Multi-sensor Data Fusion for Wearable Devices
Tiziana Rotondo
Department of Mathematics and Computer Science, University of Catania, Italy
1 RESEARCH PROBLEM
The real time information comes from multiple sour-
ces such as wearable sensors, audio signals, GPS, etc.
The idea of multi-sensor data fusion is to comb ine the
data coming from different sensors to provide more
accurate inform ation than that a single sensor alone.
To contribute to ongoing research in this area, the goal
of my research is to build a shared representation be-
tween data coming fro m different domains, such as
images, signal audio, heart rate, acceleration, etc., in
order to predic t daily activities. In the state of the art,
these arguments are tre ated in dividually. Many pa-
pers, such as (Lan et al., 2014; Ma et al., 2016) et al.,
predict daily activity from video or static imag e. Ot-
hers, such as (Ngiam et al., 2011; Srivastava and Sa-
lakhutdinov, 2014) et al., build a shared representation
then rebuild the inputs or rebuild a missing m odality,
or (Nakamura et al., 20 17) classifies f rom multimodal
data.
2 OUTLINE OF OBJECTIVES
In the real world, the information comes from diffe-
rent channels, like videos, sensors, etc. Multimodal
learning aims to build models that are able to pro-
cess inf ormation from different modalities, semanti-
cally related, creating a shared representation to im-
prove accuracies than could b e achieved by the use a
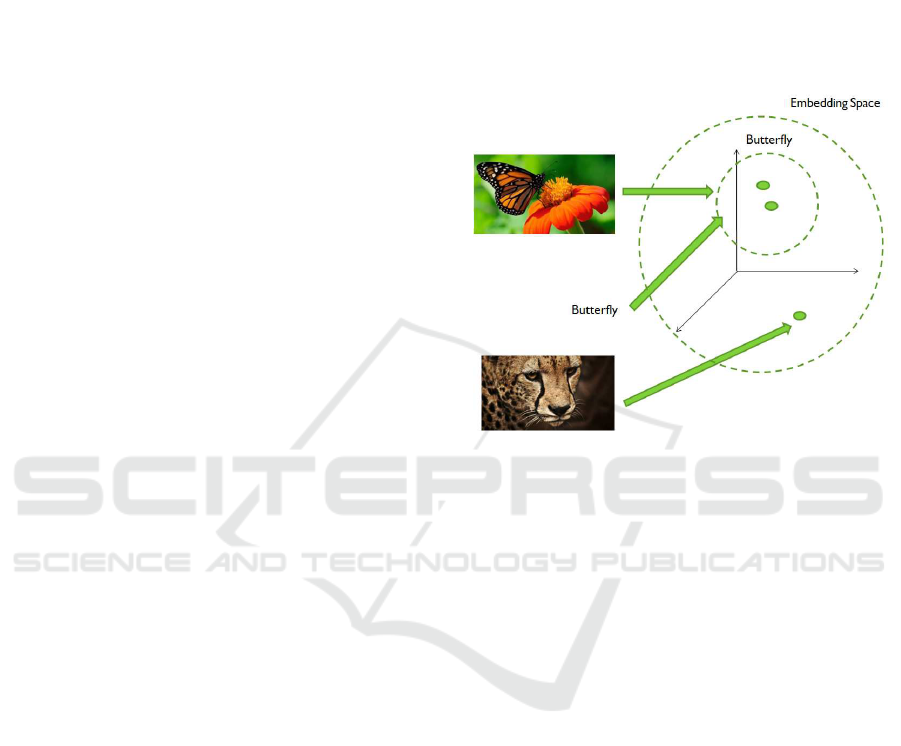
single input. As shown in Figure 1, given the images
of a butterfly and a tiger and the word “butterfly ”, we
want to project these data in a representation space
that takes account of their correlation.
As reported in (Srivastava and Salakhutdinov,
2014), each modality is characterized by different sta-
tistical properties that don’t allow us to ignore the fact
that it comes from specific input channel. The diffe-
rent inputs have a different represen ta tion, therefore,
for a model, it is difficult to find a hig hly non linear
relationship between different data. A good model of
multimodal learning must satisfy certain properties,
in fact the shared representation must be such that re-
semblance in the spa ce of representation implies simi-
Figure 1: Idea of multimodal learning.
larity of the cor responding inputs, to be easily obtai-
ned, even in the absence o f some modalities and to fill
out missing forms, starting from tho se observed.
