
Model Inversion for Impersonation in Behavioral Authentication Systems
Md Morshedul Islam and Reihaneh Safavi-Naini
Department of Computer Science, University of Calgary, Calgary, AB., Canada
Keywords:
Behavioral Authentication System, Substitute Classifier, Inverse Classifier, Impersonation Attack.
Abstract:
A Behavioral Authentication (BA) system uses behavioral characteristics of a user that is stored in their behav-
ioral profile, to verify their future identity claims. BA profiles are widely used as a second factor to strengthen
password based authentication systems. A BA verification algorithm takes the claimed identity of the user
together with their presented verification data, and by comparing the data with the profile of the claimed iden-
tity it decides to accept or reject the claim. An efficient and highly accurate verification algorithms can be
constructed by training a Deep Neural Network (DNN) on the users’ profiles. The trained DNN classifies
the presented verification data and if the classification matches the claimed identity, accepts the claim, else
reject it. This is a very attractive approach because it removes the need to maintain the profile database that
is security and privacy sensitive. In this paper we show that query access to the DNN verification algorithm
allows an attacker to break security of the authentication system by constructing the profile of a user in the
original training database and succeed in impersonation attack. We show how to construct an inverse classifier
when the attacker has black-box access to the DNN’s output prediction vectors, truncated to a single compo-
nent (highest probability value). We use a substitute classifier to approximate the unknown components of
the prediction vectors, and use the recovered vectors to train the inverse classifier and construct the profile of
a user in the database. We implemented our approach on two existing BA systems and achieved the average
success probability of 29.89% and 45.0%, respectively. Our approach is general and can be used in other DNN
based BA systems.
1 INTRODUCTION
A Behavioral Authentication (BA) system (Shi et al.,
2011; Zheng et al., 2011; Frank et al., 2013b; Islam
and Safavi-Naini, 2016) constructs a behavioral pro-
file for a user that will be used by the verification al-
gorithm to evaluate a verification request of a user that
consists of a claimed identity and some behavioral
data. The profile is constructed using the data that is
collected during a well-defined activity. The verifica-
tion algorithm compares the presented behavioral data
with the stored profile associated with the claimed
identity, and decides to accept or reject the request.
BA systems have been used to strengthen password-
based authentication system, and provide a range of
attractive properties such as protection against cre-
dential sharing without the need for additional hard-
ware.
Behavioral profile of a user consists of a set of m
d-dimensional vectors over real numbers R, each di-
mension corresponding to a feature, and each vector
corresponds to a measurement of behavioral features.
The user profile is generated during a trusted registra-
tion phase, and is stored at the server. A verification
request (also called authentication) will consist of a
set of m behavioral measurement samples, together
with a claimed identity. In a traditional verification
algorithm, a distance measure will be used to evalu-
ate “closeness” of the presented verification data (m
samples) with the set of samples in the claimed user
profile. This requires the server to keep a database
of user profiles which will need protection and secure
data management because of the security and privacy
sensitivity of profile data. An attractive approach to
verification without the need for the server to maintain
the profile database is to use the profile data to train
a classifier such as a DNN classifier, where each user
is assigned to one class. The trained classifier will be
used to evaluate verification requests by classifying
the verification data (Centeno et al., 2017; Deng and
Zhong, 2015; Lu et al., 2018). This approach removes
the need to store the profile data and significantly im-
proves the system’s privacy.
DNN for user authentication. DNNs have been
used for biometric and behavioral authentication sys-
tems. For example, DNN based authentication sys-
tems have been constructed for face data (Schroff
et al., 2015), fingerprint data (Pandya et al., 2018),
mouse movements (Chong et al., 2019), gait data
(Jung et al., 2019), and keystroke data (Deng and
Islam, M. and Safavi-Naini, R.
Model Inversion for Impersonation in Behavioral Authentication Systems.
DOI: 10.5220/0010559802710282
In Proceedings of the 18th International Conference on Security and Cryptography (SECRYPT 2021), pages 271-282
ISBN: 978-989-758-524-1
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
271

Zhong, 2015). The DNN classifier learns the map-
ping between the user data in the training data set and
a set of classes, each corresponding to a user, by com-
posing a parametric function consisting of the layers
of the DNN. The output of a DNN classifier with N
classes on each data sample (vector) of BA system is
an N dimensional probability vector (sum of compo-
nents equal to 1.0) that is called the prediction vector,
where the i
th
component represents the “belief” of the
classifier that the input is in the i
th
class. The final
decision of the verification algorithm will be based
on the m samples that are form the verification data.
Using DNN for BA system verification has the ad-
vantage of allowing partial verification decision to be
made on each sample. This can be used for continu-
ous authentication where the user’s identity is period-
ically verified during the authentication session.
Model inversion attacks aim to reconstruct data
with the same distribution as the training data of the
DNN classifier using partial information about input
(training data and/or its domain), output (prediction
vectors) and the structure of the original DNN. Out-
put vectors of the DNN can be obtained by sending
input to the DNN that will serve as an oracle, and re-
ceiving its response. Access to the target classifier
can be in black-box or white-box, where in the for-
mer the querier only sees (part of) the prediction vec-
tor, while in the latter the full working information
of the DNN will be accessible to the attacker. The
complexity of model inversion depends on the type of
the attacker’s access to the DNN, and the data avail-
able to them. Model inversion attacks (Yang et al.,
2019b) have followed two approaches, optimization-
based and training-based, where the former is re-
stricted to white-box access to the DNN only. We
consider black-box access and so focus on the latter
approach.
In training-based model inversion attacks (Doso-
vitskiy and Brox, 2016a; Dosovitskiy and Brox,
2016b; Nash et al., 2019; Yang et al., 2019b; Yang
et al., 2019a) a second DNN classifier is trained to act
as the inverse of the target DNN classifier. The in-
verse classifier can then be used to generate the data
with the same distribution as the training data of the
target classifier. Most existing works assume that at-
tacker has access to the full prediction vectors of a
subset of the original training data. In (Yang et al.,
2019b; Yang et al., 2019a) authors give the construc-
tion of an inverse classifier when only a few top com-
ponents of the prediction vector is known (referred to
as truncated prediction vector), and the data from the
input domain (not the training data) are available. The
input data in their work is face image data.
Our Work. We consider a setting where a BA sys-
tem with a DNN based verification algorithm is used
for user authentication. The attacker can send verifi-
cation queries, receive the responses, and accept the
associated confidence value. We assume the system
description, that is the format of profile and the gen-
eral structure of the DNN verification algorithm, is
known. However, important information including
the training data set and and the values of the pa-
rameters of the trained DNN are not accessible. A
user can send behavioral samples to the verification
system, and for each, receive a truncated prediction
vector where only the largest component is non-zero
and all other components are zeroed. The goal of the
attacker is to impersonate a registered user by con-
structing behavioral samples for the verification claim
that are accepted by the DNN based verification algo-
rithm with sufficiently high probability. Verification
data has the same format as the training data and so
impersonation attack can be seen as a model inversion
attack where the goal of the attacker is to construct
behavioral samples of a user.
Challenges. The response of the verification oracle
to a query is a prediction vector that has a single non-
zero component. To train an inverse classifier, how-
ever, the complete prediction vector is required. The
main challenge in our work is to reconstruct the full
prediction vector from the output vector of verifica-
tion oracle that has a single non-zero component. A
similar attack setting had been considered in (Yang
et al., 2019b; Yang et al., 2019a) for face authentica-
tion system. Authors however allowed the adversary
to have access to the top 5-10 components of the pre-
diction vector, which effectively contains most of the
probability mass and captures the relationship of the
presented sample to all “close” neighbouring classes.
Considering only a single non-zero component signif-
icantly reduces the available information of the adver-
sary. Additionally, unlike (Yang et al., 2019b; Yang
et al., 2019a) where samples of domain data (not the
training data) can be easily obtained through internet
searches, in our setting, one needs to generate samples
of behavioral data by running the BA registration al-
gorithm for different users (that will be different from
the registered ones) to collect data.
