
Publishing and Consuming Semantic Views for Construction of
Knowledge Graphs
Narciso Arruda
1 a
, Amanda D. P. Venceslau
1 b
, Matheus Mayron
1
, V. M. P. Vidal
1
and V. M. Pequeno
2 c
1
Departamento de Computação, Federal University of Ceará, Fortaleza, Ceará, Brazil
2
TechLab, Departamento de Ciências e Tecnologias, Universidade Autónoma de Lisboa Luís de Camões, Portugal
Keywords:
Knowledge Graph, Semantic Integration, Vocabulary, Data Quality, Semantic View.
Abstract:
The main goal of semantic integration is to provide a virtual semantic view that is semantically connected to
data so that applications can have integrated access to data sources through the virtual Knowledge Graph. A
semantic view can be published on a semantic portal to make it reusable for building Knowledge Graphs for
different applications. This paper takes the first step towards publishing a semantic view on a semantic portal.
This paper has three main contributions. First, we introduce a vocabulary for specifying semantic views. Then,
we introduce a vocabulary for specification and quality assessment of Knowledge Graph. Third, we describe
an approach to automatize the construction of a high-quality Knowledge Graph reusing a semantic view.
1 INTRODUCTION
In recent years, with the increase in the amount of
public data available, it has also increased the number
of applications that demand large volumes of hetero-
geneous data in order to allow greater accuracy in data
analysis. These types of applications require the cre-
ation of a homogeneous view of the data.
Recently, the term Knowledge Graph (KG) has
been used in association with Semantic Web tech-
nologies, linked data, large-scale data analytics and
cloud computing (Ehrlinger and Wöß, 2016). The use
of knowledge graphs is on the rise as a way of build-
ing homogeneous knowledge bases as a graph struc-
ture, combine different heterogeneous databases.
In the literature, the virtual Knowledge Graph
(VKG) approach has been discussed in a paradigm
known as ontology-based data access (OBDA) (Xiao
et al., 2018). The VKG approach proposes to use
one consistent virtual graph, more flexible than a
rigid table structure and embed domain knowledge
(Xiao et al., 2019). In VKG, integration views are
virtual, which enables simplified design and mainte-
nance as these views can be tested and modified in-
stantly. However, the amount of data encountered can
a
https://orcid.org/0000-0003-3873-8468
b
https://orcid.org/0000-0003-4118-4224
c
https://orcid.org/0000-0002-6424-0252
cause query performance bottlenecks and to remedy
this problem, many organizations create copies of the
data, also called specialized Knowledge Graph, mate-
rializing a portion of the data as required. In addition,
specialized Knowledge Graph goes through a process
of conflict resolution and the use of data quality met-
rics that allow queries over a consolidated database.
We call semantic integration the process that
makes use of a conceptual representation of the data
and its relationship to deal with heterogeneity. The
main goal of semantic integration is to provide a vir-
tual semantic view, which is semantically connected
to data so that applications can have integrated access
to data sources. To make the semantic view reusable,
it should be published on a Semantic Portal, which
is intended to consolidate and semantically integrate
large numbers of heterogeneous data sources into a
comprehensive dataspace. Chem2bio2rdf (Bleiholder
and Naumann, 2010), SemanticDB (D Pierce et al.,
2012), and SemanticSUS (da Cruz et al., 2019) are
examples of semantic portals.
Once a semantic view (see, Section 2) has been
specified and published, semantic integration has al-
ready been performed a priori, so it can be used to
build a virtual Knowledge Graph or reused to build
specialized Knowledge Graph using Mashup View
(see, Section 3), which can also be published and ac-
cessed by external applications. The semantic view
allows integration approaches like (Collarana et al.,
Arruda, N., Venceslau, A., Mayron, M., Vidal, V. and Pequeno, V.
Publishing and Consuming Semantic Views for Construction of Knowledge Graphs.
DOI: 10.5220/0009421401970204
In Proceedings of the 22nd International Conference on Enterprise Information Systems (ICEIS 2020) - Volume 1, pages 197-204
ISBN: 978-989-758-423-7
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
197

Figure 1: Three Level Framework for Semantic View Spec-
ification.
2017; Schultz et al., 2011), to be able to define the in-
tegration steps, providing the reuse and reduction of
time-consuming for design other applications.
