
Automatic Information Extraction from Piping and Instrumentation
Diagrams
Rohit Rahul, Shubham Paliwal, Monika Sharma and Lovekesh Vig
TCS Research, New Delhi, India
Keywords:
P&ID Sheets, Symbol Classification, Pipeline Code Extraction, Fully Convolutional Network, Tree-structure.
Abstract:
One of the most common modes of representing engineering schematics are Piping and Instrumentation dia-
grams (P&IDs) that describe the layout of an engineering process flow along with the interconnected process
equipment. Over the years, P&ID diagrams have been manually generated, scanned and stored as image files.
These files need to be digitized for purposes of inventory management and updation, and easy reference to
different components of the schematics. There are several challenging vision problems associated with digi-
tizing real world P&ID diagrams. Real world P&IDs come in several different resolutions, and often contain
noisy textual information. Extraction of instrumentation information from these diagrams involves accurate
detection of symbols that frequently have minute visual differences between them. Identification of pipelines
that may converge and diverge at different points in the image is a further cause for concern. Due to these
reasons, to the best of our knowledge, no system has been proposed for end-to-end data extraction from P&ID
diagrams. However, with the advent of deep learning and the spectacular successes it has achieved in vision,
we hypothesized that it is now possible to re-examine this problem armed with the latest deep learning models.
To that end, we present a novel pipeline for information extraction from P&ID sheets via a combination of
traditional vision techniques and state-of-the-art deep learning models to identify and isolate pipeline codes,
pipelines, inlets and outlets, and for detecting symbols. This is followed by association of the detected com-
ponents with the appropriate pipeline. The extracted pipeline information is used to populate a tree-like data
structure for capturing the structure of the piping schematics. We have also evaluated our proposed method on
a real world dataset of P&ID sheets obtained from an oil firm and have obtained extremely promising results.
To the best of our knowledge, this is the first system that performs end-to-end data extraction from P&ID
diagrams.
1 INTRODUCTION
A standardized representation for depicting the equip-
ment and process flow involved in a physical process
is via Piping and Instrumentation diagrams (P&ID).
P&ID diagrams are able to represent complex en-
gineering workflows depicting schematics of a pro-
cess flow through pipelines, vessels, actuators and
control valves. A generic representation includes
fluid input points, paths as pipelines, symbols which
represent control and measurement instruments and,
sink points. Most industries maintain these complex
P&IDs in the form of hard-copies or scanned images
and do not have any automated mechanism for in-
formation extraction and analysis of P&IDs (Arroyo
et al., 2014). Consequently, future analysis and au-
dit for process improvement involves manual involve-
ment which is expensive given the domain expertise
required. It would be of great value if the data present
in P&ID sheets could be automatically extracted and
provide answers to important queries related to the
connectivity of plant components, types of intercon-
nections between process equipments and the exis-
tence of redundant paths automatically. This would
enable process experts to obtain the information in-
stantly and reduce the time required for data retrieval.
Given the variations in resolution, text fonts, low
inter-class variation and the inherent noise in these
documents, this problem has previously been consid-
ered too difficult to address with standard vision tech-
niques. However, deep learning has recently shown
incredible results in several key vision tasks like seg-
mentation, classification and generation of images.
The aim of this paper is to leverage the latest work in
deep learning to address this very challenging prob-
lem, and hopefully improve the state-of-the-art for in-
formation extraction from these P&ID diagrams.
Rahul, R., Paliwal, S., Sharma, M. and Vig, L.
Automatic Information Extraction from Piping and Instr umentation Diagrams.
DOI: 10.5220/0007376401630172
In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2019), pages 163-172
ISBN: 978-989-758-351-3
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
163
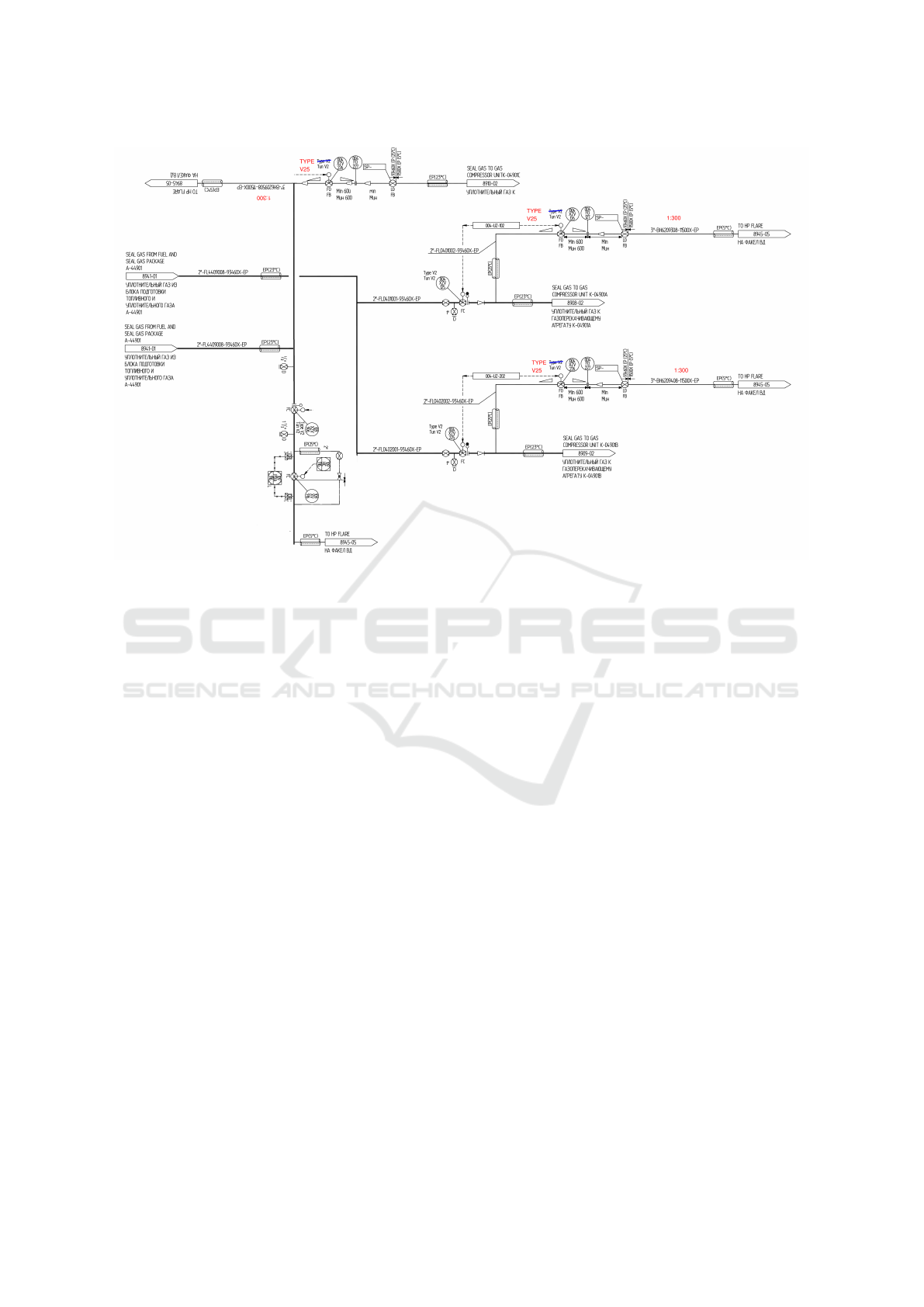
Figure 1: An Example of Piping and Instrumentation Diagram sheet.
