre-
sent two main contributions:
• We present and discuss several new architectures
and scenarios for the cloud-based sharing of ge-
netic data.
• We add watermarking techniques to the approach
by (Cherrueau et al., 2015) in order to support ow-
nership and integrity properties of shared genetic
data. Concretely, we present a language-based ap-
proach for building applications and servers for
the composition of privacy-preserving applicati-
ons manipulating shared genetic data.
3
We also
present an algebraic theory that allows for the op-
timization of such applications and servers.
The paper is structured as follows. Sec. 2 presents
basic information about the sharing of genetic data
2
Privacy-preserving sharing and processing of genetic
data, http://www.privgen.cominlabs.u-bretagneloire.fr
3
The Idris implementation of our approach is
available at: https://github.com/BoujdadFz/PrivGen-
Rep/blob/master/ coshed.idr.
G
? data
Trusted
party
G
case data
Cloud
(storage
&nonsensitive
computations)
sensitive computations
G
control data
Data
. . .
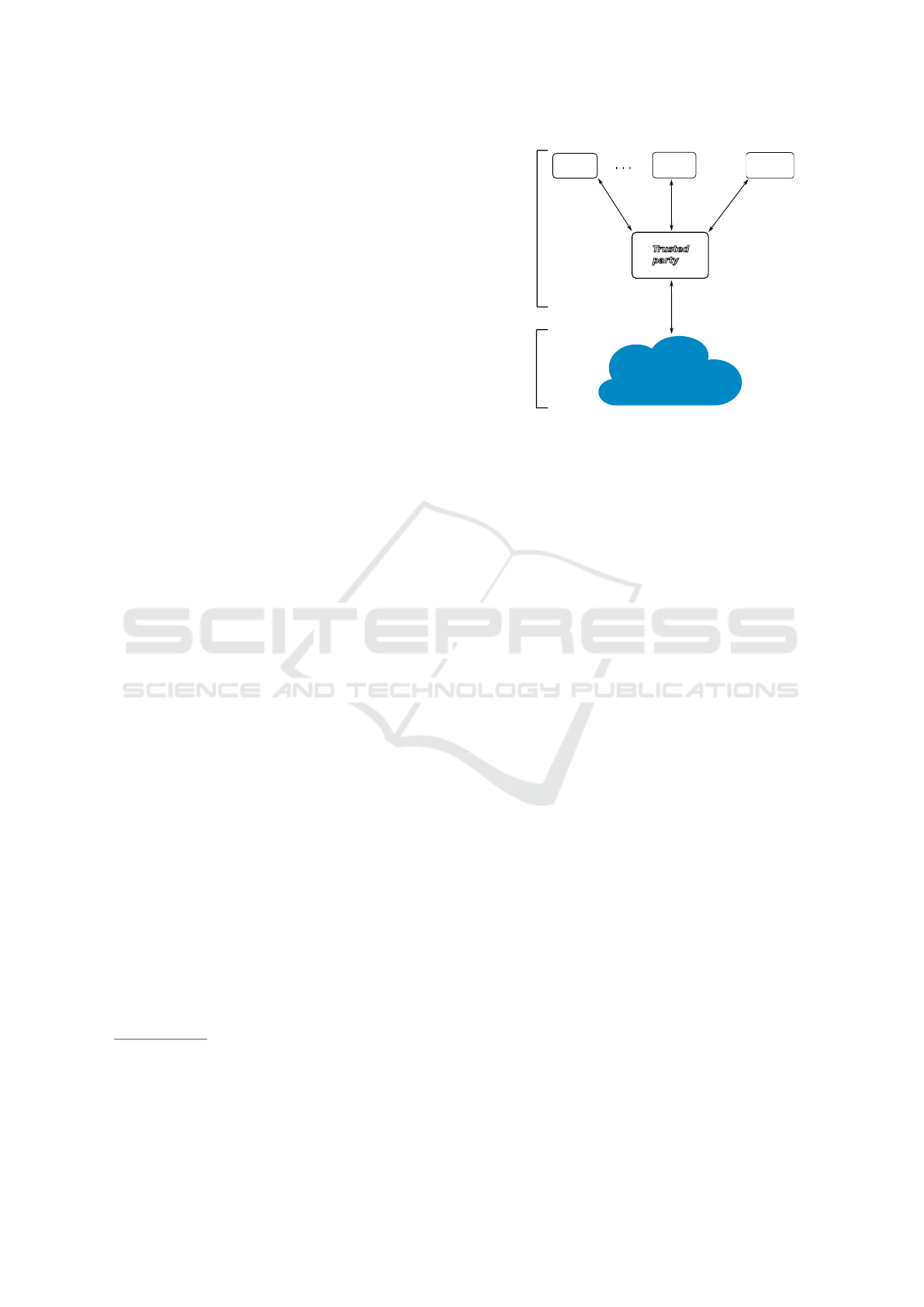
Figure 1: Genetic data sharing via a trusted party.
and introduces new corresponding software architec-
tures for this purpose. In Sec. 3 we present our ap-
proach COSHED for the compositional construction
of systems for the sharing of genetic data. We close
with a conclusion.
2 GENETIC DATA SHARING
Together with our partners of the PRIVGEN project,
we are studying more flexible architectures that sup-
port wider sharing of genetic cohorts in the Cloud
while preserving data privacy properties. Existing ge-
netic data and computation servers are limited essen-
tially to simple client-server systems that allow gene-
ticians to perform highly restricted stateless queries.
In contrast, the partners of PRIVGEN are working on
more powerful collaborative data-sharing architectu-
res. Concretely, the geneticians in the PRIVGEN pro-
ject are interested in a scalable architecture that al-
lows for sharing between multiple owners of genetic
data (research or private institutions) and researchers
in genetics.
2.1 Architectures
Based on the requirements of geneticians we are pro-
posing new architectures that allow for genetic data
sets provided by different organizations to be shared.
