
Recommender Systems Robust to Data Poisoning using Trim Learning
Seira Hidano and Shinsaku Kiyomoto
KDDI Research Inc., Saitama, Japan
Keywords:
Recommender Systems, Matrix Factorization, Data Poisoning, Trim Learning.
Abstract:
Recommender systems have been widely utilized in various e-commerce systems for improving user experi-
ence. However, since security threats, such as fake reviews and fake ratings, are becoming apparent, users are
beginning to have their doubts about trust of such systems. The data poisoning attack is one of representative
attacks for recommender systems. While acting as a legitimate user on the system, the adversary attempts to
manipulate recommended items using fake ratings. Although several defense methods also have been pro-
posed, most of them require prior knowledge on real and/or fake ratings. We thus propose recommender
systems robust to data poisoning without any knowledge.
1 INTRODUCTION
Recommender systems have an essential role in im-
proving user experience in recent e-commerce sys-
tems. Users can efficiently find out potentially prefer-
able items by using the recommender system. How-
ever, recommended items are selected based on rat-
ings from other users. Since in such an environment,
anybody can easily provide malicious data, there is
concern about security risks, such as fake reviews and
fake ratings.
In this paper, we especially focus on data poison-
ing attacks for recommender systems. The data poi-
soning attack manipulates recommended items by in-
jecting fake ratings to the system. Although several
attacks have been proposed, defense techniques have
not really reached maturity yet. Most of existing de-
fense methods require prior knowledge on real and/or
fake ratings. We thus propose recommender systems
robust to data poisoning without any knowledge.
1.1 Related Work
The main objective of data poisoning attacks for rec-
ommender systems is to raise or lose the popularity of
specific items. To this end, (Burke et al., 2005) dis-
cussed creating ratings of malicious users with lim-
ited knowledge, and introduced three attack models:
random attacks, average attacks, and bandwagon at-
tacks. (Williams et al., 2006) additionally provided an
attack model called obfuscated attacks, which makes
it more difficult to detect malicious users.
Defense methods are categorized into two models:
supervised approach and non-supervised approach. In
the supervised setting, detectors are trained with a set
of rating data with a label of a legitimate or mali-
cious user. Several features have been designed for
this model (Chirita et al., 2005; Burke et al., 2006;
Mobasher et al., 2007; Wu et al., 2011; Wu et al.,
2012). Although this type of detectors achieve high
accuracy, conditions are not practical. For instance, it
is difficult to obtain rating data with a label in actual
usecases. On the other hand, non-supervised meth-
ods generate a detector using a rating data set without
labels. (Mehta, 2007) developed this type of first de-
tector based on PCA, which we call the PCA-based
method in this paper. However, it was shown that
non-supervised methods are vulnerable to advanced
attacks like the obfuscated attack (Li et al., 2016).
1.2 Our Contribution
We propose a new defense method without any
knowledge, which is more effective than existing
methods. Our main contribution is summarized as fol-
lows:
• We design a matrix factorization algorithm using
trim learning. Matrix factorization is the most rep-
resentative method for predicting unobserved rat-
ings. Trim learning, proposed by (Jagielski et al.,
2018), is a learning method robust to data poison-
ing for linear regression. By applying the concept
of the trim learning to the matrix factorization, we
develop a learning algorithm that precludes fake
Hidano, S. and Kiyomoto, S.
Recommender Systems Robust to Data Poisoning using Trim Learning.
DOI: 10.5220/0009180407210724
In Proceedings of the 6th International Conference on Information Systems Security and Privacy (ICISSP 2020), pages 721-724
ISBN: 978-989-758-399-5; ISSN: 2184-4356
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
721

ratings with high accuracy.
• We demonstrate the effect of our proposed method
with a real-world dataset. Assuming four types
of data poisoning attacks, we compare the perfor-
mance of our proposed method with another ex-
isting detection method. The results show that our
proposed method improves robustness to data poi-
soning dramatically.