The digitization process of P&IDs involves identi-
fication and localization of pipeline codes, pipelines,
inlets, outlets and symbols which is followed by map-
ping of individual components with the pipelines. Al-
though tools for the digitization of engineering draw-
ings in industries are in high demand, this problem
has received relatively little attention in the research
community. Relatively few attempts have been made
in the past to address digitization of complex engi-
neering documents comprising of both textual and
graphical elements, for example: complex receipts,
inspection sheets, and engineering diagrams (Verma
et al., 2016), (Wang et al., 2009), (Arroyo et al.,
2014), (Gupta et al., 2017), (Adam et al., 2000).
We have found that connected component analy-
sis (Koo and Kim, 2013) is heavily employed for
text-segmentation for such documents (Verma et al.,
2016). However, the recently invented Connectionist
Text Proposal Networks (CTPN) (Tian et al., 2016)
have demonstrated the capability to detect text in ex-
tremely noisy scenarios. We utilize a pre-trained
CTPN network to accurately detect the text patches
in a P&ID image. In the literature, symbol detec-
tion is performed by using shape based matching
techniques (Belongie et al., 2002), auto associative
neural networks (Gellaboina and Venkoparao, 2009),
graph based techniques (Yu, 1995). However, detect-
ing symbols in P&ID sheets is quite challenging be-
cause of the low inter-class variation among different
symbols and the presence of text and numbers inside
symbols. To alleviate this issue, we succesfully em-
ploy Fully Convolutional Networks (FCN) which are
trained to segment out the individual symbols.
Thus, our proposed pipeline for information ex-
traction from P&ID sheets uses a combination of
state-of-the-art deep learning models for text and
symbol identification, in combination with low level
image processing techniques for the extraction of dif-
ferent components like inlets, outlets and pipelines
present in the sheets. Moreover, given the paucity of
sufficient real datasets for this domain, automating the
process of information extraction from P&ID sheets
is often harder than in other domains and significant
data augmentation is required to train deep models.
We evaluate the efficacy of our proposed method on
4 sheets of P&IDs, each containing multiple flow di-
agrams, as shown in Figure 1.
To summarize, we have formulated the digiti-
zation process of P&IDs as a combination of (1)
heuristic rule based methods for accurate identifica-
tion of pipelines, and for determining the complete
flow structure and (2) deep learning based models for
identification of text and symbols and (3) rule based
association of detected objects and a tree based rep-
resentation of process flow followed by pruning for
determining correct inlet to outlet path. While formu-
lating the digitization process of P&IDs, we make the
following contributions in this paper:
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
164
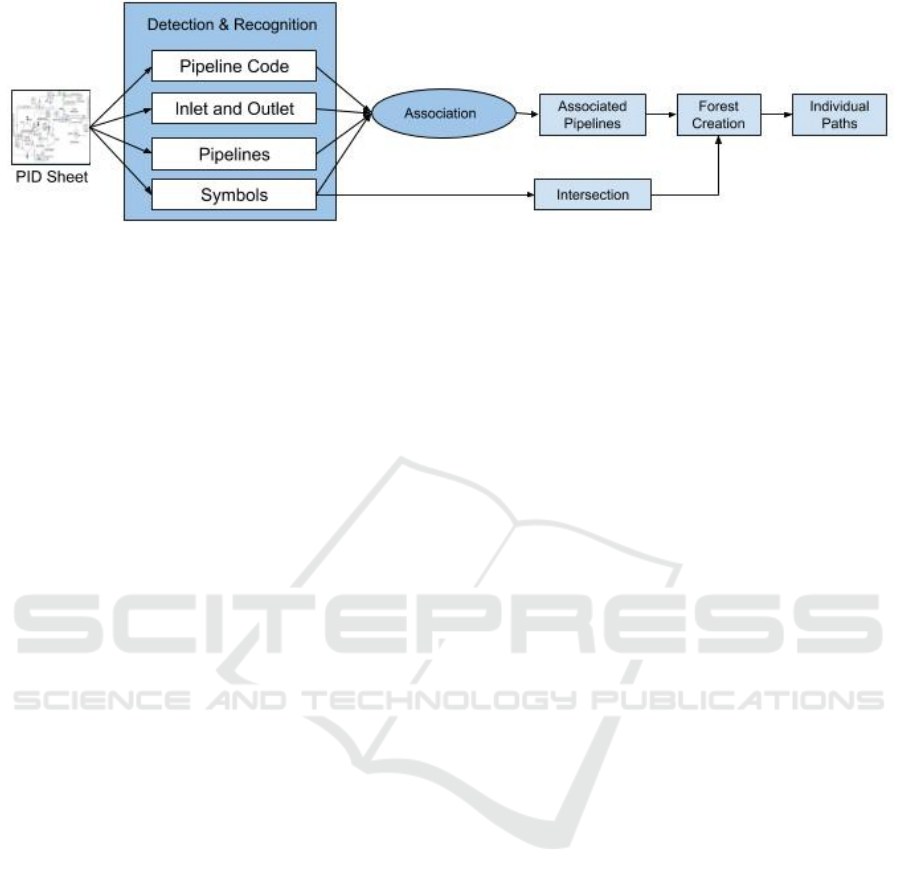
Figure 2: Flowchart showing proposed 2-step process for digitization of Piping and Instrumentation Diagrams. First, P&ID
sheet is fed to a detection and recognition engine which identifies and isolates different components of the process flow like
pipelines, pipeline codes, inlets, outlets and symbols using a combination of traditional vision techniues and deep learning
models. Subsequently, the extracted components are sent to an association module for mapping with the appropriate pipeline.
