
Multi-stage Off-line Arabic Handwriting Recognition Approach using
Advanced Cascading Technique
Taraggy Ghanim
1,2
, Mahmoud I. Khalil
2
and Hazem M. Abbas
2
1
Faculty of Computer Science, Misr International University, Egypt
2
Faculty of Engineering, Ain Shams University, Egypt
Keywords:
Arabic Handwriting Recognition, Random Forest, Kullback-Leibler Divergence, Pyramid Histogram of
Gradient, Support Vector Machine.
Abstract:
Automatic Recognition of Arabic Handwriting is a pervasive field that has many challenging complications to
solve. Such complications include big databases and complex computing activities. The proposed approach
is a multi-stage cascading recognition system bases on applying Random Forest classifier (RF) to construct
a forest of decision trees. The constructed decision trees split big databases to multiple smaller data-mined
sets based on the most discriminating computed geometric and regional features. Each data-mined set include
similar database classes. RF match each test image with one of the data-mined sets. Afterwards, the matching
classes are sorted relative to test image using Pyramid Histogram of Gradients and Kullback-Leibler based
ranking algorithm. Finally, the classification process is applied on the highly ranked matching classes to
assign a class membership to test image. Adjusting the classification process to only consider the highly
ranked database classes reduced the computing classification and enhanced the overall performance. The
proposed approach was tested on IFN-ENIT Arabic database and achieved satisfactory results and enhanced
sensitivity of decision trees to reach 93.5% instead of 86.5% (Ghanim et al., 2018).
1 INTRODUCTION
Automatic Arabic Handwriting recognition is a chal-
lenging computer vision application. It is useful for
analyzing and digitizing handwritten documents, re-
serving and documenting old manuscripts. It requires
building robust hybrid classifiers that merge differ-
ent but complementary methods to achieve high au-
tomatic recognition rates.
Handwritten recognition process is categorized
into online or offline process(Amin, 1998). Offline
recognition is based solely on visual images and pixel
information which is more challenging and concerned
in our work.
Arabic is a cursive language and one of the ma-
jor worldwide document sources (Amin, 1998). Lan-
guage specifications and description are provided by
(Abandah and Khedher, 2009) and (AbdelRaouf et al.,
2008). It is the native language of more than 420 mil-
lion people around the world, the sixth most spoken
language, and used in around 27 different languages
(Campbell and Grondona, 2008) and can be repre-
sented in different handwriting styles.
The proposed approach is divided into three cas-
caded stages. The first is matching each test image
with set of database classes. The second is ranking
the set of matching classes and finally classification as
described and analyzed in Section 3.In the introduced
approach, recognition is done without character seg-
mentation to decrease computing time and errors due
to wrong segmentation.
Previous related work is summarized in section 2.
The approach is described in section 3. The experi-
ments and analysis of achieved results are proposed
in section 4 . Conclusion and Future work are finally
in sections 5 and 6.
2 LITERATURE REVIEW
Lawgali (Lawgali, 2015) provided a survey on Arabic
handwritten automatic recognition. (Ghanim et al.,
2018) summarized the different applied classifiers in
this research area.
Hidden Marcov Model (HMM) was applied by
(Hicham et al., 2016), (AlKhateeb et al., 2011),
(Jayech et al., 2015) and (Dreuw et al., 2011) on
IFN/ENIT Arabic database (Pechwitz et al., 2002).
532
Ghanim, T., Khalil, M. and Abbas, H.
Multi-stage Off-line Arabic Handwriting Recognition Approach using Advanced Cascading Technique.
DOI: 10.5220/0007374605320539
In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2019), pages 532-539
ISBN: 978-989-758-351-3
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
Localized density features and statistical-type fea-
tures (Hicham et al., 2016) were extracted achieving
78.95% recognition rate. Intensity features on mir-
rored word image (MWI) (AlKhateeb et al., 2011)
were extracted and achieved 86.73% success rate
without re-ranking and 89.24% with re-ranking. Sta-
tistical and structural features (Jayech et al., 2015)
achieved 91.1% recognition rates. Multi-Stream
Hidden Markov Model was applied for handwriting
recognition (Mezghani et al., 2014) using Gaussian
Mixture Models (GMMs) to recognize Arabic and
French handwritten words.
Support Vectored Machines (SVMs) achieved ef-
fective results in this field when applied on the
IFN/ENIT database. (Elleuch et al., 2016) applied
convolution neural network (CNN) and SVM to clas-
sify only 56 classes with error rate 7.05%. (Al-
Dmour and Abuhelaleh, 2016) proposed a multi-stage
model using SURF feature descriptor and K-means
clustering algorithm to recognize 85% using SVM.
