
Locality-Sensitive Hashing for Efficient Web Application Security Testing
Ilan Ben-Bassat
1
and Erez Rokah
2
1
School of Computer Science, Tel-Aviv University, Tel-Aviv, Israel
2
IBM, Herzliya, Israel
Keywords:
Security Testing, Automated Crawling, Rich Internet Applications, DOM Simi larity, Locality-Sensitive
Hashing, MinHash.
Abstract:
Web application security has become a major concern in recent years, as more and more content and services
are available online. A useful method for identifying security vulnerabilities is black-box testing, which rel ies
on an automated crawling of web applications. However, crawling Rich Internet Applications (RIAs) is a very
challenging task. One of the key obstacles crawlers face is the state similarity problem: how to determine if
two client-side states are equivalent. As current methods do not completely solve this problem, a successful
scan of many real-world RIAs is still not possible. We present a novel approach to detect redundant content for
security testing purposes. The algorithm applies locality-sensitive hashing using MinHash sketches in order
to analyze the Document Object Model (DOM) structure of web pages, and to efficiently estimate similarity
between them. Our experimental results show that this approach allows a successful scan of RIAs that cannot
be crawled otherwise.
1 INTRODUCTION
The information era has turned the Internet into a cen-
tral part of modern life. Growing amounts of data and
services are available today, making web application
development an important skill fo r both enterprises
and individuals. The heavier the relianc e on web ap-
plications, the higher the motivation of attackers to
exploit security vulnerabilities. Unfortu nately, such
vulnerabilities are very common (Gordeychik et al.,
2010), leading to an inc reasing need to detect and re-
mediate them.
Black-box security scanners a ddress the problem
of ensuring secure d web applications. They simulate
the behavior of a user crawling an application wit-
hout access to the source code. When discovering
new pages and new content, the scanner performs a
series of a utomated security tests, based on a data-
base of known vu lnerabilities. This way, the appli-
cation can be easily and thoroughly analyzed from a
security point of view. See (Bau et al., 2010; Doup´e
et al., 2010) for surveys on available scanners.
It is clear that a comprehe nsive security scan re-
quires, among other factors, both high coverage and
efficiency. If the crawler cannot reach significant parts
of the application in a reasonable time, then the secu-
rity assessment of the application will be incomp le te .
In particular, a web crawler should refrain from was-
ting time and memory resources on scanning pages
that are similar to previously visited ones. The defini-
tion of r edundant pag es depends on the crawling pur-
pose. For traditional web indexing purposes, different
contents imply d ifferent pages. However, for secu rity
testing purposes, different sets of vulnerabilities im-
ply different pages, regardless of the exact co ntent of
the pages.
While the p roblem of page similarity (or sta te si-
milarity) is a fundamental challenge for all web cra-
wlers (Pomik´alek, 201 1), it h as become even more
significant since the emergence of a new generation
of web applications, often called Rich Internet Appli-
cations (RIAs).
RIAs make extensive usage in technologies such
as AJAX (Asynchronous JavaScript and XML) (Gar-
rett et al., 2005), which enable client-side processing
of data that is asynchronously sent to and from the
server. Thus, the content of a web p age ch anges dy-
namically without even reloading the page. New da ta
from the server can be reflected to th e user by mo-
difying the DOM (Nicol et al., 2001) of the page
through UI events, albeit no change was done to the
URL itself. Although such technologies increase the
responsiveness of we b a pplications a nd make them
more user-friendly, they also pose a great difficulty on
Ben-Bassat, I. and Rokah, E.
Locality-Sensitive Hashing for Efficient Web Application Security Testing.
DOI: 10.5220/0007255301930204
In Proceedings of the 5th International Conference on Information Systems Security and Privacy (ICISSP 2019), pages 193-204
ISBN: 978-989-758-359-9
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
193

modern web crawlers. While traditional crawlers fo-
cused on visiting all possible URLs, current-day cra-
wlers should examine every client state that can be ge-
nerated via an execution of a series of HTML events.
The expo nentially large number of possible sta-
tes emphasizes the need to efficiently detect similarity
between different a pplication states. Failing to solve
the state similarity problem results in a poor scan qua-
lity. If the algorithm is too strict in deciding whether
two states are similar, then too many redundant sta-
tes would be crawled, yielding long or even endless
scans. On the other han d, if the resemblance re la tion
is too lax, the crawler might mistakenly deem new
states as near-duplicates of p reviously-seen states, re-
sulting in an incom plete coverage.
As stated before, every URL of a RIA is actually
a dynamic application, in wh ic h states are accessed
through UI events. Consequently, eliminating dupli-
cate content can not rely solely on URL analysis, such
as in (Bar-Yossef et al., 2009). Instead, a common
method that black-box scanners use in order to de-
cide whether two pages are similar, is to analyze their
DOM structure and pr operties, without taking the text
content into account. This is a useful approach for se-
curity oriented crawling, since often the text content
of a page is irrelevant to the security assessment. As
opposed to the content, the elements and logic that al-
low user interaction are more relevant for a security
analysis. For exam ple, consider a commercial web
application with a catalog section, containing thou-
sands of pages. The ca ta log pages share the same
template, yet every one of them is d edicated to a dif-
ferent product. While the variety of products may be
of interest for search engines like Google or Yahoo, it
is of no great impor tance to black-box security scan-
ners, as all pages probably sh are the same set of se-
curity vulnerabilities. Therefore, an analysis of the
DOM structures of the pages might suggest that they
are near-duplicates of each other.
In the past de c ade, several methods have been pro-
posed to determine similarity between DOMs (see
section 2). Most of the methods include DOM nor-
malization techniqu es, possibly followed by applying
simple hash functions. While these methods were
proven to be successful in scanning several RIAs,
they are often too strict, leading to a state explosion
problem and very long scans. Moreover, since hash
functions used in this context so far have, to the best
of our knowledge, no special properties, minor dif-
ferences between two cano nical DOM forms might
result in two completely different hash values. The-
refore, many complex application s still cannot be cra-
wled in a reasonable time. Approaches involving dis-
tance measures, such as (Mesbah and Van Deursen,
2008), are not scalable and req uire computing distan-
ces between all-pairs of DOMs.
In th is paper we pr e sent a different approach for
the state similarity problem for security oriented cra-
wling. Our approach is based on locality-sensitive
hashing (LSH) (Indyk and Motwani, 1998), a nd on
MinHash sketches in particular (Broder, 1997; Bro-
der et al., 2000). A locality-sensitive hash function
satisfies the property that the probab ility of collision,
or a t least clo se num erical hash values, is much higher
for similar objects than for other objects. LSH sche-
mes have already be en used in th e context of detecting
duplicate textual content (see (Pomik´alek, 20 11) for a
survey). Recently, MinHa sh sketches have also be-
come an efficient solution for bioinformatic challen-
ges, where large amounts of biolo gical sequence data
require efficient computational methods. As suc h,
they c a n be used to detect inexact matches between
genomic sequences (Berlin et al., 2015; Popic and
Batzoglou, 2016). However, LSH techniques have not
yet been used by black -box security scanners. The
flexibility of MinHash sketches enab le s detec ting du-
plicate states if two DOMs differ in a small number
of DOM elements, regardless of their type. The LSH
technique that we use makes the algorithm scalable
for large RIAs as well. Combined together, our met-
hod makes exploring industrial RIAs feasible.
