Membrane Layer Method to Separate Simulation and Visualization for
Large-scale In-situ Visualizations
Akira Kageyama, Naohisa Sakamoto and Kohei Yamamoto
Department of Computational Science, Kobe University, Kobe 657-8501, Japan
Keywords:
In-situ Visualization, High Performance Computing, CFD, Magnetohydrodynamics, MPMD.
Abstract:
With the progress of simulation technology, the demand for the in-situ visualization i n high-performance
computing is increasing. We propose a multiple-program, multiple-data (MPMD) approach to the in-situ vi-
sualization to realize interactive in-situ visualizations. We separate processor nodes in a massively parallel
computer system into two parts; one devoted only to the simulation and the other devoted only to the visuali-
zation. Both the simulation and visualization programs are parallelized by MPI ( Message Passing Interface).
The number of MPI processes for the visualization is the same or larger than that for the simulation. The
multiple camera method that we proposed in our previous study enables interactive analysis of the visualiza-
tion movies thus generated. The simulation and visualization programs are separated by a layer mimicking
a semipermeable membrane. It is semipermeable because information runs in one-way from the simulation
to the visualization through the layer, and the layer prevents the simulation program from being affected by
visualization program’s possible delay. The membrane is implemented as two independent MPI programs
which correspond to the front and back faces of it. The four MPI programs (the simulation, visualization, and
membrane faces) are executed at once based on an MPMD framework.
1 INTRODUCTION
In contra st to the post-process visualization, the pre-
sence of the in-situ visua lization is gradua lly ri-
sing (Bethel et al., 2013). A straightforward way to
realize the in-situ visualization is to perform the visu -
alization on the same computer system as the simu-
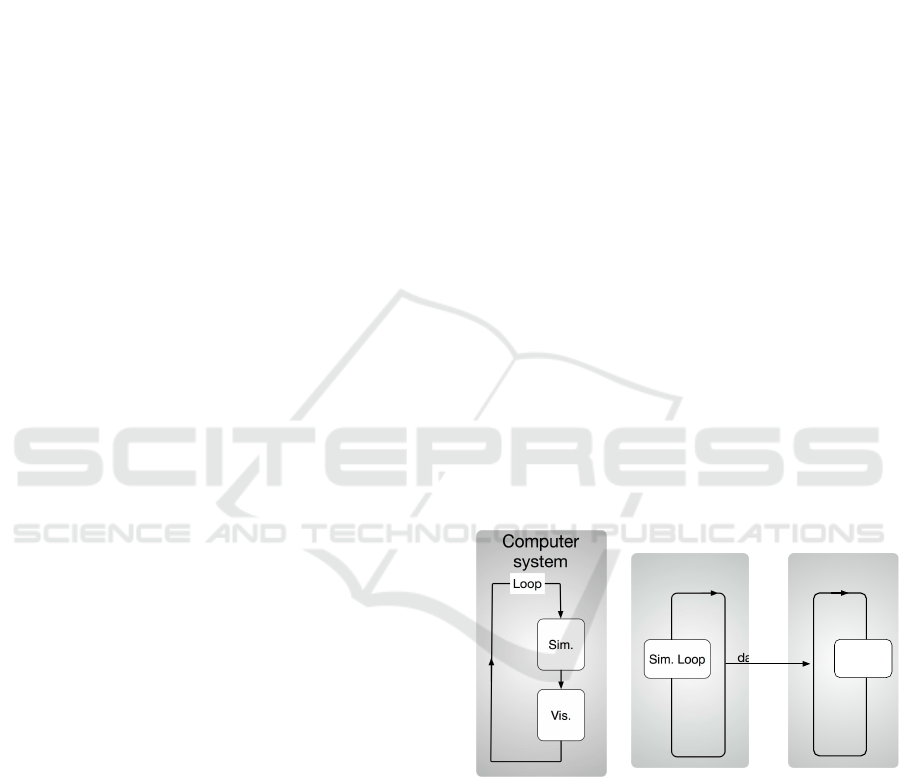
lation [see Fig. 1(a)]. The visualization in this me t-
hod, h owever, erodes the computational resources for
the simulation such as the memory and processing
time. One can avoid the resource erosion by perfo r-
ming the visualization on another computer system
[see Fig. 1(b)]. In this approach, one has to send simu-
lation data through the network between the two com -
puter systems whose bandwidth is usually narrow.
