
Database Recovery from Malicious Transactions: A Use of Provenance
Information
Theppatorn Rhujittawiwat
1
, John Ravan
1
, Ahmed Saaudi
1
, Shankar Banik
2
and Csilla Farkas
1
1
Computer Science & Engineering Dept., University of South Carolina, Columbia, SC, U.S.A.
2
Dept. of Mathematics and Computer Science, The Citadel, The Military College of South Carolina, Charleston, SC, U.S.A.
Keywords:
Database, Malicious Transaction, Security, Dependency Graph, Data Provenance.
Abstract:
In this paper, we propose a solution to recover a database from the effects of malicious transactions. The
traditional approach for recovery is to execute all non-malicious transactions from a consistent rollback point.
However, this approach is inefficient. First, the database will be unavailable until the restoration is finished.
Second, all non-malicious transactions that committed after the rollback state need to be re-executed. The
intuition for our approach is to re-execute partial transactions, i.e., only the operations that were affected by
the malicious transactions. We develop algorithms to reduce the downtime of the database during recovery
process. We show that our solution is 1.) Complete, i.e., all the effects of the malicious transactions are
removed, 2.) Sound, i.e., all the effects of non-malicious transactions are preserved, and 3.) Minimal, i.e.,
only affected data items are modified. We also show that our algorithms preserve conflict serializability of the
transaction execution history.
1 INTRODUCTION
The increase in the number and sophistication of cy-
berattacks makes cybersecurity one of the top prior-
ities for organizations. One of the recent studies to
evaluate the impact of cyberattacks was performed
by the Ponemon Institue (Bissell et al., 2019). They
studied over 355 companies to evaluate the damages
incurred from cybercrime. Their results show that,
on average, each company lost $11.7 million in 2017
and $13.0 million in 2018. Part of this damage comes
from the hourly cost of service downtime.
Malicious transactions further escalate the cost of
recovery. Such transactions are often detected at a
later time, after malicious transaction as well as other
transactions dependent of the malicious one are com-
mitted. Efficient recovery methods are needed to re-
duce the cost of service downtime and recovery work.
Traditional recovery methods are based on the re-
execution of all non-malicious transactions from a
consistent backup point. However, this causes the
database to be unavailable until the restoration is com-
pleted. Moreover, transactions that were not affected
may also be re-executed.
To improve recovery speed, researchers aim to re-
duce the number of transactions that need to be re-
executed. Transactions that were affected by the ma-
licious transactions are identified by transaction de-
pendency and input comparison. The approaches pre-
sented by Ammann et al. (Ammann et al., 2002),
Liu et al. (P. Liu, P. Ammann, and S. Jajodia, 2000),
Panda et al. (Panda and Haque, 2002) have used trans-
action dependency to identify compromised transac-
tions. The works of Kim et al. (Kim et al., 2012),
and Chandra et al. (Chandra et al., 2011) have used
input comparison to determine unaffected transac-
tions. Input comparison approaches provide simpler
and faster solutions than the dependency approaches.
However, transaction dependency approaches provide
greater details about which transactions are affected
and a higher possibility to salvage good transactions
than the input comparison approaches. Therefore,
there is a possibility that the dependency-based ap-
proaches may provide better overall performance than
input comparison-based approaches when it can sal-
vage many good transactions. In this case, the re-
duced re-execution cost outweighs the slower deter-
mination process.
Our work fits into the category of transaction
dependency-based recovery. We propose a novel ap-
proach to use data provenance to reduce the computa-
tional cost of recovery. We define transaction depen-
dency based on an attribute-value assignment. Our
work closely relates to the work of Panda et al. (Panda
Rhujittawiwat, T., Ravan, J., Saaudi, A., Banik, S. and Farkas, C.
Database Recovery from Malicious Transactions: A Use of Provenance Information.
DOI: 10.5220/0010553900390048
In Proceedings of the 10th International Conference on Data Science, Technology and Applications (DATA 2021), pages 39-48
ISBN: 978-989-758-521-0
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
39

and Haque, 2002). However, their work focuses on
the identification of the affected transactions. Their
solution requires the shutdown of the database during
the recovery process. Our work reduces the duration
of the database downtime and lets the unaffected part
of the database operate during the recovery process.
Our method uses transaction dependency to deter-
mine which transactions have to be re-executed and
which attributes have to be updated. We use data
provenance to collect crucial information for the re-
covery process. Instead of the complete shutdown
of the database, we only lock the database until the
corrupted data items are identified. The unaffected
part of the database will become active and perform
the service after the identification is finished. The af-
fected parts of the database will be available as soon
as the data items are recovered. Our solution will im-
prove the availability of the database during recovery
and reduce the downtime from malicious transaction
attacks.
We show that our solution is 1.) Complete, i.e., all
the effects of the malicious transactions are removed,
2.) Sound, i.e., all the effects of non-malicious trans-
actions are preserved, and 3.) Minimal, i.e., only af-
fected data items are modified. We also show that our
algorithms preserve conflict serializability of the con-
current transaction execution.
The paper is organized as follows: Section 2 dis-
cusses the existing research used to drive the direction
of the solution. Section 3 defines the problem and out-
lines the system model. Section 4 describes solution,
we present our algorithms and provide formal proofs.
We conclude in Section 5.
2 RELATED WORK
Many researchers proposed approaches to improve
the process to recover from malicious transactions.
There are two major approaches to identify affected
transactions and reduce re-execution cost: transaction
dependency-based approach, and input comparison-
based approach.
The works of Kim et al. (Kim et al., 2010)(Kim
et al., 2012) and Chandra et al. (Chandra
et al., 2011)(Chandra et al., 2013) introduce input
comparison-based approaches. In their approaches,
if the current input of re-executing transaction is the
same as the input when this transaction is originally
executed, this re-execution will be skipped because
the output will obviously be the same. These meth-
ods can be processed easily from reading the trans-
action log, which records the inputs. They also do
not require extra memory and computational power
to build a complicated dependency structure between
transactions. However, these approaches cannot save
the re-execution cost of transactions which have dif-
ferent inputs but produce the same outputs. For ex-
ample, a transaction that blindly updates values inde-
pendently from its inputs. These approaches provide
a fast and simple solution with less possibility to save
re-execution cost.
