
Ontology-based Approach for Business Opportunities Recognition
Vinicius Ferreira Salgado
1
, Diego Bernardes de Lima Santos
1
,
Frederico Giffoni de Carvalho Dutra
2 a
, Fernando Silva Parreiras
3 b
and Wladmir Cardoso Brand
˜
ao
1 c
1
Department of Computer Science, Pontifical Catholic University of Minas Gerais (PUC Minas), Belo Horizonte, Brazil
2
Companhia Energ
´
etica de Minas Gerais (CEMIG), Belo Horizonte, Brazil
3
Laboratory for Advanced Information Systems, FUMEC University, Belo Horizonte, Brazil
Keywords:
Business Opportunity, Information Extraction, Web Crawler, Ontology.
Abstract:
The Web is the main source of business related information due to its accessibility, diversity and huge size,
resulting from the high degree of collective engagement. However, extracting relevant information from this
vast environment to use in decision making by organizational staff is a great challenge. In particular, the
gathering of information related to business opportunities and its effective treatment to extract pieces of useful
information to predict consumer and market behavior is essential for organizational survival. Although some
approaches for handling business related information from Web have been proposed in literature, they under
exploit contextual semantic patterns for information extraction, e.g., the set of properties related to the business
opportunity topic. The present article proposes an ontology-based approach to recognize business opportuni-
ties from business related news extracted from the Web. Experimental results show that of our approach can
effectivelly recognize business opportunities, reaching up to 90% of accuracy.
1 INTRODUCTION
The leading search engine has reported the index of
more than one trillion uniquely addressable docu-
ments and the processing of more than 40 thousand
user queries each second (Cutts, 2012). The acces-
sibility, diversity and massive-scale nature make the
Web the main source of information and services for
business, demanding efficient approaches to retrieve
and filter relevant content for decision making by or-
ganizational staff. Particularly, organizations increas-
ingly use the Web to improve their performance, min-
ing business opportunities that can result in higher
profits. The United States Federal Trade Commis-
sion
1
defines a business opportunity as an invest-
ment that allows the beginning of a business, usu-
ally involving the sale or lease of a product or service
that enable the purchaser-licensee to begin a business.
Broadly, a business opportunity is a situation in which
a
https://orcid.org/0000-0002-8666-0354
b
https://orcid.org/0000-0002-9832-1501
c
https://orcid.org/0000-0002-1523-1616
1
https://www.ftc.gov
it is possible for people and enterprises to buy, sell,
exchange, lease or acquire products and services.
Crawling business information from the Web with
no proper treatment does not provide organizations
with the capacity to make assertive decisions. Ad-
ditionally, crawling business information from Web
pages demands filtering those exclusively related to
business opportunities, recognize entities related to
the opportunities, estimate important missing values
and rank the opportunities according to a business cri-
teria that optimize decision making by the organiza-
tional staff. Therefore, an ontology-based approach to
extract information related to business opportunities
from Web is paramount for organizational effective-
ness. In this article, one proposes BOR, an ontology-
based approach for business opportunities recogni-
tion. Particularly, the ontology is used to drive the
extraction of information on business opportunities
from business related news collected from Web. One
assesses the effectiveness of the proposed approach
by using it in a real organizational scenario to build a
business opportunity dataset for a large Brazilian en-
ergy company. The main contributions of this article
are: i) BOR, an ontology-based approach for busi-
594
Salgado, V., Santos, D., Dutra, F., Parreiras, F. and Brandão, W.
Ontology-based Approach for Business Opportunities Recognition.
DOI: 10.5220/0010400105940601
In Proceedings of the 23rd International Conference on Enterprise Information Systems (ICEIS 2021) - Volume 1, pages 594-601
ISBN: 978-989-758-509-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

ness opportunities recognition from business news; ii)
a throughout evaluation of BOR by assessing its ef-
fectiveness in a real organizational scenario and; iii)
a business opportunity dataset with public business
news extracted from the Web.
The present article is organized as follows: Sec-
tion 2 presents literature review. Section 3 presents re-
lated work. Section 4 presents OntoBE, the ontology
used by the proposed approach to drive the business
opportunities recognition process. Section 5, presents
BOR, the ontology-based approach to recognize busi-
ness opportunities from business related news. Sec-
tion 6 presents the experimental setup, followed by
experimental results in Section 7. Finally, Section 8
concludes, pointing directions for future work.
2 BACKGROUND
2.1 Web Crawlers
Information retrieval (IR) is the research field that
investigates the representation, storage, organization
and access to information items to provide easy ac-
cess for users to information of their interest (Baeza-
Yates and Ribeiro-Neto, 2011). In particular, infor-
mation items typically correspond to text documents.
Thereby, an information retrieval system (IRS) re-
trieves relevant documents related to a user informa-
tion need expressed by a query. IRS should not only
to decide which documents to retrieve, or how to ex-
tract relevant pieces of information from such doc-
uments, but mainly to decide what is relevant for
users (Brand
˜
ao et al., 2014).
Web crawlers collect documents from the Web as
fast as possible to build a comprehensive local corpus
of documents (Pant et al., 2004). For this, they send
requests for documents to web servers and process the
responses to download and store the collected docu-
ments into a corpus (Dr. K. Iyakutti, 2017).
2.2 Web Extractors
Information extraction (IE) is the task of automati-
cally extracting structured information from unstruc-
tured or semi-structured documents (Yu et al., 2014).
In most cases, this task concerns processing human
language through natural language processing (NLP).