Sharing is performed using trusted parties mediating
data that is stored and (partially) manipulated in fede-
rated clouds. In the following, we propose two new
such architectures. These architectures differ, in par-
ticular, in the policies for genetic data sharing (GDS)
they allow for. Additionally, we motivate that water-
marking techniques are a crucial means to satisfy ow-
nership and integrity properties in this context.
CLOSER 2018 - 8th International Conference on Cloud Computing and Services Science
490
G
case data
G
control data
G
? data
...
sensitive computations
cloud
(storage
&nonsensitive
computations
local
server
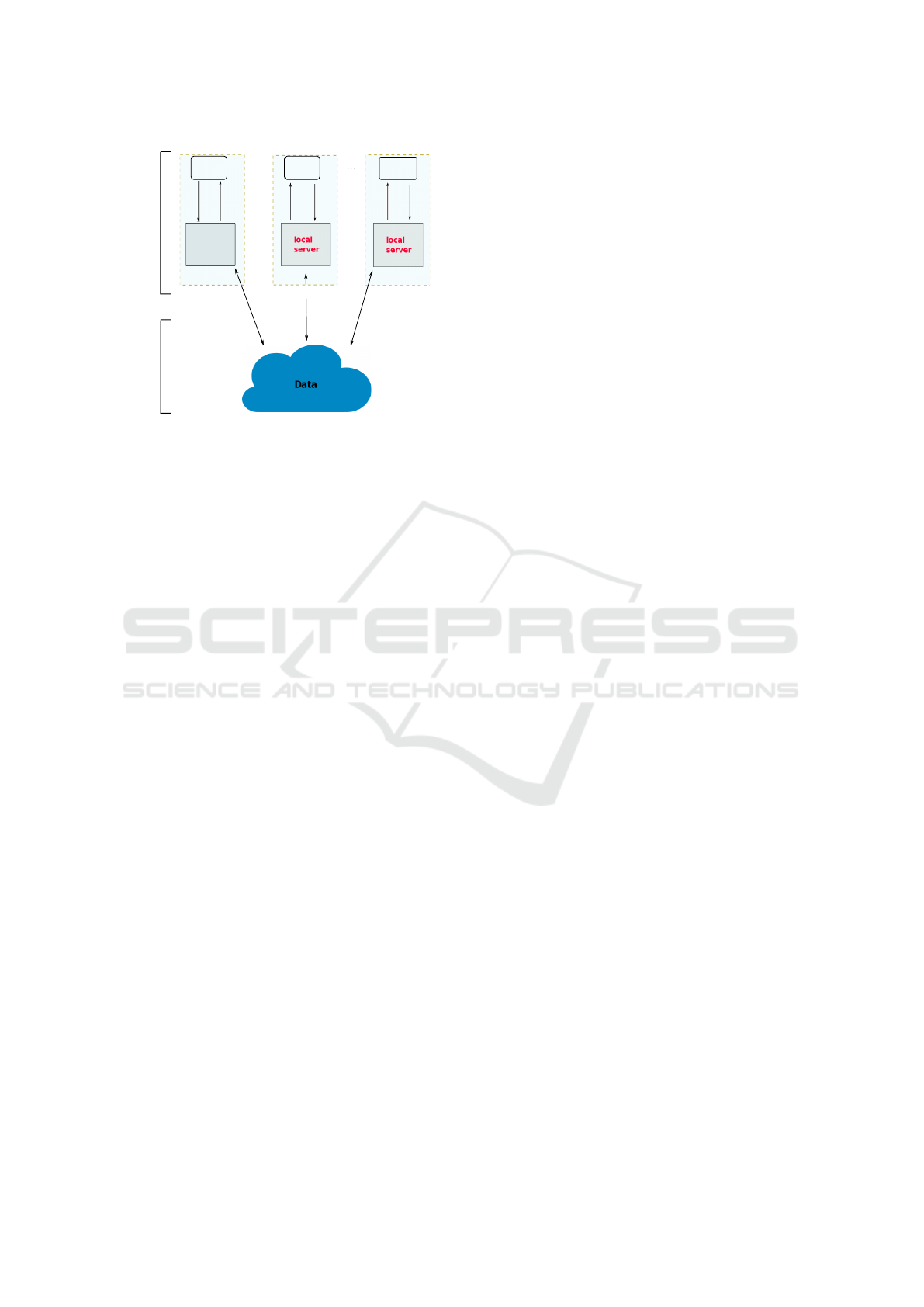
Figure 2: Genetic data sharing via local servers and cloud.
2.1.1 Trusted Party Architecture
The first architecture we propose, shown in Fig. 1,
enables data to be shared among different geneticians
(G in the figure) and to be transferred to a cloud infra-
structure. Communications are mediated by a trusted
party (TP) that can enforce privacy and security pro-
perties of the data and computations shared among
the other participants. Because of the strong control
provided by the mediating trusted party, this architec-
ture is particularly suitable to cooperation scenarios
between partners having different GDS policies.
Since this kind of architecture includes data to
be transferred from the geneticians (or corresponding
owner institutions) to both the Cloud and the TP, ow-
nership and integrity properties of shared genetic data
are crucial in addition to more frequently-used confi-
dentiality properties.
Trusted parties can be integrated into genetic ap-
plications in different ways: Kantarcioglu et al. (Kan-
tarcioglu et al., 2008) employ a trusted entity for sto-
ring encrypted genetic data and processing (anony-
mous) computations on it; Xie et al. (Xie et al., 2014)
uses a trusted component for key distribution and ma-
nagement. We rather allow for direct access to gene-
tic data by the trusted party in our architecture, which
is in fact conform to real-world applications (Gulcher
et al., 2000).
This architecture can be generalized to allow for
sharing as part of federated Clouds. In Sec. 3.1.1 we
harness such an architecture in the context of a con-
crete sharing scenario.