There are several transaction dependency-based
approaches. The works of Ammann et al. (Ammann
et al., 2002) and Liu et al. (P. Liu, P. Ammann, and S.
Jajodia, 2000)(Liu and Jajodia, 2001) define the trans-
action by using the read and write sets of transactions.
A transaction T
j
depends on another earlier transac-
tion T
i
if the read set of T
j
shares the same data item
as a write set of T
i
and this data item is not presented
in write sets of any transaction committed between
them. The corresponding dependency graph can be
used to identify transactions that are affected by ma-
licious transactions. The later work of Chakraborty et
al. (A. Chakraborty, A. K. Majumdar, and S. Sural,
2010) follows the same direction but uses different
granularity. The dependency is defined on columns
instead of data items to improve scalability. However,
this approach saves fewer unaffected transactions than
the previous approaches.
Our work closely relates to the works of Panda et
al. (Panda and Giordano, 1998)(Panda and Haque,
2002)(Panda and Jing Zhou, 2003), Lomet et al.
(Lomet et al., 2006), Haraty et al. (Haraty and Zbib,
2014)(Haraty et al., 2016)(Haraty et al., 2018), and
Kaddoura et al. (Kaddoura et al., 2016). They de-
fine dependency based on how each data item is up-
dated. A transaction T
j
depends on another trans-
action T
i
if T
j
updates any data item according to
a data item lastly updated by T
i
. These approaches
provide greater details on how transactions depend
on each other than the read/write set dependency ap-
proaches. Thus, they provide the highest possibil-
ity to save unaffected transactions comparing all the
above approaches. However, the computational costs
are also the highest.
To improve the performance, we use the concept
of data provenance. Our solution reduces the recovery
cost by building data provenance that contains trans-
action dependency when each transaction is commit-
ted. This provides information to speed up the recov-
ery process. There are many data provenance works
which influenced our solution such as Xu and Wang
(Xu and Wang, 2010), Zhang et al. (Zhang et al.,
2012), Hammad and Wu (Hammad and Wu, 2014),
He et al. (He et al., 2015), Backes et al. (Backes et al.,
2016), and Liang et al. (Liang et al., 2017). They
provide different data provenance structures which
DATA 2021 - 10th International Conference on Data Science, Technology and Applications
40

record information to counter specific malicious at-
tacks.
3 PROBLEM SPECIFICATION
AND PRELIMINARIES
Malicious transactions can potentially be committed
before they are detected, thus propagating their dam-
age across the database. The problem of malicious
transaction recovery has two major parts: identifying
the scope of damage and repairing the damage. The
damage from a malicious transaction can spread to
other transactions. For example, if a malicious trans-
action T
i
updates the value of attribute A
1
, every trans-
action that uses this A
1
will be affected by T
i
and will
need to be corrected. Furthermore, if an affected non-
malicious transaction T
j
uses A
1
to update A
2
, then
A
2
will need to be corrected therefore spreading the
damage and the scope of the correction will be re-
duced. On the other hand, a transaction T
l
which does
not use A
1
can be indirectly affected if it uses A
2
from
T
j
.
Our goal is to reduce the cost of locating every af-
fected transaction, limit propagation of the corrupted
values, and reduce the recovery work.
Next, we present our recovery framework and cor-
responding definitions.
Definition 1. A relation schema R is denoted by
R(A
1
, ...,A
n
), where R is the name of the relation and
A
i
|i ∈ {1, ..., n} is an attribute name.
Definition 2. An attribute value pair is denoted by
(A, v), where v is the value of an attribute A such that
v is in the domain of attribute A, i.e., v ∈ Dom(A).
Definition 3. A relation instance r is denoted by r(R),
where R(A
1
, ..., A
n
) is the relation schema of r. r is
a set of tuples r = {t
1
, ..., t
m
}, where each tuple is a
set of n attribute value pair t = {(A
1
, v
1
), ..., (A
n
, v
n
)}
such that each value v
i
∈ Dom(A
i
). We also represent
a tuple as an order list of n values t =< v
1
, ..., v
n
>
such that each value v
i
∈ Dom(A
i
).
Definition 4. An attribute-value assignment is de-
noted by
t = {(A
1
, v
1
), .., (A
j
, v
j
), .., (A
n
, v
n
)}
−→ t
0
= {(A
1
, v
1
), .., (A
j
→ exp), .., (A
n
, v
n
)} (1)
for some attribute value pair of A
j
∈ R, (A
j
, v
j
)
will be set to (A
j
, exp) such that exp is either;
1. A constant value v
0
j
∈ Dom(A
j
).
2. An attribute A
k
∈ R with value v
k
, such that v
k
∈
Dom(A
k
).
3. An arithmetic expression which includes constant
values, attribute names in R, and/or arithmetic
operators.
Example 1: Transaction T
1
.
UPDATE r
SET
A
1
= 10 ,
A
2
= A
1
,
A
3
= 2A
1
+ 20 ;
Example 1 shows value assignments by transac-
tion T
1
on relation r with schema R(A
1
, A
2
, A
3
).
T
1
assigns the constant value 10 to attribute A
1
,
attribute A
2
is assigned the value of A
1
, and attribute
A
3
is assigned using an arithmetic expression.
Definition 5. An attribute-value conditional assign-
ment is denoted by
t{(A
1
, v
1
), .., (A
j
, v
j
), .., (A
n
, v
n
)}
−→ t
0
{(A
1
, v
1
), .., (A
j
→ exp, c), .., (A
n
, v
n
)} (2)
for some attribute value pair of A
j
∈ R, (A
j
, v
j
)
will be set to (A
j
, {exp, c}) when condition c is
satisfied. The boolean expression c may include truth
values, boolean variables, arithmetic expressions,
relational operators, and/or boolean operators.
