
DynamoML: Dynamic Resource Management Operators for Machine
Learning Workloads
Min-Chi Chiang and Jerry Chou
National Tsing Hua University, Hsinchu, Taiwan
Keywords:
Deep Learning, GPU Resource Management, Job Scheduling, Performance Optimization.
Abstract:
The recent success of deep learning applications is driven by the computing power of GPUs. However, as
the workflow of deep learning becomes increasingly complicated and resource-intensive, how to manage the
expensive GPU resources for Machine Learning (ML) workload becomes a critical problem. Existing resource
managers mostly only focus on a single specific type of workload, like batch processing or web services, and
lacks runtime optimization and application performance awareness. Therefore, this paper proposes a set of
runtime dynamic management techniques (including auto-scaling, job preemption, workload-aware schedul-
ing, and elastic GPU sharing) to handle a mixture of ML workloads consisting of modeling, training, and
inference jobs. Our proposed system is implemented as a set of extended operators on Kubernetes and has
the strength of complete transparency and compatibility to the application code as well as the deep learning
frameworks. Our experiments conducted on AWS GPU clusters prove our approach can out-perform the native
Kubernetes by 60% system throughput improvement, 70% training time reduction without causing any SLA
violations on inference services.
1 INTRODUCTION
Deep Learning (DL) is popular in data-center as an
important workload for artificial intelligence, because
it powers variety of applications, including image
classification (He et al., 2016; Krizhevsky et al.,
2017), object detection (Redmon et al., 2015; Xu
et al., 2017), language processing (Vaswani et al.,
2017; Devlin et al., 2018; Yang et al., 2019; Liu et al.,
2019; Lan et al., 2019) to self-driving cars (Tian et al.,
2017) and autonomous robotics (Levine et al., 2016).
However, deep learning is also known to be comput-
ing intensive. As reported in a recent survey (Amodei
and Hernandez, 2018), the amount of computations
used in the largest AI training runs has been increas-
ing exponentially with a 3.4-month doubling time,
which is at the pace even faster than the Moore’s
Law. The increasingly popular trend of AutoML tech-
niques, such as automatic hyper-parameter tuning and
network architecture search, further pushes the need
of computing power as models must be repeatedly
trained with different settings in order to refine DL
models.
GPUs have emerged as a popular choice for deep
learning applications because of their tremendous
throughput powered by massive parallelism. Hence,
today’s deep learning production systems are mostly
built on shared multi-tenant GPU clusters where
abundant computing resources can be utilized and
shared among users to enable large-scaled model
training, and highly efficient model inference serving.
Therefore, it has drawn increasing attention from both
industry and research communities to improve the ef-
ficient and performance of expensive GPU resources
for DL workloads.
Resource management (such as resource alloca-
tion, job scheduling) is one of main approaches for
improving job performance, system throughput and
hardware utilization. But managing the resources of
DL workload on GPU cluster can be challenging be-
cause DL production needs several processing stages
from data pre-processing to model training, valida-
tion, and finally model deployment for serving in-
ferences. The workflow is also known as the ML
pipeline. For simplicity, we refer the computation be-
fore model training as the modeling jobs; the com-
putations for modeling and hyper-parameter tuning
as the training jobs; and the computations for serv-
ing model inference requests as the inference jobs.
The workload characteristics of each of these jobs can
be widely different from each other. For instance,
modeling jobs can be non-GPU bound jobs because
some of the data pre-processing tasks involve inter-
active data analysis, and others may hardly be paral-
122
Chiang, M. and Chou, J.
DynamoML: Dynamic Resource Management Operators for Machine Learning Workloads.
DOI: 10.5220/0010483401220132
In Proceedings of the 11th International Conference on Cloud Computing and Services Science (CLOSER 2021), pages 122-132
ISBN: 978-989-758-510-4
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

leled using GPU, such as feature extraction in adver-
tisement (He et al., 2014) and data augmentation in
computer vision (Zoph et al., 2019). Training and in-
ference jobs both require GPUs, but training behaves
like parallel batch processing with huge and stable
GPU usage pattern, while inference behaves like web
service with short and bursty GPU usage pattern. In
addition, inference jobs can have strict SLA require-
ments on the request response time. In contrast, train-
ing jobs can be suspended through the checkpoint-
restart mechanism. The mixture and diverse comput-
ing jobs in DL workload creates difficulties as well as
opportunities on resource management.
Existing cluster schedulers (e.g., Borg (Verma
et al., 2015), YARN (Vavilapalli et al., 2013)) are de-
signed for general-purpose workload. Their schedul-
ing algorithms (e.g., DRF (Ghodsi et al., 2011),
TetriSched (Tumanov et al., 2016), corral (Jalaparti
et al., 2015), HT-Condor (Tannenbaum et al., 2001))
are mostly designed to ensure resource fairness and
utilization by allocating a fixed amount of resources
for each job according to the resource requirements
specified by the job owner upon job submission. As a
result, existing approach may lead to sub-optimal ap-
plication performance and system throughput due to
the following reasons.
1. Application-oblivious Scheduling. Existing
schedulers only concern about the amount of re-
sources allocated to each job without being aware
of the application performance and resource char-
acteristics. For training jobs, the location of allo-
cated GPUs can significantly affect training time
due to communication overhead. For inference
jobs, their performance is measured by SLA guar-
antee which depends not only on the resource
allocations, but also on the time-varied service
workload (i.e., inference requests from clients).
For modeling jobs, they are consisted of non-GPU
and interactive workload, so their performance
can be much less sensitive to GPU resources.
Hence, without properly considering the perfor-
mance impact from resource allocations can eas-
ily lead to under-utilization or under-provisioning
problems.
2. Static Resource Management. Due to the work-
load diversity and time-varied resource demands
of DL workload, dynamic resource management
like job preemption, auto-scaling, is essential to
guarantee application performance and resource
utilization. But existing cluster managers often
require job owners to manually operate or re-
submit their jobs in order to adjust the resources
of jobs. The lack of resource management expe-
rience and information further discourage users to
adjust their job resources when necessary.
3. Coarse-grained GPU Allocation. Due to the
lack of multi-tasking management of GPU device,
the minimum granularity of GPU allocation today
is a single GPU device. That means an application
can have multiple GPUs, but each GPU can only
be allocated to exactly one application. While DL
jobs can be accelerated using GPUs, a single DL
job may not always utilize the whole GPU card
due to reasons like memory-bound training jobs
with large batch sizes or large network models,
non GPU-bound modeling jobs with human inter-
actions, and inference job with time-varied work-
loads. Hence, existing GPU cluster without sup-
porting GPU sharing can result in low resource
utilization and system throughput.
4. Homogeneous Workload Consideration. Not
until recently, DL domain specific management
systems (Peng et al., 2018; Xiao et al., 2018; Xiao
et al., 2020) have been proposed to tackle the is-
sues above. However, all of them focus on DL
training jobs only. With the emerging trend of
MLOps and AutoML that requires to unify ML
system development (Dev) and ML system opera-
tion (Ops) together, end-to-end ML pipelines with
mixture workloads are likely to be ran and man-
aged in a shared resource pool provided by a sin-
gle production system. Therefore, resource man-
ager should be designed with the consideration of
jobs with different performance metrics, workload
characteristics, and execution priorities.