Our Approach. The attacker’s goal is to construct
fraudulent verification data for a user (i.e., specified
index in the prediction vector) that will be accepted
by the verification algorithm. We achieve this goal by
constructing an inverse classifier. At a high level the
attack has the following steps: (1) generate domain
data that will be used as queries to the target DNN
classifier, (2) design a substitute classifier to complete
the truncated prediction vectors that are the output of
the target classifier, (3) use the completed prediction
SECRYPT 2021 - 18th International Conference on Security and Cryptography
272

vectors to train the inverse classifier in conjunction
with the target classifier, and (4) construct imperson-
ation data. More details on each step is given below.
1. Generating Data. To generate the required pro-
file data, referred to as attack data to distinguish
them from the DNN original training data, the at-
tacker will use the profile generator of the BA sys-
tem (software would be publicly available). They may
use outsourcing services such as Amazon Mechanical
Turks (AMT) to generate the required attack data. If
needed, the generated data can be expanded using ar-
tificial data generation methods, including probabilis-
tic models or classification-based imputation models.
In our experiment, we used published data of two ex-
isting systems (Frank et al., 2013b; Islam and Safavi-
Naini, 2016) and used to oversample them to allow
training of the inverse DNN. The attack data is parti-
tioned into two sets, one used for the training of the
substitute classifier, and the other used for the training
of the inverse classifier.
2. Constructing a Substitute Classifier. We used a k-
nearest neighbors (k-NN) classifier as the substitute
classifier for the target DNN classifier. The two clas-
sifiers will have the same number of classes. Training
the substitute classifier needs labelled training data.
We used oracle access to the target DNN classifier to
label half of the attack data that was allocated to the
substitute classifier. The k-NN classifier was trained
using the labelled data. This effectively creates a one-
to-one correspondence between the prediction vectors
of the target classifier and the k-NN classifier. Once
the substitute classifier is trained (the highest output
index of the target classifier matches the highest in-
dex of the substitute classifier), for each class i we
will use samples of the attack data to obtain the 5-10
(neighbouring) classes with the highest probabilities.
These are the most similar classes to i in the DNN
classifier.
3. Constructing Inverse Classifier. We assume that
the structure of the target classifier, that is the number
of layers and their types, are known to the attacker.
The inverse classifier will have the same layers, in
reverse order. (We note that the approach can also
be used when the structure of the target classifier is
not known, in which case the attacker will experiment
with different number and types of layers, to arrive at
a good inverse classifier.)
To train the inverse classifier, each vector in the
data set is used to query the target classifier (ora-
cle access) to obtain the truncated prediction vector.
The same vector will then be inputted to the substi-
tute classifier to reconstruct the missing components
of the prediction vector. The sample is dropped if the
top components of the prediction vectors of the two
classifiers do not correspond to the same index value.
The reconstructed prediction vectors are given as in-
put to the inverse classifier to obtain the data samples.
An error is measured based on the input and output
of the target classifier and the inverse classifier. The
parameters (weights) of the inverse classifier are up-
dated based on this error, and the process is repeated
until the error is sufficiently low.
4. Constructing Impersonation Data. A fraudulent
verification profile consists of m distinct data sam-
ples
1
. The trained inverse classifier needs an appro-
priate input prediction vector to construct the corre-
sponding data sample. We noted that the structure of
the input prediction vectors of the inverse classifier is
the same as the structure of the prediction vector of
the DNN classifier. To construct the first prediction
vector of a target user at index i, the first step is to as-
sign a high probability value (close to 1.0) to the target
class i. Next, we will use the top 5-10 neighboring
classes of i, that were generated using the substitute
classifier, to complete the prediction vector by using
the non-zero components to correspond to the neigh-
bouring classes of i, and the values of each component
to be proportional to the corresponding values of the
neighbouring class. The remaining m − 1 data sam-
ples are generated by updating the probability values
of the initially chosen prediction vector.
Experimental Results. We implemented and evalu-
ated our proposed approach for two existing BA sys-
tems: Touchalytics (Frank et al., 2013b) and eDAC
(Islam et al., 2021) which is an extended version of
DAC (Draw A Circle) (Islam and Safavi-Naini, 2016).
The approach however is general and can be used in
other BA systems that use DNN for verification de-
cision. In each case, we divided the profiles of the
BA systems into two sets: the first set of profiles is
used to train a DNN classifier, and the second set of
profiles is used as attack data. Each DNN classifier
has 4-5 stacks of dense layers along with their activa-
tion functions. A softmax function layer uses as the
last layer to return the output probability values in the
prediction vector. The inverse DNN classifier has al-
most the same but inverse architecture of the target
DNN classifier.
We compared the output distribution similarity of
the k-NN classifier with the output distribution of the
DNN classifier. For the same input, on average, there
are 2-3 and 5-7 common classes in the top 5 and top
1
Distinctness is necessary to prevent the trivial attack
where an attacker repeats a single vector multiple times.
In practice this attack can be prevented using different ap-
proaches by the verification algorithm (e.g., requiring pre-
sented vectors to have a minimum distance) that will use the
characteristics of the training data.
Model Inversion for Impersonation in Behavioral Authentication Systems
273

Table 1: List of notions.
Notation Meaning
C DNN classifier
S Substitute classifier
InvC Inverse classifier
x Input vector of C and S
ˆ
y Prediction vector of C and S
y Ground truth vector
N Number of classes in C and S
v Input prediction vector of InvC
ˆ
x Output vector of InvC
D Training data of C
D
1
Training data of S
D
2
Training data of InvC
E Data reconstruction error
10 classes of the two prediction vectors. We use this
to recover the missing information of Truncated Pre-
diction Vector, which will be used to train the inverse
classifier. The training process stops when the aver-
age reconstruction error is around 0.01. For a target
user associated with class c
i
in the output prediction
vector, we used probability value 0.98 in c
i
and dis-
tributed the remaining probability values over the 5-
10 neighboring classes using substitute classifier out-
put. Our experimental results show that around 45.0%
of Touchalytics and 29.0% of eDAC users are vulner-
able to impersonation attack.
Notations. Table 1 summarizes the notations used in
this paper.
Paper Organization. Section 2 describes the pre-
liminaries and related works. Section 3 is about the
model inversion and implementation attack. Section
4 gives details of the experimental results. Finally,
Section 5 concludes the paper.
2 PRELIMINARIES AND
RELATED WORKS
DNN Classifier. In a DNN classifier, a neuron is
an elementary computing unit that uses a set of in-
puts, a set of weights and an activation function to
translate inputs into a single output, which can then
be used as input to another neuron. While the de-
tails can vary between neural networks, the function
f
i
(w
i
, x) is commonly a weighted function in the form
of w
i
x. The weights of each neuron are tuned during
the training stage such that the final network output
(prediction vector
ˆ
y) is biased towards the value of
the ground truth vector y (the expected output vec-
tor). The non-linear behavior in a neural network is
obtained by using an activation function (often uses a
sigmoid function) to which the output of f
i
is passed
and modified. This non-linear behavior allows neural
networks to describe more complicated systems while
still combining inputs in a simple fashion.
Definition 2.1. A DNN classifier C uses a hierarchi-
cal composition of n parametric functions f
i
to model
an input vector x where each f
i
is modelled using a
layer of neurons, and parameterized by a weight vec-
tor w
i
. The last layer of C uses a softmax function
σ(.) (for multi-class classification) to encode the be-
lief that the input belongs to each class of the DNN
classifier, and give the probability values in a predic-
tion vector
ˆ
y.
ˆ
y = C(x) = σ( f
n
(w
n
, ··· f
2
(w
2
, f
1
(w
1
, x)))) (1)
If input vector x is from user u
i
then in ground
truth vector y the probability value y[i] = 1.0, and the
probability value of other classes is 0.0. For x, a good
classifiers C will have a very high probability value
in
ˆ
y[i], and non-zero probability values in the neigh-
bor classes of
ˆ
y[i], where
∑
ˆ
y[i] = 1.0. An error func-
tion measures the (distribution) difference between y
and
ˆ
y. For a profile
¯
X with m data samples, the m
truncated prediction vectors of the DNN classifier will
form a prediction table (see Figure 1).