The multiple attributes assignment
t{(A
1
, v
1
), .., (A
n
, v
n
)}
−→ t
0
{(A
1
, v
1
), .., (A
i
→ exp
i
, c
i
), ..., (A
j
→
exp
j
, c
j
), .., (A
n
, v
n
)} is interpreted as a sequence of
update to attributes A
i
, ..., A
j
Definition 6 (Data Dependency Pair). A data depen-
dency pair is denoted by
Dp
A
i
= (A
i
, {A
1
, ..., A
n
}) (3)
We also represent it as
Dp
A
i
= (A
i
, Set
A
i
) (4)
Where an attribute A
i
depends on a set of at-
tributes Set
A
i
= {A
1
, ..., A
n
} such that A
i
∈ R, i ∈
{1, ..., n}. The data dependency is transitive, i.e., if
(A
i
, A
j
) and (A
j
, A
k
) then (A
i
, A
k
).
For a transaction T, Dp
T
= {Dp
A
1
, ..., Dp
A
n
} denotes
all the dependency pairs Dp
A
1
, ..., Dp
A
n
where at-
tributes A
i
|i ∈ {1, ..., n} were modified by T.
Definition 7 (Last Assignment Table). A last assign-
ment table L has the schema
L(A, T ) (5)
Where A is the column with domain {A
1
, ..., A
n
} ∈ R
and T is the column for representing the last transac-
tion that updated attribute A
i
. The domain of T is the
identities of the transactions.
Database Recovery from Malicious Transactions: A Use of Provenance Information
41

Definition 8 (Transaction Dependency). Transaction
T
j
depends on transaction T
i
iff there is an attribute
A
j
that is modified by T
j
and A
j
depends on an at-
tribute A
i
that was updated by T
i
. The transaction
dependency is transitive. We also say that transaction
T
i
affects transaction T
j
if transaction T
j
depends on
transaction T
i
.
Definition 9. Data dependency record of provenance
for transaction T is denoted by
P
T
=< ID
T
,ts, R s,W s, Dp > (6)
Where ts is the timestamp when transaction T com-
mitted, ID
T
is the id of transaction T
i
, R s is a set of
read attributes, W s is a set of modified attributes, Dp
is the data dependency set of T.
Definition 10 (Conflict Transactions). Transaction T
1
and transaction T
2
are in conflict if at least one of the
following conditions is met:
1. R s
T
1
∩W s
T
2
is not ∅.
2. R s
T
2
∩W s
T
1
is not ∅.
3. W s
T
1
∩W s
T
2
is not ∅.
Operation Dependency Graph: Assuming a trans-
action can read and write each attribute only once, we
can recreate the partial order of the operation of T as
a directed acyclic graph (DAG) G
T
. For each record
T in P
T
:
1. For each attribute A
i
in R s, create a node r[A
i
].
2. For each attribute A
j
in W s, create a node w[A
j
]
and read Dp
A
j
in Dp.
3. Create a directed edge from each r[A
i
] where A
i
is
in Set
A
j
to w[A
j
].
4. If any subgraph G
0
T
has only one node with no
edge, create a directed edge from the node in G
0
T
to another node outside of G
0
T
that has no directed
edge pointing to it.
5. If any subgraph G
0
T
contains an edge but does not
contain any edge connect to any node outside of
G
0
T
, create a directed edge from any node that has
no directed edge pointing from it in G
0
T
to an-
other node outside of G
0
T
that has no directed edge
pointing to it.
The step 4 and 5 ensure that all subgraphs will be con-
nected together in the correct direction.
Notation 1. Given relation R with a single column.
S[R] denotes the set containing the attribute values of
relation R.
4 PROPOSED SOLUTION
In this section, we will present the algorithms that are
needed to properly recover from malicious transac-
tions. We also present the formal properties and the
complexity analysis of our solution.
4.1 Provenance-based Transaction
Recovery
In this section we present out recovery algorithms.
Algorithm 1 creates a data dependency record of
provenance for each transaction. Each record con-
tains transaction ID, timestamp, attributes which are
read or written by this transaction, and a set of
data dependency pairs. These records will be used
to find the minimal number of transactions and at-
tributes that have to be recovered.Algorithm 2 finds
the affected transactions and affected attributes. The
records generated by Algorithm 1 provide informa-
tion on how each attribute is updated. By scanning
through those records, all affected transactions and
affected attributes can be found. All affected transac-
tions will be added into a table containing their trans-
action ID and ID of transactions, which they depend
on. All affected attributes will be locked until they
are repaired. The last assignment table L is generated
so the system knows when affected attributes can be
unlocked. Once affected attributes are updated with
values from the re-execution of their last assignment
transactions, they will be unlocked.
Algorithm 3 repairs the damage. The affected
transaction table AT generated by Algorithm 2 pro-
vides information on which transactions have to be
re-executed. The re-execution will be processed on
a snapshot of the database. The unaffected part of
the database can be operated during this repair pro-
cess. The affected transactions will be re-executed
in a topological order based on transaction depen-
dency. The affected attributes will be unlocked once
the transactions that last updated them are commit-
ted. This provides availability of those attributes as
soon as possible.
4.2 Formal Properties and Complexity
Analysis
In this section, we analyze and formally prove the
properties of our solution. We also evaluate the com-
plexity of our approach and compare it with the cost
of traditional transaction recovery.
Theorem 1. Given a malicious transaction T
k
and a
transaction execution history, the output of Algorithm
DATA 2021 - 10th International Conference on Data Science, Technology and Applications
42

Algorithm 1: Create Data Dependency Provenance Record.
Input: Transaction, T
i
and data provenance table P
T
Output: Data dependency provenance record of T
i
as
P
T
i
=< ID
T
i
,ts, R s,W s, Dp >
1: Initialization
2: If data provenance table is not available, create an
empty table P
T
(ID, ts, R s,W s, Dp)
3: Let ts := ””, R s := {}, W s := {}, Dp := {}, ts
= timestamp when T
i
is committed, ID
T
i
= gener-
ated id based on transaction committed order
4:
5: for all attributes A
i
in T
i
do
6: if attribute A
i
is assigned by {exp, c} then
7: Set
A
i
= {}
8: Dp
A
i
= (A
i
, Set
A
i
)
9: W s = W s ∪ A
i
10: for all attributes A
j
in {exp, c} do
11: Dp
A
i
= (A
i
, {Set
A
i
∪ A
j
})
12: end for
13: Add Dp
A
i
to Dp
14: else
15: R s = R s ∪ A
i
16: end if
17: end for
18: Insert record (ID
T
i
,ts, R s,W s, Dp) into P
T
2 is 1.) Complete, 2.) Sound, and 3.) Minimal.
