
Upgraded W-Net with Attention Gates and Its Application in
Unsupervised 3D Liver Segmentation
Dhanunjaya Mitta
1
, Soumick Chatterjee
1,2,3 a
, Oliver Speck
3,4,5,6 b
and Andreas N
¨
urnberger
1,2 c
1
Faculty of Computer Science, Otto von Guericke University, Magdeburg, Germany
2
Data and Knowledge Engineering Group, Otto von Guericke University, Magdeburg, Germany
3
Biomedical Magnetic Resonance, Otto von Guericke University Magdeburg, Germany
4
German Center for Neurodegenerative Disease, Magdeburg, Germany
5
Center for Behavioral Brain Sciences, Magdeburg, Germany
6
Leibniz Institute for Neurobiology, Magdeburg, Germany
Keywords:
Unsupervised Learning, Deep Learning, MRI Segmentation, Liver Segmentation.
Abstract:
Segmentation of biomedical images can assist radiologists to make a better diagnosis and take decisions faster
by helping in the detection of abnormalities, such as tumors. Manual or semi-automated segmentation, how-
ever, can be a time-consuming task. Most deep learning based automated segmentation methods are supervised
and rely on manually segmented ground-truth. A possible solution for the problem would be an unsupervised
deep learning based approach for automated segmentation, which this research work tries to address. We use a
W-Net architecture and modified it, such that it can be applied to 3D volumes. In addition, to suppress noise in
the segmentation we added attention gates to the skip connections. The loss for the segmentation output was
calculated using soft N-Cuts and for the reconstruction output using SSIM. Conditional Random Fields were
used as a post-processing step to fine-tune the results. The proposed method has shown promising results,
with a dice coefficient of 0.88 for the liver segmentation compared against manual segmentation.
1 INTRODUCTION
Image Segmentation is the process of dividing an im-
age into multiple segments, where the pixels in each
segment are connected with respect to their intensities
or by Regions of Interest (Anjna and Er, 2017). Seg-
mentation of biomedical images is a major advance-
ment in the field of medical imaging, as it helps ra-
diologists and doctors to make better and faster deci-
sions. Many approaches to medical image segmen-
tation using various deep learning techniques have
been proposed. These methods, however, require a
large amount of training data with their respective
segmentation masks also known as ground truth im-
ages (Badrinarayanan et al., 2017; Chaurasia and Cu-
lurciello, 2017; Kr
¨
ahenb
¨
uhl and Koltun, 2011; Paszke
et al., 2016; Zheng et al., 2015). Abdominal MR im-
age segmentation is an interesting and challenging re-
search area (Gotra et al., 2017), but not yet very much
a
https://orcid.org/0000-0001-7594-1188
b
https://orcid.org/0000-0002-6019-5597
c
https://orcid.org/0000-0003-4311-0624
explored, until recently (Kavur et al., 2020). While
performing abdominal segmentation, liver segmenta-
tion is one of the most challenging task due to the high
variability of its shape and its proximity to various
other organs (Gotra et al., 2017). This research ad-
dresses the challenge of segmenting the liver from 3D
MR images without using any manual ground truth
for training the deep neural network model.
Our state of the art model is based on W-Net (Xia
and Kulis, 2017) with both the U-Nets replaced by
Attention U-Nets (Oktay et al., 2018). The original
W-Net works with 2D images, but as we want to work
with volumetric 3D MR images, the network architec-
ture was adapted for 3D images by using 3D convo-
lution layers (Sect. 2.3) and by modifying the calcu-
lation of pixel weights to voxel weights (Sect. 2.2).
We show the applicability of our approach for liver
segmentation using the CHAOS (Kavur et al., 2020)
challenge dataset (Sect. 2.1).
488
Mitta, D., Chatterjee, S., Speck, O. and Nürnberger, A.
Upgraded W-Net with Attention Gates and Its Application in Unsupervised 3D Liver Segmentation.
