
Japanese Scene Character Recognition using Random Image Feature
and Ensemble Scheme
Fuma Horie
1
and Hideaki Goto
2
1
Graduate School of Information Sciences, Tohoku University, Sendai, Japan
2
Cyberscience Center, Tohoku University, Sendai, Japan
Keywords:
Random Image Feature, Japanese Scene Character Recognition, Synthetic Scene Character Data, Ensemble
Voting Classifier, Multi-Layer Perceptron.
Abstract:
Scene character recognition is challenging and difficult owing to various environmental factors at image cap-
turing and complex design of characters. Japanese character recognition requires a large number of scene
character images for training since thousands of character classes exist in the language. In order to enhance
the Japanese scene character recognition, we utilized a data augmentation method and an ensemble scheme
in our previous work. In this paper, Random Image Feature (RI-Feature) method is newly proposed for im-
proving the ensemble learning. Experimental results show that the accuracy has been improved from 65.57%
to 78.50% by adding the RI-Feature method to the ensemble learning. It is also shown that HOG feature
outperforms CNN in the Japanese scene character recognition.
1 INTRODUCTION
Recognition of text information in the scene, which is
often referred to as scene character recognition, has
some important applications such as automatic driv-
ing system and automatic translation. Scene charac-
ter recognition is more difficult in comparison with
printed character recognition as there are various fac-
tors such as rotation, geometric distortion, uncon-
trolled lighting, blur, noise and complex design of
characters in the scene images. Japanese scene char-
acter recognition requires a large number of training
data since thousands of character classes exist in the
language. However, collecting a large number char-
acter image samples in real scenes is a hard task.
Some previous researches introduced a data aug-
mentation method using Synthetic Scene character
Data (SSD) which is randomly generated by some
particular algorithms such as filter processing, mor-
phology operation, color change, and geometric dis-
tortion from the font sets of printed characters (Jader-
berg et al., 2014)(Ren et al., 2016)(Jiang and Goto,
2017)(Horie and Goto, 2018). Jader et al. and Ren
et al. have shown that the accuracy of the deep neu-
ral network model can be improved by adding SSD
to the training data. It has been proved that the aug-
mentation methods are effective for improving the ac-
curacy of the scene character recognition. Figure 1
shows some examples of the Japanese characters in
natural scenes. In our previous work (Jiang and Goto,
2017)(Horie and Goto, 2018), we developed a train-
ing datasets consisting of both Real Scene character
Data (RSD) and SSD. The ensemble scheme is used
to improve the generalization ability of the classifier.
For further improvements of the generalization
ability, Random Image Feature (RI-Feature) method
is newly proposed in this paper. The RI-Feature
method is to randomly process an image before ex-
tracting character features and it is applied to each
classifier by different parameters. It is expected that
the RI-Feature method will make the generalization
ability higher. Moreover, we propose a new ensemble
scheme using Multi-Layer Perceptron (MLP) in this
paper. Experimental results show the effectiveness of
RI-Feature method and MLP.
Convolutional Neural Network (CNN) has
achieved a remarkable performance in various image
recognition tasks including also the scene character
recognition. However, the CNN needs a large number
of high-quality training data. It is thought that CNN
is not able to achieve high accuracy in the scene char-
acter recognition when it suffers from the shortage
of training data. Especially, Japanese scene character
datasets currently available are far from enough
to train the CNN. Some previous scene character
recognition systems use HOG feature since it has
414
Horie, F. and Goto, H.
Japanese Scene Character Recognition using Random Image Feature and Ensemble Scheme.
DOI: 10.5220/0007341904140420
In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2019), pages 414-420
ISBN: 978-989-758-351-3
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

been found that the HOG feature outperforms the
other features (SIFT, DAISY, SURF, etc.) (Tian et al.,
2016). In this paper, we compare the performances
of CNN and HOG by some experiments using SSD.
This paper is organized as follows. Section II de-
scribes the ensemble scheme and RI-Feature method.
Section III shows the process of experiments and the
results. Conclusions and future work are given in sec-
tion IV.