The problem c oncerning how to build a shared re-
presentation is not new (Bostr¨om et al., 2007). Fusing
informa tion is a core ab ility for humans. They com-
bine all senses, sight, smell, sound, taste and touch
data, for example , to understand if a food is hot or
cold or in general to capture information. Sensors
have been proposed also to emulate this human ca-
pability. This allows several applications in rob otics,
in surveillance, artificial intelligence and so on. As
already mentioned, we plan to fuse multimodal lear-
ning with prediction of daily activities. The predictio n
of the future is a challenge that has always fascina-
ted human people. As reported in (L an et al., 2014),
given a shor t video or a image, humans can pre dict
what is going to happen in the near future. Obser-
ving the previous actions, this is possible. The cre-
ation of machines that anticipate future actions is an
issue in Computer Vision field. In the state of the art,
there are many applications in robotics and health care
that use this predic tive characteristic. For example,
(Chan et al., 2017) proposed a RNN model for anti-
cipating accidents in da shcam videos. (Koppula and
Saxena, 2016) studied how to enable robots to anti-
cipate human-object intera ctions from visual input in
order to provide adequate assistance to the user. (Kop-
22
Rotondo, T.
Multi-sensor Data Fusion for Wearable Devices.
In Doctoral Consortium (DCETE 2018), pages 22-28

pula e t al., 2016; Mainprice a nd Berenson, 2013; Du-
arte et al., 2018) study how to anticipate human acti-
vities for improving the co llaboration between human
and robot.
3 STATE OF THE ART
We focus our review of related works addressing re-
presentation, frame anticipation , object interactio n,
action an ticipation, m ultimodal learning, multimodal
dataset and adopted system in the state of the art.
3.1 Representation
In ( Vondrick et al., 2015), they explore how to antici-
pate hu man actions and objects by learning from un-
labeled video. In particular, they proposed a deep net-
works to predict the visual repr esentation of images
in the future. In (B¨utepage et al., 2017), it is proposed
a deep learning framework for human motion capture
data that learns a generic repr esentation from a large
corpus of motion capture data and generalizes well
to new, unseen, motio ns, using an encoding- decoding
network tha t learns to predict future 3D poses from
the most recent past. (Ryoo et al., 2014) introduces a
new featu re repre sentation named pooled time series
that is based on time series pooling of featu re descrip-
tors. (Oh et al., 2015) considers spatio-tempor al pre-
diction problems where future image-frames depend
on control variables or actions as well as previous fra-
mes.
3.2 Frame Anticipation
In (Vondrick and Torralba, 2017) they develop a mo-
del for generating the immediate future in unconstrai-
ned scenes that gener ates the future by transforming
pixels in the past. In (Walker et al., 2 017), the authors
use the f uture poses generated to a Generative Adver-
sarial Network (GAN) to predict the future frames of
the video in pixel space. In (Xue et al. , 2016), they
propose a novel approach that mod els f uture frames
from a single in put image in a probabilistic manner.
3.3 Object Interaction
In (Furnari et al., 2017), it is investigated the topic
of next-active-object prediction from First Person vi-
deos. They a nalysed the r ole of egocen tric object m o-
tion in anticipating object interactions and propose a
suitable evaluation pro tocol. In (Koppula and Saxena,
2016), the goal is to enable robots to predict hum an-
object interactions from visual input in order to assist
humans in daily tasks.
3.4 Action Anticipation
The go al of action anticipa tion is to detect an action
before it happens. In (Gao et al., 2017), it is pro-
posed a Reinforced Encoder-Decoder (RED) network
for actio n anticipation that takes multiple history re-
presentations as input and learns to anticipate a se-
quence of future representations. These anticipated
representations are pro c essed by a classification ne t-
work for action classification. In (La n et al., 2014),
it is pr esented a hierarchical model that represent the
human movements to infer future actions from a sta-
tic image or a short video clip. In (Ma et a l., 2016),
the authors proposed a method to improve training of
temporal deep mode ls to learn activity progression for
activity detection and early reco gnition tasks.