This paper takes the first step towards publishing
a semantic view. The proposed approach combines
ontologies and linked data to face the challenges in
developing applications where there is a need to in-
tegrate heterogeneous data sources. The paper has
three main contributions, which are described in sec-
tions 2, 3 and 4. Section 2 introduces a vocabulary
for specifying a semantic view. A semantic view is
specified with the help of local views and sameAs
linkset views. Section 3 introduces a vocabulary
for specification and quality assessment of Knowl-
edge Graphs, providing relevant source information
and quality metrics to benefit applications that aim
to build high quality KG (Collarana et al., 2017). It
also discusses how to reuse a semantic view specifi-
cation for semi-automatic generation of a Knowledge
Graph. Section 4 describes an approach for building
high-quality Knowledge Graphs based on the quality
metadata of a semantic view. Finally, Section 5 con-
tains the conclusions.
2 SEMANTIC VIEW
In this section, we discuss a three-level ontology-
based framework (Vidal et al., 2015), as summarized
in Figure 1, to formally specify semantic view and a
vocabulary to represent this specification and meta-
data.
2.1 Semantic View Specification
In the proposed framework, the semantic view re-
sulting from semantic integration over data sources
S
1
, . . . , S
n
is a triple λ = (O
D
, V, L), where:
• O
D
represents the domain ontology (semantic
view layer). O
D
is responsible for establishing
a vocabulary to be shared to describe the data
sources;
• V represents a set of local view specifications
V
1
, . . . , V
n
that describes the data sources S
1
, . . . , S
n
using the terms in O
D
. A local view specification
V
i
is a tuple (O
Vi
, M
Vi
), where:
– O
Vi
is the ontology of the local view. The vo-
cabulary of O
Vi
is a subset of the vocabulary of
O
D
whose terms occur in M
Vi
.
– M
Vi
is a set of mappings that relate terms of
vocabulary O
D
with terms Si;
• L is a set of linkage rules that specify virtual
sameAs links between resources in different lo-
cal views. These links are used to relate resources
that represent the same entity of the real world.
We consider two types of sameAs links: imported
sameAs links, which are exported by a Linked
Data source, and mashup sameAs links, which are
automatically created based on a sameAs linkset
view specification (Casanova et al., 2014) specifi-
cally defined for the mashup application;
The process for generating the semantic view spec-
ification λ consists of 3 steps: (1) Modeling of the
domain ontology; (2) Generation of the local views
specifications; (3) Generation of the linkage rules.
2.2 Semantic View Vocabulary
The vocabulary for describing semantic view (VSV)
is partitioned in three categories: General Metadata,
View Specification Metadata and Quality Metadata.
Given that a semantic view is a virtual dataset, the vo-
cabulary for general metadata uses the terms in VoID
vocabulary (Hartig and Zhao, 2010) for providing ba-
sic metadata about a dataset. VoID (prefix void:) is
an RDF Schema vocabulary for expressing metadata
about RDF datasets. It is intended as a bridge be-
tween the publishers and users of RDF data, with ap-
plications ranging from data discovery to cataloging
and archiving of datasets. The main terms in VoID
for general metadata are: dcterms:description, dc-
terms:created, dcterms:license, dcterms:source, dc-
terms:Source and dcterms:vocabulary.