To address the aforementioned problems, we present
DynamoML, a Dynamic resource Management Oper-
ators for Machine Learning workloads. DynamoML
consists of three modualized runtime resource man-
agement operators. First operator manages fine-
grained shared GPU allocation to increase GPU uti-
lization. Second operator is an application-aware
scheduler to improves the performance of distributed
model training. Third operator is a performance-
driven auto-scaling controller to guarantees the SLA
requirement of model inference services. The three
operators can further collaborate to each other to
provide dynamic resource allocation across differ-
ent types of jobs through preemptive and priority
scheduling. Our system is designed and implemented
as the extended framework components to the Kuber-
netes, which has become the de facto resource man-
ager of containerized clusters and data centers. Our
experiments running a mixture of ML pipeline work-
load on a 16-GPUs cluster show that DynamoML im-
proves the native Kubernetes by increasing the system
throughput by more than 60%, reducing the average
training time by 70%, and eliminating all the SLA vi-
DynamoML: Dynamic Resource Management Operators for Machine Learning Workloads
123

olations. Our in-depth analysis also show that without
proper coordination and collaboration between differ-
ent management techniques to balance the resource
between training job and inference jobs, several issues
could occur, including SLA violation on inference
service, wasted idle GPUs, prolonged model training
time.
The rest of the paper is structured as follows. Sec-
tion 2 discusses the DL workload characteristics and
overall system architecture. Section 3 describes the
design and implementation of each DynamoML op-
erators. Section 4, and Section 5 presents our exper-
iment setup and results, respectively. Finally, the re-
lated work discussion is in Section 6, and the paper is
concluded in Section 7.
2 SYSTEM AND WORKLOAD
MODEL
2.1 ML Pipeline Workload
In this work, we consider a GPU cluster running a
set of computing jobs produced from the ML pipeline
workflow. In general, the jobs can be classified into
three types: modeling, training, and inference. The
workload characteristics of these three types of jobs
are summarized in Table 1, and briefly discussed as
follows.
• Modeling. We use modeling jobs to represent all
the computing jobs before model training. In gen-
eral, modeling jobs involve neural network model
building and interactive data pre-processing, in-
cluding data cleaning, labeling, validations, and
feature extraction. In practice, users normally per-
form these tasks through web notebooks, such as
Juypter Notebook. Since the computations in this
pipeline stage commonly involves data process-
ing and human interaction, the GPU usage is low,
some execution delay can be tolerated, and the
workload pattern can be bursty.
• Training. Model training can be extremely
time consuming. In order to reduce training
time, distributed model training across multiple
GPU-nodes has been supported by the main-
stream deep learning frameworks, such as Tensor-
flow, PyTorch, and Keras. Most of them adapt
the BSP (Bulk Synchronous Parallel) comput-
ing method to implement the data parallel model
training, where a training job is consisted of a set
of worker processes, and all the workers must syn-
chronously aggregate their gradients at the end of
each training iteration in order to update the model
weights. Since training time can be long, mod-
ern deep learning libraries also support checkpoint
mechanism to tolerant faults and to restart training
with different resource configurations. Therefore,
comparing other two types of jobs, training has the
highest resource usage and the lowest urgency.
• Inference. To serve model’s inference requests
from clients, an inference job often packages the
model and deploys it as a web service (e.g., TF-
Server). Similar to web services, the workload of
a web service can be time-varied according to the
number of client requests, and the SLA require-
ment of a service can be guaranteed. Therefore,
inference jobs should have the highest urgency
with periodic workload pattern and medium GPU
usage demand.
2.2 DynamoML Operators
According to the aforementioned workload character-
istics, we proposed and implemented a resource man-
agement framework called DynamoML. The goal of
our system is to support efficient ML pipeline work-
load executions on GPU cluster by maximizing re-
source utilization while satisfying application perfor-
mance requirements.
Our work is implemented as an extended frame-
work on Kubernetes, because Kubernetes has become
the most popular resource orchestrator for hosting
containerized computing workload. However, Kuber-
netes, like our cluster schedulers (e.g., Borg (Verma
et al., 2015), YARN (Vavilapalli et al., 2013), HT-
Condor (Tannenbaum et al., 2001)), is lack of proper
resource management for DL workloads. Our re-
source management techniques are implemented as
three modualized operators:
• Shared GPU Allocator. it enables fine-grained
shared GPU allocation in Kubernetes. Hence, the
GPU utilization can be increased by allowing mul-
tiple non-GPU bound modeling jobs to share a sin-
gle GPU. In comparison, the native device plug-in
framework of Kubernetes doesn’t allow fractional
allocation.
• Distributed Training Job Scheduler. It is a runtime
scheduler that addresses several resource alloca-
tion problems of distributed model training jobs.
(1) It reduces the communication overhead of dis-
tributed training by packing the workers of a train-
ing job on a single node . (2) It avoids the idle re-
source problem of synchronous computations by
proving gang scheduling, so that all the workers
of a training job will be scheduled together as a
group. (3) It uses checkpoint mechanism to force
CLOSER 2021 - 11th International Conference on Cloud Computing and Services Science
124
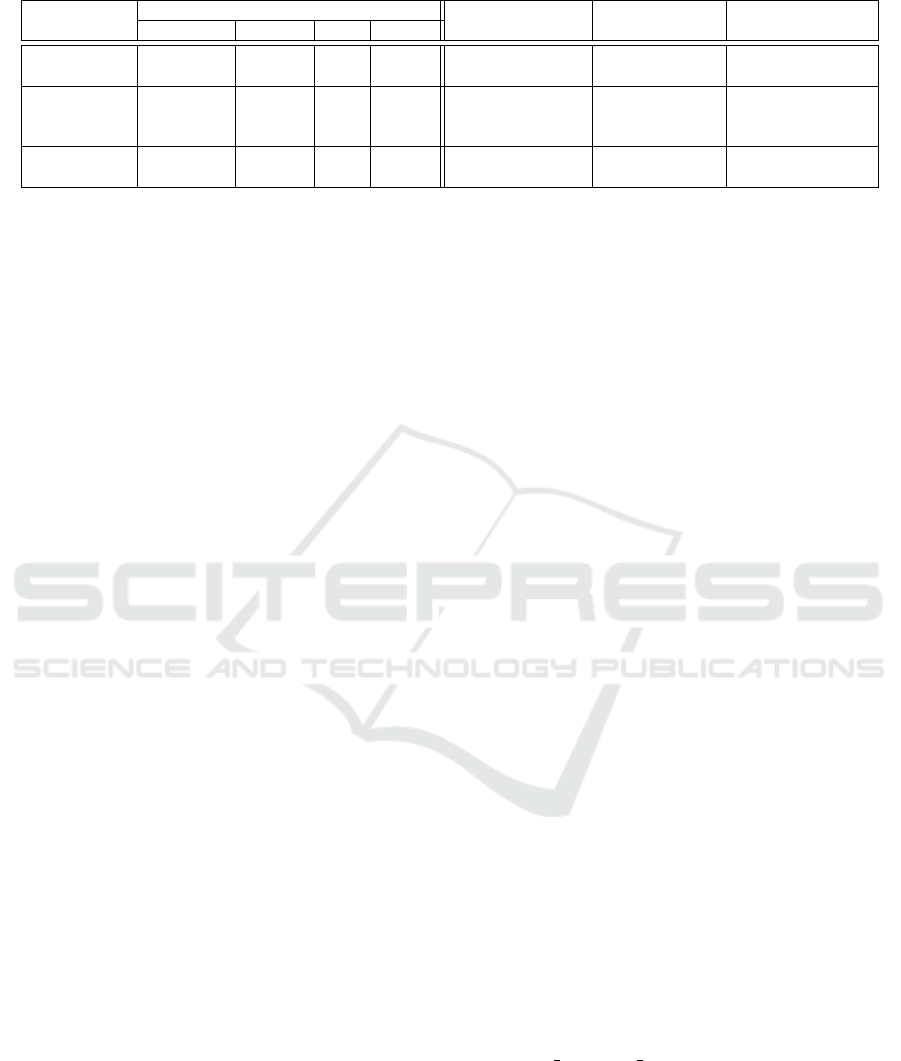
Table 1: Summary of ML Pipeline workload characteristics and their corresponding resource management solutions.
