
Data-centric Refinement of Database-Database
Dependency Analysis of Database Program
Angshuman Jana
Indian Institute of Information Technology Guwahati, India
Keywords:
Database Program, Structured Query Language, Program Dependency Graph, Refinement.
Abstract:
Since the pioneer work by Ottenstein and Ottenstein, the notion of Program Dependency Graph (PDG) has
attracted a wide variety of compelling applications in software engineering, e.g. program slicing, information
flow security analysis, debugging, code-optimization, code-reuse, code-understanding, and many more. In
order to exploit the power of dependency graph in solving problems related to relational database applications,
Willmor et al. first proposed Database Oriented Program Dependency Graph (DOPDG), an extension of PDG
by taking database statements and their dependencies further into consideration. However, the dependency
information generated by the DOPDG construction algorithm is prone to imprecision due to its syntax-based
computation, and therefore the approach may increase the susceptibility of false alarms in the above-mentioned
application scenarios. Addressing this challenge, in this paper, the following two main research objectives are
highlighted: (1) How to obtain more precise dependency information (hence more precise DOPDG)? and (2)
How to compute them efficiently? To this aim, a data-centric based approach is proposed to compute precise
dependency information by removing false alarms. To refine the database-database dependency, the syntax-
based DOPDG construction is augmented by adding three extra nodes and edges (as per the condition-action
execution sequence) with each node that represents the database statement.
1 INTRODUCTION
The database technology is always at the heart of any
information systems, facilitating one to store exter-
nal data into persistent storage and to process them
efficiently (Goldin et al., 2004). Even in the era of
big data, a survey by TDWI in 2013 (Russom, 2013)
says that, for a quarter of organizations, more than
20% of large volume of data are structured in na-
ture and are stored in the form of relational database.
Due to the structured form of stored data, relational
database management systems gain immense popu-
larity among the database community. A most com-
mon way to develop a database application is to
embed relational database languages such as SQL,
PL/SQL, HQL, etc., into other host languages like C,
C++, Java, etc.(Goldin et al., 2000; Date, 2006). Over
the decades, database applications are playing a piv-
otal role in every aspect of our daily lives by providing
an easy interface to store, access and process crucial
data with the help of Relational Database Manage-
ment System (RDBMS). Some examples of software
systems where database applications act as an inte-
gral part include online shopping store, banking sys-
tem, railway reservation system, even critical systems
such as air traffic control, health care and so on.
In the software systems, the dependency informa-
tion among program statements and variables, solv-
ing a large number of software engineering tasks se-
curity analysis (Hammer, 2010; Mandal et al., 2014;
Ahuja et al., 2016), taint analysis (Krinke, 2007),
program slicing (Tip, 1994; Jana et al., 2015), op-
timization (Ferrante et al., 1987; Bondhugula et al.,
2008), code-reuse (Jiang, 2009), code-understanding
(Podgurski and Clarke, 1990; Jana et al., 2018a). One
most suitable representation of these dependencies is
in the form of Dependency Graph that consists of both
data- and control-dependencies among program com-
ponents. The control-dependencies among statements
are computed based on the syntactic structure of the
program: a statement s
2
is said to be control depen-
dent on another statement s
1
iff there exists a path p
from s
1
to s
2
such that every statement s
i
6= s
1
within p
will be followed by s
2
in every possible path to the end
of the program, and there is an execution path from s
1
to the end of the program that does not go through
s
2
. Similarly, a way to compute data-dependencies is
to consider syntactic presence of one variable in the
234
Jana, A.
Data-centric Refinement of Database-Database Dependency Analysis of Database Program.
DOI: 10.5220/0009891202340241
In Proceedings of the 15th International Conference on Software Technologies (ICSOFT 2020), pages 234-241
ISBN: 978-989-758-443-5
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

definition of another variable: a statement s
2
is said
to be data-dependent on another statement s
1
if there
exists a variable x such that x is defined by s
1
and sub-
sequently used by s
2
, and there is a x-definition free
path from s
1
to s
2
(Ottenstein and Ottenstein, 1984).
Since the pioneer work by Ottenstein and Ot-
tenstein (Ottenstein and Ottenstein, 1984), the no-
tion of Program Dependency Graph (PDG) has at-
tracted a wide variety of compelling applications
in software engineering, e.g. program slicing, in-
formation flow security analysis, debugging, code-
optimization, code-reuse, code-understanding, and
many more. Since its inception, a number of vari-
ants are also proposed for various programming
languages and features, possibly tuning them to-
wards their suitable application domains, like Sys-
tem Dependence Graph (SDG) (Horwitz et al., 1990),
Class Dependence Graph (ClDG) (Larsen and Har-
rold, 1996) and etc. In order to exploit the power
of dependency graph in solving problems related
to relational database applications, Willmor et al.
first proposed Database Oriented Program Depen-
dency Graph (DOPDG), an extension of PDG by
taking database statements and their dependencies
further into consideration as (i) Program-Database
dependency (PD-dependency) which represents de-
pendency between an imperative statement and a
database statement, and (ii) Database-Database de-
pendency (DD-dependency) which represents a de-
pendency between two database statements. How-
ever, the dependency information generated by the
DOPDG construction algorithm is prone to impreci-
sion due to its syntax-based computation, and there-
fore the approach may increase the susceptibility of
false alarms.
