
High-speed Retrieval and Authenticity Judgment
using Unclonable Printed Code
Kazuaki Sugai, Kitahiro Kaneda and Keiichi Iwamura
Tokyo University of Science 6-3-1 Niijuku, Katusika-ku Tokyo, 125-8585, Japan
Keywords: Authenticity Judgment, Inkjet Print, Physically Unclonable Function, Feature Matching, Image Processing.
Abstract: The distribution of counterfeit products such as food packages, branded product tags, and drug labels, which
are easy to imitate, has become a serious economic and safety problem. To address this problem, we propose
a method to judge counterfeit products from commonly used inkjet-printed codes. To judge authenticity,
copies of printed matter of an inkjet printer are used as they are difficult to duplicate. In this study, we propose
a new authenticity judgment system that combines the locally likely arrangement hashing (LLAH) system,
which performs high-speed image retrieval, and Accelerated-KAZE (A-KAZE), which matches the features
of inkjet-printed matter with high accuracy to verify accuracy.
1 INTRODUCTION
In recent years, information and manufacturing
technologies have been advancing at an extremely
fast pace. While this has increased convenience in
daily life, determining the authenticity of information
and distinguishing between genuine and counterfeit
products have become increasingly difficult due to its
elaborate production. According to OECD/EIPO
(2019) survey the amount of counterfeit and pirated
goods traded worldwide trade is approaching $500
billion, which is equivalent to approximately 2.5% of
the world's total trade. Counterfeit goods range from
branded goods and airline boarding passes to
pharmaceuticals and food products. According to
WHO (2010) report a wide range of counterfeit
products, with the increased Internet penetration rate,
provide a dizzying array of both branded and generic
drugs. In more than 50% of cases, medicines
purchased online from illegal sites that conceal their
physical address were found to be counterfeit; many
of these products are labeled and packaged to look
genuine, making it difficult to distinguish between
counterfeit and genuine products at a glance. In
addition, counterfeit medicines have a tremendous
impact on society, not only in terms of economic
damage but also as a threat to the health and safety of
consumers, infringement of intellectual property
rights and trademark rights, and as a source of income
for illegal organizations.
In the field of security printing, holograms (Lim
et al., 2019) and security inks (Song et al., 2016) are
used, and artifact metrics using transmitted light
images (Matsumoto et al., 2000, Matsumoto et al.,
2004) have been used in Japan for some time.
Other methods have been proposed, such as the
use of unique random patterns created by
imperfections on the surface of objects, such as paper
plant fibers or industrial products (Yamakoshi et al.,
2007, Ito et al., 2004, Ito et al., 2018 and Fuji Xerox
Co., 2018), or the use of double-encoded codes, in
which the black cells of a barcode are encoded with
both normal and special black ink (Pacific Printing
Co., 2018).
In terms of productivity and cost, we think that the
inkjet printing method is best suited to the trend of
small-lot, multi-variety printing in the printing
industry, where the life cycle of products on the
market is short, consumer needs are diversified, and
high added value is sought. This research is focused
on the fact that the method is optimal in terms of
productivity and cost, and that it is possible to print
on various media such as film, cloth, plastic, and
wood, which is not possible with the
electrophotographic method.
This research aims to construct a system that
enables producers and consumers to judge product
authenticity by cross-verifying the printed codes on
labels and tags at the time of manufacture production
and delivery.
Sugai, K., Kaneda, K. and Iwamura, K.
High-speed Retrieval and Authenticity Judgment using Unclonable Printed Code.
DOI: 10.5220/0010542100570064
In Proceedings of the 18th International Conference on Signal Processing and Multimedia Applications (SIGMAP 2021), pages 57-64
ISBN: 978-989-758-525-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
57

Under a microscale, ink grains can be observed on
inkjet printouts. The shapes and positions of these
grains are slightly different for each print, and the
combination of these grains can be regarded as their
unique feature. Herein, we developed a system to
embed ink grains in a part of a printed code, which
can be enlarged and captured and verified that its
features (shape and position of the ink grains) are
registered in a database. The code can be
authenticated via highly discriminative color
matching.