DOI: 10.5220/0010221504880494
In Proceedings of the 10th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2021), pages 488-494
ISBN: 978-989-758-486-2
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

1.1 Related Work
Many approaches to image segmentation have been
proposed by different researchers. A variety of atlas-
based segmentation methods have been described
(Gee et al., 1993; Crum et al., 2001; Baillard et al.,
2001). Aganj et.al introduced an approach by com-
puting the local center of mass of the putative region
of each pixel, to perform unsupervised medical im-
age segmentation (Aganj et al., 2018). Dong Nie et.al
proposed an approach for brain image segmentation
of infants by using deep neural networks (Nie et al.,
2016). Christ et. al designed an approach by joining
two fully cascaded neural networks for automatic seg-
mentation of the liver and its lesions in low-contrast
heterogeneous medical volumes (Christ et al., 2017).
Oktay et.al introduced a novel attention gate, which
will implicitly learn to suppress regions that are not
relevant (Oktay et al., 2018). These gates are ap-
plied to the standard U-Net architecture to highlight
the important features, which are passed through skip
connections. Noise and irrelevant information in skip
connections are eliminated by extracting coarse-scale
information in gating. This is performed right before
the concatenation operation to merge only relevant ac-
tivations. Xide Xia et.al proposed an approach for a
W-Net model by stacking two U-Nets one after an-
other, for unsupervised image segmentation, but for
non-medical RGB images (Xia and Kulis, 2017). By
using this model, segmentation maps can also be pre-
dicted even for applications, which do not have any
labeling information available.
1.2 Contribution
Most of the research on biomedical image segmen-
tation using deep learning by now has been focused
on supervised learning. This research is a proof-of-
concept for biomedical image segmentation using un-
supervised learning. The current results are not per-
fect, but there are many scopes for improvements -
that will be discussed later. In this research, a novel
3D Attention W-Net architecture has been proposed,
which has been built by replacing the 2D U-Nets of
the original W-Net (Xia and Kulis, 2017), by the 3D
Attention U-Nets (Oktay et al., 2018), and for the re-
construction loss, SSIM (Larkin, 2015) has been used.
Furthermore, some minor changes were introduced
to the Attention U-Net architecture before incorporat-
ing them to the W-Net, which are discussed in a later
chapter.
2 METHODOLOGY
2.1 Dataset
The dataset that has been used in this study has been
provided by the CHAOS Challange (Kavur et al.,
2019; Kavur et al., 2020). The dataset consists of
a CT Dataset of 40 subjects, and an MRI Dataset
of 40 subjects, with two different sequences - T1-
DUAL and T2-SPIR. T1-DUAL contains in-phase
and opposed-phase images. For our work, we choose
the available 40 volumes of T1-DUAL in-phase. The
dataset came with a manually labeled ground-truth.
For the purpose of this research they were intention-
ally ignored during training. Those ground-truths
were used only during the evaluation of the algo-
rithm’s performance.
2.2 Pre-processing
The images were normalized to have pixel values be-
tween (0,1) before supplying them to the network, to
bring them to a common scale for faster convergence
while training. Simultaneously, the weights between
the voxels were calculated using Eq. 1, where w
i j
is the weight between the pixel i and j, which is re-
quired in calculating Normalized-Cuts using Eq. 3
(loss function). The architecture is based on auto-
encoders in which the encoder part maps the input
to the pixel-wise segmentation layer without losing
its original spatial size and the decoder part recon-
structs the original input image from the dense pre-
diction layer.
ω
i, j
= e
−
k
F
i
−F
j
k
2
σ
2
I
∗
e
−
k
X
i
−X
j
k
2
σ
2
X
(1)
2.3 Model Construction: 3D Attention
W-Net
The base W-Net architecture proposed by (Xia and
Kulis, 2017) was modified by replacing both the U-
Nets with 3D Attention U-Nets (Oktay et al., 2018).
The original W-Net was proposed for 2D Images,
both weight calculation and soft ncuts loss calculation
have been adopted for 3D.
The network is illustrated in 1. The network con-
sists of two parts.
• AU-Encoder, which is on the left side of the net-
work and
• AU-Decoder, which is on the right.
Upgraded W-Net with Attention Gates and Its Application in Unsupervised 3D Liver Segmentation
489

Figure 1: 3D Attention W-Net.