To exemplify our motivation briefly, let us con-
sider a small database code snippet below that con-
sists three SQL statements Q
1
, Q
2
and Q
3
:
Q
1
: UPDATE emp SETsal:=sal+1000 WHERE sal ≤ 3000
Q
2
: UPDATE emp SETsal:=sal
*
.2 WHERE sal ≥ 7000
Q
3
: SELECT MAX(sal) FROM emp WHERE sal ≥ 5000
The statement Q
3
is syntactically dependent on Q
1
and Q
2
for ’sal’ because it is a used-variable in Q
3
and it is a defined-variable both in Q
1
and Q
2
. Note
that, the values of ’sal’ in the database, the part of
sal-values defined by Q
1
is not overlapping with the
sal-values subsequently used by Q
3
. Therefore, the
dependency between Q
1
and Q
3
is false alarm.
Observe that syntax-based DOPDG construction
approach may generate false dependencies. Gener-
ation of false dependency information and its use
in any software-engineering activities, such as safety
property verification of any critical systems, may en-
force. Particularly, false dependency information re-
duces the system throughput, as a result, financial
cost and resource utilization may be affected. Un-
fortunately, since then no significant contribution is
found in this research direction. As the values of
database attributes differ from that of imperative lan-
guage variables, the computation of semantics (and
hence semantics-based dependency) of database ap-
plications is, however, challenging and requires dif-
ferent treatment. The key point here is the static iden-
tification of various parts of the database information
possibly accessed or manipulated by database state-
ments at various program points.
Addressing this challenge, in this paper, I aim
to answer the following two main research objec-
tives: (1) How to obtain more precise dependency
information (hence more precise DOPDG)? and (2)
How to compute them efficiently? To this aim, I
propose a data-centric based approach to compute
precise dependency information by removing false
alarms. To refine the database-database dependency,
I augment the syntax-based DOPDG construction by
adding three extra nodes along with edges (as per the
condition-action execution sequence) with each node
that represents the database statement. This propose
approach serves an automatic tool to compute various
dependencies information among variables and state-
ments in database applications. This tool will also
useful in future to solve many software-engineering
problems, e.g. Database Code Slicing (Larsen and
Harrold, 1996), Database Leakage Analysis (Halder
et al., 2014), Data Provenance (Cheney et al., 2007),
Materialization View Creation (Sen et al., 2012),
Concurrent System modeling, etc.
Roadmap: In section 2, I discuss the current state-
of-the-art in the literature. In section 3, I describe a
running example. The propose approach is introduced
in section 4. Section 5 provides an overall tool archi-
tecture. Finally section 6 concludes the work.
2 RELATED WORKS
In (Ottenstein and Ottenstein, 1984; Ferrante et al.,
1987) authors introduced the notion of Program De-
pendency Graph (PDG) aiming program optimiza-
tion. It is an intermediate representation of programs
where nodes represent program statements and edges
represent data- and control-dependencies between the
statements. Over the past, PDG plays important
roles in various software systems activities, e.g. pro-
gram slicing (Tip, 1994), code-reuse (Jiang, 2009),
language-based information flow security analysis
Data-centric Refinement of Database-Database Dependency Analysis of Database Program
235

(Krinke, 2007; Hammer, 2010; Halder et al., 2014;
Halder et al., 2016), code-understanding (Podgurski
and Clarke, 1990). Since then, various extension
and modification of PDG have been proposed towards
many directions. Over the past several decades, var-
ious form of dependency graphs are evolved in dif-
ferent contexts for different programming languages,
e.g. Program Dependence Graph (PDG) (Ottenstein
and Ottenstein, 1984) in case of intra-procedural pro-
grams, System Dependence Graph (SDG) (Horwitz
et al., 1990) in case of inter-procedural programs,
Class Dependence Graph (ClDG) is introduced for
Object Oriented Programming (OOP) languages in
(Larsen and Harrold, 1996). Willmor et.al. (Will-
mor et al., 2004) introduced a variant of program de-
pendency graph, known as Database-Oriented Pro-
gram Dependency Graph (DOPDG), by considering
the two additional data dependencies due to the pres-
ence of database statements: (i) Program-Database
dependency (PD-dependency) which represents de-
pendency between an imperative statement and a
database statement, and (ii) Database-Database de-
pendency (DD-dependency) which represents a de-
pendency between two database statements.
All such proposed dependency graphs are con-
structed based on the syntactic presence of variable in
the definitions of other variable. However, syntactic
dependency computations may produce false alarms.
