
Identifying Suspects on Social Networks:
An Approach based on Non-structured and Non-labeled Data
Érick S. Florentino
a
, Ronaldo R. Goldschmidt
b
and Maria C. Cavalcanti
c
Defense Engineering and Computer Engineering Departments, Military Institute of Engineering - IME,
Praça Gen. Tibúrcio 80, Rio de Janeiro, Brazil
Keywords:
Suspects Identification, Social Network Analysis, Controlled Vocabulary.
Abstract:
The identification of suspects of committing virtual crimes (e.g., pedophilia, terrorism, bullying, among oth-
ers) has become one of the tasks of high relevance when it comes to social network analysis. Most of the time,
analysis methods use the supervised machine learning (SML) approach, which requires a previously labeled
set of data, i.e., having identified in the network, the users who are and who are not suspects. From such a
labeled network data, some SML algorithm generates a model capable of identifying new suspects. However,
in practice, when analyzing a social network, one does not know previously who the suspects are (i.e., labeled
data are rare and difficult to obtain in this context). Furthermore, social networks have a very dynamic na-
ture, varying significantly, which demands the model to be frequently updated with recent data. Thus, this
work presents a method for identifying suspects based on messages and a controlled vocabulary composed
of suspicious terms and their categories, according to a given domain. Different from the SML algorithms,
the proposed method does not demand labeled data. Instead, it analyzes the messages exchanged on a given
social network, and scores people according to the occurrence of the vocabulary terms. It is worth to highlight
the endurance aspect of the proposed method since a controlled vocabulary is quite stable and evolves slowly.
Moreover, the method was implemented for Portuguese texts and was applied to the “PAN-2012-BR” data set,
showing some promising results in the pedophilia domain.
1 INTRODUCTION
The analysis of social or complex networks
1
has at-
tracted great socio-economic interest from the pub-
lic and private institutions, since through this analy-
sis it is possible to extract characteristics and behav-
ioral patterns of people on these networks (Dorogovt-
sev and Mendes, 2002; Figueiredo, 2011). For exam-
ple, the identification of people who use the resources
of these networks in order to commit and/or propa-
gate acts that may bring risks inside and outside the
network, such as terrorism, pedophilia, virtual bully-
ing (Pendar, 2007; Villatoro-Tello et al., 2012; Santos
and Guedes, 2019).
a
https://orcid.org/0000-0002-0828-4058
b
https://orcid.org/0000-0003-1688-0586
c
https://orcid.org/0000-0003-4965-9941
1
A social or complex network, in the context of this
work, is a highly interconnected multigraph, where each
vertex represents a network item (e.g., person, web page,
photo, company, group, etc.) and each edge represents some
kind of interaction between the items connected by it (e.g.,
friendship, collaboration, communication, etc.).
Most authors, when working with this topic, use
the supervised machine learning approach, which
consists of using a set of previously labeled data, in-
forming the types of people (suspect and not suspect)
in the network in order to build classification models
(Fire et al., 2012; Villatoro-Tello et al., 2012). How-
ever, for the identification of suspects of committing
virtual crimes, there is a great difficulty in obtaining a
previously labeled set of data (i.e., generally, labeled
data in this context are rare), which requires to carry
out this labeling manually (Pendar, 2007). Further-
more, social networks have a very dynamic nature,
varying significantly, which demands the model to be
frequently updated with recent data. Given such a
hard situation, the following research question may
be posed: How to identify suspicious people, using
messages, on social networks, without depending on
a previously labeled data set? In this direction, the
present work raises the hypothesis that the use of a
controlled vocabulary over the domain of the applica-
tion can lead to the identification of suspects of com-
mitting a virtual crime without the need of a previ-
ously labeled data set.
Florentino, É., Goldschmidt, R. and Cavalcanti, M.
Identifying Suspects on Social Networks: An Approach based on Non-structured and Non-labeled Data.
DOI: 10.5220/0010440300510062
In Proceedings of the 23rd International Conference on Enterprise Information Systems (ICEIS 2021) - Volume 1, pages 51-62
ISBN: 978-989-758-509-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
51

This work presents a method for identifying sus-
pects of committing virtual crimes using messages
from a social network. In the proposed method,
these messages are prepared using text mining tech-
niques in order to reduce computational processing
and facilitate information extraction. Once prepared,
a controlled vocabulary composed of terms related to
the field of application is used. This vocabulary is
weighted according to a domain expert and to the ex-
istence of these terms in the analyzed network. From
the weighted vocabulary, it is also possible to score
each person according to the use of those terms in
their messages. In the end, people are ordered in a de-
scending manner, where the most suspicious of com-
mitting virtual crimes will be at the top of the list.
It is important to highlight the endurance aspect of
the proposed method since a controlled vocabulary is
quite stable and evolves slowly if compared to the dy-
namic nature of the social networks data usually used
by most works on this area.
The present text has five other sections, organized
as follows: In Section 2 some basic concepts related
to the analysis of social networks, text mining, and
knowledge representation are presented. In Section 3,
some of the main related works are presented, high-
lighting the contribution of this work. Then, Section
4 describes the proposed method. Details about the
experiments performed and the results obtained are in
Section 6. Finally, Section 7 reveals the main contri-
butions of this article and points out alternatives for
future work.
2 BASIC CONCEPTS
In social network analysis it is common to repre-
sent the network using a directed multigraph with
attributes. This multigraph may be homogeneous
or heterogeneous
2
(Muniz et al., 2018; Dong et al.,
2012). In a homogeneous directed multigraph G(V ,
E), V is a set of nodes representing individuals or ob-
jects (e.g. people), and E is a set of directed edges
representing a type of relationship between the ver-
tices (e.g. messages). This type of multigraph makes
it possible to represent, for example, messages sent
2
A G graph is said to be: (a) homogeneous if, and only
if, G has only one type of vertex/node and one type of edge;
(b) heterogeneous if, and only if, G has two or more types
of vertex/node or edge; (c) a property graph if, and only
if, G contains attributes associated to its nodes and/or to
its edges; (d) a multigraph if, and only if, G has two or
more types of edge connecting the same pair of nodes; (e) a
directed graph if, and only if, G has directed edges, making
it possible to identify the source and destination nodes of
each edge.
and received by nodes of the type person, u and v,
where u and v ∈ V , e = (u, v), e ∈ E.
In a heterogeneous directed multigraph G(V , E),
the V set is formed by different types of nodes (e.g.
person and book), and the E set, by different types
of edges (e.g. buy and read). More formally, V =
V
1
∪V
2
∪ ... ∪ V
n
and E = E
1
∪ E
2
∪ ... ∪ E
n
. Thus, V
and E are formed by the union, respectively, of differ-
ent types of nodes and directed edges. For example,
consider the heterogeneous directed multigraph G(V ,
E), where V = V
P
∪ V
B
and E = E
PB
∪ E
BP
. In G,
each v
i
∈ V
P
and v
j
∈ V
B
, are nodes of the type Person
and Book, respectively. Additionally, E
PB
and E
BP
,
are sets of edges e
k
= (v
i
, v
j
) that represent the buy-
ing relationships and e
m
= (v
i
, v
j
) that represents the
reading relationships, respectively. Thus, one can ex-
press that a person v
1
bought a book v
3
that was read
by a person v
2
, as follows: v
1
, v
2
∈ V
P
, v
3
∈ V
B
and
∃(v
1
, v
3
) ∈ E
PB
and ∃(v
3
, v
2
) ∈ E
BP
.It is common, in
multigraphs, for vertices (v ∈ V ) and/or edges (e ∈ E)
to be associated with one or more attributes that can
represent different types of information about them
(e.g. temporal, topological and/or contextual). These
attributes could, for example, associate the message
exchanged between a pair of persons represented in
the multigraph.
