
Semantic Entanglement on Verb Negation
Yuto Kikuchi
1
, Kazuo Hara
1
and Ikumi Suzuki
2
1
Yamagata University, 1-4-12 Kojirakawa-machi, Yamagata City, 990-8560, Japan
2
Nagasaki University, 1-14 Bunkyo, Nagasaki City, 852-8521, Japan
Keywords: Word2vec, Word Vector, Word Analogy Task.
Abstract: The word2vec, developed by Mikolov et al. in 2013, is an epoch-creating method that embeds words into a
vector space to capture their fine-grained meaning. However, the reliability of word2vec is inconsistent. To
evaluate the reliability of word vectors, we perform Mikolov’s word analogy task, where word
, word
, and
word
are provided. Under the condition that word
exhibits a particular relation with word
, the task
involves searching the vocabulary and returning the most relevant word for word
for the same relation. We
conduct an experiment to return negative words for verbs using word2vec for 100 typical Japanese verbs and
investigate the effect of context (i.e., surrounding words) on correct or incorrect responses. It is shown that
the task fails when the sense of verbs and negative relation are entangled because the semantic calculation of
verb negation does not hold.
1 INTRODUCTION
Recently, the automatic generation of natural
language sentences has progressed significantly
owing to the development of artificial intelligence
(AI) technology. For example, the advent of
technology that uses AI to generate fake news articles
that appear real (Brown et al., 2020) has surprised
humans, and Google Translate (Wu et al., 2016) can
now provide translations that are similar to those
written by humans.
Several methods have been developed to generate
word vectors, the representative of which is
word2vec, published by (Mikolov et al., 2013). The
word2vec is based on the “distributional hypothesis”
(Harris, 1954) pertaining to the meaning of a word,
i.e., the hypothesis that the meaning of a word is
determined by the context (originally, “a word is
characterized by the company it keeps” (Firth, 1957)).
More specifically, word2vec vectorizes words such
that the inner product of word vectors that appear in
similar contexts is a high value.
For example, the following are sentences using
the verb “go” and its negation “do not go.”
I go to school.
I go to the office.
I do not go to school.
I do not go to the office.
In this example, “go” and “do not go” are used in
similar contexts, i.e., both are used with content
words that represent a destination. Therefore,
word2vec is expected to represent these words as
similar vectors (i.e., two vectors with a high inner
product value).
Conversely, the negation of verbs, such as “do not
go” and “do not choose” are used in similar contexts.
For example, they are often used in contexts with
conjunctions to clarify reasons, as in the following
examples:
I do not go to school because it is far away.
I do not choose it because I hate it.
However, it seems that these contexts share only
function words, such as conjunctions, and not content
words. Therefore, word2vec is not expected to
represent the negation of these verbs as extremely
similar vectors.
Conversely, word2vec is expected to yield vectors
with similar differences regardless of verbs, i.e.,
vectors that represent the difference between the
negation and affirmation of verbs. In other words, the
following holds:
𝑣
−𝑣
≒𝑣
−𝑣
(1)
This is because the part where the content words
contribute to the vector construction is canceled, and
Kikuchi, Y., Hara, K. and Suzuki, I.
Semantic Entanglement on Verb Negation.
DOI: 10.5220/0010560000710078
In Proceedings of the 10th International Conference on Data Science, Technology and Applications (DATA 2021), pages 71-78
ISBN: 978-989-758-521-0
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
71

only the negative function remains in the difference
vectors.
1.1 Word Analogy Task
Mikolov et al., the developers of word2vec, reported
in an experiment involving the “word analogy task”
that the following equation holds when using word
vectors generated by word2vec:
argmax
∈
cos𝑣
+ 𝑣
− 𝑣
, 𝑣
= queen
(2)
Here, “Vocabulary” is a set of words, and cos (a,
b) is an operation that calculates the cosine of the
angle between vectors a and b.
Specifically, the word analogy task is as follows:
First, word
, word
𝐁
, and word
are provided,
where word
and word
exhibit some relation (the
type of relation is not specified). In this setting, the
word analogy task requests to return the word
(word
) that will be obtained when this relation is
applied to word
.
In the example presented by Mikolov et al.,
word
= man, word
= king, word
= woman, and
word
= queen. The problem was to infer, “If the
man who governs the country is called the king, then
what is the woman who governs the country?” This
query can be returned correctly using word vectors
generated by word2vec (the correct response is
“queen”).
1.2 Challenges to Be Addressed in This
Study
Mikolov et al. showed some successful examples of
the word analogy task when in fact, it failed in many
cases. In particular, (Yoshii et al., 2015) reported that
it was difficult to return the negation of a verb in
Japanese.