As a notable achievement, (Mastroeni and Zanardini,
2008) introduced the notion of semantic-data depen-
dency which focuses on the actual values of variable
rather than their syntactic presence. For instance,
although the expression “e = x
2
+ 4w mod 2 + z”
syntactically depends on w, semantically there is no
dependency as the evaluation of “4w mod 2” is al-
ways zero. Therefore, syntax-based approach may
fail to compute an optimal results. Another approach
Condition-Action rule (Baralis and Widom, 1994) is
also applicable for dependencies computation, in case
of database applications, SQL statements define ei-
ther a part of the values or all of the values corre-
sponding to an attribute depending on the condition
present in the WHERE clause. But this approach is
unable to provided the optimal solution and suffer
from high computational cost (O(2
n
) where n repre-
sent the number of variables in a program). In (Alam
and Halder, 2016) authors proposed semantics-based
DOPDG using weakest precondition and postcondi-
tion of Hoare Logic to address the information-flow
analysis of database applications. But this approach
lead to an exponential computational overhead and
also unable to compute optimal result. (Halder and
Cortesi, 2013; Jana et al., 2018b; Jana and Halder,
2016) formalized the semantics for dependency re-
Start;
Q
0
: Connection c =DriverManager.getConnection(. . . . . .);
Q
1
: UPDATE emp SET sal := sal +Sbonus WHERE age > 60;
Q
2
: SELECT AVG(sal) FROM emp WHERE age > 60;
Q
3
: SELECT AVG(sal) FROM emp WHERE age < 60
Q
4
: UPDATE emp SET sal := sal +Cbonus;
Q
5
: SELECT AVG(sal) FROM emp;
Stop;
Figure 1: A database code snippet Prog.
finement in a simple setting following the Abstract
Interpretation as an initial attempt. However this is
also suffer form large number of false alarm. A se-
mantic characterization of dependency provenance is
proposed in (Cheney et al., 2007), where dependency
provenance is intended to show how (part of) the out
put of a query depended on (part of) its input. (Amtoft
and Banerjee, 2007) defined a Hoare-style logic to an-
alyze variable independency.
3 RUNNING EXAMPLE
let us consider a small database code snippet Prog,
depicted in Figure 1, that enhance the salary of all
employees in any organization by the common bonus
amount Cbonus and by the additional special bonus
amount Sbonus only for aged employees. Note that,
the syntactic presence of attribute ’sal’ as a defined-
attribute at statement Q
1
and as an used-attribute at
statement Q
3
. Therefore, the statement Q
3
is syn-
tactically dependent on statement Q
1
. However, a
careful observation reveals that syntactic presence of
database attribute as a way of database database de-
pendency computation may often result in false alarm,
and thus fails to generate precise set of dependencies.
For example, if any one focus on the value of the at-
tribute ’sal’ in the code that the values of ’sal’ referred
in the “WHERE” clauses at statements Q
1
and Q
3
do not
overlap with each other. Hence the statement Q
3
does
not dependent on statement Q
1
. I show, in the subse-
quent sections, how the propose approach effectively
identifies false DD-dependencies in Prog.
4 PROPOSED APPROACH
In this section, I describe a novel approach, how
to refine the syntactic DOPDG for gaining the pre-
cise Database-Database (DD) dependency informa-
tion among the statements of a database program. At
first, I recall from (Willmor et al., 2004) the syntax-
based DOPDG construction. In the next step, the syn-