Performance of a DNN classifier is measured by
rank-t (t ≥ 1) accuracy. For rank-1 accuracy of C, the
top class of the prediction vector is the same as the top
class of the corresponding ground truth vector, and for
rank-t accuracy the top class is in the top t classes of
the ground truth vector.
Inverse Classifier. Model inversion attack con-
structs and trains an inverse classifier for a target
DNN classifier to reconstruct the data with the same
distribution as the training data of a target DNN clas-
sifier (Dosovitskiy and Brox, 2016a; Dosovitskiy and
Brox, 2016b; Nash et al., 2019; Yang et al., 2019a;
Yang et al., 2019b). Model inversion attack is also
used to predict the sensitive attributes (Hidano et al.,
2018; Wu et al., 2016) of the target classifier’s train-
ing data. One can also use optimization-based data
reconstruction approach (Fredrikson et al., 2015; Lin-
den and Kindermann, 1989; Mahendran and Vedaldi,
2015) to reconstruct the data. Gradient-based opti-
mization requires white-box access to the target DNN
classifier while training-based model inversion can
work in black-box setting.
Training-based model inversion approach trains a
new DNN classifier which is the inverse of the tar-
get DNN classifier. The inverse DNN classifier takes
the output of the target DNN classifier as input, and
outputs the input of the target DNN classifier. The
training process minimizes the average error between
SECRYPT 2021 - 18th International Conference on Security and Cryptography
274
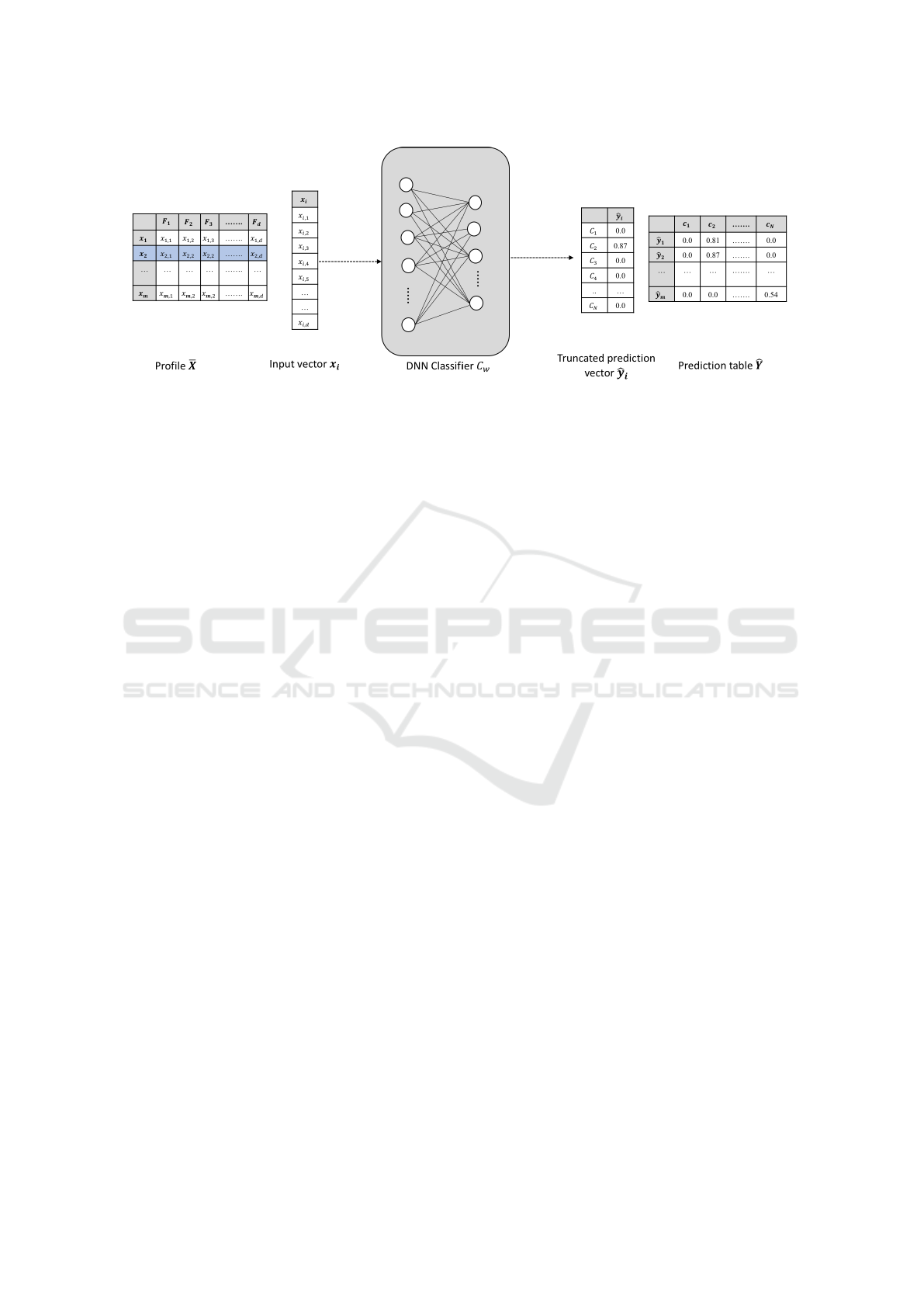
Figure 1: For a profile
¯
X with m data samples, the DNN classifier generates m truncated prediction vectors. In each truncated
prediction vector, the largest component is non-zero and all other components are zeroed.
the output of the inverse classifier and the input of
the target classifier, where the average is over the set
of all training data samples of the inverse classifier.
Training-based model inversion is a one-time effort
for training the inverse classifier. Once the classifier
is trained, the trained inverse classifier is used the pre-
diction vectors to generate the artificial profile data.
Substitute Classifier. Model extraction attack (i)
builds a substitute classifier (Papernot et al., 2017) of
a target DNN classifier, or (ii) extracts the model (tar-
get classifier) parameters (Tram
`
er et al., 2016). Both
attacks can be in black-box setting, where the target
DNN classifier works as an oracle. We use substitute
classifier to reconstruct the truncated prediction vec-
tors of the verification oracle. The substitute classi-
fier will have the same number of classes as the target
classifier, and will use the same input-output format.
For each input the substitute classifier maximizes the
similarity of its output (distribution) with that of the
target DNN classifier. To train the substitute classifier,
the attacker needs labelled training data. This can be
obtained from the output of the oracle. In (Papernot
et al., 2017), it is assumed that the attacker has access
to a subset of training samples of the target classi-
fier. In this case, the data samples and their predicted
class labels returned by the oracle is sufficient to train
the substitute classifier. In our case, the attacker only
knows the domain of the data for the training data of
the substitute classifier.
k-NN classifier. We use k-NN classifier (Cover and
Hart, 1967) as a substitute classifier for the target
DNN classifier. To estimate the prediction vector
ˆ
y by
k-NN classifier, we use the approach of (Mandelbaum
and Weinshall, 2017). The Equation (1) of (Mandel-
baum and Weinshall, 2017) estimates the probability
value of the prediction vector
ˆ
y.
3 ATTACK MODEL
Attacker’s Knowledge. We assume that the at-
tacker has the following knowledge and capabilities
for impersonating a target user:
1. The attacker does not know the training data (pro-
files) and parameters of the target classifier. The
attacker knows the BA system and the algorithm
used during the registration phase, and the general
structure of the DNN based verification system.
2. The target classifier also works as an oracle, and
the attacker can send the behavioral samples to the
oracle to receive the oracle response. The output
of the oracle will be a truncated prediction vector
where only the largest component is non-zero, and
all other components are zeroed.
3. The profile generator of the BA system is publicly
available. Here, profile generator is a software
that is used by the BA system to collect behav-
ioral data from the users. The attacker will out-
source the profile generator to collect attack data
from the users whose profiles are not used to train
the classifier.
4. From attack data, the attacker will be able to know
the input format of the target classifier. From
Truncated Prediction Vector, the attacker will be
able to know the output format of the target clas-
sifier as well as the total number of class in the
classifier.