For example, suppose word
= go, word
= do
not go, word
= choose, and word
= do not choose.
The task is to return the negation of “choose.” The
correct response is “do not choose.” This is exactly
the calculation problem using the following equation:
argmax
∈
cos𝑣
+ 𝑣
− 𝑣
, 𝑣
(3)
If Eq. (1) holds, then it should be calculated as
follows to obtain the correct response:
argmax
∈
cos𝑣
+𝑣
− 𝑣
, 𝑣
≒argmax
∈
cos
𝑣
+
𝑣
− 𝑣
,𝑣
= argmax
∈
cos(𝑣
, 𝑣
)
= do not choose
However, the equation was not calculated in this
manner. In general, it is difficult to return a negative
word for a verb when using word vectors generated
by word2vec. In this study, we investigate the
contributing factors.
The remainder of this paper is organized as
follows: In Section 2, we present an experiment to
return negative words for verbs using word2vec for
100 typical Japanese verbs. We report that word
and word
, not word
and word
, which affect the
difficulty of the word analogy task. In Section 2, we
report the following observation regarding the
frequency of word occurrence in the corpus: When
word
and word
appear frequently in the corpus,
the analogy of the negation of a verb tends to be
successful. Subsequently, in Section 3, we investigate
the effect of context (i.e., surrounding words) on
correct or incorrect responses and report the
following observation: When word
and word
are
likely to appear in common contexts, the analogy of
the negation of a verb tends to be successful. Finally,
in Section 4, we conclude the paper by summarizing
the results and presenting some future directions.
2 WORD ANALOGY TASK
EXPERIMENT FOR
NEGATION OF VERBS
Using the word vectors generated by word2vec, we
conducted an experiment wherein we performed a
word analogy task to obtain negative words for
specified verbs.
2.1 Method
2.1.1 Corpus
First, we extracted text from 10,000 web pages of
Japanese Wikipedia and used them as the corpus for
word2vec.
DATA 2021 - 10th International Conference on Data Science, Technology and Applications
72

2.1.2 Morphological Analysis
Next, we used the morphological analyzer MeCab
1
to
convert the text into word sequences. In addition, we
combined the word labeled as “auxiliary verb” by
MeCab with the verb that is the target of the auxiliary
verb to form a synthetic word of the form “do not
verb” (“ない” in Japanese = auxiliary verb = “do
not” in English). Hence, we were able to obtain the
negation of verbs as words.
2.1.3 Generating Word Vectors using
Word2vec
We used word2vec to generate word vectors to
increase the similarity (inner product) between words
appearing in similar contexts in the corpus. Table 1
lists the values of the word2vec parameters used in
this experiment.
Table 1: Parameter values used for word2vec.
Paramete
r
Value
window size 8
(
default = 5
)
# epochs 15 (default = 5)
# negative samplings 25 (default = 5)
The parameter window size represents the
number of surrounding words that define the
context. The number of surrounding words
required to generate word vectors may vary
depending on the corpus used. In this
experiment, we used text from Japanese
Wikipedia, which includes various topics, as the
corpus. We used a window size larger than the
default value to precisely capture the meanings
of various words appearing in this corpus.
Because the quality of word vectors tends to
improve when the numbers of epochs and
negative samplings are high, these values are set
to be larger than the default values.
2.1.4 Verbs Used in Experiment
The verbs used for the word analogy task in this
experiment were the top 100 verbs that appear
frequently in the corpus. Figure 1 shows a list of these
verbs and their negative words.
2.1.5 Experimental Procedure
In the word analogy task, we first assume that the
word for word
is word
; subsequently, the word
1
https://taku910.github.io/mecab/
Figure 1: List of 100 pairs of Japanese verbs and their
negated words used in experiment.
for word
is obtained, i.e., word
. The experimental
procedures are as follows:
(1) Based on the list shown in Figure 1, select a pair
of verbs and their negative words (e.g. “go” and
“do not go”).
(2) Let the verb selected in (1) be word
and the
negative word of the selected verb be word
.
(e.g., word
= “go,” word
= “do not go”).
(3) Select another pair from the list in Figure 1.
(4) Let the verb selected in (3) be word
and the
negative word of the selected verb be word
.
(5) Using the word vectors generated by word2vec,
obtain the cosine similarity between 𝑣
+
𝑣
−𝑣
and each word vector for all
Japanese words. Next, select the top 10 Japanese
words with the highest cosine similarity.