tactic DOPDG is augmented by adding three extra
ICSOFT 2020 - 15th International Conference on Software Technologies
236
Q
2
start
Q
1
Q
0
Q
3
Q
4
Q
5
stop
sal
age,
sal sal
sal,
age
sal, age
sal
sal
sal
sal
sal
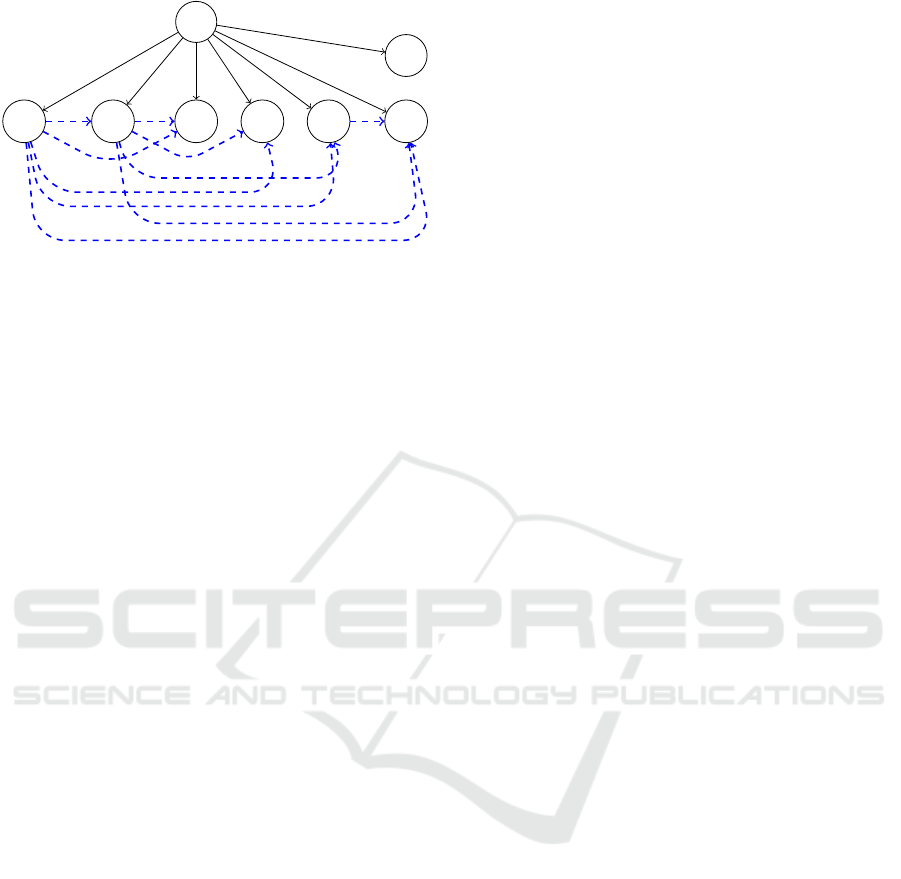
Figure 2: Syntax-based DOPDG of Prog.
nodes along with edges (as per the condition-action
execution sequence) with each node that represents
the database statement. Finally, based on the aug-
mented DOPDG ψ the used and defined-parts of the
database is calculated and their overlapping informa-
tion refine the DD-dependency.
4.1 Syntax-based DOPDG
Database-Oriented Program Dependency Graph
(DOPDG) (Willmor et al., 2004) is an extension of
PDG to the case of database programs. DOPDG
considers two additional dependencies: (i) Program-
Database dependency and (ii) Database-Database
dependency. A PD-dependency represents the
dependency between a database statement and an
imperative statement, whereas a DD-dependency
represents the dependency between two database
statements. Let us recall them below:
Definition 1 (Program-Database (PD) Dependency
(Willmor et al., 2004)). A database statement Q is PD
dependent on an imperative statement S for a variable
k (denoted S
K
−→ Q) if the below three hold: (i) k is de-
fined by S, (ii) k is used by Q, and (iii) there is no
redefinition of k between S and Q.
The PD-dependency of S on Q is defined similarly.
Definition 2 (Database-Database (DD) Dependency
(Willmor et al., 2004)). Let Q.SE, Q.IN, Q.U P and
Q.DE represent the operations on database which are
select, insert, update, and delete respectively by state-
ment Q. A database statement Q
1
is DD-dependent on
another database statement Q
2
for an attribute a (de-
noted Q
1
a
−→ Q
2
) if the following hold: (i) Q
1
.SEL ∩
(Q
2
.INS ∪ Q
2
.UPD ∪ Q
2
.DEL) 6=
/
0, and (ii) there
is no roll-back operation in the execution path p be-
tween Q
2
and Q
1
(exclusive) which reverses back the
effect of Q
2
.
Example 1. Consider the running example Prog
depicted in Figures 1 (section 3). The control depen-
dencies Start → Q
1
, Start → Q
2
, etc. are computed
in similar way as in the case of traditional PDG. The
used and defined attributes at each program point of
Prog are computed as follows:
DEF(Q
0
)={sal, Sbonus, Cbonus, age}
DEF(Q
1
)={sal} USE(Q
1
) = {Sbonus, age}
DEF(Q
2
)={
/
0} USE(Q
2
) = {sal, age}
DEF(Q
3
)={
/
0} USE(Q
3
) ={sal, age}
DEF(Q
4
)={sal} USE(Q
4
) = {Cbonus}
DEF(Q
5
)={
/
0} USE(Q
5
) = {sal}
Observe that statement Q
0
defines all database
attributes as it connects to the database, resulting
DEF(Q
0
) to contain all attributes. From the above
information, the following data dependencies are
identified:
• DD-dependencies for attributes sal and
age: {Q
0
→ Q
1
, Q
2
, Q
3
, Q
4
, Q
5
},
{Q
1
→ Q
2
, Q
3
, Q
4
, Q
5
} and {Q
4
→ Q
5
},
The syntax-based DOPDG construction of Prog is
depicted in Figure 2.
4.2 Augmentation of DOPDG
In this section, the syntax-based DOPDG is aug-
mented by adding extra nodes and edges (according to
condition and action present in a database statement)
with the node that represent the database statement.
At first step, I identify the set of database statements
(Select, Insert, Update and Delete) in a database pro-
gram and mark (may used any color) the correspond-
ing nodes in the DOPDG. In particular, the presence
of Data Manipulation Language (DML) statements in
a database program is identified based on the pres-
ence of keywords such as SELECT, UPDATE, DELETE
and INSERT in the database statements.