3.1 Model Inversion Attack
We use the training-based approach to train an in-
verse classifier InvC as (i) it will help to produce arti-
ficial data samples in a black-box setting, (ii) one can
Model Inversion for Impersonation in Behavioral Authentication Systems
275
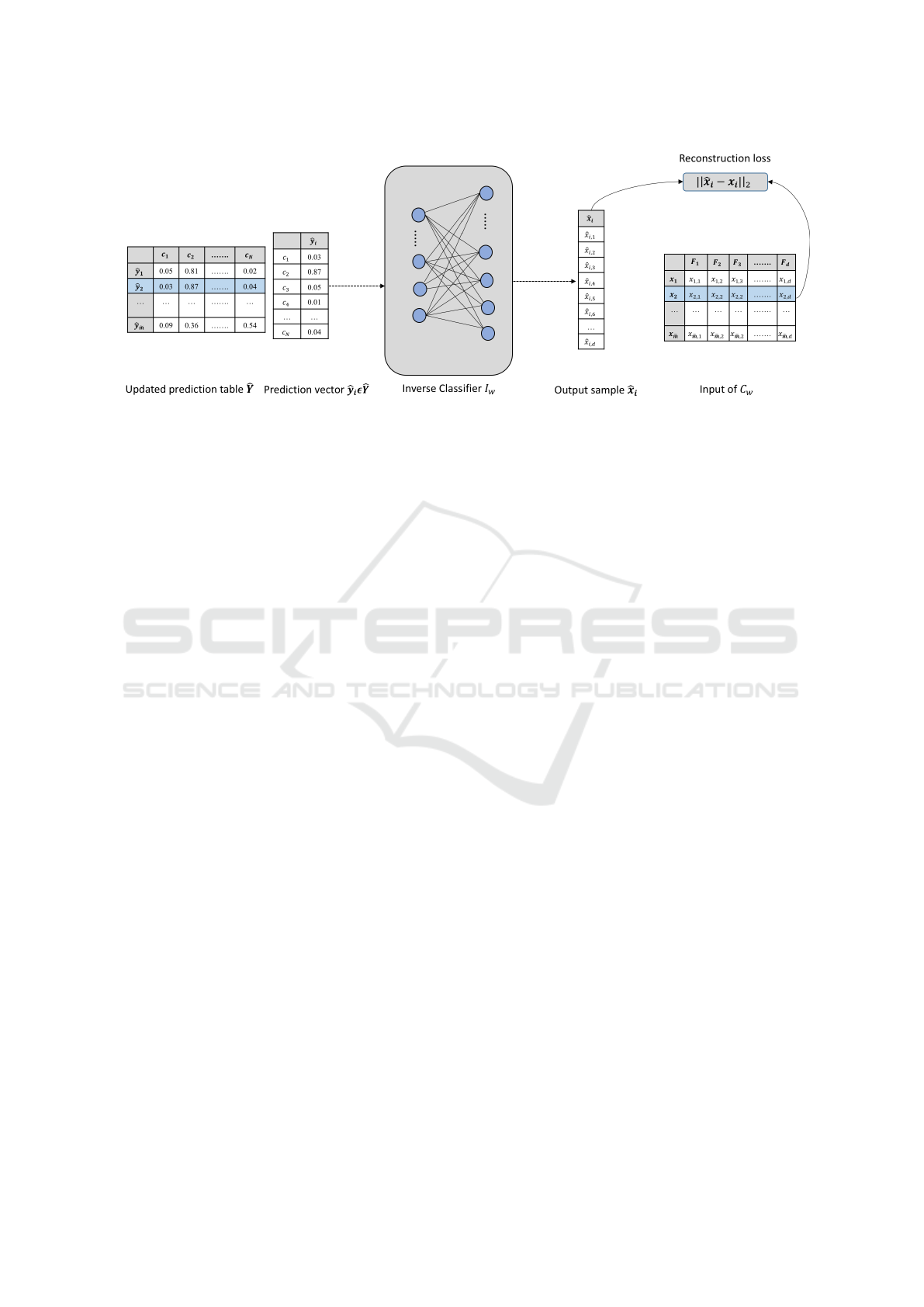
Figure 2: For x
i
, the InvC takes the updated prediction vector
ˆ
y
i
as input, and output the artificial data sample
ˆ
x
i
. The
reconstruction error is L2 difference between x
i
and
ˆ
x
i
.
use attack data to train the inverse classifier, and (iii)
it could achieve substantial inversion accuracy over
other approaches. During training, the attack data
transfer the knowledge about the decision boundaries
of the target classifier to the inverse classifier by the
prediction vectors. However, the Truncated Predic-
tion Vector with a single component misses important
information about the decision boundaries of the tar-
get classifier. We will use a substitute classifier S of
the target classifier C to fill the zero components of the
truncated prediction vectors. For both S and InvC, the
attacker will have oracle access to C. One can reduce
the number of oracle queries by making additional as-
sumptions about attacker’s knowledge. For example,
the authors of (Mo et al., 2020) assume hidden layers
of similar model of C is known and use them in InvC.
We leave reduction of queries as a direction for future
research. Details about each step is given below:
Step1: Generating Attack Data. A BA system has a
profile generator algorithm that collects the user’s be-
havioral data and constructs the profile. Profile gener-
ators are usually mobile applications (software), and
they are publicly available. The attacker can use the
software to collect the required attack data using out-
souring platform such as AMT. This data will be used
to train the substitute classifier, and to train the inverse
classifier. Let, D
1
and D
2
be two disjoint sets that are
constructed from the attack data and are used to train
substitute and inverse classifier, respectively.
Step 2: Constructing and Training a Substitute
Classifier. To construct and train a substitute clas-
sifier S that approximates the target classifier C, the
information of the target classifier will be used. We
choose k-NN classifier as substitute classifier of the
target classifier. The benefits of using k-NN classifier
are that (i) k-NN classifier requires relatively small
amount of (training) data for each classes, and (ii) it
is easy to implement. The performance of the k-NN
classifier is also compatible with the performance of
other classifiers. One can also use the same architec-
ture of the original DNN classifier for the substitute
classifier, but it would need significantly more train-
ing data.
Label the Training Data. Training the k-NN classi-
fier needs labelled training data. We use oracle ac-
cess to the target classifier to label data samples in D
1
.
For a data sample x
i
∈ D
1
if the oracle response
ˆ
y[i]
has a non-zero component that is higher than a pre-
determined threshold T , the sample will be labelled
as c
i
. The process will be repeated for all attack data
samples in D
1
.
Output Distribution Similarity. Most components of
the prediction vectors of a DNN classifier are negligi-
ble, and the top 5-10 probability values have the most
of the probability mass (Srivastava et al., 2015). This
means that the distributions similarity of the outputs
of S and C depend on the probability values of the
t (t = 5 − 10) top-ranked classes. We use Definition
(3.1) for distributions similarity. The closer the output
distributions of S and C are, the more accurate will be
the recovery of the information.
Definition 3.1. Let C be a classifier, and S be a sub-
stitute classifier of C. Both have the same number
of classes, and their input-output format are also the
same. Let D be a set of training data of C, and D
1
be a set of training data of S. For each class c
i
∈ C
there is a corresponding class c
i
∈ S, and their train-
ing data are also close to each other.
For an input vector x, let the prediction vectors of
C and S is
ˆ
y, and
ˆ
y
0
, respectively. For the output distri-
butions similarity, both prediction vectors will satisfy
the following two conditions with high probability:
SECRYPT 2021 - 18th International Conference on Security and Cryptography
276

1. If the highest probability value of
ˆ
y is in
ˆ
y[i] then
the highest probability value of
ˆ
y
0
will be in
ˆ
y
0
[i].
2. Let the next t − 1 highest probability values
of
ˆ
y be
ˆ
y[i
1
],
ˆ
y[i
2
], ··· ,
ˆ
y[i
t
]. Then most of
ˆ
y
0
[i
1
],
ˆ
y
0
[i
2
], ··· ,
ˆ
y
0
[i
t
] will hold the next t −1 high-
est probability values of
ˆ
y
0
.
Because of the small values of most of the com-
ponents, we only need to recover the non-negligible
components.