In particular, an information extraction system (IES)
transforms the raw material collected by IRS, refining
and reducing it to a germ of the original text. It starts
with a collection of relevant text, such as newspaper
and journal articles, transforming them into informa-
tion that is more readily digested and analyzed by
isolating relevant text fragments, extracting relevant
information from the fragments and piecing together
targeted information in a coherent framework (Cowie
and Lehnert, 1996). Thereby, web extractors are IES
that extracts pieces of information from web docu-
ments. While web crawlers collect documents from
Web, web extractors retrieves pieces of relevant in-
formation from collected documents.
One of the most known application of web ex-
tractors is the extraction of entities, such as persons,
organizations, locations and monetary values, from
text documents, a task called Named Entity Recogni-
tion and Classification (NERC) (Nadeau and Sekine,
2007).
2.3 Text Classification
Text classification or categorization, and document
classification or categorization, refer to the task of as-
signing a document, or a piece of text, to one or more
classes or categories (Mladeni et al., 2010). Text clas-
sification can be performed either through manual an-
notation or by automatic labeling. With the growing
scale of text data in industrial applications, automatic
text classification is becoming increasingly important
(Minaee et al., 2020). They are particularly useful
in the processing of information extracted from the
Web, composed of a huge volume of textual docu-
ments. Text classification is also a challenging task
due to the great diversity of languages and dialects
(Lai et al., 2020).
Usually, text classification approaches are com-
posed by distinct components, such as text extrac-
tors, content transformers, classifiers and evaluators.
In particular, the initial entry consists of a set of raw
text data D = {d
1
, d
2
, ...,d
N
} usually extracted from
a set of unstructured documents (Aggarwal and Zhai,
2012). Then a set of transformation procedures, re-
ferred as text pre-processing, can be performed on D,
such as tokenization, lower case conversion, special
character removal, accent replacement, stop word re-
moval, stemming and lemmatization. Next, a classi-
fier implemented from a large set of classification al-
gorithms is applied to the D to determine the classes
associated with each element. Finally, the classifier’s
effectiveness is estimated using statistic procedures
and effectiveness metrics (Aggarwal and Zhai, 2012).
3 RELATED WORK
The h-TechSight system detects changes and trends in
business related information to monitor business mar-
kets over a period of time (Kokossis et al., 2005). The
Ontology-based Approach for Business Opportunities Recognition
595

authors present experimental results focusing in job
advertisement and argue that their system has been
tested by real users in industry, increasing the effi-
ciency of acquiring knowledge and supporting indus-
try projects. In the same vein, an ontology-based
approach for information extraction (Saggion et al.,
2007) focus in e-business, recognizing relevant con-
cepts in business documents, such as acquisition, part-
nerships, contracts and investments. The authors
present an automatic annotator of information ex-
tracted from the Web that identifies the link between
ontology and annotated text, and an application that
extracts business related information per location.
The MBOI approach (Bai et al., 2004; Tajarobi
et al., 2005) collects and classifies business related
documents (calls for tenders) from Web by using a
classification model based on language modeling with
unigrams. The authors argue that MBOI was used
by several companies that reported a significant im-
provement in their business activities. In an extended
work (Paradis et al., 2005) the authors improve MBOI
by incorporating text entity extractors for locations,
organizations, dates and money.
Web news portals expose their content through
different platforms to reach more readers, such as so-
cial networks. Thus, the search for information on
these platforms becomes an interesting objective. For
instance, business opportunities can be found on sev-
eral crowdfunding sites. Crowdfunding is the prac-
tice of funding a venture by raising money from a
large number of people. Kickstarter (An et al., 2014)
crawls business posts from Twitter to recommend in-
vestors for crowdfunding projects. The recommenda-
tion approach uses text classification with supervised
learning to evaluate the content of tweets, resulting in
a effective textual classification.
Similarly to the other approaches previously re-
ported in literature (Duarte et al., 2007; Pirovani and
Oliveira, 2018) where the authors present an outper-
forming effectiveness of web extractors for NLP tasks
in Portuguese, in this article one address the problem
of crawling business related information from Por-
tuguese news in the Web and extract from them busi-
ness related information. But different from them,
one use an enterprise ontology to drive the crawling
and extraction of business opportunities.
4 THE ONTOBE ONTOLOGY
Ontologies enable the explicit definition of the logical
structure of concepts and their relationships to gen-
erate common understanding about a specific topic,
also reducing development time and cost for the topic
modeling and improving data quality. An ontology
should be independent from a computer or social con-
text, be consistent and also hold the lowest number
of claims (Gruber, 1993). The BOR approach uses
the OntoBE ontology (Falci et al., 2020) to drive the
business opportunities recognition process. OntoBE
is applied on the crawler, filter and in the classifica-
tion steps, providing improvements in the accuracy of
these components. The ontology does not represent
all business strategies, but rather the universe of busi-
ness based on new developments and expansion of
productive capacity, resulting in news which is more
relevant for the business opportunities context. Figure
1 presents the main concepts and conceptual relation-
ships provided by OntoBE.
OntoBE focuses in relationships between people,
processes and technologies and was designed to sup-
port decision making, such as the case of customers
needing to search for business expansion attributes
and researchers needing to provide statistics and ex-
plain interactions of people and processes of business
expansion information gathering. OntoBE addresses
particular functional requirements, such as general
news, information on companies and industrial sec-
tors, company directories, product, biographical, fi-
nancial, investment, legal an statistical information,
and market research. The information on companies
and industrial sectors corresponds to academic jour-
nals related to business publications, financial publi-
cations and newspapers dedicated to business. As pre-
viously mentioned events covered by OntoBE poten-
tially incorporate business opportunities. For instance
the acquisition, merge or expansion of a company, the
growth happened due to the financial amount invested
increasing its production capacity possibly generating
new jobs, aiming an improvement in revenue.