The vocabulary for expressing metadata about
a semantic view specification is defined as OWL
ontology. Fig. 3 shows the main fragment of the
VSV vocabulary (prefix vsv:). The main classes
and properties are: vsv:SemanticViewSpecification,
owl:Ontology, vsv:LocalView, vsv:LinkageRule,
vsv:QualityMetadata, vsv:hasQualityMetadata,
vsv:hasLocalView. The vocabulary was developed
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
198
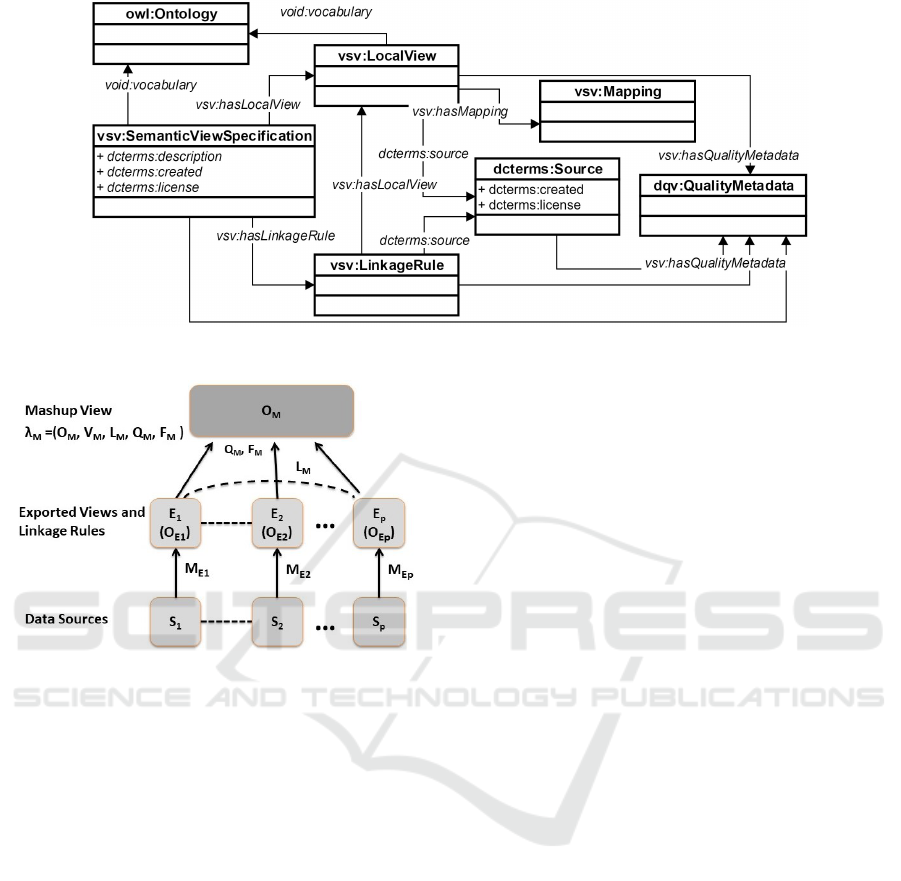
Figure 2: A Fragment of the Semantic View Specification Vocabulary.
Figure 3: Three Level Framework for Mashup View Speci-
fication.
with understandability and usability in mind. For this
reason, we apply a consistent scheme for property
names, using "has" followed by a class name.
For expressing metadata about the quality of a se-
mantic view, we use the terms in Data Quality Vo-
cabulary (DQV) (prefix dqv:) (Debattista et al., 2016)
discussed in Section 4. In our framework, the quality
of semantic views is computed based on the quality of
the local views and quality of the linkset Views. For
more details see (Zaveri et al., 2013).
3 MASHUP VIEW
The creation of a mashup view is a complex task
which involves four major challenges: (1) selection of
the Linked Data sources that are relevant for the ap-
plication; (2) extraction and translation of data from
different, possibly heterogeneous data sources to a
common vocabulary; (3) identification of links be-
tween resources in different Linked Data sources; (4)
combination and fusion of multiple representations of
the same real-world object into a single representation
and resolution of data inconsistencies to improve the
quality of the data.
In this section, we present an ontology-based
framework (Vidal et al., 2015) used in our approach
to specifying a mashup view, and a vocabulary to
represent this specification and metadata. The ma-
terialization of a mashup view is calling special-
ized Knowledge Graph, it is automatically processed
based on its specification.
3.1 Mashup View Specification
We use a three level ontology-based framework Vi-
dal et al. (2015), as summarized in Figure 3, to
formally specify Knowledge Graph. The specifica-
tion of a Knowledge Graph M is a quintuple, λ =
(O
M
, V
M
, L
M
, F
M
, Q
M
), where:
• O
M
is the mashup view ontology;
• V
M
is a set of exported view specifications
E
1
, ..., E
n
that describes the data sources S
1
, ..., S
n
using the terms in O
M
. Each view E
i
is a tuple
(M
Ei
, O
Ei
), where:
– M
Ei
is a set of rules that relate terms of vocab-
ulary O
M
with terms of vocabulary Si;
– O
Ei
is the ontology of the exported view E
i
.
The vocabulary of O
Ei
is a subset of the vocab-
ulary of O
M
whose terms occur in M
Ei
.