Step 4: Reconstruct Truncated Prediction Vector.
For a data sample x, let
ˆ
y and
ˆ
y
0
have the highest prob-
ability value on the same class index (class index i for
user u
i
), and let
ˆ
y[i] = α. The remaining probabil-
ity mass α
0
= 1 − α will then be distributed over the
next t − 1 top classes of
ˆ
y that will be obtained using
the neighbouring classes of i in
ˆ
y
0
. Let the next top
t − 1 classes of
ˆ
y
0
be
ˆ
y
0
[i
1
],
ˆ
y
0
[i
2
], ··· ,
ˆ
y[i
t−1
]. Then
ˆ
y[i
j
] =
ˆ
y
0
[i
j
]
α
0
, j = 1, 2, ··· , t − 1. Here, closer neigh-
boring class will have higher probability.
Step 5: Constructing and Training the Inverse
Classifier. The inverse classifier has its input and out-
put format as inverse of the target DNN classifier. In
our experiments, we assumed that the structure of the
target DNN classifier, the number of layers and num-
ber of nodes in each layer are known to the attacker.
(This assumption can be relaxed in practice where the
attacker will experiment with different number and
types of layers to arrive at a good inverse classifier.)
The inverse classifier has its layers in reverse or-
der of the target classifier; that is, the last layer of the
DNN classifier (except the softmax layer) will form
the first layer of the inverse classifier, and in general,
the j-th layer to the last of the target classifier will be-
come the j-th layer of the inverse classifier. The lay-
ers and number of nodes in each layer of the inverse
classifier can be modified to optimize the performance
of the inverse classifier.
Training Inverse Classifier. Let for a data sample
x
i
∈ D
2
, the output of the oracle be a Truncated Pre-
diction Vector
ˆ
y
i
. We update
ˆ
y
i
using the substi-
tute classifier and assign some random values in the
weights (parameters) of the inverse classifier. Let
for updated
ˆ
y
i
, the output of the inverse classifier is
ˆ
x
i
= InvC(
ˆ
y
i
), where
ˆ
x
i
is a new (artificial) data sam-
ple. So, the initial reconstruction error E (L2 norm)
for the data sample x
i
is E = ||x
i
−
ˆ
x
i
||
2
. The average
initial reconstruction error for all data samples of D
2
is
avg(E) =
1
|D
2
|
|D
2
|
∑
i=1
||x
i
−
ˆ
x
i
||
2
. (2)
The goal of the attacker is to minimize this aver-
age reconstruction error. Based on the estimated av-
erage error by Equation (2), a backward propagation
will update the weights of the inverse classifier. We
repeat the process for the data samples of D
2
to find
a set of weights of the inverse classifier, which will
bring the reconstruction error sufficient low. Figure 2
shows the training process of the inverse classifier.
3.2 Impersonation Attack
The verification profile requires a set of m distinct be-
havioral samples. The trained inverse classifier needs
an appropriate input prediction vector v to construct
each data sample. The vector v will have dimension
N and t non-zero components. For user u
i
, we will as-
sign v[i] = α (a probability value close to 1.0) and the
remaining probability mass 1 − α will be distributed
among t − 1 “closets” neighbours of c
i
. The proce-
dure to assign values to each non-zero component of
the vector is described in Section 3.1, Step 4.
Let for v
i
the output of the inverse classifier be
ˆ
x
i
.
The attacker will count
ˆ
x
i
as an element of the verifi-
cation profile if the oracle response to
ˆ
x
i
has the non-
zero component (probability value) with sufficiently
high value. The attacker will use v
i
to produce other
close, yet distinct, prediction vectors. Let v
j
is a
new prediction vector which is generated by slightly
changing the probability of v
i
. For v
j
the output of
the inverse classifier
ˆ
x
j
is accepted as a new sample if
(i) the oracle output on
ˆ
x
j
is class j with sufficiently
high confidence, and (ii) if the distance ||x
i
−
ˆ
x
j
||
2
is
higher than a preset value.
Let for a target user u
i
,
ˆ
X = {
ˆ
x
1
,
ˆ
x
2
, ··· ,
ˆ
x
m
} is a
set of m artificial data samples. The attacker will then
use the profile
ˆ
X to initiate a false verification request
(u
i
,
ˆ
X). The verification algorithm of the BA system
will accept the claim if for
ˆ
X the rank-1 accuracy of
C is higher than a predefined threshold.
4 EXPERIMENTAL RESULTS
We have implemented and evaluated our proposed
approach on two existing BA systems: Touchalytics
(Frank et al., 2013b), and extended version of DAC,
eDAC (Islam et al., 2021). Touchalytics uses users’
touch data (up-down and left-right scrolling) when in-
teracting with the profile generator. We downloaded
Touchalytics data from (Frank et al., 2013a) and it has
the data from 41 distinct users. eDAC uses behav-
ioral features of users that are collected while drawing
random challenge circles that are presented to them
to verify their verification request. We downloaded
eDAC data from (Islam and Safavi-Naini, 2021) that
has the data of 195 distinct users.
Model Inversion for Impersonation in Behavioral Authentication Systems
277
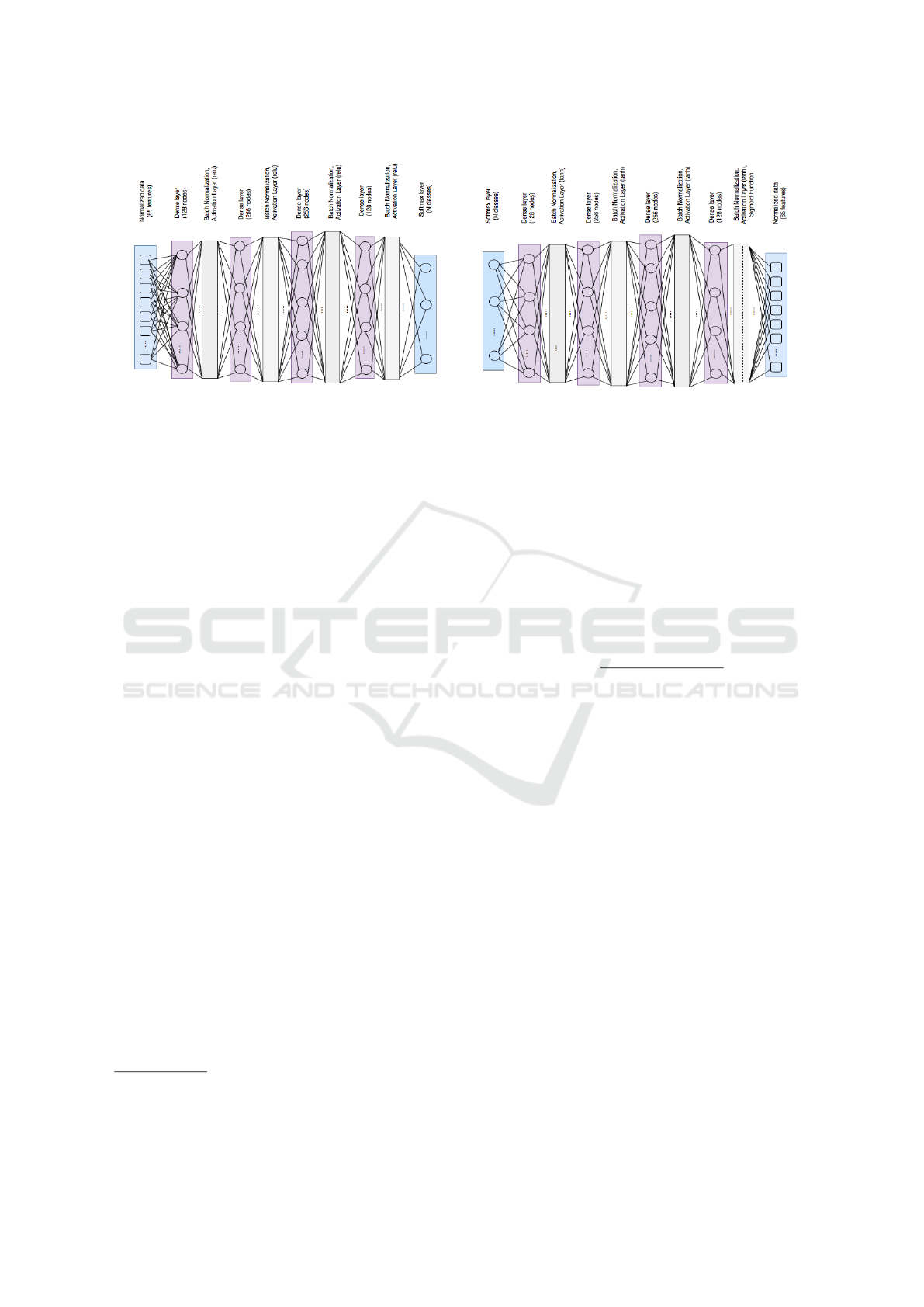
(a) (b)
Figure 3: (a) DNN architecture of eDAC classifier. It has multiple stacks of dense, relu, and batch-normalization layers. A
softmax function in the last layer of the classifier outputs the prediction vector. (b) DNN architecture for the inverse classifier
of eDAC classifier. The architecture of the inverse classifier is almost the same, but opposite to the corresponding classifier.