(Khaissidi et al., 2016) applied Histograms of Ori-
ented Gradients (HoGs) with SVM on Ibn-Sina data-
set (Moghaddam et al., 2010).
(Sa
¨
ıdani and Echi, 2014) extracted a combination
of Pyramid HOG and co-occurrence Matrix of HOG.
(Elfakir et al., 2015) extracted HOG features using
Sobel edge detectors. SVM was applied on the nor-
malized features for classification.
Different types of Neural Networks (NN) were
applied in this area. Pseudo-Zernike moments fea-
tures (Leila et al., 2011) with Fuzzy ARTMAP neu-
ral network classified 96 word classes written by hun-
dred writers with 93.8% recognition rate. (Lawgali
et al., 2014) extracted Discrete Cosine Transform
(DCT) features and applied Artificial Neural Net-
work to classify a subset of IFN/ENIT database with
90.73% accuracy. (Benjelil et al., 2012) used a steer-
able pyramid decomposition method with k-NN clas-
sifier and achieved 97.5% success rate on a database
of 800 printed and handwritten words.
Random forest (RF) was applied for handwriting
recognition. (Shamim et al., 2018) presented a com-
parative study for offline digit recognition and SVM
with RF classifier achieved highest results. (Do and
Pham, 2015) computed GIST features with RF on
USPS, MNIST data-sets. (Zamani et al., 2015) ap-
plied RF and convolutional neural network (CNN)
for Persian handwritten digit recognition. The sys-
tem was tested on Hoda data-set (Khosravi and Kabir,
2007). The concept of cascading classifiers was ap-
plied on different recognition problems and achieved
satisfactory results (Ghanem et al., 2009), (Mohamed
et al., 2018).
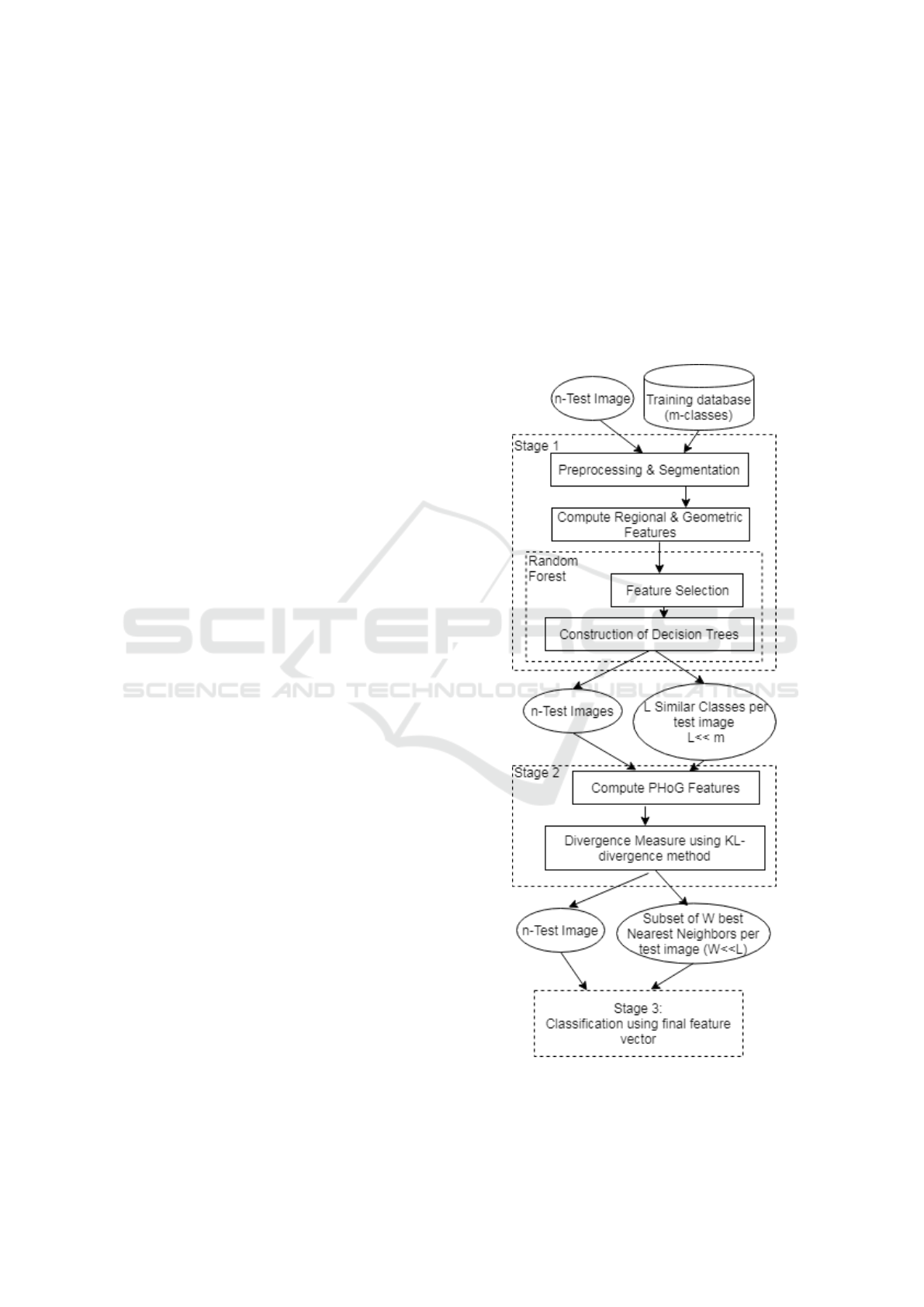
3 THE PROPOSED APPROACH
In the proposed approach three main consecutive
stages are applied as presented in Figure 1. All stages
are complementary to each other. The output of
each stage passes as an input to the next subsequent
stage. Each stage passes smaller set of chosen training
classes to its next consecutive stage. Reducing num-
ber of concerned database classes per stage eases the