Herein, we propose such a system by combining
Locally likely arrangement hashing (LLAH), a high-
speed image retrieval system that utilizes ink
variation in inkjet printing, and Accelerated-KAZE
(A-KAZE), which realizes the feature matching of
inkjet-printed materials.
2 PHYSICALLY UNCLONABLE
FUNCTION OF
INKJET-PRINTED CODES
The shape and positional relationship of the ink on the
paper can be a unique feature of materials printed by
an inkjet printer that can't be observed by laser
printer. The following factors can cause differences
in the shapes and positions of the ink.
1. Slight airflow on the paper surface
2. The direction in which the header moves when the
ink is fired
3. Air resistance of the ink in flight
4. Differences in the fiber quality of the adherend.
These properties can be used for authenticity
determination, as the uniqueness of these object
fingerprints (Physically unclonable function
properties), which each print possesses, makes it
difficult to reproduce maliciously. These properties
are independent of the printer type and apply to all
printers.
In this study, QR codes, typically used for airline
tickets and pharmaceutical labels, are used as an
embedding medium to obtain characteristics unique
to inkjet printing. Specifically, a single color
(grayscale information) with a density of 200 (Max
255), as shown in Figure 1, is embedded in the white
area in the upper left corner of the QR code to an
extent that it does not interfere with its use, and then
printed.
Figure 1: Embedded grayscale (density 200) (Max 255) and
QR code after embedding.
As an example, Figure 2 shows enlarged images
of three QR codes printed where the upper left white
area of each QR code was embedded with a single
color. But the same URL can be read from each QR
code.
Figure 2: QR codes and an enlarged photo of the upper left
corner.
The figure shows that, for the printed QR codes
with embedded grayscale information, the shape and
position of the printed ink differ greatly, and the same
ink arrangement can be difficult to reproduce exactly
on a microscopic level. Therefore, the characteristics
of printed material can be treated as features for
authenticity determination. And this study has shown
that these features are not lost after three years of
storage.
3 METHOD OF HIGH-SPEED
RETRIEVAL AND
AUTHENTICITY JUDGMENT
ALGORITHM
3.1 Overview of the System
The outline of the proposed system is shown in Figure
3, which can be classified primarily into the following
processes.
1. Capturing the QR code and saving the image
2. Image preprocessing for LLAH
3. Fast retrieval by LLAH
4. Authenticity judgment by feature matching using
A-KAZE
SIGMAP 2021 - 18th International Conference on Signal Processing and Multimedia Applications
58

Figure 3: Outline of the proposed new system for determining authenticity.
Figure 4: The capturing environment used and the actual
capturing scene. Left: The phone and microlens used.
Right: The image capture set up.
3.2 Image Preprocessing
We applied image preprocessing to extract feature
points for the LLAH system using the captured
images. The following procedure was used to
preprocess the image and produce a binary image in
which the ink hues were extracted from the grayscale
part by dividing it into three colors: cyan, magenta,
and yellow. Each color was extracted by setting a
range in the Hue, Saturation, Value (HSV) color
system. Which is calculated by using OpenCV3.30
library with threshold value.
1. Hue
Cyan: 90 to 150,
Magenda: 150 to180,
Yellow: 20 to 40
2. Saturation All: 90 to 255
3. Value All: 120 to 255
Figure 5 shows the cropped image immediately after
capturing and the ink colors extracted. (Colors are
added for clarity).
Figure 5: Comparison before and after preprocessing.
The process for image preprocessing is as follows.
1. Cropping of the input image to 100 × 100 pixels
along the right and bottom edges.
2. Shrinkage processing.
3. Detect the outline of the QR code and the
boundary line between black and white.
4. Determine the angle of the above boundary line
and correct the angle of the captured QR code.
5. The origin of the boundary line is calculated using
a new algorithm that adds assistance to the
approximation.
6. Crop the image further to the size of 700 × 500
pixels.