The network consists of 18 modules (marked with
dotted lines in Figure 1), each module consists of two
3D convolutional layers with kernel size three. Each
layer is followed by a non-linear activation function
and an instance normalization layer. In total, we are
using 46 3D convolutional layers. The first nine mod-
ules represent the encoder network which predicts the
segmentation maps and the next nine modules recon-
struct the original input image from the segmentation
output coming from the encoder part.
The most frequently used non-linear activation
function is the Rectified Linear Unit (ReLU). How-
ever, there is a chance of dying neurons (Lu et al.,
2019). Therefore, we used the Parametric Rectified
Linear Unit or PReLU (He et al., 2015), which is
similar to LeakyReLU with the difference of using
the hyper-parameter α for negative results, which is
adaptively learnt during the training, instead of using
a fixed value (such as 0.01) as in LeakyReLU. The
data used in this research contain different patient data
and the number of slices differs between subjects. To
construct batches, data padding to an equal number
of pixels would be required. Instead, we used a batch
size of one while training the network.
As mentioned in the literature (Oktay et al., 2018),
the encoder part consists of a contracting path that
captures context and an expansion path that enables
precise localization. As shown in Figure 1, an input
image is given to the first module of the encoder part.
Then it undergoes convolutional operations followed
by PReLU and instance normalization twice before
moving forward to the next module. The modules are
connected through 3D max pooling layers, which de-
crease the image size by two. We also store the orig-
inal image size before performing the pooling opera-
tion recover the image size during the expansion path
of the U-Nets. The initial module produces 64 feature
Figure 2: Attention gate (Oktay et al., 2018).
maps as output and after every module, the number of
features is increased by two.
In the contraction path, modules are connected via
max pool, which is indicated in brown color; in the
expansion path, modules are connected through the
upsample layer followed by modules similar to the
contraction path and are denoted with green color ar-
rows. Upsampling is performed using trilinear inter-
polation, and the output size of the interpolation is set
to the image sizes saved ptior to each of the max pool
operations. Skip connections are passed through at-
tention gates to suppress irrelevant regions and noisy
responses. The attention gate architecture is from
(Oktay et al., 2018) and shown in Figure 2.
The output of the encoder is passed to a fully con-
nected 3D convolution layer with a kernel size of one
and a stride of one, followed by a softmax layer. This
convolution layer helps to map the 64 feature maps of
the output to the required number of K classes, and the
softmax function rescales them to (0,1) with a sum-
mation of all the K feature maps as one. During the
inference stage, the output of the softmax layer is the
final output of the model. During training, the output
of the softmax is given as the input of the first module
of the second U-Net. The second U-Net is similar to
the first one, with the only differences being the final
fully connected convolution layer and the final activa-
tion function. The fully connected layer provides one
final output instead of K outputs. For the final activa-
ICPRAM 2021 - 10th International Conference on Pattern Recognition Applications and Methods
490

tion function, the sigmoid function is used instead of
the softmax, which also rescales the output between
(0,1) but doesn’t make the sum equal to one.
2.4 Loss Functions
We used two loss functions in this research. The first
one is directly after the encoder U-Net, to optimize
the encoder U-Net only; the other one is at the end of
the decoder U-Net to optimize both the U-Nets.
2.4.1 N-Cuts Loss
The first loss function applied to the output of the en-
coder U-Net is the N-Cuts loss (Xia and Kulis, 2017).
The output from the softmax layer of the encoder U-
Net is a K-class prediction for each voxel. Normal-
ized cuts from (Shi and Malik, 2000) as a global cri-
terion for image segmentation, as shown in Eq. 2 are
applied, where A
k
is the number of voxels in segment
k, V is the total number of voxels, and w calculates
the weight between two pixels.
Since the argmax function is non-differentiable, it
is not possible to get the corresponding gradients dur-
ing back-propagation. Therefore, the soft n-cuts loss
(Ghosh et al., 2019) is used as shown in Eq. 3, where
p(u = A
k
) measures the probability of node u belong-
ing to class A
k
. The output of the encoder U-Net is
forwarded to this soft N-Cuts loss function along with
the voxel-weight calculated during the pre-processing
stage, following Eq. 1. The network is trained to min-
imize the N-Cuts loss, by optimizing the parameters
of the encoder U-Net.