2 RELATED WORK
A common approach for a n efficient detection of du-
plicate states in AJA X applications is to apply sim-
ple hash functions on the DOM string representation.
The authors of (Duda et al., 200 9) and (Frey, 2007)
compute hash values according to the structure and
content of the state. H owever, although these met-
hods can remove redundant copies of the same state,
they are too strict for the purpose of detecting near-
duplicate pages.
CRAWLJAX (Mesbah and Van Deursen, 2008) is
a crawler for AJAX applications tha t decides whet-
her two states are similar acco rding to the Levensh-
tein distance (Levenshtein, 1966) between the DOM
trees. Using this method, however, for computing
distances between all-pairs of possible states is infe-
asible in large RIAs. In a later work (Roest et al.,
2010), the state equivalence mechanism of the algo-
rithm is improved by first applying an Oracle Compa-
rator Pipelining (OCP) befo re hash values are com-
puted. Each comparator is targeted to strip the DOM
string from an irrelevant substring, which might cause
meaningle ss difference s between two states, e.g., time
stamps, advertisement banners. CRAWLJAX is the-
ICISSP 2019 - 5th International Conference on Information Systems Security and Privacy
194

refore less strict in comparing application states, but
the comparator pipeline requires manual co nfigura-
tion and adjustment for every scan. FEEDEX (Fard
and Mesbah, 2013), which is built on top of CRAWL-
JAX, uses tree edit distance (Tai, 1979) to compare
two DOM trees.
The notion of Jaccard similarity is used in
j
¨
Ak (Pellegrino et al., 2015). In this p a per, the auth ors
consider two pages as similar if they shar e the same
normalized URL and their Jaccard in dex is above a
certain threshold. A no rmalized URL is obtained af-
ter stripping the query values an d sorting the query
parameters lexicographically. The Jaccard similarity
is computed between sets of JavaScript event, links
and HTML forms that appear in the web pages.
Two techniques to improve any DOM based state
equivalence mechan ism are presented in (Ch oudhary
et al., 2012). The first aims to discover unnece ssary
dynamic content by loading and reloading a page.
The second identifies session parameters and ignores
differences in requests and responses due to them.
The DOM un iqueness tool described in (Ayoub
et al., 2013) identifies pages with similar DOM struc-
ture by detecting repeating patterns and re ducing
them to a ca nonical DOM representation, which is
then hashed into a single numerical value. The user
can c onfigure the algorithm and determine which
HTML tags are included in the canonical represen -
tation, and whether to include their text content. This
method captures structural changes, such as add itions
or deletions of rows in a table. It is also n ot affected
by elements shuffling, since it involves sorting the ele-
ments in every DOM subtree. However, modifications
that are not re c ognized as part of a structural pattern
lead to a false separation between two near-duplicate
states. The method in ( Moosavi et al., 2014) further
extends this algorithm b y splitting a DOM tree into
multiple subtrees, each corresponding to an indep e n-
dent application component, e.g., w idgets. The DOM
uniqueness algorithm is applied on every comp onent
indepen dently, thus avoiding explosion in the number
of possible states when the same data is being dis-
played in different combinations.
The structure of a pag e is also the key for cluste-
ring similar pages in (Doup´e et al., 2 012), in which a
model of the web application’s state machine is built.
The authors model a page using its links (a nchors
and forms), an d store this information in a prefix tree.
These trees a re vectorized and the n stored in ano ther
prefix tree, called the Abstract Page Tree (APT). Si-
milar pages are found by analyzing subtrees of the
APT.
A different approach for clusterin g application
states into different equivalence clusters appears in
software to ols that model and test RIAs u sing execu-
tion tra ces, such as RE-RIA (Amalfitano et al., 2008),
CrawlRIA (Amalfitano et al., 201 0b), and CreRIA
(Amalfitano et al. , 2010 a). The clustering is done by
evaluating several equivalence criteria, which depend
on the DOM set of elements, event listeners and event
handlers. Two DOMs are considered equivalent if one
set contains the other a s a subset. This method has a
high memory consu mption and computatio n time.
Research efforts have been made during the years
in detecting near-duplicate text, esp ecially in the con-
text of the Web. A s the general problem of duplicate
content detection was not th e focus of this paper, we
refer the readers to a detailed survey for more infor-
mation on the subject (Pomik´alek, 2011).
3 MinHash SKETCHES
MinHash is an efficient tec hnique to estimate the Jac-
card similarity between two sets. Given two sets, A
and B, the Jaccard similarity (Jaccard, 1901) of the
sets, J(A,B), is a measure of how similar the sets are:
J(A, B) =
|A ∩B|
|A ∪B|
(1)
The Jacca rd similarity value ranges between 0
(disjoint sets) and 1 ( equal sets). However, direct
computation of this ratio r equires iterating over all
the elements of A and B. MinHash (Broder, 1997)
is an efficient m e thod to estimate the Jaccard simila-
rity of two sets, without explicitly constructing their
intersection and union. The efficiency of the method
comes from reducing every set to a small number of
fingerpr ints.
Let S be a set, and let h be a hash function whose
domain includes the elements of S. We define h
min
(S)
as the element a of S, which is mapped to the mini-
mum value, among all the elements of S:
h
min
(S) = argmin
a∈S
h(a) (2)
We consider again two sets of elements, A and B.
One can easily verify that:
Pr[h
min
(A) = h
min
(B)] = J(A,B) (3)
Eq. 3 implies that if we define a random variable
R
A,B
as follows:
R
A,B
=
1 if h
min
(A) = h
min
(B)
0 if otherwise
(4)
then R
A,B
is an indicator variable which satisfies
E[R
A,B
] = J(A,B). However, R
A,B
is either 0 or 1, so it
Locality-Sensitive Hashing for Efficient Web Application Security Testing
195

is not useful as an estimator of the Jaccard similarity
of A and B. As it is done in many estimation techni-
ques, it is possible to reduce the variance of R
A,B
by
using multip le hash fun c tions and computing the ra-
tio of the hash function s, for which the minimum ele-
ment is the same. I n other words, assume now a set
of ℓ hash functions, h
1
,... ,h
ℓ
. For each 1 ≤ i ≤ ℓ we
define R
(i)
A,B
as in Eq. 4, replacing h with h
i
. The im-
proved estimator for the Jacc ard similarity of A and B,
T (A,B), is now g iven by:
T (A,B) =
∑
ℓ
i=1
R
(i)
A,B
ℓ
(5)
By Chern off bound, it c a n be shown that the ex-
pected error is O(
1
√
ℓ
).