• L
M
is a set of linked view specifications L
1
, ..., L
m
between E
1
, ..., E
n
. We consider two types of
sameAs links: imported sameAs links, which are
exported by a Linked Data source, and mashup
sameAs links, which are automatically created
based on a sameAs linkset view specification
Casanova et al. (2014) specifically defined for the
mashup application;
Publishing and Consuming Semantic Views for Construction of Knowledge Graphs
199

• Q
M
is a set of quality requirements, which are re-
quested by the user application;
• F
M
is a set of fusion rules that specify how to re-
solve the problem of contradictory attribute val-
ues when combining multiple representations of
the same real-world object into a single represen-
tation (canonical IRI).
The process for generating the mashup view speci-
fication, without reusing a semantic view specifica-
tion, consists of 4 steps: (1) Modeling of the mashup
view ontology; (2) Generation of the exported views
specifications; (3) Generation of the exported sameAs
linkset view specifications; (4) Definition of quality
requirements and fusion rules. Note that, steps 2-4 re-
quires semantic integration of the data source, which
is not an easy task.
In case that a semantic view is previ-
ously specified, semantic integration is done
a priori, and a mashup view specification
λ = (O
M
, V
M
, L
M
, Q
M
, F
M
), can be automatically
generated based on O
M
, Q
M
, and the semantic
view specification λ = (O
D
, V, L). In this case, the
vocabulary of O
M
is a subset of the vocabulary of O
D
,
therefore O
M
can be defined using a faceted search
interface by selecting concepts and specifying filters.
3.2 Mashup View Vocabulary
The vocabulary for describing a mashup view (MV)
is partitioned in three categories: General Metadata,
Data Mashup View Specification Metadata and
Quality Metadata. The vocabularies for general
and quality metadata is the same one used by the
semantic view and discussed in previous section. The
vocabulary for expressing metadata about a mashup
view specification is defined as an OWL ontology.
Figure 4 shows a fragment of the MV vocabulary
(prefix mv:). The main classes and properties
are: mv:MashupViewSpecification, owl:Ontology,
mv:ExportedViewSpecification, mv:LinkageRule,
dqv:QualityMetadata, mv:hasQualityMetadata,
mv:hasExportedViewS.
4 BUILDING HIGH-QUALITY
KNOWLEDGE GRAPH
We start this section by presenting the main concepts
of data quality and then discuss how to represent those
concepts using the DQV vocabulary. We conclude
this section by summarizing a data quality assessment
methodology.
4.1 Data Quality Vocabulary
The standardized formulation of data quality in
RDF/OWL facilitates transparency, verification, and
sharing of linked data quality. Data on Web Best
Practices (DWBP) point to the importance of publish-
ing data quality information about data on the Web.
For this purpose, the DWBP created a vocabulary to
express data quality, called Data Quality Vocabulary
(DQV) (Debattista et al., 2016).
Data quality is commonly conceived as a multi-
dimensional construction with dimensions such as
timeliness, completeness, consistency, interoperabil-
ity, conciseness, representational conciseness and
availability (Wang and Strong, 1996). The quality
dimensions are composed of quality metrics, which
measure the quality of the data along the dimensions
(Bizer and Cyganiak, 2009). More specifically, qual-
ity metrics are heuristics designed to fit a specific as-
sessment situation Wang (2005).
Figure 5 shows a fragment of the DQV vo-
cabulary. The DQV vocabulary distinguishes be-
tween three layers of abstraction (metric, dimen-
sions, and category), based on a survey presented in
(Zaveri et al., 2016). Quality metrics (dqv:Metric)
are grouped into quality dimension (dqv:Dimension),
by property dqv:inDimension. Quality dimensions
are grouped into quality category (dqv:Category), by
property dqv:inCategory. dqv:QualityMeasurement
represents a quality metric measure of a given re-
source (rdfs:Resource), a resource can be a set of data,
a set of links, a graph or a set of triples in which qual-
ity measurement is performed.
Many quality metrics have been proposed to as-
sess the quality of Linked Data sources because of the
importance and use of this data (Zaveri et al., 2016).
For example, in Table 1 the metrics M8 and M9 as-
sess the quality of the interoperability dimension and
the metrics M5, M6, and M7 assess the quality of the
accessibility category.
4.2 Materialization and Quality
Assessment of Knowledge Graph
In this section, we propose a method for generation
and quality assessment of knowledge graph. To be
useful, a knowledge graph must have good quality.