Touchalytics classifier and its inverse classifier follows almost same structure (see Figure 7 in Appendix).
Experiment Setup. We downloaded and cleaned
2
Touchalytics data before using them. eDAC did not
require data cleaning. We then combined the regis-
tration and verification data of each user, for both BA
systems, and applied a shuffling on them before using
the data in the experiments. This combining of data
will give us 186-1230 data samples of dimension 30 in
each profile of Touchalytics, and 80-240 data samples
of dimension 65 in each profile of eDAC. To reduce
the effect of biases that are the result of features hav-
ing different ranges, we normalized the feature values
so that all feature ranges coincide with [0,1]. From
each profile, we separated 20.0% of data for testing
purposes.
Data Oversampling. We need sufficient data in each
profile for DNN experiments. We used Synthetic Mi-
nority Over-sampling Technique (SMOTE) (Chawla
et al., 2002) in the remaining data sample to increase
the profile size. SMOTE is an oversampling algo-
rithm that generates new data which lies between any
two existing data samples of a profile. In our experi-
ments, we ensured that both BA systems have a mini-
mum of 1000 data samples per profile. After applying
SMOTE, we also confirm the correctness and secu-
rity of both BA systems. For that, we train two BA
classifiers for two BA systems by the over-sampling
profiles, and then testing them by the data that were
separated before. In both systems, correctness and se-
curity remained nearly the same.
Training Data of DNN Classifier and Attack Data. We
divided all profiles of each BA system into two equal
groups (drop one profile from each BA system to keep
2
We replace ‘NaN’ and ‘Infinity’ by zero, and dropped
the ‘doc id’, ‘phone id’, and ‘change of finger orientation’
columns.
the number of profile same in each group of both BA
systems): (i) group 1- all profiles of this group are
used to train and validate the DNN classifier, and (ii)
group 2- all profiles of this group are used as attack
data. In each group, there are 20 Touchalytics profiles
and 97 eDAC profiles, respectively.
Prediction Vector of k-NN Classifier. We used Equa-
tion (3) for the probability values estimation of the
prediction vector of k-NN classifier.
ˆ
y[i] =
∑
k
j=1,x
j
∈c
i
e
−||x−x
j
||
2
∑
k
j=1
e
−||x−x
j
||
2
, (3)
where
ˆ
y[i] represent the probability value that the data
sample x is in class c
i
. For Equation (3), we update the
Equation (1) of (Mandelbaum and Weinshall, 2017).
This is because, in our case all data samples of both
BA systems are in the features’ space. For our imper-
sonation attack, we run the following experiments: (i)
design and train the DNN based classifier, (ii) design
and train the inverse classifier, and (iii) construct arti-
ficial profiles for impersonation attack.
4.1 DNN Classifier Design and Training
This section is about to design the architectures of
DNN classifiers for both BA systems. We then train
and validate both classifiers by the data samples of
group 1. We also test their performance by test data.
Experiment 1: Design DNN Classifier Architec-
ture. To confirm the effectiveness of our proposed
approach, we need the DNN based classifier. For
both Touchalytics and eDAC classifier, we design two
separate hierarchical DNN architectures. The idea to
build a hierarchical model is that each higher level
layer in a DNN classifier captures more complex non-
linear features from the data. Both architectures have
SECRYPT 2021 - 18th International Conference on Security and Cryptography
278

(a) (b)
Figure 4: (a) Training and validation accuracy of eDAC classifier. In 50 epochs of training, the classifier can achieve 98.16%
of training, and 97.85% of validation accuracy, respectively. (b) Data reconstruction error of eDAC based inverse classifier.
The inverse classifier reduced the error to 0.011 in a reasonable number of epochs. Touchalytics classifier and its inverse
classifier has almost same pattern (see Figure 8 in Appendix).
multiple dense, batch-normalization, and activation
(ReLU) layers. The dense layer provides the learn-
ing features from all combinations of the input fea-
tures of previous layer. The ReLU layer works as
an activation function of the soft boundary, and the
batch-normalization layer normalizes the data. A
Touchalytics classifier has five stacks of dense, ReLU
and batch-normalization layers, and each layer has
64, 128, 256, 128, and 64 nodes, respectively. On
the other hand, the eDAC classifier has four stacks
of dense, ReLU and batch-normalization layers with
128, 156, 256, and 128 nodes, respectively. A softmax
function layer is used as the last layer of each classi-
fier to represent the output probability distribution in
a prediction vector. Figure 3 (a) shows the architec-
tures of DNN based eDAC classifiers (see Figure 7 (a)
in Appendix for Touchalytics classifier).
Experiment 2: Training the DNN Classifier. From
the data samples of each profile of group 1, we use
80.0% of data for training and 20.0% of data for
validation purpose. In 50 epochs of training both
Touchalytics and eDAC classifier achieve 96.28%,
and 98.16% classification accuracy, and 95.27%, and
97.85% validation accuracy, respectively. See Figure
4 (a) and Figure 8 (a) (in Appendix ) for the train-
ing and validation accuracy of eDAC and Touchalyt-
ics classifier, respectively. Each epoch takes only 3-
4 seconds and 8-9 seconds in both Touchalytics and
eDAC classifier. For the test data that were separated
earlier, the classification accuracy of both DNN clas-
sifiers are 95.31% and 97.97%, respectively.
To ensure that none of the profiles of group 2 (at-
tack data) are used to train their corresponding DNN
classifier, we estimate the classification accuracy of
both DNN classifiers by using the profiles of group
2. In this case, Touchalytics and eDAC classifier have
only 1.91% and 1.01% classification accuracy. For
the attack data, this result is what we expect to get.
4.2 Inverse Classifier Design and
Training
This section is about to design the architecture of in-
verse classifier, recover the missing components of
Truncated Prediction Vector by substitute classifier
and train the inverse classifier by the reconstructed
prediction vectors.
Experiment 1: Design Inverse Classifier Architec-
ture. The input-output format of both inverse classi-
fiers are the same as their corresponding classifiers’
output-input format. We use multiple stacks of dense
layers, batch-normalization layers, and tanh activa-
tion layers in each inverse classifier design. The last
layer of each inverse classifier uses sigmoid function
layer to keep the output in [0,1]. The architecture of
both inverse classifiers are almost the same but op-
posite of their corresponding target classifiers. Fig-
ure 3 (b) and Figure 7 (b) (in Appendix) shows the
DNN architectures of eDAC based inverse classifier
andTouchalytics based inverse classifier.
Experiment 2: Measure Output Distribution Simi-
larity. For each class of k-NN classifier, we use a sub-
set of data samples of group 2 (attack data samples in
D
1
) that were labelled by the oracle. The input-output
dimension of Touchalytics and eDAC based substitute
classifiers is 30 and 65, 20, and 97, respectively.
We estimated the output similarity of the k-NN
and target DNN classifier based on their top t classes.