3.5 Multimodal Learning
The aforem e ntioned papers mostly concern a single
modality such as video. We want to extend these con-
cepts to multimodal inputs. This problem is not only
theoretical but it has already been dealt with machine
learning techniques. On e of the firsts paper on Mul-
timodal Learning is (Ngiam et al., 2011) where video
and audio signals are used as input. The aims of this
article are: compress the inpu ts into a shared repre-
sentation and then rebuild them and rebuild a missing
mode, for example from the video, you want to get the
audio signal and the video signal as output. The cre-
ation of a fused representation has also been tre ated
in other papers (Srivastava and Salakhutdinov, 2014;
Aytar et al., 2 017), in particular they build a represen-
tations that are robust in another way. Indeed, these
representations are very important because they are
fundamental components to understan d relationships
between modalities.
In (Nakamura et al., 2017), a model for reaso ning
on multimoda l data to jointly predict activities and
energy expenditures is proposed. In particular, for
these tasks they co nsider Egocentric videos augmen-
ted with heart rate and acceleration signals. In (Wu
et al., 2 017), it is proposed a on -wrist motion trig-
gered sensing system for anticipating daily intention.
They introduces a Recurrent Neural Network (RNN)
to anticipate intention and a policy network to reduce
computation r equirement.
Multi-sensor Data Fusion for Wearable Devices
23

3.6 Multimodal Dataset
In this section, we discuss about the datasets in the
state-of-the-art. The data are an important point; in
fact these are collected at different sampling f requen-
cies, there fore, be fore pr oceeding to extract the featu -
res, it is necessary to synchro nize the various in puts
in order to have all the related modalities.
The egocentric multimodal dataset (Stanford-
ECM) (Nakamura et al., 2017) comprises 31 hours of
egocentric video (113 videos) augmented with acce-
leration and heart r a te data. The video and triaxial
acceleration wer e capture with mobile p hone with a
720 × 1280 resolution and 30 fps and 30Hz, respecti-
vely. The lengths of the individual videos covered a
diverse range from 3 minutes to about 51 minutes in
length. The heart rate was collected with wrist sen-
sor every 5 seconds (0.2 Hz). These data was time-
synchro nized through Bluethoot.
The Multimodal Egocentric Activity dataset
(Song e t al., 2016) contains 20 distinct life-logging
activities performed by different human subjects a nd
comprises these data: video, accelerometer, gravity,
gyrosco pe, linear acceleration, magnetic field and ro-
tation vector. The Google Glass enables to synchro-
nize egocentric video and senso r data. The video was
collected with a 12 80 × 720 resolution and 29.9 fps
while the sensor data with a lenght of 15 second and
10Hz. Each activity category h a s 10 sequences of 15
seconds.
Multimodal User-Generated Videos Dataset
(Bano et al., 2015) contains 24 user-generated videos
(70 min s) captured using hand-held mobile p hones
in high brightness and low brightness scenarios
(e.g. day and night-time). The video (audio and
visual) along with the inertial senso r (accelerometer,
gyrosco pe, magnetometer) data is provid e d for each
video. These recordings are captured using single
camera at distinc t timings and locations, changing
lights and varying camera motions. Each c aptured
video was manually annotated to get labels for
camera motions (pan,tilt, shake) at each second . The
ground-truth labels are included in the dataset.
In (Wu et al., 2017 ), the authors collected Daily
Intention Dataset that was used fo r training model to
predict the future and they select 34 daily intentio ns.
Each of this is associated with a motion and an object.
The video was collected with a 640 × 480 resolution.
3.7 Adopted System
In this sectio n, we describe some of the models that
are presented in th e state o f the ar t. Many of these are
based on the study of different deeps networks, star-
ting from the Restricted Boltzman n Machines (RBM)
(Ngiam et al., 2011; Srivastava and Salakhutdinov,
2014) to more used Convolutional Neural Networks
(CNN) (N akamura et al., 2017), accumulated by the
fact that each a rchitecture processes a probability dis-
tribution on all of it multimodal input space.
