
Ontology-based Question Answering Systems over Knowledge Bases:
A Survey
Wellington Franco
1
, Caio Viktor
1
, Artur Oliveira
1
, Gilvan Maia
1
, Angelo Brayner
1
, V. M. P. Vidal
1
,
Fernando Carvalho
1
and V. M. Pequeno
2
1
Departamento de Computac¸
˜
ao, Federal University of Cear
´
a, Fortaleza, Cear
´
a, Brazil
2
TechLab, Departamento de Ci
ˆ
encias e Tecnologias, Universidade Aut
´
onoma de Lisboa Lu
´
ıs de Cam
˜
oes, Portugal
{vvidal, brayner, carvalho}@lia.ufc.br, vpequeno@autonoma.pt
Keywords:
Question Answering Systems, Ontology, Knowledge Bases, Literature Survey.
Abstract:
Searching relevant, specific information in big data volumes is quite a challenging task. Despite the numerous
strategies in the literature to tackle this problem, this task is usually carried out by resorting to a Question
Answering (QA) systems. There are many ways to build a QA system, such as heuristic approaches, machine
learning, and ontologies. Recent research focused their efforts on ontology-based methods since the resulting
QA systems can benefit from knowledge modeling. In this paper, we present a systematic literature survey on
ontology-based QA systems regarding any questions. We also detail the evaluation process carried out in these
systems and discuss how each approach differs from the others in terms of the challenges faced and strategies
employed. Finally, we present the most prominent research issues still open in the field.
1 INTRODUCTION
The advent of Natural Language Interfaces (NLI) se-
cured the interest of Natural Language Processing
(NLP) researchers for practical applications. In par-
ticular, Question Answering (QA) systems are closely
related to Computational Linguistics (Herzog and
Rollinger, 1991; Wilensky et al., 1988). Ontologies
(Daconta et al., 2003) are fundamental Knowledge
Bases (KBs), such as DBPedia (Bizer et al., 2009),
YAGO (Suchanek et al., 2007), YAGO2 (Hoffart
et al., 2013), and Freebase (Bollacker et al., 2008).
KBs perform information collection on a regular time
basis from open, constantly expanding resources such
as Wikipedia (Hakimov et al., 2013). Many chal-
lenges surround the field of KBs, such as base cover-
age, commonsense, rules, and socio-cultural aspects
(Weikum et al., 2019).
Regarding a QA system, consulting a KB requires
a thorough mastery of elaborate, formal concepts re-
garding ontologies and their underlying technologies.
A knowledge base QA system aims to retrieve the
information requested by users in natural language,
but in terms of automatic inferences or queries op-
erating over KBs. Actual access to a KB demands
queries to be written in formal, complex languages
such as SPARQL (Seaborne and Prud’hommeaux,
2008; Diefenbach et al., 2018). Resorting to sophis-
ticated user interfaces is time-consuming and also
demands customization efforts for different domains
and users.
In this work we present a literature survey on
ontology-based QA systems that operate over Knowl-
edge Bases. The remaining of this manuscript is or-
ganized as follows: Section 2 initially introduces the
main types of QA systems. Sections 3 and 4 contain a
discussion about related works and golden standards
for evaluation, respectively; Section 5 is devoted to
the discussion of works found in this literature sur-
vey; Section 6 presents the top research challenges
identified in this survey; and the conclusions and main
considerations about this investigation are developed
throughout Section 7.
2 QA SYSTEM TYPES
Given the full range of topics involved in QA sys-
tem, this paper focuses on an existing classifica-
tion based on the type of response expected to be
found (Latifi, 2018): Closed-Domain Question An-
swering (QADR), QA for Comprehension Reading
(QACR), Community Question Answering (QAC),
532
Franco, W., Viktor, C., Oliveira, A., Maia, G., Brayner, A., Vidal, V., Carvalho, F. and Pequeno, V.
Ontology-based Question Answering Systems over Knowledge Bases: A Survey.
DOI: 10.5220/0009392205320539
In Proceedings of the 22nd International Conference on Enterprise Information Systems (ICEIS 2020) - Volume 1, pages 532-539
ISBN: 978-989-758-423-7
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

QA Over Domain Ontologies, Ontology-Based QA
(QASOBO), and Linked Open Data Question An-
swering (QALOD).
QADR: question and search space are restricted
to a particular domain, so users often show high
expectations for appropriate responses, i.e., having
no answer is preferable to reporting wrong answers
(Weikum et al., 2019). QADR systems are usually
applied to specific tasks and use lexical, terminolo-
gies, knowledge bases, ontologies, and other domain-
restricted lexical-conceptual resources (Latifi, 2018).
QACR: questions are closely related to a given
document, user’s ability to understand the matters
presented in that document can be assessed. Richard-
son et al. (2013) proposed MCTest
1
, a machine text
comprehension dataset formulated based on different
aspects of 660 stories.
QAC: social QA network is based on interactions
within a virtual community, such as Quora or Stack
Overflow. QAC starts when a user posts an initial
consultation formulated using natural language, thus
triggering a line of interventions by other community
members.
QASOBO: answers are not sought directly in
plain, unstructured text documents, but in ontologies
(Diefenbach et al., 2018), so systems can take advan-
tage of its linguistic and terminological data, its rela-
tions, properties, and inference capabilities.
QALOD: there is a substantial growth of avail-
able resources in the Semantic Web over the past few
years, regarding both quantity and complexity, includ-
ing the Linked Open Data initiative.