The compressed representation
hh
1
min
(S),..., h
ℓ
min
(S)i of a set S is defined as its
MinHash sketch. Since ℓ is significantly smaller tha n
the size of S, the estimation of the Jaccard similarity
is efficient in both time and memory.
4 METHOD
In this section we present the c omplete algorithm for
detecting duplica te con te nt du ring a black-box secu-
rity scan. The first step is transforming a web page,
given as an HTTP response string, into a set of shing-
les, or k-mers. In the second step, the algorithm uses
MinHash sketches in order to efficiently compute si-
milarity between pages. However, the method descri-
bed in section 3 still requires that we comp ute the si-
milarity between all possible pair s of states. Instead,
we use an efficient LSH approach that focuses only
on pair s that are potentially similar. We outline the
complete algorithm at the end of this section.
4.1 Set Representation of Web Pages
As stated in section 1, the text content of a web page
is usually irrelevant for the state similarity problem in
the co ntext o f security scans. Therefore, we rely on
the DOM representation of th e page. The algorithm
extracts the DOM tree from the HTTP resp onse, and
serializes it to a string. The relevant in formation for
the state similarity task includes the DO M elements
and their structure, the events an d the event handler s
that are associated with the elements, as well as some
of their attributes. Yet, for simplicity reasons, in this
paper we o nly consider the names of the elements and
the structure of the DOM.
Since we are interested in using MinH ash, there is
a need to transform the string representation of the
DOM into a set of elements. For the sake of this
purpose, we use the notion of shing le s, or k-mers,
which are sequences of any k consecutive words. In
this case, since the DOM elements ar e the building
blocks of the DOM tree, we conside r every element
as a word. The algorithm can filter o ut part of the
DOM elements, if they are marked as irrelevant.
A key factor in the perfo rmance of the algorithm
is the choice of the value of k. If k is too small, then
many k-mers will appear in all web pages, and most
of the pages will be similar to ea c h other. Alternati-
vely, as th e value of k becom es too high, the compa-
rison of states is too strict. So, k should have a large
enoug h value, su ch that the probability of different
states sharing the same k-mer, is low.
4.2 Efficient LSH for MinHash Sketches
To accelerate the proc ess of detecting duplicate con-
tent, we u se a hash table indexing approach, which
rearranges the sketches in a way that similar states
are more likely to be stored closely in our data struc-
ture. D issimilar states, on the other hand, are not sto-
red together, or are rarely stored in proximity. Such an
approa c h is also used in other domains, e.g., genome
assembly (Berlin et al., 2015).
The algorithm co nstructs a data structure of ℓ
hash tables, ea ch c orresponding to a different hash
function. I n the i-th hash table, we map every hash va-
lue v, which was computed by the i-th hash function,
to a set of DOM IDs, which correspond to DOMs that
are ha shed to this value. So , if w e denote the set of all
DOMs by P , and for every set-r e presentation P ∈ P
we denote its ID by ID(P), then the i-th table is a
mapping of the following form:
v 7→
ID (P) | P ∈ P ∧h
i
min
(P) = v
(6)
Using Eq. 3, we can see that the higher the Jac-
card similarity of two DOMs is, the higher the proba-
bility of their IDs being in the same set (or bucket).
Given two DOM representations, P and P
′
, we get
by Eq. 5 that an estimator for the Jacc ard similarity
J(P,P
′
) can be computed according to the number of
hash ta bles, for which ID(P) and ID(P
′
) are in the
same bucket. T his follows directly from the fact that
for every 1 ≤ i ≤ℓ, if the i-th hash table contains bo th
ID (P) and ID(P
′
) in the same bucket, then it holds
that h
i
min
(P) = h
i
min
(P
′
). So , we can derive an esti-
mator, T
∗
, for this particular LSH scheme, which is
based on Eq. 5. Let us denote the i-th hash table by
g
i
, 1 ≤i ≤ℓ, and let us mark the bucket which is ma p-
ped to hash value v in the i-th table, by g
i
(v). We then
have:
ICISSP 2019 - 5th International Conference on Information Systems Security and Privacy
196

T
∗
(P,P
′
) =
i | ∃v.ID(P),ID(P
′
) ⊆ g
i
(v)
ℓ
(7)
Following E q. 7, there is no nee d to c ompare
every DO M to all other DOMs. For every pair of
DOM representa tions, which shar e no common buc-
ket, the estimated value of their Jaccard similarity is
0.
4.3 The Complete Algorithm
We now combine the shingling process and the LSH
technique, and describe the complete algorithm for
detecting duplicate content, durin g a black-box secu-
rity scan. For simplicity, we assume a given set of
application states, S . With this assumption in mind,
we can discard the part of parsing web pa ges and ex-
tracting links and JavaScript actions. A pseudo-code
of the algorithm is given in Algorithm 1.
In an initialization phase (lines 1-3), the code ge-
nerates ℓ hash functions, out of a family H of hash
functions. For each hash function, h
i
, a correspon-
ding hash ta ble, g
i
, is allocated in an array of h ash
tables. The rest of the code (lines 4-20) describ e s the
crawling process and the creation of an index of n on-
duplicate pages.
For each application state, s, the algorithm crea-
tes its DOM set representation, P, using the meth od
Shingle(s,k). The method extracts the DOM tree of
the web page of state s, filters out all text and irrele-
vant elemen ts, and converts the list of DOM eleme nts
into a set of overlapping k-consecutive elements. We
omit the description of this method fr om the pseudo-
code.
lines 6-13 analyze the DOM set representation, P.
A MinHash sketch of the set of shingles is computed
by evaluating all hash fun c tions. While doing so, we
maintain a coun t of how many times every DOM ID
shares the same bucket with the currently analyz ed
DOM, P. This is don e using a mapping, f , which is
implemented as a hash table as well, with a constant-
time insertion and lookup (on average). The highest
estimated Jaccard similarity score is th en found (line
14). If this score is lower than the minimum threshold,
τ, then a pplication state s is considered to have new
content for the purpose of the scan. In such a case, it
is added to the index, and the data set of hash values
is u pdated by addin g the MinHash sketch of the new
state. Otherwise, it is discarded as duplicate conte nt.
The state equivalence mechanism described h ere
is not an equivalence relation, since it is not transitive.
This fact implies that the order in which we analyze
the states can influence the number of unique states
found. For example, for every τ and every odd integer
Algorithm 1: Removing duplicate web application states.