That is,
Completeness: All the transactions that were affected
by T
k
appear in column AT (T ). All the attributes that
were affected by T
k
appear in column L(A).
Soundness: For each tuple in AT (T, Set
T
), Set
T
con-
tains only those transactions that were affected by T.
For each tuple in L(A, T ), T is the last transaction
that updated A.
Minimal: Column AT (T ) contains only those trans-
actions that were affected by T
k
.
Column L(A) contains only those attributes that were
affected by T
k
.
This theorem shows that Algorithm 2 will find all
affected transactions and affected attributes.
Proof Sketch.
Completeness: by induction;
Let T
1
, T
2
, ..., T
n
be n transactions following T
k
in
transaction log, AT
n
contains all transactions affected
by T
k
from T
1
to T
n
, and L
n
contains all attributes
affected by T
k
from T
k
to T
n
.
The base case: when n = 1.
1. Let L
1
initially contains all attributes updated by
T
k
.
Algorithm 2: Finding affected transaction.
Input: Data dependency provenance table P
T
, Trans-
action ID T
k
of a malicious transaction, and a
transaction log
Output: The affected transaction table AT(T, Set
T
)
and the last assignment table L(A, T)
1: Initialization
2: Create empty tables AT (T, Set
T
), and L(A, T )
3:
4: Abort all incomplete transactions
5: We are locking the database
6: Read the data dependency provenance record P
T
of the malicious transaction T
k
in the table
7: for all dependency pair (A
i
, Set
A
i
) in Dp do
8: Insert record (A
i
, T
k
) into L
9: end for
10: for all T
i
following T
k
in transaction log ordered
by committed time do
11: Read record of T
i
in P
T
12: for all dependency pair (A
i
, Set
A
i
) in Dp do
13: if Set
A
i
∩ S[π
A
(L)] is not ∅ then
14: if T
i
6∈ S[π
T
(AT )] then
15: Set
T
i
= {}
16: for all A
j
∈ Set
A
i
∩ S[π
A
(L)] do
17: Set
T
i
= Set
T
i
∪ π
T
(σ
A=A
j
(L))
18: end for
19: Insert record (T
i
, Set
T
i
) into AT
20: else
21: Set
T
i
= π
Set
T
(σ
T =T
i
(AT ))
22: for all A
j
∈ Set
A
i
∩ S[π
A
(L)] do
23: Set
T
i
= Set
T
i
∪ π
T
(σ
A=A
j
(L))
24: end for
25: Update record σ
T =T
i
(AT ) to
(T
i
, Set
T
i
)
26: end if
27: if A
i
6∈ S[π
A
(L)] then
28: Insert record (A
i
, T
i
) into L
29: else
30: Update record σ
A=A
i
(L) to (A
i
, T
i
)
31: end if
32: else if A
i
∈ S[π
A
(L)] and Set
A
i
∩ S[π
A
(L)]
is ∅ then
33: Delete record σ
A=A
i
(L)
34: end if
35: end for
36: end for
37: We are unlocking only the attributes in database
6∈ S[π
A
(L)]
2. AT
1
contains T
1
if T
1
update an attribute A
1
de-
pending on an attribute A
k
in L
1
.
3. Records of T
1
in data provenance table P
T
shows
whether A
1
depends on A
k
.
Database Recovery from Malicious Transactions: A Use of Provenance Information
43

Algorithm 3: Repairing.
Input: The affected transaction table AT , the last as-
signment table L, and the snapshot of database at
the time before the malicious transaction commit-
ted
Output: A consistent database state where all mali-
cious and affected transactions are undone
1: Initialization
2: Create empty ordered list FixQueue =<
T
1
, T
2
, ... > with the size equal to the number of
records in AT
3:
4: for all π
Set
T
(AT ) do
5: Set
T
= Set
T
− T
k
6: end for
7: while AT is not ∅ do
8: if π
Set
T
i
(AT ) is empty then
9: Add T
i
to FixQueue
10: Delete record σ
T =T
i
(AT )
11: for all π
Set
T
(AT ) do
12: Set
T
= Set
T
− T
i
13: end for
14: end if
15: end while
16: if T
k
∈ S[π
T
(L)] then
17: Fixed attributes F := π
A
(σ
T =T
k
(L))
18: for all A
i
∈ S[F] do
19: Unlock A
i
20: end for
21: end if
22: for all FixQueue[i] where i = 0, i++ do
23: execute FixQueue[i]
24: if FixQueue[i] ∈ S[π
T
(L)] then
25: Fixed attributes F := π
A
(σ
T =FixQueue[i]
(L))
26: for all A
i
∈ S[F] do
27: Update database with A
i
28: Unlock A
i
29: end for
30: end if
31: end for
4. If A
1
depends on A
k
, A
1
is also affected by T
k
so
T
1
is added to AT
1
and A
1
is added to L
1
.
The induction case: assume AT
n−1
contains all trans-
actions that are affected by T
k
from T
1
to T
n−1
, and
L
n−1
contains all attributes affected by T
k
from T
k
to
T
n−1
.
1. Consider transaction T
n
update an attribute A
n
.
2. Records of T
n
in P
T
shows whether A
n
depends on
any attribute A
l
in L
n−1
.
3. If A
n
depends on A
l
, A
n
is also affected by T
k
so
T
n
is added to AT
n
and A
n
is added to L
n
.
Conclusion: By the principle of induction, AT
n
con-
tains all transactions affected by T
k
and L
n
contains
all attributes affected by T
k
.
Soundness: Assume that there is a transaction
T
0
in Set
T
that is not affected by T. But then, because
there is an attribute in T
0
that is dependent on an
attribute of T (Algorithm 2 lines 16 and 17). This is a
contradiction of our initial assumption.
Minimality: Trivially follows.