We take in this paper another approach to the in-
situ visualization, which is a kind of combination of
the two styles shown in Figs. 1(a) and (b). In this in-
situ visualization, both the simulation and visualiza-
tion run in the same computer system but on different
processor nodes; see Fig. 2.
The motivation of this study stems from the recent
trends of th e growing number of processor nodes in
supercomputer systems. The K computer, for exam-
ple, has more than 82,000 SPARC64 VIIIfx processor
Sim.
Vis.
Loop
Computer
system
(a)
Sim. Loop
data
(b)
Vis. Loop
Computer
system
Network
Computer
system
Figure 1: Two styles of in-situ visualization. (a) Visualiza-
tion is performed on the same computer system as the simu-
lation. (b) Visualization is performed on a different compu-
ter system from the simulation. The simulation data to be
visualized are transferred t hrough the network connecting
the two systems.
nodes. It is difficult for most simulation programs to
occupy such a system with full nodes by one job. As
the Amdahl’s law says (Amdahl, 2007), the speedup
of the execution time by th e parallelization saturates
at the node number around 5000, when just 5% of the
code is not parallelized. Since the number of proces-
sors in today’s supercomputers is excessive for most
106
Kageyama, A., Sakamoto, N. and Yamamoto, K.
Membrane Layer Method to Separate Simulation and Visualization for Large-scale In-situ Visualizations.
DOI: 10.5220/0006854901060111
In Proceedings of 8th International Conference on Simulation and Modeling Methodologies, Technologies and Applications (SIMULTECH 2018), pages 106-111
ISBN: 978-989-758-323-0
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
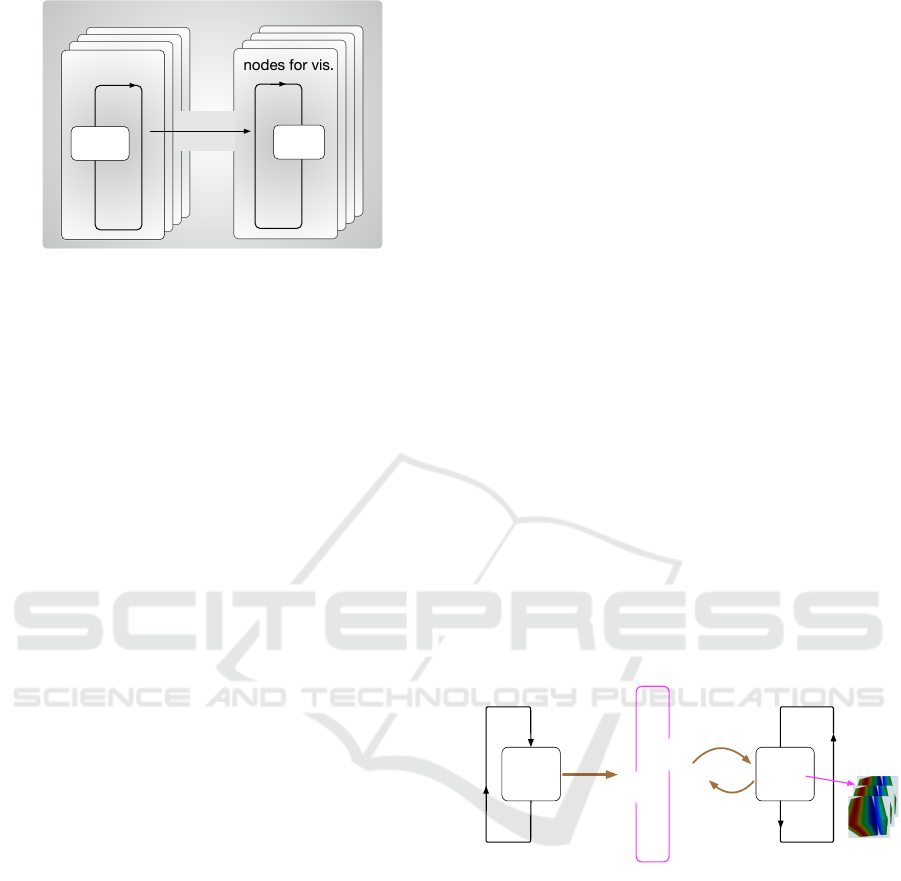
nodes for vis.