Finally, a tree-like data structure is created to determine the flow from inlet to outlet.
• We propose a novel pipeline consisting of a
two-step process for information extraction from
P&ID diagrams, comprising of a combination of
detection of different components of the process
flow followed by their association with appropri-
ate pipeline and representation in a tree-like data
structure to determine the flow from inlet to outlet.
• We propose the use of conventional image pro-
cessing and vision techniques to detect and rec-
ognize graphic objects (e.g. pipelines, inlets and
outlets) present in P&ID.
• We use a fully convolutional neural network
(FCN) based segmentation for detection of sym-
bols in P&ID sheets at the pixel level because of
very minute visual difference in appearance of dif-
ferent symbols, as the presence of noisy and tex-
tual information inside symbols makes it difficult
to classify based on bounding box detection net-
works like Faster-RCNN (Ren et al., 2015).
• We evaluate our proposed pipeline on a dataset of
real P&ID sheets from an oil firm and present our
results in Section 5.
The remainder of the paper is organized as fol-
lows: Section 2 gives an overview of related work in
the field of information extraction from visual docu-
ments. An overview of the proposed pipeline for auto-
matic extraction of information from P&ID is given in
Section 3. Section 4 describes in detail the proposed
methodology for extracting different P&ID compo-
nents like pipeline code, pipelines and symbols etc.
and their mapping. Subsequently, Section 5 gives de-
tails about the dataset, experiments and a discussion
on the obtained results. Finally, we conclude the pa-
per in Section 6.
2 RELATED WORK
There exists very limited work on digitizing the con-
tent of engineering diagrams to facilitate fast and ef-
ficient extraction of information. The authors (Goh
et al., 2013) automated the assessment of AutoCAD
Drawing Exchange Format (DXF) by converting DXF
file into SVG format and developing a marking algo-
rithm of the generated SVG files. A framework for
engineering drawings recognition using a case-based
approach is proposed by (Yan and Wenyin, 2003)
where the user interactively provides an example of
one type of graphic object in an engineering drawing
and then system tries to learn the graphical knowl-
edge of this type of graphic object from the exam-
ple and later use this learned knowledge to recognize
or search for similar graphic objects in engineering
drawings. Authors of (Arroyo et al., 2015) tried to
automate the extraction of structural and connectiv-
ity information from vector-graphics-coded engineer-
ing documents. A spatial relation graph (SRG) and its
partial matching method are proposed for online com-
posite graphics representation and recognition in (Xi-
aogang et al., 2004). Overall, we observed that there
does not exist much work on information extraction
from plant engineering diagrams.
However, we discovered a significant body of
work on recognition of symbols in prior art. (Adam
et al., 2000) proposed Fourier Mellin Transform fea-
tures to classify multi-oriented and multi-scaled pat-
terns in engineering diagrams. Other models utilized
for symbol recognition include Auto Associative neu-
ral networks (Gellaboina and Venkoparao, 2009),
Deep Belief networks (Fu and Kara, 2011), and con-
sistent attributed graphs (CAG) (Yu, 1995). There are
also models that use a set of visual features which cap-
ture online stroke properties like orientation and end-
point location (Ouyang and Davis, 2009), and shape
Automatic Information Extraction from Piping and Instrumentation Diagrams
165

based matching between different symbols (Belongie
et al., 2002). We see that most of the prior work fo-
cuses on extracting symbols from such engineering
diagrams or flow charts. To the best of our knowl-
edge, there exists no work which has proposed an end-
to-end pipeline for automating the information extrac-
tion from plant engineering diagrams such as P&ID.
In literature, Connected Component (CC) analy-
sis (Koo and Kim, 2013) has been used extensively
for extracting characters (Gupta et al., 2017) from im-
ages. However, connected components are extremely
sensitive to noise and thresholding may not be suit-
able for P&ID text extraction. Hence, we utilize
the recently invented Connectionist Temporal Pro-
posal Network (CTPN) (Tian et al., 2016) to detect
text in the image with impressive accuracy. For line
detection, we utilize Probabilistic hough transform
(PHT) (Kiryati et al., 1991) which is computationally
efficient and fast version of the standard hough trans-
form as it uses random sampling of edge points to
find lines present in the image. We make use of PHT
for determining all the lines present in P&ID sheets
which are possible candidates for pipelines. In our
paper, we propose the use of Fully convolutional neu-
ral network (FCN) based segmentation (Shelhamer
et al., 2016) for detecting symbols because trandi-
tional classification networks were unable to differ-
entiate among different types of symbols due to very
minute inter-class differences in visual appearances
and presence of noisy and textual information present
inside symbols. FCN incorporates contextual as well
as spatial relationship of symbols in the image, which
is often necessary for accurate detection and classifi-
cation of P&ID symbols.
3 OVERVIEW
The main objective of the paper is to extract
the information from the P&ID sheets representing
schematic process flow through various components
like pipelines, valves, actuators etc. The information
is extracted from P&ID and stored in a data struc-
ture that can be used for querying. The P&ID dia-
gram shown in Figure 1 depicts the flow of oil through
pipelines from inlet to outlet, where outlets and in-
lets denote the point of entry and exit of the oil, re-
spectively. Each outlet is unique and may connect to
multiple inlets, forming a one-to-many relationship.