For each x ∈ D
1
, almost all top classes of the predic-
tion vectors of both classifiers satisfy the condition
(1) of Definition 3.1. Moreover, in the top 5 classes
of two prediction vectors of two classifiers, on aver-
age there are 2-3 common classes. If we take the top
10 classes from each prediction vector of both clas-
sifiers, there are on average 5-7 common classes (see
Figure 5). We use these results to update the missing
components of
ˆ
y of the DNN classifier.
Model Inversion for Impersonation in Behavioral Authentication Systems
279
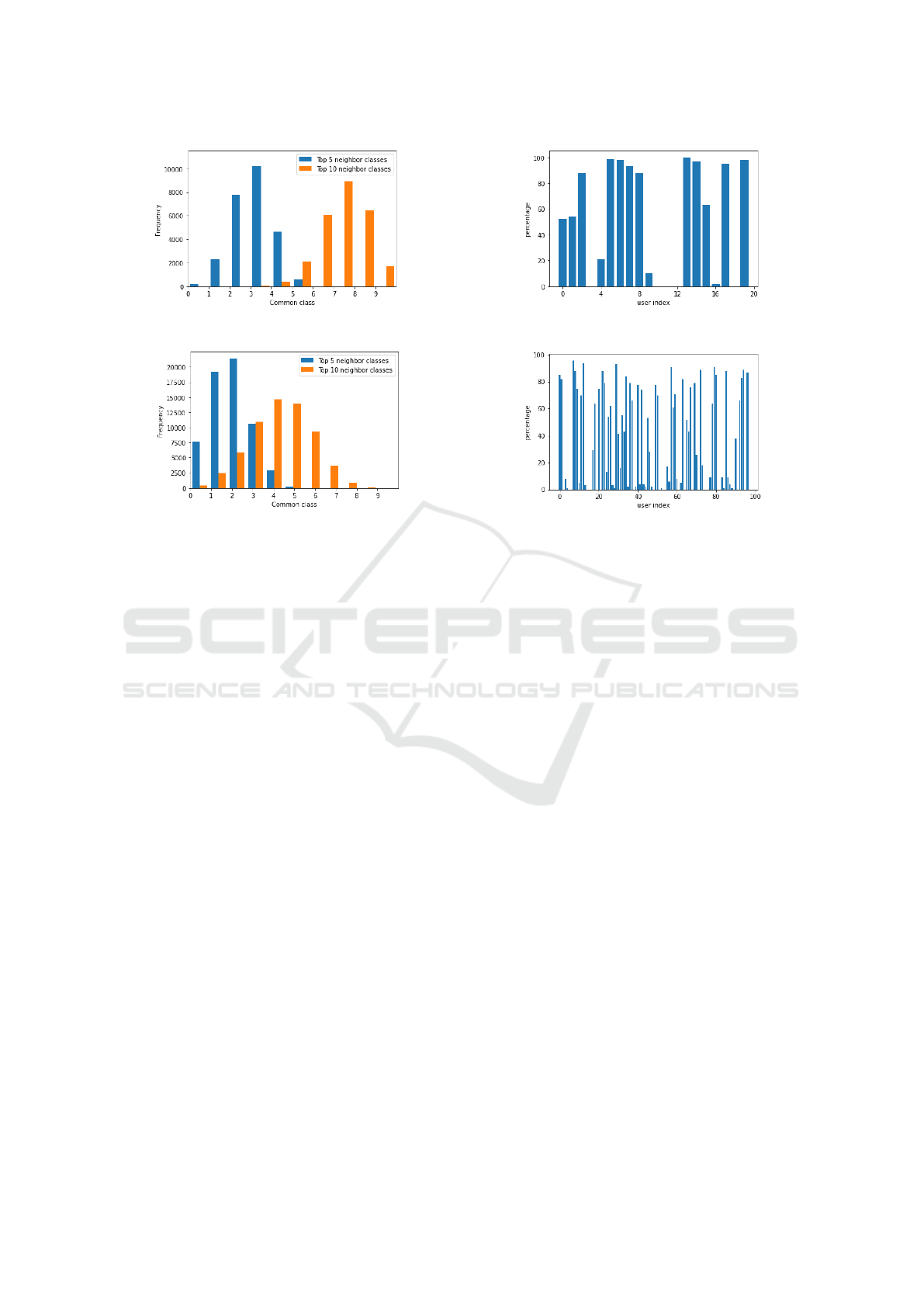
(a)
(b)
Figure 5: For same input, the common classes in the pre-
diction vector of substitute and DNN classifier. In the top 5
classes of two prediction vectors, on average there are 2-3
common classes and there are 5-7 common classes in the
top 10 classes.
Experiment 3: Training the Inverse Classifier. To
train the inverse classifier, we use the updated pre-
diction vectors. We use “mean-square-error” as the
error function between the inverse classifier’s output
and the DNN classifier’s input. To reach a reason-
able average reconstruction error, Touchalytics based
inverse classifier took 50 epochs (each epoch took 2-
3 seconds), and eDAC based inverse classifier took
200 epochs (each epoch took 7-8 seconds). The av-
erage error in both Touchalytics and eDAC based in-
verse classifier are 0.010 and 0.011, respectively. Fig-
ure 4 (b) shows the error of eDAC inverse classi-
fiers. Touchalytics inverse classifier has almost same
error (see 8 (b) in Appendix). For less number of
features, Touchalytics-based inverse classifier takes
fewer epochs during training the inverse classifier
compare to the eDAC based inverse classifier.
4.3 Impersonation Attack
For verification data, we first generate the input pre-
diction vectors and then use them in the trained in-
verse classifier. Detailes are given below.
Experiment 1: Input Prediction Vector Genera-
tion. For a target user, we generate the input predic-
tion vector v by assigning a highest probability value
to the corresponding class i of user u
i
and then by dis-
(a)
(b)
Figure 6: Rank-1 accuracy of an artificial verification data
ˆ
X. If for acceptance,
ˆ
X needs minimum 70.0% of rank-1
accuracy then 45.0% of Touchalytics and 29.89% of eDAC
users are vulnerable to impersonation attack.
tributing the remaining probability values to the top
5-10 neighbour classes of the target user class. We al-
ter the probability value of each target class from 0.80
to 1.0 (for probability value 1.0, there is only one in-
put vector) and found that the higher the probability
value in the target user’s class is, the more chance of
acceptance (by the DNN verification algorithm) the
corresponding verification data has. In Touchalytics,
for the probability value in the range 0.80 to 1.0, the
percentage of artificially generated verification data
that are accepted by the DNN verification algorithm
is increased from 30.47% to 58.06%. In the case of
eDAC, it varies from 23.60% to 50.94%.
Experiment 2: Impersonation Attack. For a fraud-
ulent claim (u
i
,
ˆ
X), we generate input prediction vec-
tor by assigning v[i] = 0.98, and then distributing re-
maining probability values to the top 5 (in Touchalyt-
ics), and top 10 (in eDAC) neighbour classes of target
class. There are on average 600-650 data samples in
each artificial profile. For Touchalytics, we generate
20 artificial profiles and 97 artificial profiles for eDAC
and use them to impersonate the uers’ of the DNN
classifier. Figure 6 shows the percentage of data sam-
ples in each
ˆ
X, which is accepted by the DNN based
verification algorithm. Here, all artificial verification
profiles of both BA systems are not equally accepted.
For (u
i
,
ˆ
X), if an accept decision requires minimum
70.0% rank-1 classification accuracy then 45.0% of
SECRYPT 2021 - 18th International Conference on Security and Cryptography
280

Touchalytics users, and 29.89% of eDAC users are
vulnerable to impersonation attack.
5 CONCLUDING REMARKS
We constructed and trained the inverse classifier in a
black-box setting by using attack data. The substi-
tute classifier helped the attacker to recover the miss-
ing information of truncated prediction vectors. We
generate input prediction vectors for the trained in-
verse classifier for the fraudulent verification claim,
where every vector has the highest probability value
in the target user’s class. In our experiments, we
used Touchalytics and eDAC data and achieved an
accepted success rate in impersonation attack. Our
work raises a number of research questions, includ-
ing the design of more efficient attacks by improving
the substitute and inverse classifiers. Protecting DNN
classifier of the BA system from this type of attack
can be another future research direction.