2.1.2 Local Computations Architecture
Fig. 2 shows a model for computations performed
by geneticians that all have their own infrastructure
able to handle computations on genetic datasets of
bearable sizes. In this case, sharing of data is done
through the Cloud. A typical workflow may define a
dataset, encrypt it for transfer in the Cloud where it
may undergo some privacy-neutral processing, before
finally being transmitted to its final recipient. This
workflow requires fragmentation techniques, crypto-
graphic techniques and client-side computations. In
this architecture as well ownership properties have to
be satisfied which can be assured by watermarking.
This architecture and corresponding workflows re-
quire closer integration between the collaborators, no-
tably their GDS policies.
3 PRIVACY FOR SHARED
GENETIC DATA
The architectures manipulating shared genetic data
introduced in the previous section may easily lead to
violations, for instance, of privacy properties. Such
violations may stem from simple programming errors
or more difficult errors in the applications’ logic. Our
approach is based on the C2QL approach by (Cherru-
eau et al., 2015) who provide composition and query
languages for the secure and privacy-preserving pro-
gramming of distributed applications. In the follo-
wing, we first review the basic mechanisms of their
approach before detailing ours.
C2QL enables the development of privacy-aware
applications by the implementation of distributed al-
gorithms composing computations involving encryp-
ted and fragmented data, as well as client-side compu-
tations. SQL-like queries are supported on top of pos-
sibly encrypted and fragmented data. The approach
essentially consists of two parts: language support for
the development of secure and privacy-preserving ap-
plications and an algebraic theory supporting corre-
sponding optimizations and correctness proofs.
Language Support. The C2QL language provides
de/constructors for the encryption and the fragmen-
tation of data, respectively denoted Decrypt, Crypt,
Defrag and Frag. Client-side computations are ini-
tiated automatically depending on the fragmentation
and encryption status of data. The constructors are
used as part of a domain specific language that is em-
bedded in the Idris (www.idris-lang.org) program-
ming language. Idris programs are used to compose
secure and privacy-aware applications as well as the
queries over genomic data. Idris’ dependent type sy-
stem enables the verification of basic secure proper-
ties at compile time, e.g., that a given encrypted data
fragment can only be used after decryption.
Constructive Privacy for Shared Genetic Data
491

1 -- Bas ic va lue ty pe s
2 da ta Ty = BOO L | N AT | TE XT
3 | C RYPT Crypt Ty Ty
4
5 -- At tr ibute : ( c ol umn name , va lu e t ype)
6
7 Attri bu te : Ty pe
8 Attri bu te = ( S tring , Ty )
9
10 -- Tab le sc he ma : l ist of at tr ib ut es
11
12 Sch em a : T ype
13 Sch em a = L ist A tt ri bu te
14
15 -- D B e nv ir on me nt : v ec tor of ta ble s che ma s
16
17 En v : Na t → T yp e
18 En v n = V ect (S n ) S che ma
Figure 3: Basic data types.
Figure 3 shows the basic types implementing data
bases. Figure 4 shows the abstract definitions of
1 -- AD T ( a lgebr ai c dat a t yp e) f or pr iva cy o pe ra to rs
2 da ta Pr ivy : ( e nv0 : E nv n ) → ( en v1 : En v m ) →
3 (∆ : S ch ema ) → T ype wh er e
4
5 -- en cry pt s an at tr ib ut e i n an en vi ro nm en t
6 C r yp t : ( a : At tr ib ute ) → ( c : Cr yp tTy ) →
7 { au to p : EnvEl em a env} →
8 P ri vy en v ( c ryptE nv c a en v ) [ ]
9
10 -- fr ag ments an en vir . at the ’m ost rig ht ’ s ch em a
11 -- @ p pro of tha t ‘δ‘ ⊆ ‘( la st env ) ‘
12 Fr ag : (δ: Sc hem a ) → { au to p : I nc δ ( la s t en v )} →
13 P ri vy en v ( f rag En v δ en v) []
14
15 -- AD T f o r da ta re co ve ry op er at or s
16 da ta Qu ery : (∆ : Sch em a ) → Ty pe wh ere
17
18 -- dec ry pt s val ue s of ‘a ‘ u sing in fo rm at io n ‘ d‘
19 -- @ p1 proo f t ha t v al ues of ‘a ‘ ar e e nc ry pt ed
20 -- wi th sc hem a ‘c ‘.
21 De cr yp t :
22 (a : Att ri bu te ) → ( d : De cr yp t c ) →
23 { de fa ul t Re fl p1 : ( CR YP T c t ) = ( sn d a )} →
24 { au to p2 : Ele m a ∆} →
25 Q ue ry ∆ → Quer y ( r ep la ce On a ( fs t a , t ) ∆)
26
27 -- defrag me nt s va lu es of ‘q1 ‘ an d ‘ q2 ‘
28 De fr ag : ( q1 : Que ry δ) → ( q2 : Que ry δ’) →
29 Q ue ry ( d el et e Id (n ub (δ + + δ ’ ) ) )
Figure 4: Privacy-enforcing operators and queries.
privacy-enforcing operators (type Privy) and the en-
cryption/fragmentation constructors as well as queries
(Query) that are constructed by, if necessary, decryp-
ting and defragmenting shared data.
Algebraic Theory. The compositions of privacy-
enforcing operators and query operations are linked
by numerous algebraic laws that express, for instance,
the commutativity of certain compositions of operati-
ons. Based on these laws, applications over shared
data can be transformed. Such transformations are
useful, for instance, in order to distribute data by
fragmentation (and thus helping privacy through de-
identification of data) or optimize application per-
formance (in particular, by harnessing the cloud to
handle most of the benign computations).
Henceforth, we denote a set of attributes (co-
lumns) in a given relational database as a and use ◦
as the symbol for composition. SQL-like projection
is denoted by π
a
while selection is σ
p
where p is the
selection predicate. The algebraic operators used are:
• crypt
(s,a)
, decrypt
(s,a)
: encryption and decryption
operators parameterized by a schema s (e.g., AES)
and the target attribute a to be encrypted in the
relational database.