Ncut
k
(V ) =
K
∑
k=1
∑
uεA
k
,vε(V −A
k
)
ω(u, v)
∑
uεA
k
,tε(V )
ω(u, t)
(2)
J
so f t−Ncut
(V, K) =
K −
K
∑
k=1
∑
uεV
p(u = A
k
)
∑
uεV
ω(u, v)P(v = A
k
)
∑
uεV
p(u = A
k
)
∑
tεV
ω(u, t)
(3)
2.4.2 Reconstruction Loss
Reconstruction loss is used to calculate the loss be-
tween the output of the decoder U-Net and the in-
put image. The network was trained to minimize the
reconstruction loss similar the auto-encoder architec-
ture. Structural Similarity Index (SSIM) is used to
calculate the reconstruction loss. A higher SSIM,
however, is better and thus the negative of the SSIM
value has been used.The network was trained to min-
imize the reconstruction loss, by optimizing the pa-
rameters of both the U-Nets.
SSIM is used to measure the similarities within
the pixels i.e., whether the pixels in the images those
are being compared have similar pixel density values.
SSIM values lie between (0,1), where 1 indicates that
both images are identical.
We calculate SSIM by using the following for-
mula:
SSIM(x, y) =
(2µ
x
µ
y
+C
1
) + (2σ
xy
+C
2
)
(µ
2
x
+ µ
2
y
+C
1
)(σ
2
x
+ σ
2
y
+C
2
)
(4)
where µ
x
, µ
y
are the mean values of x and y, σ
2
x
,
σ
2
y
are the variance of x and y, σ
xy
is the co-variance
of x and y, C
1
, C
2
are two variables to stabilize the
division with weak denominator.
The network was trained with the MR abdominal
dataset provided by (Kavur et al., 2020), which con-
tains 40 volumes. The given set was divided into a
training (25 volumes), a validation (5 volumes), and a
test set (10 volumes). Both N-cuts and reconstruction
loss were minimized, given equal priority (weights)
to both loss functions.
2.5 Post-processing using Conditional
Random Fields
The use of many max-pooling layers may result in in-
creased invariance, which can cause localization ac-
curacy reduction. To obtain fine boundaries in the
output segments, conditional random fields or CRF
(Chen et al., 2017) were applied as a post-processing
step in a 3D CRF variant (Chatterjee et al., 2020).
E(X) =
∑
φ(u) +
∑
ψ(u, v) (5)
Where u and v are the voxels, φ(u) is the unary
potential and ψ(u, v) is the pair-wise potential.
After the CRF, the cluster values corresponding
to the liver were identified manually for one volume.
The selected clusters were merged to obtain the liver
segmentation for the remaining volumes.
3 RESULTS
We used two U-Nets to form a W-Net for training the
model on a given training dataset; during testing, only
the first U-Net was used, as the output of the first U-
Net corresponds to the automatic segmentation. This
predicted segmentation was then passed through the
CRF post-processing to recover the boundaries. The
network was trained to predict 15 different clusters to
segment various parts of the image. Then, the clusters
with the liver segment were identified as the final re-
sult. The relevant cluster numbers were chosen from
Upgraded W-Net with Attention Gates and Its Application in Unsupervised 3D Liver Segmentation
491

only one test volume and applied to all other test vol-
umes.
The results were compared to the available
ground-truth. Only the liver as our region of interest
was considered from both output and ground-truth.
Two representative slices, corresponding to the man-
ually segmented liver and the predicted segmentation
of the liver are shown in Figure 3 and 4. The pro-
posed liver segmentation is compared to the ground
truth liver segmentation quantitatively using intersec-
tion over union and dice coefficient. The quantitative
evaluation results are shown in Table 1. Task 3 of the
CHAOS challenge (Kavur et al., 2019) was for MRI
liver segmentation and the best model reported a dice
coefficient of 0.95 and the average of all the models
was 0.86 (Kavur et al., 2020). While the proposed
model achieved a dice coefficient (0.88) higher than
the average, it failed to perform better than the best
result. All models in the challenge, however, used the
available ground truth segmentation and were trained
in a supervised manner. Also all models were trained
using all three different types of MRIs available in
the CHAOS dataset (types are discussed in Sect. 2.1),
whereas the proposed non-supervised model was only
trained and tested on T1-DUAL in-phase images. It
can be observed that the vessels, which were consid-
ered part of the liver by the rater during manual seg-
mentation, except for one (as can be seen in Figure 4),
were not included by the proposed network.
