
Exploring Machine-learning Techniques for Early Detection of
Depression from Social Media Posts
Nalini Singh
1
, Rajnish Pandey
1
, Praveen Mishra
1
, Shashank S. Tiwari
2
, Mariya Siddiqui
1
1
IET, Dr. RLAU, Ayodhya, UP, India
2
REC, Ambedkarnagar, UP, India
mariyasiddiqui7388@gmail.com
Keywords: Machine-learning classifiers, SVM, Twitter, Depression
Abstract: Different social media platforms are trendy among all age groups of people. They post their daily activities
regarding the things which have happened to them. People also express their feelings which can be of any
kind, such as depressive, sarcastic, irony, and many more. Identifying depression from those social media
posts is very difficult work. This work has collected a dataset containing depressive and non-depressive
tweets from Twitter and investigated different conventional machine-learning classifiers. Among all
classifiers, the Support Vector Machine (SVM) performs better than the remaining and obtained an F1-score
of 0.89.
1 INTRODUCTION
The smooth access of distinct interpersonal
interaction destinations has empowered anybody to
make effortlessly, express, and offer their thoughts,
musings, conclusions, and emotions about anything
with billions of others around the globe. With the
development of innovations, it's entirely possible to
share your contemplation about anything via online
media stages, for example, Twitter, Wikipedia,
Google, Facebook, Instagram, and so forth.
Our work is based on the data collected from
Twitter about Depression. We found different
situations where a person can go into the depression
state smoothly but coming out of it is very hard
without professional advice or consulting a
psychiatrist. Even though it's a crucial mental issue,
not exactly 50% of the individuals who have this
wistful issue accessed psychological well-being
administrations. Sorrow has gotten one of the
predominant psychological wellness issues. This
could be a consequence of numerous elements,
including having nonattendance of mindfulness
about the sickness. One solution would be to create a
machine that could detect a person's depression even
early. It will help create awareness among people to
maintain good mental health. There may be different
reasons behind a person getting into the depression
state, such as not getting the desired job, due to a
family problem, abusive relationship, constant
disappointment in the examinations, not getting a
healthy working environment, the demise of a loved
one's, some other individual issues and, intake of
excessive medications also leads to depression.
Depression is a great problem in our community
and has continuously been a trending area for
sentiment analysis researchers. It is mainly a mental
disorder in which people become sad without
knowing the reason behind their sadness. People
start forming negative thoughts in their minds; they
could not concentrate on their work correctly, which
creates a sad environment. Depression may cause
mental disorders also. It's a severe crippling disorder
that might negatively affect humans from all
generations, leading to sadness, feeling lonely, and
inability to sleep. It is considered the largest factor
in global disability and a key reason for suicide.
Depression often leads people to commit suicide
because they cannot find a solution. And if it is not
treated, it impacts people's daily lives surrounded by
the individual who's really depressed, as in a family,
in the office, or even in our societies. As per the
World Health Organization (WHO) study in 2018,
over 350 million individuals experienced depression,
and just about 1 million individuals with
wretchedness ended their lives every year. As per
WHO, 4.4% of people are going through a state of
22
Singh, N., Pandey, R., Mishra, P., Tiwari, S. and Siddiqui, M.
Exploring Machine-learning Techniques for Early Detection of Depression from Social Media Posts.
DOI: 10.5220/0010561800003161
In Proceedings of the 3rd International Conference on Advanced Computing and Software Engineering (ICACSE 2021), pages 22-27
ISBN: 978-989-758-544-9
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

depression, which is more common in females than
males. The use of social networks has increased with
the rise in population and communications
technology, and they are being used for many
different purposes. Here we have used these social
networking sites as a source to collect data on
depression. In this research, various methods of
depression prediction are discussed in depth. The
methods involve the collection of a dataset by social
media posted texts. From extracted information, the
result is obtained.
Here, by identifying and extracting emotions
from the text posted through social media (Twitter),
using machine-learning techniques, and natural
language processing (NLP) techniques, we present a
person's level of depression.
Machine-learning procedures might offer some
highlights that can help with analyzing the
interesting examples covered up in digital channels
and cycle them to uncover the state of mentality (for
example, 'joy', 'bitterness', 'outrage', 'uneasiness',
discouragement) among interpersonal organizations'
clients.In this study, we aim to observe the post and
determine if the user is depressed. We can further
detect other mental problems and might be able to
form a mechanism that would assist us with
distinguishing and cutoff despondency dispersion in
interpersonal organizations. This examination abuses
Twitter's data over 10,000 tweets . Different
conventional machine-learning classifiers are
utilized to recognize the depression level, of which
Support Vector Machine (SVM) shows the highest
outcomes, with an exactness of 0.91 and F1-score of
0.89. This paper's remaining portion is as follows:
Section 2 illustrates the related work. Section 3
explains the dataset. Section 4 describes the different
conventional machine-learning classifiers to detect
depression. Section 5 tells us about classification
approach. Section 6 displays the result of the work.