Quality assessment of knowledge graph is not a sim-
ple process, as it involves other factors such as qual-
ity of data sources, quality of mappings, and quality
of sameAs links. Normally, KG quality is calculated
along at least three dimensions (Dong and Naumann,
2009): completeness, conciseness, and consistency.
Consistency expresses how much the data are in the
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
200

Figure 4: A Fragment of the Mashup View Specification Vocabulary.
dqv:QualityMeasurement
+ dqv:value
rdfs:Resource
+
dqv:computedOn
dqv:Metric
+ dqv:expectedDataType
dqv:Dimensiondqv:Category
dqv:inDimension
q
q
v
:
M
e
t
dqv:isMeasurementOf
dqv:inCategory
q
dqv
:
y
QualityMeas
esource
rc
e
dqv:hasQualityMeasurement
Figure 5: A Fragment of the DQV Vocabulary.
real world, while completeness and conciseness are,
in a way, analogous to recall and precision in infor-
mation retrieval (Knap et al., 2012).
As shown in Figure 6, materialization is per-
formed incrementally, and at each step, the quality
of the triples and datasets (materialized views) gener-
ated is also computed. The process of computing data
quality is called quality assessment, in which process
quality metadata is computed to measure data quality.
Thus, errors can be detected by directing modifica-
tions that increase the quality of the data.
Table 2 shows quality metrics of exported view,
linkset view and mashup view used to quality assess-
ment of consistency dimension. The consistency of
the mashup view is computed by the quality metrics
MV M1, MV M2, and by the consistency of the in-
stances of mashup view, that is computed by the con-
sistency of its triples. Which in turn is computed by
the metrics MV M3 and MV M4, and by the consis-
tency of the exported views and linkset views. The
consistency of the exported views and linkset views
are computed by the metrics LV M1, LV M2 and met-
rics EV M1, EV M1, respectively. They depend on
the consistency of the data source, the consistency of
the linkset view also depends on the consistency of
the exported views.
The generation of KG is processed automatically
using as input the mashup view specification, data
sources and quality metadata from data sources. As
shown in Figure 6, the process for building the spe-
cialized knowledge graph consists of 3 steps, de-
scribed in following.
Step 1. Materialization and Quality Assessment of
Exported Views
In this step, each view in is materialized using the
mappings. In this step, the quality of the exported
view is also computed based on the quality metadata
of the data sources, mapping rules, and the exported
view materialization.
Step 2. Materialization and Quality Assessment of
Linkset Views
This step identifies and materializes sameAs links.
Each view is materialized using the linkage rule.
Due to the importance of sameAs links, various ap-
proaches have been proposed to compute link quality,
for example, based on functional properties (Papaleo
et al., 2014) and using network measurements (Guéret
et al., 2012)
Step 3. Data Fusion and Quality Assessment of
Knowledge Graph
In this step, the fusion of multiple representations
representing the same real-world entity into a single
representation is performed. Fusion rules in F define
how to solve the problem of conflicts that can occur
in fusion objects. Resolving data inconsistency im-
proves the quality of knowledge graph.
In the proposed framework, the specification of
quality requirements, with the help of the user, should
help in choosing which function to use to resolve a
particular type of conflict. For example, if the user
opts for a more complete mashup view, conflicts be-
tween values are not resolved.
As shown in Figure 6, during the data fusion pro-
cess, the quality assessment of the generated triples
Publishing and Consuming Semantic Views for Construction of Knowledge Graphs
201

Table 1: Examples of Metrics, Dimensions and Categories.
Category Dimension Metric
Intrinsic Consistency M1 (Usage of incorrect domain or range data type)
M2 (Misuse owl:DatatypeProperty or owl:ObjectProperty)
M3 (Entities as members of disjoint classes)
Conciseness M4 (Provides a measure of the redundancy of the dataset)
Accessibility Availability M5 (desereferentiability of the URI)
M6 (SPARQL endpoint availability)
M7 (RDF dump availability)
Representa- Interopera- M8 (existing terms reuse)
tiol bility M9 (existing vocabulary reuse)
Concision M10 (short URIs)
Table 2: Quality Metrics of the Consistency Dimension for Knowledge Graph.