5 THE BOR APPROACH
Figure 2 presents the BOR architecture and from it
one observe that first, the crawler component extracts
news from Web,s starting with a list of seed URLs.
The URLs in the list contain addresses of business
related sites and portals. The crawler component ex-
tracts information such as author, date of last mod-
ification, description, text, title and the URL of the
crawled news and store them in the Business News
database. Particularly, the database also stores all the
original news. The OntoBE provides business con-
cepts that supply the crawling strategy.
Second, the filter component performs the follow-
ing procedures over the data stored in the Business
News database: removal of duplicate links, removal
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
596
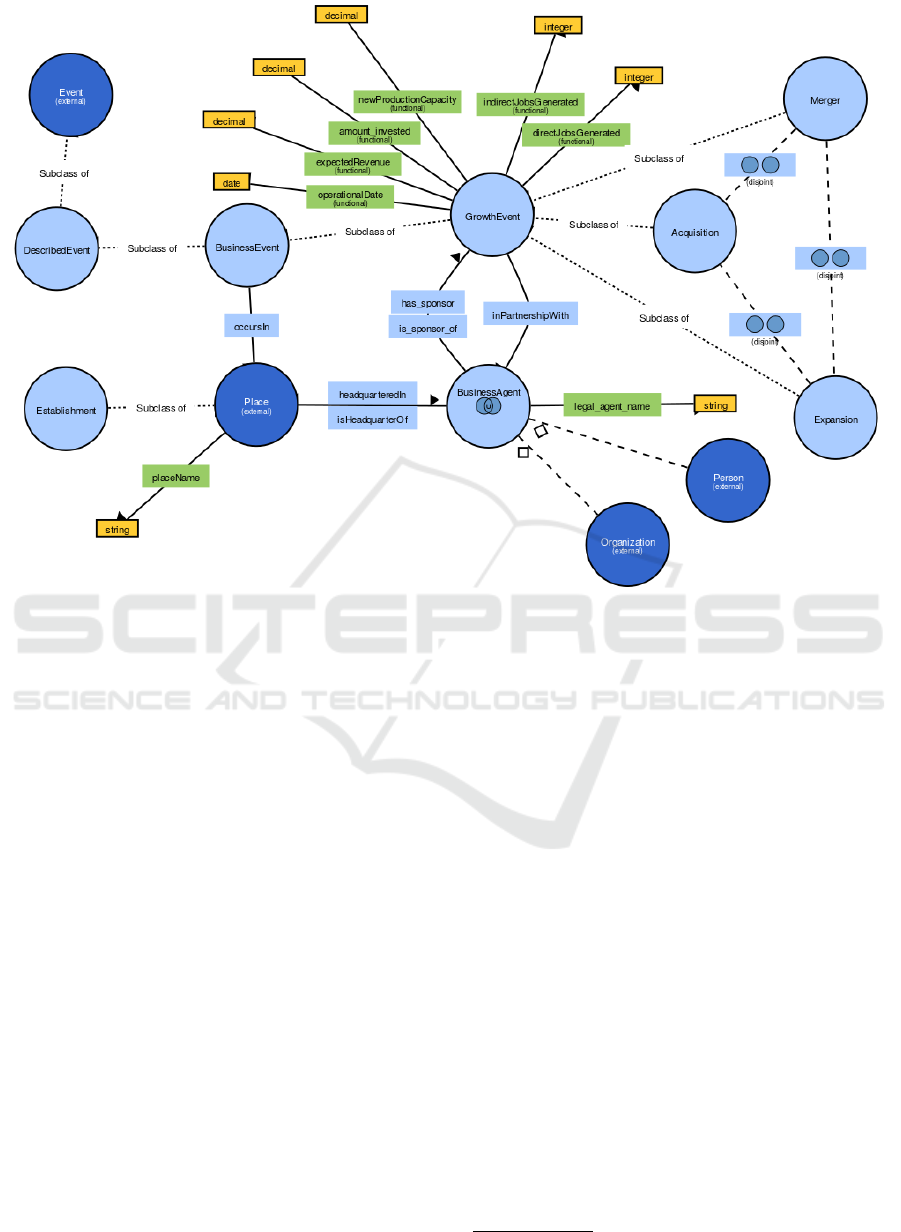
Figure 1: The OntoBE ontology.
of invalid links, removal of news that doesn’t have ti-
tle or full text. The objective of this step is to build
a pre-processed news repository with relevant con-
tent that can be effectively used for text classification.
All filtered content are stored in the Business Con-
tent repository. In particular, the Business Content
repository stores the title, description, URL, status,
the queue for adding related entities and the news full
text. Once again, the OntoBE provides business con-
cepts and taxonomy that supports the content filtering.
Third, the classifier component performs the clas-
sification of news. In particular, it learns how to clas-
sify business news from labeled examples extracted
from the Business Content repository. For the initial
classification, the news was manually labeled in or-
der to enrich the automatic classification. The man-
ual classification were made by specialists and ana-
lyzes the words contained in the title, description and
full text. After labeling, the text is classified through
the text classification technique and stored in Busi-
ness Opportunities News for future entity extraction.
Finally, the extractor component recognize enti-
ties in business opportunities news. The objective of
this step is to extract OntoBE entities from classified
news to highlight business opportunities.
6 EXPERIMENTS
This section presents the experiments one carried out
to evaluate the BOR approach, including experimen-
tal setup and procedures. In particular, the exper-
iments answer the following research questions: i)
How effective is BOR to collect and filter business
related news from Web? ii) Which textual features
provide positive impact on the classification perfor-
mance? iii) How does BOR perform to recognize
business opportunities from business related news?