Input: S : set of web application states
H : family of hash functions
k: shingle size
ℓ: MinHash sketch size
τ: Jaccard similarity threshold
Output: set of states with no near-duplicates
1: hh
1
,... , h
ℓ
i ← sample ℓ functions from H
2: [g
1
,... , g
ℓ
] ← array of ℓ hash tables
3: i ndex ←
/
0
4: for s ∈ S do
5: P ← Shingle(s,k)
6: f ← mapping of type N → N
+
7: for i in range 1,.. . ,ℓ do
8: v ← h
i
min
(P)
9: for docId in g
i
(v) do
10: if docId ∈ f then
11: f (docId) ← f (docId) + 1
12: else
13: f (docId) ← 1
14: score ← max
j∈f
f ( j)
15: if score < τℓ then
16: for i in range 1,... , ℓ do
17: v ← h
i
min
(P)
18: if v /∈ g
i
then g
i
(v) ←
/
0
19: g
i
(v) ← g
i
(v) ∪ {ID(s)}
20: index ← index ∪ {s}
21: return index
m, we can construct a series of application states
s
1
,... ,s
m
, such that J(s
i
,s
i+1
) ≥ τ for every 1 ≤ i ≤
m−1, but J(s
i
,s
j
) < τ for every 1 ≤i, j ≤m such that
|i − j| ≥ 2. Algorithm 1 outputs either ⌊
m
2
⌋ or ⌈
m
2
⌉
unique states, depending on the scan order. Although
theoretically possible, we argue that web applications
rarely exhibit such a problematic scenario.
4.4 MinHash Generalization Properties
It is clear that the MinHash algorithm generalizes
na¨ıve methods th a t directly apply hash functions on
the en tire string representation of the DOM , such
as (Duda et al., 2009) and (Frey, 2007). By generali-
zation we mean that for any given pair of states, s
1
and
s
2
, and any given hash f unction h, if h(s
1
) = h(s
2
),
then a pplying our L SH scheme also yields an equa-
lity between the states. Therefore, any pair of pages
that are considered the same state by a na¨ıve h a shing
algorithm , will also be treated as such by the method
we pro pose.
More interesting is the fact that our alg orithm is
also a gener alization of a more complex method. The
algorithm in (Ayou b et al., 2013) identifies repeating
patterns that should be ignored when detecting dupli-
cate content. Denote by d
1
and d
2
two DOM strings
that differ in the number of times that a repeating pat-
tern occurs in them. More precisely, let d
1
= ARRB
Locality-Sensitive Hashing for Efficient Web Application Security Testing
197

and d
2
= ARRR..RRRB be two DOM strings, where A,
B, and R are substrings of DOM eleme nts. Let us as-
sume that the me thod in (Ayoub et al., 2013) iden tifies
the rep e ating patterns and obtain s the same cano nical
form for both d
1
and d
2
, which is ARB. This way,
d
1
and d
2
are identified as duplicates by (Ayoub et al.,
2013). It is easy to see then that if k < 2 |R|, where the
length of a DOM substring is defined as the number of
DOM elements in it, then the MinHash approach will
also mark these two DOM strings as duplica te s, since
there is no k- mer that is included in d
2
and not in d
1
,
and vice versa. This proof do es no t hold for the case
of d
1
= ARB. However, our approach will also mark
d
1
and d
2
in this case as near-duplica te content with
high probability if k is relatively sma ll comparing to
the lengths of A, B, and R.
5 PERFORMANCE EVALUATION
In this section w e present the evaluation process of
the LSH based approach for detectin g similar states.
We report the results of this method when applied to
real-world applications, and compare it to four other
state equivalence heuristics.
5.1 Experimental Setup
We implemented a pro totype of the L SH mechanism
for MinHash sketches as part of IBM
R
Security App-
Scan
R
tool (IBM Secur ity AppScan, 2016). AppS-
can uses a different notion for crawling than most ot-
her scanners. It is not a request-based crawler, but
rather an action-based one. The crawler utilizes a
browser to per form actions, instead of manipulating
HTTP requests and directly executing code via a Ja-
vaScript engine. While processing a new page, all
possible actions, e.g., clicking on a link, submitting
a form, inputting a text, are extracted and adde d to a
queue of unexplored actions. Every action is executed
after replaying the sequence of actions that resulted in
the state from which it was originated. The crawling
strategy is a mixture of BFS and DFS. As a result, the
crawler can go deeper into the application, while still
avoid focusing on on ly one part of it.
The M inHash algorithm ca n be combined with
any crawling mec hanism. The algorithm marks re-
dunda nt pages, and their content is ignored. Offline
detection o f duplicate content is not feasible for mo-
dern, complex applications with an enormous amount
of pages, since one cannot first construc t the entire set
of possible pages. In fact, this set can be infinite, as
content might be dy namically generated.
We perform e d security scans on seven real-world
web applications and compared the efficiency of
our method with other DOM state equivalence algo-
rithms. The first three applications are simple RIAs,
which can be manually analyzed in order to ob tain
a true set o f all possible application states. We w e re
given access to two I BM-internal applications for ma-
naging security scans on the cloud : Ops Lead and
User Site. As a third simple RIA we chose a pu-
blic web- based file manager called elFinder (elFin-
der, 2016). We chose applications that are used in
practice, without any limitations on the we b techno-
logies they are implemented with.
In order to assess the performance of a state e qui-
valence algorithm, it must also be tested on c om-
plex a pplications with a significant number of near-
duplicate pages. Otherwise, inefficient mechanisms
to detect similar states m ight be considered success-
ful in crawling web applications. The refore, we also
condu c te d scans on four complex online applications:
Faceboo k , the famous social networking website (Fa-
cebook, 2004); Fan dango , a movie ticketing applica-
tion (Fandango, 2000); GitHub, a leading develop-
ment platform for version control and collabor ation
(GitHub, 2008); and Netflix, a known servic e for wa-
tching TV episodes and movies (Netflix, 1997), in
which we crawled only the media subdomain. These
applications were chosen due to their high complex-
ity and extensive usage of moder n web technologies,
which pose a great challenge to web application secu-
rity scanners. In addition, they contain a considerable
amount of near-duplicate content, which is not always
the case when it comes to offline versions of real-
world web applications. We analyzed the results of
scanning the four complex applications without com-
paring them to a manually-constructed list of applica-
tion states.
Since a full process of crawling a complex RIA
can take several ho urs or even days, a time limit was
set for every scan. Such a limit also e nables to test
how fast the crawler can find new content, which is
an important aspect of a black-box security scanner.
We report the number of no n-redundant states
found in the scans, along with their duration tim es.