Job Type Workload Characteristics Problems Solutions Results
type pattern usage urgency
Modeling interactive Bursty Low Med 1.Low utilization Fractional & elastic Increase utilization
(e.g., Notebook) data analysis GPU allocation
BSP (Bulk 1.Resource monopoly 1.Gang & locality 1.Avoid idle resources
Training Synchronous Persistent High Low 2.Communication aware scheduling 2.Reduce training time
(e.g., TFJob) Parallel) 3.Synchronization 2.Task preemption
Inference Web service Periodic Med High 1.SLA requirement Auto-scaling Avoid SLA
(e.g., TFServer) 2.Elastic workload violation
resource preemption on training jobs, so the re-
sources won’t be monopolized by the long run-
ning training jobs. In comparison, the native Ku-
bernetes scheduler cannot achieve these goals be-
cause it lacks of the awareness of application per-
formance.
• Inference Service Auto-scaling Controller. It aims
to dynamic add or remove the server instances of a
service job according to the response time of infer-
ence requests, so that an application level SLA re-
quirement can be guaranteed under workload vari-
ations. In comparison, the existing scaling mech-
anism in Kubernetes is based on resource usage
not application performance. Furthermore, when
the system is lack of resources for inference jobs,
auto-scaling controller can ask job scheduler to re-
lease the resources of training jobs. Therefore, in-
ference jobs always have the highest scheduling
priority in our framework.
2.3 Design Requirements & Strengths
Besides the goal of resource management, Dy-
namoML also has the following strengths from its de-
sign requirements.
• Transparency. All the resource control mechanism
of DynamoML are implemented as the extended
components of Kubernetes using the technique
like custom controller, sidecar container, and li-
brary hooks. Therefore, no code modification to
the deep learning computing frameworks or user
program. Because of transparency, our system
can work seamlessly with Kubernetes, and our re-
source management strategy can also be applied
any application with the same targeted workload
characteristics.
• Modularization. each component of DynamoML
provides a standalone management service, such
as GPU sharing, scheduling and auto-scaling.
These services are triggered by their service-
defined API and event. Hence, system administra-
tors can independently deploy the individual com-
ponents of DynamoML according to their needs.
• Agility. To overcome the workload variation and
diversity of ML pipeline jobs, DynamoML fo-
cuses on runtime resource sharing and manage-
ment. Form resource allocation aspect, our GPU
sharing supports elastic allocation which allows
the actual resource usage to be bounded between
a user specified range specified by a pair of val-
ues (request, limit), so that the resource within the
range can be elastically shared among users. From
resource usage aspect, DynamoML supports auto-
scaling and preemption on training and inference
jobs, so that resource demands can be adjusted and
adapted to the runtime application behavior and
performance.
3 SYSTEM IMPLEMENTATION
3.1 Shared GPU Allocator
GPU sharing is a necessary mean to improve re-
source utilization, especially for modeling and infer-
ence jobs. Our GPU sharing solution consists of two
parts. First is to enable fractional GPU allocation in
Kubernetes. Second is to ensure the GPU resource
can be shared fairly among containers.
The device plug-in framework of Kubernetes
treats GPU device as a single non-divisible resource
object, so fractional GPU allocation is not allowed.
To overcome this limitation, our system first launches
a set of pods to allocate the GPU resources from
Kubernetes, and obtain GPU devices’ UUID. Then
the same GPU can be attached to multiple con-
tainers installed with nvidia docker package by set-
ting the GPU’s UUID in in the environment variable
“NVIDIA VISIBLE DEVICES”. To support frac-
tional allocation, our shared GPU allocator will track
the residual resource amount on each GPU, and en-
sure GPUs are not over-allocated.
After a GPU is attach and accessible by a con-
tainer, we still have to ensure the actual resource us-
age doesn’t exceed the allocation amount. As shown
in Figure 1, to throttle the GPU usage of a container,
DynamoML: Dynamic Resource Management Operators for Machine Learning Workloads
125

ϭϴϯ
Es//ƌŝǀĞƌ
ƉƉůŝĐĂƚŝŽŶWƌŽŐƌĂŵ
,ŽŽŬůŝďƌĂƌLJ͕
ZƵŶƚŝŵĞ
/ŶƚĞƌĐĞƉƚĞĚ
ŬĞƌŶĞůůĂƵŶĐŚ͕
ƐLJŶĐW/Ɛ
^ĐŚĞĚƵůĞƌ
'Wh
W/
ƉĂƐƐͲ
ƚŚƌŽƵŐŚ
dŽŬĞŶƌĞƋƵĞƐƚ
ΘhƐĂŐĞŝŶĨŽ
ƚŽŬĞŶ
ůŝĞŶƚ͗ϭ
KŶůLJĐĂůůƐ
ĂĨƚĞƌƚŽŬĞŶĞdžƉŝƌĞƐ
^ĐŚĞĚƵůŝŶŐƋƵĞƵĞ
Figure 1: GPU usage control framework.
we insert a LD PRELOAD hook library in the con-
tainer to intercept its GPU API. The intercepted GPU
APIs will be blocked until the hook library receives
an execution token from the scheduler of our GPU al-
locator. A time-sharing scheduler is implemented to
pass the token around containers according to their
resource allocation demand. Therefore, the resource
usage of a container cannot exceed its allocated de-
mand. To maximize GPU utilization, we further sup-
port elastic allocation, which allow users to specify
their minimum and maximum demand as (request,
limit), so that the requested resource can be reserved
and guaranteed, while the residual capacity can still
be utilized by the container without exceeding its
limit. More details of the design and implementation
can be found in our previous work (Yeh et al., 2020).
3.2 Training Job Scheduler
The native Kubernetes scheduler schedules the con-
tainer (i.e. pod) of each worker task independently
on random nodes with sufficient resources. However,
distributed training jobs are communication-bound
with task dependency among each other. So the naive
FCFS random scheduling algorithm of native Kuber-
netes scheduler can cause significant communication
and synchronization overhead.
To address the above issues, we developed our
own job-level scheduler on top of the task-level na-
tive scheduler to schedule and manage all the tasks
of a training job as a unit. Through our scheduler,
a job is only launched when the system has enough
residual capacity to run all its tasks simultaneously.
Thus, resources will not be occupied by tasks waiting
for synchronization. To minimize the communication
overhead of a job, our scheduler tends to pack all the
tasks of a job on as fewer number of compute nodes
as possible. The location of the task is controlled by
specifying the “node selector” label in the pod spec
of the workers, so the native scheduler can only cre-
ate the pods on the designated nodes of our scheduler.