As per the execution sequence, I divide each
database statement with two part: one is condition-
part and another one is action-part. Formally, a SQL
statement Q is denoted by hA, φi where A represents
an action-part and φ represents a conditional-part.
The action-part A includes SELECT, UPDATE, DELETE
and INSERT operations which are denoted by A
sel
,
A
upd
, A
del
and A
ins
respectively. The conditional-
part φ represents the condition under the WHERE clause
of the statement, which follows first-order logic for-
mula. For instance, the query Q = “UPDATE emp
SET sal:=sal+100 WHERE age >40” is denoted by Q =
hA
upd
, φi where A
upd
represents “ sal:=sal+100” and
φ represents “age >40”.
Now, each marked node of the syntax-based
DOPDG is augmented by three extra nodes and edges
where each node and edge are labeled by hφ, ∆
φ
i,
h¬φ, ∆
¬φ
i and hA, ∆
A
i respectively. The ∆
φ
represents
Data-centric Refinement of Database-Database Dependency Analysis of Database Program
237

Q
2
start
Q
1
Q
0
Q
3
Q
4
Q
5
stop
∆
Q
1
φ
∆
Q
1
¬φ
∆
Q
1
A
∆
Q
2
φ
∆
Q
2
¬φ
∆
Q
2
A
∆
Q
3
¬φ
∆
Q
3
φ
∆
Q
3
A
∆
Q
4
A
∆
Q
5
A
¬φ
φ
A
φ
¬φ
A
¬φ
φ
A
A
A
Figure 3: Augmentation of the DOPDG of Prog.
a part of the database which satisfies φ, whereas the
∆
¬φ
represents a part of database which does not sat-
isfy φ. The ∆
A
is obtained after performing an action
A on ∆
φ
. Observe that, the φ, ¬φ and A are labeled
with the edges of the corresponding nodes.
Example 2. Let us consider the database program
Prog in Figure 1. The augmented DOPDG of Prog
is depicted in Figure 3. Observe that, in Prog the set
database statements are Q
1
, Q
2
, Q
3
, Q
4
and Q
5
and
their corresponding nodes are marked by red color in
the augmented DOPDG. Now, Q
1
is represented by
hA
upd
, φi where A
upd
represents “ sal:=sal+Sbonus”
and φ represents “age >60”. Therefore, in the aug-
mented DOPDG, node ∆
Q
1
φ
represent the part of
the database which satisfies age >60, the node ∆
Q
1
¬φ
represent the part of the database which satisfies
6=(age >60) and the node ∆
Q
1
A
which obtained af-
ter performing sal:=sal+Sbonus and their associated
edges are added with node Q
1
of the DOPDG. Simi-
larly nodes and edges are added with the nodes Q
2
,
Q
3
, Q
4
and Q
5
of the DOPDG. Note that, in the
case of Q
4
and Q
5
, the φ is empty. Therefore, only
nodes ∆
Q
4
A
and ∆
Q
5
A
along with the connected edges
are added with node Q
4
and Q
5
respectively.
4.3 Dependency Computations
Now I compute the DD-dependencies among
database statements. From the augmented DOPDG
ψ, I compute the set of used- and defined-parts of the
database w.r.t. database statements.
Given two database statements Q
1
and Q
2
. The
defined-part by Q
1
and the used-part by Q
2
are :
E
Q
1
= D
def
(Q
1
, ψ) = h∆
Q
1
φ
, ∆
Q
1
A
i
U
Q
2
= D
use
(Q
2
, ψ) = h∆
Q
2
φ
i
The semantic dependency and independency of Q
2
on
Q
1
are determined based on the following four cases:
Case − 1. ∆
Q
1
φ
∩ ∆
Q
2
φ
6=
/
0 ∧ ∆
Q
1
A
∩ ∆
Q
2
φ
=
/
0
Case − 2. ∆
Q
1
φ
∩ ∆
Q
2
φ
=
/
0 ∧ ∆
Q
1
A
∩ ∆
Q
2
φ
6=
/
0
Case − 3. ∆
Q
1
φ
∩ ∆
Q
2
φ
6=
/
0 ∧ ∆
Q
1
A
∩ ∆
Q
2
φ
6=
/
0
Case − 4. ∆
Q
1
φ
∩ ∆
Q
2
φ
=
/
0 ∧ ∆
Q
1
A
∩ ∆
Q
2
φ
=
/
0
Therefore, Q
2
is DD-Independent on Q
1
if and only if
E
Q
1
∩ U
Q
2
=
/
0; that is ∆
Q
1
φ
∩ ∆
Q
2
φ
=
/
0 ∧ ∆
Q
1
A
∩ ∆
Q
2
φ
=
/
0. This pictorial representation of the above cases are
depicted in Figure 4.