Section 7 is about the discussion. Finally, Section 8
outlines the conclusions and future scope of the
study.
2 RELATED WORK
Alsagri et al. introduced a novel approach based on
the Linear SVM model. It utilizes Linguistic Inquiry
and Word Count (LIWC), sentiment analysis, social
activity, and synonyms and achieved an accuracy of
82.5% on the Twitter dataset. Lin et al. also
performed their study using Reddit user's data. They
employed combined features (LIWC+LDA+
BIGRAM) and N-grams to classify depression
records using Multilayer Perceptron (MLP) model
and scored an accuracy of 91%. Hassan et al. [4]
performed their study on two datasets, the Twitter
dataset, and 20newsgroups. In his investigation, By
noticing and separating emotions from the text,
applying emotion theories, machine learning
techniques, and natural language processing
techniques, he introduced how to discover an
individual's depression level. SVM shows the best
results with an accuracy of 91% in comparison to
Naive Bayes and Maximum Entropy classifiers.
Guntuku et al. introduced a new approach based on
the Neural Network model in which it utilizes N-
grams features and reached an accuracy of 70% on
the Twitter dataset. Arun et al. exhibit a novel
methodology for identifying depression using
clinical information from the on-going Mysore
investigations of Natal consequences for Aging and
Health (MYNAH). The proposed model was
created, utilizing XGBoost and an accuracy of
97.80% by using feature selection on the accessible
information of evaluations with improved certainty.
Khan et al. referenced a framework that predicts and
calculates the Bengali text's sentiment that was
obtained from Facebook. They utilized machine-
learning classifier algorithms to locate the best
exactness and identify the two sorts of groupings as
happy and sad. In the wake of preprocessing the
information, they tokenized the data by utilizing
Countvectorizer. They applied six different
algorithms to foresee the most noteworthy exactness
from that point onward. Among them, the
Multinomial Naive Bayes gave us the most excellent
accuracy of 86.67%. Peng et al. proposed a multi-
kernel SVM-based model. It utilizes three feature
categories: user micro-blog text, user profile, and
user behaviours and gained an accuracy of 83.46%.
Nadeem et al. conducted their study using 2.5M
tweets. He employed features such as bow and
sentiment analysis using the Naive Bayes model and
scored an accuracy of 81%. Jain et al. worked on
two different depressive datasets. One
is based
on the questionnaire and another on
Twitter.
Exploring Machine-learning Techniques for Early Detection of Depression from Social Media Posts
23

Table 1: Some potential work on depression
AUTHOR FEATURES MODEL PER.
AlSagri et
al. [2]
LIWC
Sentiment
Analysis
Social Activity
S
y
non
y
ms
Linear SVM Acc: -
82.5%
Lin et al.
[3]
Combined features
(LIWC+LDA+BIG
RAM)
N-gra
m
Bi-gram
with SVM
Acc: -
91%
Hassan et
al. [4]
N-grams
Parts of Speech
Negation
Sentiment
Anal
y
ze
r
SVM Acc: -
91%
Guntuku
et al. [5]
N-grams Neural
Networ
k
Acc: -
70%
Arun et al.
[6]
Eurotot
Avggrip
HTN
Frifrailtylot
BMI
XG Boost Acc: -
97.80%
Khan et al.
[7]
Countvectorizer Multinomial
Naive Bayes
Acc: -
86.67%
Peng et al.
[1]
TF-IDF Multi-kernal
SVM
Acc: -
83.46%
Nadeem et
al. [8]
Bow
Sentiment Anal
y
sis
Naive Bayes Acc: -
81%
Jain et al.
[9]
Age
Sex
Regularity
TF-IDF etc
XGBoost
Logistic
Regression
Acc(q): -
83.87%
Acc
(Twitter)
: -
86.45%
Asad et al.
[10]
TF-IDF
NLT
K
Naive Bayes Acc: -
74%
They performed different conventional machine-
learning classifiers. Among them, XG Boost
performed better on the first dataset with an
accuracy of 83.87%, and Logistic Regression
performed better on the second dataset with an
accuracy of 86.45% on the Twitter dataset. Asad et
al., in their proposed model, data is gathered from
user posts on two web media sites: Twitter and
Facebook. They employed TF-IDF features on the
Naive Bayes model and scored an accuracy of 74%.