3.7.1 Boltzmann Machines
The Boltzmann Machines (BM) (Salakhutd inov and
Hinton, 2009) are networks with a symmetrical con-
nections between binary units, c alled visible variables
v ∈ {0,1}
D
and hidden variables h ∈ {0, 1}
P
. There
are connections between the visible state and the hid-
den state and between the units of the same type. The
energy of the state {v,h} is defined as
E(v,h;θ) = −
1
2
v
T
Lv −
1
2
h
T
Jh − v
T
W h, (1)
where θ = {W, L, J} are the parameters of the model
that represent, respectively, the interactio ns between
the visible-hidden, visible-visible an d hidden-hidden
states. The probability that the model assigns to the
visible variable v is
p(v; θ) =
p
∗
(v,θ)
Z(θ)
=
1
Z(θ)
∑
h
exp(−E(v,h; θ)), (2)
Z(θ) =
∑
v
∑
h
exp(−E(v,h;θ)). (3)
where p
∗
is the non-normalized probability and Z(θ)
the partition function. Updating the parameters neces-
sary to calculate the log-likelihood with the gradient
descent method are obtained from (2):
△W = α(E
Pdata
[vh
T
] − E
Pmodel
[vh
T
]),
△L = α(E
Pdata
[vv
T
] − E
Pmodel
[vv
T
]),
△J = α(E
Pdata
[hh
T
] − E
Pmodel
[hh
T
]),
(4)
where α is the learning rate, E
Pdata
[·] is the data de-
pendency prediction and E
Pmodel
[·] is the prediction
on the model. Th e learning algorithm of the BMs re-
quires a very long execution time because it is neces-
sary to initialize in a random way the Markov chain s
to estimate the predictions on the data a nd on the
model. Learning is more effective if you use the
Restricted Boltzmann Machines (Srivastava and Sa-
lakhutdinov, 2014; Salakhutdinov and Hinton, 2009)
(RBMs). In such mode ls there are connections bet-
ween the visible layer and the hidden state but there
are no connections between variables of th e same
type. The parameters L, J are null. In this case
the algorithm is efficient using the Contrastive Diver-
gence which provides an approximation of the log-
likelihood with a short Markov ch ain. It is possible
to use a sto chastic approximation to appro ximate the
prediction of the mod el. θ
t
and X
t
, respectively, the
parameter a nd the status are a dded as follows:
DCETE 2018 - DCETE
24

• Given X
t
, X
t+1
is updated by an o perator
T
θ
(X
t+1
,X
t
) leaving p
θ
t
unchanged.
• θ
t+1
is obtained by replacing the predictability of
the intractable model with the prediction against
X
t+1
.
A necessary condition for convergence is that the le-
arning rate decreases as time passes
max
∑
t=0
α
t
= +∞ and
max
∑
t=0
α
2
t
< +∞. This is satisfied for α
t
= 1/t.
The models described are the base cell of the
Deep Boltzmann Machines (DBM) (Salakhutdinov
and Hinton, 2009). These latest networks allow us
to learn the potential of internal representations and
allow us to deal with unlabelled or par tially labelled
data.
In (Ngiam et al., 2011), RBMs are used to build a
shared re presentation, as shown in Figure 2. One of
the most linear RBM approaches for audio and video,
as in Figure 2.a, 2.b. The resulting probability can be
used as a n ew representation of the data. This method
is used as a referen ce mo del.
The 2.c m odel was given input to the concatena-
tion of inputs, but given the nonlinear correlation of
the data, it is difficult for the RBM to provide a mul-
timodal representation. In particular, the units born
have strong connections between the individual mo-
des and weak connections between units that connec t
the two modes.
Finally, a mode l that takes into account the pre-
vious ones is considered; in fact, the mo dalities are
trained separately and then the results a re concatena-
ted. The first level of visualization is a phoneme and
at my levels. T he latter model is used to train weights
to use autoencoder mo dels.
3.7.2 RNN
The RNNs (LeCun et al. , 2015) are models tha t pr o-
cess an input sequenc e one element at a time, keeping
in its hidden units a state vector that contains informa-
tion related to the previous elements of the sequence.
These networks use the same parameters, for this re-
ason they perform the same computation at each mo-
ment of time on different inputs of the same sequence .
The training of such networks is affected by the vanis-
hing/exploding gradient p roblem, in which the calcu-
lated and propagated backward gradients tend to in-
crease or decrease at each moment of time, therefore,
after a certain number of instants of time, the gradient
diverges to infinity or converges to zero. To overcome
this problem, long short-term memory (LSTM) net-
works are used, which are p articular RNNs with hid-
den units that recall previous inputs for a long time.