2 JAPANESE SCENE
CHARACTER RECOGNITION
USING SSD AND ENSEMBLE
SCHEME
2.1 Flow of the Recognition System
SSD and ensemble scheme were utilized in our pre-
vious work (Horie and Goto, 2018). The new sys-
tem proposed in this paper is an extended version
of the previous system, and Random Image Feature
(RI-Feature) method is newly introduced. Figure 2
shows the flow of our recognition system. Let T be
the number of classifiers. T subsets are created from
the original font dataset by the bootstrap sampling
(Breiman, 1996). Each subset consists of K images.
These subsets are converted to an SSD set. RI-Feature
sets are extracted from the generated SSD. Finally, T
classifiers are created by learning the RI-Feature sets.
At the recognition stage, T RI-Features are extracted
from a query image, and each RI-Feature is put into
each classifier. The answers obtained from every clas-
sifier are combined by plurality voting.
2.2 Synthetic Scene Character
Generator
Synthetic Scene character Data (SSD) is used in order
to increase the training data and to enhance the recog-
nition system in this paper. Some previous researches
have shown the effectiveness of SSD for the scene
character recognition (Jaderberg et al., 2014)(Ren
et al., 2016)(Jiang and Goto, 2017)(Horie and Goto,
2018). SSD is generated through some processes such
as distortion, color change, morphology operation,
background blending and various filters.
The SSD sets are created from image subsets. The
i-th subset S
i
is sampled from an original image set S
o
by the bootstrap method. Normaly,
S
i
= {s
i
j
}, s
i
j
∈ S
o
= {s
o
j
},
where s
i
j
is randomly sampled with replacement.
The SSD are generated by the following process-
ing in this paper.
• Affine Transformation.
The process is defined by the following matrix:
1 0 C
x
0 1 C
y
0 0 0
a
1
a
2
0
a
3
a
4
0
0 0 1
1 0 −C
x
0 1 −C
y
0 0 1
,
a
1
, a
3
∈ [0.9, 1.1], a
2
, a
4
∈ [−0.1, 0.1],
where (C
x
,C
y
) is the center coordinate of the im-
age. a
1
, a
2
, a
3
and a
4
are chosen from uniformly-
random numbers.
• Gaussian Filter.
3×3 matrices are used as the kernels of Gaussian
filter, and they are defined by the following for-
mula:
K(x, y) =
1
2πσ
2
exp
−
x
2
+ y
2
2σ
2
, σ ∈ [0, 10].
(1)
σ is chosen with uniformly-random numbers.
• Morphology Operation.
3×3 matrices are used as kernels of morphology
operation. The operation mode is selected ran-
domly from dilation, erosion, and none.
• Color Change.
We chose 20 colors frequently appeared in various
scene character images. Two colors are selected
randomly as the background and foreground. The
channel intensities of the output image are calcu-
lated by the following formula;
L
′
R
(i, j) =
L(i, j) ×
R
f
− R
b
255
+ R
b
+ 0.5
,
L
′
G
(i, j) =
L(i, j) ×
G
f
− G
b
255
+ G
b
+ 0.5
,
L
′
B
(i, j) =
L(i, j) ×
B
f
− B
b
255
+ B
b
+ 0.5
,
(2)
where L(i, j) is the character image before pro-
cessing, L
′
R
(i, j), L
′
G
(i, j), and L
′
B
(i, j) are
the matrices representing the processed images,
R
f
, G
f
, and B
f
are the foreground colors, R
b
, G
b
,
and B
b
are the background colors, respectively.
• Random Filter (RF).
Random filter is proposed in our previous paper
(Horie and Goto, 2018). The kernels of random
filter are defined by the following formula;
K = (k
n,n
)
1≤n≤3
, k
n,n
∈ R,
3
∑
m=1
3
∑
n=1
k
m,n
= 1, (3)
where k
n,n
is randomly selected.
Japanese Scene Character Recognition using Random Image Feature and Ensemble Scheme
415

Figure 1: Example of Japanese scene characters.
Training stage:
Recognition stage:
Figure 2: Flow of ensemble scheme.
Each process is applied to each image using differ-
ent parameters. Normally, all SSD are different with
each other.
Figure 3 shows the flow of the above SSD gener-
ation. Figure 4 shows some examples of SSD gener-
ated by the above processing.
2.3 Random Image Feature
Ensemble scheme has been used to improve the gen-
eralization ability of classifiers in some previous work
(Jiang and Goto, 2017)(Horie and Goto, 2018). We
have shown that the ensemble scheme effectively im-
proves the accuracy of scene character recognition.