6.1 Crawler Setup
The crawler component uses two different strategies
to collect news from Web: vertical and horizontal.
The vertical strategy uses a seed of Brazilian news
portals, going in-depth search on the sites. The hori-
zontal strategy uses a set of keywords to collect news
pages from Web by using a programmable search en-
gine
2
. The domains for the vertical crawling and the
keywords for the horizontal crawling related to busi-
ness related news were constantly evaluated and up-
dated to enrich the Business News database. In partic-
2
https://developers.google.com/custom-search
Ontology-based Approach for Business Opportunities Recognition
597
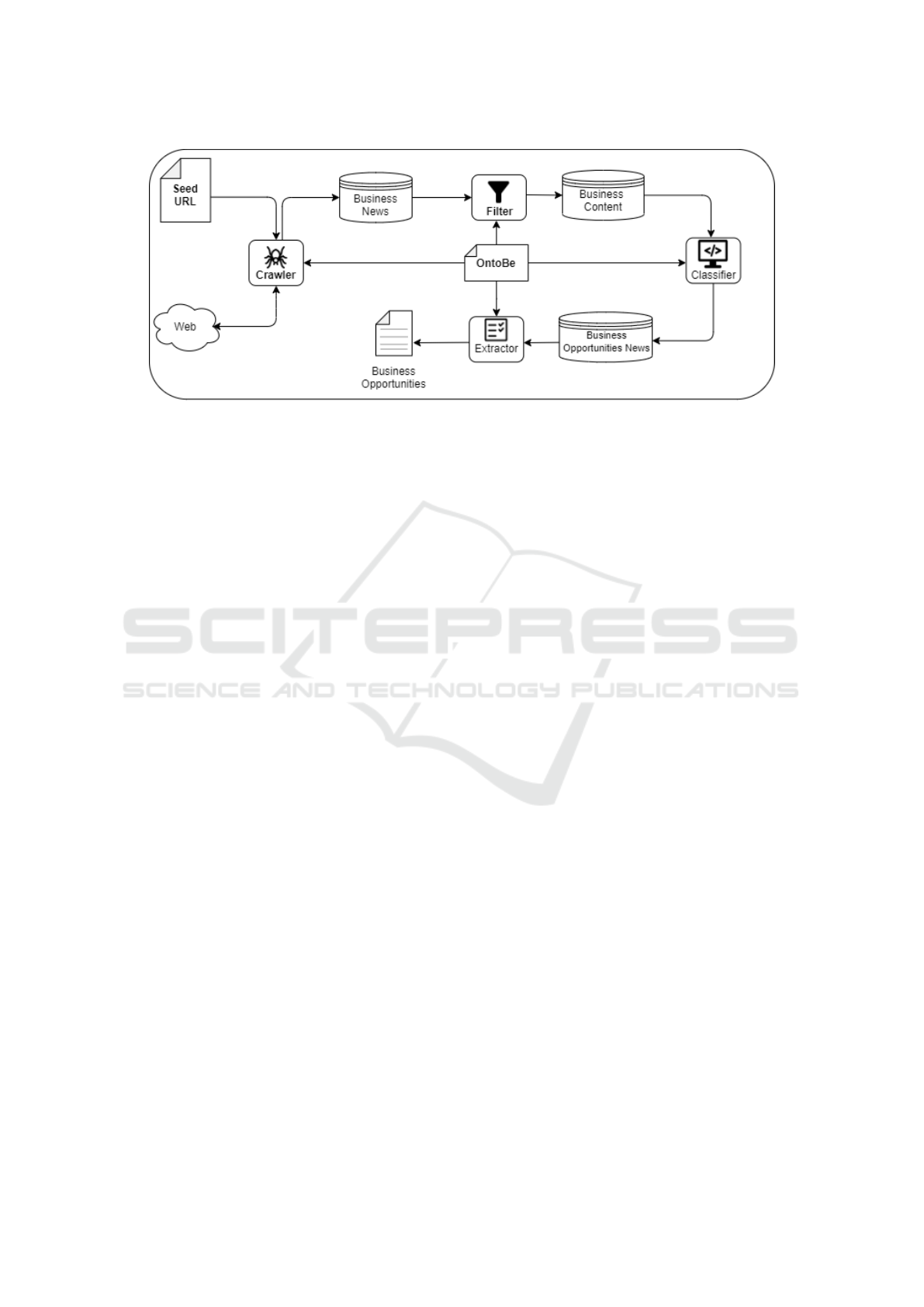
Figure 2: The BOR architecture.
ular, domains are automatically changed to get news
in sites where there are more business related news.
Keywords are automatically updated according to the
most used terms in business related news. The crawler
is able to search for data and recognize content fields
such as author, download date, modified date, pub-
lished date, description, filename, image URL, lan-
guage, source domain, page title, URL and full text.
6.2 Filter Setup
In the filtering step one define requirements for rele-
vant news to be recognized as business related news.
A reference database provided by R&D CEMIG was
used for this. It contains business related news as de-
fined by OntoBE presented in Figure 1 and follows
the definition of business opportunity. In particular,
first a check is performed on the language that must
be set as Portuguese, to get news in Portuguese. Then,
the process described in Section 5 its applied. Finally,
the news is stored in the Business Content repository
with ID: unique identifier for the news, the same one
defined on the Business News database; Title: the title
of the news; Description: the description of the news;
Full Text: the full text (the entire body) of the news;
URL: the news URL from where it was crawled; Sta-
tus: the news class to be set by the classifier, e.g.