7. Adjust contrast.
8. Extract the three ink hues.
9. Grayscale conversion.
10. Adaptive Binarization.
11. Smoothing by Gaussian filter.
12. Re-binarization.
13. Invert bits to create an image for input into LLAH.
14. Shrink the image again to remove the noise.
3.3 Fast Retrieval by LLAH
The feature matching system A-KAZE was
introduced into the proposed system to judge the
authenticity of printed matter. Even though the
system is very accurate in judging the authenticity of
inkjet-printed matter, it takes approximately 0.4 to 1.0
s for a one-to-one match. To match 100,000 images
with Only A-KAZE, the system would take
approximately 27 h, which is far from our goal within
10s ,so it is impractical for a real system. Therefore,
in the proposed system, we used a technique called
locally likely arrangement hashing (LLAH), which
was proposed by Nakai et al., 2006, Iwamura et al.,
2007, and Takeda et al., 2011, that can retrieve
matching images as quickly as 0.02 to 0.04 s
regardless of the number of images registered in the
database.
Previously, the LLAH technique was used for
document image retrieval. Document image retrieval
is a technique where images similar to the input image
are retrieved. For example, by taking a picture of a
LLAH
re
t
rieval
A-KAZE
ma
t
ching
Real
Fake
Feature point
extraction
&
Calculation of
features
High-speed Retrieval and Authenticity Judgment using Unclonable Printed Code
59
paper article with a digital camera and inputting it into
the retrieval system, the user can retrieve pre-
registered documents and their references. Web
services for this technique are also available.
LLAH does not use the image information as is
but a unique index value obtained from the image for
the registration and matching process, thus reducing
the data size and realizing high-speed and high-
performance retrieval.
3.3.1 LLAH Extraction of Feature Points
and Calculation of Feature Values
Since LLAH judges the match of images based on the
arrangement of feature points, the same feature points
must be extracted even in the case of projective
distortion, noise, or low resolution. Therefore, the
center of gravity is used as a feature point and
obtained from the ink portion of the binary image
generated during preprocessing.
The positions of the obtained feature points are
indicated by coordinate information. These positions
will change with the angle during capturing changes.
To obtain the same feature values even in such a
situation, the feature values are not calculated from a
single feature point but calculated based on the
positional relationship between feature points. In
addition, since the images captured by the camera are
subject to projection transformation, we used affine
invariants as the feature values, which was proposed
by Nakai et al., 2006, and which are robust to changes
in the position of the feature points as geometric
invariants robust to such changes. Figure 6 is shown
to explain affine invariants.
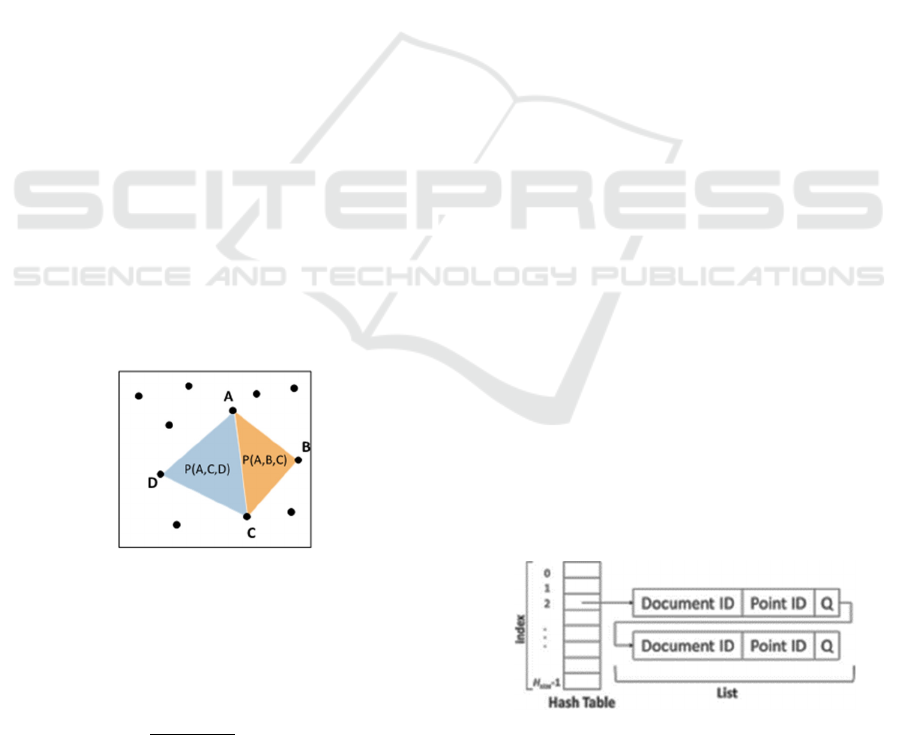
Figure 6: Calculation of affine invariants.