ACKNOWLEDGEMENT
This work is in part supported by Natural Sci-
ences and Engineering Research Council of Canada
and Telus Communications Industrial Research Chair
Grant.
REFERENCES
Centeno, M. P., van Moorsel, A., and Castruccio, S.
(2017). Smartphone continuous authentication us-
ing deep learning autoencoders. In 2017 15th An-
nual Conference on Privacy, Security and Trust (PST),
pages 147–1478. IEEE.
Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer,
W. P. (2002). Smote: synthetic minority over-
sampling technique. Journal of artificial intelligence
research, 16:321–357.
Chong, P., Elovici, Y., and Binder, A. (2019). User authen-
tication based on mouse dynamics using deep neural
networks: A comprehensive study. IEEE Transac-
tions on Information Forensics and Security, 15:1086–
1101.
Cover, T. and Hart, P. (1967). Nearest neighbor pattern clas-
sification. IEEE transactions on information theory,
13(1):21–27.
Deng, Y. and Zhong, Y. (2015). Keystroke dynamics
advances for mobile devices using deep neural net-
work. Recent Advances in User Authentication Using
Keystroke Dynamics Biometrics, 2:59–70.
Dosovitskiy, A. and Brox, T. (2016a). Generating images
with perceptual similarity metrics based on deep net-
works. In Advances in neural information processing
systems, pages 658–666.
Dosovitskiy, A. and Brox, T. (2016b). Inverting visual rep-
resentations with convolutional networks. In Proceed-
ings of the IEEE conference on computer vision and
pattern recognition, pages 4829–4837.
Frank, M. et al. (2013a). Touchalytics. http://www.
mariofrank.net/touchalytics/. [Online; accessed 01-
March-2021].
Frank, M. et al. (2013b). Touchalytics: On the applicabil-
ity of touchscreen input as a behavioral biometric for
continuous authentication. IEEE Transactions on In-
formation Forensics and Security, 8(1):136–148.
Fredrikson, M., Jha, S., and Ristenpart, T. (2015). Model
inversion attacks that exploit confidence information
and basic countermeasures. In Proceedings of the
22nd ACM SIGSAC Conference on Computer and
Communications Security, pages 1322–1333.
Hidano, S., Murakami, T., Katsumata, S., Kiyomoto, S., and
Hanaoka, G. (2018). Model inversion attacks for on-
line prediction systems: Without knowledge of non-
sensitive attributes. IEICE Transactions on Informa-
tion and Systems, 101(11):2665–2676.
Islam, M. M. and Safavi-Naini, R. (2016). Poster: A be-
havioural authentication system for mobile users. In
Proceedings of the 2016 ACM Conference on Com-
puter and Communications Security (CCS ’16), pages
1742–1744. ACM.
Islam, M. M. and Safavi-Naini, R. (2021). Draw A Circle
(DAC). https://github.com/mdmorshedul/DAC. [On-
line; accessed 01-March-2021].
Islam, M. M., Safavi-Naini, R., and Kneppers, M. (2021).
Scalable behavioral authentication. IEEE Access,
9:43458–43473.
Jung, D., Nguyen, M. D., Han, J., Park, M., Lee, K., Yoo, S.,
Kim, J., and Mun, K.-R. (2019). Deep neural network-
based gait classification using wearable inertial sensor
data. In 2019 41st Annual International Conference
of the IEEE Engineering in Medicine and Biology So-
ciety (EMBC), pages 3624–3628. IEEE.
Linden, A. and Kindermann, J. (1989). Inversion of multi-
layer nets. In Proc. Int. Joint Conf. Neural Networks,
volume 2, pages 425–430.
Lu, C. X., Du, B., Zhao, P., Wen, H., Shen, Y., Markham,
A., and Trigoni, N. (2018). Deepauth: in-situ au-
thentication for smartwatches via deeply learned be-
havioural biometrics. In Proceedings of the 2018
ACM International Symposium on Wearable Comput-
ers, pages 204–207.
Mahendran, A. and Vedaldi, A. (2015). Understanding deep
image representations by inverting them. In Proceed-
ings of the IEEE conference on computer vision and
pattern recognition, pages 5188–5196.
Mandelbaum, A. and Weinshall, D. (2017). Distance-based
confidence score for neural network classifiers. arXiv
preprint arXiv:1709.09844.
Mo, K., Huang, T., and Xiang, X. (2020). Querying little
is enough: Model inversion attack via latent informa-
Model Inversion for Impersonation in Behavioral Authentication Systems
281

tion. In International Conference on Machine Learn-
ing for Cyber Security, pages 583–591. Springer.
Nash, C., Kushman, N., and Williams, C. K. (2019). In-
verting supervised representations with autoregressive
neural density models. In The 22nd International
Conference on Artificial Intelligence and Statistics,
pages 1620–1629.
Pandya, B., Cosma, G., Alani, A. A., Taherkhani, A.,
Bharadi, V., and McGinnity, T. (2018). Fingerprint
classification using a deep convolutional neural net-
work. In 2018 4th International Conference on Infor-
mation Management (ICIM), pages 86–91. IEEE.
Papernot, N., McDaniel, P., Goodfellow, I., Jha, S., Celik,
Z. B., and Swami, A. (2017). Practical black-box at-
tacks against machine learning. In Proceedings of the
2017 ACM on Asia conference on computer and com-
munications security, pages 506–519.
Schroff, F., Kalenichenko, D., and Philbin, J. (2015).
Facenet: A unified embedding for face recognition
and clustering. In Proceedings of the IEEE conference
on computer vision and pattern recognition, pages
815–823.
Shi, E., Niu, Y., Jakobsson, M., and Richard, C. (2011). Im-
plicit authentication through learning user behavior. In
Proceedings of ISC’2010, pages 99–113. Springer.
Srivastava, R. K., Greff, K., and Schmidhuber, J. (2015).
Training very deep networks. In Advances in neural
information processing systems, pages 2377–2385.
Tram
`
er, F., Zhang, F., Juels, A., Reiter, M. K., and Risten-
part, T. (2016). Stealing machine learning models via
prediction apis. In 25th {USENIX} Security Sympo-
sium ({USENIX} Security 16), pages 601–618.
Wu, X., Fredrikson, M., Jha, S., and Naughton, J. F. (2016).
A methodology for formalizing model-inversion at-
tacks. In 2016 IEEE 29th Computer Security Foun-
dations Symposium (CSF), pages 355–370. IEEE.
Yang, Z., Chang, E.-C., and Liang, Z. (2019a). Adversar-
ial neural network inversion via auxiliary knowledge
alignment. arXiv preprint arXiv:1902.08552.
Yang, Z., Zhang, J., Chang, E.-C., and Liang, Z. (2019b).
Neural network inversion in adversarial setting via
background knowledge alignment. In Proceedings of
the 2019 ACM SIGSAC Conference on Computer and
Communications Security, pages 225–240.
Zheng, N., Paloski, A., and Wang, H. (2011). An effi-
cient user verification system via mouse movements.
In Proceedings of the 18th ACM conference on Com-
puter and communications security (CCS ’11), pages
139–150. ACM.
APPENDIX
Figure 7 (a,b) shows the DNN architecture of Touch-
alytics classifier and inverse classifier. Figure 8 (a)
shows the training and validation accuracy of Touch-
alytics classifier. The data reconstruction error of
Touchalytics based inverse classifier is shown in Fig-
ure 8 (b).
(a)
(b)
Figure 7: DNN architecture of (a) Touchalytics classifier,
and (b) inverse classifier. Inverse classifiers architecture is
almost same, but opposite to the corresponding classifier.
(a)
(b)
Figure 8: (a) In 50 epochs of training, the Touchalytics clas-
sifier can achieve 96.28% of training, and 95.27% of vali-
dation accuracy, respectively. (b) Data reconstruction error
of Touchalytics inverse classifier reduced to 0.01 in a rea-
sonable number of epochs.
SECRYPT 2021 - 18th International Conference on Security and Cryptography
282