Theorem 2. Given a malicious transaction T
k
and
a transaction execution history, Algorithm 3 recovers
the database to a consistent state, such that
1. All the effects of T
k
are removed.
2. All of the effects of the other transaction are pre-
served.
3. The recovered history is conflict serializable.
First we note, that by Theorem 1, AT (T, Set
T
) and
L(A, T) are complete, minimal, and sound, thus sup-
port 1.) and 2.) above.
Next, we show by contradiction, that all the effects
of T
k
are removed by Algorithm 3.
Proof Sketch.
Consistency by contradiction;
1. Assume that some inconsistent attribute A
i
that is
affected by malicious transaction T
k
and A
i
is not
fixed by Algorithm 3.
2. But attribute A
i
must be assigned by a transaction
T
i
that is affected by T
k
.
3. Algorithm 3 executes all transactions in AT by
their committed order on the given snapshot and
AT contains all transactions that are affected by
T
k
.
4. AT contains all transaction id which are affected
by T
k
. So T
i
is in AT .
5. Since T
i
is re-executed from a consistent state
without affect from T
k
by Algorithm 3, all at-
tributes assigned by T
i
are consistent including A
i
.
6. So A
i
must be consistent. This contradicts the sup-
position that A
i
is inconsistent.
Serializability;
Case 1: There is no conflict operation between trans-
action T
i
and T
j
.
1. In this case, the following conditions must be true
by definition of conflict transactions
(a) R s
T
i
∩W s
T
j
is ∅.
DATA 2021 - 10th International Conference on Data Science, Technology and Applications
44
(b) R s
T
j
∩W s
T
i
is ∅.
(c) W s
T
i
∩W s
T
j
is ∅.
2. The partial order of transaction T
i
and T
j
can be
represented using directed graph.
3. There is no edge between node of T
i
and T
j
be-
cause of the conditions above.
4. So the graph is a directed acyclic graph. This his-
tory is conflict-serializable.
Case 2: There is a conflict operation between transac-
tion T
i
and T
j
.
1. In this case, at least one of the following condi-
tions must be true by definition of conflict trans-
actions
(a) R s
T
i
∩W s
T
j
is not ∅.
(b) R s
T
j
∩W s
T
i
is not ∅.
(c) W s
T
i
∩W s
T
j
is not ∅.
2. Case (a): R s
T
i
∩W s
T
j
is not ∅.
1 T
i
always reads attribute value from the snap-
shot which is a database state preceding a state
that T
j
writes. So the read operation of T
i
al-
ways precedes the write operation of T
j
.
2 The partial order of transaction T
i
and T
j
can be
represented using a directed graph.
3 The edge between node of T
i
and T
j
is in a di-
rection from T
i
to T
j
because T
i
always precedes
T
j
.
4 So the graph is a directed acyclic graph. This
history is conflict-serializable.
3. Case (b): R s
T
j
∩W s
T
i
is not ∅.
1 Algorithm 2 discovers all attributes that are af-
fected by a malicious transaction T
k
as claimed
in Theorem 1 and it locks all those attributes.
2 There are 2 possible cases as follows:
i) The attribute A
i
in R s
T
j
∩W s
T
i
is not an af-
fected attribute.
ii) The attribute A
i
in R s
T
j
∩W s
T
i
is an affected
attribute.
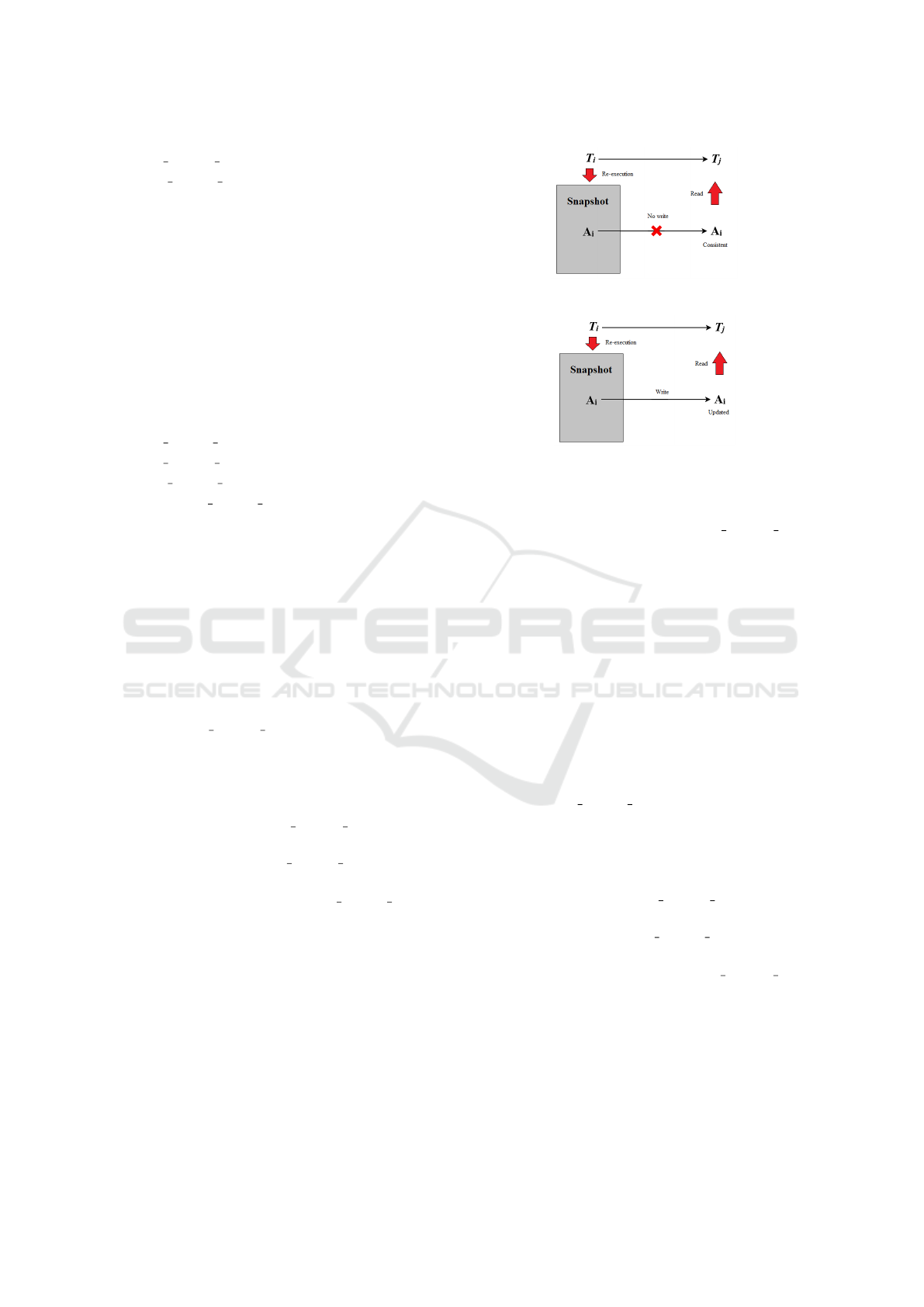
2.1 Case (i): the attribute A
i
in R s
T
j
∩W s
T
i
is not
an affected attribute.