3 RELATED SURVEYS
Cimiano and Minock (2009) carried out qualitative
analyzes of the underlying problems and challenges
regarding the construction of NLI, resulting in 11
challenges identified for QA systems, such as ques-
tion types, ambiguities, spatial prepositions, modi-
fiers and superlatives, aggregation, comparison, and
negation. Freitas et al. (2012) focused in the chal-
lenges of building effective query mechanisms for
large-scale data, exemplifying the differences be-
tween Information Retrieval (IR), SPARQL queries,
and QA systems. (Lopez et al., 2013) listed and
discussed the main forms of assessment and golden
standards applicable to QA systems, their limitations
and key questions for future works. (Mishra and
Jain, 2016) proposed 8 classification criteria for QA
systems: application domain; question types; ques-
1
http://research.microsoft.com/mct
tion analysis types; data source type; correspondence
function types; characteristics of data sources; tech-
niques used; and forms of responses generated. They
also presented advantages, disadvantages, and repre-
sentative systems.
(H
¨
offner et al., 2017) coined the term Semantic
Query Answering (SQA) in their survey: users ask
questions in NL using their terminology for which re-
ceive a concise answer, generated by querying a KB
Resource Description Framework (RDF)
2
. They also
analyzed and categorized methods that address spe-
cific problems of SQA. (Diefenbach et al., 2018) pub-
lished a suvery on SQA focusing on the “standard ar-
chitecture” of existing systems, which subdivides the
problem into four steps/modules: Question Analysis,
Sentence Mapping, Disambiguation, Query Build-
ing, and Queries over Distributed Knowledge Bases.
(Soares and Parreiras, 2018) presented a systematic
literature review of studies published from 2000 to
2017. They focused on identifying QA techniques
and tools with particular attention to the relationship
between QA systems and NLP. A similar study was
published by (Tasar et al., 2018) to identify and ana-
lyze the main methods, datasets, and venues of works
published between 2010 and 2017 for QALOD. From
an initial universe of 843 articles, the authors selected
53 studies as primary studies from which methods
were analyzed and gaps between approaches were
identified. (Wohlgenannt et al., 2019) also analyzed
frameworks for QALOD, but comparing visual dia-
grammatic approaches to querying data with existing
NL-based systems. Using the (QALD7) dataset, they
assessed that visual methods iteratively until the an-
swer is found and showed some benefits in relation to
4 NL-based systems, such as better data exploration
and better performance.
Most systematic reviews on SQA research focus
on evaluation (Lopez et al., 2013), specific domains
(Freitas et al., 2012; Soares and Parreiras, 2018), cat-
egorization (Mishra and Jain, 2016; H
¨
offner et al.,
2017) or general approaches (Diefenbach et al., 2018)
and techniques (Soares and Parreiras, 2018). Our re-
search aims to analyze the SQA works dealing with
both specific and general domains under the light of
how ontologies can be employed to assist or improve
QA systems.
2
Definition made by (Hirschman and Gaizauskas, 2001)
Ontology-based Question Answering Systems over Knowledge Bases: A Survey
533

4 GOLDEN STANDARDS AND
EVALUATION
There is an interesting diversity of standard data sets
available to evaluate QA systems. Such Golden Stan-
dards (GSs) establish reference problems for evalua-
tion. Given the enormity of the datasets, typical eval-
uations using a GS include manual checks on reduced
scenarios to ensure the quality of the data and results.
These are main GS referenced in literature: Ques-
tion Answering over Linked Data (QALD) (Cimiano
et al., 2013; Cimiano and Minock, 2009), WebQues-
tions (Berant et al., 2013), Stanford Question An-
swering Dataset (SQuAD) (Rajpurkar et al., 2016),
and SimpleQuestions (Bordes et al., 2015).
QALD’s questions are prepared for an annual
challenge held at CLEF (Conference and Labs of
the Evaluation Forum), ESWC (European Semantic
Web Conference), and ISWC (International Seman-
tic Web Conference) conferences. Questions are usu-
ally answered using up to three binary relationships,
but typically resorting to modifiers such as order by
and count. The training set is qualitative but quite
small, with about 50 to 250 questions, leaves by it-
self little to no space for supervised approaches such
as deep learning (LeCun et al., 2015). WebQuestions
contains about 5,810 questions drawn from Freebase
(Bollacker et al., 2008). Of these, about 97% can be
answered using a single reified statement with poten-
tially few constraints (type, temporal, etc).
SQuAD addresses reading comprehension and
contains 100,000 questions about articles from
Wikipedia collected by Amazon Mechanical Turk
(AMT) (Paolacci et al., 2010). SQuAD’ questions
were validated using DBPedia (Bizer et al., 2009),
so each answer is text passage or an extension of the
corresponding reading passage. However, some ques-
tions are impossible to answer. Finally, SimpleQues-
tions contains 108,442 questions built from Freebase
that, due to their factual nature, can be answered using
a binary relation. (Petrochuk and Zettlemoyer, 2018)
showed that about 33.9% of these questions are unan-
swerable due to problems concerning the nature of the
underlying data.
Acc(Q) =
# correct answers for Q
# questions in Q
(1)
The assessment of QA systems is usually performed
based on the following metrics: accuracy; recall, also
known as sensitivity; and F-score. Accuracy (Acc)
is most widely used since it indicates the fraction
of questions that are answered correctly for a set Q
(Equation 1). recall (Rec) is similar to accuracy, but
only considers the subset of the answerable questions
and does not consider wrong, irrelevant responses. F-
score considers both false cases as a combination of
precision and recall. F
1
is typically used for small
data sets that usually have unbalanced classes.