Such u nits, taking as input, at each instant, the pre-
vious state and the cu rrent one and combining them,
decide which information to keep a nd which to delete
from me mory.
The aim of the paper (Nakamura et al., 2017) is
to recognize a daily activity and c alculate its energy
expenditure, starting from a multimodal dataset. An
LSTM is introduce d that takes in input a multimodal
representation o f the video and the a cceleration and
returns in output the ac tivity label and the energy con-
sumption for each fra mes. Heart rate is also integrated
to estimate the energy spent.
In (Wu et al., 2017 ), a model based on the RNN is
proposed with two LSTM layers in order to be able to
handle the variations, as follows
g
t
= Emb(W
emb
,con( f
m,t
, f
o,t
)), (5)
h
t
= RNN(g
t
,h
t−1
), (6)
p
t
= So ftmax(W
y
,h
t
), (7)
y
t
= argmax
y∈Y
p
t
(y), (8)
where Y is the set of intent indices, p
t
is the soft-
max pr obability of each intention in Y, W
y
is the pa-
rameter of the model to tra in, h
t
is the hidden repre -
sentation co ached, g
t
is the fixed size of the output
of Emb(·), W
emb
is the parameter of the embedding
function Emb (·), con(·) is the concatenatio n opera-
tion and Emb(·) is a linear mapping function.
Policy network π is also introduced to determine
when to pro c ess a n image in a rep resentation of th e f
o
object. The network continuously observes the mo-
vement f
m,t
and the hidden state of the RNN h
t
to be
able to calculate f
o,t+1
.
4 EXPECTED OUTCOME
In this section, we describe our pipeline, shown in
Figure 3. Stanford-ECM Da ta set (Nakamura et al.,
2017) is considered. It has video, acceleration and he-
art rate data, so the problem is defined as follows: gi-
ven V = { v
1
,v
2
,...,v
T
} with v
i
∈ R
2
∀i ∈ {1,2, ...,T }
a sequence of video frame , A = {a
1
,a
2
,...,a
T
} with
a
i
∈ R
3
∀i ∈ {1, 2,...,T } a sequenc e of a ccelera-
tion signals and H R = {hr
1
,hr
2
,...,hr
T
} with hr
i
∈
R ∀i ∈ {1,2, ..., T } a sequence of heart rate signal,
(x
v
t
,x
a
t
,x
hr
t
) ∀t ∈ {1 , 2,...,T } ar e the feature re pre-
sentations of video, acce le ration and heart rate sig-
nal and x
t
= (x
v
t
,x
a
t
,x
hr
t
)
T
the features vector. Given
(x
t
,x
t+1
,label
t
,label
t+1
) as input, we want to predic t
next action, observing only data before the activity
starts.
Multi-sensor Data Fusion for Wearable Devices
25
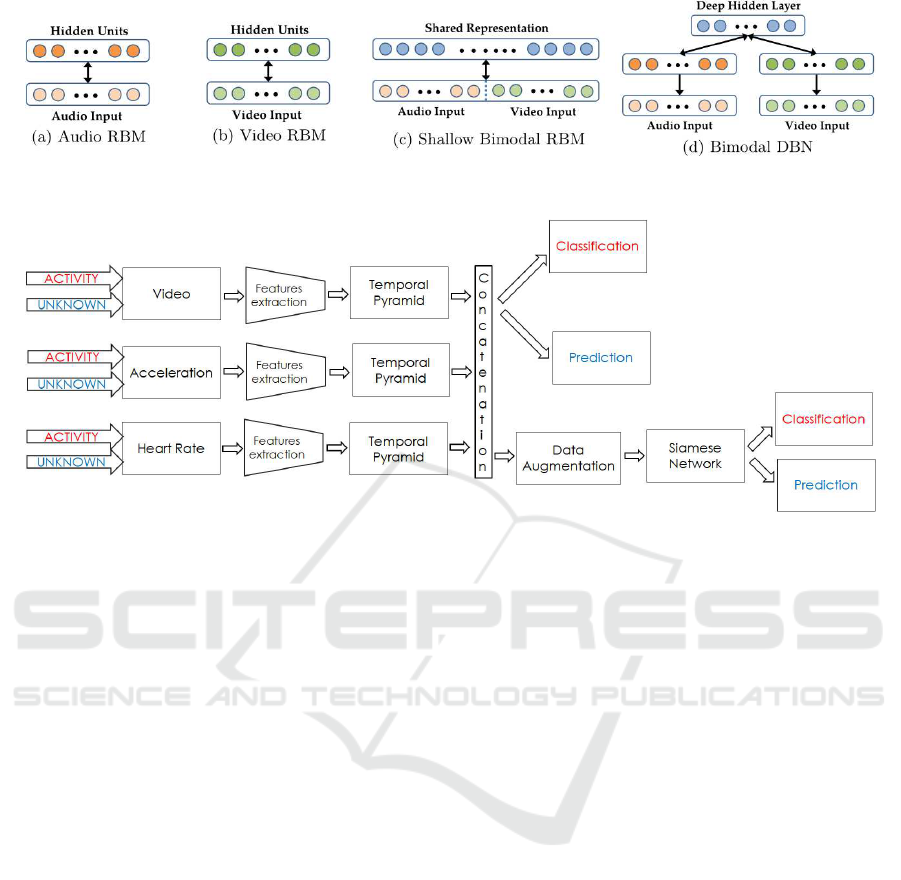
Figure 2: RBM Pretraining Models.
Figure 3: Pipeline of our model.
Since this dataset was created for classification
task, it is not spe c ific for pre diction task. It is adap-
ted for our task and Unknown/Activity transitions are
selected. The da taset is cut around transitions and 64