classification task and equate classifier growing com-
plexity.
Figure 1: The proposed system overview.
Multi-stage Off-line Arabic Handwriting Recognition Approach using Advanced Cascading Technique
533
3.1 Stage 1: Matching Test Image with
Similar Database Training Classes
This stage match each test image with a set of sim-
ilar database classes. First, preprocessing and seg-
mentation are applied (section 3.1.1), a set of features
(Dileep, 2012) are then computed (section 3.1.2).
Random Forest classifier vote for the optimum set of
computed features and match each test image with a
set of database classes. Matching sets include similar
database classes together and is represented by a de-
fined range of selected feature values. This introduces
a data-mined database.
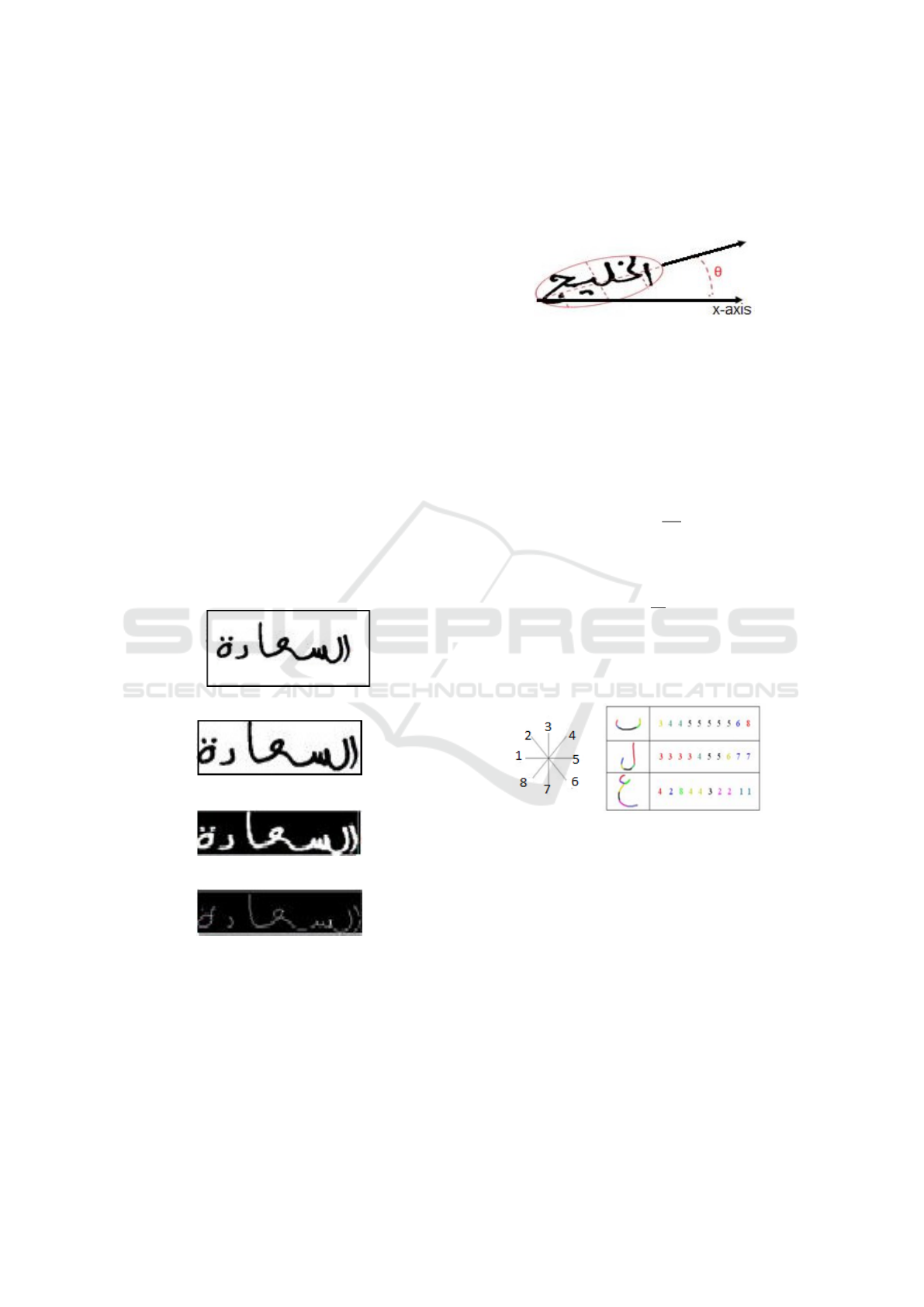
3.1.1 Preprocessing and Segmentation
The first stage starts by passing each test image and
training database classes through preprocessing and
segmentation as shown in Figure 1. It is an essential
stage for consistent post analysis and classification.
Images are binarized, cropped, normalized and
thinned to one pixel wide to remove variations in
handwritten images as shown in Figure 2. Binariza-
tion concentrates computations on regions of interest.
(a) original image
(b) cropped image
(c) image negative
(d) image thinning
Figure 2: A sample image during preprocessing.
3.1.2 Regional and Geometric Features
Extraction
A set of regional and geometry based features
(Dileep, 2012) are computed. Based on the applied
feature selection technique (section 3.1.3), Extent fea-
ture is an effective regional feature that represents the
normalized area of the skeleton. It is a scalar mea-
surement that specifies the ratio of handwritten word
area to area of the word imaginary bounding ellipse
as shown in Figure3.
Figure 3: Word Bounding Ellipse.
The geometric features; descriptors of image con-
tours, are computed after dividing image into six dif-
ferent zones (Dileep, 2012). Zoning considers the po-