5 COMPARING QA
APPROACHES
We adopted the following search criteria to select
works discussed in this paper: an initial search was
carried out for QA works that resort to ontologies in
the process of building their strategy for solving the
problem; both open-domain QA and closed domain
systems were contemplated in this search; finally, we
intend to find material that allows us to discuss the
main challenges and point out future works on QA
systems built on top of ontologies.
Ontology Natural Language Interaction, ONLI
+
(Mithun et al., 2007): NLP is used as front-end
for the Racer reasoner (Haarslev and M
¨
oller, 2001)
and nRQL new Racer Query Language (Haarslev
et al., 2004), which augments and extends the func-
tional API to query a knowledge base using tuples
in using assertions from Description Logic (Baader
et al., 2003), so the system can retrieve all individ-
uals matching a query concept. Experimental evalu-
ation shows that ONLI
+
does not lose performance
in terms of transforming NL questions into nRQL
queries while its approach increases users’ expres-
siveness. Portable nAtural laNguage inTerface to
Ontologies, PANTO (Wang et al., 2007): accepts
form inputs in NL to generate SPARQL queries by
performing a mapping between an ontology’s con-
cepts, instances, and relations and NL using a syn-
tactical analysis tree built by the Stanford Parser
and Stanford CoreNLP (De Marneffe and Manning,
2008). PANTO also uses WordNet (Miller, 1995) and
string similarity (Cohen et al., 2003) to increase map-
ping quality. The result is converted to the query triple
form in OntoTriples, i.e., Ontology Triples compat-
ible with some ontology statements in the form of
<subject, predicate, object> and represented as enti-
ties. Finally, OntoTriples are interpreted as SPARQL.
The main problem with PANTO is the heavy reliance
on the Stanford Parser.
AquaLog (Lopez et al., 2007): a portable system
that receives queries expressed in NL and ontology
as input, extracting responses from one or more KBs
while it learns user jargon to improve experience over
time. Two language models are used to (a) convert NL
queries into query triple format and (2) to transform
query triple to triple in ontology format. The under-
lying data model consists of RDF triples. AquaLog
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
534

has poor performance relative to its ability to answer
complex questions.
Question Answering System Applied to the Cinema
Domain, QACID (Ferr
´
andez et al., 2009): its main
component are ontology, data, a dictionary, user query
collections, and the linking mechanism. QACID de-
pends on manually constructed ontologies and does
not feature a partial matching strategy for dealing with
cases in which no exact match is found. QACID was
tested in the Spanish language using ontological mod-
eling for the Cinema domain. QACID heavily relies
on the domain, so its coverage is limited both in terms
of answerable questions and spatiotemporal parame-
ters.
Question-based Interface to Ontologies, QuestIO
(Tablan et al., 2008): an NLI to access structured,
domain-independent information, with no training
step required. QuestIO automatically converts short
conceptual NL queries into formal queries that can
be executed over virtually any semantic repository.
This approach is efficient for small, domain-specific
ontologies, and it also performs relatively well for
poorly formed questions. However, QuestIO may par-
tially or even not answer complex questions, lacks
user interaction for improving results, and has no han-
dling capable of resolving the ambiguity of searches
using keywords.
Feedback, Refinement and Extended Vocabulary
Aggregation, FREyA (Damljanovic et al., 2010): im-
proves QuestIO concerning a deeper understanding of
the semantic meaning of questions to better deal with
ambiguity when ontologies are spanning multiple do-
mains. FREyA allows users to enter any queries and
resorts to a parse tree for identifying the type of ques-
tion answers that are capable of providing more con-
cise answers. Similar to AquaLog, FREyA uses user
feedback to improve performance over time.
Question Answering System for YAGO Ontology,
QASYO (Hogan et al., 2011): integrates NLP, ontolo-
gies, and information retrieval technologies into ap-
proach at one sentence-level in four steps, i.e., ques-
tion classification, a language component, query gen-
erator, and query processor. QASYO provides an-
swers extracted from the available semantic mark-
ings for queries expressed in NL and YAGO ontology
(Suchanek et al., 2007, 2008). Semantic analysis ex-
tracts keywords from questions for both use in queries
and to detect the expected response type. However,
QASYO strongly tied to YAGO and the use of key-
word severely limits expressiveness of queries to sim-
ple ones.
Ontology-based Question Answering on the Seman-
tic Web, Pythia (Unger and Cimiano, 2011): builds
compositional representations of meaning using a vo-
cabulary alignment for an ontology based on deep lin-
guistic analysis, which allows the construction of for-
mal queries even for complex NL questions involving
quantification and superlatives. Pythia can translate
representations of meaning into formal queries by re-
sorting to a grammar, and also uses an interface to per-
form a lexical-ontological specification that explains
possible linguistic links of ontology concepts. How-
ever, Pythia is limited to small knowledge bases and
cannot be used as a general solution.
Deep Web Extraction for Question Answering,
DEQA (Lehmann et al., 2012): is a conceptual frame-
work that combines semantic technologies with ef-
fective data extraction. DEQA performs web data
extraction for real estate site offerings, where there
is no structured user interface for the users, given
the case of all Oxford real estate agencies. Data is
integrated to link extracted data with prior knowl-
edge, such as geospatial information about relevant
points of interest. Then, DEQA maps NL questions
into SPARQL patterns, which are quite limited as the
coverage of questions, especially the complex ones.