Sim. Loop
Vis. Loop
nodes for sim.
Computer system
data transfer
by MPI
Figure 2: In-situ visualization proposed in this paper. Both
the simulation and visualization are performed on the same
(parallel) computer system. The same or even larger num-
ber of processor nodes is allocated to the visualization than
the processor nodes for the simulation.
simulation programs, we have to conceive a new way
to make the best use of supercomputer systems, and
we be lieve that the in- situ visualization is a pro mising
candidate.
Recently, a similar in-situ visualization to our met-
hod is reported (Bu ffat et al., 2 017). In addition to the
existence of the membrane layer described below, a
difference between their study and ours is the number
of processor nodes devoted to the visualization. The
number of visualization nodes in theirs is smaller than
the number of nodes used for the simula tion. On the
other hand, we use the same or even larger number of
processor n odes for the visualization compared with
the simulation nodes.
2 DESIGN
In the du al-system approach to the in-situ visualiza-
tion shown in Fig. 1(b), simulation data are sent to the
visualization system through the network betwee n the
two computer systems. On the othe r hand, in our me t-
hod, we do not have to invoke such a (usually slow)
data transfer because both the simulation and the visu-
alization programs run on the sam e computer system:
We can take advantage of the broad bandwidth bet-
ween the processing nodes in a supercomputer system
and a customized libr ary of MPI (Messag e Passing In-
terface) optimized to the system.
In our in-situ visualization method, the simula-
tion and visualization are almost independent applica-
tions. Since there is no tight connection or sync me-
chanism between them, the execution speeds of the
two applications can be very different. Before each
execution, one is supposed to a llocate adequate num-
bers of processor nodes for the simulation and visu-
alization in such a way that the two application s run
with a balanced pair of loads. In som e c ases, howe-
ver, the bala nce might collapse. Pr eparing for such a
situation, we set a principle that priority is given to the
simulation rather than the visualization: The simula-
tion should run without being affected by the visua-
lization, even if the visualization takes tremendously
long time to render an image. In other words, un-
der this principle, we want the simulation job to run
without waiting for the end of the rendering even if
we might lose certain range of image sequence of the
output visualization movie.
In practice, a simulation researcher usually has an
estimated time for a pure simulation job (without an
in-situ visualization) under a given numbe r of paral-
lel processors, say N
s
. In our approach to the in-situ
visualization, we allocate additional no des N
v
in the
same computer system devoted to the visualization.
Since the visualization job on these N
v
nodes d oes not
affect the simulation job on N
s
nodes, the estimated
time for the simulation job is basically the same if we
can igno re the data transfer time from the simulation
to the visualization by mak ing u se of an intermediate
layer, which will be described in the next section .