Frequently, in a social network, it is required to
analyse contextual information, especially messages
and descriptions. In this context, the use of text min-
ing can be an interesting approach, because through it,
one seeks to extract useful information, using compu-
tational techniques (Berry Michael, 2004). Text min-
ing is usually seen as a process composed of several
stages, among which we can highlight, the indexa-
tion and normalization. In the latter, techniques are
employed to reduce and standardize the text. One of
them is stemming, which reduces a word to its rad-
ical, for example, the radical of the words “beauti-
ful” and “beauty” would be “beauti”. Another tech-
nique is the removal of stop words that remove from
the text words with little or no meaning, for exam-
ple, the words “a”, “and”, among others. Another text
mining usual step is to calculate the relevance of the
terms, that may be based on measures such as term
frequency (TF) and the inverse document frequency
(IDF). These measures, respectively, check the fre-
quency and the rarity of a term in a collection of
textual data, making it possible to represent numeri-
cally the relevance of the term (Morais and Ambrósio,
2007).
Another technique that can be applied to social
network analysis is the semantic annotation of texts,
which uses semantic resources such as controlled vo-
cabularies (or thesaurus), ontologies, among others
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
52

(Moura, 2009). Controlled vocabularies are a set of
descriptor terms that are semantically related to a
given domain. These terms can be organized in the
form of hierarchies, that is, with hierarchical relation-
ships between them (Sales and Café, 2009). On the
other hand, an ontology is a more sophisticated se-
mantic resource, because in addition to representing
terms from a given field of knowledge, it maintains
several types of relationships between them, includ-
ing hierarchical relationships (Chandrasekaran et al.,
1999).
3 RELATED WORK
In the literature, some works focus on the identifica-
tion of criminal suspects on social networks. Similar
to the present work, some of them adopt a contextual
analysis approach, i.e., they perform a content anal-
ysis of the exchanged messages to identify criminal
practices or suspects.
Pendar (2007) sought to identify sexual preda-
tors using people’s messages in a social network. In
this work, the authors count on a set of data previ-
ously labeled, informing predators and non-predators.
They perform different linguistic analysis of the mes-
sages exchanged by these people on the social net-
work, such as Bag-of-words and TF-IDF statistical
measurements. According to the authors, this infor-
mation is provided to a machine learning algorithm
to generate a model that characterizes sexual preda-
tor messages, which will enable the identification of
sexual predators in an unlabeled network.
Villatoro-Tello et al. (2012) and Santos and
Guedes (2019) followed the same line of the method
developed by Pendar (2007). The work of Villatoro-
Tello et al. (2012) differs in that it attacks both prob-
lems at once, i.e., their method is able to identify sus-
picious conversation and also is able to tell which user
is the sexual predator. Santos and Guedes (2019)’s
work is very similar to Pendar (2007). Its main con-
tribution is that, to the best of our knowledge, it was
one of the first works that developed a method to iden-
tify messages with a pedophile content in Portuguese.
Differently, Fire et al. (2012) and Wang (2010)
have developed methods to identify spammers on so-
cial networks that take into account topological infor-
mation. The method proposed in Fire et al. (2012)
assumes that a highly connected user with friends
that belong to several non connected communities has
a great possibility to be a spammer. Yet in Wang
(2010), besides the topological information (e.g., the
relevance of a user according to the number of mes-
sages sent and received), it also takes into account the
content of the messages (e.g., the existence of HTML
links, mentions to other people, and reference to trend
topics). Similarly to Pendar (2007), both methods use
a supervised approach, i.e., they need to use previ-
ously labeled data sets, informing spammers and non-
spammers.
Another interesting work was developed by
Elzinga et al. (2012). They present a non-automated
method, using a time relational semantic system, aim-
ing to analyze messages with a pedophile content in
chat rooms for a certain time. The authors identified
seven categories of terms used by pedophiles: sweet
greetings, compliments, intimate parts, sexual manip-
ulations, cam and photos, where and when. These cat-
egories characterize how pedophiles establish a con-
nection and escalate the conversation on the net, to-
wards a physical meeting. In the proposed analysis,
each message is manually framed in one of those cat-
egories, and then they analyze the dynamics of the
conversation. However, they did not report on the im-
plementation of their method to automate the iden-
tification of the conversation dynamics pattern on a
social network.
Bretschneider et al. (2014) developed a method
to identify harassment messages on social networks.
Based on a set of profane words, they select mes-
sages that mention them for further checking. If a
message contains a profane word directly address-
ing some people, then they are labeled as harassment
messages. In the naive version of the method, the au-
thors labeled messages that mention profane words as
harassment messages. Yet in Bretschneider and Peters
(2016), a new version of the method was developed to
identify Cyberbullying practice. In this version, those
who have sent at least two harassment messages to the
same person, are labeled as a Cyberbullying offender.
Also, they calculate the degree of the offensive based
on the use of a property directed multigraph, where
nodes represent people, and a directed edge repre-
sents people’s interaction. In this multigraph, edge
attributes represent the interaction harassment degree
(the number of received and sent harassment mes-
sages). Additionally, node attributes represent one’s
offensive degree (the number of offended people and
the number of harassment messages sent).
Apart from Elzinga et al. (2012), Bretschneider
et al. (2014) and Bretschneider and Peters (2016), all
other mentioned works need a set of previously la-
beled data. This network labeling can be very costly
and, depending on the network used, sometimes even
impossible, as it is mostly a manual task.
More specifically, in Pendar (2007) and Villatoro-
Tello et al. (2012), depending on the size of the an-
alyzed dataset, a linguistic analysis of the messages
Identifying Suspects on Social Networks: An Approach based on Non-structured and Non-labeled Data
53
can have a high computational demand. Yet in Santos
and Guedes (2019), the authors used a single analy-
sis of the messages, reducing the computational ef-
fort. In Fire et al. (2012) and Wang (2010) the au-
thors follow a topological approach. However, only
in Wang (2010), the authors combine topological and
contextual approaches, restricted to the Twitter social
network. On the other hand, following a vocabulary-
based approach, in Elzinga et al. (2012) the authors
explore the dynamics of the content of the message,
but they did not report on doing so for identifying
criminal suspects in a large set of network messages.
Yet in Bretschneider et al. (2014) and Bretschnei-
der and Peters (2016), the authors propose an au-
tomated method for identifying cyberbullying crim-
inals. However, its content analysis focuses only on
this type of crime.
4 PROPOSED METHOD
In order to fill in some of the gaps left by the related
work described above, this section presents INSPEC-
TION, a new method for identifying suspects from
the content of messages exchanged on a social net-
work. Its main differential is that it does not require
a labeled base. The idea is to use a categorized and
weighted vocabulary. Similar to other related work,
the method analyzes the content of messages, identi-
fying suspicious messages based on that vocabulary.