(6) From the 10 words selected, 1 point is assigned
if word
(i.e., the correct answer) matches the
word with the highest cosine similarity (the first
place word), 0.5 points if it matches the second
place word, and 0.25 points if it matches the
third place word (if it does not match the words
up to the third place, points are not assigned).
(7) Do not modify the pair selected in (1), replace
the pair selected in (3) with another pair, and
repeat steps (4) to (6).
(8) Replace the pair selected in (1) with another
pair, and repeat steps (2) to (7).
2.2 Results
Table 2 shows the experimental results. Each row
corresponds to a specific word analogy task and its
results. Columns A, B, C, and D are word
, word
,
word
, and word
, respectively. Columns E to N
Semantic Entanglement on Verb Negation
73

Table 2: Experimental results (excerpt).
Table 3: Summary of experimental results (part of entire table).
Table 4: Summary of experimental results (entire table).
DATA 2021 - 10th International Conference on Data Science, Technology and Applications
74
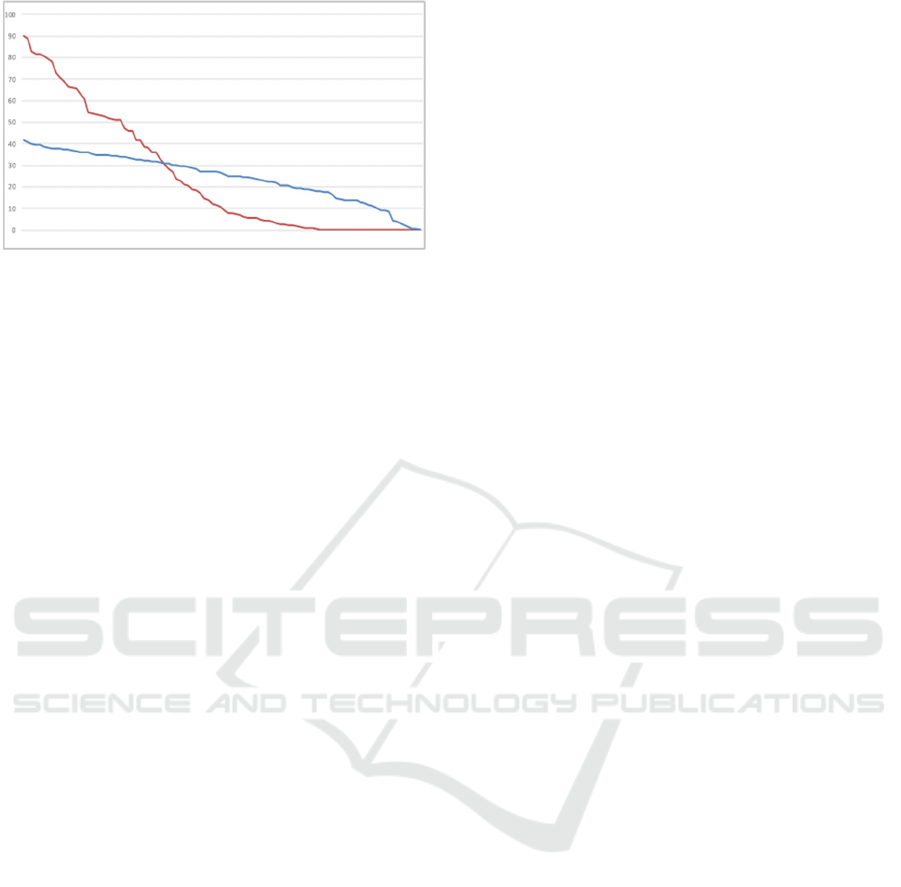
Figure 2: Plot of vertical sums of points (red graph); plot of
horizontal sums of points (blue graph) in Table 3.
show a ranked list of words from the 1st to 10th in the
descending order of cosine similarity with 𝑣
+
𝑣
−𝑣
. The words in the blue cells
matched with the correct answers (i.e., they matched
with word
). The numerals in the rightmost column
show the points earned based on step (6). It is
noteworthy only the partial results are shown in Table
2, whereas the overall results were obtained in the
same format.
Table 4 is a summary of Table 2, with the pair of
word
and word
in column C, and the pair of
word
and word
in the third row. Table 3 shows an
enlarged version of the top three rows and the lower
rows of the left part of Table 4.
For example, in cell E84 of Table 3 where row
84 and column E coincide, word
and word
are “become” and “do not become,”
respectively, and word
and word
are “exist”
and “do not exist,” respectively. In this setting
for the word analogy task, the point earned is
1.0, as indicated in cell E84; this means that the
first place word matches the correct answer.