sition of line segments as a feature and satisfy the con-
cept of feature localization. Eight features are com-
puted per zone. First four are the normalized number
ˆ
N of horizontal, vertical, left diagonal, right diagonal
lines, as defined in equation 1.
ˆ
N = 1 −
2N
10
(1)
The second four features are the normalized length
ˆ
L
of all line types as defined in equation 2.
ˆ
L =
L
A
z
(2)
where A
z
is the zone area. Line types are deter-
mined using the concavity features (Theodoridis and
Koutroumbas, 2006) as shown in Figure 4.
Figure 4: Concavity features.
3.1.3 Random Forest for Feature Selection and
Decision Trees Construction
Random Forest classifier perform feature selection to
choose most effective features from the computed set
of regional and geometric features. A forest of deci-
sion trees are then constructed to vote for a group of
similar classes corresponding to each test image.
Database classes are split into two branches at
each tree node. Splitting is based on features’ impor-
tance. Importance of features is estimated from their
impact on model accuracy. The measured importance
of the computed features is shown in Figure 5. The
x-axis is the feature, values from 1 till 5 are the com-
puted regional features including number of PAWs,
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
534

Figure 5: Feature Importance.
number of holes, eccentricity, extent and orientation
respectively , other values are the computed set of ge-
ometric features (Dileep, 2012). It is clearly shown
from Figure 5 that extent;feature 4, is the most rele-
vant regional features, while the whole set of geomet-
ric features are all important and affect performance
positively.
Finally, based on the measured features impor-
tance, the selected set of features includes extent and
the 8 geometric features. Based on the selected fea-
tures, Apriori pruning algorithm (Rokach and Mai-
mon, 2014) match each test sample with a set of sim-
ilar database classes; called item-sets.