“null” for non-classified, positive for business related
news and negative for business unrelated news; Enti-
ties: a list with entities to be extracted from the news.
6.3 Classifier Setup
The classifier is responsible to associate news to
classes based on the news content and considering
the business context. News text should go through
a process of normalization. These process consists of
steps as show in Section 2.3, also removing the quota-
tion marks that is commonly used in Portuguese, be-
sides removing large spaces between text segments
and also line breaks. Particularly, the classification
evaluation can be defined as follows: 1) Reading and
processing the news in the Business Content reposi-
tory; 2) Evaluation with four different sources of tex-
tual features extracted from the news: i) Title; ii) Title
+ Description; iii) Title + Full Text; iv) Title + De-
scription + Full text; 3) Evaluation of the effective-
ness of each classifier with different training and test
configurations; 4) Identification of the most effective
approaches to identify business related news.
The classification process is carried out initially
with a quantity of news and, to simulate the operating
environment, it was necessary to include more news
and perform the reclassification, with the intention of
leaving the classifier with a better accuracy. To eval-
uate the classification, different algorithms were used
to generate the models, particularly the algorithm RF
(Random Forest) with the maximum depth of the tree
in 5, the number of trees in the forest in 10 and 1 of
features to consider when looking for the best split.
The algorithm SVM (Support Vector Machine) with
linear kernel with tolerance for stopping criteria in
1e−4 and the algorithm NN (Neural Network) imple-
mented using a multi-layer perceptron with regular-
ization L2 in 1 and with a maximum number of inter-
actions in 1000. Finally, after the classification, the
news are available for the extraction of entities.
6.4 Extractor Setup
The extractor component is responsible to recognize
different entities in the news such as organizations,
people and locations. The process consists of ex-
tracting entities based on the OntoBE ontology, where
they are initially extracted as common entities, for ex-
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
598

ample, investment extraction begins with three extrac-
tions (’$’, ’SYM’), (’26’, ’NUM’), (’billion’, ’NUM’)
resulting in the entity (’$26 billion’, ’AMOUNT IN-
VESTED’). For a better understanding, the extraction
process can be defined as follows: 1) Reading the pre-
classified business related news; 2) Extract entities
driven by the OntoBE ontology, resulting in business
opportunities entities; 3) Evaluation of the effective-
ness of the entity extractor.
7 EXPERIMENTAL RESULTS
This section presents the experimental results that
support the answers for the three research questions
presented in Section 6. In particular, one build differ-
ent datasets to support experiments
3
, presenting ex-
perimental results of two cycles of tests.
7.1 Crawling Effectiveness
In this section, one address the first research ques-
tion by assessing the effectiveness of the crawler and
filter components. The average crawling rate was
150 documents per minute and the requests were dis-
tributed in time to avoid web servers overload. Table 1
presents the amount of news in each cycle.
Table 1: Number of news.
Process Quantity
First Cycle Second Cycle
Crawling 1,466 10,834
Filtering 504 3,702
Valid links 962 7,132
The removal step consists of eliminating some news
after applying the filter. After this process the result
of valid links is obtained. Then, they will initially be
classified manually, in order to create a labeled basis
for the classification process.
7.2 Classification Efectiveness
In this section, one address the second research ques-
tion, assessing approaches to classify business related
news. Table 2 and 3 show the accuracy in first cy-
cle for each algorithm used to filter news with dif-
ferent resources for each training and test configura-
tion. One evaluates four different sources of textual
resources extracted from the business related pages:
i) Title (TO); ii) Title + Description (TD); iii) Ti-
tle + Full Text (TF); iv) Title + Description + Full
3
http://doi.org/10.5281/zenodo.4019968
text (ALL). Significance is verified with a two-tailed
paired t-test (Jain, 1991), with the symbol N (H) de-
noting a significant increase (decrease) at the p < 0.05
level, and the symbol • denoting no significant differ-
ence.
The result of first cycle shows that the RF clas-
sifier is less effective than the others, as it contains
few words related to the business context. In addition,
Linear SVM classifier outperforms the others with an
accuracy from 94% to 100%, depending on the num-
ber of instances used in the training. In order to carry
out the evolution of the classification by adding new
business related news, Table 4 and 5 present the re-
sults for the second cycle. In this scenario, the Lin-
ear SVM classifier outperforms the other classifiers.
These results show that the algorithm is capable of as-
sociating relevant words to the business context. Re-
membering our goals, these observations attest to the
effectiveness of our approach to collect and filter busi-
ness related news.
7.3 Extractor Effectiveness
In this section, one address the third research question
by assessing the effectiveness of our approach to rec-
ognize entities in business related news. In particular,
BOR uses a supervised learning model to recognize
entities in Portuguese.
The result of extraction shows that not all entities
were extracted from news related to business. The
amount invested and the local information are the
most important for classified news. To circumvent
the problem of null fields, the database ”business enti-
ties”, as shown in Figure 2, stores all news with their
respective entities. Table 6 shows the accuracy for
the entities of OntoBE. The information as investing
company (legal agent name) and local (placeName)
is present in more than 90% of the news. Both in-
formation is crucial for further research, if necessary.
The information from entities about the expected re-
turn on investment, the beginning of the new opera-
tion and new production capacity impacted the final
accuracy by not containing much information in the
news. The news available does not have details nec-
essary to fill these entities. For the BOR architecture,
the information extracted according to the OntoBE
ontology reaches an accuracy of 36% of 423 news
classified as business related.