2.1.1 The attribute A
i
which was written by af-
fected transaction T
i
is consistent and will
not be overwritten after T
i
is re-executed in
snapshot. So the history is preserved and
the write operation of T
i
over A
i
precedes the
read operation of T
j
as in the original history.
2.1.2 The partial order of transaction T
i
and T
j
can
be represented using a directed graph.
2.1.3 The edge between node of T
i
and T
j
is in a
direction from T
i
to T
j
because T
i
always pre-
cedes T
j
.
Figure 1: Transaction Dependency in Case 2.b.i.
Figure 2: Transaction Dependency in Case 2.b.ii.
2.1.4 So the graph is a directed acyclic graph. This
history is conflict-serializable.
2.2 Case (ii): The attribute A
i
in R s
T
j
∩W s
T
i
is
an affected attribute.
2.2.1 The attribute A
i
is locked by Algorithm 2 un-
til the re-execution of affected transactions
which modifies A
i
is finished and the con-
sistent value of A
i
is updated. So the write
operation of T
i
always precedes the read op-
eration of T
j
.
2.2.2 The partial order of transaction T
i
and T
j
can
be represented using a directed graph.
2.2.3 The edge between node of T
i
and T
j
is in a
direction from T
i
to T
j
because T
i
always pre-
cedes T
j
.
2.2.4 So the graph is a directed acyclic graph. This
history is conflict-serializable.
4. Case (c): W s
T
i
∩W s
T
j
is not ∅.
1 Algorithm 2 discovers all attributes that are af-
fected by a malicious transaction T
k
as claimed
in Theorem 1 and it locks all those attributes.
2 There are 2 possible cases as follows:
i) The attribute A
i
in W s
T
j
∩W s
T
i
is not an af-
fected attribute.
ii) The attribute A
i
in W s
T
j
∩W s
T
i
is an affected
attribute.
2.1 Case (i): the attribute A
i
in W s
T
j
∩ W s
T
i
is
not an affected attribute.
2.1.1 The attribute A
i
which was written by af-
fected transaction T
i
is consistent and will
not be overwritten after T
i
is re-executed in
snapshot. So the history is preserved and
the write operation of T
i
over A
i
precedes the
write operation of T
j
as in the original his-
tory.
Database Recovery from Malicious Transactions: A Use of Provenance Information
45
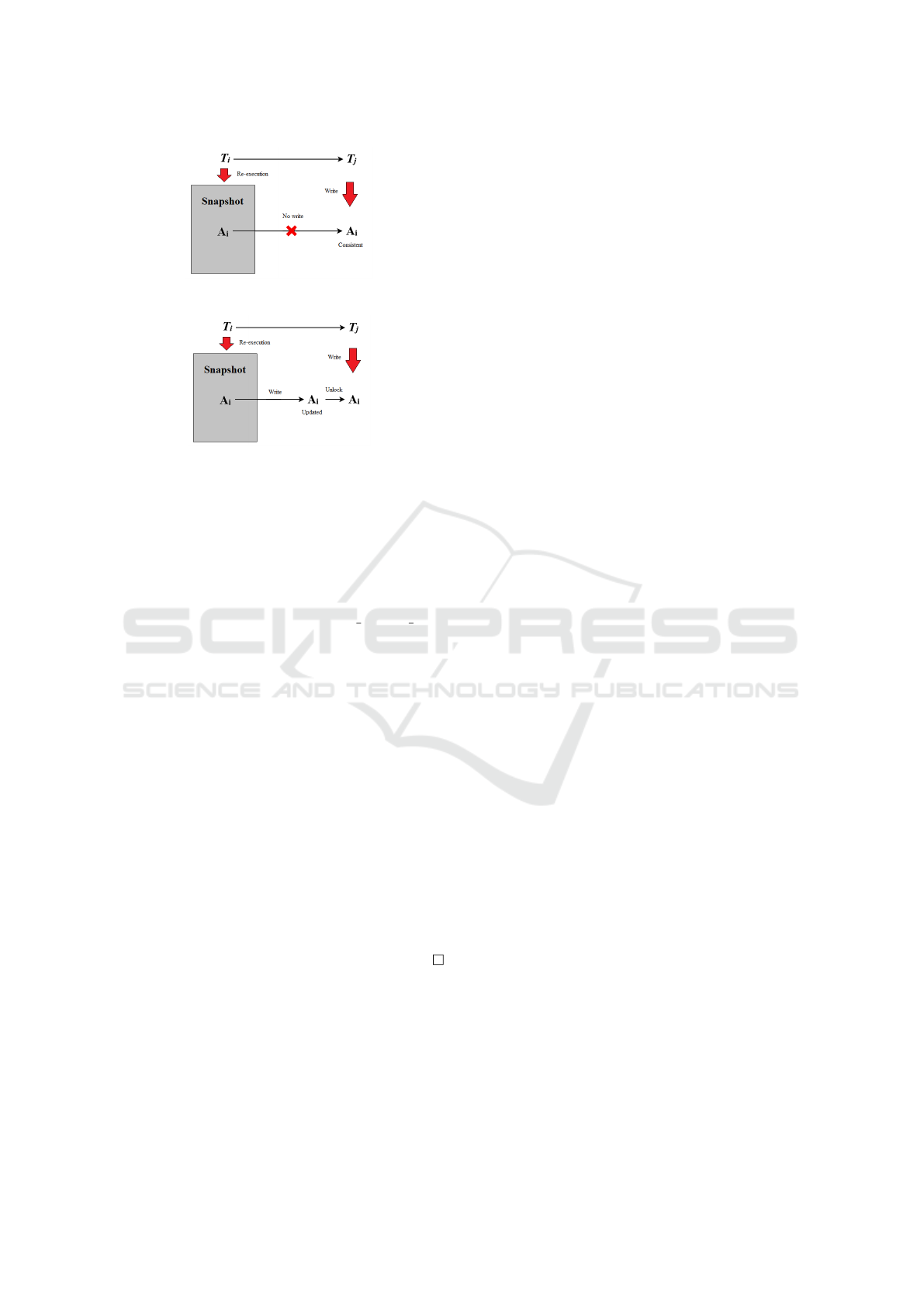
Figure 3: Transaction Dependency in Case 2.c.i.