2 PRELIMINARIES
2.1 Recommender Systems
We focus on collaborating filtering based on matrix
factorization that is widely used in real-world recom-
mender systems (Koren et al., 2009). Let m and n be
the numbers of users and items in the system, respec-
tively. Let M ∈ R
m×n
be a rating matrix including
a large number of missing elements. We denote by
Ω a set of indices whose ratings are observed. M
i, j
indicates a rating of the ith user for the jth item. Ma-
trix factorization is used to generate two latent factors
U ∈ R
m×k
and V ∈ R
k×n
, where k min(m,n) is a
positive integer. We call U and V a user matrix and
an item matrix, respectively. These are given by solv-
ing the following optimization problem:
min
U,V
∑
(i, j)∈Ω
(M
i, j
− u
i
v
j
)
2
+ λ(||U||
2
+ ||V||
2
), (1)
where u
i
and v
j
indicate the ith row of U and the jth
column of V, respectively, and λ (≥ 0) is a regular-
ization parameter. || · || is the Frobenius norm.
The recommender system predicts the values of
missing elements in M by calculating
b
M = UV. Rec-
ommended items are selected based on the predicted
ratings.
Stochastic gradient decent (SGD) and alternating
minimization are well-known as optimization meth-
ods to solve Eq. (1). Since the SGD method is faster
and easier to implement for a sparse matrix like a
rating matrix M, we develop our learning algorithm
based on it. The algorithm loops through all the rat-
ings in a training set. We here define a prediction error
for a given rating as
e
i, j
:
= M
i, j
− u
i
v
j
. (2)
At each iteration, both of the user matrix U and the
item matrix V are modified as follows:
u
i
← u
i
+ η · (e
i, j
· u
i
− λ · v
j
) (3)
v
j
← v
j
+ η · (e
i, j
· v
i
− λ · u
i
), (4)
where η (> 0) is a learning rate.
2.2 Data Poisoning Attacks
In the data poisoning attack for a recommender sys-
tem, the adversary creates multiple user accounts, and
injects fake ratings. Let M
0
∈ R
m
0
×n
be a fake rating
matrix injected to the recommender system, where m
0
is the number of the malicious users. We define attack
size as α
:
= m
0
/m.
We especially focus on an attack whereby the pop-
ularity of target items is elevated, which is called a
push attack. Ratings from a malicious user for the
push attack consist of three parts:
• Target Items: The items whose popularity is what
the adversary would like to increase. The highest
rate is assigned.
• Filler Items: The items are rated to make detection
difficult. Filler Size β is measured as a ration of
the number of the filler items to n.
• Unrated Items: The remaining items that are not
rated occupy a majority of a data point.
Rating values for filler items are assigned based
on either of the following four strategies (Burke et al.,
2005; Burke et al., 2006):
• Random Attacks: The filler items are randomly
rated around the overall average rating value.
• Average Attacks: The filler items are randomly
rated around the average rating value of each item.
• Bandwagon Attacks: Some filler items are the
most popular items and rated with the maximum
rating value. The other filler items are randomly
rated around the overall average rating value. In
the experiments of this paper, half of filler items
are assigned to the most popular items.
• Obfuscated Attacks: All the filler items are ran-
domly selected among some highly popular items,
and randomly rated around the overall average rat-
ing value.
2.3 Trim Learning
The trim learning, proposed by (Jagielski et al., 2018),
is a learning method robust to data poisoning. Let D
be a training set that consists of N legitimate samples
and N
0
malicious samples. Let L be a loss function
with model parameters θ. Jagielski et al. formally
defined the optimization problem as follows:
min
θ,I
L(D
I
,θ)
s.t. I ⊂ [N + N
0
],|I | = N, (5)
where D
I
⊂ D is a set of data samples corresponding
to indices I .
ICISSP 2020 - 6th International Conference on Information Systems Security and Privacy
722

Jagielski et al. provided an optimization algorithm
to solve Eq. (5) for linear regression. We apply this
concept to matrix factorization, and develop a learn-
ing algorithm robust to data poisoning for a recom-
mender system.
3 METHOD
We propose a learning method robust to data poison-
ing for a recommender system by combining matrix
factorization and trim learning. This section defines
an optimization problem for our method, and devel-
ops a robust matrix factorization algorithm.