Then, according to the results of the analysis of the
exchanged messages of each person on the network,
it ranks them. The higher the position at the rank,
the more suspect, which facilitates the identification
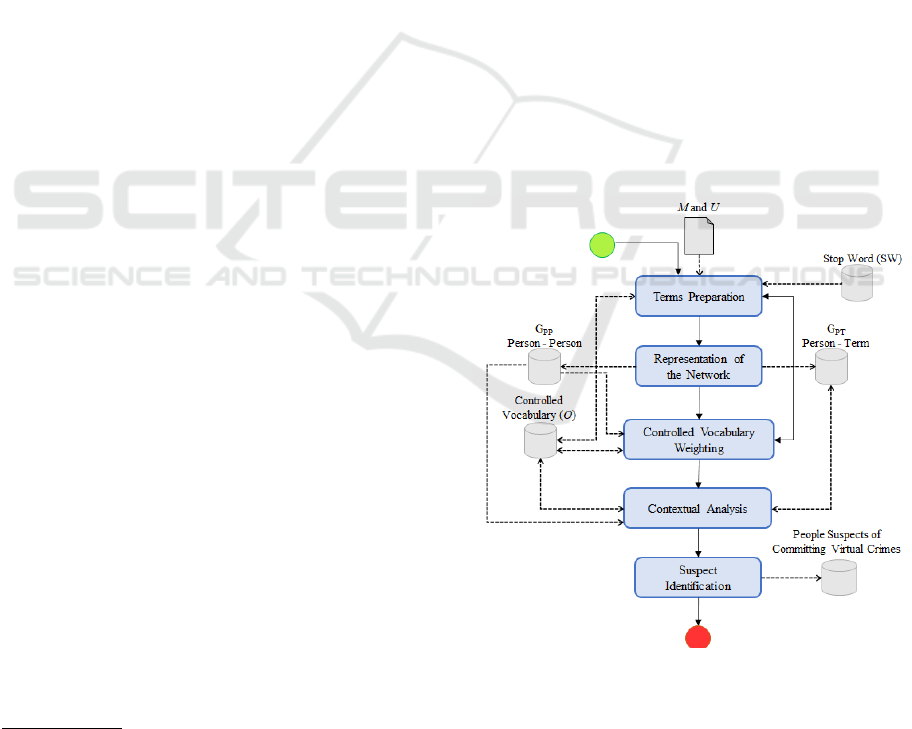
of criminal suspects. Figure 1 gives an overview of
the proposed method, which is described as follows.
Let a cutout of a network N composed of a set of
messages M sent and/or received by people from a
set U. Each message m
x
, is an ordered set of terms
3
(m
x
= t
1
,t
2
, ...,t
n
). This method seeks to identify in
U, people with suspicious behavior, through the terms
used in the M messages (t
j
∈ m
x
).
Initially, as Figure 1 shows, in the Terms Prepara-
tion step, all the terms t
j
of every m
x
are treated. This
treatment allows the standardization of these terms,
creating a set of messages with treated terms, called
M
0
. Based on this set (M
0
) and on the set of people
(U), the Representation of the Network step generates
two multigraphs, one to represent the interaction be-
3
Formally, each message is represented as a tuple <
o, d, m
x
>, where a source person (o), sends to a destina-
tion person (d) some message content (m
x
). However, at
some points of this article, a message is represented as m
x
,
for the sake of simplification.
tween people, and another that connects people and
terms they used in their messages.
The Controlled Vocabulary Weighting step counts
on a controlled vocabulary composed of suspicious
terms, previously defined by an expert, according to
a field of application (e.g. Pedophilia, Terrorism,
among others). It is assumed that the vocabulary used
is divided into large categories, covering the different
aspects of the domain in question. Before weighing
the vocabulary, the specialist’s view is initially taken
to weigh the categories, according to their impor-
tance. Each term of the vocabulary is then weighed
according to its occurrence in the existing messages
(M
0
).
Later, at the Contextual Analysis step, each person
is analyzed according to the presence of suspicious
terms used in their sent messages. At the end, each
person is assigned a score, which represents numer-
ically the suspicious behavior of a person. Once the
scores of all users have been calculated at the Sus-
picious Person Identification step, those persons are
ranked. Thus the most suspicious of committing vir-
tual crimes, according to the domain of the applica-
tion, will be at the top of the list.
The following subsections detail each of the steps
of the proposed method.
Figure 1: INSPECTION - Overview.
4.1 Terms Preparation
For every m
x
∈ M, this step treats each term t
j
∈ m
x
,
in order to obtain only the normalized terms that are
more relevant to be analyzed. To do so, this step has
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
54

the following sub-steps:
• Normalization and Extraction of Textual Content:
Due to the high textual informality existing in
messages on social networks, for each t
j
∈ m
x
,
it is necessary to remove the use of repeated let-
ters. Besides, to standardize these terms, all of
them are placed in lower case and have removed
their accents, signs, and punctuation.
• Stop Words Removal: This sub-step seeks to re-
move the stop words from m, i.e., remove the t
j
with little or no meaning. This removal aims to
reduce the computational effort of the next steps,
since removing these terms consequently also re-
duces the number of terms that will be analyzed
by the method. As shown in Figure 1, this step
counts on the SW set, which is the set of terms
with little or no meaning. At the end of this step,
we have:
m
x
= m
x
− SW (1)
• Stemming: This sub-step extracts the radical from
each t
j
∈ m
x
, and generates a new stemmed term
(t
0
j
):
t
0
j
= stem(t
j
) (2)
In case a given t
j
cannot be stemmed, then t
0
j
=
t
j
. Formally, ∀m
x
∈ M ∀t
j
∈ m
x
then t
0
j
= stem(t
j
)
and m
0
x
= m
0
x
∪ {t
0
j
} and M
0
= M
0
∪ {m
0
x
}. Thus,
the new m
0
x
set is built by means of the stemming
of the terms t
j
∈ m
x
, and M
0
is built on each m
0
x
.
4.2 Representation of the Network
Through M
0
and U, this step builds two multi-graphs
directed. These multigraphs, besides making it pos-
sible to identify the people who send and receive one
or more messages or terms, also make it possible to
carry out the analyses that will be made in the next
steps.
• Representing People and Messages (G
PP
). In
this representation, G
PP
(V
P
, E
PP
) is a homo-
geneous directed multigraph representing people
and messages from the network. Thus, each v
P
∈
V
P
represents a person of U. As for the e
PP
∈
E
PP
, besides representing a directed connection
between two people that exchanged a message, it
has a contextual attribute (e
PP
.T ) that represents
the message text. G
PP
(V
P
, E
PP
) is constructed as
follows:
– V
P
= U , where each v
P
∈ V
P
represents a per-
son who sent and/or received one or more mes-
sages;
– E
PP
= {e
PP
| e, r ∈ V
P
, e
PP
= (o, d) and
∃< o, d, m
0
x
> ∈ M
0
, e
PP
.T = m
0
x
}, where each
e
PP
∈ E
PP
is a connection that represents a mes-
sage sent from one person to another.
• Representing People and Terms (G
PT
). In this
representation, the heterogeneous directed multi-
graph G
PT
(V
P
∪V
T
, E
PT
∪ E
T P
) is responsible for
representing both the people, and the terms (t
0
j
)
used in m
0
∈ M
0
by those people. So there are two
kinds of vertices. Vertices v
P
∈ V
P
represent the
users in U, and vertices v
T
∈ V
T
represent terms
used in messages exchanged between those users.
Every e
PT
∈ E
PT
and e
T P
∈ E
T P
are directed edges
that represent, respectively, the person who sent
and received a certain term. Thus, G
PT
(V
P
∪V
T
,
E
PT
∪ E
T P
) is constructed as follows:
– V
T
= {v
T
| ∃m
0
x
∈ M
0
}, where v
T
= t
0
j
and t
0
j
∈
m
0
x
;
– E
PT
= {e = (o,t) | o ∈ V
P
and t ∈ V
T
and ∃e
0
∈
E
PP
}, where e
0
= (o, d) and t ∈ e
0
.T ;
– E
T P
= {e = (t, d) | d ∈ V
P
and t ∈ V
T
and ∃e
0
∈
E
PP
}, where e
0
= (o, d) and t ∈ e
0
.T .
4.3 Controlled Vocabulary Weighting
As already mentioned, the present method is based on
a controlled vocabulary composed of terms related to
the domain of the application, or more specifically,
to the type of crime under investigation.Vocabulary
terms are weighted with the help of a specialist and
based on the set of messages exchanged in a social
network. Thus, it becomes possible to express nu-
merically how suspicious a term is in the context of a
cutout from a social network.