Figure 4: Transaction Dependency in Case 2.c.ii.
2.1.2 The partial order of transaction T
i
and T
j
can
be represented using a directed graph.
2.1.3 The edge between node of T
i
and T
j
is in a
direction from T
i
to T
j
because T
i
always pre-
cede T
j
.
2.1.4 So the graph is a directed acyclic graph. This
history is conflict-serializable.
2.2 Case (ii): the attribute A
i
in W s
T
j
∩W s
T
i
is
an affected attribute.
2.2.1 The attribute A
i
is locked by Algorithm 2 un-
til the re-execution of affected transactions
which modify A
i
is finished and the consis-
tent value of A
i
is updated. So the write op-
eration of T
i
always precedes the write oper-
ation of T
j
.
2.2.2 The partial order of transaction T
i
and T
j
can
be represented using a directed graph.
2.2.3 The edge between node of T
i
and T
j
is in a
direction from T
i
to T
j
because T
i
always pre-
cedes T
j
.
2.2.4 So the graph is a directed acyclic graph. This
history is conflict-serializable.
5. Consider all the possible cases, the history con-
taining all operations of T
i
and T
j
is conflict-
serializable.
Complexity Analysis: Assume n number of transac-
tions were committed after the malicious transaction,
the database has m number of attributes, and r num-
ber of transactions were affected by the malicious
transaction. Let t
create
denote the time required to
create the provenance record for a transaction. The
time required to retrieve the attributes that may have
been corrupted by a transaction is denoted by t
check
.
The time required to add a transactions to a queue
waiting for recovery is denoted by t
queue
, the time
required to reexecute a transaction is denoted by
t
reexecute
, and the time required to unlock an attribute
is denoted by t
unlock
.
Algorithm 1. To create the provenance table
for each transaction, the loop from line 5-17 will be
executed at most m times and the nested loop from
line 10-12 will be executed at most m times. This
give us: Time = m
2
(t
create
).
Algorithm 2. To find all affected transactions,
Algorithm 2 checks each transaction. The loop from
line 12-35 will be executed at most m times and
either the nested loop from line 16-18 or another
nested loop from line 22-24 will be executed at
most the combined total of m times. The process
will be repeated for each transaction. This give us:
Time = nm
2
(t
check
).
Algorithm 3. To repair the database, the af-
fected transactions will be queued and re-executed.
After a transaction is re-executed, then attributes of
this transaction will be unlocked if there is no risk
of inconsistency. The while loop from line 7-15 will
be executed r times until all affected transactions are
queued. The nested loop on line 11-13 will be exe-
cuted r times. The checking process from line 16-20
checks for attributes that are affected by only the
malicious transaction, they can be rolled back and un-
locked immediately. The loop from line 22-31 will be
executed r times to fix each affected transaction. The
unlock process from line 24-30 checks for attributes
that were last updated by the re-executed transaction
is the last transaction which assign the values then
unlock. These attributes are unlocked that updated
these attributes. This process may be repeated up to
m times for each transaction (max. m × r). This give
us: Time = r
2
(t
queue
) + r(t
reexecute
) + rm(t
unlock
).
Re-execute All Transactions. To re-execute all
transactions, we have to go through all n transac-
tions then unlock all m attributes. This give us:
Time = n(t
reexecution
) + m(t
unlock
).
Comparison between using Our Solution and
Re-executing All Transactions. Our solution use the
total time of Algorithm 2 and Algorithm 3: Time =
nm
2
(t
check
) + r
2
(t
queue
) + r(t
reexecute
) + rm(t
unlock
).
Without loss of generality, we assume that for most
realistic workloads, the checking, queuing, and
unlocking processes (in Algorithm 2 and Algorithm
3) require substantially less time than the time needed
DATA 2021 - 10th International Conference on Data Science, Technology and Applications
46

to re-execute a transaction. The time required by our
solution will be bounded by Time = r(t
reexecute
). The
time required by re-executing all transactions will be
bounded by Time = n(t
reexecute
). Thus, our solution
can perform faster on the assumptions that r < n and
the processes in our algorithms requires substantially
less time than the re-execution process.
5 CONCLUSIONS & FUTURE
WORK
As the numbers and sophistication of attacks against
databases increase, it is necessary to support effi-
cient and correct recovery from malicious transac-
tions. The solution presented in this paper provides
an efficient an correct solution to recover from ma-
licious transactions. This increases the availability
of the system without dramatically decreasing perfor-
mance. We showed that our solution also preserves
conflict serializability.
Our ongoing work extends our results to reduce
the number of malicious transactions that affect the
database. Our approach is to combine snapshot iso-
lation with data provenance. Our provenance data
incorporates snapshot isolation to predict transaction
behavior. The transaction scheduler can use this in-
formation to prioritize transactions and block poten-
tial malicious transactions.
ACKNOWLEDGEMENT
This project was partially supported by the NCAE-C
Cyber Curriculum and Research 2020 Program.