It is a challenging aspect to mine item-sets from
large database (Han et al., 2011). If a long item-set is
frequent, then all its subsets are frequent as well. For
example, a k-item-set ( i.e. of length k items ) contains
total number of frequent item-sets defined by
k
1
+
k
2
+ ··· +
k
k
= 2
k
− 1 (3)
Each matching set include similar classes with
similar features. Different sets may include common
classes. Some smaller sets may be a subset of other
bigger sets which serve the matching process to be
implemented as a binary search tree. The test image
is now matched with a set of similar database classes
and both are ready for ranking stage.
3.2 Stage 2: Ranking Stage (PHoG &
KL-divergence)
Each test image and its matching set of similar classes
pass through stage 2. Kullback-Leibler divergence
(Ghanim et al., 2018) is computed between Pyra-
mid Histogram of Gradient features of input images
(Sa
¨
ıdani and Echi, 2014). Accordingly, the match-
ing classes are ranked from the nearest to the furthest
(Ghanim et al., 2018) relative to test image. The ob-
jective of this stage is to pass only subset of highly
ranked classes to classification stage as presented in
Figure 1.
3.2.1 Statistical Features Extraction: Pyramid
Histogram of Gradients PHoG
Histogram of oriented gradients HoGs is a statistical-
type descriptor that performs orientation analysis at
different levels (Ghanim et al., 2018). It captures fine
details and more discriminating information about
words skeletons than the ordinary HoGs (Sa
¨
ıdani and
Echi, 2014).
Oriented gradients are extracted per image zone as
shown in Figure 6 by Canny edge detector (Gonzalez
and Woods, 2007) as defined in equation 4.
θ = arctan
G
y
G
x
(4)
Gx and Gy are gradients in x and y direction, θ is ori-
entation [0,360
◦
] which are discretized to eight val-
ues (Saidani et al., 2015). PHoG features are com-
puted and normalized per image zone for the 8 de-
fined angular bins. KL-divergence is computed be-
tween feature vectors of test image and its matching
classes 3.2.2.
3.2.2 Divergence Measure: Kullback-Leibler
(KL)
KL divergence measure has been popularly used in
data-mining (Ghanim et al., 2018). It is a non-
symmetric measure of difference between any two
probability distributions; as PHoGs, for orientation
analysis. It is a non-symmetric metric measure. The
measure from one distribution q(x) to another p(x) is
not equal to the measure from q(x) to p(x). It is a
non-negative value that equals to zero if and only if
p(x) = q(x).
This measurement ranks the members of matching
set from the nearest to the furthest relative to the test
image. Classes of high ranks pass to final classifying
stage instead of passing all database.
3.3 Stage 3: Classification Stage
Finally each test image pass through classification
stage with only highly ranked best nearest neighbors
classes to vote for final membership class.
3.3.1 Final Feature Vector: Statistical &
Geometric Features Extraction
Final feature vector is a combination of the selected
features from stage 1 and the PHoG features from
stage 2. Final features vector is used to classify the
test image as described next section 3.3.2.
Multi-stage Off-line Arabic Handwriting Recognition Approach using Advanced Cascading Technique
535

(a) Level=1 (b) Level=2 (c) Level=3
Figure 6: Pyramid histogram of gradients (F:frequency, G:oriented gradient).(Ghanim et al., 2018)
3.3.2 Classification: Multi-class Support Vector
Machines
A bigger feature vector is now ready to train a multi-
class SVM. Only the highly ranked best matching ref-
erence classes are used in training SVM. The output
finally determines the test image membership training
class.
Many surveys (Kumar and Rao, 2013) demon-
strated effectiveness of SVM. There are two schemes
to convert SVM to series of binary SVM’s (Abdi-
ansah and Wardoyo, 2015), one-versus-rest and one-
versus-one. In the proposed solution, the one-versus-
one approach is applied. It is symmetric SVM model
and does not suffer from the unbalanced classification
problem.
4 EXPERIMENTS
4.1 Database
The approach is tested on IFN/ENIT database (Pech-
witz et al., 2002) of 937 distinct classes. Data-set is
composed of 5 parts named a, b, c, d and e.
4.2 Matching Set Selection
Matching sets vary in sizes. Sensitivity is measured
by degree of correct class inclusion in the matching
set. Random Forest for decision trees construction
enhanced sensitivity to be 93.5% instead of 86.5%
in (Ghanim et al., 2018). The weighted average
matching set size computed from equation 5 is ap-
proximately 172.6 different classes, which is approx-
imately 18% of the whole database number of classes.