Moreover, DEQA does not support complex opera-
tors such as “less than” and “greater than”. QAAL
(Kalaivani and Duraiswamy, 2012): results from a
comparison of different input types, query processing
methods, and the input and output formats of various
systems. The authors also analyzed and discussed dif-
ferent performance metrics in addition to their limita-
tions. QAAL uses a graph matching algorithm to as-
sociate the query with the answer (Collins and Loftus,
1975), thus improving its results in terms of generated
SPAQRL queries. Although QAAL uses NLP for im-
proving its accuracy, the adoption of keywords limits
the search scope, which detracts QAAL’s applicabil-
ity for complex questions. Also, QUAAL is limited
to closed domain and does not handle ambiguity.
Question Answering wiKiframework-based System,
QAKiS (Cabrio et al., 2012): a QALOD that ad-
dresses the problem of question interpretation as
correspondence with relationship-based ontology, in
which the fragments of the question correspond to
the binary relations in the ontology. QAKiS first
tries to match fragments with textual templates au-
tomatically collected from Wikipedia. QAKiS’s
relationship-based mapping for question interpreta-
tion allows to convert user questions into a query lan-
guage, e.g., SPARQL. However, QAKiS is heavily
tied to Wikipedia and DBpedia. PARALEX (Fader
et al., 2013): an interactive open domain QA system
that maps questions into simple queries over extrac-
tions made by an open information extraction sys-
tem (Banko et al., 2007). PARALEX executed on
an extracted KB and used sentences extracted from
Ontology-based Question Answering Systems over Knowledge Bases: A Survey
535

WikiAnswers to learn a query function for carrying
out queries over a KB.
SINA (Shekarpour et al., 2015): a scalable search
system for answering NL queries by transforming
user-supplied keywords or queries into SPARQL
queries over a set of interconnected data sources. In-
ternally, SINA uses a Markov Chain Model to de-
termine, from different datasets, which resources are
best suited to respond to each query. The key advan-
tage of this approach is its independency from on-
tology data schema: SINA generates a set of prede-
fined templates that scale to large knowledge bases
in an easy-to-use manner. DEANNA (Yahya et al.,
2012, 2013): as far as it was possible to investigate,
the only QA system that approaches QALD from a
formal Integer Linear Programming (ILP) perspec-
tive. DEANNA simultaneously addresses the prob-
lems of question decomposition and disambiguation
using an optimization model that combines phrase
selection and mapping into semantic targets. Con-
straints ensure that sentences are selected to preserve
their phrasal dependencies in the mapping image for
semantic destinations. However, there is no clear
evidence that this promising approach can be easily
adapted to other datasets or domains.
Hybrid Deep Relation Extraction for Question
Answering on Freebase, HybQA (Mohamed et al.,
2017): proposes a QA strategy focused on extract-
ing the relationship in a hybrid way over the Freebase
dataset, which consists of using state-of-the-art deep
neural networks to capture the type of relationship be-
tween a question and the expected answer. This re-
lationship is verified using Wikipedia to choose the
best relationship. Evaluation using HybQA over the
WebQuestions dataset showed an improvement over
existing models in terms of accuracy, which is 57%.
A Semantic-based Closed and Open Domain Ques-
tion Answering System, ScoQAS (Latifi et al., 2017;
Latifi, 2018): this system proposed a hybrid ap-
proach, i.e., handles factoid questions for both open
and closed domains. ScoQAS adopt QALD as a
golden standard for evaluation purposes. The main
differential of ScoQAS is using a set of graph infer-
ences for the closed domain. On the other hand, as its
main limitation, ScoQAS does not address complex
questions.
Figure 1 compares strategies in terms of accu-
racy. Initial approaches were domain-specific, so
these adopt a well-formed schema for a better ac-
curacy when compared to the latest approaches pro-
posed for open domain. ONLI (Mithun et al., 2007),
QAAL (Kalaivani and Duraiswamy, 2012), and PAR-
ALEX (Fader et al., 2013) do not adopt accuracy.
Figure 1: Accuracy for each approach found in this review.
6 RESEARCH CHALLENGES
Evidence found in the literature show that, whilst
domain-specific QA can be addressed with enough
manual effort, there is no single system capable of
answering complex questions regarding multiple do-
mains (see Table 1). Due to the breadth of the studies
and because they are recently published works, our
analysis of the articles shows that the following re-
search challenges are still open (H
¨
offner et al., 2017;
Diefenbach et al., 2018).
Lexical Gap (Hakimov et al., 2015). Despite the
advances experienced in the field, the same meaning
can still be expressed in many different ways using
natural language. Queries and KBs many times are
not built on top of the same vocabulary, i.e., using
synonyms or the same abstraction level. The lexi-
cal gap problem still occurs when a vocabulary used
in the question differs from that used when labeling
KBs, making it difficult for QA systems to find a link
or association between a question and its answer. This
seems to be a promising subject for future work in the
area, as tackling this challenge has resulted in a sig-
nificant improvement on the results reported by QA
systems (Petrochuk and Zettlemoyer, 2018).
Queries over Multiple Knowledge Bases. If the in-
formation that is referenced in a query is represented
by distributed RDF resources, then the corresponding
information need for formulating a proper answer can
be found in multiple bases. Performing a combination
of knowledge bases demands both schema-level and
entity-level matching to merge partial results or trans-
lations between databases. This is required to find
dataset entities that are semantically equivalent to a
single, “global” entity during the query execution.