In Tables 3 and 4, cells with values of 1, 0.5, and
0.25 are indicated in pink, light blue, and light
green, respectively.
The numerals in the bottom row cells of Tables
3 and 4 are the total scores, i.e., the vertical sums
of the points. Additionally, pair word
and
word
in the third row are sorted from left to
right in the descending order of their total
scores.
The maximum value of the total scores is 99
because the 100 pairs of verbs and their negation
shown in Figure 1 are used to generate a word
analogy task alternately.
Owing to space limitations, the right side of
column AZ is not shown in Table 3; however,
the horizontal sums of the points were
calculated. Pair word
and word
in column C
were sorted from top to bottom in the
descending order of the sums.
The numerals in the first and second rows are
the ranking of word
among 100 verbs and the
ranking of word
among 100 verb negations
used in the experiment with respect to the
number of occurrences in the corpus,
respectively. Similarly, the ranking of word
among 100 verbs and the ranking of word
among 100 verb negations are shown in
columns A and B, respectively. The red and blue
cells indicate the top and bottom 30 rankings,
respectively.
2.3 Discussion
In Figure 2, the red graph is a plot of the vertical sums
of the points shown in Table 4, and the blue graph is
a plot of their horizontal sums. We observed that the
red graph varied more significantly than the blue one.
This implies that the difficulty of the word analogy
task depends primarily on word
and word
rather
than word
and word
.
Therefore, we focused on word
and word
. As
shown in the second row of Table 4, many cells on
the left side are red, whereas many cells on the right
side are blue. Because the red and blue cells in the
second row indicate high and low frequencies of
word
occurrence, respectively, if word
appears
frequently in the corpus, then the vertical sum of the
points tends to be large, and vice versa. Furthermore,
if word
appears frequently in the corpus, then the
word vector of word
generated by word2vec is
sufficiently precise to return a correct response to the
word analogy task. Therefore, the vertical sum of
points can be interpreted as a success indicator for the
word analogy task.
In this experiment, the top 100 verbs that appear
frequently in the corpus were used as word
, and the
word vector of word
generated by word2vec should
always be precise.
However, the right side of the second row in
Table 4 contained red cells, where the vertical sum of
the points indicated a low value. These red cells
reflect the difficulty of the word analogy task despite
the high occurrence frequency of word
in the
corpus.
Semantic Entanglement on Verb Negation
75

3 STUDY OF SURROUNDING
WORDS
In the previous section, we mentioned that word
analogy tasks are often difficult, although word
(i.e., the verb) and word
(negation of the verb)
appear frequently in the corpus. We presume that the
difficulty emerges from the words around word
and
word
because word2vec generates a word vector
using the surrounding words. Therefore, we analyzed
the surrounding words of word
, i.e., the red cells in
the second row of Table 4. Furthermore, we analyzed
the words surrounding word
paired with word
.
The surrounding words are the two words
preceding the word of interest. We analyzed the two
preceding words because in Japanese, words that
describe verbs appear immediately before the verbs.
3.1 Method
For pair word
and word
, the following procedures
were used:
(1) Let Surrounding
be a set of surrounding
words for word
, and Count
𝑤
be the
number of co-occurrences of the surrounding
word 𝑤 ∈ Surrounding
with word
in the
corpus. For word
, we calculated the total
number of co-occurrences, TotalCount
=
∑
Count
𝑤
. For example, when word
=
“come” (= “ 来 る” in Japanese),
TotalCount
= 8533.
(2) For the word 𝑤 ∈ Surrounding
, calculate the
probability that 𝑤 co-occurs with word
, i.e.,
Prob
𝑤
=Count
𝑤
÷TotalCount
. For
example, when word
= “come,” because the
word “out” co-occurs with “come” 236 times,
Prob
(“out”) = 236 ÷ 8533 ≒ 0.028.
(3) Let Surrounding
be a set of surrounding
words of word
, and Count
𝑤
be the
number of co-occurrences of the surrounding
word 𝑤 ∈ Surrounding
with word
in the
corpus. For word
, we calculated the total
number of co-occurrences, TotalCount
=
∑
Count
𝑤
. For example, when word
=
“do not come” (= “ 来 ない” in Japanese),
TotalCount
= 915.
(4) For the word 𝑤 ∈ Surrounding
, calculate the
probability that 𝑤 co-occurs with word
, i.e.,
Prob
𝑤
=Count
𝑤
÷TotalCount
. For
example, when word
= “do not come,”
because the word “out” co-occurs with “do not
come” 63 times, Prob
(“out”) = 63 ÷
915 ≒ 0.069.