Finally, our scheduler monitors the system re-
source usage status to dynamically adjust the number
Figure 2: The system design diagram of the inference auto-
scaling controller.
of workers of training jobs. Additional workers are
added to training jobs when the system loading is low,
so that jobs can take advantage of the residual capac-
ity to reduce their execution time. On the other hand,
workers can also be taken from jobs when the system
loading is high, so that the resources can be reclaimed
from the running jobs to launch the waiting jobs as
soon as possible. More details of the design and im-
plementation can be found in our previous work (Lin
et al., 2019).
3.3 Inference Auto-scaling Controller
In order to dynamically scale up and down in re-
sponse to a varied number of users’ requests, we inte-
grated Kubernetes Horizontal Pod Autoscaler (HPA).
However, the na
¨
ıve Kubernetes Horizontal Pod Au-
toscaler (HPA) is limited to scale pods according to
the current state of CPU or memory consumption.
The most direct way to scale pods should depend on
the current number of users’ requests, which requires
us to integrate third-party solutions to fulfill this goal.
We further integrate Istio, a popular tool to build ser-
vice mesh in our implementation, to gather the re-
quests’ information within the cluster.
The term service mesh is used to describe the net-
work of microservices that make up such applications
and their interactions. Its requirements can include
service discovery, load balancing, metrics, and moni-
toring. Istio’s solution creates a network of deployed
services with traffic management, security, observ-
ability, and extensibility. It directly attaches a sidecar,
a proxy to help pod exchanging information, to ev-
ery pod. Whenever there exists a need to pass data
between pods, the sidecar would intercept all net-
work communication. By intercepting the commu-
nications, Istio generates metrics for all service traf-
fic in, out, and within an Istio service mesh. These
metrics provide information on behaviors such as the
CLOSER 2021 - 11th International Conference on Cloud Computing and Services Science
126
overall traffic volume, the error rates within the traf-
fic, and the response times for requests. As a result,
we use Istio as our primary tool to gather the commu-
nications metrics.
As shown in Figure 2, when we successfully fetch
the metrics from Istio, we need to store the informa-
tion for Kubernetes Custom Metrics API to query. Al-
though we’re able to forward data from Istio to Ku-
bernetes Custom Metrics API directly, we could fur-
ther store, query, and monitor the metrics if we store
in Prometheus. By employing Prometheus, a popular
Time-Series Database, to periodically forward infor-
mation to Prometheus, we gather the metrics, includ-
ing the request number per second and response time.
Then, since Kubernetes HPA is only able to fetch met-
rics from Kubernetes Custom Metrics API, we install
the Prometheus Adapter and register it to Kubernetes
Custom Metrics API. Finally, Kubernetes HPA is ca-
pable of scale up and down pods according to the cur-
rent number of users’ requests.
In order to prioritize the inference jobs and pre-
empt the training jobs if needed. Whenever there’s
a necessity to increase the inference pods in re-
sponse to flooded users’ requests, our auto-scaling
controller would check whether current residual re-
sources are available for inference jobs to scale up.
If not, we would sequentially evict the workers of
training jobs (TFJobs), release sufficient GPU re-
sources for inference pods. We leave at least one
worker (chief worker) for every TFJobs in our imple-
mentation, so that TFJobs can proceed training pro-
cess continuously without requiring checkpoint. Fi-
nally, the Kubernetes API scheduler would allocate
GPU resources for the new inference pods, which
makes platform reach inference jobs’ Service Level
Agreement (SLA).
In our implementation, we label the inference
pods first, making Kubernetes Operator capable of
identifying inference jobs. Then, by Kubernetes na-
tive event-driven mechanism, we registered OnAdd,
OnUpdate events of inference pods. Whenever Ku-
bernetes HPA decides to scale up inference pods, the
training job scheduler would be notified by the Ku-
bernetes control manager, check whether the current
residual resource is available for the new pod, and
decide whether to release the resources for inference
jobs by scaling down training workloads. Also, train-
ing job scheduler would periodically check the resid-
ual resources. After Kubernetes HPA scale down in-
ference pods and release the GPU resources, training
job scheduler would scale up training jobs once detect
residual resources.
VSHHGXSRIWUDLQLQJWKURXJKSXW
QXPEHURI*38V
0QLVW
5HVQHW
/LQHDU
Figure 3: The speedup of model training throughput of us-
ing multi-GPUs.
4 EXPERIMENT SETUP
We evaluate our implementation by conducting the
experiments on AWS cloud platform using a Kuber-
netes cluster consisting of 2 nodes (p3.16xlarge in-
stance type). Each node is equipped with a 64-cores
CPU (Intel Xeon E5-2686 v4), 488GB of RAM, and
8 Nvidia Tesla V100 GPUs with 128GB of device
memory. In order to conduct a comprehensive eval-
uation of our implementation, we design workloads
that include the computing jobs for modeling, train-
ing, and inference. The training and inference jobs
are based on the popular DL framework - Tensorflow.
The modeling jobs are based on the Jupyter Note-
book, which is a primary tool for developers to build
and test their models.
For the training jobs, we employ two different
common-seen image classification models (Mnist,
ResNet-50) and divide all of the Tensorflow
jobs (TFJob) into three groups. Every TFJob would
consist of one Parameter Server (PS) and several
workers, where workers can be added or removed
in response to the state of the residual resource in
our implementation. Each worker requests one GPU,
and a TFJob runs for a fixed training iterations. As
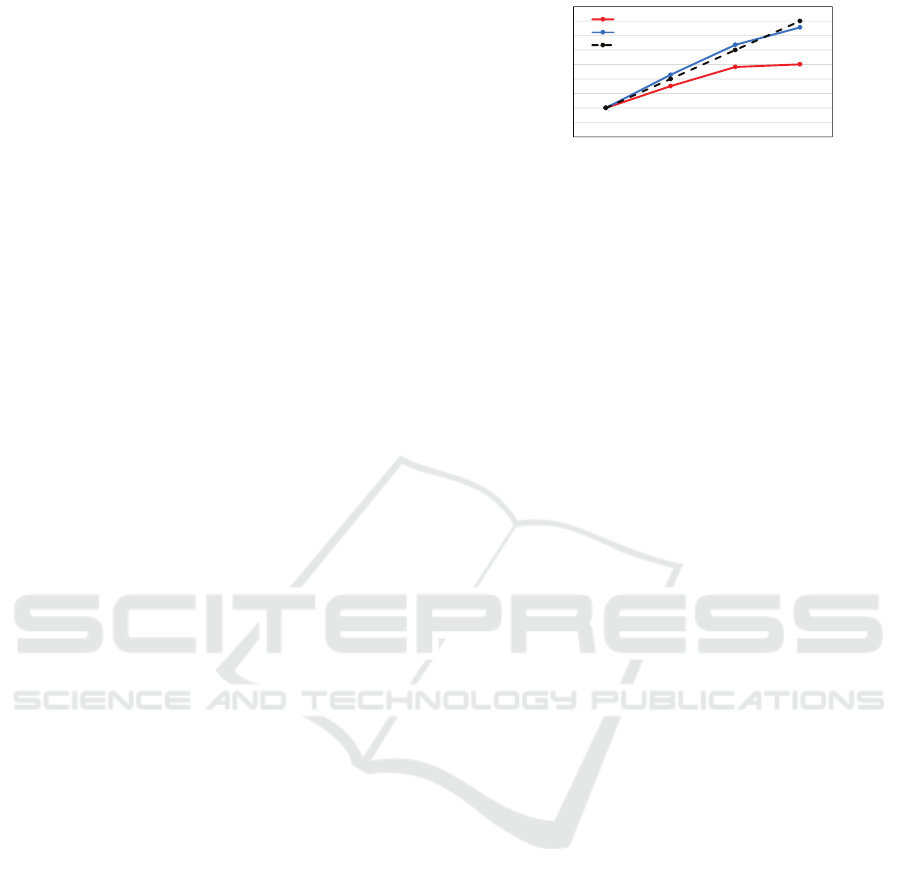
shown in Figure 3, both models can have higher train-
ing throughput and shorter training time when using
more GPUs. The speedup of ResNet-50 is close to
linear. The speedup of Mnist doesn’t increase much
with more than 3 GPUs because its model is too small
to have enough computations for parallel processing.