The symbols indicate the machine parts present on
the pipeline to control the flow and to filter the oil in a
specific way. The pipelines are identified by a unique
P&ID code which is written on top of every pipeline.
To capture all the information from the P&ID
sheets, we propose a two-step process as follows :
• In the first step, we identify all the individual com-
ponents like pipelines, pipeline codes, symbols,
inlets and outlets. We use conventional image
processing and vision techniques like connected
component analysis (Koo and Kim, 2013), proba-
bilistic hough transform (Kiryati et al., 1991), ge-
ometrical properties of components etc. to local-
ize and isolate pipelines, pipeline codes, inlets and
outlets. Symbol detection is carried out by using
fully convolutional neural network based segmen-
tation (Shelhamer et al., 2016) as symbols have
very minute inter class variations in visual appear-
ances. Text detection is performed via a Connec-
tionist Text Proposal Network (CTPN), and the
recognition is performed via the tesseract OCR li-
brary.
• In the second step, we associate these components
with each other and finally capture the flow of
oil through pipelines by forming a tree-like data
structure. The tree is able to represent one-to-
many relationship where each outlet acts as root
node and each inlet is treated as a leaf node. The
pipelines represent intermediate nodes present in
the tree.
4 PROPOSED METHODOLOGY
In this section, we discuss the proposed methodolody
for extracting information from P&ID sheets in de-
tail. It is a two-step process as shown in Figure 2
in which the first step involves detection and recog-
nition of individual components like pipeline-codes,
symbols, pipelines, inletss and outlet. The second
step involves association of detected components with
the appropriate pipelines followed by formulation of
tree-like data structure for finding the process flow of
pipeline schematics. These steps are detailed as fol-
lows :
4.1 Detection and Recognition
We use vision techniques for extracting different com-
ponents like pipeline-codes, symbols, pipelines, inlets
and outlets present in P&IDs. We divide these com-
ponents into two-types : 1. text containing pipeline-
codes and 2. graphic objects like pipelines, symbols.
As observed from Figure 1, P&ID sheets have text
present which represents pipeline code, side notes,
sometimes as part of a symbol or container / symbol /
tag numbers, we call these text segments as pipeline-
code. The non-text components like pipelines, sym-
bols, inlets and outlets are termed as graphic objects.
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
166
Now, we discuss the detection and recognition meth-
ods for different components as follows :
• Detection of Pipeline Code: The pipeline code
distinctly characterizes each pipeline. Hence, we
first identify the pipeline code. While previous
approaches utilized thresholding followed by
connected components in order to extract the
codes, we utilize a CTPN (Tian et al., 2016)
network pre-trained on a scene-text dataset for
pipeline-code detection, as it was far more robust
to noise / color in the document. CTPN is a
convolutional network which accepts arbitrarily
sized images and detects a text line in an image
by densely sliding a window in the convolutional
feature maps and produces a sequence of text
proposals. This sequence is then passed through
a recurrent neural network which allows the
detector to explore meaningful context informa-
tion of text line and hence, makes it powerful to
detect extremely challenging text reliably. The
CTPN gives us all possible candidate components
for pipeline code with 100 % recall but with
significant number of false positives which are
filtered out in a later step. Subsequently, we
use tesseract (Smith, 2007) for reading each
component detected in the previous step. Since,
pipeline codes have fixed length and structure, we
filter out false positives using regular expressions.
For example, the pipeline code is of the format
N”-AANNNNNNN-NNNNNA-AA where N
denotes a Digit and A denotes an alphabet. This
domain knowledge gives us all the pipeline codes
present in the P&ID sheets.
• Detection of Inlet and Outlet: The inlet or outlet
marks the starting or ending point of the pipeline.
There is a standard symbol representing inlet or
outlet. It is a polygon having 5 vertices and the
width of the bounding box is at least thrice its
height. We use this shape property of the symbol
to detect inlet / outlet robustly using heuristics.
For detection of the inlets and outlets, we subtract
the text blobs detected as pipeline codes from
a binarized input image for further processing.
Then, we use Ramer-Douglas algorithm (Fei and
He, 2009) in combination with known relative
edge lengths to identify the polygons. After
detecting each polygon, we find out whether it
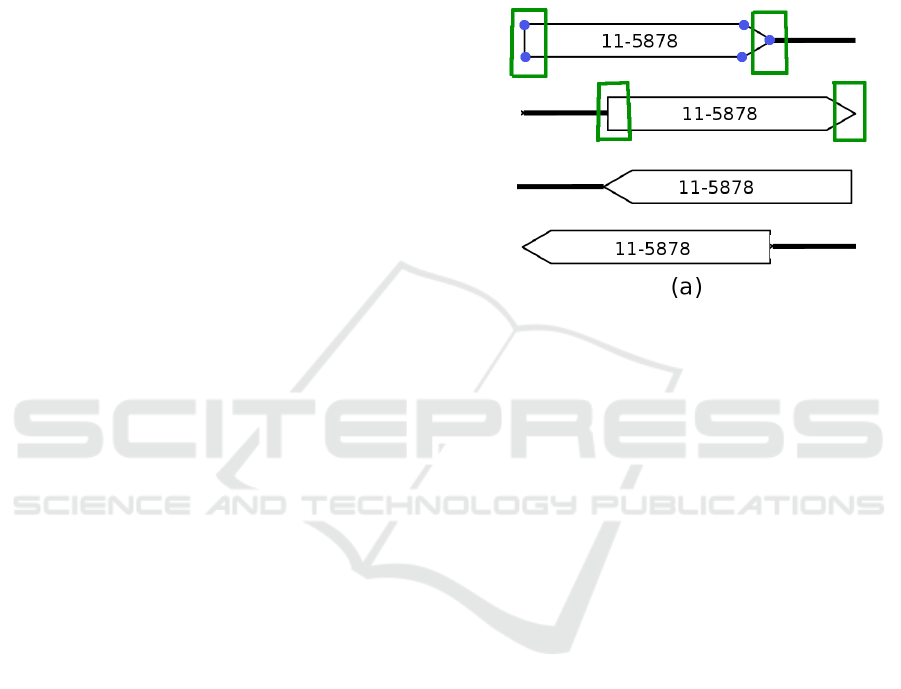
is an inlet or an outlet. As can be seen from
Figure 1, there are 4 possible cases of polygons
because there are two types of tags present in
P&ID : left-pointing and right-pointing. Each of
the right-pointing or left-pointing tag can either
be an inlet or an outlet. We find the orientation
of tags from the points given by Ramer-Douglas
knowing the fact that there will be 3 points on one
side and two on another side in a right-pointing
or left-pointing tag, as shown in Figure 3. To
further classify whether the candidate is an
inlet or outlet among them, we take a small
kernel K on either side of the component image
and find out which edge is crossed by a single line.