A controlled vocabulary, in the present work, is
defined as a tuple O = [C, R], where C is a set of
classes and R is a set that represents the generaliza-
tion/specialization relationships between them. This
means that the vocabulary is constituted of a set of
taxonomies, one for each category/facet that must be
taken into consideration for the crime type in focus.
To better explain the Controlled Vocabulary Weight-
ing step, C is subdivided into C
r
and C
s
(C = C
r
∪
C
s
), so that C
r
and C
s
are, respectively, a set of root
classes, one for each taxonomy, and a set of their
subclasses. In addition, each c
s
i
∈ C
s
is linked di-
rectly or indirectly to (descendant of) a single c
r
j
in
C
r
. Each c
r
j
generically represents the terms that cor-
respond to its subclasses. And, each c
s
i
is previously
known as a suspicious term. Each c
r
and c
s
has a w
attribute (c
r
j
.w and c
s
i
.w) that indicates the relevance
of the term in the vocabulary according to the network
cutout, i.e., how suspicious the term is in that context.
Identifying Suspects on Social Networks: An Approach based on Non-structured and Non-labeled Data
55

The first sub-step of the controlled vocabulary
weighting step begins by arbitrarily assigning the val-
ues of the weights to all c
r
.w, where c
r
∈ C
r
, accord-
ing to an specialist in the crime type under investiga-
tion.
Subsequently, the subclasses of the controlled vo-
cabulary are weighted according to their frequency
in the available messages. To do this, initially, ev-
ery c
s
i
∈ C
s
goes through the Terms Preparation step
(and all its sub-steps). Formally, ∀c
s
i
∈ C
s
then c
0
s
i
=
stem(c
s
i
) and C
0
s
=C
0
s
∪{c
0
s
i
}. This way, it emerges the
O
0
vocabulary, where O
0
= [C
0
, R] and C
0
= C
r
∪C
0
s
.
Knowing that the subclasses c
0
s
∈ C
0
s
represent suspi-
cious terms that could be used in messages on the net-
work, the operation described in (3) aims to identify
the set (A) of suspicious terms that are present in the
cutout of the analyzed social network. In other words,
this set will be built with elements c
0
s
i
∈ C
0
s
if exists
t
0
j
∈ V
T
, such that c
0
s
i
= t
0
j
.
A = C
0
s
∩V
T
(3)
Then, by means of Equation 4, the Global Weight
(Wilbur and Yang, 1996) of each t
0
j
∈ A, (GW
t
j
) is
calculated. It is also known as Inverse Document Fre-
quency (or IDF) (Robertson, 2004). This equation
checks the inverse frequency of the term t
0
j
, or the
rarity of the term, in the set of messages of the net-
work cutout. Therefore, the less the term appears in
the message set, the greater is its importance.
GW
t
0
j
= log
2
|E
PP
|
|n
t
0
j
|
!
(4)
Where:
• |E
PP
| is the total number of edges in G
PP
;
• |n
t
0
j
| is the number of edges in E
PP
that have
the term t
0
j
in the messages they represent (n
t
0
j
=
{e
pp
i
|t
0
j
∈ e
pp
i
.T }).
However, the Global Weight (GW
t
0
j
) is not sufficient
to calculate the relevance of each term in the context
of the different categories (root classes) of the vocab-
ulary. Therefore, to adjust the relevance of each t
0
j
∈ A according to its root class (c
r
k
), a normalization
operation is required. The goal is to limit GW
t
0
j
to
the weight w of its corresponding c
r
k
. To do this, ini-
tially, it is necessary to find the Highest Global Weight
(HGW), which is given by Equation 5. It calculates
the maximum rarity of any term in relation to the mes-
sages of the network cutout.
HGW = log
2
(|E
PP
|) (5)
Then, Equation 6 may be used to calculate the ratio
of the Global Weight of each t
0
j
with respect to the
Highest Global Weight HGW. In this equation, a rule
of three is applied, i.e., assuming HGW corresponds
to 100%, thus it is possible to obtain each equivalent
ratio GW
t
0
j
.
GW
%
t
0
j
=
GW
t
0
j
HGW
(6)
Now, based on these ratios, each term weight may
be normalized according to the weight of their cor-
responding root class, assigned by the specialist. To
do this, for each root class (c
r
k
) it is necessary to
define the corresponding weight interval (Min() and
Max()). Thus, Max(c
r
k
) = c
r
k
.w and Min(c
r
k
) = Max(
{c
r
f
.w|c
r
f
∈ C
r
− {c
r
k
} ∧ c
r
f
.w < c
r
k
.w} ∪ {0}). Fi-
nally, the normalized global weight of each t
0
j
is given
by Equation 7:
GW
N
t
0
j
= ((Max(c
r
k
) − Min(c
r
k
)) × GW
%
t
0
j
) + Min(c
r
k
)
(7)
It is worth noting that this equation normalizes each
term global weight (GW
N
t
0
j
), placing it within a range
limited by two root class weights. The top bound-
ary of such range corresponds to the weight of the
root class to which the t
0
j
is connected (Max(c
r
k
)), and
the bottom boundary corresponds to the weight of the
smaller subsequent root class (Min(c
r
k
)), if it exists.
If it does not exist, 0 is assumed. Thus, GW
N
t
0
j
is found
from GW
%
t
0
j
within the mentioned range.
For each c
0
s
i
= t
0
j
, the operation described in (8) as-
signs the normalized global weight of a term (GW
N
t
0
j
)
to the corresponding term (or subclass) in the con-
trolled vocabulary representation.
c
0
s
i
.w = GW
N
t
0
j
(8)
4.4 Contextual Analysis
At this step, contextual analysis is carried out based
on the term weights of each person’s messages.
Briefly, the idea is to obtain a score that expresses how
suspicious each person’s behavior is. The following
sub-steps describe how this score is calculated. At the
end of this step, this score is stored for each person of
the network (v
P
.st | v
P
∈ V
P
of G
PT
).
Initially, all terms used by a person are retrieved.
For each v
P
∈ V
P
of G
PT
it is necessary to retrieve
all v
T
to which it is connected. More formally, for a
given v
P
, this step retrieves the following set:
C
v
T
(v
P
) = {v
T
|∃(v
P
, v
T
) ∈ E
PT
} (9)
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
56
Since not all terms v
T
∈ C
v
T
(v
P
) are suspect terms, the
next operation reduces this set to a new correspond-
ing set, containing only terms that are present in the
controlled vocabulary. That way, using the set of sub-
classes (C
0
s
) of the vocabulary O
0
, and knowing that
v
T
0
j
= c
0
s
i
, a reduced set is created for each v
P
∈ V
P
of
G
PT
:
C
∩
v
T
(v
P
) = C
v
T
(v
P
) ∩C
0
s
(10)
Next sub-step calculates two metrics that were de-
veloped to quantify each person’s suspicious behav-
ior: M
GW
and M
FGW
. These metrics generally quan-
tify the use of all suspicious terms by a person (v
T
∈
C
∩
v
T
(v
P
)). As shown in Equation 11, M
GW
metric is
the sum of the rarity of each suspect term used by a
person in messages, normalized by the weight of a
root class, to which this term is connected.
M
GW
(v
P
) =
∑
c
s
i
∈C
∩
v
T
(v
P
)
c
s
i
.w (11)
Note that Equation 11 does not take into account term
frequency, i.e., how frequently a person used each
suspect term. Differently, as shown in Equation 12,
M
FGW
metric multiplies each term normalized global
weight by term frequency, indicating the importance
of this term for a person in relation to all the messages
analyzed.