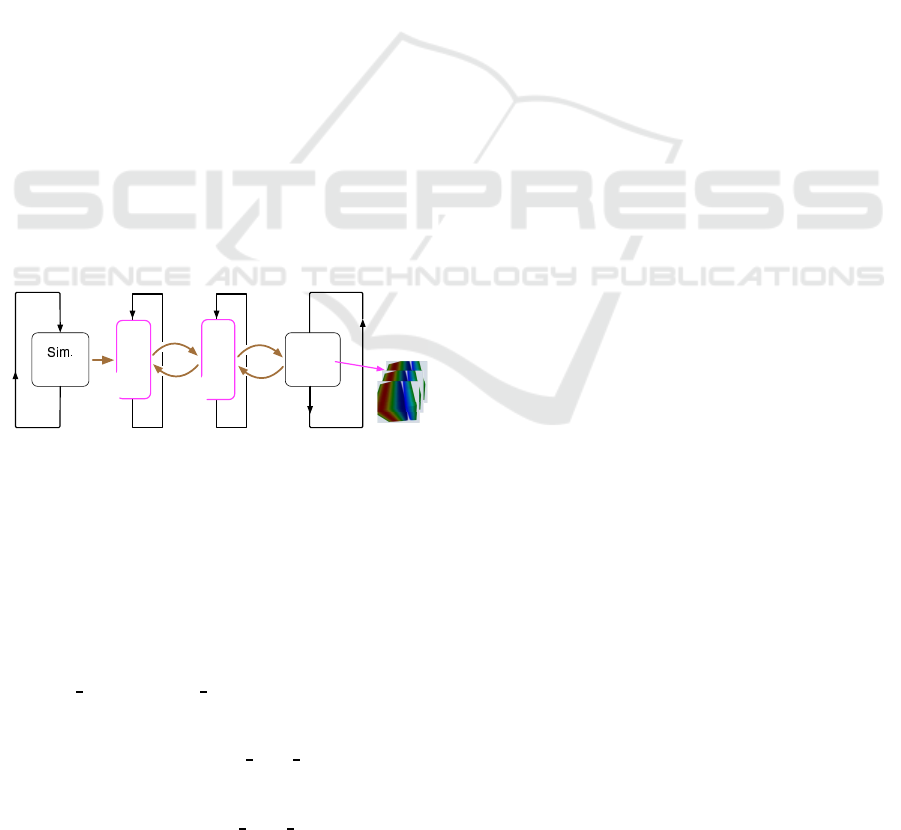
3 MEMBRANE LAYER
We place a virtual “semipermeable membrane” bet-
ween the simulation and the visualization, to fully se-
parate the two programs. See Fig. 3.
Sim.
program
images
Main loop
Viz.
program
Main loop
request
of new data
data
data
Membrane
Figure 3: The membrane model proposed in this study. It
separates the simulation program and the visualization pro-
gram. The visualization program is invisible to the simula-
tion program, and vice versa, by the membrane. The simu-
lation program “throw” numerical data to be visualized to
the membrane and the membrane is always ready to receive
them. The membrane pass the data to the visualization pro-
gram on demand from the visualization program.
One of the purposes of the membrane is to make
the two programs being “invisible” each other. The
simulation program, which is an MPI-based parallel
program, can communicate only with the membrane :
The visualization program is invisible f or the simula-
tion progr am. On the other hand, the visualizatio n
program, which is also an MPI-based parallel pro-
gram, can communicate o nly with the membrane and
the simulation program is invisible. For simulation
Membrane Layer Method to Separate Simulation and Visualization for Large-scale In-situ Visualizations
107
researchers, the inv isibility is helpful because it re-
leases them from the burden of visualization-related
tasks. They just throw simulation data to the (front
side of) m embrane and the all tasks are automa tica lly
done.
The membrane is semipermeable because the in-
formation goes in o ne way. While the simulation data
is sent from the simulation prog ram to the visualiza-
tion program, no information is sent from the visua-
lization to the simulation. (Only one exception is a
vital sign of the visualization program: A flag signal
is sent to the simulation when the visualization hap-
pens to die d ue to some error.)
The membrane is implemen te d as two ind e pen-
dent MPI programs. They conceptually correspond
to the f ront face (simulation side) and the back face
(visualization side) of the membrane. The front and
back face pro grams h ave N
f
and N
b
MPI processes,
respectively. See Fig. 4.