Figure 3: Figure showing inlets and outlets of P&ID dia-
grams.
• Detection of Pipeline: We remove the detected
text and inlet / outlet tags from the image for
detecting pipelines. We then use probabilistic
hough transform (Kiryati et al., 1991) on the
skeleton (Saha et al., 2016) version of the image
which outputs a set of all lines including lines
that do not correspond to pipelines.
• Detection of Pipeline Intersections: The output
of the hough lines is a set of lines which does
not take into account the gap at the intersections,
as shown in Figure 4. There can be two kinds
of intersections : a valid intersection or an
invalid intersection. We aim to find all the valid
intersections. This is achieved by determining all
the intersections between any two line segments
by solving the system of linear equations. The
solution to the equations is a point which should
lie on both finite pipelines. This assumption en-
sures that the solution is a part of foreground. An
invalid intersection is the intersection where the
solution of the two linear equations for the line
has given us an intersection but there exists no
such intersection in the image. This is indicated
by the gap in one of the lines involved in the
intersection, as shown in Figure 4. To discard
invalid intersections, we draw a square kernel
of size 21 with the center at the intersection and
check for lines intersecting with the edges of the
square. Here, we have two possibilities : (1)
Automatic Information Extraction from Piping and Instrumentation Diagrams
167

Figure 4: Figure showing pipelines in P&ID sheets.
where the intersections are on the opposite edges
of the square and no intersection on other two
edges of the square. This means that there is
no intersection and there is just one line which
passes through the intersection. (2) where there
can be intersection on three or all four edges of
the square. This is the case of valid intersection
between the pipelines. Thus we obtain the
pipeline intersections and store them for use later
to create of a tree-like data structure for capturing
the structure of pipeline schematics.
• Detection of Symbols: There are various types of
symbols present in the P&ID sheets which repre-
sent certain instruments responsible for controling
the flow of oil through pipelines and performing
various tasks. In our case, we have 10 classes
of symbols to detect and localise in the sheets,
e.g. ball valve, check valve, chemical seal,
circle valve, concentric, flood connection,
globe valve, gate valve nc, insulation and
globe valve nc. As can be seen in Figure 6, these
symbols have very low inter-class difference in
visual appearances. So, standard deep networks
for classification are not able to distinguish them
correctly. Therefore, we propose to use fully
convolutional neural network (FCN) (Shelhamer
et al., 2016) for detecting symbols. FCNs, as
shown in Figure 5, are convolutional networks
where the last fully connected layer is replaced by
a convolution layer with large receptive field. The
intuition behind using segmentation is that FCN
network has two parts : one is downsampling
path which is composed of convolutions, max
pooling operations and extracts the contextual in-
formation from the image, second is upsampling
path which consists of transposed convolutions,
unpooling operations to produce the output with
size similar to input image size and learns the
Figure 5: Fully convolutional segmentation network taken
from (Shelhamer et al., 2016).
precise spatial location of the objects in the image.
Data Annotation for FCN: For detecting sym-
bols using FCN, we annotated a dataset of real
world P&IDs diagrams from an oil firm. The
original P&ID sheets are of very large size, so we
divided it into smaller patches of size 400 × 400
for annotating the symbols. These patches
contain different classes of symbols and can have
multiple symbols present in a single patch. The
symbols were annotated by masking their pixel
values completely and subsequently, obtaining
the boundaries of the symbol masks representing
the shape of the symbol. To automate this process
of extracting outlines of symbol masks, a filter
was applied for the region containing the masked
shape, i.e, bitwise-and operation was used. This
was followed by thresholding the patches to get
the boundaries / outlines only and then it was
dilated with a filter of size 3 × 3. As the training
dataset was limited, we augmented the images by
performing some transformations on the image
like translation and rotation.
Training Details: We use VGG-19 (Simonyan
and Zisserman, 2014) based FCN for training
symbol detector. An input image of size 400 ×
400 is fed to the network and it is trained using
Adam optimizer with a learning rate of 0.0004 and
batch size of 8.