Algorithm to Compute DD-dependency based on
used and defined Information The algorithm DDA
takes a list of used- and defined-parts (D
use
and D
de f
)
at each program point c
i
of the database program of
size n, and generates refine DOPDG. The algorithm
remove edges (false alarm) between DOPDG-nodes
c
i
and c
j
based on the emptiness checking of the
intersection of the defined-part by c
i
and the used-
part by c
j
. To remove false dependency where more
than one database statements (in sequence) redefine
an attribute values which is finally used by another
statement, the condition D
de f
(i) ⊆ D
de f
( j) verifies
whether defined-part at program point c
i
is fully cov-
ered by the defined-part at program point c
j
. In this
case, integer variable f represents the ‘1’ value which
indicate the dependency between c
i
and c
j
.
Algorithm 1: DDA.
Input: used- and defined-part (D
use
, D
de f
) by all
database statements in the program.
Output: Refine DOPDG
Set flag=TRUE
for i =1 to n-1 do
for j=i+1 to n do
if D
de f
(i) ∩ D
use
(j)=
/
0 then
int f = 0;
Remove the edge from i
th
node to j
th
node (i → j);
Report this as a false alarm;
else
. . . Do nothing . . .
if flag=True then
if D
de f
(i) ⊆ D
de f
(j) then
f = 1;
Break;
End
Illustration on Running Example: Now I illus-
trate the DD-dependency refinement on the running
example Prog in Figure 1 (section 3). The DD-
ICSOFT 2020 - 15th International Conference on Software Technologies
238
∆
Q
1
φ
∆
Q
2
φ
∆
Q
1
A
∆
Q
2
φ
x
y
∆
Q
1
φ
∆
Q
2
φ
∆
Q
1
A
∆
Q
2
φ
x
y
∆
Q
1
φ
∆
Q
2
φ
∆
Q
1
A
∆
Q
2
φ
x
y
∆
Q
1
φ
∆
Q
2
φ
∆
Q
1
A
∆
Q
2
φ
x
y
Figure 4: Representations of 4 Cases: from Case-1 to Case-4 (from left to right).
Q
2
Start
Q
1
Q
0
Q
3
Q
4
Q
5
Stop
sal
age,
sal sal
sal,
age
sal, age
sal
sal
sal
Figure 5: Refine DOPDG of Prog.
dependency refinements are computed applying the
following steps:
• Compute defined- and used-parts based on the ψ.
• Refinement of syntactic dependencies in “Prog”
using Algorithm 1.
By removing two false dependencies Q
1
→ Q
3
and
Q
1
→ Q
5
, the refine DOPDG of Prog is depicted in
Figure 5. Observe that, as ∆
Q
1
φ
∩ ∆
Q
3
φ
=
/
0 ∧ ∆
Q
1
A
∩
∆
Q
3
φ
=
/
0 the dependency Q
1
→ Q
3
is removed (false
alarm). Similarly, the dependency Q
1
→ Q
5
is re-
moved (false alarm) as the part of sal-values defined
by Q
1
is fully redefined by Q
4
and never reaches Q
5
.
5 TOWARDS IMPLEMENTATION
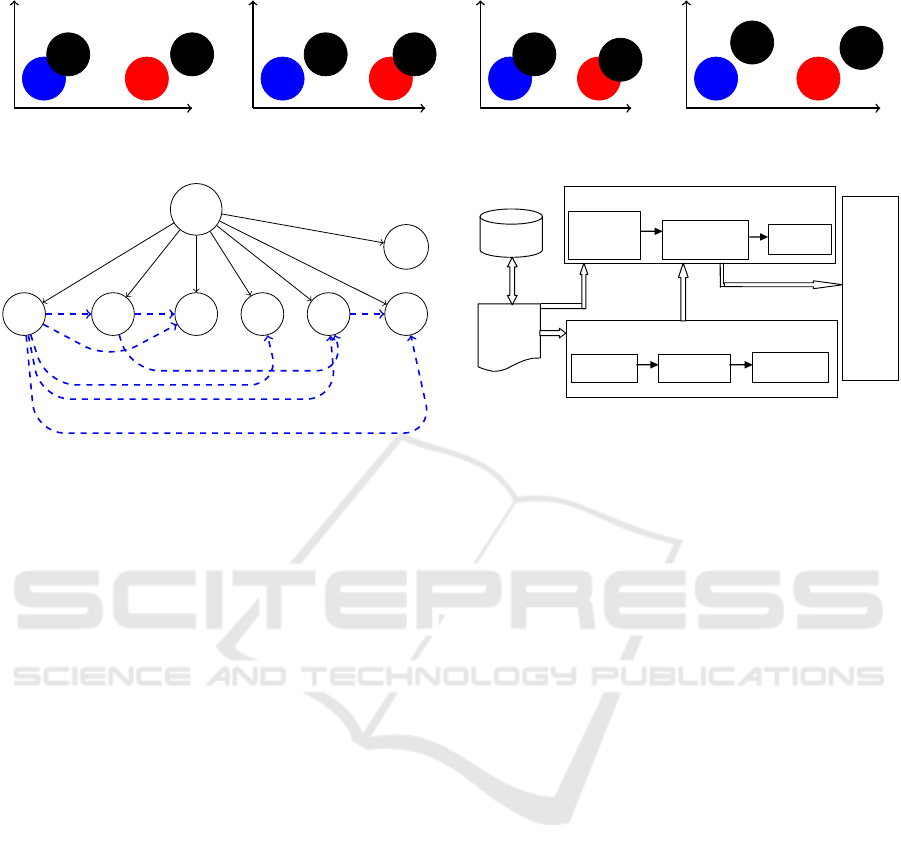
I design a tool Database-Database Dependency An-
alyzer (D3A) based on the proposed framework. In
general, the D3A accepts as inputs a database pro-
gram and computes more precise set of Database-
Database (DD) dependency information among the
statements as output. The tool D3A consists of two
major components: (i) Syntax-based module, and (ii)
Refinement module. Figure 6 depicts the overall ar-
chitecture of the tool. This two components also con-
sist the following key modules which play important
roles in implementing the proposed framework:
• Proformat: The module “Proformat” annotates
input database programs and adds line numbers
(starting from zero) to all statements.