Factor Metric Description
Mashup View MV_M1 conformance of the source ontology and mashup ontology
(schema consistency) (Wang (2012))
MV_M2 mappings conforms to the semantics of information
represented (mapping consistency) (Wang (2012))
MV_M3 difference between value v and other (conflicting) values (Knap et al. (2012))
MV_M4 confirmation values (Knap et al. (2012))
Exported View EV_M1 The degree to which exported ontology is free
of (logical/formal) contradictions (Zaveri et al. (2016))
EV_M2 Proportion of mappings in the exported view
error-free (Zaveri et al. (2016))
Linkset View LV_M1 measures the similarity of instances linked to sameAs based
on functional properties (Papaleo et al. (2014))
LV_M2 measures the similarity of instances linked to sameAs
based on linkage in linkset view
is performed. The quality of export views and links
are important in determining the quality of the triple,
also taking into account the equality and similarity of
conflicting values (Knap et al., 2012).
5 CONCLUSIONS AND FUTURE
WORK
This paper introduces a framework to publishing vir-
tual Knowledge Graph on a semantic portal. First, we
introduce a vocabulary for specifying semantic views.
Then, we introduce a vocabulary for specification and
quality assessment of Data Mashup view. Third, we
describe an approach to automatize the construction
of a high-quality Knowledge Graph reusing a seman-
tic view specification. The proposed vocabularies as
provides metadata for describing quality information
about the semantic view and the mashup view. The
quality information provided by the proposed vocab-
ulary, enables the data quality assessment.
As a case study, we built SemanticSUS
1
, a se-
mantic portal which is intented to offer a semantic
view that semantically integrates data sources from
the unified health system of Brazil (SUS). In its cur-
rent state, SemanticSUS semantically integrates three
SUS data sources which are available on the GISSA
platform (Freitas et al., 2017). The portal semantic
View was used to generate the specification of the
knowledge graph NDR (Neonatal Death Risk). The
RMN mashup integrates information about children
who lived less then 28 days (neonatal period), and it
was used to develop a predictive model to establish
the risk of neonatal death.
As a suggestion for future work, new metrics can
be incorporated into the quality vocabulary. In (Ar-
ruda et al., 2019) we propose a Fuzzy evaluation ap-
proach to allow the creation of semantic rules (close
to spoken language) to relate and evaluate the quality
of the linked data. So using this fuzzy approach con-
tribute to a more comprehensive quality assessment.
1
https://semanticsus.github.io/semanticSUS/index.html
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
202

Figure 6: Knowledge Graph Materialization.
We are also developing a tool to facilitate the process
of building high-quality Data Mashup views and in-
cremental maintenance by reusing a Semantic view
specification (Arruda, 2019). In our approach, the
Data Mashup view is generated in three steps: first,
the user specifies the mashup view ontology and
the quality requirements of the mashup application.
Then, the specification of the mashup view is auto-
matically generated by reusing the mapping and link-
age rules defined by the semantic view specification.
Finally, the materialization and quality assessment of
the Data Mashup view is automatically accomplished
using the strategy described in Section 4.
REFERENCES
Arruda, N. (2019). Framework for construction and in-
cremental maintenance of high-quality linked data
mashup. In International Conference on Conceptual
Modeling, pages 213–221. Springer.
Arruda, N., Alcântara, J., Vidal, V., Brayner, A., Casanova,
M., Pequeno, V., and Franco, W. (2019). A fuzzy ap-
proach for data quality assessment of linked datasets.
In Proc. of the 21st Int. Conf. on Enterprise Informa-
tion Systems.
Bizer, C. and Cyganiak, R. (2009). Quality-driven informa-
tion filtering using the wiqa policy framework. Jour-
nal of Web Semantics, 7(1):1–10.
Bleiholder, J. and Naumann, F. (2010). Data fusion and
conflict resolution in integrated information systems.
PhD thesis, University of Potsdam.
Casanova, M. A., Vidal, V. M., Lopes, G. R., Leme,
L. A. P. P., and Ruback, L. (2014). On material-
ized sameas linksets. In International Conference
on Database and Expert Systems Applications, pages
377–384. Springer.
Collarana, D., Galkin, M., Traverso-Ribón, I., Lange, C.,
Vidal, M.-E., and Auer, S. (2017). Semantic data in-
tegration for knowledge graph construction at query
time. In 2017 IEEE 11th International Conference on
Semantic Computing (ICSC), pages 109–116. IEEE.