4.2 Association and Structuring
At this stage, we have detected all the necessary com-
ponents of the P&ID diagrams. Next step is to as-
sociate these components with each other and form a
structure of the pipeline schematics. This is done as
follows :
• Tags to Pipeline Association: We find the line
emerging direction from the orientation of inlet
and outlet. We associate the closest pipeline from
the line emerging point in the direction of pipeline
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
168
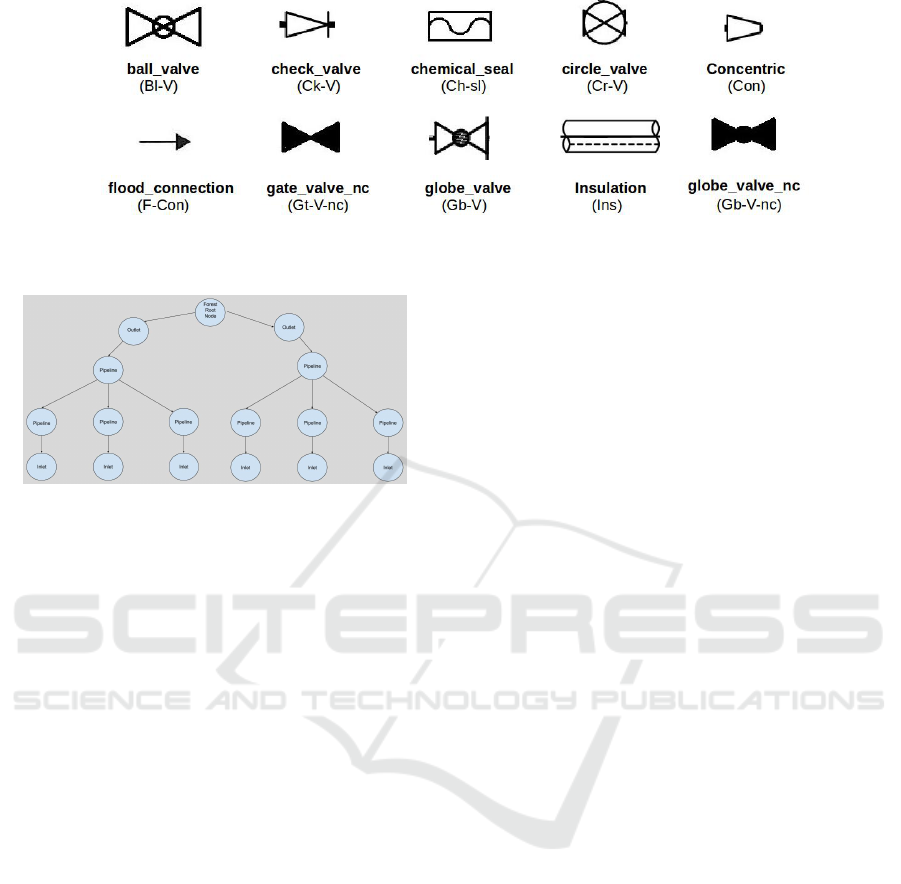
Figure 6: Different classes of symbols present in P&ID sheets.
Figure 7: An example of tree-like data structure creation for
capturing the process flow of pipeline schematics of P&ID.
to the tag. The closest pipeline is determined
based upon euclidean distance.
• Pipeline Code to Pipeline Association: Simi-
larly, we assign the pipeline codes to the near-
est pipeline based on the minimum euclidean dis-
tance from any vertex of the bounding box of
nearest to the nearest point on the line.
• Symbols to Pipeline Association: Subsequently,
every detected symbol will be associated to clos-
est pipeline using minimum euclidean distance,
provided it is not separated from the pipeline.
Following this, we represent the structure of
P&ID diagrams in the form of a forest, as shown in
Figure 7. Each outlet is treated as the root node of a
specific tree in the forest and inlets are treated as leaf
nodes. This means that all the lines are intermediate
nodes. Each tree has minimum height of 2, root node
has single child. Trees can have common nodes i.e.,
it can have common pipelines and inlet tags, but a
root node is unique in the forest. At any time, a single
flow path is represented by unique path between
outlet and inlet.
Tree Pruning: The Pruning of tree is required to re-
move the false detections of pipelines by hough lines
transform algorithm. A false positive pipeline is one
which is represented in tree as a leaf node and does
not link to any of the inlets. Therefore, we prune the
tree by starting from the root node and removing all
the nodes that do not lead to any inlet.
5 EXPERIMENTAL RESULTS
AND DISCUSSIONS
In this section, we evaluate the performance of our
proposed end-to-end pipeline for extracting informa-
tion from P&ID sheets. We use a dataset of real world
PID sheets for quantitative evaluation which contains
4 number of sheets consisting of 672 flow diagrams.
Table 1 shows the accuracy of detection and associ-
ation of every component of the pipeline schematics.
Row 1 of Table 1 gives the accuracy of pipeline code
detection by CTPN followed by filtering of false pos-
itives using domain knowledge of standard code for-
mat. 64 codes are successfully detected out of total
71 giving accuracy of 90.1%. We also show the vi-
sual output of CTPN on text detection on a sample
P&ID sheet, as given in Figure 8.
Next, pipelines are detected with an accuracy
of 65.2% because of some random noise such as
line markings and overlaid diagrams. The proposed
heuristics based method for outlet and inlet detection
performed really well giving 100% accuracy of detec-
tion, as given by Row 3 and 4, respectively. During
the association of pipeline codes and outlets with the
appropriate pipe, we were able to successfully asso-
ciate 41 out of 64 pipeline codes and 14 out of 21
outlets, only. This is because of the fact that some-
times pipelines are not detected properly or pipelines
do not intersect with the outlet, which happened in our
case, as evident by pipeline detection accuracy given
in Row 2 of Table 1. However, inlets are associated
quite successfully with the appropriate pipeline, giv-
ing an association accuracy of 96.8%.