frames before and after transitions are considered.
Now, we d e scribe how fea ture representation x
v
t
, x
a
t
and x
hr
t
for each signal has been obtained.
For visual data, features are extracted from pool5
layer of Inception CNN, pretrained on ImageNet
(Deng et al., 2009). Each video frame has bee n trans-
formed into a 1024-dimensional feature vector x
v
t
.
For acceleration data, the features have be en ex-
tracted from the raw signal and a sliding window with
size of 32fps has been considered. For time-domain
features, mean, stan dard deviation, skewness, kurto-
sis, percentiles (10th, 25th, 50th, 75th , 90th), acce-
leration count for each axis and correlation coeffi-
cients b etween each axis have been comp uted. For
frequency-domain features, we c onsider the spectral
entropy J = −
N/2
∑
i=0
¯
P
i
· lo g
2
¯
P
i
where
¯
P
i
is the n ormali-
zed power spectral density computed from Short Time
Fourier Transform (STFT). Then, all features are con-
catenated and x
a
t
is a 36-dimensional vector.
For hear rate data, the features are extracted from
the time-series of the raw signals. Mean and standard
deviation are co mputed and x
hr
t
∈ R
2
.
Features are represented in a temporal pyramid
(Pirsiavash and Ramanan, 2012) with three levels (le-
vel 0, level 1 and level 2). The top level j = 0 is a
histogram (mean) over the full temporal extent of a
data, the next level (j=1) is the co ncatenation of two
histograms obtained by temporally segmenting each
modality into two halfs, and so on. In th is way, we
have 7 histograms. Theref ore, 1024 × 7 visual featu-
res, 36 × 7 acceleration features, and 2 × 7 heart rate
features are obtained. All features are concatenated
into a single vector x
t
= (x
v
t
,x
a
t
,x
hr
t
)
T
and features vec-
tor size is 7434.
Since we have a few data, a data augmentation
technique is used to expand the training set to prevent
over-fitting. As reported in (Krizhevsky et al., 2012)
geometric transformation and RGB channels altera-
tion are the traditional d ata augmentation approaches,
while (Zhu et al., 2017) proposes a method with GAN
and Cy cleGAN.
In the current configuration, the permutation is
considered of each piec e of u nknown with the vari-
ous sections of the activities. For Siamese Network,
each un known is paired with any activity. In this case,
we created a “false” couples but these are necessary to
implement the Siamese network. The labels of each
transition are changed from 0-8 to 0-1, as follows:
if unknown and the activity belong to the same class
(e.g. unkn own rela ted to walking and walking), 1 is
assigned, other w ise 0 is assigned if unknown and the
activity are different (e.g. unknown related to walking
and food preparation).