For further improvement of the recognition accuracy,
we propose RI-Feature method.
RI-Feature method applies some random image
processing to the character image before extracting
Figure 3: Flow of SSD generation.
the character features. The random processing is ap-
plied for each classifier using different parameters.
Let D
i
be the i-th SSD set. The processing is as fol-
lows.
• Multi-Scale Resizing (MSR).
Images of D
i
are resized to the following size;
s
i
=
16 (1 ≤ i ≤
T
3
)
32 (
T
3
≤ i ≤
2T
3
)
64 (
2T
3
≤ i ≤ T )
, (4)
where T is the number of classifiers.
MSR was proposed in the previous paper(Jiang
and Goto, 2017). It was demonstrated that MSR
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
416

Figure 4: Examples of SSD used in the training.
effectively improve the ensemble recognition ac-
curacy.
• Random Filter (RF).
Images of D
i
are calculated by RF using the fol-
lowing kernel;
K
i
= (k
i
n,n
)
1≤n≤3
, k
i
n,n
∈ R,
where
3
∑
m=1
3
∑
n=1
k
i
m,n
= 1. (5)
RF is used more than once and by combined with
Mean Filter (MF). We expect that RF is useful for
adding some variations to the features as it intro-
duces various effects to the image. MF is expected
to simulate image blur and also to reduce image
noise.
• Random Affine (RA).
Images of D
i
are deformed by affine transforma-
tion using the following matrix;
1 0 C
x
0 1 C
y
0 0 0
a
i
1
a
i
2
0
a
i
3
a
i
4
0
0 0 1
1 0 −C
x
0 1 −C
y
0 0 1
,
(6)
a
i
1
, a
i
3
∈ [0.8, 1.2], a
i
2
, a
i
4
∈ [−0.2, 0.2],
where (C
x
,C
y
) is the center coordinate of the im-
age.
K
i
, a
i
1
, a
i
2
, a
i
3
and a
i
4
are randomly determined.
RI-Feature method is considered to make an over-
all correlation of classifiers smaller. Ensemble learn-
ing theory is considered in some researches. Tumor
and Ghosh indicated the following formula (Tumor
and Ghosh, 2016).
err
add
(H) =
1 + θ(T − 1)
T
err
add
(h), (7)
where err
add
is the overall error rate of classifiers,
err
add
(h) is the mean of error rates of classifiers, θ
is an overall correlation of classifiers, and T is the
number of classifiers. The overall error rate becomes
smaller by making err
add
(h) or θ smaller or increas-
ing T . For example, Random Forest is the ensem-
ble learning considered an overall correlation of clas-
sifiers (Breiman, 2001). It is expected that the RI-
Feature method makes θ smaller by adding some fluc-
tuations to the input data.
2.4 Recognition Stage
To recognize a query image, T RI-Features are ex-
tracted from the query image at first. Some differ-
ent combinations of random parameters and kernels,
s
i
, K
i
, a
i
1
, a
i
2
, a
i
3
, and a
i
4
are used to extract the i-
th RI-Feature. Second, the RI-Features are put into
each classifier, and each classifier produces the class
label as output. An answer vector is created as follows
when the i-th classifier outputs an answer r
i
.
A
i
= (a
i
1
, a
i
2
, ..., a
i
N
c
),
a
i
j
=
1 if j = r
i
0 if j ̸= r
i
, (8)
where N
c
is the number of classes. The final answer
R is calculated by the plurality voting as follows.