The purpose of the front face program is to re-
ceive the simulation data from the simulation pro-
gram. Since the front face program is devoted to this
task of data re c eiving, the simulation program can as-
sume that the data transfer is completed without delay,
even if other programs (the back face of the mem-
brane and the visualization) are doing their work. By
this mechanism, the membrane a llows the simu lation
program to run without being influenced by the visu-
alization, along the “simulation first” principle menti-
oned above.
program
images
Main loop
Viz.
program
Main loop
Main loop Main loop
request
request
data data
data
Front face
Back face
Figure 4: The implementation of the membrane. It consists
of two independent MPI programs, which correspond to the
front and the back faces of the membrane.
In total, we have four MPI programs to realize the
proposed in-situ visualization method: One simula-
tion program, two membrane programs (front & back
faces), and one visualization program. We execute
the four a s an MPMD (Multiple-Progra m, Multiple-
Data) type application. Each prog ram is a stand-
alone, independent MPI program. (They have their
own
MPI Init
and
MPI Finalize
calls.) By sub-
mitting the four MPI executables to a supercompu-
ter at once as an MPMD application, a comprehen-
sive MPI communicator (
MPI Comm world
) is auto-
matically constructed. The four programs comm uni-
cate with each other by the standard MPI function s
within th e communicator
MPI Comm world
.
As the simulation goes on, it sporadically sends
data D
n
to the front face of the me mbrane, with D
n
being a set of simulation to be visualized. Th e index
n (= 1, 2, 3,.. .) is a time counter. It is usually much
smaller than the simulation’s main loop counter ℓ; for
example, ℓ = 100 n when one visualizes the data every
100 steps of th e simulation. In most of its execution
time, the front face prog ram waits for the new data D
n
from the simulation program and receives it immedi-
ately when it is sent. After c ompleting the transfer o f
D
n
, the simulation program continues its job an d the
front face p rogram send s D
n
to the back face program
of the membrane.
On the con trary to the front face, the back face is
rather busy. Its mission is to store the latest simulation
data, and pass them to the visualization program when
they are requested.
When the visualization program has finished its
job for the latest visualizing data D
n−1
, it sends a re-
quest signal to the back face of the membran e for the
next data. There are three possible cases here.
Case 1: The visualization job (for D
n−1
) is finis-
hed so swiftly that the membrane programs still hold
D
n−1
. In this case, the back face of the membrane
does not r e turn any data to the visualization until it
receives the new data D
n
from the simulation (via the
front face of the membrane) .
Case 2: The membranes already have the new d a ta
D
n
when the re quest signal comes from the visualiza-
tion. This is the ideal case for the load balance bet-
ween the simulation and v isu alization. T he bac k face
sends D
n
to the visualization in resp onse to the re-
quest.
Case 3: The visu a lization job (for D
n−1
) is so slow
that the sim ulation job produces the new data D
n+1
while the visualization (for D
n−1
) is still running. In
this case, the data D
n
on the membranes are overwrit-
ten by D
n+1
. Information of D
n
will be missing in
the visualization movie produced by this in-situ visu-
alization method. This is the defect we intentionally
accept, following the “simulation first” principle.
4 INTERACTIVE VIEWING OF
IN-SITU VISUALIZATION
MOVIES
A problem in the in-situ visualization as a practical
tool for the simulation’s analytics is that the u ser can-
not inte ractively change the visualization-r elated va-
riables, such as the view point, viewin g direction, vi-
sualization methods and their parameters. To over-
come this problem, we proposed a m ulti-camera ap-
SIMULTECH 2018 - 8th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
108

proach (Kageyama and Yamada, 2014). Since the de-
tails are reported in detail in our paper, here we briefly
summarize it.
Figure 5: The movie database in our multiple camera met-
hod (Kageyama and Yamada, 2014) for interactive in-situ
visualization. Applying the i n-situ visualization on many
cameras scattered in and around the simulation region, we
get a movie database, or a “field” of images defined in four-
dimensional (4-D) space; 3-D for the camera position and
1-D for time or frame in the movies. The user specifies a
“path” in the 4-D space. A specially designed browser ex-
tract a sequence of still images on the path and show them
as an animation on the PC’s screen.