Table 1: Quantitative analysis of the performance (only for
the ROI).
Metric Values
Intersection over Union (IoU) 0.7885
Dice Coefficient 0.8812
4 FUTURE WORK
This paper stands as a proof of concept for unsu-
pervised biomedical image segmentation using the
proposed 3D Attention W-Net. Further tests will be
performed to evaluate the robustness of the approach
as well as the clinical applicability. This approach
will also be compared against other unsupervised seg-
mentation methods. Only the T1-DUAL in-phase vol-
umes were used, even though the CHAOS dataset also
contains T1-DUAL opposed-phase and T2-SPIR vol-
umes. Evaluation of the performance with the other
available contrasts may further improve the results.
A mixed training approach combining T1-DUAL
in-phase, opposed-phase and T2-SPIR is a fur-
ther option.
In the presented approach, CRF was applied to
post-process the results. A direct inclusion of CRF
within the model before N-Cuts during training may
be beneficial. A further option is a semi-supervised
version of the algorithm, applying pre-training (both
U-Nets separately) with a manually labeled small
dataset followed by unsupervised training as de-
scribed in this contribution.
5 CONCLUSION
In this work, we propose an extension of current deep
learning approaches (W-Net) for unsupervised seg-
mentation of non-Medical RGB to volumetric med-
ical image segmentation. The model was enhanced
by using attention gates and extended to a 3D atten-
tion W-Net. The results demonstrate that the proposed
model can be used for unsupervised segmentation of
medical images. However, further experiments are
needed to judge the robustness and generalizability of
the approach. One reason for the remaining devia-
tion from the manual segmentation may be that the
ground truth images supplied in the dataset provide
liver segmentation including liver vessels. These were
not included by our unsupervised approach but were
naturally included as part of the liver by the super-
vised network. Our proposed network correctly seg-
mented the liver without inclusion of these vessels.
Thus unsupervised learning may be used to enrich or
guide manual expert annotation. Future research on
the learning approach itself will include end-to-end
training by incorporating conditional random fields in
the training pipeline. We expect that pre-training both
U-Nets of the W-Net separately on a small ground
truth set in a supervised manner may also further im-
prove the results.
ACKNOWLEDGEMENTS
This work was in part conducted within the context
of the International Graduate School MEMoRIAL at
the Otto von Guericke University (OVGU) Magde-
burg, Germany, kindly supported by the European
Structural and Investment Funds (ESF) under the pro-
gramme ”Sachsen-Anhalt WISSENSCHAFT Inter-
nationalisierung” (project no. ZS/2016/08/80646).