Multilingual QA. The knowledge found in the
Web and information systems is written in multiple
languages. Although RDF resources can be described
multilingually by adopting language tags, there is no
single language that is always used in Web docu-
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
536
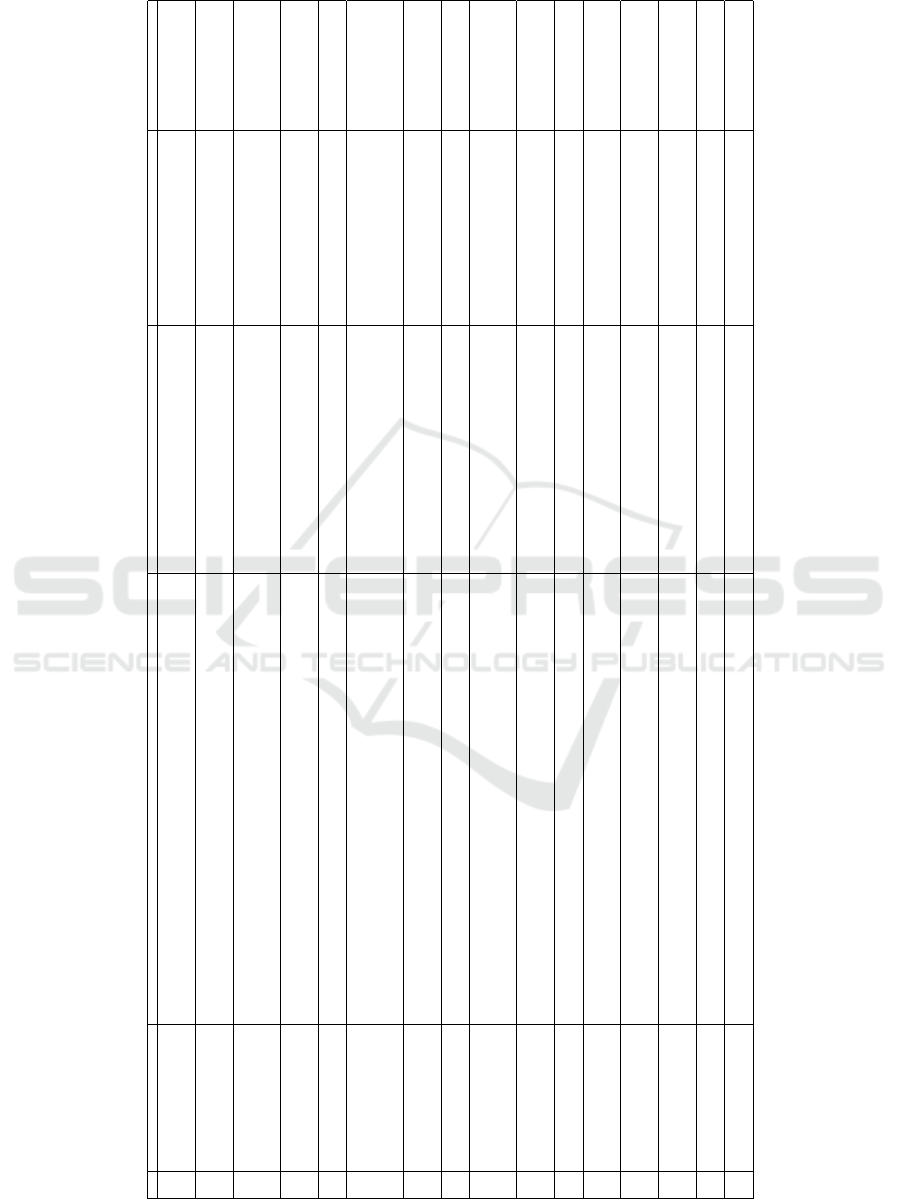
Table 1: Summary of works found in the literature about ontology-based QA systems.
ID QA Systems Characteristics Limitations Dataset Adopted Evaluation
T001 ONLI Mithun et al. (2007)
Queryes in NL with nRQL.
Syntactical Analysis.
Ontology Mapping.
Query interface for the Racer system.
Domain-dependent.
Limited analyzed question types.
Own (30 question and respective nRQL query pairs
for two genome-related onologies)
MRR (Mean Reciprocal Rank): 0.35
T002 PANTO Wang et al. (2007)
Uses WordNet and string similarity measures in ontology mapping algorithms.
NL question as input and outputs a SPARQL query.
QueryTriples as intermediary representation.
Converts queries into triples in OntoTriples.
Scalability: only works for small ontologies.
Does not use data indexing techniques.
Constraints the query scope.
Weak user interaction.
Mooney (http://www.cs.utexas.edu/users/ml/nldata.html)
Geographic basis, restaurant, and work.
Accuracy: 88.05%, 90.87%, 86.12%
Accuracy: 85.86%, 96.64%, 89.17%
T003 AquaLog Lopez et al. (2007)
Independent domain grammar.
Queries in LN.
Uses string similarity algorithms.
Uses GATE and WordNet platform.
Ontology-based relationship similarity Triple Response Service (RSS).
Lack of adequate reasoning services defined by ontology.
Does not understand queries in the format “How much”.
Does not explore scope quantifiers: (“each”, “all”, and “some”)
Own base built with 69 pairs of questions and answers.
Closed domain.
Accuracy: 58%
T004 QuestIO Tablan et al. (2008)
Open domain application.
Translates NL and keywords into SPARQL query by means of linguistic analysis.
Ontologic dictionary search.
Iterative Transformation until a SeRQL query is obtained.
Lacks user interaction.
Session-based.
Cannot solve ambiguity from terms of keywords.