¯x =
∑
n
i=1
(x
i
∗ w
i
)
∑
n
i=1
w
i
(5)
¯x is the weighted average, x is the set size and w is the
normalized weights of sets. Largest set contains 423
different classes (worst case) which is 44.7% of the
946 total database classes.
Figure 7 shows the effect of the different regional
and geometric features and Random forest (RF) on
the overall matching error. Figure 7a shows that num-
ber of holes, PAWs, eccentricity and word orientation
cause 21% misclassification error. Figure 7b shows
that Extent feature cause an exponential reduction in
misclassification error to be 9%. Including the ge-
ometric features to Extent feature reduce error from
9% to 6%, Figure 7c.
4.3 The Ranking Stage
The approach categorized database into three main
parts;labelled 30, 20 and 5, according to average ra-
tio between training and testing samples. Figure 8
shows that increasing PHoG level causes proceeding
of correct class in early ranks. This cause fast graph
saturation where high recognition rates are achieved.
Fastest saturation achieved with label 30 due to ex-
istence of enough training samples relative to testing
ones. This leads to passing as small sets of classes
as possible to final stage and so less training time as
shown in Figure 8b and 8c. The correct class rank
in worst case is 100 inside matching set. Accord-
ingly, only 10.5% of the total database classes passes
to classification stage.
4.4 The Classification Stage
The SVM is applied with different kernel’s type at
different levels of Pyramid Histogram of gradients as
shown in Figure 9.
Final classification is applied on highly ranked
classes. The Linear SVM with level 5 PHoG achieves
the highest recognition rate. Figure 9a shows SVM
output with Level 1 PHoG; original HOG. Figure 9b
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
536

(a) no. of holes, paws and eccentricity
and orientation.
(b) Effect of extent after excluding
no. of holes, PAWS, ecc, orientation.
(c) Effect of extent and geometric fea-
tures.
Figure 7: Effect of selected features on Classification Error, (N=number of decision trees), (ER% = error rate).
(a) Experiment on classes with label
30.
(b) Experiment on classes with label
20.
(c) Experiment on classes with label
5.
Figure 8: Effect of Ranking on the Expected Success Rate (Ghanim et al., 2018) (TPR: True positive rate), (R: rank of correct
class).
(a) Level 1 PHoG and Geometric fea-
tures with SVM.
(b) Level 3 PHoG and Geometric fea-
tures with SVM.
(c) Level 5 PHoG and Geometric fea-
tures with SVM.
Figure 9: System Recognition Rate.
is for level 3 PHoG. The linear kernel gives the best
results with all sets but the polynomial kernel was bet-
ter than quadratic. Figure 9c displays the system per-
formance on level 5 PHoG. The linear kernel with set
labeled “30” outperforms all the other experiments.
4.5 Comparative Experiments and
Results
Table 1 represents similar systems’ experiments and
their results relative to proposed approach. Some
classification systems applied word segmentation to
character level, while others didn’t. Segmentation
modify error rates by predicting the correct sequence
of word characters based on pre-defined dictionary
but increase computation complexity. The proposed
approach is applied without segmentation and consid-
ered absence of pre-defined dictionary. The results in
table 1 indicate the distinction of the proposed solu-
tion results than others.
4.6 Reasons of Misclassification
Visual similarity between different classes is one of
the main reasons of misclassification as shown in ta-
ble 2.
Multi-stage Off-line Arabic Handwriting Recognition Approach using Advanced Cascading Technique
537

Table 1: Comparative results of systems applied on IFN-ENIT.
Approach reference Training-testing Approach Segmentation Word error rate
(Abandah et al., 2014) abcd-e BLSTM-RNN without 24.28%
(Lawgali et al., 2014) abcd-e DCT-NN with 14.64%
(Jayech et al., 2015) abc-d MSHMM with 8.95%
without 16.9%
abcd-e without 27.6%
with 17.09%
(Hicham et al., 2016) abcd-e denstity-HMM with 21.05%
(Elleuch et al., 2016) 56 classes Conv-CNN SVM with 7%
(Al-Dmour and Abuhelaleh, 2016) 18 classes Surf-SVM without 15%
Proposed approach abc-d RF-PHOG-KL-SVM Without 3.6%
abcd-e Without 14.6%
Table 2: Sample of visual similarity between classes.