A
f
=
T
∑
i=1
A
i
, A
f
= (a
f
1
, a
f
2
, ..., a
f
N
c
),
R = argmax
x
{ f (x) | f (x) = a
f
x
}. (9)
3 PERFORMANCE EVALUATION
OF ENSEMBLE SCHEME
3.1 Experimental Environment
Experimental environment is as follows:
• CPU: Intel Core i7-3770 (3.4 GHz)
• Memory: 16 GB
• Development language: C/C++, Python
3.2 Dataset
We have created a new Japanese scene character
dataset which is based on the dataset compiled in
Japanese Scene Character Recognition using Random Image Feature and Ensemble Scheme
417
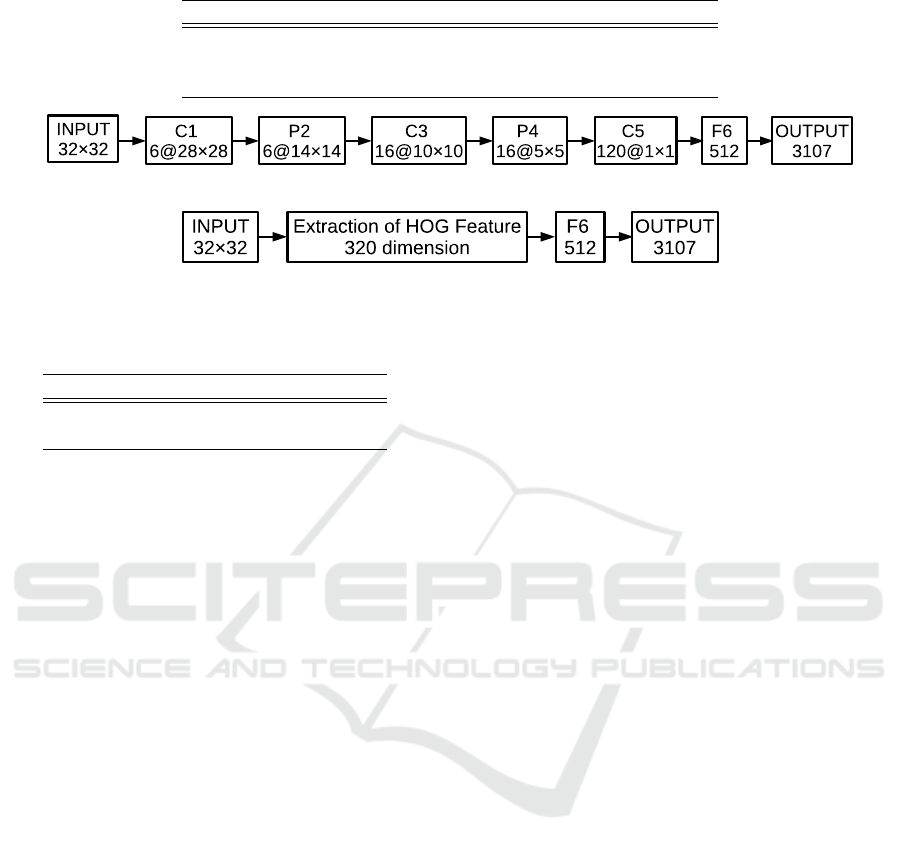
Table 1: Parameters of a HOG feature.
Image size Cell size Block size Orientation Dimension
16×16 2 16 5 320
32×32 4 32 5 320
64×64 8 64 5 320
CNN
HOG-3LP
Figure 5: The architecture of CNN and HOG-3LP.
Table 2: Results of Comparison between CNN and HOG.
Method Recognition accuracy [%]
CNN 63.21
HOG-3LP 66.21
(Horie and Goto, 2018) for testing. The dataset con-
sists of Hiragana, Katakana and Kanji (1,400 images
and 523 classes) taken in real scenes. All charac-
ter images are in color and in arbitrary size. Seven
Japanese fonts (3,107 classes, total 21,749 characters)
are used for training. The training dataset does not in-
clude real scene characters since it is difficult to col-
lect characters of all classes in Japanese.
3.3 Comparison of CNN and HOG
Although CNN has been reported to achieve high-
level accuracy in character recognition, it is thought
that CNN is not effective in a situation of learning
only SSD. In order to confirm it, the following two
architectures are compared.
• CNN: CNN based on LeNet(LeCun et al., 1998)
which consists of 512 nodes in F6 layer and 3,107
in the output layer.
• HOG-3LP: Three-Layer Perceptron (3LP) which
consists of 320 nodes in the input layer, 512 in the
hidden layer and 3,107 in the output layer, and the
learning HOG feature of 320 dimension. ReLU is
used as the activation function in the hidden layer
(Glorot et al., 2011).
Figure 5 shows the architectures. The parameters
of the HOG feature are shown in Table 1. 434,980
grayscale synthetic scene character images are used
as training data in either cases.
Table 2 shows the results. It is shown that CNN
is inferior to HOG. Thus, we use the HOG feature
hereinafter.