Refinement of syntax-based dependency
Syntax-based dependence computations
Proformat
ExtractInfo
Dependence
Set of
optimal
depend
ency
Database
applicati
on
Database
Identifying
Database
Statements
Augmentation
of DOPDG
Analyzer
_
Figure 6: Overall Architecture of Database-Database De-
pendency Analyzer (D3A).
• ExtractInfo: This module extracts detail infor-
mation about input programs, i.e. control state-
ments, defined variables, used variables, etc. for
all statements in the program.
• Dependency: The “Dependency” module com-
putes syntax-based dependencies among program
statements using the information computed by
“ExtractInfo” module.
• Identifying Database Statements: This mod-
ule computes the number of SQL statements
present in the database program. In particular, the
presence of Data Manipulation Language (DML)
statements is identified based on the presence of
keywords such as SELECT, UPDATE, DELETE and
INSERT in the statements.
• Augmentation of DOPDG: The module aug-
ments the syntax-based DOPDG construction, by
adding three extra nodes and edges (based on the
condition-action execution sequence) with each
node that represents the database statement.
• Analyzer: Finally this module identifies false de-
pendency (if any) based on the used (as per condi-
tion of a statement) and defined (as per action of a
statement) nodes of augmented DOPDG and their
overlapping.
Data-centric Refinement of Database-Database Dependency Analysis of Database Program
239

6 CONCLUSIONS AND FUTURE
WORKS
In this paper, I proposed data-centric based approach
to compute precise dependency information (by re-
moving false alarms) among the database statement
of a database application. To refine the syntax-
based DD-dependency information (may exist false
alarm), I design a Database-Database Dependency
Analyzer (D3A) based on the following key modules:
(i) Identifying database statements, (ii) Augmentation
of syntax-based DOPDG and (iii) Analyzer. Cur-
rently, I am implementing the proposed tool D3A, as
per the description provided in the tool architecture,
in a modular way to support scalability. In future, this
tool will be used to address efficiently several soft-
ware engineering problems like Database Code Slic-
ing (Larsen and Harrold, 1996), Database Leakage
Analysis (Halder et al., 2014), Data Provenance (Ch-
eney et al., 2007), Materialization View Creation (Sen
et al., 2012), Concurrent System modeling, etc.
REFERENCES
Ahuja, B. K., Jana, A., Swarnkar, A., and Halder, R. (2016).
On preventing sql injection attacks. In Advanced
Computing and Systems for Security, pages 49–64.
Springer.
Alam, M. I. and Halder, R. (2016). Refining Dependencies
for Information Flow Analysis of Database Applica-
tions. In International Journal of Trust Management
in Computing and Communications. Inderscience.
Amtoft, T. and Banerjee, A. (2007). A logic for information
flow analysis with an application to forward slicing of
simple imperative programs. Sci. Comput. Program.,
64(1):3–28.
Baralis, E. and Widom, J. (1994). An Algebraic Approach
to Rule Analysis in Expert Database Systems. In Pro-
ceedings of the 20th International Conference on Very
Large Data Bases, VLDB ’94, pages 475–486. Mor-
gan Kaufmann Publishers Inc.
Bondhugula, U., Hartono, A., Ramanujam, J., and Sadayap-
pan, P. (2008). PLUTO: A practical and fully au-
tomatic polyhedral program optimization system. In
Proceedings of the ACM SIGPLAN 2008 Conference
on Programming Language Design and Implementa-
tion (PLDI 08), Tucson, AZ (June 2008).