The obtained dataset is stro ngly unbalan ced, so
DCETE 2018 - DCETE
26

we considered 121 sequences from same unknown
and activity and 154 sequences from different
unknown and activity for each class, in order to ba-
lance activity classes a nd unk nown class. In this way,
dataset has 12177 sequences. This is the input for Sia-
mese n etwork (Koch et al., 2015) that con sists of twin
networks which accept distinct inputs but the weig-
hts are shared. During training the two sub-network s
extract features from two inputs, while the jo ining
neuron m e asures the distance between the two feature
vectors.
In our experime nt, euclidean metrics is used to
calculate the distances between inputs. Th e contras-
tive loss f unction has been used. Three convolutio-
nal layers are considered with numbers of filters 32,
64 and 2, respectively, all of size 3 × 1 and a relu
activatio n function. The output of each convolutional
layer is reduced in size using a max-pooling layer that
halves the number of features. A k-nearest-neig hbor
classification algorithm (K-NN) and a support vector
machine (SVM) are used on features for classification
purposes.
5 STAGE OF THE RESEARCH
Our preliminary results prove that we can pred ict
daily activity from multim odal data. In particular,
Stanford-ECM Data set has bee n considered and we
implemented a siamese network to build an embe d-
ding space. The performance of the experiment has
been evaluated with a SVM for different kernels and
a K -NN for different values of K.
In fu ture works, we want to improve our pipeline
and test its o n other datasets. The result that I expect
and that should validate the problem an d the approach
is to overcome the values of accuracy in classification
baseline.
ACKNOWLEDGEMENTS
I would like to thank my advisors Prof. Sebastiano
Battiato (University of Catania), Prof. Giovanni Ma-
ria Farinella (University of Catania) and Ing. Vale-
ria Tomaselli (STMicroelectronic s, Catania) for their
continued supervision and support.
REFERENCES
Aytar, Y., Vondrick, C ., and Torralba, A. (2017). See,
hear, and read: Deep aligned representations. CoRR,
abs/1706.00932.
Bano, S., Cavallaro, A., and Parra, X. (2015). Gyro-based
camera-motion detection in user-generated videos. In
Proceedings of the 23rd ACM International Confe-
rence on Multimedia, MM ’15, pages 1303–1306,
New York, NY, USA. ACM.
Bostr¨om, H., Andler, S. F., Brohede, M., Laere, J. V., Ni-
klasson, L., Nilsson, M., Persson, A., and Ziemke, T.
(2007). On the definition of information fusion as a
field of research. Technical report.
B¨utepage, J., Black, M. J. , Kragic, D., and Kjellstr¨om,
H. (2017). Deep representation learning for hu-
man motion prediction and cl assification. CoRR,
abs/1702.07486.
Chan, F.-H., Chen, Y.-T., Xiang, Y., and Sun, M. (2017).
Anticipating accidents in dashcam videos. In Lai,
S.-H., Lepetit, V., Nishino, K., and Sato, Y., edi-
tors, Computer Vision – ACCV 2016, pages 136–153,
Cham. Springer International Publishing.
Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., and Fei-Fei,
L. (2009). Imagenet: A large-scale hierarchical image
database. In 2009 IEEE Conference on Computer Vi-
sion and Pattern Recognition, pages 248–255.
Duarte, N., Tasevski, J., Coco, M. I., Rakovic, M., and
Santos-Victor, J. (2018). Action anticipation: Re-
ading the intentions of humans and robots. CoRR,
abs/1802.02788.
Furnari, A., Battiato, S., Grauman, K ., and Farinella, G. M.
(2017). Next-active-object prediction from egocentric
videos. Journal of Visual Communication and Image
Representation, 49:401 – 411.
Gao, J., Yang, Z., and Nevatia, R. (2017). RED: reinfor-
ced encoder-decoder networks for action anticipation.
CoRR, abs/1707.04818.
Koch, G., Zemel, R., and Salakhutdinov, R. ( 2015). Sia-
mese neural networks for one-shot image recognition.
Koppula, H. S., Jain, A., and Saxena, A. (2016). Antici-
patory Planning f or Human-Robot Teams, pages 453–
470. Springer International Publishing, Cham.
Koppula, H. S. and Saxena, A. (2016). Anticipating human
activities using object affordances for reactive robo-
tic response. IEEE Trans. Pattern Anal. Mach. Intell. ,
38(1):14–29.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012).