Class name Similar Class name
Ñm
.
Ì
'@ Õæ
k
.
@
ú
G@ñË@ ú
æ@ñË@
èP@Q
«ñK
.
èX@Q«ñK
.
(a) Misclassification due to bad handwriting styles
(b) Misclassification due to inaccurate thinning results
Figure 10: Samples of Misclassified Images.
Bad handwriting styles and inaccurate thinning
also mislead the system as shown in Figure 10a and
10b. Misclassification is sometimes due to lack of
training samples of some classes.
5 CONCLUSIONS
The proposed approach is a cascaded classifier for of-
fline Arabic handwritten recognition. It is applied on
IFN/ENIT database. Random Forest improved per-
formance of decision trees. High levels of PHoG in-
crease effectiveness of ranking stage.
6 FUTURE WORK
Future plan is to apply deep learning techniques to
improve classification rates and matching process to
build more robust recognition systems.
REFERENCES
Abandah, G. A., Jamour, F. T., and Qaralleh, E. A.
(2014). Recognizing handwritten Arabic words us-
ing grapheme segmentation and recurrent neural net-
works. International Journal on Document Analysis
and Recognition (IJDAR), 17(3):275–291.
Abandah, G. A. and Khedher, M. Z. (2009). Analysis of
handwritten Arabic letters using selected feature ex-
traction techniques. International Journal of Com-
puter Processing of Languages, 22(01):49–73.
AbdelRaouf, A., Higgins, C. A., and Khalil, M. (2008). A
database for Arabic printed character recognition. In
International Conference Image Analysis and Recog-
nition, pages 567–578. Springer.
Abdiansah, A. and Wardoyo, R. (2015). Time complex-
ity analysis of support vector machines (SVM) in lib-
svm. International Journal Computer and Applica-
tion, 128(3).
Al-Dmour, A. and Abuhelaleh, M. (2016). Arabic hand-
written word category classification using bag of fea-
tures. Journal of Theoretical and Applied Information
Technology, 89(2):320.
AlKhateeb, J. H., Ren, J., Jiang, J., and Al-Muhtaseb, H.
(2011). Offline handwritten Arabic cursive text recog-
nition using hidden markov models and re-ranking.
Pattern Recognition Letters, 32(8):1081–1088.
Amin, A. (1998). Off-line Arabic character recognition: the
state of the art. Pattern recognition, 31(5):517–530.
Benjelil, M., Mullot, R., and Alimi, A. M. (2012). Lan-
guage and script identification based on steerable
pyramid features. In Frontiers in Handwriting Recog-
nition (ICFHR), pages 716–721. IEEE.
Campbell, L. and Grondona, V. (2008). Ethnologue: Lan-
guages of the world. Language, 84(3):636–641.
Dileep, D. (2012). A feature extraction technique based on
character geometry for character recognition. Depart-
ment of Electronics and Communication Engineering,
Amrita School of Engineering, Kollam, India.
Do, T.-N. and Pham, N.-K. (2015). Handwritten digit recog-
nition using gist descriptors and random oblique deci-
sion trees. In Some Current Advanced Researches on
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
538

Information and Computer Science in Vietnam, pages
1–15. Springer.
Dreuw, P., Heigold, G., and Ney, H. (2011). Confidence-and
margin-based MMI/MPE discriminative training for
off-line handwriting recognition. International jour-
nal on document analysis and recognition, 14(3):273–
288.
Elfakir, Y., Khaissidi, G., Mrabti, M., and Chenouni, D.
(2015). Handwritten Arabic documents indexation us-
ing HOG feature. International Journal of Computer
Applications, 126(9).
Elleuch, M., Maalej, R., and Kherallah, M. (2016). A new
design based-SVM of the CNN classifier architecture
with dropout for offline Arabic handwritten recogni-
tion. Procedia Computer Science, 80:1712–1723.
Ghanem, T. M., Moustafa, M. N., and Shahein, H. I. (2009).
Gabor wavelet based automatic coin classsification. In
2009 16th IEEE International Conference on Image
Processing (ICIP), pages 305–308. IEEE.
Ghanim, T. M., Khalil, M. I., and Abbas, H. M. (2018).
Phog features and kullback-leibler divergence based
ranking method for handwriting recognition. In IAPR
Workshop on Artificial Neural Networks in Pattern
Recognition, pages 293–305. Springer.
Gonzalez, R. C. and Woods, R. E. (2007). Digital image
processing. Pearson.