In the experiments, we set the maximum workers to 4
for both models.
For the inference jobs, we use a Resnet-50 model
as our inference service for all requests. Inference job
runs on TF-Serving applications, which computes the
forward propagation upon each arrival client requests.
Hence, its GPU usage is also approximately propor-
tional to the number of client requests. In our experi-
ment, One TF-Serving inference pod is configured to
consume only one GPU. As a result, the number of in-
ference pods would dynamically increase or decrease
in response to the number of active clients. For the
DynamoML: Dynamic Resource Management Operators for Machine Learning Workloads
127

ϳŵŝŶ
ϬŵŝŶ
ϭϬ
ϰϬ
ϭϬϬ
ϭϲϬ
ϮϮϬ
ϮϴϬ
ϯϰϬ
ϮϴϬ
ϮϮϬ
ϭϲϬ
ϭϬϬ
ϰϬ
ϯϰϬ
ϰϬ
ϰϬ
ϭϯŵŝŶ
ϰϬ
ϰϬ
ϰϬ
ϰϬ
ϰϬ
ϰϬ
ϭϬϬ
ϮϭŵŝŶ
ϭϲϬ
ϮϮϬ
ϭϲϬ
ϭϬϬ
ϰϬ
ϰϬ
ϮϴŵŝŶ
ϮϰŵŝŶ
ϰDE/^dƚƌĂŝŶŝŶŐ
ũŽďƐĂƌƌŝǀĞ
ϰZĞƐŶĞƚͲϱϬ
ƚƌĂŝŶŝŶŐũŽďƐĂƌƌŝǀĞ
ϭϬŵŝŶ
ϮϬŵŝŶ
ϰZĞƐŶĞƚͲϱϬͬDE/^d
ƚƌĂŝŶŝŶŐũŽďƐĂƌƌŝǀĞ
/ŶĐƌĞĂƐĞĨƌŽŵϭϬƚŽϯϰϬ
ĞĐƌĞĂƐĞƚŽϰϬ
ϬŵŝŶ
ϮϴŵŝŶ
ZĞŵĂŝŶĂƚϰϬ
/ŶĐƌĞĂƐĞ
ƚŽϮϮϬ
ĞĐƌĞĂƐĞ
ƚŽϰϬ
/ŶĨĞƌĞŶĐĞ
ǁŽƌŬůŽĂĚ
dƌĂŝŶŝŶŐ
ǁŽƌŬůŽĂĚ
Figure 4: Testing workload for system evaluations. The
workload of interface jobs are time-varied by adjusting the
number of active users. The workload of training jobs are
submitted in 4 groups and 4 jobs per group at time 0, 10, 20.
The modeling jobs are consisted of 4 notebook instances
persistently running throughout the experiments.
Table 2: Compared system configurations. The setting with
a resource management technique is marked by ”V”.
Training Inference GPU
scheduling auto-scaling Sharing
DynamoML V V V
K8S+Sharing V
K8S+Scaling V
Native K8S
purpose of evaluating the response time of inference
job under different workloads, a web client would
keep sending requests with a varied inter-arrival time.
Finally, for the modeling jobs, we sporadically is-
sue model evaluation requests to the Jupyter Note-
book instances, and the average GPU usage of a mod-
eling job never exceeds 25%.
To evaluate the benefits of our resource manage-
ment techniques in a runtime system. We construct
a testing work as shown in Figure 4. It contains a
total of 4 modeling (notebook) jobs, 1 inference job,
and 16 training jobs. The inference jobs and mod-
eling jobs are persistently running in the system, but
their user workload changes over time. As mentioned
above, the modeling has a sporadic random generated
workload with less than 25% GPU usage. The work-
load of the inference job controlled by adjusting the
number of concurrent active web clients in each time
interval (per minute) which can be seen from the bars
at each minute in Figure 4. Finally, the 16 training
jobs are submitted to the system every 10minutes in 4
groups with 4 jobs per group. The first group arrives
at 0
th
minute with 4 Mnist training jobs. The second
group arrives at 10
th
minute with 4 Resnet-50 train-
ing jobs. The last group arrives at 20
th
minute with 2
training jobs for each of the two models.
The goal of our evaluation is to compare the sys-
tem and application performance running the above
test work under different resource management con-
figuration settings. The names and resource manage-
ment techniques of each setting are summarized in Ta-
ble 2. The initial number of workers for a training job
is 2, and the initial number of server instance for a in-
ference job is 1. Both training and inference jobs can
be scaled upto to 12 instances (training workers or in-
ference servers) when auto-scaling techniques are ap-
plied (i.e., the total number of GPUs in our testbed is
16.). By default, all types of jobs request one GPU
per container instances (i.e., pods). Only when GPU
sharing technique is applied, a modeling job can allo-
cate 0.25 GPU.
5 EXPERIMENT RESULTS
5.1 System Performance Comparison
Figure 5 plots the GPU resource allocation results
over each time interval under different system set-
tings. Due to space limits, we show the results of
DynamoML and K8S+Scaling to illustrate the key
benefit of our approach. As recall, DynamoML sup-
ports all three proposed techniques: inference scaling,
training scheduling, and GPU sharing. K8S+Scaling
only supports inference scaling. K8S+Scaling also
represents the common use case when people are only
able to use the native Kubernetes installation with the
HPA auto-scaling package to run ML workloads.
According to the workload variation of inference
job, the allocation result can be discussed in the fol-
lowing three time frames from the DynamoML time-
line.
0min∼7min: The inference workload keeps in-
creasing during this time frame. Our auto-scaling op-
erator detected the increased request response time,
and started to launch more inference servers. Hence,
the number of GPUs allocated to inference increases
from 1 to 12. Noted, the inference job can occupy as
many as 12 GPUs because the training jobs are pre-
empted and forced to release their GPUs for inference
jobs. Therefore, some the training job only allocated
1 GPU at times. On the other hand, when there is
residual capacity or un-used GPUs, they can also be
dynamically allocated to the training jobs for reducing
training time. Therefore, the GPU allocation during
this time frame is almost always fully utilized.