We scatter a lot of virtual cameras, or view poin ts,
inside and around the simulation region, applying in-
situ visualizations at once with them. As a result of
this multiple in-situ visualizations, the same number
of movie files as the number of cameras are produced
at the end of the simulation. We construct a database
by assoc iating the camera position to e ach movie. As
shown in Fig. 5, the datab ase is regarded as a “field”
of still images defin ed in a four dimensional spac e:
The still images are located in a three-dimensional
spatial (x,y, z) d imension and one-dimensional tem-
poral (t) dimension . We retrieve the movie database
from the supercom puter system to a PC and explore
the database with a specially designe d database brow-
ser. The browser shows image sequences (animati-
ons) on a window of a PC’s screen. An image se-
quence is extracted from the database according to a
user-specified “path” in the four dimension a l space.
By this method, we can attain the in teractive viewing
of in-situ generated v isualizations. For example, the
user can walk through the simulation space through
the PC’s interface (the mouse and keyboard) to find a
hot spot of interest in the sim ulation region, and o b-
serve the structure or dynamics there in detail from
the closest camera to the spot with adequate visuali-
zation methods and parameters.
A key point of our interactive in-situ visualization
is to have sufficient number of view points or cameras.
The larger the number of cameras, the smoother we
get in the walk-through. In the present study, we place
N
v
cameras inside and around the simulation region,
and perform N
v
in-situ visualizations in parallel, i.e.,
one visualization per one node.
We use functionalities of the KVS (Kyoto Visua-
lization System) (Sakamoto and Koyamada, 2015) in
the visualization program. The KVS is an efficient
framework for scientific visualization and provides
a rich set of modules for the visualization pipeline,
i.e., data importing, filtering, mapping and rende-
ring (Telea, 2014). The KVS uses OpenGL graphics
library for hardware acce le rated renderin g with GPU
(Graphics Processing U nit). Therefore, the visuali-
zation program requires a software emulation to run
on a supercomputer system without GPUs. In th is p a -
per, we use the off-screen ren dering framework for the
KVS (Nonaka et al., 2018) based on OSMesa (Off-
Screen Mesa), which has be c ome the de facto stan-
dard for the CPU extension of OpenGL.
5 TEST
We te st our in-situ visualiza tion method on a su-
percomputer system Oakforest-PACS (Fujitsu PRI-
MERGY CX600 M1) which consists of 8208 nodes
with one Inte l Xeon Phi in each node. The target si-
mulation is our original MHD (magnetohydrodyna-
mics) simulation co de, named cg-mhd.
We solve the compressible MHD equations in a
rectangu la r region with cg-mhd. The 2nd-order fi-
nite difference method on the c artesian coordina te sy-
stem is used for the spatial derivatives in the equa-
tions and the 4th-order Run ge-Kutta method is used
for the temporal integration. The simulation region is
divided into multiple sub-rectangular regions and one
MPI process is allocated to each sub-region. For tests,
we run cg-mhd with 32 nodes, or N
s
= 32.
The original cg-mhd code is a parallelized, stand-
alone, simulation c ode for various studies on MHD
pheno mena, such as M H D convection, MHD dyn-
amo, MHD self-organiza tion, etc. To incorporate the
code into the proposed in-situ visualization, all we
need to do is the following two minor modifications.
One is to chang e the n a me of the MPI’s to p-level
communicator. The origina l cg-mhd code uses the de-
fault MPI communicator
MPI Comm world
for the ma-
nagement of all MPI processes in the program. Since
the communicator variable
MPI Comm world
is u sed
for the inter-program co mmunications in our MPMD
application, we rename the top-level communicator
in the c g-mhd from
MPI Comm world
to other name
(
comm sim
).
The second change we made to cg-mhd is an ob -
vious one: We add a fu nction call to send simulation
data to the front face of the membrane. It is just a call
of
MPI Send
.