When there are four points A, B, C, and D on the
same plane as shown in the above figure, the affine
invariant for point A is calculated by the following
equation:
𝑃
𝐴
,𝐶,𝐷
𝑃
𝐴
,𝐵,𝐶
(1)
where P (A, B, C) is the area of the triangle formed
by the three points A, B, and C. This feature is
calculated and discrete-valued from the nearest point
to a point. When obtaining m points in the vicinity of
a certain point, it is simplest to set m = 4; however, if
this is the only method used, the same feature value
may be calculated for features in different images and
result in an incorrect match. Therefore, to further
improve the discriminability, we can set m ≥ 4, find
all combinations of four points out of m points, and
use the sequence of discretized values of affine
invariants computed from the combinations as feature
values. In this study, we set m = 6. Each sequence was
uniquely determined by moving in a clockwise
direction.
3.3.2 Registration with the Database
When registration the extracted features in the
database, we obtained the index, H
index
, and
quotient, Q, from the extracted features so that they
can be uniquely retrieved using the following
equation:
𝑟
𝑖
𝑚
𝐶
4
1
𝑖0
𝑑
𝑖
𝑄𝐻
𝑠𝑖𝑧𝑒
𝐻
𝑖𝑛𝑑𝑒𝑥
(2)
where r_(i) is the discrete value of the i-th affine
invariant, d^i is the number of discrete value levels,
and H
size
is the size of the hash table. In this study, we
set d = 10 and H
size
= 1086. In other words, in two
matching images, the same index, H
index,
and quotient
Q can be obtained from the same feature vector.
Therefore, during retrieval, for features with the same
H
index
(when collisions occur at the same index),
quotient Q is used for comparison instead of the
feature values. Therefore, as shown in Figure 7, the
image ID, feature point ID, and quotient Q are
registered in the database. The image ID and feature
point ID are the image and feature point identification
numbers, respectively. When a collision occurs in the
index, a list is added.
Figure 7: Configuration of the database (Takeda et al.,
2006).
SIGMAP 2021 - 18th International Conference on Signal Processing and Multimedia Applications
60

Figure 8: Comparison of registered data with collation data (right) and fake data (left).
3.3.3 Retrieval from Database
Matching is performed by voting on registered
images using a voting table. First, as in the
registration process, the index of the database is
calculated for each feature point, and the obtained
index is used to refer to the list shown in Figure 7. For
each item in the list, we checked if the quotient
matches, and if it does, we increment the image ID
item in the voting table. Finally, the results were
sorted by the number of increments, and the images
were outputted as the retrieved results.
3.3.4 Need for Additional Feature Matching
By setting a threshold value at the "Retrieval from
database" stage in the LLAH system introduced in
Section 3.3, the system can determine the authenticity
of collation and fake data. However, since the LLAH
system uses binary black and white images for
matching, a high threshold value is required to reject
all fake data when the dataset is large. Therefore, we
proposed combining color matching with LLAH to
make a more powerful system for judging
authenticity, instead of using LLAH alone.
3.4 Judgment of Authenticity by
A-KAZE
To solve the above problem, we introduced A-KAZE
matching, which can perform highly discriminative
verification using color images, while LLAH, which
can independently determine authenticity, is used for
verification from the database without setting a
threshold.