8min∼20min: As the inference workload de-
creases, we can observe DynamoML quickly allocate
the available GPUs free from the inference job to the
training jobs. As a result, a training job can use up
to 4 GPUs at a time, and the training time is greatly
reduced. Because the training job finishes too early,
only 4GPUs needs to be used for handling the infer-
ence requests between time 18min∼20min which can
CLOSER 2021 - 11th International Conference on Cloud Computing and Services Science
128
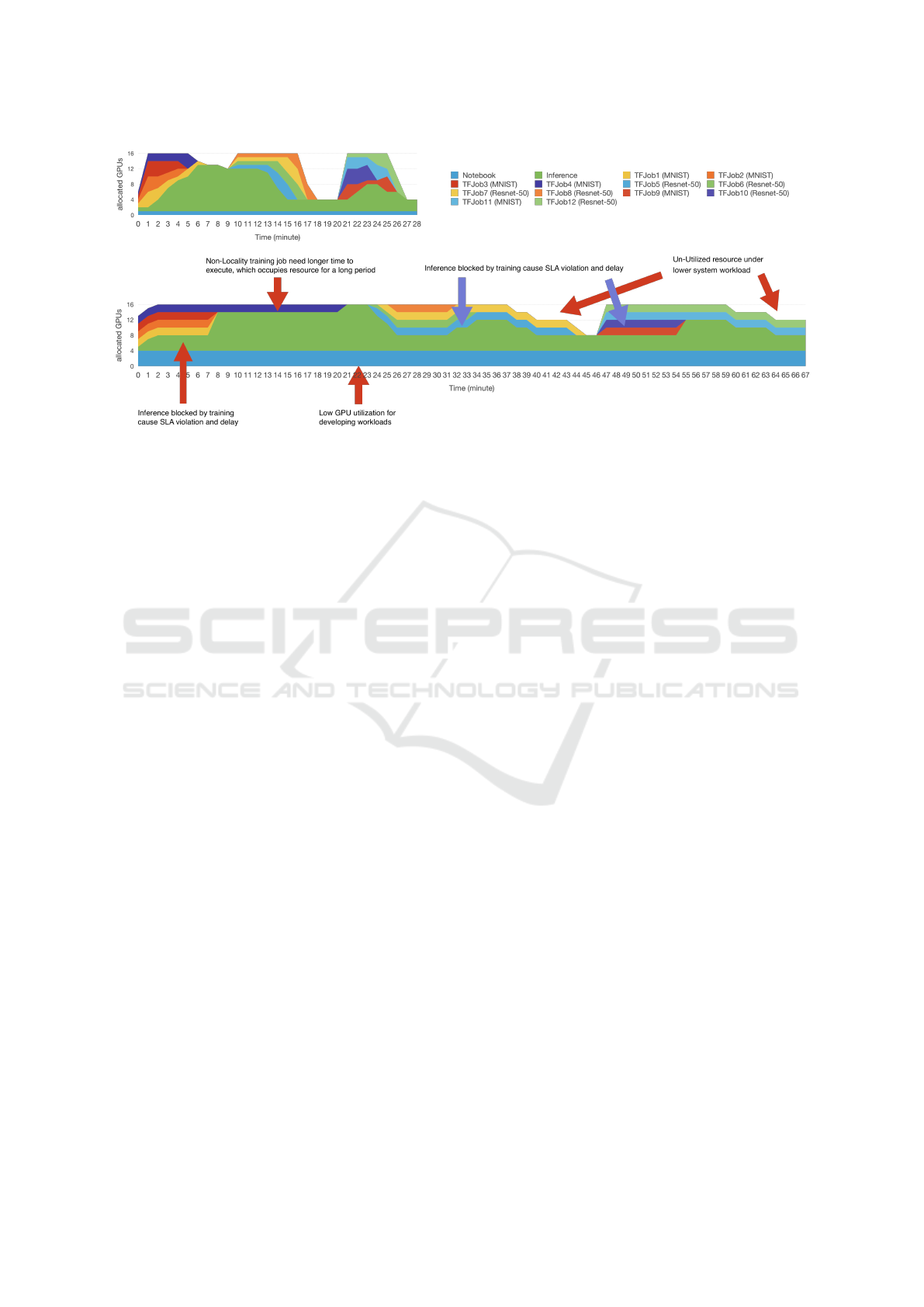
Figure 5: The overall resource allocation for DynamoML (top) and K8S+Scaling (bottom).
lead to an additional benefit of energy and cost saving
for system administrators or service providers.
21min∼28min: The last group of training job ar-
rives at 20min, and the inference workload also starts
to increase at 21min. So similar to the first time frame,
both training jobs and inference jobs can get more re-
sources at runtime, but the inference jobs have higher
priority than the training jobs. Also because of the
lower inference workload in this time frame com-
paring to the first time frame, training jobs received
more GPUs and complete all the training jobs before
27min.
In comparison, we can observe several problems
from the K8S+Scaling setting. (1) It fixes the allo-
cation of training job to 2 GPUs, and each model-
ing job (Notebook instance) occupies 1 GPU. Hence,
even though the inference job can be scaled to ob-
tain more GPUs, it can only use the residual capacity
from training and modeling jobs. Therefore, between
0min to 7min, the inference job only receives 4 GPUs
while it would receive 11 GPUs by DynamoML. (2)
The Kubernetes scheduler didn’t pack the workers of
a training on the same node which results in much
longer training time. In particularly, the communi-
cation overhead has a greater impact on the small
size models, like MNIST, because their communica-
tion time often takes higher ratio of the overall ex-
ecution time. Therefore, compared to the results of
DynamoML, TFJob4, TFJob7 and TFJob11 all took
much longer time to finish under the K8S+Scaling
setting. (3)Because the resource of training jobs is
fixed, they can take advantage of the residual capac-
ity in the system when system workload is light. For
instance, there are GPUs available between 37min to
46min, and 59min to 67min, but they cannot be al-
located to training jobs and cause unwanted resource
waste.
In sum, we can observe the important of dynamic
resource management when running complex and di-
verse workloads on a shared resource pool. With
our techniques, the overall workload execution time
is significantly reduced from 67mins to 27mins, an
improvement of almost 60%, and there are still rooms
for us to free-up some idle resources for energy or
cost saving. More importantly, DynamoML can im-
prove resource utilization and training performance
while guaranteeing the SLA requirement of inference
jobs. In the next two subsections, we further analyze
the performance of training jobs and the SLA viola-
tions of inference jobs to analyze the reasons of our
improvement.
5.2 Training Time Analysis
This subsection analyzes the impact of our resource
management techniques on the training jobs from run-
ning test workload shown in Section 4. Because
training job has lower execution priority and can be
queued in the submission queue when not enough re-
source available, the total execution time of a train-
ing can be divided into two parts: the training time
and the waiting time. The training time is the ac-
tual running time for training, and the waiting time
is time of a job waiting in the scheduling queue.
Therefore, we compare the improvements of these
two time measurements, and the total execution time
in Figure 6. Interestingly, we found that K8S+Scaling
produces the worst results across all the measure-
ments, even worse than the native K8S. This is be-
cause K8S+Scaling only optimizes for the inference
jobs not for the training jobs. Hence, in order to sat-
isfy the SLA requirements, it allow inference jobs to
DynamoML: Dynamic Resource Management Operators for Machine Learning Workloads
129

ZDLWLQJWLPH WUDLQLQJWLPH H[HFXWLRQWLPH
QRUPDOL]HGWLPH
'\QDPR0/ QDWLYH.6 .66KDULQJ .66FDOLQJ
Figure 6: Training time comparison.