ICPRAM 2021 - 10th International Conference on Pattern Recognition Applications and Methods
492
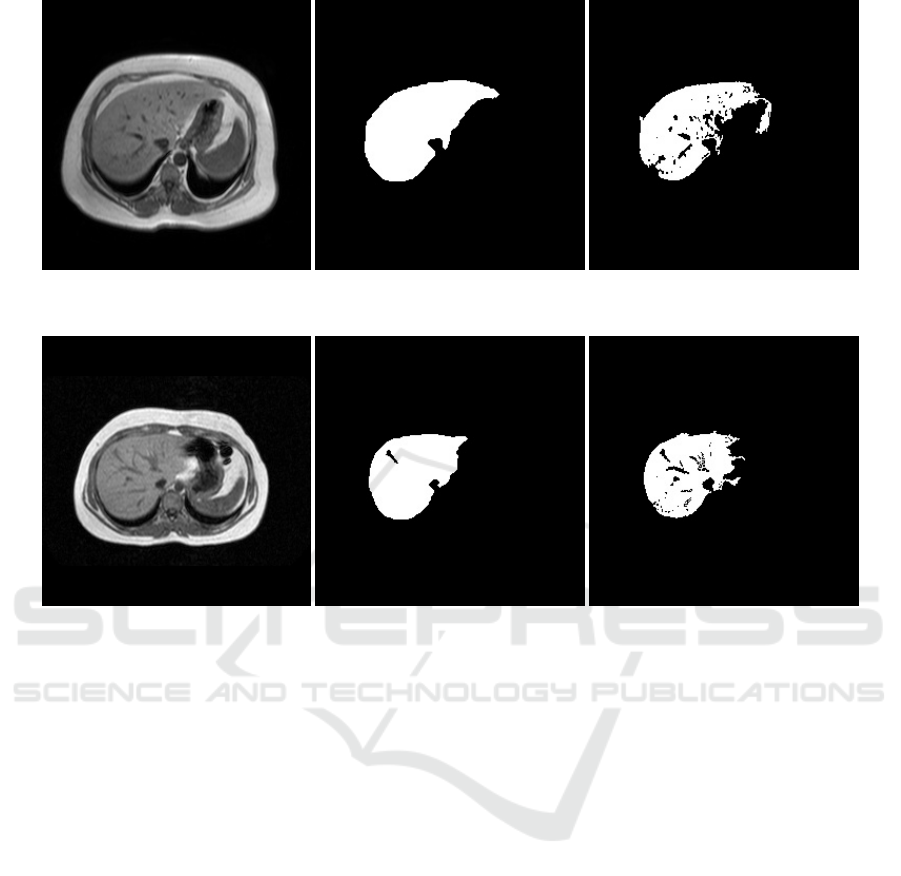
Figure 3: Example slice of a test volume: From left to right - Original slice, Ground Truth, only the liver segment, Output of
the network - Clusters containing the liver segmentation were considered as our region of interest.
Figure 4: Example slice of a test volume: From left to right - Original slice, Ground Truth, only the liver segment, Output of
the network - Clusters containing the liver segmentation were considered as our region of interest.
REFERENCES
Aganj, I., Harisinghani, M. G., Weissleder, R., and Fischl,
B. (2018). Unsupervised medical image segmentation
based on the local center of mass. Scientific reports,
8(1):13012.
Anjna, E. A. and Er, R. K. (2017). Review of image seg-
mentation technique. International Journal of Ad-
vanced Research in Computer Science, 8(4).
Badrinarayanan, V., Kendall, A., and Cipolla, R. (2017).
Segnet: A deep convolutional encoder-decoder ar-
chitecture for image segmentation. IEEE transac-
tions on pattern analysis and machine intelligence,
39(12):2481–2495.
Baillard, C., Hellier, P., and Barillot, C. (2001). Segmenta-
tion of brain 3d mr images using level sets and dense
registration. Medical image analysis, 5(3):185–194.
Chatterjee, S., Bickel, M., and Krishna, S. (2020).
soumickmj/denseinferencewrapper: Initial release.
Chaurasia, A. and Culurciello, E. (2017). Linknet: Exploit-
ing encoder representations for efficient semantic seg-
mentation. In 2017 IEEE Visual Communications and
Image Processing (VCIP), pages 1–4. IEEE.
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., and
Yuille, A. L. (2017). Deeplab: Semantic image seg-
mentation with deep convolutional nets, atrous convo-
lution, and fully connected crfs. IEEE transactions on
pattern analysis and machine intelligence, 40(4):834–
848.
Christ, P. F., Ettlinger, F., Gr
¨
un, F., Elshaera, M. E. A.,
Lipkova, J., Schlecht, S., Ahmaddy, F., Tatavarty, S.,
Bickel, M., Bilic, P., et al. (2017). Automatic liver
and tumor segmentation of ct and mri volumes using
cascaded fully convolutional neural networks. arXiv
preprint arXiv:1702.05970.
Crum, W. R., Scahill, R. I., and Fox, N. C. (2001). Au-
tomated hippocampal segmentation by regional fluid
registration of serial mri: validation and application in
alzheimer’s disease. Neuroimage, 13(5):847–855.