• frag
π
a
, defrag
π
a
: column-oriented fragmentation
and defragmentation operators
Figure 5 shows some examples of the algebraic laws
that are used later.
π
a ¯a
◦ defrag
π
a
≡ defrag
π
a
◦ (π
a
,π
¯a
) (1)
σ
pa∧p ¯a
◦ defrag
π
a
≡ defrag
π
a
◦ (σ
pa
,σ
p ¯a
) (2)
π
a
◦ decrypt
(s,a)
≡ decrypt
(s,a)
◦ π
a
(3)
if dom(p) /∈℘(a)
σ
p
◦ decrypt
(s,a)
≡ decrypt
(s,a)
◦ σ
p
(4)
Figure 5: Commutation laws.
3.1 The COSHED Approach
Our approach for a COnstructive SHaring of gEnetic
Data (COSHED) extends the C2QL approach with
watermarking functions. In fact, genetic data water-
marking is a promising technique for integrity, tra-
ceability or ownership protection. Concretely, we
have added the watermarking scheme in (Iftikhar
et al., 2015) that supports ownership and integrity pro-
tection properties for digital genetic data. In the follo-
wing, we present operators for watermarking and the
detection of watermarks that can be composed with
the ones for encryption and fragmentation. We also
introduce the corresponding algebraic laws that go-
vern the relationship between the different privacy-
enforcing techniques.
Language Support. Watermarks are represented as
a type WATERMARK whose first argument represents the
watermarking scheme (for now we have implemented
only one scheme GIG (Iftikhar et al., 2015)). We have
implemented operators wat
a
and detectw
(a,secrets)
,
see Fig. 6, respectively for watermark application (as
part of the privacy-enhancing technologies of ADT
Privy) and watermark detection as used in queries
(ADT Query). The wat
a
operator has as parame-
ters the attribute that indicates which columns have
to be watermarked in addition to two implicit argu-
ments for compile-time verification. More precisely,
CLOSER 2018 - 8th International Conference on Cloud Computing and Services Science
492
1 -- @G IG st an ds for Ge nI nf oG ua rd wat er ma rki ng sc he me
2 da ta WmT y = G IG
3 da ta Ty = .. . | W AT ER MA RK Wm Ty Ty
4
5 -- a funct io n tha t wa te rm ar ks an at tr ib ut e
6 -- @ p i s a proof th at @ a is in ’env ’
7 wa tE nv : ( a: At tribute ) → ( wms : WmT y ) → ( en v : En v n)
8 → { au to p : So ( i sI nE nv a e nv )} → En v n
9 wa tE nv a wm s e nv =
10 map (\ s = > i f ( e le m a s) the n rep la ce On a
11 ( fst a, W AT ER MA RK wms (s nd a )) s
12 e lse s) e nv
13
14 -- AD T w ith i nf or ma ti on for w atermar k de te ct io n
15 da ta Rea dM : W mT y → T ype wh er e
16 RG IG : ( k :K ey ) → R ea dM G I G
17
18 -- wa te rmark ap plicati on op er at or
19 da ta Pri vy :
20 ...
21 Wat : ( a : A tt ri bute ) →
22 { au to p1 : So ( is Ra wT yp e ( sn d a )) } →
23 { au to p2 : So ( is In En v a e nv )} →
24 P ri vy en v ( watE nv a G IG en v ) [ ]
25
26 -- wa te rmark d et ec ti on o pe rator
27 da ta Que ry :
28 ...
29 dete ct w :
30 (a : Att ri bu te ) → ( i nf o : R ead M GI G ) →
31 { de fa ul t Re fl p1 : ( sn d a ) = ( W AT ER MA RK GIG t) }
32 → Q ue ry ∆ → { a uto p2 : El em a ∆} →
33 Q ue ry (( re pl ac eO n a ( fs t a , t ) ∆) ++[ M yT att oo ])
Figure 6: Watermarking operators.
p1 serves as a (pre-defined) proof that the passed attri-
bute is not watermarked nor encrypted; p2 ensures its
membership in the targeted environment. Similarly,
in the query operator detectw
(a,secrets)
, p1 is a proof
that the parameter attribute was previously watermar-
ked with the right schema, i.e., GIG, so that water-
mark detection makes sense.
Laws. The watermarking schema GIG is reversible,
we can hence define the identity law
id ≡ detectw
a
◦ wat
a
(5)
Unlike for the encryption/decryption operators,
the watermarking schema is not a parameter because
the entire schema has already been defined (Iftikhar
et al., 2015). Actually, most watermarking laws will
be specific to the watermarking schema, contrary to
encryption which essentially is a more general opera-
tion.
The second law stipulates that watermark de-
tection can be delayed to after decryption provided
that the watermark application took place before en-
cryption.
decrypt
(s,a)
◦ crypt
(s,a)
◦ detectw
a
◦ wat
a
≡
detectw
a
◦ decrypt
(s,a)
◦ crypt
(s,a)
◦ wat
a
(6)
Furthermore, watermark detection commutes with
projection:
π
a
◦ detectw
a
≡ detectw
a
◦ π
a
(7)
Provided that selection is not performed on wa-
termarked attributes, watermark detection commutes
with selection: if dom(p) ∩ a = Ø
detectw
a
◦ σ
p
= σ
p
◦ detectw
a
(8)
3.1.1 Cloud-based Association Studies
We are now ready to present our definition of the ad-
vanced architectures for sharing of genetic data. Con-
sidering a scenario for large genomic-wide associa-
tion studies (GWAS), a federated cloud architecture
as proposed in Sec. 2.1 is considered that satisfies the
characteristics required by geneticians from the PRI-
VGEN project:
• The public cloud provider should not be able to
get direct access to identifying data
• Geneticians/researchers should not be able to get
direct access to external identifying data, e.g., ge-
nomes.
• Ownership and integrity properties of the data
have to be satisfied.
Explanation of how these requirements are satis-
fied in our architecture is given later in this section.