M
FGW
(v
P
) =
∑
c
s
i
∈C
∩
v
T
(v
P
)
W (v
P
, c
s
i
) × c
s
i
.w (12)
where:
• v
T
j
= c
s
i
• W (v
P
, v
T
j
) retrieves the frequency of use of a par-
ticular suspect term by a person, formally:
W (v
P
, v
T
j
) = |{(o,t) ∈ E
PT
∧ o = v
P
∧t = v
T
j
}|
Finally, the user may select one of the proposed met-
rics (Equations 11 or 12), and then the corresponding
score is assigned to each person, representing his/her
suspicious behavior, as follows:
v
P
.st = M
GW
(v
P
) (13)
v
P
.st = M
FGW
(v
P
)) (14)
It is worth noting that operations 13 and 14 assign
the weights, respectively obtained by the Equations
11 and 12, to the analyzed person representation (v
P
).
4.5 Suspect Identification
At this step, an ordered list of people is generated ac-
cording to the selected score metric. In a descending
order of scores, people at the top of the list are the
most suspicious ones.
5 EXAMPLE
This section aims to illustrate the usage of the method
presented in Section 4. Let the sets of users and
messages be, respectively, U = {Carlos, Paula, Ana}
and M = { <Carlos, Paula, How about a beach to-
morrow my beautiful?>, <Paula, Ana, Beachhh?>,
<Ana, Paula, Not tomorrow!>, <Paula, Ana, Want
to?>, <Carlos, Paula, Let’s go tomorrow?>}. These
sets were processed by the proposed method, and each
step is described as follows.
Terms Preparation. In this step some sub-steps
such as Normalization and Extraction of Textual Con-
tent, Stop Words Removal and Stemming, are exe-
cuted, and M is converted into M
0
= { <Carlos, Paula,
{beach, tomorrow, beauti}>, <Paula, Ana, {beach}>,
<Ana, Paula, {tomorrow}>, <Paula, Ana, {want},
<Carlos, Paula, {tomorrow}> }.
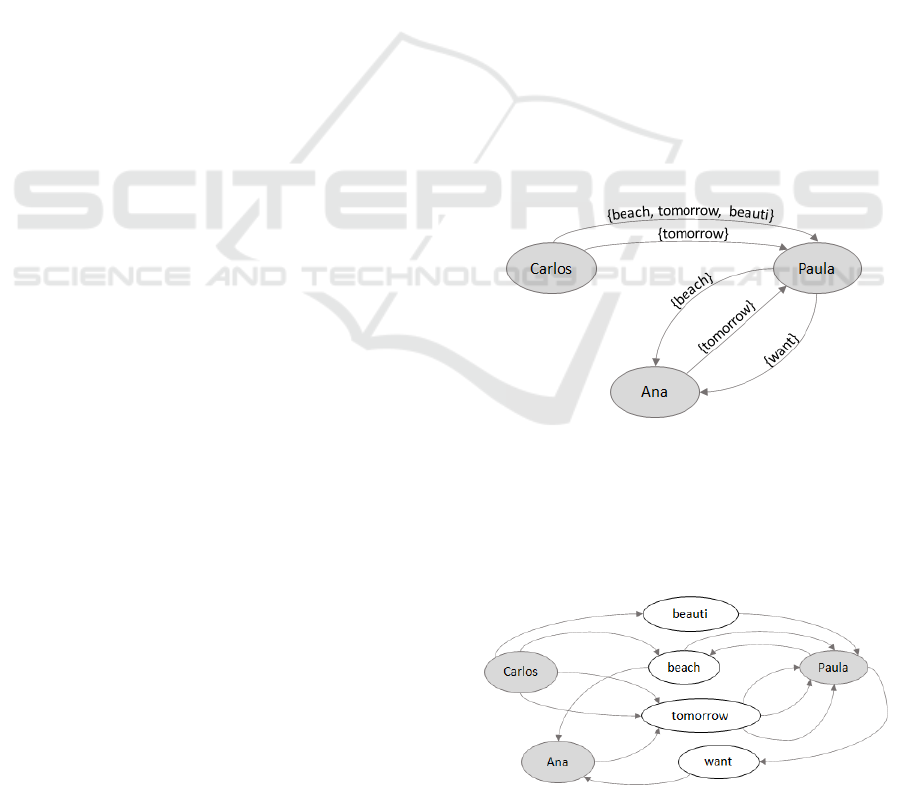
Representation of the Network. From M
0
and U
two multigraphs are built: G
PP
and G
PT
. In G
PP
(V
PP
,
E
PP
), V
PP
= {Carlos, Paula, Ana} and E
PP
= {(Car-
los, Paula), (Paula, Ana), (Ana, Paula), (Paula, Ana),
(Carlos, Paula)}, where, for instance, e
PP
1
= (Carlos,
Paula), e
PP
1
.T = {beach, tomorrow, beauti}. Figure
2 shows the graphical representation of G
PP
for the
complete example.
Figure 2: Graphic representation of the multigraph Person-
Person (G
PP
) built from the example.
In G
PT
(V
P
∪V
T
, E
PT
∪ E
T P
) graph, shown in Fig. 3,
V
T
is the set of white nodes, while V
P
is the set of
gray nodes. The edges of the graph correspond to the
connections between the nodes from both sets, V
p
and
Figure 3: Graphic representation of the Multigraph Person-
Term (G
PT
) built from the example.
Identifying Suspects on Social Networks: An Approach based on Non-structured and Non-labeled Data
57
V
T
. For instance, the edge (Carlos, beauti) ∈ E
PT
,
while (beauti, Paula) ∈ E
T P
.
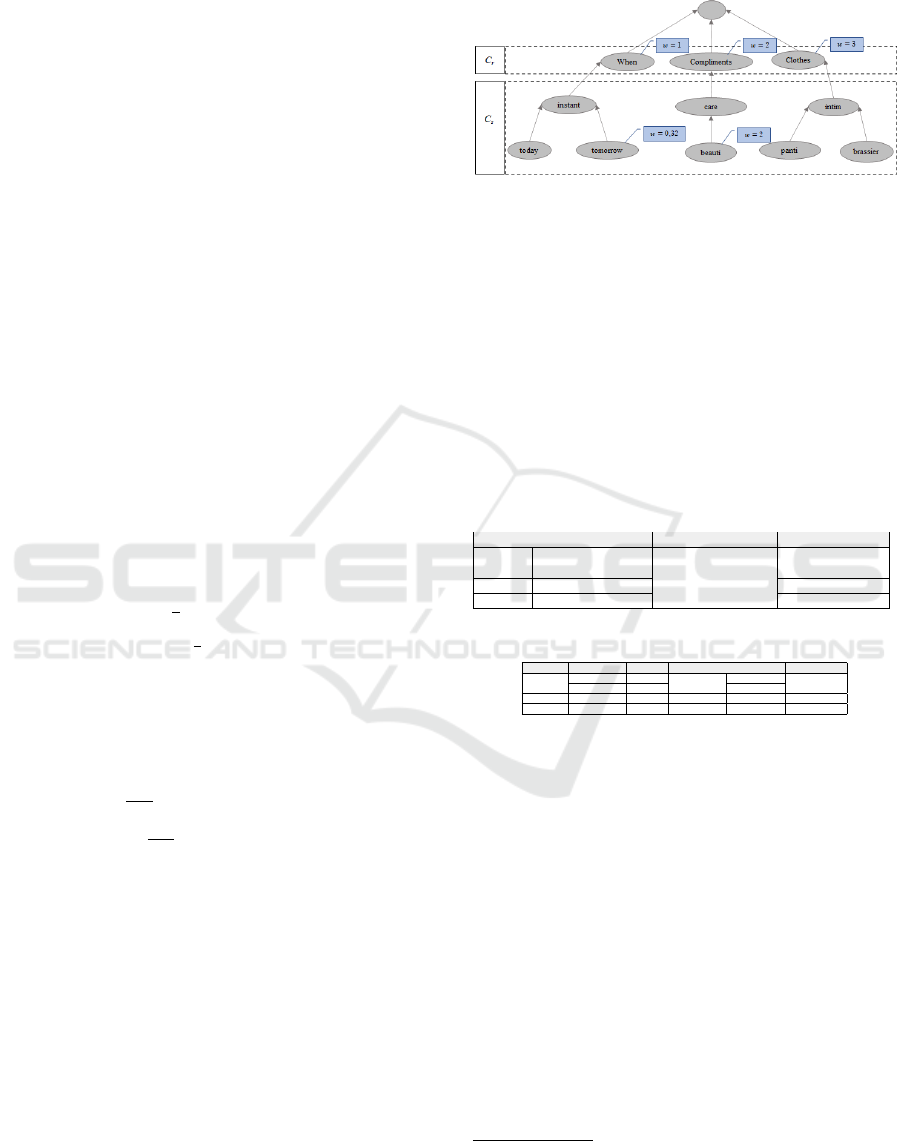
Controlled Vocabulary Weighting. First, it is as-
sumed that there is a controlled vocabulary formed
by a set of terms C
s
, commonly used in Pedophiles
conversation. This vocabulary is organized according
to some generic categories (C
r
classes). For this ex-
ample C
r
= {When, Compliments, Clothes}. Fig. 4
shows the terms used in this example, and their orga-
nization as subclasses of the categories in C
r
. Each
of these categories is weighted by a specialist, with
values 1, 2 and 3, respectively.