3HUFHQWDJHRIWLPH
7KHQXPEHURIZRUNHUV
Figure 7: The distribution of the
number of worker per TFJob un-
der DynamoML.
Ϭ
Ϯϱ
ϱϬ
ϳϱ
ϭϬϬ
Ϭ ϭ Ϯ ϯ ϰ ϱ ϲ ϳ ϴ ϵ ϭϬ ϭϭ ϭϮ ϭϯ
&ŽĨũŽďƐ;йͿ
:ŽďĞdžĞĐƵƚŝŽŶƚŝŵĞ;ŵŝŶƵƚĞͿ
dŚĞĂǀŐƚŝŵĞŽĨŶĂƚŝǀĞ
<ϵ^ŝƐϭϯŵŝŶ
LJŶĂŵŽD> ƌĞĂĐŚĞƐ
ϭϬϬйǁŝƚŚŝŶϴŵŝŶƐ
Figure 8: The distribution of the training
job execution time under DynamoML.
allocate more resources, and sacrifices training jobs.
As a result, training jobs have higher probability to be
blocked or running with few GPUs. K8S+Sharing is
better than native Kubernetes, because it reduces the
amount of GPUs used by the modeling jobs, so train-
ing jobs can gain better performance. However, the
improvement of GPU sharing for training job is lim-
ited, because the communication overhead is the main
performance bottleneck for training jobs as we saw
from the cases like TFjob4 in Figure 5. In compari-
son, DynamoML combines all our techniques to sig-
nificantly reduce the waiting time by 55%, the train-
ing time by 70%, and the total execution time by 70%.
Finally, to prove our training job scheduler did dy-
namically add or remove workers to training jobs ac-
cording to the system loading, Figure 7 shows the
time distribution of a training job with a given number
of workers when using DynamoML. As seen, in av-
erage, about 22% of the job execution time uses only
1 GPU, 63% of the time uses 2 or less GPUs. Only
the reminding 37% of time using 3 or 4 GPUs. But
according to the execution time distribution shown
in Figure 8, DynamoML still significantly reduce the
overall training time. With DynamoML, more 60%
of the training jobs finishes within 5mins, and the
longest execution time is 8mins. In contrast, the aver-
age execution time for native K8S is 13mins.
5.3 Inference Performance Analysis
Lastly, we analyze the SAL violation of inference
job from the running test workload shown in Sec-
tion 4. Figure 9 shows the overall client response
time distribution of the TF-serving inference job un-
der different system settings. K8S+Sharing has the
worst results, where some of the requests have re-
sponse time over 1024ms. This is because it doesn’t
supports auto-scaling on the inference service. Dy-
namoML performs the best with no requests with re-
sponse time over 128ms, because it can preempt train-
ing jobs when necessary. One the other hand, al-
though K8S+Scaling also supports auto-scaling on in-
ference inference, but it cannot preempt training jobs.
As a result, the amount of resources for inference
&')RIFOLHQWUHTXHVWV
UHTXHVWUHVSRQVHWLPHPV
'\DQPR0/
.66FDOLQJ
.66KDULQJ
Figure 9: The comparison of the distribution of the response
time from inference jobs.
SHUFHQWDJHRI
6/$YLRODWLRQUHTXHVWV
WKHQXPEHURIDFWLYHFOLHQWV
'\QDPR0/
.66FDOLQJ
QDWLYH.6
Figure 10: SLA Violation of inference jobs under different
number of active users.
jobs can be bounded by the training jobs. Therefore,
the response time of K8S+Scaling is mostly between
128ms∼512ms. Figure 10 further breaks down the
SLA violation probability under different inference
workloads which is controlled by the number of ac-
tive clients. As expected, the violation probability
increases under highly workload. Only DynamoML
can be resilient to the workload because its ability to
obtain enough resources to satisfy the SLA require-
ments.
6 RELATED WORK
In recent years, both research and industry have made
great efforts to improve the performance of deep
learning jobs in a GPU cluster by utilizing domain-
specific knowledge. However, all these works target
on distributed training jobs alone. While our work
address the ML pipeline workload including model-
CLOSER 2021 - 11th International Conference on Cloud Computing and Services Science
130

ing and inference jobs as well. Also, most of the pro-
posed techniques requires modifications to the deep
learning frameworks, while our work can be transpar-
ent and general to DL applications.
Gandiva (Xiao et al., 2018) is a scheduling frame-
work developed by Microsoft. It supports many
management techniques together to maximize system
throughput for training jobs. It provides GPU shar-
ing among jobs in both temporal and spatial domains.
In temporal domain, jobs run on GPU in an inter-
leaved manner through suspend-resume mechanism.
In spatial domain, jobs simply run simultaneously on
a GPU at the same time, but jobs can be migrated to
another GPU if performance degradation is detected.
Gandiva also applies scaling mechanism to jobs that
self-declare to have good scalability. In order to min-
imize the overhead of their managing overhead like
migration, suspend-resume, and scaling, Gandiva has
to modify the deep learning frameworks, like Tensor-
flow and Pytorch.
The rest of researches are mainly focus on a more
specific resource management technique. Some of the
work focus on scaling policy of distributed training
jobs. For instance, Optimus (Peng et al., 2018) pro-
poses a GPU resource scheduler to decide the proper
resource amount and resource allocation according
to a performance model of distributed training jobs.
Similar to Optimus, DL2 (Peng et al., 2021) is a DL
driven scheduler that aims to decide proper resource
allocation to a distributed training job. But the per-
formance model proposed by DL2 is based on deep
reinforcement learning.
Other works focus on the job placement problems
for minimizing the communication time of distributed
training jobs. For instance, (Amaral et al., 2017) pro-
posed a topology aware scheduling to decide the map-
ping between worker tasks and GPU slots based on
the Hierarchical Static Mapping Dual Recursive Bi-
partitioning algorithm. Rather than optimizing the
performance of a single training job, Tiresias (Gu
et al., 2019) is a scheduler based on the Gittins index
policy to minimize the average job completion time
of the whole system.
Finally, there is growing interest to explore GPU
sharing technique for DL jobs. Spatial GPU shar-
ing can suffer from unpredictable performance inter-
ference and resource contention. So, temporal GPU
sharing is more commonly adapted in practice. But
temporal sharing can be limited by the GPU mem-
ory size, and context switch overhead. Salus (Yu
and Chowdhury, 2019) takes advantage of the highly
predictable and largely temporal usage memory pat-
tern to provide a fine-grained sharing mechanism by
switching jobs at the lowest memory usage point.
Antman (Xiao et al., 2020) further modifies the execu-
tion and scheduling engine of deep learn frameworks
to support switching at the unit of operators (GPU
kernels).
7 CONCLUSIONS
Deep learning workflow has become one of the pri-
mary workloads in data centers and GPU clusters. In
this paper, we aim to optimize the application perfor-
mance and system utilization through a set of runtime
dynamic resource management techniques. We use
GPU sharing to increase the resource utilization of
non-GPU bounded modeling jobs, use performance-
driven auto-scaling to guarantee the SLA requirement
of inference jobs, and use workload-aware schedul-
ing and preemption to improve training job efficiency
and avoid idle GPUs. While all these techniques have
been discussed and used for different kinds of com-
puting workload, we are one of the few work that
really integrate and apply them together specifically
for the ML pipeline workflow. Our system are built
as extended operators on Kubernetes, and transpar-
ent to applications. Hence, our solution can be eas-
ily applied to general GPU clusters and DL workload.