3.4 Evaluation of RI-Feature
The following RI-Feature structures are compared in
order to evaluate the effects of the RI-Feature method.
• MSR (Horie and Goto, 2018)
• MSR-RF
• MSR-RA
• MSR-RF-MF-RF-MF-RF
• MSR-RA-RF-MF-RF-MF-RF
Regarding the parameters of the ensemble learning,
T = 90 and K = 9000 are used in all cases. Nearest
Neighbor Search (NNS) is utilized as the classifier of
the ensemble scheme. We have chosen NNS in order
to see the system’s behavior in an environment which
is as simple as possible in this early stage of devel-
opment. Although using some other classifiers would
be quite interesting, it should be included in our future
work.
Table 3 shows the results. Particularly, the combi-
nation of RF and MF greatly improves the accuracy.
This is probably because the MF effectively decreases
the image noise. Moreover, it is thought that the RA
makes the ensemble learning robust against geometric
distortions.
Figure 6 shows the evaluation results about the
number of classifiers. Our system using the RI-
Feature outperforms the previous system in a condi-
tion of T > 15.
3.5 Improvement of Classifiers
It is expected that more SSD make the recognition
system better. Time complexity and space complex-
ity of NNS are both O(n), where n is the number
of image samples. On the other hand, the complex-
ities of Support Vector Machine (SVM) and Multi-
Layer Perceptron (MLP) are O(1). Thus, SVM and
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
418
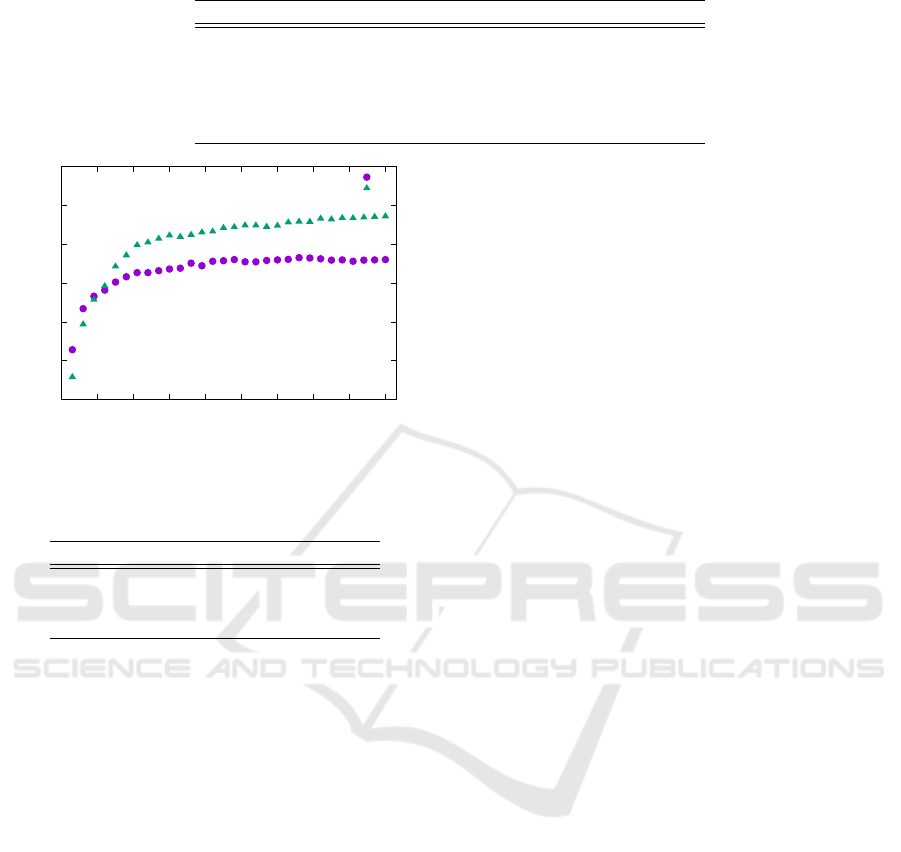
Table 3: Comparison among methods of different RI-Feature.