(5) For the word 𝑤 ∈ Surrounding
∪
Surrounding
, compare the values of
Prob
𝑤
and Prob
𝑤
to identify the
smaller value. Subsequently, the total value
HistIntersect =
∑
minProb
𝑤
,Prob
𝑤
is calculated. In other words, the histogram
intersection of the two discrete probability
distributions, Prob
𝑤
and Prob
𝑤
, is
calculated. The larger the value of HistIntersect,
the more likely is the verb and its negated word
to share the surrounding words, i.e., the verb and
its negated word are more likely to be used in
the same context.
3.2 Results
The results of this study are summarized in Table 5.
Columns B, C, and D contain word
, word
, and
HistIntersect, respectively. Column A contains the
vertical sum of the points in Table 4 for pair word
and word
, i.e., a success indicator of the word
analogy task. As presented in Table 5, the value of
HistIntersect tends to be large for pair word
and
word
, whose success indicator of the word analogy
task is high.
3.3 Discussion
We discovered that the word analogy task is easy
when a verb and its negative word share the same
surrounding words, that is, when they are used in the
same context. For example, the word that appears
most frequently as a surrounding word for “come” is
“out,” which is the most frequently used word around
“do not come” as well. Specifically, the expressions
“come out” (= “出て来る” in Japanese) and “do not
come out” (= “出て来ない” in Japanese) appear
frequently in the corpus. When expressions in which
the verb can be replaced with the negative word of the
verb and vice versa appear frequently in the corpus,
the analogy task is easy.
Conversely, when the surrounding words are only
used with either a verb or its negative word, then the
analogy task becomes difficult. For example, the
word that appears the most frequently as a
surrounding word for the negative word “do not get”
(= “得ない” in Japanese) is “any choice but to do”
(= “せざるを” in Japanese). By contrast, “any
choice but to do” has never appeared as a surrounding
word for “get” (= “得る” in Japanese) in the corpus.
When surrounding words co-occur only with either a
DATA 2021 - 10th International Conference on Data Science, Technology and Applications
76

Table 5: Results of this study.
verb or its negative word (such as in idiomatic
expressions), the analogy task becomes challenging.
4 CONCLUSIONS
We discovered that the following two conditions were
necessary to correctly respond to the word analogy
task for a verb and its negated word:
(1) Both the verb and its negated word appear
frequently in the corpus.
(2) The verb and its negated word share the same
surrounding words, i.e., they are used in the
same context.
In particular, regarding (2), we assumed that the
surrounding words shared by word
and word
represented their base meanings. Moreover, the
operation of 𝑣
−𝑣
canceled the base
meaning, causing only the relation between word
and word
(i.e., negation) to remain. However, if no
surrounding word is shared by word
and word
,
then the operation 𝑣
−𝑣
will not cancel
the base meaning.
In addition, the correct and incorrect responses to
the word analogy task depended on the method of
word vector generation. In this study, word vectors
were generated using the surrounding words defined
by a fixed window. However, the word vectors
changed based on the definition of the surrounding
words. In fact, an attempt to generate word vectors
using an attention mechanism instead of a fixed
Semantic Entanglement on Verb Negation
77

window has been reported (Sonkar et al., 2020).
Furthermore, word vectors can be generated using not
only surrounding words, but also grammatical
information, such as part of speech and conjugations
of words. A future task is to generate word vectors
that can decompose the meaning of each word and the
relation between words with fine granularity.
REFERENCES
T. Brown et al., Language Models are Few-Shot Learners,
In Proc. NeurIPS, 2020.
Y. Wu et al., Google’s neural machine translation system:
Bridging the gap between human and machine
translation, In arXiv preprint arXiv:1609.08144, 2016.
T. Mikolov et al., Efficient estimation of word
representations in vector space, In Proc. ICLR
workshop, 2013.
Z. Harris, Distributional structure, Word, Vol. 10, No. 23,
pp. 146-162, 1954.
J. R. Firth, Papers in Linguistics, Oxford University Press,
pp. 1934-1951, 1957.
K. Yoshii et al., Construction and evaluation of Japanese
word vectors, IPSJ SIG Technical Report, Vol. 2015-
NL-221, No. 4, 2015.
S. Sonkar et al., Attention Word Embedding, In Proc. the
28th International Conference on Computational
Linguistics, pp. 6894-6902, 2020.
DATA 2021 - 10th International Conference on Data Science, Technology and Applications
78