Membrane Layer Method to Separate Simulation and Visualization for Large-scale In-situ Visualizations
109

While the simulation program (cg-mhd) and the
two membrane programs (front and back faces) are
written in Fortran 2003, the main part of the visuali-
zation program, KVS, is written in C++. We imple-
ment a wrapp er layer in Fortran 2003 over KVS. By
making use of the standard
ISO C BINDING
function
included in Fortran 2003 language specification, we
can easily pass the simulation data to KVS. Our soft-
ware is po rtable to any supercomputer system as long
as a Fortran 2003 compiler is supported.
(a)
(b)
Figure 6: Snapshots of a test in-situ visualization of an
MHD (magnetohydrodynamics) simulation in a rectangu-
lar region. An Al fv´en wave is propagated in a direction and
temperature (a) and density (b) fields are visualized with
KVS. The two panels (a) and (b) are taken from different
camera positions and on different time steps.
As a test, we visualize three scalar fields (pres-
sure, density, and temperature) simula te d by cg-mhd.
There ar e various po ssible ways to implement the
membrane. Here in this paper, we parallelize them
by field-base decomposition. The front face program
has three MPI pr ocesses, each of which is in charge
of r eceiving one of the scalar fields from the simu la-
tion pro gram. The back face of the membrane h a s the
same number (three ) of MPI process. Each process in
the back face receives the field data from its counter-
part in the front face.
The visualization program has 32 MPI processes,
or 32 cameras. Fig. 6 shows sample snapshots by two
cameras among the 32 cameras. A test MHD wave
(Alfv´en wave) propagation was successfully simula-
ted by cg-mhd and visua lized by KVS.
To estima te the effect of the membrane, we com -
pared two in-situ visualization methods, i.e., with and
without the membrane in the MHD simulation. The
computations were performed on a different compu-
ter system (Fujitsu FX- 10). The elapsed real time in
seconds (averages of five runs) f or 10, 000 steps of the
simulations are shown in Fig. 7. Th e in-situ visualiza -
tions are called every 50 steps in both cases. Than ks
to the membrane , the time for the simulation is dras-
tically reduced.
with
membrane
without
membrane
Figure 7: Elapsed time (in seconds) for the MHD simulation
with and without the membrane. In-situ visualizations are
called every 50 steps. The simulation time is almost halved,
owing to the membrane.
6 CONCLUSIONS
When one performs a massively p arallel simulation
on a supercomputer system, he/she faces two techn i-
cal problems. One is the difficulty in the data visua-
lization. As the scale of a simulation grows, the post-
process visualization, i.e., visualization after simula-
tion, becomes impractical due to the enormous size
of the numerical data produced by every simulation.
Although the in-situ visualization, i.e., visualization
at the same time as the simulation, is free from the
enormous numerical data, it slows down the simula-
tion ( in the mono-system application) or is baffled by
the limited bandwidth of th e inter-computer network
(in th e dual-system application).
The other technical problem in HPC is that it is
difficult to increase the number of proce ssor nodes
used in a massively parallel computer system for a
simulation due to the saturation of parallel efficiently.
After a certain amount of (usually painful) time spent
for the optimization of a parallel simulation code, it
is almost impossible to double the number of using
processor nodes under a given set of simulation para-
meters.
In this paper, we propose a framework for the
in-situ visualization for large-scale simulations to re-
solve the above two technical problems at once. In
this framework, we allocate—lavishly—a large num-
ber of processor nodes only f or the visualization in the
same superco mputer system as the simulation. Since
the simulation nodes and the visualization nodes are
closed in the same computer system, the data ca n be
swiftly transferred from the simulation no des to the
visualization nodes, owing to the optimized network
SIMULTECH 2018 - 8th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
110

system and the MPI implementation for the super-
computer system. (This resolves the first difficulty
of the visualization in HPC.) In our proposal, the size
of the allocated nodes for visualization is very large;
it can be the same or even larger than the size of the
simulation nodes. (This resolves the second difficulty
of the para lleliza tion.)