G1
case data
Tru st ed
party
G2
case data
Cloud
(storage
&nonsensitive
computations)
sensitive computations
G3
control data
P1
P2
(Q1,Q2,Q3)
(Q2,Q3)
Q1
dem_datal
- dem_datar ;
- vcf files.
LeftCloud
RightCloud
Results
rightCloudTab1;
leftCloudTab
rightCloudTab2
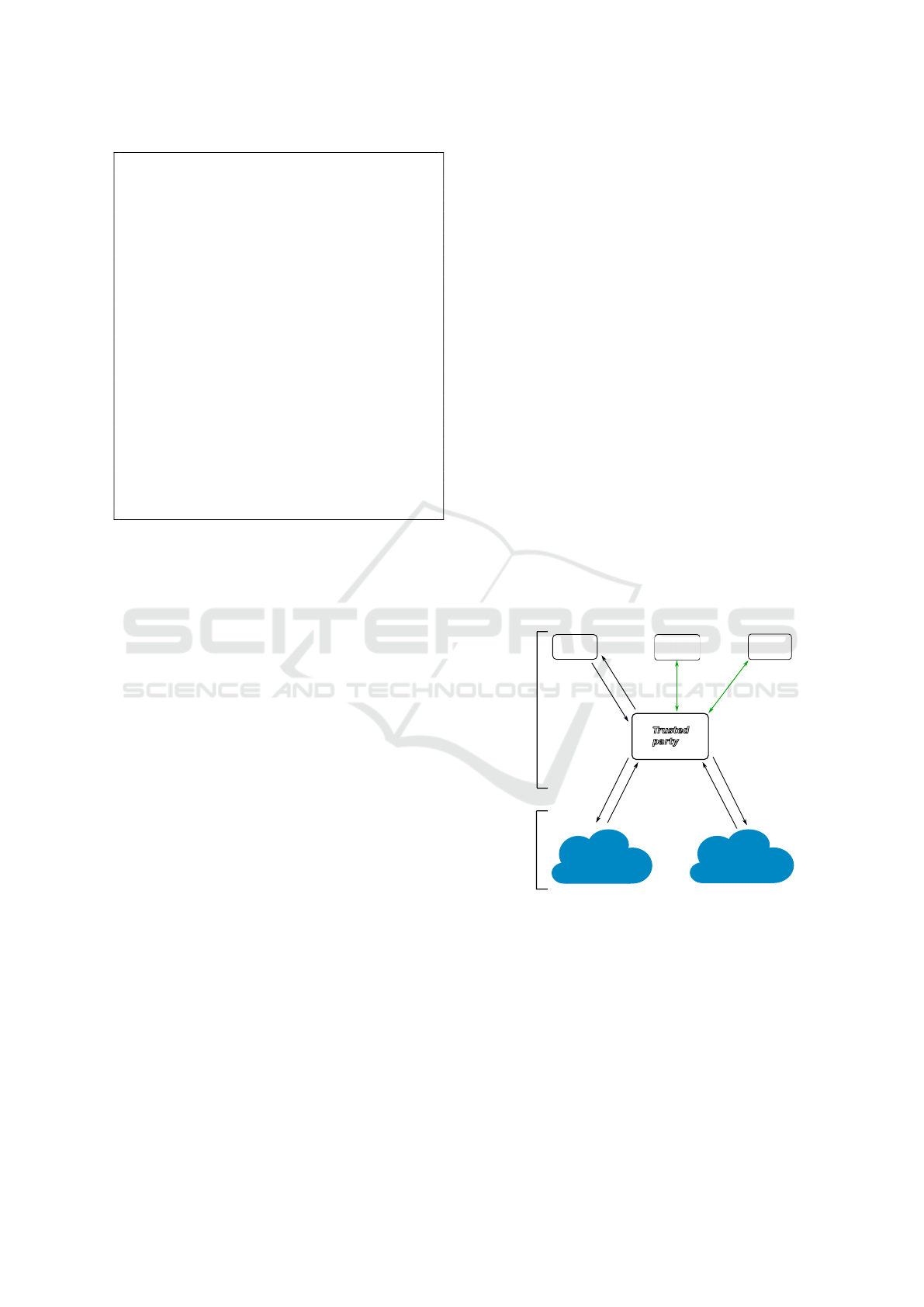
Figure 7: Genetic data sharing scenario via a trusted party.
Scenario Architecture. We illustrate an implemen-
tation of a variant of the sharing through the trusted-
party architecture presented in Sec. 2.1, variant shown
in Fig. 7. This architecture variant is used as part of
a scenario for sharing genetic cohorts in GWAS. In
this scenario, genetic data is of two sorts: case data
represents the set of vcf files containing variants be-
longing to patients holding the studied disease, while
control data concerns healthy participants. As is often
the case in genetics, control data are not in sufficient
Constructive Privacy for Shared Genetic Data
493

supply in research centers: data sharing with exter-
nal researchers that possess interesting control data is
therefore of high interest.
We present participants with their zip code, day of
birth (DoB), gender, information of whether the sub-
ject is contributing case or control data and their
corresponding vcf file. Had the database been local,
the representation would be in two tables as follows:
Subject (SubjectId,ZIP,DoB,Gender,CaseCtrl)
SubjectVcf (recordId,Variant,TypeVariant,
position,SubjectId)
For privacy-preserving outsourcing in the cloud
that fits the aforementioned requirements defined by
geneticians, four security techniques are applied in
the scenario:
• Fragmentation for confidentiality: the triplet
(zip code,gender,DoB) forms a quasi-identifier
(Sweenay, 2000): fragmentation is therefore used
to forbid any re-identification attempts. There-
fore, we store the pair (zip code, gender) and
DoB in different fragments in different non-
communicating Clouds (denoted as LeftCloud
and RightCloud in Fig. 7);
• Encryption for confidentiality: used for any data
that can not be fragmented nor it can be kept plain
at cloud level; in our scenario case, the vcf file
is symmetrically encrypted (field-wise) except for
the position field;
• Watermarking for ownership and integrity pro-
tection of genomes. In fact, genomes will be
accessed in clear format by the trusted party and
any unintended disclosure of data can also threa-
ten the ownership of data and its integrity.