3.1 Problem Setting
Since it is difficult for the adversary to imitate legit-
imate users, the behavior of malicious users is statis-
tically different from that of legitimate users. As a
result, training loss for malicious users will be larger,
as compared to legitimate users. In addition, contam-
inated items such as target items and filler items make
training loss larger for both legitimate users and ma-
licious users. We thus design an algorithm to learn
a model while trimming both of malicious users and
contaminated items.
To this end, we define an optimization problem for
our proposed method as follows:
min
U,V,I
u
,I
v
L(M,U,V, I
u
,I
v
)
=
∑
(i, j)∈Ω
I
u
×I
v
(M
i, j
− u
i
v
j
)
2
+ λ(||U||
2
+ ||V||
2
)
s.t. I
u
⊂ [m], I
v
⊂ [n], |I
u
| = m
∗
, |I
v
| = n
∗
, (6)
where I
u
and I
v
are subsets of users and items, respec-
tively. m
∗
and n
∗
are the numbers of users and items
that are not trimmed, respectively. Ω
I
u
×I
v
is a set of
observed elements in M corresponding to only users
I
u
and items I
v
.
3.2 Algorithm
We adopt alternative minimization for solving the op-
timization problem (6). Our algorithm first solves U
and V while keeping I
u
and I
v
. Then I
u
and I
v
be
solved with U and V fixed.
Let U
∗
and V
∗
be user and item matrices corre-
sponding to I
u
and I
v
, respectively. Let U
c
and V
c
be user and item matrices corresponding to trimmed
users I
c
u
= [m] \ I
u
and trimmed items I
c
v
= [n] \ I
v
,
respectively. In the optimization process of U and
V, U
∗
and V
∗
are first solved using the SGD method
described in Section 2.1. After that, U
c
(resp. V
c
) are
Algorithm 1: Trim matrix factorization.
Input : M, m, n, k, m
∗
, n
∗
, α, β, λ, η
Output: U
∗
, V
∗
, I
u
, I
v
1 Initialize I
(0)
u
, I
(0)
v
.
2 t ← 0
3 repeat
4 U
∗(t)
,V
∗(t)
←
argmin
U
∗
,V
∗
L(M,U
∗
,V
∗
,I
(t)
u
,I
(t)
v
)
5 I
c(t)
u
← [m] \ I
(t)
u
, I
c(t)
v
← [n] \ I
(t)
v
6 U
c(t)
←
argmin
U
c
L(M,U
c
,V
∗(t)
,I
c(t)
u
,I
(t)
v
)
7 V
c(t)
←
argmin
V
c
L(M,U
∗(t)
,V
c
,I
(t)
u
,I
c(t)
v
)
8 U
(t)
← concatenate(U
∗(t)
,U
c(t)
)
9 V
(t)
← concatenate(V
∗(t)
,V
c(t)
)
10 I
(t+1)
u
,I
(t+1)
v
←
argmin
I
u
,I
v
L(M,U
(t)
,V
(t)
,I
u
,I
v
,)
11 t ← t +1
12 until I
(t)
u
= I
(t−1)
u
∧ I
(t)
v
= I
(t−1)
v
13 return U
∗(t)
, V
∗(t)
, I
(t)
u
, I
(t)
v
solved with V
∗
(resp. U
∗
) fixed. I
u
and I
v
can also
be solved using alternative minimization. Algorithm
1 summarizes the algorithm of our proposed method.
4 EXPERIMENTS
4.1 Setup
We used the MovieLens 1M dataset (GroupLens Re-
search, 2016) as a real-world dataset. We imple-
mented four types of attacks described in Section 2.2.
The attack size was set to α = 0.05, 0.1, 0.15 or 0.2.
An item was randomly selected as a target item. The
filler size was set to β = 0.05, 0.1, 0.15 or 0.2, and
filler items were also randomly selected for each value
of β. We conducted each attack 10 times for each pa-
rameter set in order to stabilize results. Parameters
of our proposed method were set to k = 32, m
∗
= m,
n
∗
= (1 − β)n − 1, λ = 0.01, and η = 0.02.