While this work mainly aims to demonstrate the ben-
efit and importance of dynamic resource management
to ML workload, we plan to evaluate our system with
more complex and real ML pipeline workload to fur-
ther study and design more sophisticate algorithms for
each of optimization techniques in the future.
REFERENCES
Amaral, M., Polo, J., Carrera, D., Seelam, S., and Steinder,
M. (2017). Topology-aware gpu scheduling for learn-
ing workloads in cloud environments. In Proceedings
of the International Conference for High Performance
Computing, Networking, Storage and Analysis, pages
1–12.
Amodei, D. and Hernandez, D. (2018). Ai and compute.
https://openai.com/blog/ai-and-compute/.
Devlin, J., Chang, M., Lee, K., and Toutanova, K. (2018).
BERT: pre-training of deep bidirectional transformers
for language understanding. CoRR, abs/1810.04805.
Ghodsi, A., Zaharia, M., Hindman, B., Konwinski, A.,
Shenker, S., and Stoica, I. (2011). Dominant resource
fairness: Fair allocation of multiple resource types. In
NSDI, page 323–336.
Gu, J., Chowdhury, M., Shin, K. G., Zhu, Y., Jeon, M.,
Qian, J., Liu, H., and Guo, C. (2019). Tiresias: A
GPU cluster manager for distributed deep learning. In
NSDI, pages 485–500.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
DynamoML: Dynamic Resource Management Operators for Machine Learning Workloads
131

ual learning for image recognition. In 2016 IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 770–778.
He, X., Pan, J., Jin, O., Xu, T., Liu, B., Xu, T., Shi, Y.,
Atallah, A., Herbrich, R., Bowers, S., and Candela, J.
Q. n. (2014). Practical lessons from predicting clicks
on ads at facebook. In Proceedings of the Eighth In-
ternational Workshop on Data Mining for Online Ad-
vertising, page 1–9.
Jalaparti, V., Bodik, P., Menache, I., Rao, S., Makarychev,
K., and Caesar, M. (2015). Network-aware scheduling
for data-parallel jobs: Plan when you can. In Proceed-
ings of the 2015 ACM Conference on Special Interest
Group on Data Communication, page 407–420.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2017). Im-
agenet classification with deep convolutional neural
networks. Commun. ACM, 60(6):84–90.
Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P.,
and Soricut, R. (2019). ALBERT: A lite BERT for
self-supervised learning of language representations.
CoRR, abs/1909.11942.
Levine, S., Pastor, P., Krizhevsky, A., and Quillen, D.
(2016). Learning hand-eye coordination for robotic
grasping with deep learning and large-scale data col-
lection. CoRR, abs/1603.02199.
Lin, C.-Y., Yeh, T.-A., and Chou, J. (2019). DRAGON: A
dynamic scheduling and scaling controller for manag-
ing distributed deep learning jobs in kubernetes clus-
ter. In International Conference on Cloud Computing
and Services Science (CLOSER), pages 569–577.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D.,
Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov,
V. (2019). Roberta: A robustly optimized BERT pre-
training approach. CoRR, abs/1907.11692.
Peng, Y., Bao, Y., Chen, Y., Wu, C., and Guo, C. (2018).
Optimus: An efficient dynamic resource scheduler for
deep learning clusters. In EuroSys, pages 1–14.
Peng, Y., Bao, Y., Chen, Y., Wu, C., Meng, C., and Lin, W.
(2021). DL2: A deep learning-driven scheduler for
deep learning clusters. IEEE Transactions on Parallel
Distributed Systems, 32(08):1947–1960.
Redmon, J., Divvala, S. K., Girshick, R. B., and Farhadi, A.
(2015). You only look once: Unified, real-time object
detection. CoRR, abs/1506.02640.
Tannenbaum, T., Wright, D., Miller, K., and Livny, M.
(2001). Condor – a distributed job scheduler.
Tian, Y., Pei, K., Jana, S., and Ray, B. (2017). Deeptest:
Automated testing of deep-neural-network-driven au-
tonomous cars. CoRR, abs/1708.08559.
Tumanov, A., Zhu, T., Park, J. W., Kozuch, M. A., Harchol-
Balter, M., and Ganger, G. R. (2016). Tetrisched:
Global rescheduling with adaptive plan-ahead in dy-
namic heterogeneous clusters. In EuroSys, pages 1–
16.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L. u., and Polosukhin,
I. (2017). Attention is all you need. In Guyon,
I., Luxburg, U. V., Bengio, S., Wallach, H., Fer-
gus, R., Vishwanathan, S., and Garnett, R., editors,
Advances in Neural Information Processing Systems,
volume 30, pages 5998–6008. Curran Associates, Inc.
Vavilapalli, V. K., Murthy, A. C., Douglas, C., Agarwal, S.,
Konar, M., Evans, R., Graves, T., Lowe, J., Shah, H.,
Seth, S., Saha, B., Curino, C., O’Malley, O., Radia,
S., Reed, B., and Baldeschwieler, E. (2013). Apache
hadoop yarn: Yet another resource negotiator. In Pro-
ceedings of Symposium on Cloud Computing.
Verma, A., Pedrosa, L., Korupolu, M., Oppenheimer, D.,
Tune, E., and Wilkes, J. (2015). Large-scale cluster
management at google with borg. In EuroSys, pages
1–17.
Xiao, W., Bhardwaj, R., Ramjee, R., Sivathanu, M., Kwatra,
N., Han, Z., Patel, P., Peng, X., Zhao, H., Zhang, Q.,
Yang, F., and Zhou, L. (2018). Gandiva: Introspective
cluster scheduling for deep learning. In OSDI, pages
595–610.
Xiao, W., Ren, S., Li, Y., Zhang, Y., Hou, P., Li, Z., Feng,
Y., Lin, W., and Jia, Y. (2020). Antman: Dynamic
scaling on GPU clusters for deep learning. In OSDI,
pages 533–548.
Xu, D., Anguelov, D., and Jain, A. (2017). Pointfusion:
Deep sensor fusion for 3d bounding box estimation.
CoRR, abs/1711.10871.
Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov,
R. R., and Le, Q. V. (2019). Xlnet: Generalized
autoregressive pretraining for language understand-
ing. In Wallach, H., Larochelle, H., Beygelzimer,
A., d'Alch
´
e-Buc, F., Fox, E., and Garnett, R., editors,
Advances in Neural Information Processing Systems,
volume 32, pages 5753–5763. Curran Associates, Inc.
Yeh, T.-A., Chen, H.-H., and Chou, J. (2020). Kubeshare:
A framework to manage gpus as first-class and shared
resources in container cloud. In Proceedings of the
29th International Symposium on High-Performance
Parallel and Distributed Computing, page 173–184.
Yu, P. and Chowdhury, M. (2019). Salus: Fine-grained
GPU sharing primitives for deep learning applica-
tions. CoRR, abs/1902.04610.
Zoph, B., Cubuk, E. D., Ghiasi, G., Lin, T., Shlens, J., and
Le, Q. V. (2019). Learning data augmentation strate-
gies for object detection. CoRR, abs/1906.11172.
CLOSER 2021 - 11th International Conference on Cloud Computing and Services Science
132