Imagenet classification with deep convolutional neu-
ral networks. In Pereira, F., Burges, C. J. C., Bottou,
L., and Weinberger, K. Q., editors, Advances in Neu-
ral Information Processing Systems 25, pages 1097–
1105. Curran Associates, Inc.
Lan, T., Chen, T.-C., and Savarese, S. (2014). A hierar-
chical r epresentation for future action prediction. In
Fleet, D., Pajdla, T., Schiele, B., and Tuytelaars, T.,
editors, Computer Vision – ECCV 2014, pages 689–
704, Cham. Springer International Publishing.
LeCun, Y., Bengio, Y., and Hinton, G. E. (2015). Deel l ear-
ning. Nature, 521(7553):436–444.
Ma, S., Sigal, L., and Sclaroff, S. (2016). Learning activity
progression in lstms for activity detection and early
detection. In 2016 IEEE Conference on Computer Vi-
sion and Pattern Recognition (CVPR ) , pages 1942–
1950.
Multi-sensor Data Fusion for Wearable Devices
27

Mainprice, J. and Berenson, D. (2013). Human-robot colla-
borative manipulation planning using early prediction
of human motion. In 2013 IEEE/RSJ International
Conference on Intelligent Robots and Systems, pages
299–306.
Nakamura, K., Yeung, S ., Alahi, A., and Fei-Fei, L. (2017).
Jointly learning energy expenditures and activities
using egocentric multimodal signals. In 2017 IEEE
Conference on Computer Vision and Pattern Recogni-
tion ( CVPR), pages 6817–6826.
Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., and Ng,
A. Y. (2011). Multimodal deep learning. In Procee-
dings of the 28th International Conference on Inter-
national Conference on Machine Learning, ICML’11,
pages 689–696, USA. Omnipress.
Oh, J., G uo, X. , Lee, H., Lewis, R. L., and Singh, S. P.
(2015). Action-conditional video prediction using
deep networks in atari games. CoRR, abs/1507.08750.
Pirsiavash, H. and Ramanan, D. (2012). Detecting activities
of daily living in first-person camera views. In 2012
IEEE Conference on Computer Vision and Pattern Re-
cognition, pages 2847–2854.
Ryoo, M. S., Rothrock, B., and Matthies, L. H. (2014).
Pooled motion features for first-person videos. CoRR,
abs/1412.6505.
Salakhutdinov, R. and Hinton, G. E. (2009). Deep boltz-
mann machines. In Proceedings of the Twelfth In-
ternational Conference on Artificial Intelligence and
Statistics, AI STATS 2009, Clearwater Beach, Florida,
pages 448–455.
Song, S., Cheung, N., Chandrasekhar, V., Mandal, B., and
Lin, J. (2016). Egocentric activity recognition with
multimodal fi sher vector. CoRR, abs/1601.06603.
Srivastava, N. and S al akhutdinov, R. (2014). Multimodal
learning with deep boltzmann machines. Journal of
Machine Learning Research, 15:2949–2980.
Vondrick, C., Pirsiavash, H., and Torralba, A. (2015). An-
ticipating the future by watching unlabeled video.
CoRR, abs/1504.08023.
Vondrick, C. and Torralba, A. (2017). Generating the fu-
ture with adversarial transformers. In 2017 IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 2992–3000.
Walker, J., Marino, K., Gupta, A., and Hebert, M. (2017).
The pose knows: Video forecasting by generating
pose futures. CoRR, abs/1705.00053.
Wu, T., Chien, T., Chan, C., Hu, C., and Sun, M. (2017).
Anticipating daily intention using on-wrist motion
triggered sensing. CoRR , abs/1710.07477.
Xue, T., Wu, J., B ouman, K. L., and Freeman, W. T.
(2016). Visual dynamics: Probabilistic future frame
synthesis via cross convolutional networks. CoRR,
abs/1607.02586.
Zhu, J.-Y., Park, T., Isola, P., and Efros, A. A.
(2017). Unpaired image-to-image translation using
cycle-consistent adversarial networks. CoRR,
abs/1703.10593.
DCETE 2018 - DCETE
28