A simple in-situ visualization loses the user’s inte-
ractivity such a s th e viewpoint control, which is very
important for effective a nalysis. We can overcome
this problem by making use of the multi-camera met-
hod proposed in (Kageyama and Yamada, 2014), in
which we apply multiple in-situ visualizations at once
from many view points scattered as dense as possible
in and around the simulation region. The abundant
nodes for the visualization enables us to perform such
a lavish v isualization style.
Using more nodes for the visualization than for
the simulation, our proposal can be regarded as a new
way of supercomputer usage: The machine is mor e
for the visualization rather than for the simulation.
It would not be unreasonable becau se, in extremely
large-scale HPC, researchers tend to spend more time
for the visualization than for the simulation.
We have developed an MPMD application in
which four MPI programs are executed at on c e. The
first program is for the simulation. Although we used
in this paper an MHD simula tion code as a test, this
simulation part is interchangeable in our framework.
To enab le visualization on CPU-based supercom-
puter systems with out GPU, we have developed a pa-
rallel visualization program based on KVS, which is
a general- purpose visualization framework written in
C++, in its off-screen rendering mode. To receive
data sent from simulation program, we implement a
wrapper layer for this visualization program in For-
tran 2003 over KVS.
We place a membrane-like layer betwee n the si-
mulation and the visualization pr ograms. One of the
purposes of the membrane is to fully separate the si-
mulation and visualization. From the simulation code
level, we do not “see” the existence of the visualiza-
tion program: We do not call any visualization-related
function from the simulation. All we have to do in
the simulation code is to th row numerical data to the
membrane. The invisibility reduces the burden of the
visualization-related works to simulation researchers
in realizing the in-situ visualization on supercompu-
ters. The membran e also prevents the simulation pro-
gram from being influenced by the visualization pro-
gram.
The membrane is implemented by two indepen-
dent MPI programs. The two programs correspond to
the front and back faces of the mem brane. The front
face is to receive numerical data from the simulation
and the back face is to pass the data to the visualiza-
tion.
As a proof-of-concept experiment, we have per-
formed a relatively a small-scale expe riment in which
70 M PI processes are invoked in total: 32 for the si-
mulation + 3 for the fron t face membrane + 3 for
the back face membrane + 32 for the visualization,
and confirmed that this in-situ visualization frame-
work works.
ACKNOWLEDGEMENTS
This work was supported by JSPS KAKENHI Grant
Numbers JP17H02998 and JP17K00169. This work
was also supported b y SCAT (Support Center for Ad-
vanced Telecom munications Te chnology Research,
Foundation) , Japan.
REFERENCES
Amdahl, G. M. (2007). Computer Architecture and Am-
dahl’s Law. IEEE Solid-State Circuits Newsletter,
12(3).
Bethel, E. W., Childs, H., and Hansen, C. (2013). High
performance visualization : enabling extreme-scale
scientific insight. CRC Press.
Buffat, M., Cadiou, A., Le Penven, L., and Pera, C. (2017).
In situ analysis and visualization of massively parallel
computations. International Journal of High Perfor-
mance Computing Applications, 31(1):83–90.
Kageyama, A. and Yamada, T. (2014). An approach to
exascale visualization: Interactive viewing of in-situ
visualization. Computer Physics Communications,
185:79–85.
Nonaka, J., Matsuda, M., Shimizu, T., Sakamoto, N., Fujita,
M., Onishi, K., Inacio, E. C., Ito, S., Shoji, F., and
Ono, K. (2018). A Study on Open Source Software for
Large-Scale Data Visualization on SPARC64fx based
HPC Systems. In International Conference on High
Performance Computing in Asia-Pacific Region, pages
278–288.
Sakamoto, N. and Koyamada, K. (2015). KVS: A simple
and effective framework for scientific visualization. J.
Adv. Simulation. Sci. Eng., 2(1):76–95.
Telea, A. (2014). Data visualization : principles and
practice. CRC Press, 2nd edition.
Membrane Layer Method to Separate Simulation and Visualization for Large-scale In-situ Visualizations
111