• Client-side computations are used for TP com-
putations. This means that the geneticians need
to share (only) their decryption keys with the TP
which satisfies the first requirement of genetici-
ans as any access to identifying data is performed
through the trusted party.
Querying a database is more efficient when data is
plain. Therefore, increasing performance can be
achieved by decreasing the application of costly se-
curity techniques. One essential idea behind the com-
position of security and privacy-enhancing techniques
is foremost using any security method that will keep
data in plain format and does not threaten privacy. A
typical corresponding application case consists in in-
formation whose sensitivity results from it being asso-
ciated to other data. The triplet (zip code,gender,DoB)
is an example.
As part of the scenario, G1, G2 are genetic rese-
arch sites that initially each possess case data files;
G3 holds control data. We first assume that every re-
searcher and genetic center already outsourced their
data to a cloud provider as introduced above. In the
scenario, G1 wishes to process an association study
over a disease X. For this purpose, G3’s control sets
are needed. The scenario then proceeds as follows:
1. G1 starts by requesting TP to perform an associa-
tion study over indicated variants (Q1,Q2,Q3).
2. TP asks G3 for authorization (A1) to use its cont-
rol data in the cloud for G1’s research.
3. Assuming G3 provided its authorization, TP can
apply distributed queries to the corresponding
cloud databases and thus get the necessary data
(demographic data and parts of vcf files).
4. After computations are done, TP communicates
the inferred results to G1 (in a secure manner e.g.,
an SSL connection).
The architecture can also accommodate special
cases of sharing. For instance, it may happen that
G1’s datasets are not sufficient for some study: TP
then can search complementary data from other ge-
neticians which obviously requires their authorization
(A2).
To prepare for the implementation of the scena-
rio, we need to write correct queries, a process which
is performed using the laws about privacy-enhancing
compositions. We consider two queries, one for re-
trieving demographic data and another query to recu-
perate genetic data. The new tables of the new dis-
tributed database after applying the aforementioned
techniques become (cf. Fig. 7):
leftCloudTab (SubjectId,ZIP,Gender)
rightCloudTab1 (recordId,VariantWE,
TypeVarE,position,
SubjectId,)
rightCloudTab2 (SubjectId,DoB,CaseCtrl)
As the genetic application represented in the sce-
nario is an (abstract) genetic association computation
performed by the trusted party, both demographic and
genetic data should be provided by the cloud provi-
ders. The first query over the distributed Subject ta-
ble is meant to return the zip code and the DoB of
male subjects holding the disease. In order to retrieve
this data from the distributed environment the query
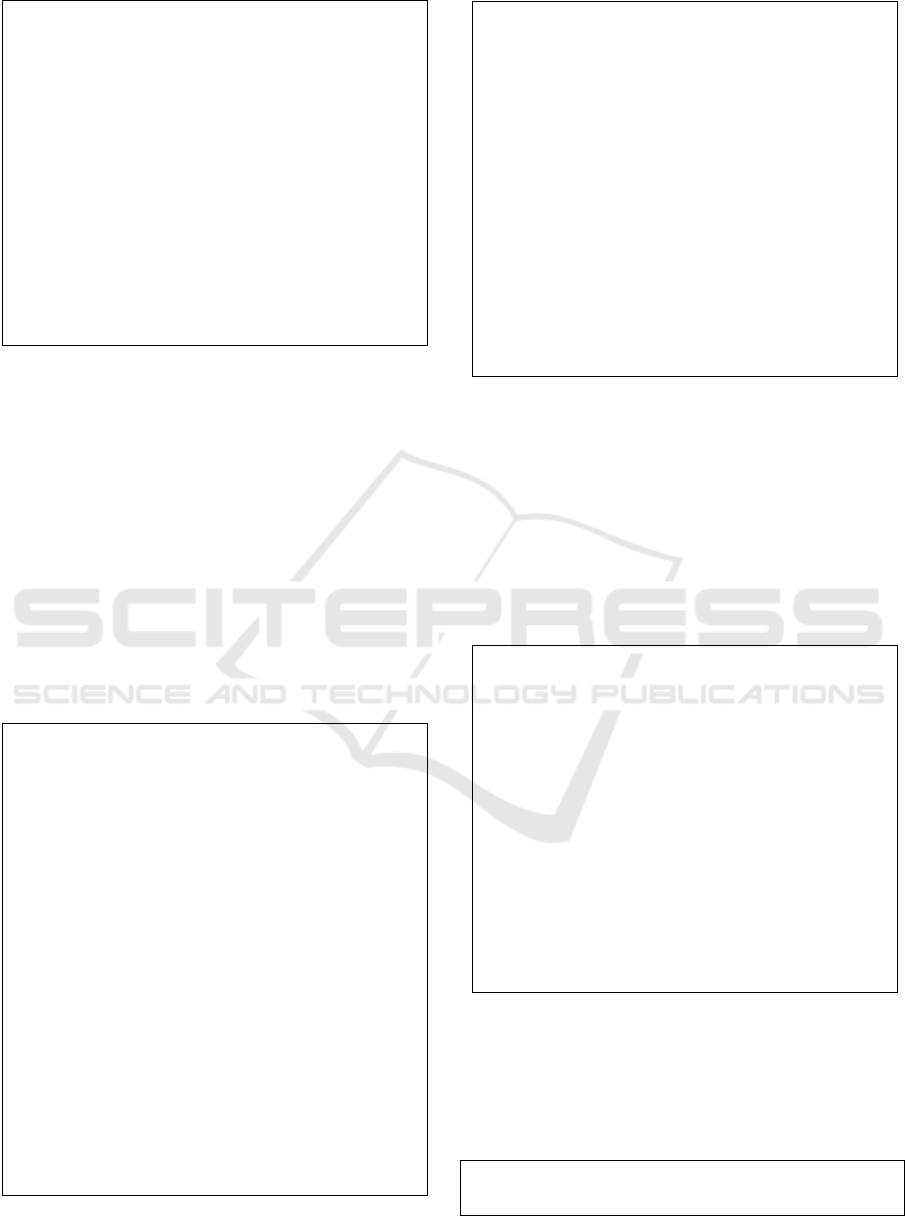
should be split. Fig. 8a shows a suitable local version
of the query. In a distributed setting, we use com-
mutation laws to obtain a distributed query (Fig. 8b)
from a local one. As for the genetic data recovery
query, the goal is to retrieve some specific positions in
the genomes of the previously selected males demo-
graphic data (which are the results of the first query,
CLOSER 2018 - 8th International Conference on Cloud Computing and Services Science
494
π
(zip,dob)
◦ σ
(gender=male∧caseCtrl=true)
(a) local query .