The vocabulary terms (C
s
) are weighted according
to their usage in the messages under analysis (V
T
).
Therefore, to avoid the cost of weighting all the terms,
first it is necessary to identify which of them need to
be weighted. Then, in order to normalize them in the
same way of the message terms, each term in the C
s
set is submitted to some of the sub-steps of the Terms
Preparation step.
The set of selected vocabulary terms (A) is ob-
tained by applying Operation 3. Since C
s
= {instant,
today, tomorrow, care, beauti, intim, panti, brassier}
and V
T
= {beach, tomorrow, beauti, want}, thus A
= {tomorrow, beauti}.Then, based on the G
PP
multi-
graph of Figure 2, the global weight (GW) of each
term t
0
j
∈ A is calculated by applying Equation 4 as
follows:
• GW
beauti
= log
2
5
1
= 2, 32
• GW
tomorrow
= log
2
5
3
= 0, 74.
Subsequently, to normalize these weights according
to the Highest Global Weight, first it is calculated by
applying Equation 5: HGW = log
2
(5) = 2, 32. Then,
using this value, Equation 6 is applied to obtain the
weight rates for each term:
• GW
%
beauti
=
2,32
2,32
= 1, 00
• GW
%
tomorrow
=
0,74
2,32
= 0, 32.
Next, these rates are used to recalculate each term
weight and normalize them according to the weights
of their corresponding categories. Considering the
fact that beauti and tomorrow are related to Compli-
ments (w = 2) and When (w = 1) categories, respec-
tively, then only these two categories are used as ref-
erences. Therefore, the reference values for each cat-
egory are calculated as follows:
• Min(Compliments) = Max({1, 0} ∪ {0}) = 1,0
• Min(When) = Max({} ∪ {0}) = 0.
Finally, Equation 8 is used to obtain the final Global
Weight for each term, within the interval of its corre-
sponding category:
• GW
N
beauti
= ((2, 0 − 1, 0) × 1, 0) + 1, 0 = 2,0
• GW
N
tomorrow
= ((1, 0 − 0) × 0, 32) + 0 = 0,32.
Figure 4: Controlled vocabulary: weighted and normalized.
Contextual Analysis. Now that the weights were cal-
culated for the selected vocabulary terms, it is possi-
ble to calculate the score of each member of the V
P
set. Table 1 summarizes the results of applying Op-
erations 9 and 10. Note that Carlos is the one that
mentions more terms that belong to the vocabulary.
Subsequently, based on the weights of the terms they
mention, a score is calculated for each person. Table
2 shows the scores for both metrics, M
FGW
(v
P
) and
M
GW
(v
P
) (Eq. 12 and 11), for all users in V
P
. These
scores indicate how suspicious a person is.
Table 1: Contextual analysis of the example.
v
p
C
v
T
(v
P
) (Eq. 9) C
0
s C
∩
v
T
(v
P
) (Eq. 10)
Carlos {beach, tomorrow, {tomorrow,
beauti} beauti}
Paula {beach, want} {}
Ana {tomorrow}
{tomorrow, beauti}
{tomorrow}
Table 2: Scores according to M
GW
and M
FGW
metrics.
v
p
C
∩
v
T
(v
P
) c
s
i
.w M
GW
(v
P
) W (v
P
, c
s
i
) M
FGW
(v
P
)
tomorrow 0,32 2
Carlos
beauti 2
2,32
1
2,64
Paula - 0 0 0 0
Ana tomorrow 0,32 0,32 1 0,32
textbfSuspect Identification. In both metrics it
was verified that Carlos got the highest scores
(M
GW
(Carlos) = 2,32 and M
FGW
(Carlos) = 2,64).
This indicates that he is the most suspicious among
the people of the U set. On the other hand, Paula did
not use any term considered suspicious in her vocab-
ulary. Thus, in both metrics her score was 0.
6 EXPERIMENTS AND RESULTS
In order to evaluate the proposed method, a proto-
type was implemented in Python v. 2.7, using sev-
eral APIs
4
. The experiments ran on this prototype.
They focused on the identification of pedophilia sus-
pects, and were carried out using the “PAN-2012-
4
APIs used: NLTK for portuguese text manipulation,
NetworkX to deal with graph structures, and AnyTree to deal
with the controlled vocabulary structure.
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
58
BR” data set (Santos and Guedes, 2019; Andrijauskas
et al., 2017). This data set was developed in partner-
ship with the Federal Prosecutor’s Office of São Paulo
(MPF-SP), the University Center of the Fundação Ed-
ucacional Inaciana (FEI), and the Federal University
of Minas Gerais (UFMG). The “PAN-2012-BR” data
set is composed of conversations in Portuguese, i.e.,
people and the messages exchanged between them.
These conversations and people are labeled as preda-
tors or non-predators. It is worth noticing that the no-
tion of predator is different from the notion of sus-
pect. However, due to the difficulty of obtaining a
data set composed of common and suspicious people
for the evaluation of the proposed method, we decided
to proceed with the experiment using the predator la-
bel, instead of suspect label.
Table 3: “PAN-2012-BR” social network statistical infor-
mation (Santos and Guedes, 2019; Andrijauskas et al.,
2017).
Label People Messages People Messages
Non Predators 330 21.909 368 22.255
Predators 77 436 39 90
TOTAL 407 22.345 407 22.345
Table 3 presents statistical information about the
“PAN-2012-BR” social network, organized by label,
users and messages. It should be noted that the
predator/non-predator labels will only be used at the
end of the experiment, to verify the method perfor-
mance. Thus, only information about people (sender
and receiver) and their exchanged messages will be
used as input for this experiment.
While planning for the experiment, it was noticed
that the number of messages exchanged by each user
in the “PAN-2012-BR” network cutout varied consid-
erably. Taking into account that the proposed method
scores people according to their messages, active peo-
ple (who sends a high number of messages) could be
heavily scored in contrast to less active ones. To avoid
this problem, the number of exchanged messages to
be analyzed per person was limited to a threshold.
Thus, to investigate the impact of this message lim-
itation, two experiment configurations were defined.
The first one executes the method on all messages of
the dataset, i.e., with no limitation (E1). The second
one (E2) analyzes a limited number of messages per
person. In this work, the median (M
d
) was used as
the maximum number of messages per person for the
whole network cutout.