8 CONCLUSION
This article introduced BOR, the ontology-based ap-
proach to recognize business opportunities from busi-
Ontology-based Approach for Business Opportunities Recognition
599

Table 2: Classification accuracy in the first cycle of news of TO and TD.
Train/Test TO TD
RF SVM NN RF SVM NN
90/10 0.6610 (±2.93e−5) 0.8252 (±1.57e−5) N 0.8252 (±1.57e−5) N• 0.6184 (±6.63e−6) 0.8463 (±4.01e−5) N 0.8463 (±4.01e−5) N•
80/20 0.6461 (±2.55e−6) 0.8860 (±8.39e−6) N 0.8860 (±8.39e−6) N• 0.6062 (±3.24e−7) 0.9276 (±1.27e−6) N 0.9174 (±3.15e−6) NH
70/30 0.5950 (±2.12e−6) 0.8958 (±3.39e−6) N 0.8709 (±3.15e−6) NH 0.5847 (±7.28e−7) 0.9655 (±1.90e−6) N 0.9344 (±1.49e−6) N•
60/40 0.5843 (±9.61e−7) 0.9142 (±1.19e−6) N 0.9090 (±1.58e−6) NH 0.5922 (±4.03e−7) 0.9714 (±6.47e−7) N 0.9688 (±6.65e−7) N•
50/50 0.5881 (±1.99e−6) 0.9296 (±4.98e−7) N 0.9230 (±5.87e−7) N• 0.6154 (±3.24e−6) 0.9631 (±9.84e−8) N 0.9730 (±3.39e−7) NH
40/60 0.5761 (±3.57e−8) 0.9446 (±5.29e−8) N 0.9308 (±1.65e−7) NH 0.5847 (±8.56e−8) 0.9809 (±1.78e−7) N 0.9740 (±2.32e−7) NH
30/70 0.5861 (±1.72e−8) 0.9450 (±1.29e−7) N 0.9371 (±1.20e−7) N• 0.5801 (±5.10e−9) 0.9822 (±5.64e−8) N 0.9792 (±1.15e−7) NH
20/80 0.5766 (±3.20e−9) 0.9506 (±4.30e−8) N 0.9046 (±2.25e−7) NH 0.5805 (±3.56e−8) 0.9844 (±3.57e−8) N 0.9597 (±7.25e−8) NH
10/90 0.5768 (±6.04e−8) 0.9572 (±5.47e−8) N 0.9491 (±2.79e−8) NN 0.5848 (±2.20e−7) 0.9838 (±1.75e−8) N 0.9826 (±1.53e−8) NH
Table 3: Classification accuracy in the first cycle of news of TF and ALL.
Train/Test TF ALL
RF SVM NN RF SVM NN
90/10 0.6084 (±4.27e−6) 1.0000 N 0.9689 (±6.62e−6) NH 0.6594 (±8.02e−6) 0.9794 (±6.50e−6) N 0.9689 (±6.62e−6) NH
80/20 0.6164 (±6.24e−7) 0.9894(±1.62e−6) N 0.9842 (±3.64e−6) N• 0.6112 (±1.05e−6) 0.9894 (±1.62e−6) N 0.9842 (±3.65e−6) NH
70/30 0.6124 (±8.10e−6) 0.9896 (±1.43e−7) N 0.9826 (±2.37e−7) N• 0.6055 (±3.67e−7) 0.9861 (±9.64e−8) N 0.9792 (±9.36e−8) NH
60/40 0.5999 (±2.57e−6) 0.9896 (±1.23e−7) N 0.9870 (±1.75e−7) N• 0.6207 (±2.05e−6) 0.9896 (±1.23e−7) N 0.9870 (±1.75e−7) N•
50/50 0.5738 (±2.27e−7) 0.9874 (±1.38e−7) N 0.9895 (±1.21e−7) N• 0.5904 (±4.44e−7) 0.9916 (±1.38e−7) N 0.9895 (±1.21e−7) NH
40/60 0.6282 (±2.81e−6) 0.9913 (±4.25e−8) N 0.9878 (±5.47e−8) NH 0.5899 (±5.79e−7) 0.9913 (±4.25e−8) N 0.9861 (±5.47e−8) NH
30/70 0.5845 (±3.77e−8) 0.9881 (±2.02e−8) N 0.9865 (±2.94e−8) N• 0.5994 (±3.54e−7) 0.9880 (±2.00e−8) N 0.9865 (±2.94e−8) N•
20/80 0.5779 (±7.75e−9) 0.9883 (±1.09e−8) N 0.9844 (±2.02e−8) NH 0.5818 (±4.65e−9) 0.9883 (±3.41e−8) N 0.9805 (±2.33e−8) NH
10/90 0.5773 (±4.52e−8) 0.9895 (±2.05e−9) N 0.9884 (±1.03e−8) N• 0.5727 (±5.56e−9) 0.9895 (±7.23e−9) N 0.9884 (±1.03e−8) N•
Table 4: Classification accuracy in the second cycle of news of TO and TD.