Here we define detection rate as a metric for our
proposed method. The detection rate is the ratio of
the number of trimmed malicious users to the total
number of malicious users. We evaluated the effect of
our proposed method using the average value of the
detection rate. For comparison, we also implemented
the PCA-based method (Mehta, 2007), and evaluated
its performance with the same metric.
Recommender Systems Robust to Data Poisoning using Trim Learning
723
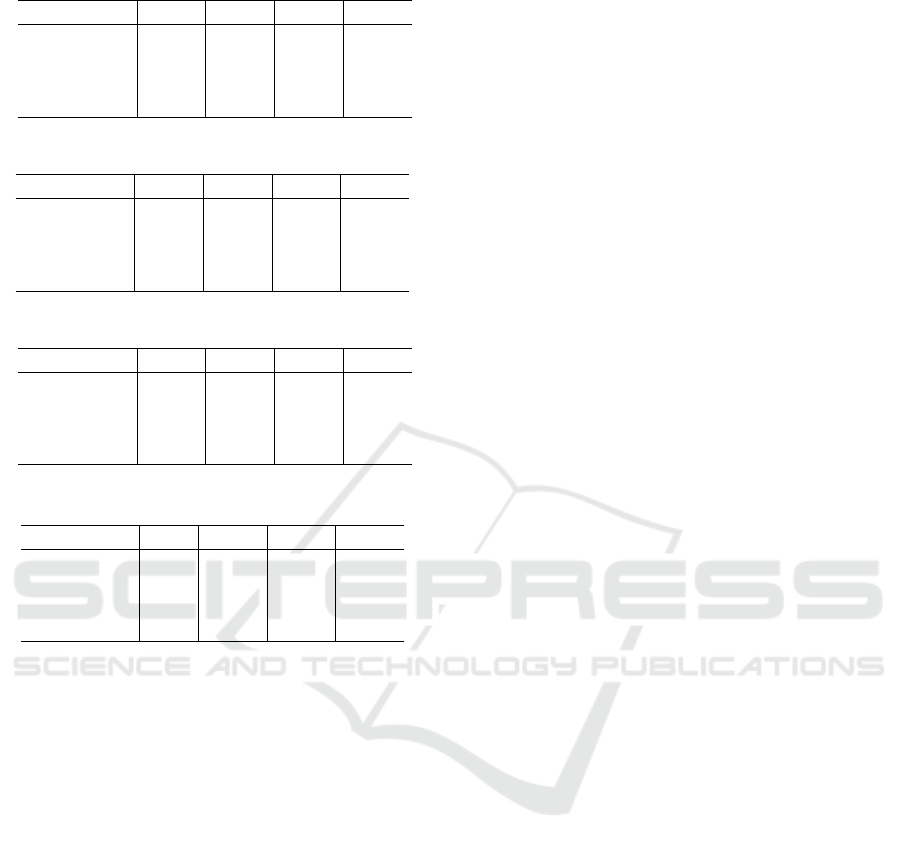
Table 1: Detection rates of our proposed method (β = 0.1).
Attack size 0.05 0.1 0.15 0.2
Random 0.887 0.941 0.963 0.974
Average 0.880 0.938 0.960 0.970
Bandwagon 0.793 0.859 0.897 0.918
Obfuscated 0.827 0.921 0.938 0.956
Table 2: Detection rates of PCA based method (β = 0.1).
Attack size 0.05 0.1 0.15 0.2
Random 0.0 0.010 0.029 0.121
Average 0.667 0.754 0.758 0.762
Bandwagon 0.733 0.770 0.802 0.780
Obfuscated 0.0 0.111 0.323 0.475
Table 3: Detection rates of our proposed method (α = 0.1).
Filler size 0.05 0.1 0.15 0.2
Random 0.761 0.941 0.993 1.0
Average 0.757 0.938 0.980 1.0
Bandwagon 0.318 0.859 0.948 0.987
Obfuscated 0.333 0.921 0.970 1.0
Table 4: Detection rates of PCA based method (α = 0.1).