π
(zip,dob)
◦ σ
(gender=male∧caseCtrl=true)
◦
defrag
zip,gender
◦ frag
zip,gender
laws 1, 2 ↓
defrag
zip,gender
◦
(π
zip
◦ σ
(gender=male)
,π
dob
◦ σ
(caseCtrl=true)
)◦
frag
zip,gender
(b) distributed query .
Figure 8: Query for demographic case data recovery.
referred to as mdd in the figure). Therefore, the right
Variant and TypeVariant elements are returned. Simi-
larly, this second query is transformed from a local
formula (Fig. 9a) to a distributed one (Fig. 9b) using
the identity and commutation laws of encryption and
watermarking described earlier in Secs. 3 and 3.1, re-
spectively. The last distributed query obtained shows,
after law-driven transformations, that to have access
to both columns, a decryption step and a watermark
detection operation should be executed over the data,
a step that ’deconstructs’ the previous encryption and
watermarking introduction that were necessary for a
secure and privacy-preserving outsourcing process.
π
(variant,typeVar)
◦
σ
((sub jectId∈mdd)∧(position=i,position= j,..))
(a) local query .
π
(variant,typeVar)
◦
σ
((sub jectId∈mdd)∧(position=i,position= j,..))
◦
decrypt
variant,typeVar
◦ crypt
variant,typeVar
◦
detectw
variant
◦ wat
variant
laws 3, 4,6, 7,8 ↓
detectw
variant
◦ decrypt
variant,typeVar
◦
π
(variant,typeVar)
◦
σ
((sub jectId∈mdd)∧(position=i,position= j,..))
◦
crypt
variant,typeVar
◦ wat
variant
(b) distributed query .
Figure 9: Query for genetic case data recovery .
1 sce na ri o : Ge ne ti cQ ue ry [ Sub je ctI d , ZIP , Gen der , DoB ,
2 Va ria nt , Ty peV ar , My Ta tt oo ]
3 sce na ri o = do
4
5 G1 ‘ S end Re qu est ‘ ( TP ,[ Q 1 ])
6 G1 ‘ S end Re qu est ‘ ( TP ,[ Q2 , Q2 ’] )
7 G1 ‘ S end Re qu est ‘ ( TP ,[ Q3 , Q3 ’] )
8
9 TP ‘ S end Re qu est ‘ ( L eft Cloud ,[ Q 1 ])
10 TP ‘ S end Re qu est ‘ ( R igh tC lou d , [Q2 , Q2 ’] )
11 TP ‘ S end Re qu est ‘ ( R igh tC lou d , [Q3 , Q3 ’] )
12
13 let q1 = Lef tC lo ud ‘ e xe cut eR eq ue st ‘ [ Q1 ];
14 let q2 = RightCl ou d ‘e xe cu te Req ue st ‘ [ Q2 , Q2 ’] ;
15 let q3 = RightCl ou d ‘e xe cu te Req ue st ‘ [ Q3 , Q3 ’] ;
16
17 demD at al ← L ef tC lo ud ‘ Se ndDa ta ‘ (TP , q1 )
18 demD at ar ← R ig ht Cl ou d ‘S end Dat a ‘ ( TP , q 2 )
19 vcfF il es ← R ig ht Cl ou d ‘S end Dat a ‘ ( TP , q 3 )
20
21 let r1 = dec ry pt Va ri an tW E ( A ESD " key 2 ") vcfFi le s ;
22 let r2 = dec ry pt Ty pe Va rE ( AES D " ke y1 ") r1 ;
23 let v cfF il es = d etect w Va riant W ( R GIG " wkey1 ") r 2;
24 let Da ta = defra g ( d ef rag d em Da tal d em Da ta r ) v cf Fi le s
25
26 TP ‘ R eturn Re su lts ‘ ( G1 , TP ‘C omp ute ‘ D ata )
Figure 10: Scenario implementation .
Scenario Implementation. The scenario imple-
mentation is given in Fig. 10: it initially sends query
requests from the genetician G1 to the trusted party TP
that forwards them to the two clouds where they are
executed. The resulting data is sent back to TP where
the genetic computation is performed. The correspon-
ding results are then communicated to G1.
1 -- En tit ie s
2 da ta En tity = Ge ne ti ci an | Tr us te dP | Cl ou d
3
4 G1 , TP , Lef tCl ou d , R ig ht Cl ou d : En tit y
5 G1 = G en et ic ia n ; TP = T ru st ed P
6 L ef tC lo ud = C lo ud ; Rig ht Cl ou d = Clo ud
7
8 l ef tClou dT ab , righ tC lo ud Tab1 , rig ht Cl ou dT ab 2 : Schem a
9 l ef tClou dT ab = i nd ex 1 Sa fe TP En v . ..