A-KAZE was introduced (Tareen et al., 2018,
Chien et al., 2016) as a feature matching method that
has high robustness, similar to SIFT and SURF, and
is good at extracting feature points on a plane;
therefore, is resistant to rotation and illumination
changes. Figure 8 shows the results of the A-KAZE
matching. Figure 8 (right) shows the comparison of
registered data collation data using A-KAZE, and
Figure 8 (left) shows the comparison of registered and
fake data. As can be seen, more than 200 features
were matched to the collation data, whereas none
were matched to the fake data. In addition, the
maximum number of matches for the fake data was
only four points, and the genuine data matches were
over 50 times higher.
However, although the feature matching A-KAZE
is very accurate for inkjet-printed materials, as
mentioned earlier, it takes approximately 0.4 to 1.0 s
for one-to-one matching, and when applied to an
assumed scale of 100,000 sheets, it takes
approximately 27 h per sheet. This is not practical for
real systems. Therefore, in this system, we will
continue to use the LLAH system, which is capable
of high-speed retrieval. So, we can accurately judge
authenticity within 10s, which is our target time and
does not burden the user. In the proposed system in
this research, the feature matching of A-KAZE is
introduced as follows: For each image divided into
three colors (cyan, magenta, and yellow), the top
three candidates for each color are retrieved using
LLAH, and a total of nine candidates (three colors ×
three candidates) are selected. We then perform A-
KAZE matching on each of the three candidates per
color to obtain a highly accurate judgment of
authenticity.
4 VERIFICATION
4.1 Verification Outline
In this study, we printed 2,000 QR codes for
verification. The images were taken in an
environment using a smartphone as described in "3.2
QR Codes Capturing." The captured images were
categorized as follows:
1. Registration data: data taken for registration of
1000 QR codes.
2. Collation data: The same 1000 QR codes were re-
captured and used to match with the registration
images.
3. Fake data: data taken from the second 1000 QR
codes without registration.
A total of 3000 images were collected in this manner.
To show that the method does not depend on the
environment in which the images are taken, the ima-
High-speed Retrieval and Authenticity Judgment using Unclonable Printed Code
61

ges were taken on different days.
To verify the accuracy of the judgment of
authenticity, we changed the size of the datasets
registered in the database. Specifically, verifications
were conducted in four dataset sizes: 20, 100, 400,
and 1000 registered, collation, and fake data.
Furthermore, the effectiveness of the proposed
method combined with A-KAZE matching was
verified by comparing the results achieved using only
the LLAH system with those using LLAH with A-
KAZE and to compare with other feature detectors, a
comparison with ORB is also shown to demonstrate
the superiority of A-KAZE.
4.2 Equipment
The following list shows the instruments used for the
verification
1. Printer:
IP8730 (print resolution 9600dpi) by Canon
Japan
2. Smartphone:
iPhone XR (camera resolution 12 million pixels)
by Apple America
3. Microlens:
i micron pro (maximum magnification 800x) by
Qing Ting E&T LLC Japan
4. Computer:
Magnate IM (Intel Core i5-9400 @ 2.90GHz,
16GB RAM) by THIRDWAVE Japan
5 RESULTS
5.1 Verification Results
Table 1 shows the results of the verification of
authenticity for each dataset size. The upper part
shows the results of the verification of the
authenticity using only the LLAH system, LLAH
with ORB and the lower part shows the results of the
proposed authenticity determination system
combined with A-KAZE.
Table 1 shows that the correctness rate for the
collation data was very high, exceeding 98%, for all
dataset sizes. In addition, the proposed system is
sufficiently accurate to be used in the real world.
Furthermore, a comparison of the accuracy of the
proposed system with that of the LLAH system alone
showed that the accuracy of the proposed system was
over 95% for small datasets of up to 400 images.
However, when A-KAZE was included, the accuracy
was further improved for the small dataset of up to
400 images, and it was confirmed that the accuracy
did not decrease and remained high even when the
number of images were increased to 1,000, which was
a point of concern.