36 specific-domain questions.
Accuracy: 50%
T005 QACID Ferr
´
andez et al. (2009)
Tested for Spanish over the cinema domain.
Query set build by means of clusters.
Query mapping between NL and knowledge bases using distance metrics,
Expensive due to the domain dependency.
Can only be applied with limited coverage.
Leaks conscient capacities of temporal and spatial context.
Closed domain.
162 question pairs.
Accuracy: 89%
T006 FREyA Damljanovic et al. (2010)
Open domain.
Identification and verification of ontology concepts.
SPARQL query generation.
Question type identification.
Reinforcement learning for improving the suggestion rank.
Session-based interaction.
Requires tests with large datasets.
Evaluation is not user-centered.
250 question from Mooney Geoquery
Accuracy: 92.4%
MRR: 78%
T007 QASYO Hogan et al. (2011)
Queries in NL.
YAGO as input.
The LN query is translated into a set of intermediate and triple-base representations, query traps.
Translates into ontology-compatible triples.
Lacks information about the nature and complexity of possibly
necessary changes in the ontology and the linguistic component.
-
Accuracy: 84,7%
T008 Pythia Unger and Cimiano (2011)
Handles with a wide range of linguistically complex questions involving quantifiers, numerals, comparisons, superlatives, and negation.
Correctly maps NL terms into the corresponding ontology concepts, despite these are superficially different.
The domain-specific lexical is built automatically from an specification of linguistic realizations of the concept ontology.
Portability (requires a new LexInfo model for a new domain to be built);
Requires not negligible effort for larger domains (DBpedia, for example)
880 questions from Mooney Geoquery
Accuracy: 82%
T009 DEQA Lehmann et al. (2012)
Application for the Web of Data.
Uses the TBSL algorithm.
Compreensive deep Web QA system.
Web extractions using OXPath.
Usses LIMES to compute complex links for specification.
Needs to cover more question types.
Does not support complex operators.
Does not support multiple languages.
100 domain-specific questions
Accuracy: 57%
T010 QAAL Kalaivani and Duraiswamy (2012)
Uses concept graph matching.
Adopts SPARQL.
Uses NLP for QA analysis.
Diffuse activation algorithm.
Normal keyword search model.
Cannot answer to complex questions in ambiguous cases.
Closed domain.
Mean Accuracy Distribution
T011 QAKiS Cabrio et al. (2012)
Open domain.
QA structured over the knowledge base.
Relevant information in unstructured form.
Cannot handle boolean and n-related questions.
Cannot perform
Procedural, Temporal or Spatial analyzes.
QALD-2 (DBPedia).
Accuracy: 39%
T012 PARALEX Fader et al. (2013)
Open domain.
Transforms text into tuple.
Learning oriented to paragraph interpreting questions.
No manual model must be created.
Not able to work with complex questions.
Lack of “answerability”.
WebQuestions (2,032).
TREC (517).
WikiAnswers (7,310).
Accuracy: 77%
T013 SINA Shekarpour et al. (2015)
Open domain.
Tries to reduce the lexical gap.
Uses Hidden Markov Chain.
Template-based.
Cannot perform Procedural, Temporal or Spatial analyzes.
Does not support complex operations.
Does not support multiple languages.
QALD-3.
Accuracy: 32%
MRR: 0.8
T014 DEANNA Yahya et al. (2012, 2013)
Integer Linear Programming (ILP) approach.
Query extension for SPO and SPOX.
Query relaxation when no results are found.
Cannot perform Procedural, Temporal, or Spatial analyzes.
Does not support complex operations.
Does not support multiple languages.
Does not adopt templates.
QALD-1.
NAGA.
Accuracy: 55%
T015 HybQA Mohamed et al. (2017)
Hybrid approach.
Open domain.
Relation Extraction
Does not handle complex questions; WebQuestions
Accuracy: 57%
T016 ScoQAS Latifi et al. (2017); Latifi (2018)
Hybrid approach.
Open and Closed domain.
Graph inferences,
Does not handle complex questions;
QALD-2.
QALD-3.
QALD-4.
Accuracy: 60%
Ontology-based Question Answering Systems over Knowledge Bases: A Survey
537

ments, for example. For a QA system, the big chal-
lenge is mediating between the user’s need for infor-
mation in her own language and the available seman-
tic data avoiding idiosyncrasies, expression gaps, and
other limitations relevant to machine translation.
7 CONCLUSION
This survey analyzed approaches for QA systems that
resort to ontologies for answering questions in both
open and closed domains. There is a relatively large
number of approaches following this for building QA
systems on top of ontologies. In this paper, we an-
alyzed the 15 main strategies found in the literature,
by (1) comparing their strengths and weaknesses, (2)
highlighting the importance of ontologies in the QA
process, (3) characterizing each system in terms of its
fundamentals and choices, and (4) distinguishing the
differences between existing systems.
A strong point of this type of system is the use of
the ontology schema to enrich the query construction,
the lack of data for training, and richer query con-
struction. The main weaknesses are the need for prior
knowledge of the schema used in the ontology and the
manual steps usually performed in the process, such
as mapping elements, etc.
As future works, we are already developing efforts
over interesting topics arising from this investigation:
to train new architectures on this problem; investi-
gate other factual question/knowledge bases and their
respective influence on the accuracy of the models;
and address specific research challenges outlined in
Section 5, such as Queries over Multiple Knowledge
Bases and answering Complex Questions..