10
11 - - Qu er ie s
12 Q1 : Q ue ry [ S ub jec tId , ZIP , Gend er ]
13 Q1 = π [ Su bject Id , ZIP , G en der ]
14 $ σ ( Ge nd er == "m al e ") ( t oQ uer y le ft Cl ou dT ab );
15
16 - - A DT whi ch pa ra me te r in di ca te s t he expec te d re sul ts
17 - - o f an ex ch ang e or co mp ut at io n in vo lv in g gen et ic da ta
18
19 d ata G en et ic Qu er y : Sch em a → Ty pe whe re
20
21 S en dR eq ue st :
22 En ti ty → ( En ti ty , L ist ( Que ry ∆)) → G en et icQ ue ry ∆
23 Send Da ta : ...
24 Co mp ut e : .. .
Figure 11: Entities, queries and ADT for scenario building.
Fig. 11 shows the entity definitions for genetici-
ans, trusted parties and clouds, a query and the main
part of the ADT for genetic queries.
1 ... let r1 =
2 de te ct w Var ia nt WE ( AES D " ke y2 ") v cf Fi les -- e rr or
3 let r2 = de crypt T yp eV arE ( AE SD " k ey1 ") r1 ; . ..
Figure 12: Ill typed query.
Constructive Privacy for Shared Genetic Data
495

Ensuring Privacy Properties. Our approach, being
based on Idris, allows for proofs of certain safety pro-
perties (that entail security and privacy properties) to
be passed as arguments to operators that are part of
correctly built queries. For instance, if we try to wa-
termark a genetic data that is already encrypted, type
checking will not pass because of the proof p1 of the
wat operator that verifies data has not been transfor-
med yet. Similarly, trying to detect a watermark from
data that has not been decrypted yet will give rise to a
type checking error, see Fig. 12.
4 CONCLUSION
In this paper we have pointed to the lack of program-
ming support for privacy-preserving applications that
manipulate shared genetic data. We have presented
two contributions: (i) new cloud-based architectu-
res for such applications that are motivated by con-
crete requirements from researchers in genetics and
(ii) a model and corresponding security- and privacy-
enhancing techniques for the development of such ap-
plications, notably using watermarking for the preser-
vation of ownership and integrity properties.
As future work, we are striving for the integra-
tion of other privacy-enhancing techniques, an effi-
cient implementation of a general Java library for bi-
omedical analyses using shared genetic data, and its
application to real-world genetic analyses.
ACKNOWLEDGEMENTS
We thank our partners from the PRIVGEN project
2
, in
particular, D. Niyitegeka, G. Coatrieux and E. Genin,
for valuable discussions on watermarking and genetic
data sharing.
REFERENCES
Behjati S, T. P. (2013). What is next generation sequen-
cing? Archives of Disease in Childhood Education
and Practice Edition.
Bouslimi, D., Coatrieux, G., et al. (2016). Data hiding
in encrypted images based on predefined watermark
embedding before encryption process. Signal Proces-
sing: Image Communication, 47.
Cherrueau, R.-A., Douence, R., and S
¨
udholt, M. (2015).
A Language for the Composition of Privacy-
Enforcement Techniques. In IEEE RATSP, pages
1037 – 1044, Helsinki, Finland.
Ciriani, V., Vimercati, S. D. C. D., Foresti, S., et al. (2010).
Combining fragmentation and encryption to protect
privacy in data storage. ACM Trans. Inf. Syst. Secur.,
13(3):22:1–22:33.
Cousin, E., Deleuze, J.-F., and G
´
enin, E. (2006). Selection
of SNP subsets for association studies in candidate ge-
nes: . . . . BMC Genetics, 7:20.
Erlich, Y. and Narayanan, A. (2014). Routes for breaching
and protecting genetic privacy. Nature Reviews Gene-
tics, pages 409–421.
Gulcher, J. R., Kristjansson, K., Gudbjartsson, H., and
Stefnsson, K. (2000). Protection of privacy by third-
party encryption in genetic research in iceland. Euro-
pean Journal Of Human Genetics.
Homer, N., Szelinger, S., Redman, M., et al. (2008). Resol-
ving individuals contributing trace amounts of dna to
highly complex mixtures using high-density snp ge-
notyping microarrays. PLOS Genetics, 4(8):1–9.
Iftikhar, S., Khan, S., Anwar, Z., et al. (2015). Genin-
foguarda robust and distortion-free watermarking
technique for genetic data. PLOS ONE, 10(2):1–22.
Kantarcioglu, M., Jiang, W., Liu, Y., and Malin, B. (2008).
A cryptographic approach to securely share and query
genomic sequences. Trans. Info. Tech. Biomed.,
12(5):606–617.
Liina Kamm, Dan Bogdanov, S. L. et al. (2013). A new way
to protect privacy in large-scale genome-wide associ-
ation studies. Bioinformatics (Oxford, England).
Lu, W.-J., Yamada, Y., and Sakuma, J. (2015). Privacy-
preserving genome-wide association studies on clouds
using fully homomorphic encryption. BMC Medical
Informatics and Decision Making, 15(5):S1.
McLaren, P. J., Raisaro, J. L., Aouri, M., et al. (2016).
Privacy-preserving genomic testing in the clinic: a
model using hiv treatment. Genetics in Medicine,
18(8):814–822.
Sweenay, L. (2000). Simple demographics often identify
people uniquely. Carnegie Mellon. Data Privacy Wor-
king Paper 3.
Tang, H., Jiang, X., Wang, X., et al. (2016). Protecting
genomic data analytics in the cloud: state of the art
and opportunities. BMC Medical Genomics, 9(1):63.
Wang, R., Wang, X., Li, Z., Tang, H., et al. (2009). Privacy-
preserving genomic computation through program
specialization. In ACM CCS, pages 338–347, New
York, NY, USA. ACM.
Xie, W., Kantarcioglu, M., Bush, W. S., et al. (2014). Secu-
rema: protecting participant privacy in genetic associ-
ation meta-analysis. Bioinformatics, 30(23):3334.
Zhang, Y., Dai, W., Jiang, X., et al. (2015). Foresee: Fully
outsourced secure genome study based on homomor-
phic encryption. ”BMC Medical Informatics and De-
cision Making, 15(5):S5.
CLOSER 2018 - 8th International Conference on Cloud Computing and Services Science
496