3 DATASET
3.1 Data Collection
To collect depressive tweets, we extract tweets with
hashtags #depression and #sad quotes using Twitter
and manually select English tweets. We also used
other specific words like 'misery', 'unhappiness', and
'sorrow' to collect depressive tweets from this
domain. Out of these collected tweets, depressive
and non-depressive tweets are further manually
separated. To gather more non-depressive tweets, we
extracted tweets with keywords such as 'misery',
'unhappiness', and 'sorrow' which do not contain
hashtags# depression and #sad quotes. Further
English tweets were manually selected from them.
Having only depressive or only non- depressive
tweets from a particular do-main may lead to an
unbiased classification system; therefore, we made
sure that there were both depressive and non-
depressive tweets from each domain.
3.2 Data Processing and Annotation
Tweets are annotated by a group of people fluent in
English. Each tweet is manually annotated for the
presence of depression.
Depression Annotation Each tweet is manually
annotated for the presence of depression using the
tags' YES' and 'NO'. Tweets with the hashtags
#depression are more likely to contain depression.
Tweets that do not include these hashtags are then
manually verified to manage depression. Here is an
example of a tweet (with translation in English) that
contains depression and one that does not:
Tweet: #depressive... I'm very upset.
Depression: YES
Tweet: #normal quotes... I'm very happy.
Depression: NO
Hashtags #depression is randomly deleted from
some tweets which contain depression so that the
dataset includes depressive tweets with the hashtags
#depression and some without the hashtag.
3.3 Dataset Analysis
The dataset consists of 12,029 English tweets, out of
which 5,529 tweets are labelled as depressive and
6,500 non-depressive. The dataset consists of two
types of tweets:
1. Tweets that are depressive but do not contain
hashtags #depression.
2. Tweets containing hashtags but not considered as
depressive.
This sparsity in the corpus also helps develop a
better system for depression detection. The average
length of a tweet is 22.2 tokens per tweet. The
ICACSE 2021 - International Conference on Advanced Computing and Software Engineering
24
detailed descriptions of this dataset can be seen in
table 2.
Table 2: Data Statistics
Class User Collected Dataset
Depressive 5,529
N
on-depressive 6,500
Total 12,029
4 DEPRESSION DETECTION
SYSTEM
For the detection of depression in English tweets, we