The high accuracy can be attributed to the LLAH
being used only for the retrieval function without a
threshold value, which is a key feature of the new
method. This allowed data to be considered positive,
where previously it would have been excluded
because the threshold value was not reached when
judged by LLAH alone.
Furthermore, the accuracy of the A-KAZE
matching system was confirmed to be 100% for
candidates of the collation and fake data, given as
arguments. On the other hand, compare with the
accuracy of LLAH with ORB, one of the feature
detectors for corner, can be seen that there is almost
no improvement in accuracy, and instead the
accuracy decreases.
In summary, the results confirm that A-KAZE is
a suitable feature matching system for the authenticity
determination of the inkjet-printed matter.
As for the average processing time, the following
breakdown was obtained for 1000 registered images.
LLAH (retrieval function): 0.25 s.
A-KAZE (authenticity judgment function): 8.42 s
Total: 8.67 s
Therefore, this system enables fast retrieval of images
by LLAH and judge for high accuracy authenticity by
A-KAZE within 10seconds, which is the target time
and fast enough for practical use. In the case of ORB,
the speed is 0.89s, which is very fast and slow
compared to that, but this is the target time and is fast
enough for practical use.
In addition, the storage usage of the system with
1000 registered images was as follows:
LLAH (retrieval function): 87 MB
A-KAZE (authenticity judgment function): 492 MB
Total: 579 MB
This breakdown shows that the database for A-KAZE
matching is approximately 6.6 times that used for
LLAH alone because it uses color images as they are.
Therefore, in real-world applications, the color
images for A-KAZE should be stored on a server in
the cloud rather than the user terminal, and responses
should be sent in response to requests.
5.2 Discussion
From the results of the verification described in
Section 5.1, we verified that if the correct candidate
is passed to A-KAZE as an argument, the system can
determine the authenticity with 100% accuracy.
SIGMAP 2021 - 18th International Conference on Signal Processing and Multimedia Applications
62

Table 1: Judgment results for each dataset size of the authenticity judgment system (Numbers in red show where the accuracy
of the proposed method was better than LLAH only and LLAH with ORB).
Therefore, observed that the accuracy of LLAH is
directly related to the correctness of the judgment.
Table 2 summarizes the results of the first, second,
and third candidate retrievals for cyan, magenta, and
yellow for a total of three sets of 1000 images of
registration data.
Table 2: Retrieval accuracy by color (1000 registered data).
The table shows that the result for the three sets
combined is 98.6%, which is very high, but the result
for the authenticity judgment of each color is between
85% and 90%, which means that there is room for
improvement. This is because when extracting the
inks in the image preprocessing stage, the specular
reflection of the flash during capturing prevents
accurate extraction of some colors, resulting in
misalignment of the center of gravity and different
feature values, leading to matches with more images.
Figure 9 shows three examples, one of which was
retrieved correctly, whereas the other two failed.
Figure 9: Comparison of successful and unsuccessful
images for determining authenticity.
The correctly retrieved image (left) is clear, but
the failed images have problems, such as red due to
the flash of the smartphone (center) and blue (right).
For the practical use of the system, numerical analysis
and verification of the images must be analyzed and
verified before image preprocessing. This will
prevent registration and judgment of authenticity on
images where it is difficult to extract ink colors,
obtain the center of gravity, and calculate feature
values.
High-speed Retrieval and Authenticity Judgment using Unclonable Printed Code
63

6 CONCLUSIONS
In this study, we proposed a high-speed and high-
accuracy authentication system by combining LLAH,
which can perform high-speed image retrieval, and
A-KAZE, which can perform high-accuracy feature
matching for inkjet-printed matter.
Our evaluation verification using a large dataset
of 1,000 images showed a correct judgment rate for
collation data exceeding 98%, and a positive
judgment rate of 100% for fake data within 10s,
which is exceptional even considering its use in the
real world.
As mentioned in the Discussion section, there is
still room for further improvement in accuracy of the
retrieval system. Further, the image preprocessing
needs to be enhanced to improve the accuracy of the
entire system.