Han, J., Pei, J., and Kamber, M. (2011). Data mining: con-
cepts and techniques. Elsevier.
Hicham, E. M., Akram, H., and Khalid, S. (2016). Using
features of local densities, statistics and HMM toolkit
(htk) for offline Arabic handwriting text recognition.
Journal of Electrical Systems and Information Tech-
nology, 3(3):99–110.
Jayech, K., Mahjoub, M. A., and Amara, N. E. B. (2015).
Arabic handwriting recognition based on synchronous
multi-stream HMM without explicit segmentation.
In International Conference on Hybrid Artificial In-
telligence Systems, volume 9121, pages 136–145.
Springer.
Khaissidi, G., Elfakir, Y., Mrabti, M., Lakhliai, Z., Che-
nouni, D., and El yacoubi, M. (2016). Segmentation-
free word spotting for handwritten Arabic documents.
International Journal of Interactive Multimedia and
Artificial Intelligence, 4.
Khosravi, H. and Kabir, E. (2007). Introducing a very large
dataset of handwritten farsi digits and a study on their
varieties. Pattern recognition letters, 28(10):1133–
1141.
Kumar, K. V. and Rao, R. R. (2013). Online handwritten
character recognition for telugu language using sup-
port vector machines. International Journal of Engi-
neering and Advanced Technology (IJEAT), 3.
Lawgali, A. (2015). A survey on Arabic character recog-
nition. International Journal of Signal Processing,
Image Processing and Pattern Recognition, 8(2):401–
426.
Lawgali, A., Angelova, M., and Bouridane, A. (2014). A
framework for Arabic handwritten recognition based
on segmentation. International Journal of Hybrid In-
formation Technology, 7(5):413–428.
Leila, C., Ma
ˆ
amar, K., and Salim, C. (2011). Combining
neural networks for Arabic handwriting recognition.
In Programming and Systems (ISPS), 2011 10th Inter-
national Symposium on, pages 74–79. IEEE.
Mezghani, A., Slimane, F., Kanoun, S., and M
¨
argner,
V. (2014). Identification of Arabic/French hand-
written/printed words using gmm-based system. In
CORIA-CIFED, pages 371–374.
Moghaddam, R. F., Cheriet, M., M. Adankon, M., Filo-
nenko, K., and Wisnovsky, R. (2010). Ibn sina: a
database for research on processing and understand-
ing of Arabic manuscripts images. Proceeding DAS
’10 Proceedings of the 9th IAPR International Work-
shop on Document Analysis Systems, pages 11–18.
Mohamed, H., Omar, R., Saeed, N., Essam, A., Ayman, N.,
Mohiy, T., and AbdelRaouf, A. (2018). Automated de-
tection of white blood cells cancer diseases. In Deep
and Representation Learning (IWDRL), 2018 First In-
ternational Workshop on, pages 48–54. IEEE.
Pechwitz, M., Maddouri, S. S., M
¨
argner, V., Ellouze, N.,
Amiri, H., et al. (2002). IFN/ENIT-database of hand-
written Arabic words. In Proc. of CIFED, volume 2,
pages 127–136.
Rokach, L. and Maimon, O. (2014). Data mining with deci-
sion trees: theory and applications. World scientific.
Sa
¨
ıdani, A. and Echi, A. K. (2014). Pyramid histogram
of oriented gradient for machine-printed/handwritten
and Arabic/Latin word discrimination. In Soft Com-
puting and Pattern Recognition (SoCPaR), 2014 6th
International Conference of, pages 267–272. IEEE.
Saidani, A., Kacem, A., and Belaid, A. (2015). Arabic/Latin
and machine-printed/handwritten word discrimination
using HOG-based shape descriptor. ELCVIA Elec-
tronic Letters on Computer Vision and Image Anal-
ysis, 14(2):1–23.
Shamim, S., Miah, M. B. A., Sarker, A., Rana, M., and
Al Jobair, A. (2018). Handwritten digit recognition
using machine learning algorithms. Global Journal of
Computer Science and Technology.
Theodoridis, S. and Koutroumbas, K. (2006). Pattern
Recognition. Academic Press.
Zamani, Y., Souri, Y., Rashidi, H., and Kasaei, S. (2015).
Persian handwritten digit recognition by random for-
est and convolutional neural networks. In Machine Vi-
sion and Image Processing (MVIP), 2015 9th Iranian
Conference on, pages 37–40. IEEE.
Multi-stage Off-line Arabic Handwriting Recognition Approach using Advanced Cascading Technique
539