However, the number of discovered states does not
necessarily reflect the quality of the scan: a state equi-
valence algorithm might co nsider two different states
as one ( false merge), or treat two views of the same
state as two different states (false split). Furthermore ,
the scan may not even reach all possible application
states. In o rder to give a measur e of how ma ny false
splits occu r d uring a scan, we compute the scan ef-
ficiency. The efficiency of a scan is defin e d as the
fraction of the scan results which contains new con-
ICISSP 2019 - 5th International Conference on Information Systems Security and Privacy
198

tent. In other word s, this is the ratio between the real
number of unique states found and the number of uni-
que states reported during the scan. A too-strict state
equivalence relation implies more duplica te content
and a lower scan efficiency. The coverage of the scan
is defin ed as the ratio between th e number of truly
unique states found a nd the real number of unique
states that exist in the application. If the relation is
too lax, then too many false merges occur, leading
to a lower scan coverage. Inefficient scans can have
low coverage as well, if the scan time is consumed al-
most entirely in exploring duplicate content. As the
scan coverage computation requires knowing the en-
tire set of application states, we computed it only for
the three simple applications. T he scan efficiency is
reported for all scanned applications.
This paper sugge sts a new approach f or the state
similarity problem. H e nce we chose evaluation cri-
teria that are directly related to how well the scan-
ner explor e d the tested applications. We do not as-
sess the quality of the explore through indirect metrics
such as the number of security issues found during
the scans. In addition, du ring the test phase AppS-
can sends thousands of custom test re quests that were
created during the explore stage. Such amount of re-
quests could overload the application server or even
affect its state, and we clearly could not do that for
applications like Facebook or GitHub. For these rea-
sons we do not report how many security vulnerabili-
ties wer e detected in each scan. An other metric that is
not applicable for online applications is the code co-
verage, i. e., the number of lines of code executed by
the scanner. This metric cannot be computed a s we
only have limited access to the code of these complex
online app lications. However, it is clear that scans
that are more efficient and have a highe r coverage rate
can detect more secu rity vulnerabilities.
Our proposed method, MinHash, was compared
to four other approaches: two hash-based algorithms,
and two additional security scan ners that apply non
hash-based techniques to detect similar states. The
Simple Hash strategy hashes every page according
to the list of DOM elements it contains (order pre-
served). The second h ash-based method, the DOM
Uniqueness tec hnique (Ayoub et al., 2013), identi-
fies similar states by reduc ing repeating patter ns in
the DOM structure and then applying a simple hash
function on the reduced DOMs. As a third approach
we used j
¨
Ak ( Pellegrino et al., 2015), whic h solves
the state similarity algorithm by computing the Jac-
card similarity between pages with the same normali-
zed URL. Another non hash -based approach was eva-
luated by using CRAWLJAX (Mesbah and Van Deur-
sen, 2008). The c rawler component of the latter tool
uses the Levenshtein edit distance to compute simila-
rity between pages. We used the default configuration
of these scanners. Section 2 provides more details on
the approaches we compared our tool with.
We scan ned the tested applications three times,
each time using a different DOM state equivalence
strategy. All scans were limited to a running time of
30 minutes. In the MinHash im plementation we set
the value of k to 12, the number of hash functions, ℓ,
to 200, and the minimum similarity threshold, τ, was
set to 0.85. The values of k and τ were determined
by performing a grid search and choosing the values
which gave o ptimal results on two of the tested appli-
cations. The numbe r of hash fun c tions, ℓ, was com-
puted using Chernoff bound, so the expected error in
estimating the Jaccard similarity of two pages is at
most 7%.
5.2 Results for Simple RIAs
Table 1 lists the results of the experime ntal scans we
condu c te d on three simple RIAs. The results show
that using MinHash as the DOM state equivalence
scheme yields fast and efficient security scans, with
a negligible impact on the coverage, if any. Scan-
ning simple a pplications with j
¨
Ak also produces high-
quality results. The rest of the approa ches were less
efficient, overestimating the number of unique sta-
tes. Some of the scans involving the other hash-based
techniques were even terminated due to scan time li-
mit. However, since the tested applications were very
limited in their size, these approaches usu ally had
high coverage rates.
5.2.1 MinHash Results
The MinHash scans were very fast and pro duced con-
cise application models. They quickly revealed the
structure of the applications, le ading to efficient scans
also in terms of m e mory requirements. The propo-
sed algorithm managed to overcome multiple types of
changes between pages that belong to the same state.
This way, pages with additional charts, banners, or
any other random DOM elem e nt, were usually con si-
dered as duplicates (see Figure 1). Similar pages that
differ in the order of their components were also cor-
rectly identified as duplicate content, since the LSH
scheme is almost indifferent to a component re orde-
ring. This property holds since a component reorde-
ring introduces new k-mers only when new combi-
nations of consecutive components are created. As
the number of reo rdered components is usually sig-
nificantly smaller than their size, the probability of
a change in the MinHash sketch is low. In addition,
Locality-Sensitive Hashing for Efficient Web Application Security Testing
199

Table 1: Results of security scans on three simple real-world web applications using five different strategies for DOM state
equivalence: j
¨
Ak (JK), CRAWLJAX (CJ), Simple Hash (SH), DOM Uniqueness (DU), and MinHash (MH). The first row
shows the real number of unique states in the application, whereas the second row contains the number of non-redundant
states reported i n each scan. The next two lines provide the coverage and efficiency rates of the scans. In the last row, a
runtime of thirty minutes corresponds to reaching the time limit.
elFinder User Site Ops Lead
JK CJ SH DU MH JK CJ SH DU MH JK CJ SH DU MH
App states 7 18 27
Scan states 7 12 38 34 7 18 20 31 21 18 31 33 42 41 25
Coverage (%) 100 100 100 100 100 100 100 100 100 94 100 100 93 89 89
Efficiency (%) 100 58 18 21 100 100 90 58 86 94 87 82 60 59 96
Time (m) 8 7 30 30 10 2 2 4 3 2 9 10 30 23 12
Figure 1: Successful merge of two views with the same
functionality using the MinHash algorithm. (a) Upper part:
a list view of a directory. (b) Lower part: the same view
with a textual popup.
multiple views of the same state that differ in a repea-
ting pattern were also detecte d. This is in correspon-
dence with section 4.4, which shows that our method
is a generaliza tion of the DOM Uniqueness appr oach.
There were, however, cases where different sta-
tes were considered the same, and this led to some
content be ing missed. The missing states were very
similar to states that had alread y been reported in the
model. See section 6 for a discussion on this matter.
5.2.2 Results of other Ha sh-based Approaches
The scans produc e d by the other hash-b ased methods
had high coverage rate. H owever, they were someti-
mes very long, and the number of reported states was
very high (up to a factor of five compared to the cor-
rect number of states). Some were even terminated
due to time limit. The stringency of the equivalence
relations led to inefficient results and to unclear appli-
cation models. Such mod els will also result in a lo n-
ger test phase, as th e black-box scan is about to send
hundreds and thousands of redundant custom test re-
quests.
As expe cted, the na¨ıve approach of simple hashing
was very inefficient. The DOM Uniquen ess method
had better re sults in two out of the three tested appli-
cations. However, relevant scans were still long and
inefficient (as low as 21% efficiency rate). Alth ough
the algorithm in (Ayoub et al., 2013) detects sim ilar
pages by reducing repeating patterns in the DOM, it
cannot detect similar pages that differ in other parts
of the DOM. Consider, for example, two similar pa-
ges where only o ne of them contains a textual popup.