Train/Test TO TD
RF SVM NN RF SVM NN
90/10 0.9285 (±4, 36e−09) 0.9453 (±4, 64e−09) N 0.9341 (±6, 51e−09) NH 0.9285 (±4, 36e−09) 0.9481 (±6,57e−09) N 0.9327 (±2, 96e−08) NH
80/20 0.9382 (±5, 45e−10) 0.9628 (±5, 48e−09) N 0.9445 (±1, 41e−09) NH 0.9382 (±5, 45e−10) 0.9663 (±7,35e−09) N 0.9438 (±2, 94e−09) NH
70/30 0.9359 (±1, 51e−10) 0.9672 (±1, 65e−09) N 0.9434 (±1, 75e−09) •H 0.9359 (±1, 51e−10) 0.9700 (±3, 19e−09) N 0.9443 (±8, 11e−10) NH
60/40 0.9386 (±6, 79e−13) 0.9715 (±2, 97e−10) N 0.9442 (±7, 93e−10) •H 0.9386 (±6, 79e−13) 0.9750 (±4, 71e−10) N 0.9466 (±4, 07e−10) NH
50/50 0.9441 (±1, 75e−11) 0.9761 (±6, 30e−10) N 0.9464 (±1, 78e−10) •H 0.9441 (±1, 75e−11) 0.9797 (±1, 02e−10) N 0.9483 (±1, 34e−10) •H
40/60 0.9410 (±1, 11e−11) 0.9779 (±2, 81e−10) N 0.9413 (±2, 81e−11) •H 0.9410 (±1, 11e−11) 0.9808 (±1, 79e−10) N 0.9422 (±1, 14e−10) •H
30/70 0.9404 (±5, 53e−12) 0.9803 (±2, 75e−10) N 0.9513 (±3, 73e−10) NH 0.9404 (±6, 41e−12) 0.9813 (±1,05e−10) N 0.9541 (±2, 36e−10) NH
20/80 0.9400 (±4, 85e−12) 0.9815 (±2, 26e−10) N 0.9503 (±1, 35e−10) NH 0.9400 (±4, 85e−12) 0.9852 (±1,76e−10) N 0.9540 (±2, 47e−10) NH
10/90 0.9407 (±3, 34e−14) 0.9828 (±2, 08e−10) N 0.9513 (±7, 49e−11) •H 0.9407 (±3, 34e−14) 0.9859 (±1, 26e−10) N 0.9544 (±5, 42e−11) NH
Table 5: Classification accuracy in the second cycle of news of TF and ALL.
Train/Test TF ALL
RF SVM NN RF SVM NN
90/10 0.9285 (±4, 36e−09) 0.9635 (±4, 89e−09) N 0.9383 (±6, 03e−08) •H 0.9285 (±4, 36e−09) 0.9593 (±4, 61e−09) N 0.9397 (±5, 14e−08) •H
80/20 0.9382 (±5, 45e−10) 0.9768 (±2, 59e−09) N 0.9487 (±5, 45e−09) NH 0.9382 (±5, 45e−10) 0.9810 (±4,54e−09) N 0.9530 (±9, 49e−09) NH
70/30 0.9359 (±1, 51e−10) 0.9831 (±3, 68e−09) N 0.9504 (±3, 40e−10) NH 0.9359 (±1, 51e−10) 0.9840 (±4,89e−09) N 0.9541 (±3, 86e−10) NH
60/40 0.9386 (±6, 79e−13) 0.9866 (±7, 48e−10) N 0.9564 (±1, 19e−09) NH 0.9386 (±6, 79e−13) 0.9876 (±7,80e−10) N 0.9554 (±9, 27e−10) NH
50/50 0.9441 (±1, 75e−11) 0.9878 (±2, 21e−10) N 0.9486 (±8, 69e−10) •H 0.9441 (±1, 75e−11) 0.9889 (±1, 73e−10) N 0.9483 (±4, 97e−10) •H
40/60 0.9410 (±1, 11e−11) 0.9906 (±2, 51e−10) N 0.9422 (±7, 66e−11) •H 0.9410 (±1, 11e−11) 0.9899 (±2, 21e−10) N 0.9443 (±2, 19e−10) •H
30/70 0.9404 (±6, 41e−12) 0.9907 (±1, 76e−10) N 0.9557 (±4, 43e−10) NH 0.9404 (±6, 41e−12) 0.9901 (±9,03e−11) N 0.9593 (±4, 70e−10) NH
20/80 0.9400 (±4, 85e−12) 0.9923 (±2, 12e−10) N 0.9568 (±6, 05e−10) NH 0.9400 (±4, 85e−12) 0.9924 (±1,85e−10) N 0.9572 (±2, 19e−10) NH
10/90 0.9407 (±3, 34e−14) 0.9924 (±4, 35e−11) N 0.9589 (±5, 41e−10) NH 0.9407 (±3, 34e−14) 0.9923 (±5,79e−11) N 0.9620 (±3, 19e−10) NH
Table 6: Accuracy of entities.
Entity Quantity Accuracy
legal agent name 385 0.91
placeName 420 0.99
amount invested 222 0.52
expectedRevenue 2 0.005
operationalDate 16 0.04
newProductionCapacity 23 0.05
directJobsGenerated 102 0.24
indirectJobsGenerated 45 0.11
ness related news from Web. Paticularly, BOR is a
supervised learning approach that exploits semantic
features from Web news, automatically labeling page
content such as title, description and full text. In con-
trast to the supervised approaches in the literature,
BOR not only exploits enterprise ontologies, but also
uses OntoBE to drive the crawling, classification and
extraction process. The proposed approach was eval-
uated using three classification steps, increasing the
amount of news extracted by simulating a growth in
news published on internet portals. The results of this
assessment attest to the effectiveness of our learning
approach for recognizing business opportunities, with
effectiveness reaching up to 90%. In addition, when
analyzing our extraction of entities, was demonstrate
the robustness of the recognition of business oppor-
tunities where they obtained the information defined
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
600

by the BOR ontology. Finally, performance analyses
on our classification methods, showed that they are
particularly suitable for textual classification.