In addition, we consider the introduction of a
verification step before the preprocessing stage to
detect images that are unsuitable for registration and
authenticity judgments (Figure 9) by getting the
average hue of the image. and to prompt the user to
re-capture the image.
REFERENCES
OECD/EIPO. (2019). Trends in trade in counterfeit and
pirated goods, Illicit Trade. OECD Publishing Paris
[PDF file], Retrieved from https://www.oecd-
ilibrary.org/trade/trends-in-trade-in-counterfeit-and-
pirated-goods_g2g9f533-en. (accessed 2021-2-10)
The World Health Organization (WHO). (2010). Growing
threat from counterfeit medicines. Bulletin of the World
Health Organization, Vol. 88, (4), April 2010, pp.247-
248.
Lim, K.T.P., Liu, H., Liu Y., and Yang J.K.W. (2019).
Holographic color prints for enhanced optical security
by combined phase and amplitude control. Nature
communications, Vol. 10, (25).
Song, Z., Lin, T., Lin, L., Lin, S., Fu, F., Wang, X., and Guo,
L. (2016). Invisible Security Ink Based on Water-
Soluble Graphitic Carbon Nitride Quantum Dots.
Angewandte chemie, Vol. 128, (8), pp.2823-2827.
Matsumoto, H., Matsumoto, T. (2000). Artifact-metric
Systems. Technical Report of IEICE, ISEC 2000-59,
pp.7-14.
Matsumoto, T., Iwashita, N. (2004). Financial Operations
and Artifact Metrics. Financial Studies, Vol. 23, (2), pp.
153-168. (in Japanese)
Yamakoshi, M., Tanaka, J., Furuya, M., Hirabayashi, M.,
Matsumoto, T. (2012). Individuality Evaluation for
Paper Based Artifact-Metrics Using Infrared
Transmitted Light Image. JAPAN TAPPI JOURNAL,
Vol. 66, (4), pp.419-425.
Ito, K., Shimiz.u, T., Sugino, T. (2004). Paper Identification
and Matching Device and Method. Japanese Patent
Publication 2004-102562.
Ito, K., Hayashi, E. (2018). Technology for the Recognition
of Unique Objects: Yoctrace®. Fuji Xerox Technical
Report 2018, (27), pp.79-85. (in Japanese)
Fuji Xerox Co.,Ltd (2018). Technology for the Recognition
of Unique Objects: Yoctrace®.
https://www.fujixerox.com/eng/company/technology/c
ommunication/annotation/yoctrace.html (accessed
2021-2-19)
Pacific Printing Co.,Ltd. (2018). Fake Code Buster: A
Proposed Solution for Determining Authenticity.
http://www.busi-tem.jp/code/code.html/. (accessed
2021-2-19) (in Japanese)
Nakai, T., Kise, K., and Iwamura, M. (2006). Use of Affine
Invariants in Locally Likely Arrangement Hashing for
Camera-Based Document Image Retrieval. Document
Analysis Systems, Vol. 7, pp541-552.
Takeda, K., Kise, and Iwamura, M. (2007). Improvement
of Retrieval Speed and Required Amount of Memory
for Geometric Hashing by Combining Local Invariants
In proc. BMVC’07.
Iwamura, M., Nakai, T., Kise, K. (2011). Real-Time
Document Image Retrieval for a 10 Million Pages
Database with a Memory Efficient and Stability
Improved LLAH. International Conference on
Document Analysis and Recognition 2011.
Tareen, S.A.K., Saleem, Z. (2018). A Comparative
Analysis of SIFT, SURF, KAZE, ORB, and BRISK.
International Conference on Computing, Mathematics
and Engineering Technologies 2018
Chien, H.J., Chuang, C.C., Chen, C.Y., and Klette, R.,
(2016). When to Use What Feature SIFT, SURF, ORB,
or A-KAZE Features for Monocular Visual Odometry,
International Conference on Image and Vision
Computing New Zealand 2016
SIGMAP 2021 - 18th International Conference on Signal Processing and Multimedia Applications
64