Filler size 0.05 0.1 0.15 0.2
Random 0.0 0.010 0.367 0.711
Average 0.0 0.754 0.754 0.784
Bandwagon 0.06 0.770 0.770 0.770
Obfuscated 0.0 0.111 0.692 0.715
4.2 Evaluation Results
Tables 1 and 2 show detection rates of our pro-
posed method and the PCA-based method, respec-
tively, when the filler size β = 0.1. Tables 3 and 4
show the results for α = 0.1. It can be shown that the
detection rate of our proposed method is much higher
than that of the PCA-based method for all the settings.
Consequently, we can say that our proposed method
improves robustness to data poisoning dramatically.
5 CONCLUSIONS
This paper proposed recommender systems robust to
data poisoning. Our proposed method is a combina-
tion of matrix factorization and trim learning. The
algorithm trains a model for recommendation while
trimming malicious users and contaminated items.
The experimental results showed that our proposed
method improves robustness to data poisoning dra-
matically.
In the feature, we will conduct additional experi-
ments with other real-world datasets as well as theo-
retical analysis of our proposed method. Furthermore,
we will apply the concept of our proposed method to
more complicated learning methods utilized in rec-
ommender systems.
REFERENCES
Burke, R., Mobasher, B., and Bhaumik, R. (2005). Lim-
ited knowledge shilling attacks in collaborative filter-
ing systems. In Proceedings of the 3rd IJCAI Work-
shop in Intelligent Techniques for Personalization.
Burke, R., Mobasher, B., Williams, C., and Bhaumik, R.
(2006). Classification features for attack detection in
collaborative recommender systems. In Proceedings
of the 12th ACM SIGKDD International Conference
on Knowledge Discovery and Data Mining.
Chirita, P., Nejdl, W., and Zamfir, C. (2005). Preventing
shilling attacks in online recommender systems. In
Proceedings of the 7th ACM international workshop
on Web information and data management (WIDM),
pages 67–74.
GroupLens Research (2016). MovieLens 1M Dataset.
http://grouplens.org/datasets/movielens/.
Jagielski, M., Oprea, A., Biggio, B., Liu, C., Nita-Rotaru,
C., and Li, B. (2018). Manipulating machine learning:
Poisoning attacks and countermeasures for regression
learning. In Proceedings of the 39th IEEE Symposium
on Security and Privacy (S&P).
Koren, Y., Bell, R., and Volinsky, C. (2009). Matrix factor-
ization techniques for recommender systems. Com-
puter and Information Science, 42(8):30–37.
Li, W., Gao, M., Li, H., and Zeng, J. (2016). Shilling at-
tack detection in recommender systems via selecting
patterns analysis. IEICE Transactions on Information
and Systems, E99-10(10).
Mehta, B. (2007). Unsupervised shilling detection for col-
laborative filtering. In Proceedings of the 22nd AAAI
Conference on Artificial Intelligence.
Mobasher, B., Burke, R., Bhaumik, R., and Williams,
C. (2007). Toward trustworthy recommender sys-
tems: An analysis of attack models and algorithm ro-
bustness. ACM Transactions on Internet Technology
(TOIT), 7(23).
Williams, C., Mobasher, B., Burke, R. D., Sandvig, J. J.,
and Bhaumik, R. (2006). Detection of obfuscated
attacks in collaborative recommender systems. In
Proceedings of the ECAI 2006 Workshop on Recom-
mender Systems.
Wu, Z., Cao, J., Mao, B., and Wang, Y. (2011). Semi-SAD:
Applying semi-supervised learning to shilling attack
detection. In Proceedings of the 5th ACM Conference
on Recommender Systems (RecSys).
Wu, Z., Wu, J., Cao, J., and Tao, D. (2012). HySAD:
A semi-supervised hybrid shilling attack detector for
trustworthy product recommendation. In Proceedings
of the 18th ACM SIGKDD International Conference
on Knowledge Discovery and Data Mining.
ICISSP 2020 - 6th International Conference on Information Systems Security and Privacy
724