REFERENCES
Baader, F., Calvanese, D., McGuinness, D., Patel-
Schneider, P., and Nardi, D. (2003). The description
logic handbook: Theory, implementation and applica-
tions. Cambridge university press.
Banko, M., Cafarella, M. J., Soderland, S., Broadhead, M.,
and Etzioni, O. (2007). Open information extraction
from the web. In Ijcai, volume 7, pages 2670–2676.
Berant, J., Chou, A., Frostig, R., and Liang, P. (2013).
Semantic parsing on freebase from question-answer
pairs. In EMNLP, pages 1533–1544.
Bizer, C., Lehmann, J., Kobilarov, G., Auer, S., Becker, C.,
Cyganiak, R., and Hellmann, S. (2009). Dbpedia-a
crystallization point for the web of data. Web Seman-
tics: science, services and agents on the world wide
web, 7(3):154–165.
Bollacker, K., Evans, C., Paritosh, P., Sturge, T., and Taylor,
J. (2008). Freebase: a collaboratively created graph
database for structuring human knowledge. In ACM
SIGMOD, pages 1247–1250. AcM.
Bordes, A., Usunier, N., Chopra, S., and Weston, J. (2015).
Large-scale simple question answering with memory
networks. arXiv preprint arXiv:1506.02075.
Cabrio, E., Cojan, J., Aprosio, A. P., Magnini, B., Lavelli,
A., and Gandon, F. (2012). Qakis: an open domain qa
system based on relational patterns. In ISWC 2012.
Cimiano, P., Lopez, V., Unger, C., Cabrio, E., Ngomo, A.-
C. N., and Walter, S. (2013). Multilingual question
answering over linked data (qald-3): Lab overview. In
CLEF, pages 321–332. Springer.
Cimiano, P. and Minock, M. (2009). Natural language inter-
faces: what is the problem?–a data-driven quantitative
analysis. In nldb, pages 192–206. Springer.
Cohen, W. W., Ravikumar, P., Fienberg, S. E., et al. (2003).
A comparison of string distance metrics for name-
matching tasks. In IIWeb, volume 2003, pages 73–78.
Collins, A. M. and Loftus, E. F. (1975). A spreading-
activation theory of semantic processing. Psychologi-
cal review, 82(6):407.
Daconta, M. C., Obrst, L. J., and Smith, K. T. (2003). The
Semantic Web: a guide to the future of XML, Web
services, and knowledge management. John Wiley &
Sons.
Damljanovic, D., Agatonovic, M., and Cunningham, H.
(2010). Natural language interfaces to ontologies:
Combining syntactic analysis and ontology-based
lookup through the user interaction. In ESWC, pages
106–120. Springer.
De Marneffe, M.-C. and Manning, C. D. (2008). The
stanford typed dependencies representation. In
Coling 2008: proceedings of the workshop on
cross-framework and cross-domain parser evaluation,
pages 1–8. Association for Computational Linguis-
tics.
Diefenbach, D., Lopez, V., Singh, K., and Maret, P. (2018).
Core techniques of question answering systems over
knowledge bases: a survey. Knowledge and Informa-
tion systems, 55(3):529–569.
Fader, A., Zettlemoyer, L., and Etzioni, O. (2013).
Paraphrase-driven learning for open question answer-
ing. In 51st ACL, volume 1, pages 1608–1618.
Ferr
´
andez, O., Izquierdo, R., Ferr
´
andez, S., and Vicedo,
J. L. (2009). Addressing ontology-based question an-
swering with collections of user queries. Information
Processing & Management, 45(2):175–188.
Freitas, A., Curry, E., Oliveira, J. G., and O’Riain, S.
(2012). Querying heterogeneous datasets on the
linked data web: Challenges, approaches, and trends.
IEEE Internet Computing, 16(1):24–33.
Haarslev, V. and M
¨
oller, R. (2001). Racer system descrip-
tion. In IJCAR, pages 701–705. Springer.
Haarslev, V., M
¨
oller, R., and Wessel, M. (2004). Query-
ing the semantic web with racer + nrql. In ADL’04,
volume 24.
Hakimov, S., Tunc, H., Akimaliev, M., and Dogdu, E.
(2013). Semantic question answering system over
linked data using relational patterns. In EDBT/ICDT
2013 Workshops, pages 83–88. ACM.
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
538

Hakimov, S., Unger, C., Walter, S., and Cimiano, P. (2015).
Applying semantic parsing to question answering over
linked data: Addressing the lexical gap. In NLDB,
pages 103–109. Springer.
Herzog, O. and Rollinger, C.-R. (1991). Text understanding
in LILOG: integrating computational linguistics and
artificial intelligence: final report on the IBM Ger-
many LILOG-Project. Springer.
Hirschman, L. and Gaizauskas, R. (2001). Natural language
question answering: the view from here. natural lan-
guage engineering, 7(4):275–300.
Hoffart, J., Suchanek, F. M., Berberich, K., and Weikum,
G. (2013). Yago2: A spatially and temporally en-
hanced knowledge base from wikipedia. Artificial In-
telligence, 194:28–61.
H
¨
offner, K., Walter, S., Marx, E., Usbeck, R., Lehmann, J.,
and Ngonga Ngomo, A.-C. (2017). Survey on chal-
lenges of question answering in the semantic web. Se-
mantic Web, 8(6):895–920.
Hogan, A., Harth, A., Umbrich, J., Kinsella, S., Polleres,
A., and Decker, S. (2011). Searching and browsing
linked data with swse: The semantic web search en-
gine. Web semantics: science, services and agents on
the world wide web, 9(4):365–401.