Such a pair of pages was mistakenly deemed as two
different states (see Figure 1). A similar case occu rred
when the repeating pattern was not exact, e.g., a table
in which every row had a different DOM structure).
5.2.3 Results of Non Hash-based Tools
The scans obtained using j
¨
Ak and CRAWLJAX were
also very fast and with perfect coverage. However,
they were not always as efficient as the MinHash-
based scans. The relatively sma ll number o f pages
and states in the tested applications enabled short run-
ning times, although these non hash-based method s
perform a high number of comparisons between sta-
tes. Among the two methods, j
¨
Ak was more efficient
than CRAWLJAX.
5.3 Results for Complex RIAs
The results shown in Table 2 emphasize that an accu-
rate and efficient state equivalence algorithm is cru-
cial for a successful scan of complex app lica tions.
The MinHash algorithm enabled scanning these ap-
plications, while the na¨ıve approach and the DOM
uniqueness algorithm completely failed in doing so
in some cases. CRAWLJAX and j
¨
Ak had reasonable
results; however, their efficiency rate s were not high.
5.3.1 MinHash Results
The MinHash-based scan s efficiently reported dozens
of application states, with approximately 80% of the
states be ing truly unique. In addition, the number of
ICISSP 2019 - 5th International Conference on Information Systems Security and Privacy
200
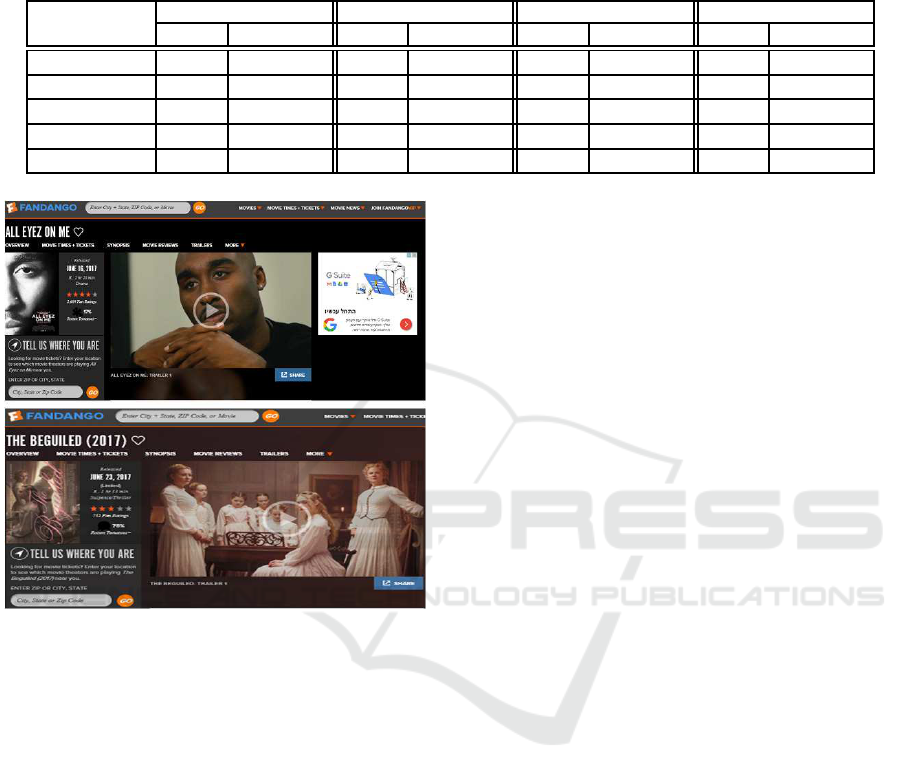
Table 2: Results of security scans on four complex real-world web applications using five different strategies for DOM state
equivalence. The first column for every application contains the number of non-redundant states reported in each scan. The
second column provides the efficiency rate (%). Scans that did not reach the time limit and crashed due to memory or other
problems - are marked with asterisk.
Facebook Fandango GitHub Netflix
States Efficiency States Efficiency States Efficiency States Efficiency
j
¨
Ak 1
*
100 54 37 26 34 47 32
CRAWLJAX 68 38 32 50 184 30 40 40
Simple Hash 694
*
2 493 4 306 22 206 7
DOM Uniq. 692
*
3 468 5 266 30 133 17
MinHash 200 8 3 34 82 108 81 27 78
Figure 2: Successful merge of two different states using
MinHash sketches. (a) Upper part: movie overview page
(b) L ower part: an overview page of a different movie.
false merges was very low. The algor ithm success-
fully iden tified different pa ges that belong to the same
application state. For example, pages that descr ibe
different past activities of Facebook users were consi-
dered as duplicate content. This is, indeed, correct, as
these pages contain the same set of possible user inte-
ractions and the same set of possible security vulne-
rabilities. A typical case in which the MinHash algo-
rithm outperforms other methods can also be found in
the projects view of GitHub. A GitHub user ha s a list
of starred (tracked) proje c ts. Two GitHub users may
have completely different lists, but these two views
are equivalent, security-wise. Figure 2 depicts anot-
her example of a successful merge of states.
At the same time, th e algorithm detected state
changes even when most of the content had not been
changed. For instance, a state change occurs when the
Fandango application is provided with information on
the user’s location. Prior to this, the user is asked
about he r location via a form. When this form is fil-
led and sen t, the application state is changed, and ge-
otargeted information is presented instead. This may
affect the security vulnerabilities in a page; hence the
need to consider these two states as different.
A successful split can also be found in the results
of the Facebook scan. The privacy settings state is al-
tered if an add itional menu is open, and this change
was detected by our method (see Figure 3). Such a
case frequently occurs in complex online applicati-
ons, where there are several actions that are common
to many views, e.g., opening menus or enabling a chat
sidebar. Therefore, the number of possible states can
be high. However, almost every combination differs
from the others, so th ey are usually co nsidered diffe-
rent states. We discuss a method to safely reduce the
number of reported states in section 6.
There were also cases where the MinHash algo-
rithm inc orrectly split or merged states. One such
case was during the Facebook scan, when analyzing
two states that are accessed through the security set-
tings page. One state allows choosing trusted friends,
and the other enables a password change. Despite
their similarity, there a re different actions tha t c an be
done in each of these states. Hence, they should be
counted as two different states, and were mistakenly
merged into one. In the opposite direction, some sta-
tes were sp lit durin g the scan into multiple groups be-
cause of insignificant changes between different re-
sponses. Section 6 sug gests several explanations for
these incorrect results.