D Pierce, C., Booth, D., Ogbuji, C., Deaton, C., Blackstone,
E., and Lenat, D. (2012). Semanticdb: a semantic web
infrastructure for clinical research and quality report-
ing. Current Bioinformatics, 7(3):267–277.
da Cruz, M. M. L., Avila, C. V. S., Vidal, V. M. P., and Ju-
nior, N. M. A. (2019). Semanticsus: Um portal semân-
tico baseado em ontologias e dados interligados para
acesso, integração e visualização de dados do sus. In
Anais Estendidos do XIX Simpósio Brasileiro de Com-
putação Aplicada à Saúde, pages 13–18. SBC.
Debattista, J., Auer, S., and Lange, C. (2016). Luzzu—a
methodology and framework for linked data quality
assessment. Journal of Data and Information Quality
(JDIQ).
Dong, X. L. and Naumann, F. (2009). Data fusion: resolv-
ing data conflicts for integration. Proceedings of the
VLDB Endowment, 2(2):1654–1655.
Ehrlinger, L. and Wöß, W. (2016). Towards a definition
of knowledge graphs. SEMANTiCS (Posters, Demos,
SuCCESS), 48.
Freitas, R., Rocha, C., Braga, O., Lopes, G., Monteiro, O.,
and Oliveira, M. (2017). Using linked data in the data
integration for maternal and infant death risk of the sus
in the gissa project. In Proceedings of the 23rd Brazil-
lian Symposium on Multimedia and the Web, pages
193–196. ACM.
Guéret, C., Groth, P., Stadler, C., and Lehmann, J. (2012).
Assessing linked data mappings using network mea-
sures. In Extended semantic web conf. Springer.
Hartig, O. and Zhao, J. (2010). Publishing and consuming
provenance metadata on the web of linked data. In
International Provenance and Annotation Workshop,
pages 78–90. Springer.
Knap, T., Michelfeit, J., Daniel, J., Jerman, P., Rych-
novsk
`
y, D., Soukup, T., and Ne
ˇ
cask
`
y, M. (2012). Od-
cleanstore: a framework for managing and providing
integrated linked data on the web. In Int. Conf. Web
Information Systems Engineering, pages 815–816.
Papaleo, L., Pernelle, N., and Saïs, F. (2014). On evalu-
ating the quality of rdf identity links in the lod. In
In the proceedings of IC’2014 Workshop" From Open
Sources to Web of Data"(SoWeDo 2014).
Schultz, A., Matteini, A., Isele, R., Bizer, C., and Becker, C.
(2011). LDIF - linked data integration framework. In
Publishing and Consuming Semantic Views for Construction of Knowledge Graphs
203

Proc. Second Int. Conf. on Consuming Linked Data,
COLD’11, Aachen, Germany. CEUR-WS.org.
Vidal, V. M., Casanova, M. A., Arruda, N., Roberval, M.,
Leme, L. P., Lopes, G. R., and Renso, C. (2015). Spec-
ification and incremental maintenance of linked data
mashup views. In International Conference on Ad-
vanced Information Systems Engineering, pages 214–
229. Springer.
Wang, J. (2012). A framework and architecture for quality
assessment in data integration. PhD thesis, University
of London.
Wang, R. Y. (2005). Information Quality (Advances in Man-
agement Information Systems). M. E. Sharpe, Inc.,
Armonk, NY, USA.
Wang, R. Y. and Strong, D. M. (1996). Beyond accuracy:
What data quality means to data consumers. J. Man-
age. Inf. Syst., 12(4):5–33.
Xiao, G., Calvanese, D., Kontchakov, R., Lembo, D.,
Poggi, A., Rosati, R., and Zakharyaschev, M. (2018).
Ontology-based data access: A survey. IJCAI.
Xiao, G., Ding, L., Cogrel, B., and Calvanese, D. (2019).
Virtual knowledge graphs: An overview of systems
and use cases. Data Intelligence, 1(3):201–223.
Zaveri, A., Kontokostas, D., Sherif, M. A., Bühmann, L.,
Morsey, M., Auer, S., and Lehmann, J. (2013). User-
driven quality evaluation of dbpedia. In Proceedings
of the 9th International Conference on Semantic Sys-
tems, pages 97–104. ACM.
Zaveri, A., Rula, A., Maurino, A., Pietrobon, R., Lehmann,
J., and Auer, S. (2016). Quality assessment for linked
data: A survey. Semantic Web, 7(1):63–93.
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
204