REFERENCES
A. Chakraborty, A. K. Majumdar, and S. Sural (2010). A
column dependency-based approach for static and dy-
namic recovery of databases from malicious transac-
tions. International Journal of Information Security,
9(1):51–67.
Ammann, P., Jajodia, S., and Liu, P. (2002). Recovery from
malicious transactions. IEEE Transactions on Knowl-
edge and Data Engineering, 14(5):1167–1185.
Backes, M., Grimm, N., and Kate, A. (2016). Data lineage
in malicious environments. IEEE Transactions on De-
pendable and Secure Computing, 13(2):178–191.
Bissell, K., Lasalle, R., and Paolo, D. C. (2019). 2019 Cost
of Cybercrime Study | 9th Annual | Accenture.
Chandra, R., Kim, T., Shah, M., Narula, N., and Zeldovich,
N. (2011). Intrusion recovery for database-backed
web applications. In Proceedings of the Twenty-Third
ACM Symposium on Operating Systems Principles,
SOSP ’11, pages 101–114, New York, NY, USA. As-
sociation for Computing Machinery.
Chandra, R., Kim, T., and Zeldovich, N. (2013). Asyn-
chronous intrusion recovery for interconnected web
services. In Proceedings of the Twenty-Fourth ACM
Symposium on Operating Systems Principles, SOSP
’13, pages 213–227, New York, NY, USA. Associa-
tion for Computing Machinery.
Hammad, R. and Wu, C. (2014). Provenance as a service:
A data-centric approach for real-time monitoring. In
2014 IEEE International Congress on Big Data, pages
258–265.
Haraty, R. A., Kaddoura, S., and Zekri, A. S. (2018).
Recovery of business intelligence systems: Towards
guaranteed continuity of patient centric healthcare
systems through a matrix-based recovery approach.
Telematics Informatics, 35(4):801–814.
Haraty, R. A. and Zbib, M. (2014). A matrix-based damage
assessment and recovery algorithm. In 2014 14th In-
ternational Conference on Innovations for Community
Services (I4CS), pages 22–27.
Haraty, R. A., Zbib, M., and Masud, M. (2016). Data dam-
age assessment and recovery algorithm from mali-
cious attacks in healthcare data sharing systems. Peer-
to-Peer Networking and Applications, 9(5):812–823.
He, L., Yue, P., Di, L., Zhang, M., and Hu, L.
(2015). Adding geospatial data provenance into
sdi—a service-oriented approach. IEEE Journal of Se-
lected Topics in Applied Earth Observations and Re-
mote Sensing, 8(2):926–936.
Kaddoura, S., Haraty, R. A., Zekri, A., and Masud, M.
(2016). Tracking and repairing damaged healthcare
databases using the matrix. International Journal of
Distributed Sensor Networks, 2015:6:6.
Kim, T., Chandra, R., and Zeldovich, N. (2012). Recovering
from intrusions in distributed systems with DARE. In
Proceedings of the Third ACM SIGOPS Asia-Pacific
conference on Systems, APSys ’12, page 10, USA.
USENIX Association.
Kim, T., Wang, X., Zeldovich, N., and Kaashoek,
M. F. (2010). Intrusion recovery using selective re-
execution. In Arpaci-Dusseau, R. H. and Chen, B., ed-
itors, 9th USENIX Symposium on Operating Systems
Design and Implementation, OSDI 2010, October 4-
6, 2010, Vancouver, BC, Canada, Proceedings, pages
89–104. USENIX Association.
Liang, X., Shetty, S., Tosh, D., Kamhoua, C., Kwiat, K.,
and Njilla, L. (2017). Provchain: A blockchain-
based data provenance architecture in cloud environ-
ment with enhanced privacy and availability. In 2017
17th IEEE/ACM International Symposium on Cluster,
Cloud and Grid Computing (CCGRID), pages 468–
477.
Liu, P. and Jajodia, S. (2001). Multi-phase damage confine-
ment in database systems for intrusion tolerance. In
Proceedings. 14th IEEE Computer Security Founda-
tions Workshop, 2001., pages 191–205.
Lomet, D., Vagena, Z., and Barga, R. (2006). Recov-
ery from ”bad” user transactions. In Proceedings of
Database Recovery from Malicious Transactions: A Use of Provenance Information
47

the 2006 ACM SIGMOD international conference on
Management of data, SIGMOD ’06, pages 337–346,
New York, NY, USA. Association for Computing Ma-
chinery.
P. Liu, P. Ammann, and S. Jajodia (2000). Rewriting histo-
ries: Recovering from malicious transactions, pages
7–40. Springer.
Panda, B. and Giordano, J. (1998). Reconstructing the
database after electronic attacks. In Jajodia, S., ed-
itor, Database Security XII: Status and Prospects,
IFIP TC11 WG 11.3 Twelfth International Working
Conference on Database Security, July 15-17, 1998,
Chalkidiki, Greece, volume 142 of IFIP Conference
Proceedings, pages 143–156. Kluwer.
Panda, B. and Haque, K. A. (2002). Extended data depen-
dency approach: a robust way of rebuilding database.
In Proceedings of the 2002 ACM symposium on Ap-
plied computing, SAC ’02, pages 446–452, New York,
NY, USA. Association for Computing Machinery.
Panda, B. and Jing Zhou (2003). Database damage as-
sessment using a matrix based approach: an intrusion
response system. In Seventh International Database
Engineering and Applications Symposium, 2003. Pro-
ceedings., pages 336–341.
Xu, G. and Wang, Z. (2010). Data provenance architecture
based on semantic web services. In 2010 Fifth IEEE
International Symposium on Service Oriented System
Engineering, pages 91–94.
Zhang, O. Q., Ko, R. K. L., Kirchberg, M., Suen, C. H.,
Jagadpramana, P., and Lee, B. S. (2012). How to
track your data: Rule-based data provenance tracing
algorithms. In 2012 IEEE 11th International Confer-
ence on Trust, Security and Privacy in Computing and
Communications, pages 1429–1437.
DATA 2021 - 10th International Conference on Data Science, Technology and Applications
48