5.3.2 Results of other Ha sh-based Approaches
As was pointed in (Benjamin e t al., 2010), when th e
equivalence relation is too stringent, the scan might
suffer from a state explosion scen ario, which requi-
res a significant amount of time and memory. This
observation accurately describes the scans involving
the other two hashing methods, which often resulted
in a state explosion scenario. Even when they in-
cluded mo st of the states reported by th e MinHash
scans, they also containe d hu ndreds of redundant sta-
Locality-Sensitive Hashing for Efficient Web Application Security Testing
201

tes. This is due to the fact that the crawler exhausti-
vely enu merated variations of a very limited number
of states. The Facebo ok and Fandango scans reported
hundreds of states, with more than 95% of the sta-
tes being du plicate content. Moreover, since the Fa-
cebook application is very complex and diverse, the
state explosion scenario caused these scans to termi-
nate due to memory problems.
It is interesting to analyze the performance of the
na¨ıve approach and the DOM Uniq ueness algorithm
when crawling the list of starred (tracked) projects of
GitHub users. While it is clear that the na¨ıve appro-
ach failed to merge two views with different number
of starred projects, it is surprising to see that the DOM
uniqueness algorithm also did not completely succ e ed
in doing so. The reason for that is because the items of
the list d o not necessarily have the same DOM struc-
ture. Theref ore, there is not always a comm on repea-
ting pattern between different lists, and the lists were
not always reduced to the same DOM canonical form.
5.3.3 Results of Non H ash-based Tools
The efficiency of the non hash-based scanners drop-
ped sig nificantly comparing to their performance on
simple RIAs. This is due to the fact that complex
online applications pose challenges that are still not
well-addressed in these crawlers. CRAWLJAX re-
quires manual configur ation of tailo red comparators
to perform better on certain applications. Moreover,
CRAWLJAX is less scalable due to its all-pairs com-
parison appro ach.
The efficiency rates of the j
¨
Ak scans were not
high, as the assumptio n that similar states must share
the same normalized URL is not always true. In
the Fandango application, for example, pages provi-
ding movie overviews contain the movie name as a
path parameter, and thus are not identified as similar.
The same problem a lso occ urred when j
¨
Ak scanned
Netflix. Multiple pages of this website offer the same
content and the same set of possible user interactions,
albeit they are written in different languages.
The crawling components of j
¨
Ak and CRAWL-
JAX cou ld not login to the Facebook application pro-
perly, so a fair comparison is not possible in that ca se.
6 CONCLUSIONS
In this paper we present a locality-sensitive h ashing
scheme for detecting duplicate content in the domain
of web application security scanning. The method is
based on MinHash sketches that are stored in a way
that allows an efficient and robust duplicate content
Figure 3: Successful split of two nearly similar states using
the MinHash algorithm. ( a) Upper part: account setting
view of a Facebook user. (b) L ower part: the same view
with an additional menu open, adding a new functionality
to the previous state.
detection.
The method is theoretically proven to be less strin-
gent than existing DOM state equivalence strategies,
and can therefore outperform them. This was also
empirically verified in a series of experimental scans,
in which o ther me thods, whether hash-based or n ot,
either completely failed to scan real- world applica-
tions, or constructed large models that did not cap-
ture their structure. As opposed to that, the MinHash
scheme enabled su ccessful and efficient scans. Being
able to better detect similar content prevents the Min-
Hash algorithm from explorin g the same application
state over and over. This way, the scans constantly re-
vealed new content, instead of exploring m ore views
of the same state. The MinHash scans got beyond the
first layers of the applicatio n, and did not consume all
the scan time on th e first few states encountered.
Reducing the scan time and the complexity of the
constructed application model does not always come
without a price. The cost of using an LSH approach
might be a n increase in the num ber of different states
being merged into one, and this could lead to an in-
complete coverage of the application. However, the
risk of a more strict equivalence strategy is to spend
both time and memory resources on duplicate con te nt,
and thus to achieve poor coverage.
This risk ca n be mitigated by better optimiz ing pa-
rameter values. The value of k, the shingle length, can
be optimized to the scanned ap plication. One c a n take
factors such as the average length of a DOM state, or
the variance in the number of d ifferent elements per
page, when setting the value of k for a given scan.
ICISSP 2019 - 5th International Conference on Information Systems Security and Privacy
202

Tuning the similarity threshold per applicatio n may
decrease the n umber of errors a s well. Of course, the
probabilistic na ture of the method also accounts for
some of the incorrect results, as the Jaccard similarity
estimations are not always accurate. In creasing the
number of hash fun c tions can reduce this inaccuracy.
The LSH schem e can be a pplied to any web ap-
plication. However, there are applications in which
its impact is more substantial. Black-box security
scanners are likely to face difficulties when scanning
complex applications. Such applications often hea-
vily rely on technologies such as AJAX, offer dozens
of possible user interactions per page, a nd contain a
great amoun t of near-duplicate content. The Min-
Hash algorithm can dramatically improve the qua-
lity of these scans, as was the case with Facebook or
Fandango. For applications with less variance in the
structure of pa ges that belong to the same application
state, such as Netflix, the DOM uniqu eness state e qui-
valence mechanism can still perform reasonably. But
even in these cases, the MinHash algorithm reaches
the same coverage more efficiently.
A locality-sensitive hashing function helps in a
better detection of similarity between states. Howe-
ver, if a state is actually a container of a number of
components, each having its own sub-state, then the
number of states in the application can grow exponen-
tially. It seems reasonable that applying our a lgorithm
on every comp onent separately would give b etter re-
sults. In this context, the component-based crawling
(Moosavi et al., 2014) could be a solution for decom-
posing a state into several building b locks, which will
all be analyzed using the MinHash algorithm.
The tested implementation of the MinHash
scheme is very basic. There is a need to take more
informa tion into consideration when constructing the
DOM string representation of a response. For exam-
ple, one can mark part o f the elements as more rele-
vant for security oriented scans, or use the value of
the attributes as well. Theoretically, two pages can
have a very similar DOM and differ only in the event
handlers that are associate d with their elements. Alt-
hough this usua lly do not occur in complex applica-
tions, there were some rare cases w here different sta-
tes were mistakenly merged into one state due to that
reason. Another potential improvement is to detect
which parts of the D O M respon se are more relevant
than others. By d oing so we can mark changes in ele-
ments that are part of a navigation bar as less signifi-
cant than those occurring in a more central part of the
application.
We believe that incorporating these optim iz ations
in the MinHash scheme would make this approach
even more robust and accurate. Co mbined with more
sophisticated crawling methods such as compone nt-
based crawling, security scans can be fur ther impro-
ved a nd provide useful information for their users.
FUNDING
This study was supported by fellowships from the E d-
mond J. Safra Center for Bioinformatics at Tel-Aviv
University, Blavatnik Research Fund, Blavatnik In te r-
disciplinary Cy ber Research Center a t Tel-Aviv Uni-
versity, and IBM.
ACKNOWLEDGEMENTS
We wish to thank Benny Chor and Benny Pinkas for
their helpful suggestions and contribution. We are
grateful to Lior Margalit f or his technical support in
performing the security scans. The work of Ilan Ben-
Bassat is part of Ph.D. th esis research conducted at
Tel-Aviv University.