For the future, there is still room for further im-
provements, such as exploit deep neural network al-
gorithms, such as those based in the Transformer ar-
chitecture, for nemad entity extraction. Another plan
is to assess the effectiveness of alternative learning
techniques for textual classification, as well as the use
of additional resources, particularly by adding new la-
beled bases.
ACKNOWLEDGEMENTS
The present work was carried out with the support
of the Coordenac¸
˜
ao de Aperfeic¸oamento de Pessoal
de N
´
ıvel Superior - Brazil (CAPES) - Financing
Code 001. The authors thank the partial support of
the CNPq (Brazilian National Council for Scientific
and Technological Development), FAPEMIG (Foun-
dation for Research and Scientific and Technological
Development of Minas Gerais), CEMIG, FUMEC,
LIAISE and PUC Minas.
REFERENCES
Aggarwal, C. C. and Zhai, C. (2012). A Survey of Text Clas-
sification Algorithms, pages 163–222. Springer US.
An, J., Quercia, D., and Crowcroft, J. (2014). Recommend-
ing investors for crowdfunding projects. In Proceed-
ings of the 23rd International Conference on World
Wide Web, WWW’14, pages 261–270.
Baeza-Yates, R. and Ribeiro-Neto, B. (2011). Modern in-
formation retrieval: the concepts and technology be-
hind search. Pearson Education.
Bai, J., Paradis, F., and yun Nie, J. (2004). Web-supported
matching and classification of business opportunities.
In Proceedings of the 2nd International Workshop on
Web-based Support Systems, WSS’04, pages 28–36.
Brand
˜
ao, W. C., Santos, R. L. T., Ziviani, N., Moura, E. S.,
and Silva, A. S. (2014). Learning to expand queries
using entities. Journal of the Association for Informa-
tion Science and Technology, 9:1870–1883.
Cowie, J. and Lehnert, W. (1996). Information extraction.
Communications of the ACM, pages 80–91.
Cutts, M. (2012). Spotlight keynote. In Proceedings of
Search Engines Strategies, SES’12.
Dr. K. Iyakutti, J. U. (2017). Mining association rules for
web crawling using genetic algorithm. International
Journal of Engineering and Computer Science, pages
2635–2640.
Duarte, J., Cavalcante, R., and Milidi
´
u, R. (2007). Ma-
chine learning algorithms for portuguese named en-
tity recognition. Inteligencia artificial: Revista
Iberoamericana de Inteligencia Artificial, pages 67–
75.
Falci, D., Dutra, F., Brand
˜
ao, W., Ferreira, E., and Parreiras,
F. (2020). Integrating ontologies for business expan-
sion information gathering. In Proceedings of the 13rd
Brazilian Seminar on Ontologies, ONTOBRAS’20.
Gruber, T. R. (1993). A translation approach to portable on-
tology specifications. Knowledge Acquisition, pages
199–220.
Jain, R. (1991). The art of computer systems perfor-
mance analysis - techniques for experimental de-
sign, measurement, simulation, and modeling. Wiley-
Interscience.
Kokossis, A., Ba
˜
nares-Alc
´
antara, R., Jim
´
enez, L., and
Linke, P. (2005). h-Techsight: a knowledge man-
agement platform for technology intensive industries.
In Proceedings of the 38th European Symposium on
Computer-Aided Process Engineering, ESCAPE’05,
pages 1345–1350.
Lai, Y.-A., Zhu, X., Zhang, Y., and Diab, M. (2020). Di-
versity, density, and homogeneity: Quantitative char-
acteristic metrics for text collections. In Proceedings
of the 12th Conference on Language Resources and
Evaluation, LREC’20, pages 1739–1746.
Minaee, S., Kalchbrenner, N., Cambria, E., Nikzad, N.,
Chenaghlu, M., and Gao, J. (2020). Deep learning
based text classification: A comprehensive review.
CoRR, abs/2004.03705.
Mladeni, D., Brank, J., and Grobelnik, M. (2010). Docu-
ment Classification, pages 289–293. Springer US.
Nadeau, D. and Sekine, S. (2007). A survey of named entity
recognition and classification. Lingvisticae Investiga-
tiones, pages 3–26.
Pant, G., Srinivasan, P., and Menczer, F. (2004). Crawling
the Web. In In Web dynamics: Adapting to change
in content, size, topology and use, pages 153–178.
Springer-Verlag New York, Inc.
Paradis, F., Nie, J.-Y., and Tajarobi, A. (2005). Discovery
of business opportunities on the internet with infor-
mation extraction. In Proceedings of the Workshop on
Multi-Agent Information Retrieval and Recommender
Systems, IJCAI’05.
Pirovani, J. and Oliveira, E. (2018). Portuguese named en-
tity recognition using conditional random fields and
local grammars. In Proceedings of the 11th Interna-
tional Conference on Language Resources and Evalu-
ation, LREC’18.
Saggion, H., Funk, A., Maynard, D., and Bontcheva, K.
(2007). Ontology-based information extraction for
business intelligence. In Proceedings of the 6th Inter-
national Semantic Web Conference, ISWC’07, pages
843–856. Springer Berlin Heidelberg.
Tajarobi, A., Garneau, J.-F., and Paradis, F. (2005). MBOI:
Discovery of business opportunities on the inter-
net. In Proceedings of HLT/EMNLP 2005 Interactive
Demonstrations, HLT-Demo’05, pages 30–31.
Yu, H., Guo, J., Yu, Z., Xian, Y., and Yan, X. (2014).
A novel method for extracting entity data from deep
web precisely. In Proceedings of the 26th Chinese
Control and Decision Conference, CCDC’14, pages
5049–5053.
Ontology-based Approach for Business Opportunities Recognition
601