Cheney, J., Ahmed, A., and Acar, U. A. (2007). Provenance
As Dependency Analysis. In Proceedings of the 11th
ICDPL, DBPL’07, pages 138–152.
Date, C. J. (2006). An introduction to database systems.
Pearson Education India.
Ferrante, J., Ottenstein, K. J., and Warren, J. D. (1987). The
program dependence graph and its use in optimiza-
tion. ACM Trans. on Programming Lang. and Sys.,
9(3):319–349.
Goldin, D., Srinivasa, S., and Srikanti, V. (2004). Ac-
tive databases as information systems. In Database
Engineering and Applications Symposium, 2004.
IDEAS’04. Proceedings. International, pages 123–
130. IEEE.
Goldin, D., Srinivasa, S., and Thalheim, B. (2000). Is=dbs +
interaction: towards principles of information system
design. In International Conference on Conceptual
Modeling, pages 140–153. Springer.
Halder, R. and Cortesi, A. (2013). Abstract Program Slicing
of Database Query Languages. In Proceedings of the
the 28th Symposium On Applied Computing - Special
Track on Database Theory, Technology, and Applica-
tions, pages 838–845, Coimbra, Portugal. ACM Press.
Halder, R., Jana, A., and Cortesi, A. (2016). Data leakage
analysis of the hibernate query language on a propo-
sitional formulae domain. In Transactions on Large-
Scale Data-and Knowledge-Centered Systems XXIII,
pages 23–44. Springer.
Halder, R., Zanioli, M., and Cortesi, A. (2014). Infor-
mation leakage analysis of database query languages.
In Proceedings of the 29th Annual ACM Symposium
on Applied Computing (SAC’14), pages 813–820,
Gyeongju, Korea. ACM Press.
Hammer, C. (2010). Experiences with PDG-Based IFC.
In Proc. of the Engineering Secure Software and Sys-
tems, pages 44–60, Pisa, Italy. Springer-Verlag.
Horwitz, S., Reps, T., and Binkley, D. (1990). Interproce-
dural slicing using dependence graphs. ACM Trans-
actions on PLS, 12(1):26–60.
Jana, A., Alam, M. I., and Halder, R. (2018a). A symbolic
model checker for database programs. In ICSOFT,
pages 381–388.
Jana, A. and Halder, R. (2016). Defining abstract semantics
for static dependence analysis of relational database
applications. In International Conference on Infor-
mation Systems Security, pages 151–171. Springer.
Jana, A., Halder, R., Chaki, N., and Cortesi, A. (2015).
Policy-based slicing of hibernate query language. In
IFIP International Conference on Computer Informa-
tion Systems and Industrial Management, pages 267–
281. Springer.
Jana, A., Halder, R., Kalahasti, A., Ganni, S., and Cortesi,
A. (2018b). Extending abstract interpretation to de-
pendency analysis of database applications. IEEE
Transactions on Software Engineering.
Jiang, L. (2009). Scalable Detection of Similar Code: Tech-
niques and Applications. PhD thesis, Davis, CA,
USA.
Krinke, J. (2007). Information flow control and taint
analysis with dependence graphs. In 3rd Interna-
tional Workshop on Code Based Security Assessments
(CoBaSSA 2007), pages 6–9.
Larsen, L. and Harrold, M. J. (1996). Slicing object-
oriented software. In Proceedings of the 18th ICSE,
pages 495–505, Berlin, Germany. IEEE CS.
Mandal, K. K., Jana, A., and Agarwal, V. (2014). A new
approach of text steganography based on mathemati-
cal model of number system. In 2014 International
ICSOFT 2020 - 15th International Conference on Software Technologies
240

Conference on Circuits, Power and Computing Tech-
nologies [ICCPCT-2014], pages 1737–1741. IEEE.
Mastroeni, I. and Zanardini, D. (2008). Data dependencies
and program slicing: from syntax to abstract seman-
tics. In Proc. of the Partial evaluation and semantics-
based program manipulation.
Ottenstein, K. J. and Ottenstein, L. M. (1984). The program
dependence graph in a software development environ-
ment. ACM SIGPLAN Notices, 19(5):177–184.
Podgurski, A. and Clarke, L. A. (1990). A formal model
of program dependences and its implications for soft-
ware testing, debugging, and maintenance. IEEE
Trans. on SE, 16(9):965–979.
Russom, P. (2013). Managing big data. TDWI Best Prac-
tices Report, TDWI Research, pages 1–40.
Sen, S., Dutta, A., Cortesi, A., and Chaki, N. (2012). A New
Scale for Attribute Dependency in Large Database
Systems. In CISIM, volume 7564 of LNCS, pages
266–277.
Tip, F. (1994). A Survey of Program Slicing Techniques.
Technical report.
Willmor, D., Embury, S. M., and Shao, J. (2004). Program
slicing in the presence of a database state. In Proc. of
the IEEE ICSM.
Data-centric Refinement of Database-Database Dependency Analysis of Database Program
241