Kalaivani, S. and Duraiswamy, K. (2012). Comparison of
question answering systems based on ontology and se-
mantic web in different environment. In Journal of
Computer Science. Citeseer.
Latifi, M. (2018). Using natural language processing
for question answering in closed and open domains.
PhD thesis, Universitat Polit
`
ecnica de Catalunya,
Barcelona.
Latifi, M., Rodr
´
ıguez Hontoria, H., and S
`
anchez-Marr
`
e, M.
(2017). Scoqas: A semantic-based closed and open
domain question answering system. Procesamiento
del Lenguaje Natural.
LeCun, Y., Bengio, Y., and Hinton, G. (2015). Deep learn-
ing. nature, 521(7553):436.
Lehmann, J., Furche, T., Grasso, G., Ngomo, A.-C. N.,
Schallhart, C., Sellers, A., Unger, C., B
¨
uhmann, L.,
Gerber, D., H
¨
offner, K., et al. (2012). Deqa: deep web
extraction for question answering. In ISWC, pages
131–147. Springer.
Lopez, V., Unger, C., Cimiano, P., and Motta, E. (2013).
Evaluating question answering over linked data. Web
Semantics: Science, Services and Agents on the World
Wide Web, 21:3–13.
Lopez, V., Uren, V., Motta, E., and Pasin, M. (2007). Aqua-
log: An ontology-driven question answering system
for organizational semantic intranets. Web Semantics:
Science, Services and Agents on the World Wide Web,
5(2):72–105.
Miller, G. A. (1995). Wordnet: a lexical database for en-
glish. Communications of the ACM, 38(11):39–41.
Mishra, A. and Jain, S. K. (2016). A survey on question an-
swering systems with classification. Journal of King
Saud University-Computer and Information Sciences,
28(3):345–361.
Mithun, S., Kosseim, L., and Haarslev, V. (2007). Resolv-
ing quantifier and number restriction to question owl
ontologies. In SKG 2007, pages 218–223. IEEE.
Mohamed, R., El-Makky, N. M., and Nagi, K. (2017). Hy-
bqa: Hybrid deep relation extraction for question an-
swering on freebase. In KEOD, pages 128–136.
Paolacci, G., Chandler, J., and Ipeirotis, P. G. (2010). Run-
ning experiments on amazon mechanical turk. Judg-
ment and Decision making, 5(5):411–419.
Petrochuk, M. and Zettlemoyer, L. (2018). Simplequestions
nearly solved: A new upperbound and baseline ap-
proach. arXiv preprint arXiv:1804.08798.
Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. (2016).
Squad: 100,000+ questions for machine comprehen-
sion of text. arXiv preprint arXiv:1606.05250.
Seaborne, A. and Prud’hommeaux, E. (2008). Sparql query
language for rdf. w3c recommendation. WWW, 15.
Shekarpour, S., Marx, E., Ngomo, A.-C. N., and Auer, S.
(2015). Sina: Semantic interpretation of user queries
for question answering on interlinked data. Journal of
Web Semantics, 30:39–51.
Soares, M. A. C. and Parreiras, F. S. (2018). A literature
review on question answering techniques, paradigms
and systems. Journal of King Saud University-
Computer and Information Sciences.
Suchanek, F. M., Kasneci, G., and Weikum, G. (2007).
Yago: a core of semantic knowledge. In 16th WWW,
pages 697–706. ACM.
Suchanek, F. M., Kasneci, G., and Weikum, G. (2008).
Yago: A large ontology from wikipedia and wordnet.
Web Semantics: Science, Services and Agents on the
World Wide Web, 6(3):203–217.
Tablan, V., Damljanovic, D., and Bontcheva, K. (2008). A
natural language query interface to structured infor-
mation. In ESWC, pages 361–375. Springer.
Tasar, C. O., Komesli, M., and Unalir, M. O. (2018). Sys-
tematic mapping study on question answering frame-
works over linked data. IET Software, 12(6):461–472.
Unger, C. and Cimiano, P. (2011). Pythia: Compositional
meaning construction for ontology-based question an-
swering on the semantic web. In NLDB, pages 153–
160. Springer.
Wang, C., Xiong, M., Zhou, Q., and Yu, Y. (2007). Panto:
A portable natural language interface to ontologies. In
ESWC, pages 473–487. Springer.
Weikum, G., Hoffart, J., and Suchanek, F. (2019). Knowl-
edge harvesting: achievements and challenges. In
Computing and Software Science, pages 217–235.
Springer.
Wilensky, R., Chin, D. N., Luria, M., Martin, J., Mayfield,
J., and Wu, D. (1988). The berkeley unix consultant
project. Computational Linguistics, 14(4):35–84.
Wohlgenannt, G., Mouromtsev, D., Pavlov, D., Emelyanov,
Y., and Morozov, A. (2019). A comparative evalua-
tion of visual and natural language question answering
over linked data. arXiv preprint arXiv:1907.08501.
Yahya, M., Berberich, K., Elbassuoni, S., Ramanath, M.,
Tresp, V., and Weikum, G. (2012). Natural language
questions for the web of data. In 2012 EMNLP-
IJCNLP, pages 379–390. Association for Computa-
tional Linguistics.
Yahya, M., Berberich, K., Elbassuoni, S., and Weikum, G.
(2013). Robust question answering over the web of
linked data. In 22nd ACM CIKM, pages 1107–1116.
ACM.
Ontology-based Question Answering Systems over Knowledge Bases: A Survey
539