Now, we present the results of symbol detection
using FCN in the form of a confusion matrix, as
shown in Table 2. FCN is trained for approx.7400
iterations and we saved the network at 7000 itera-
tions by careful observation of the cross-entropy loss
of train and validation set to prevent the network from
overfitting. There are 10 different classes of symbols
for detection in P&ID sheets. We keep one extra class
Automatic Information Extraction from Piping and Instrumentation Diagrams
169
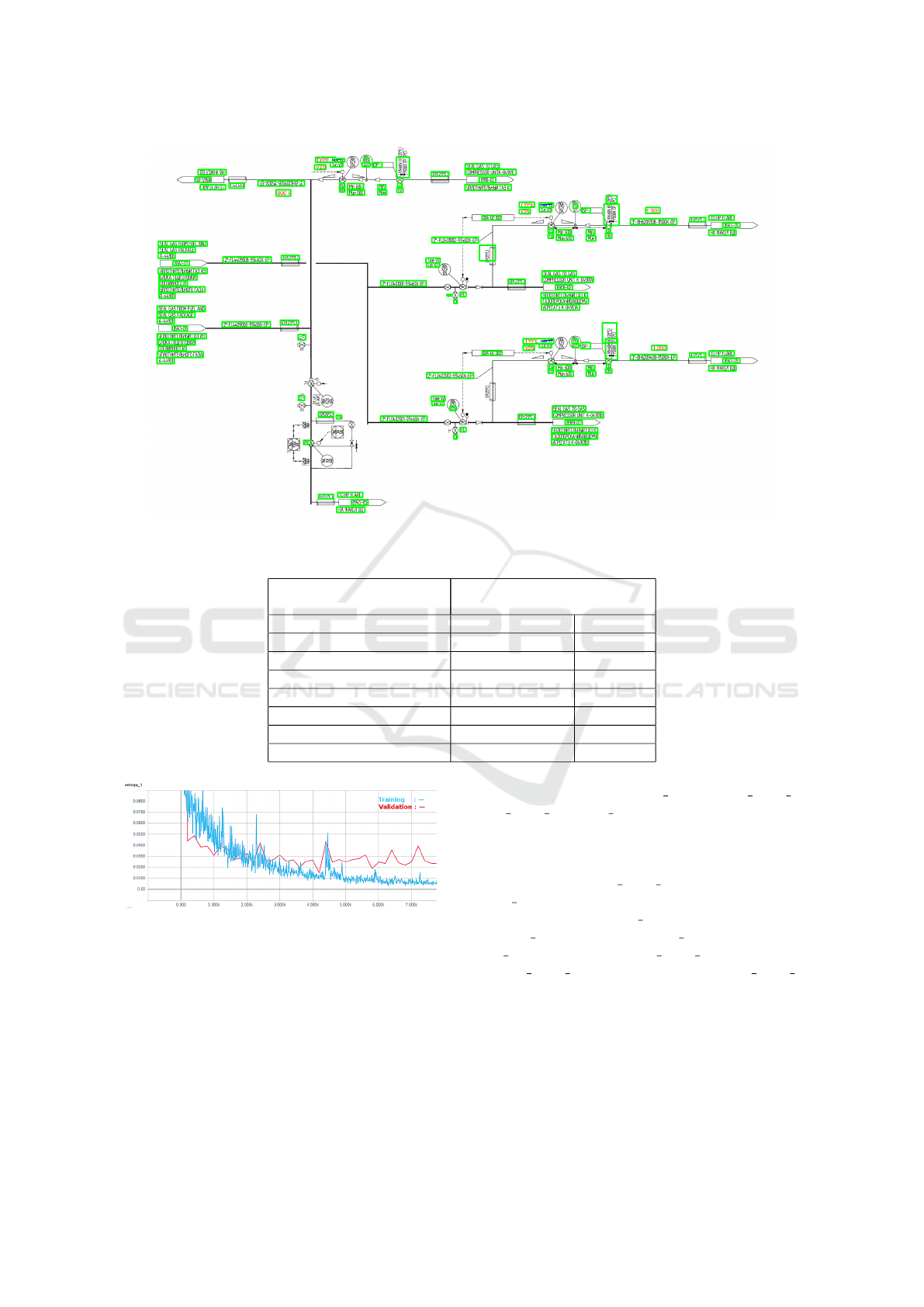
Figure 8: Figure showing text-detection output of pre-trained CTPN (Tian et al., 2016)on P&ID sheet.
Table 1: Results of proposed pipeline for individual components.
Results of
individual component
Component Successful cases Accuracy
Pipeline-Code Detection 64 / 71 90.1%
Pipeline Detection 47 / 72 65.2%
Outlet Detection 21 / 21 100%
Inlet Detection 32 / 32 100%
Pipeline Code Association 41 / 64 64.0%
Outlet Association 14 / 21 66.5%
Inlet Association 31 / 32 96.8%
Figure 9: Plot showing cross-entropy loss for train and vali-
dation sets during training of FCN (Shelhamer et al., 2016)
for symbol detection.
for training i.e. Others comprising of such symbols
present in the P&ID diagrams that are not of interest
but were creating confusions in detection of symbols
of interest. So, we have total of 11 classes of symbols
for training FCN network for symbol detection.
We experimentally observe that FCN gives en-
couraging results for symbol detection with some
minor confusions. As it is evident from the Fig-
ure 6, symbols such as ball valve, globe valve nc,
gate valve nc, globe valve look visually similar and
have very low inter-class variation in appearance.
Most of the confusion is created among these
classes of symbols only as given in Table 2 with
the exception of gate valve nc being recognised as
flood connection which are not visually similar. For
example, 5 out of 79 ball valve are being recognised
as globe valve, 4 out of 68 globe valve are detected as
ball valve, 3 out of 57 globe valve nc are recognized
as gate valve nc. Symbols such as gate valve nc
and concentric are detected successfully. We pro-
vide some sample examples of symbol detection us-
ing FCN in Figure 10.
We also calculate precision, recall and F1-score
for each class of symbols, as given in Table 3. We
found that FCN detects symbols, even with very low
visual difference in appearances, with impressive F1-
scores of values more than 0.86 for every class. Pre-
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
170

Table 2: Confusion Matrix for Symbol Detection using FCN (Shelhamer et al., 2016) network.
Predictions
Actual Bl-V Ck-V Ch-sl Cr-V Con F-Con Gt-V-nc Gb-V Ins Gb-V-nc Others
Bl-V 74 2 0 0 0 0 0 4 0 0 0
Ck-V 0 64 0 0 4 0 0 0 0 0 0
Ch-sl 0 0 25 0 0 0 0 0 0 0 0
Cr-V 0 0 0 294 0 0 0 0 0 0 0
Con 0 0 0 0 38 0 0 0 0 0 0
F-Con 0 0 0 0 0 41 0 0 0 1 0
Gt-V-nc 0 0 0 0 0 8 36 0 0 3 0
Gb-V 5 0 0 3 0 0 0 64 0 0 0
Ins 0 0 0 0 0 0 0 0 261 0 0
Gb-V-nc 0 0 0 0 0 0 0 0 0 52 0
Others 0 0 3 0 0 0 0 0 4 0 149
Table 3: Performance Measure of FCN (Shelhamer et al.,
2016) on different classes of Symbol Detection.
Precision Recall F1-Score
Bl-V 0.925 0.936 0.931
Ck-V 0.941 0.969 0.955
Ch-sl 1 0.893 0.944
Cr-V 1 0.989 0.995
Con 1 0.905 0.95
F-Con 0.976 0.837 0.901
Gt-V-nc 0.766 1 0.867
Gb-V 0.888 0.941 0.914
Ins 1 0.985 0.992
Gb-V-nc 1 0.929 0.963
Others 0.955 1 0.977
Figure 10: Examples of symbols detected using FCN. The
green and red colored bounding boxes of symbols repre-
sent ground truth and corresponding predictions by FCN,
respectively.
cision is 100% for symbols like chemical seal, cir-
cle valve, concentric, insulation and globe valve nc.