A controlled vocabulary for Pedophilia crimes,
named O
1
, was created and organized according to
6 (six) root classes (or categories) of terms, based
on the categories proposed by Elzinga et al. (2012):
“where”, “when”, “intimate parts”, “sexual manipu-
lations”, “cam and photos” and “compliments”. The
sweet greetings category was discarded due to its sim-
ilarity to the compliments category. It is worth to point
out that the subclasses for each root class or category,
were built from real ontology cutouts. Table 5 shows
each c
r
∈ C
r
of the O
1
controlled vocabulary, and their
respective sources, i.e., the semantic resources from
which the set of corresponding subclasses (c
s
) were
extracted.
To execute the experiment according to the E
2
configuration, the M
d
was calculated and only the
first 13 (thirteen) messages in M from each person
in U were selected. The experiments for both con-
figurations begun with the Terms Preparation step,
when the PAN-2012-BR dataset selected messages
went through the normalization, Stemming and Stop
Word Removal sub-steps. Then, the Representation
of the network step was executed. Table 4 shows the
data for both multigraphs (homogeneous or heteroge-
neous) that were created to represent the “PAN-2012-
BR” data. Note that different multigraphs were cre-
ated for each experiment configuration, i.e., with (E
2
)
or without (E
1
) message number limitation.
Table 4: Multigraph data for the “PAN-2012-BR” dataset.
Nodes
# of Messages Multigraph
People Terms
Edges
G
PP
- 22.345
All msgs
G
PT
7.680 119.939
G
PP
- 4.014
First 13 msgs(M
d
)
G
PT
407
2.915 18.666
At the beginning of the Controlled Vocabulary
Weighting step, the root classes (c
r
∈ C
r
) were
weighted according to the experience of a Brazilian
Federal Policeman, who is a specialist on Pedophilia
crimes. After a brief presentation of the method, the
specialist assigned values according to the importance
of each category, within a scale of 1 (one - less impor-
tant) to 6 (six - most important), as shown in Table 5.
In addition, it was recommended to assign a distinct
value to each category. The reason for this is to en-
hance the distinction between the term weights within
the range of values of each category.
Table 5: Source of the subclasses (terms) linked to each root
class of the controlled vocabulary O
1
.
C
R
w Source
Where 2.3 (Scheider and Kiefer, 2018)
When 1.5 (Hobbs and Pan, 2006)
Intimate Parts 5.7 (Rosse and Mejino, 2008)
Sexual Manipulations 5.5 (Kronk et al., 2019)
Cam and Photos 6.0 (Mukherjee and Joshi, 2013)
Compliments 4.0 (Neves, nd)
According to the pedophilia specialist, the cate-
gories used reflect the usual interaction of a typical
pedophile. First of all, the criminal usually demands
Identifying Suspects on Social Networks: An Approach based on Non-structured and Non-labeled Data
59

photos, films, etc, which is why the highest impor-
tance was given to this category (Cam and photos).
Intimate parts and Sexual Manipulations are also cat-
egories of obvious importance. Compliments are of-
ten used to gain the victim’s trust. Regarding W hen
and W here categories, these were not so important,
not only because they are very commonly used in any
conversation, but especially because the main goal of
a pedophile is not to schedule meetings, but to obtain
images, photos and films.
Once the root classes were weighted, the experi-
ments proceeded to the weighting of the O
1
remain-
ing subclasses. Each subclass was weighted based on
their corresponding root class weight, and on the het-
erogeneous multigraph extracted from the messages
in the PAN-2012-BR data set, as explained in Section
4.3, operations/equations (3) to (8).
The subsequent step of the method, Context Anal-
ysis, was also performed. It calculated both metrics
(Equations (11) and (12)) for each person in each het-
erogeneous multigraph. Thus, for each experiment
configuration, it was generated two predator rankings.
Since the experiments counted on a labeled data set,
it was possible to evaluate the method performance
with respect to those rankings. Table 6 shows the per-
formance results compared to the Naive approach of
the method proposed by Bretschneider et al. (2014)
and Bretschneider and Peters (2016), applied to the
same vocabulary. Considering that it is the evaluation
of a score ranking, an adaptation of the measure Area
Under the Curve (AUC) (Li et al., 2018) was used.
This measure expresses the probability that a suspect
always has a score higher than a non-suspect, both
chosen n times randomly. In this work, n = 100.
Note that Table 6 shows the results for both exper-
iment configurations (E
1
and E
2
) with two vocabular-
ies: O
1
and O
2
. The O
2
vocabulary is an evolution of
O
1
. It was created to include a new category of terms
to represent clothing terms (Clothes category). For
this category, the specialist assigned a weight value
of 5.0 (five) for its importance. The subclasses for
this new category (root class) were created based on
the ontology proposed in Kuang et al. (2018).
The Naive method assumes that messages are sus-
picious if they have at least one term present in the
vocabulary. Once identified suspicious messages, a
person is suspicious if he/she had sent more than two
suspicious messages to the same person. To compare
the method proposed in the present work to the Naive
method, for the latter one, people were ranked accord-
ing to the number of suspicious messages sent.
Analyzing the results in Table 6, for the experi-
ments performed using the O
1
vocabulary, the method
proposed here obtained superior results for both met-
rics, if compared to the Naive method (AUC = 0.255).
Note that the E
1
experiment configuration obtained
the best performance for the M
GW
metric (AUC =
0.478), showing a difference of 0.023, when com-
pared to the other M
FGW
metric (AUC=0.455). How-
ever, none of the metrics obtained an AUC value
greater than 0.5, which may lead to the conclusion
that the E1 experiment setup could have been inap-
propriate.
On the other hand, for the E2 experiment setup,
both metrics (M
GW
and M
FGW
) obtained results
higher than 0.5, showing a better performance of the
method when it is configured to analyze a limited
number of messages per person. The best AUC value
(0.660) was obtained with the M
GW
metric. It shows
a difference of 0.04 when compared to the AUC value
obtained with the M
FGW
metric (AUC=0.620).
With respect to the use of the evolved vocabulary
(O
2
), the experiments’ performance is very similar to
the ones using the O
1
vocabulary. Again, the method
proposed in this work obtained better results than the
Naive method Bretschneider and Peters (2014), for
both experiment setups and metrics.
Note that the E2 experiment configuration ob-
tained AUC values greater than 0.5 for both metrics,
showing a good performance of the method in exe-
cutions with both vocabularies. With the use of O
2
vocabulary, the best performance was obtained with
M
GW
metric (AUC = 0.655), which shows an im-
provement of 0.060 when compared to the AUC value
obtained with the M
FGW
metric (AUC = 0.595). For
this setup, the M
GW
metric obtained the best AUC val-
ues in all cases, and the best one was with the O
1
vocabulary (AUC = 0.660). When compared to the
AUC value obtained using the O
2
vocabulary (AUC =
0.650), it shows a downward tendency, which leads to
the idea that the evolution of the vocabulary was not
well conducted. Therefore, taking into account that
the best results were obtained with a limited num-
ber of messages per user within the network cutout
(no more than M
d
messages), it is possible to con-
clude that this may be the best setup. Moreover,
it also reduces the computational effort, and conse-
quently, shortens the execution time, which benefits
the method users. Another point to highlight is that
the method showed worse results when using the fre-
quency of suspicious terms in each person’s mes-
sages. Then, the proposed method should recommend
preferably the M
GW
metric rather than the M
FGW
met-
ric that uses the term frequency. Finally, the enrich-
ment of the controlled vocabulary should be carefully
conducted to avoid a method performance loss.
In short, the hypothesis raised at the introduction
of this work seems to have been confirmed, i.e., the
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
60

Table 6: Results obtained with the metrics M
FGW
and M
GW
,
considering the experiment configurations E1 and E2.