Gee, J. C., Reivich, M., and Bajcsy, R. (1993). Elastically
deforming a three-dimensional atlas to match anatom-
ical brain images. University of Pennsylvania Institute
for Research in Cognitive Science Technical Report
No. IRCS-93-37.
Ghosh, S., Das, N., Das, I., and Maulik, U. (2019). Under-
standing deep learning techniques for image segmen-
tation. ACM Computing Surveys (CSUR), 52(4):73.
Gotra, A., Sivakumaran, L., Chartrand, G., Vu, K.-N.,
Vandenbroucke-Menu, F., Kauffmann, C., Kadoury,
S., Gallix, B., de Guise, J. A., and Tang, A. (2017).
Upgraded W-Net with Attention Gates and Its Application in Unsupervised 3D Liver Segmentation
493

Liver segmentation: indications, techniques and fu-
ture directions. Insights into imaging, 8(4):377–392.
He, K., Zhang, X., Ren, S., and Sun, J. (2015). Delv-
ing deep into rectifiers: Surpassing human-level per-
formance on imagenet classification. In Proceedings
of the IEEE international conference on computer vi-
sion, pages 1026–1034.
Kavur, A. E., Gezer, N. S., Barıs¸, M., Conze, P.-H., Groza,
V., Pham, D. D., Chatterjee, S., Ernst, P.,
¨
Ozkan, S.,
Baydar, B., Lachinov, D., Han, S., Pauli, J., Isensee,
F., Perkonigg, M., Sathish, R., Rajan, R., Aslan, S.,
Sheet, D., Dovletov, G., Speck, O., N
¨
urnberger, A.,
Maier-Hein, K. H., Akar, G. B.,
¨
Unal, G., Dicle, O.,
and Selver, M. A. (2020). Chaos challenge – com-
bined (ct-mr) healthy abdominal organ segmentation.
Kavur, A. E., Selver, M. A., Dicle, O., Barıs¸, M., and Gezer,
N. S. (2019). CHAOS - Combined (CT-MR) Healthy
Abdominal Organ Segmentation Challenge Data.
Kr
¨
ahenb
¨
uhl, P. and Koltun, V. (2011). Efficient inference in
fully connected crfs with gaussian edge potentials. In
Advances in neural information processing systems,
pages 109–117.
Larkin, K. G. (2015). Structural similarity index ssimpli-
fied: Is there really a simpler concept at the heart
of image quality measurement? arXiv preprint
arXiv:1503.06680.
Lu, L., Shin, Y., Su, Y., and Karniadakis, G. E. (2019). Dy-
ing relu and initialization: Theory and numerical ex-
amples. arXiv preprint arXiv:1903.06733.
Nie, D., Wang, L., Gao, Y., and Shen, D. (2016). Fully con-
volutional networks for multi-modality isointense in-
fant brain image segmentation. In 2016 IEEE 13Th in-
ternational symposium on biomedical imaging (ISBI),
pages 1342–1345. IEEE.
Oktay, O., Schlemper, J., Folgoc, L. L., Lee, M., Heinrich,
M., Misawa, K., Mori, K., McDonagh, S., Hammerla,
N. Y., Kainz, B., et al. (2018). Attention u-net: Learn-
ing where to look for the pancreas. arXiv preprint
arXiv:1804.03999.
Paszke, A., Chaurasia, A., Kim, S., and Culurciello, E.
(2016). Enet: A deep neural network architecture
for real-time semantic segmentation. arXiv preprint
arXiv:1606.02147.
Shi, J. and Malik, J. (2000). Normalized cuts and image
segmentation. Departmental Papers (CIS), page 107.
Xia, X. and Kulis, B. (2017). W-net: A deep model for fully
unsupervised image segmentation. arXiv preprint
arXiv:1711.08506.
Zheng, S., Jayasumana, S., Romera-Paredes, B., Vineet, V.,
Su, Z., Du, D., Huang, C., and Torr, P. H. (2015). Con-
ditional random fields as recurrent neural networks. In
Proceedings of the IEEE international conference on
computer vision, pages 1529–1537.
ICPRAM 2021 - 10th International Conference on Pattern Recognition Applications and Methods
494