6 CONCLUSION
In this paper, we have proposed a novel end-to-end
pipeline for extracting information from P&ID sheets.
We used state-of-the-art deep learning networks like
CTPN and FCN for pipeline code and symbol de-
tection, respectively and basic low level image pro-
cessing techniques for detection of inlets, outlets and
pipelines. We formulated a tree-like data structure for
capturing the process flow of pipeline schematics af-
ter associating the detected components with the ap-
propriate pipeline. We performed experiments on a
dataset of real world P&ID sheets using our proposed
method and obtained satisfactory results.
REFERENCES
Adam, S., Ogier, J., Cariou, C., Mullot, R., Labiche, J.,
and Gardes, J. (2000). Symbol and character recog-
nition: application to engineering drawings. Inter-
national Journal on Document Analysis and Recog-
nition.
Arroyo, E., Fay, A., Chioua, M., and Hoernicke, M. (2014).
Integrating plant and process information as a basis
for automated plant diagnosis tasks. In Proceedings
of the 2014 IEEE Emerging Technology and Factory
Automation (ETFA), pages 1–8.
Arroyo, E., Hoang, X. L., and Fay, A. (2015). Automatic
detection and recognition of structural and connectiv-
ity objects in svg-coded engineering documents. In
2015 IEEE 20th Conference on Emerging Technolo-
gies Factory Automation (ETFA), pages 1–8.
Belongie, S., Malik, J., and Puzicha, J. (2002). Shape
matching and object recognition using shape contexts.
IEEE Transactions on Pattern Analysis and Machine
Intelligence, 24(4):509–522.
Fei, L. and He, J. (2009). A three-dimensional dou-
glas–peucker algorithm and its application to auto-
mated generalization of dems. International Journal
of Geographical Information Science, 23(6):703–718.
Fu, L. and Kara, L. B. (2011). Neural network-based sym-
bol recognition using a few labeled samples. Comput-
ers and Graphics, 35(5).
Gellaboina, M. K. and Venkoparao, V. G. (2009). Graphic
symbol recognition using auto associative neural net-
work model. In 2009 Seventh International Confer-
ence on Advances in Pattern Recognition, pages 297–
301.
Goh, K. N., Mohd. Shukri, S. R., and Manao, R. B. H.
(2013). Automatic assessment for engineering draw-
Automatic Information Extraction from Piping and Instrumentation Diagrams
171

ing. In Advances in Visual Informatics, pages 497–
507, Cham. Springer International Publishing.
Gupta, G., Swati, Sharma, M., and Vig, L. (2017). Informa-
tion extraction from hand-marked industrial inspec-
tion sheets. In 2017 14th IAPR International Con-
ference on Document Analysis and Recognition (IC-
DAR), volume 06, pages 33–38.
Kiryati, N., Eldar, Y., and Bruckstein, A. (1991). A
probabilistic hough transform. Pattern Recognition,
24(4):303 – 316.
Koo, H. I. and Kim, D. H. (2013). Scene text detection via
connected component clustering and nontext filtering.
Trans. Img. Proc., 22(6):2296–2305.
Ouyang, T. Y. and Davis, R. (2009). A visual approach to
sketched symbol recognition. In Proceedings of the
21st International Jont Conference on Artifical Intel-
ligence, IJCAI’09, pages 1463–1468, San Francisco,
CA, USA. Morgan Kaufmann Publishers Inc.
Ren, S., He, K., Girshick, R. B., and Sun, J. (2015). Faster
R-CNN: towards real-time object detection with re-
gion proposal networks. CoRR, abs/1506.01497.
Saha, P. K., Borgefors, G., and di Baja, G. S. (2016). A sur-
vey on skeletonization algorithms and their applica-
tions. Pattern Recognition Letters, 76:3 – 12. Special
Issue on Skeletonization and its Application.
Shelhamer, E., Long, J., and Darrell, T. (2016). Fully
convolutional networks for semantic segmentation.
CoRR, abs/1605.06211.
Simonyan, K. and Zisserman, A. (2014). Very deep con-
volutional networks for large-scale image recognition.
CoRR, abs/1409.1556.
Smith, R. (2007). An overview of the tesseract ocr engine.
In Proceedings of the Ninth International Conference
on Document Analysis and Recognition - Volume 02,
ICDAR ’07, pages 629–633, Washington, DC, USA.
IEEE Computer Society.
Tian, Z., Huang, W., He, T., He, P., and Qiao, Y. (2016).
Detecting text in natural image with connectionist text
proposal network. CoRR, abs/1609.03605.
Verma, A., Sharma, M., Hebbalaguppe, R., Hassan, E., and
Vig, L. (2016). Automatic container code recognition
via spatial transformer networks and connected com-
ponent region proposals. In Machine Learning and
Applications (ICMLA), 2016 15th IEEE International
Conference on, pages 728–733. IEEE.
Wang, N., Liu, W., Zhang, C., Yuan, H., and Liu, J. (2009).
The detection and recognition of arrow markings
recognition based on monocular vision. In 2009 Chi-
nese Control and Decision Conference, pages 4380–
4386.
Xiaogang, X., Zhengxing, S., Binbin, P., Xiangyu, J., and
Wenyin, L. (2004). An online composite graphics
recognition approach based on matching of spatial re-
lation graphs. Document Analysis and Recognition,
pages 44–55.
Yan, L. and Wenyin, L. (2003). Engineering drawings
recognition using a case-based approach. In Sev-
enth International Conference on Document Analysis
and Recognition, 2003. Proceedings., pages 190–194
vol.1.
Yu, B. (1995). Automatic understanding of symbol-
connected diagrams. In Proceedings of 3rd Interna-
tional Conference on Document Analysis and Recog-
nition, volume 2, pages 803–806 vol.2.
ICPRAM 2019 - 8th International Conference on Pattern Recognition Applications and Methods
172