RI-Feature method Recognition accuracy [%]
MSR (Horie and Goto, 2018) 65.57
MSR-RF 70.14
MSR-RA 71.64
MSR-RF-MF-RF-MF-RF 76.00
MSR-RA-RF-MF-RF-MF-RF 78.50
30
40
50
60
70
80
90
0 10 20 30 40 50 60 70 80 90
Recognition accuracy [%]
The number of classifiers T [-]
MSR
MSR-RA-RF-MF-RF-MF-RF
Figure 6: The evaluation about the number of classifiers.
Table 4: Evaluation of different classifiers in the ensemble
learning.
Classifier Recognition accuracy [%]
NNS 78.50
SVM 77.93
3LP 80.71
MLP are able to learn a large number of training data.
The previous methods (Jiang and Goto, 2017)(Horie
and Goto, 2018) utilized SVM in the ensemble learn-
ing. We have introduced MLP in order to improve the
recognition accuracy.
Following three classifiers are compared.
• NNS: Nearest Neighbor Search
(K = 9, 000, T = 90)
• SVM: Linear Support Vector Machine (C = 1)
(K = 200, 000, T = 90)
• 3LP: Three-Layer Perceptron
(K = 200, 000, T = 90)
Figure 7 shows the architecture of 3LP. ReLU is used
as the activation function in the hidden layer (Glorot
et al., 2011). MSR-RF-MF-RF-MF-RF-MF-RF-RA
is used as the RI-Feature method in all cases.
Table 4 shows the results. It is shown that 3LP is
superior to NNS and SVM. It is considered that the
number of training data and the kind of classifier are
important for the ensemble scheme. Figure 8 shows
that our proposed system is able to recognize char-
acters which has some rotation, blur, lighting, noise
and various fonts. It is shown that the correct an-
swers of some incorrectly recognized characters are
included in the second or third candidate. We ex-
pected that some of the characters are correctly rec-
ognized by combining the natural language process-
ing or any other processes. Our system can not rec-
ognize some characters having great geometric distor-
tion, complex background, and extraordinary design.
4 CONCLUSION
We have proposed RI-Feature method for improve-
ment of the ensemble scheme proposed in our previ-
ous work. RI-Feature method is to randomly process
an image before extracting the character features. We
have also proposed to introduce MLP in the ensemble.
Experimental results have shown that HOG out-
performs CNN in the case of using only SSD. It
is also shown that the accuracy has been improved
from 65.57% to 78.50% by the newly introduced RI-
Feature method in the ensemble scheme.
Our future work includes to examine the appro-
priate feature in the ensemble scheme learning the
Japanese synthetic scene characters.
REFERENCES
Breiman, L. (1996). Baggin predictors. Machine Learning,
24:123–140.
Breiman, L. (2001). Random forests. Machine Learning,
45:5–32.
Glorot, X. et al. (2011). Deep sparse rectifier neural net-
works. In Proceedings of Machine Learning Re-
search, volume 15, pages 315–323.
Horie, F. and Goto, H. (2018). High-accuracy japanese
scene character recognition using synthetic scene
characters and multi-scale voting classifier. In
DAS2018 Short Paper.
Jaderberg, M. et al. (2014). Synthetic data and artificial neu-
ral networks for natural scene text recognition. Work-
shop on Deep Learning, NIPS.
Jiang, L. and Goto, H. (2017). Ensemble classifier with
dividing training scheme for chinese scene character
recognition. In 2017 International Conference on Im-
age and Vision Computing New Zealand (IVCNZ).
LeCun, Y. et al. (1998). Gradient-based learning applied to
document recognition. In Proc. of the IEEE.
Japanese Scene Character Recognition using Random Image Feature and Ensemble Scheme
419

Figure 7: The architectures of 3LP.
Correctly recognized characters
Incorrectly recognized characters
Figure 8: Recognition examples.
Ren, X. et al. (2016). A cnn based scene chinese text recog-
nition algorithm with synthetic data engine. arXiv
preprint arXiv: 1604.01891.
Tian, S. et al. (2016). Multilingual scene character recogni-
tion with co occurrence of histogram of oriented gra-
dients. Pattern Recognition, 51:125–134.
Tumor, K. and Ghosh, J. (2016). Theoretical foundations of
linear and order statistics combiners for neural pattern
classifiers. In Technical Report TR-95-02-98, Com-
puter and Vision Research Center, University of Texas,
Austin.
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
420