REFERENCES
Amalfitano, D., Fasolino, A. R., and Tramontana, P. (2008).
Reverse engineering finite state machines from rich
internet applications. In 2008 15th Working Confe-
rence on Reverse Engineering, pages 69–73. IEEE.
Amalfitano, D., Fasolino, A. R., and Tramontana, P.
(2010a). An iterative approach for the reverse engi-
neering of rich internet application user interfaces. In
Internet and Web Applications and Services (IC I W),
2010 Fifth International Conference on, pages 401–
410. IEEE.
Amalfitano, D., Fasolino, A. R., and Tramontana, P.
(2010b). Rich internet application testing using execu-
tion trace data. In Software Testing, Verification, and
Validation Workshops (ICSTW), 2010 Third Internati-
onal Conference on, pages 274–283. IEEE.
Ayoub, K., Aly, H., and Walsh, J. (2013). Document object
model (dom) based page uniqueness detection. US
Patent 8,489,605.
Bar-Yossef, Z., Keidar, I., and Schonfeld, U. ( 2009). Do not
crawl in the dust: different urls with similar text. ACM
Transactions on the Web (TWEB), 3(1):3.
Bau, J., Bursztein, E., Gupta, D., and Mitchell, J. (2010).
State of the art: Automated black-box web applica-
tion vulnerability testing. In 2010 IEEE Symposium
on Security and Privacy, pages 332–345. IEEE.
Benjamin, K., Bochmann, G. v. , Jourdan, G.-V., and Onut,
I.-V. (2010). Some modeling challenges when testi ng
rich internet applications for security. In Software Tes-
ting, Verification, and Validation Workshops (ICSTW),
2010 Third International C onference on, pages 403–
409. IEEE.
Locality-Sensitive Hashing for Efficient Web Application Security Testing
203

Berlin, K., Koren, S., Chin, C.-S., Drake, J. P., Lando-
lin, J. M., and Phil lippy, A. M. (2015). Assem-
bling large genomes with single-molecule sequencing
and locality-sensitive hashing. N ature biotechnology,
33(6):623–630.
Broder, A. Z. (1997). On the resemblance and containment
of documents. In Compression and Complexity of Se-
quences 1997. Proceedings, pages 21–29. IEEE.
Broder, A. Z., Charikar, M., Frieze, A. M., and Mitzenma-
cher, M. (2000). Min-wise independent permutations.
Journal of Computer and System Sciences, 60(3):630–
659.
Choudhary, S ., Dincturk, M. E., Bochmann, G. V., Jourdan,
G.-V., Onut, I. V., and Ionescu, P. (2012). Solving
some modeling challenges when testi ng rich internet
applications for security. In 2012 IEEE Fifth Inter-
national Conference on Software Testing, Verification
and Validation, pages 850–857. IEEE.
Doup´e, A., Cavedon, L., Kruegel, C., and Vigna, G. (2012).
Enemy of t he state: A state-aware black-box web vul-
nerability scanner. In USENIX Security Symposium,
volume 14.
Doup´e, A., Cova, M., and Vigna, G. (2010). Why johnny
can’t pentest: An analysis of black-box web vulnera-
bility scanners. In International Conference on De-
tection of Intrusions and Malware, and Vulnerability
Assessment, pages 111–131. Springer.
Duda, C., Frey, G., Kossmann, D., Matter, R., and Zhou, C.
(2009). Ajax crawl: Making ajax applications sear-
chable. In 2009 IEEE 25th International Conference
on Data Engineering, pages 78–89. IEEE.
elFinder (2016). elfinder. http://elfinder.org/. [Online].
Facebook (2004). Facebook. https://www.facebook.com/.
[Online].
Fandango (2000). Fandango. https://www.fandango.com/.
[Online].
Fard, A. M. and Mesbah, A. (2013). Feedback-directed ex-
ploration of web applications to derive test models. In
ISSRE, volume 13, pages 278–287.
Frey, G. (2007). Indexing ajax web applications. PhD the-
sis, Citeseer.
Garrett, J. J. et al. (2005). Ajax: A new approach to web
applications.
GitHub (2008). Github. https://github.com/. [Online].
Gordeychik, S., Grossman, J., Khera, M., Lantinga, M.,
Wysopal, C., Eng, C. , Shah, S., Lee, L. , Murray, C.,
and Evteev, D. (2010). Web application security sta-
tistics. The Web Application Security Consortium.
IBM Security AppScan (2016). Ibm security app-
scan. https://www.ibm.com/security/application-
security/appscan. [Online].
Indyk, P. and Motwani, R. (1998). Approximate nearest
neighbors: towards removing the curse of dimensio-
nality. In Proceedings of the thirtieth annual ACM
symposium on Theory of computing, pages 604–613.
ACM.
Jaccard, P. (1901). Distribution de la Flore Alpine: dans le
Bassin des dranses et dans quelques r´egions voisines.
Rouge.
Levenshtein, V. I. (1966). Binary codes capable of cor-
recting deletions, insertions and reversals. In Soviet
physics doklady, volume 10, page 707.
Mesbah, A. and Van Deursen, A. (2008). Exposing the
hidden-web induced by ajax. Technical report, Delft
University of Technology, Software Engineering Re-
search G roup.
Moosavi, A., Hooshmand, S., Baghbanzadeh, S., Jourdan,
G.-V., Bochmann, G. V., and Onut, I. V. (2014). Index-
ing rich internet applications using components-based
crawling. In International Conference on Web Engi-
neering, pages 200–217. Springer.
Netflix (1997). Netflix. https://media.netflix.com/. [On-
line].
Nicol, G., Wood, L., Champion, M., and Byrne, S. (2001).
Document object model ( dom) level 3 core specifica-
tion. W3C Working Draft, 13:1–146.
Pellegrino, G ., Tsch¨urtz, C., Bodden, E., and Rossow, C.
(2015). j¨ak: Using dynamic analysis to crawl and
test modern web applications. In International Works-
hop on Recent Advances in Intrusion Detection, pages
295–316. Springer.
Pomik´alek, J. (2011). Removing boilerplate and duplicate
content from web corpora. Disertacnı pr´ace, Masary-
kova univerzita, Fakulta informatiky.
Popic, V. and Batzoglou, S. (2016). Privacy-preserving read
mapping using locality sensitive hashing and secure
kmer voting. bioRxiv, page 046920.
Roest, D., Mesbah, A., and Van Deursen, A. (2010). Re-
gression testing ajax applications: Coping with dyn-
amism. In 2010 Third International Conference on
Software Testing, Verification and Validation, pages
127–136. IEEE.
Tai, K.-C. (1979). The tree-to-tree correction problem.
Journal of the ACM (JACM), 26(3):422–433.
ICISSP 2019 - 5th International Conference on Information Systems Security and Privacy
204