Proposed Method
E1 E2
Controlled
Vocabulary
Bretcheneider
(Naive)
M
GW
M
FGW
M
GW
M
FGW
O
1
0,255 0,478 0,455 0,660 0,620
O
2
0,275 0,430 0,430 0,655 0,595
use of a controlled vocabulary over a crime type do-
main may be a way towards the identification of suspi-
cious persons. It is important to highlight that despite
the AUC values presented by INSPECTION are not
comparable to the ones produced by machine learn-
ing methods, the proposed method does not demand
labeled data as these methods do.
7 CONCLUSIONS
One of the main concerns in the analysis of social net-
works is to identify suspicious people. It is a hard
task to find out who makes use of these networks to
practice crimes or spread risk to other people. There
are already several machine learning based methods
to identify suspicious people in social networks. Al-
though most of them have shown promising results,
they demand previously labeled data (indicating who
are the suspects) to build their classification models.
Such demand hampers their use in real applications
because labeled data in the context of virtual crimes
are usually rare and difficult to obtain. Given this
scenario, the present work proposed INSPECTION, a
method that uses a controlled vocabulary, specifically
built according to the crime type in focus, to identify
suspicious people in the social network, without the
need of previously labeled data sets.
To evaluate the proposed method, this work re-
ports on experiments for the pedophilia criminal sce-
nario. To perform these experiments, a prototype was
implemented. Also, a specific controlled vocabulary
was built (in Portuguese), based on other existing vo-
cabularies. The results show that the INSPECTION
method is a promising approach to identify suspi-
cious people without depending on a previously la-
beled data.
Future works include evaluating the performance
of the proposed method applied to other social net-
works, and other crime types. In addition, an on-
going work is the extension of the proposed method
to include social network topological analysis. Such
analysis may lead to improvements on the INSPEC-
TION’s performance. Moreover, the inclusion of a
new stage in the INSPECTION process to enrich the
controlled vocabulary is foreseen, as well as, to con-
sider semantic information while weighting the con-
trolled vocabulary.
ACKNOWLEDGEMENTS
This study was partially funded by the Cybernetic
Research Subproject of the Brazilian Army Strategic
Project. In addition, the authors would like to thank
Dr. Paulo Renato da Costa Pereira, a specialist in pe-
dophilia crimes of the Brazilian Federal Police, for his
valuable support throughout the experiments.
REFERENCES
Andrijauskas, A., Shimabukuro, A., and Maia, R. F. (2017).
Desenvolvimento de base de dados em língua por-
tuguesa sobre crimes sexuais (in Portuguese). VII
Simpósio de Iniciação Científica, Didática e Ações
Sociais da FEI.
Berry Michael, W. (2004). Automatic discovery of similar
words. Survey of Text Mining: Clustering, Classifica-
tion and Retrieval”, Springer Verlag, New York, LLC,
pages 24–43.
Bretschneider, U. and Peters, R. (2016). Detecting cyber-
bullying in online communities. European Confer-
ence on Information Systems.
Bretschneider, U., Wöhner, T., and Peters, R. (2014). De-
tecting online harassment in social networks. Inter-
national Conference on Information Systems.
Chandrasekaran, B., Josephson, J. R., and Benjamins, V. R.
(1999). What are ontologies, and why do we need
them? IEEE Intelligent Systems and their applica-
tions, 14(1):20–26.
Dong, Y., Tang, J., Wu, S., Tian, J., Chawla, N. V., Rao, J.,
and Cao, H. (2012). Link prediction and recommen-
dation across heterogeneous social networks. In 2012
IEEE 12th International conference on data mining,
pages 181–190. IEEE.
Dorogovtsev, S. N. and Mendes, J. F. (2002). Evolution of
networks. Advances in physics, 51(4):1079–1187.
Elzinga, P., Wolff, K. E., and Poelmans, J. (2012). Ana-
lyzing chat conversations of pedophiles with temporal
relational semantic systems. In Europ. Intel. and Se-
curity Informatics Conf., 2012, pages 242–249. IEEE.
Figueiredo, D. R. (2011). Introdução a redes complexas (in
Portuguese), pages 303–358. Sociedade Brasileira de
Computação, Rio de Janeiro.
Fire, M., Katz, G., and Elovici, Y. (2012). Strangers intru-
sion detection-detecting spammers and fake profiles in
social networks based on topology anomalies. Human
Journal, pages 26–39.
Hobbs, J. R. and Pan, F. (2006). Time ontology in owl.
W3C working draft, 27:133.
Kronk, C., Tran, G. Q., and Wu, D. T. (2019). Creating a
queer ontology: The gender, sex, and sexual orienta-
tion (gsso) ontology. Studies in health technology and
informatics, 264:208–212.
Kuang, Z., Yu, J., Li, Z., Zhang, B., and Fan, J. (2018). In-
tegrating multi-level deep learning and concept ontol-
ogy for large-scale visual recognition. Pattern Recog-
nition, 78:198–214.
Identifying Suspects on Social Networks: An Approach based on Non-structured and Non-labeled Data
61

Li, S., Huang, J., Zhang, Z., Liu, J., Huang, T., and Chen,
H. (2018). Similarity-based future common neighbors
model for link prediction in complex networks. Sci-
entific reports, 8(1):1–11.
Morais, E. A. M. and Ambrósio, A. P. L. (2007). Mineração
de textos (in Portuguese). Relatório Técnico–Instituto
de Informática (UFG).
Moura, M. A. (2009). Informação, ferramentas ontológicas
e redes sociais ad hoc: a interoperabilidade na con-
strução detesauros e ontologias (in Portuguese). In-
formação & Sociedade: Estudos, 19:59–73.
Mukherjee, S. and Joshi, S. (2013). Sentiment aggrega-
tion using conceptnet ontology. In Proceedings of the
Sixth International Joint Conference on Natural Lan-
guage Processing, pages 570–578.
Muniz, C. P., Goldschmidt, R., and Choren, R. (2018).
Combining contextual, temporal and topological in-
formation for unsupervised link prediction in social
networks. Knowledge-Based Systems.
Neves, F. (n.d.). Elogios de A a Z (in Por-
tuguese). https://www.dicio.com.br/elogios-de-a-a-z.
Accessed: 2020-07-18.
Pendar, N. (2007). Toward spotting the pedophile telling
victim from predator in text chats. ICSC, pages 235–
241.
Robertson, S. (2004). Understanding inverse document fre-
quency: on theoretical arguments for idf. Journal of
documentation.
Rosse, C. and Mejino, J. L. (2008). The foundational model
of anatomy ontology. In Anatomy Ontologies for
Bioinformatics, pages 59–117. Springer.
Sales, R. d. and Café, L. (2009). Diferenças entre tesauros e
ontologias (in Portuguese). Perspectivas em Ciência
da Informação, 14(1):99–116.
Santos, L. and Guedes, G. P. (2019). Identificação de
predadores sexuais brasileiros por meio de análise
de conversas realizadas na internet (in Portuguese).
XXXIX Congresso da Sociedade Brasileira de Com-
putação.
Scheider, S. and Kiefer, P. (2018). (re-) localization of
location-based games. In Geogames and Geoplay,
pages 131–159. Springer.
Villatoro-Tello, E., Juárez-González, A., Escalante, H. J.,
Montes-y Gómez, M., and Pineda, L. V. (2012). A
two-step approach for effective detection of misbehav-
ing users in chats. CLEF.
Wang, A. H. (2010). Don’t follow me: Spam detection in
twitter. In International Conference On Security and
Cryptography (SECRYPT), pages 1–10. IEEE.
Wilbur, W. J. and Yang, Y. (1996). An analysis of statistical
term strength and its use in the indexing and retrieval
of molecular biology texts. Computers in Biology and
Medicine, 26(3):209–222.
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
62