have used a baseline classification system in which
word-based features was used to identify the level or
type of depression. Further, these features were
observed via machine-learning techniques to detect
depression.
4.1 Preprocessing
It is a typical practice via online media to utilize
camel cases while writing hashtags. Along these
lines, we extract the hashtags from each tweet and
extract separate tokens from it by eliminating the '#'
and utilizing a hashtag deterioration approach,
accepting it is written in camel case. For example,
we can get 'I', 'Am', and 'Depressive' from
'#IAmDepressive'. URL's mentions, stop words, and
punctuations are taken out from tweets for further
processing.
4.2 Features
Word N-Grams: Word n-gram indicates having or
not having a continuous sequence of n-word or
tokens in a tweet. Word n-grams have been
demonstrated to be valuable features for depression
detection in previous experiments. We consider all
n-grams for estimations of 'n' from 1 to 5. We
consider just those n-grams for features that happen
at least ten times in the corpus to prune the feature
space.
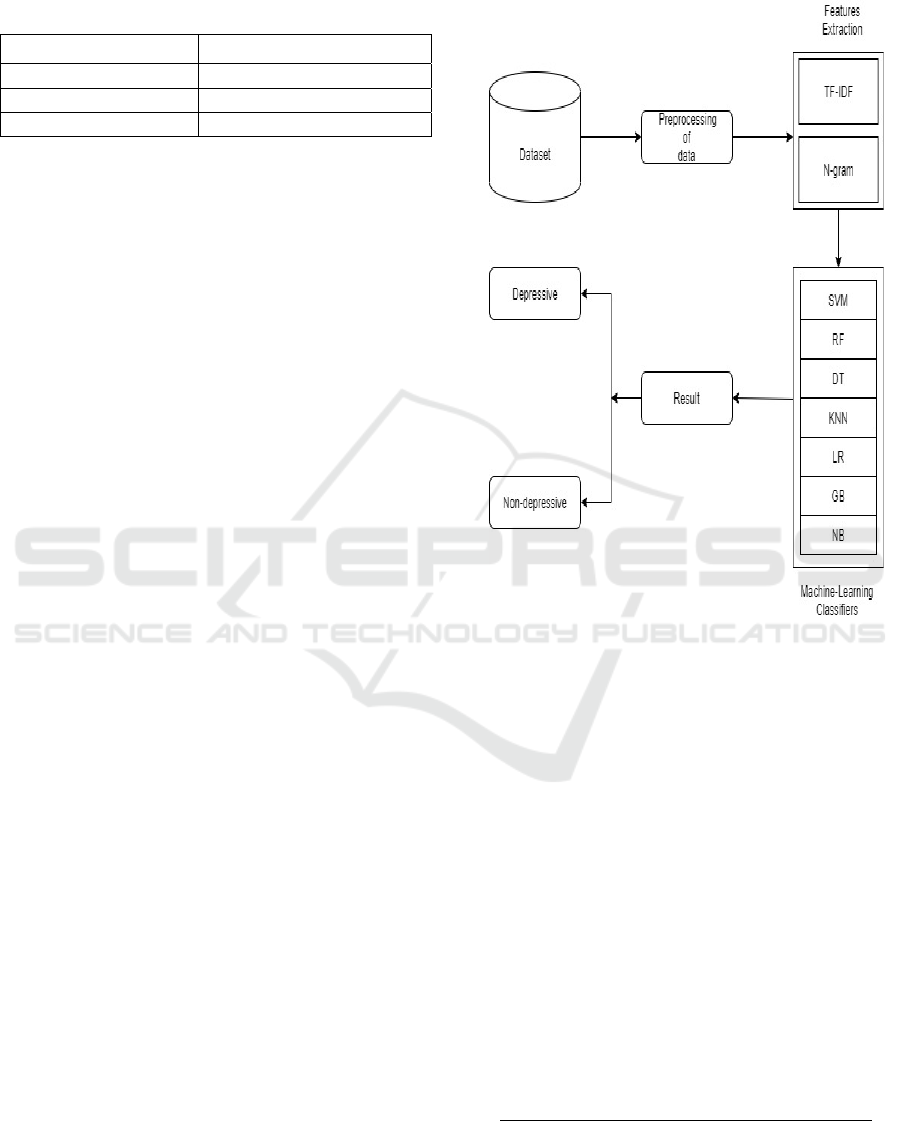
5 CLASSIFICATION APPROACH
We have used seven different conventional machine-
learning classifiers such as Support Vector Machine
(SVM), Random Forest (RF), Decision Tree (DT),
K-Nearest Neighbors (KNN), Logistic Regression
(LR), Gradient Boosting (GB), and Naive Bayes
(NB). We use the scikit-learn implementation of
these methods for depression detection.
Figure 1: Structure of Depression Detection
6 RESULT
On doing extensive experiments on the collected
dataset, it is found that the different conventional
classifiers achieve acceptable performance. The
Support Vector Machine (SVM), Random Forest
(RF), Decision Tree (DT), K-Nearest Neighbors
(KNN), Logistic Regression (LR), Gradient
Boosting (GB) and Naive Bayes (NB) achieves an
F1-score of 0.89, 0.72, 0.79, 0.62, 0.88, 0.81 and
0.84.
The mathematical equations for the precision, recall,
and F1-score can be seen from following equations.
Precision(depressive)=
𝑁𝑢𝑚𝑏𝑒𝑟𝑜𝑓𝑎𝑐𝑐𝑢𝑟𝑎𝑡𝑒𝑙𝑦𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑𝑑𝑒𝑝𝑟𝑒𝑠𝑠𝑖𝑣𝑒𝑠𝑒𝑛𝑡𝑒𝑛𝑐𝑒𝑠
𝑇𝑜𝑡𝑎𝑙𝑛𝑢𝑚𝑏𝑒𝑟𝑜𝑓𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑𝑑𝑒𝑝𝑟𝑒𝑠𝑠𝑖𝑣𝑒𝑠𝑒𝑛𝑡𝑒𝑛𝑐𝑒𝑠
Exploring Machine-learning Techniques for Early Detection of Depression from Social Media Posts
25
Recall(depressive)=
𝑁𝑢𝑚𝑏𝑒𝑟𝑜𝑓𝑎𝑐𝑐𝑢𝑟𝑎𝑡𝑒𝑙𝑦𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑𝑑𝑒𝑝𝑟𝑒𝑠𝑠𝑖𝑣𝑒𝑠𝑒𝑛𝑡𝑒𝑛𝑐𝑒𝑠
𝑇𝑜𝑡𝑎𝑙𝑛𝑢𝑚𝑏𝑒𝑟𝑜𝑓𝑎𝑐𝑡𝑢𝑎𝑙𝑑𝑒𝑝𝑟𝑒𝑠𝑠𝑖𝑣𝑒𝑠𝑡𝑎𝑡𝑒𝑚𝑒𝑛𝑡𝑠
F1-Score=2×
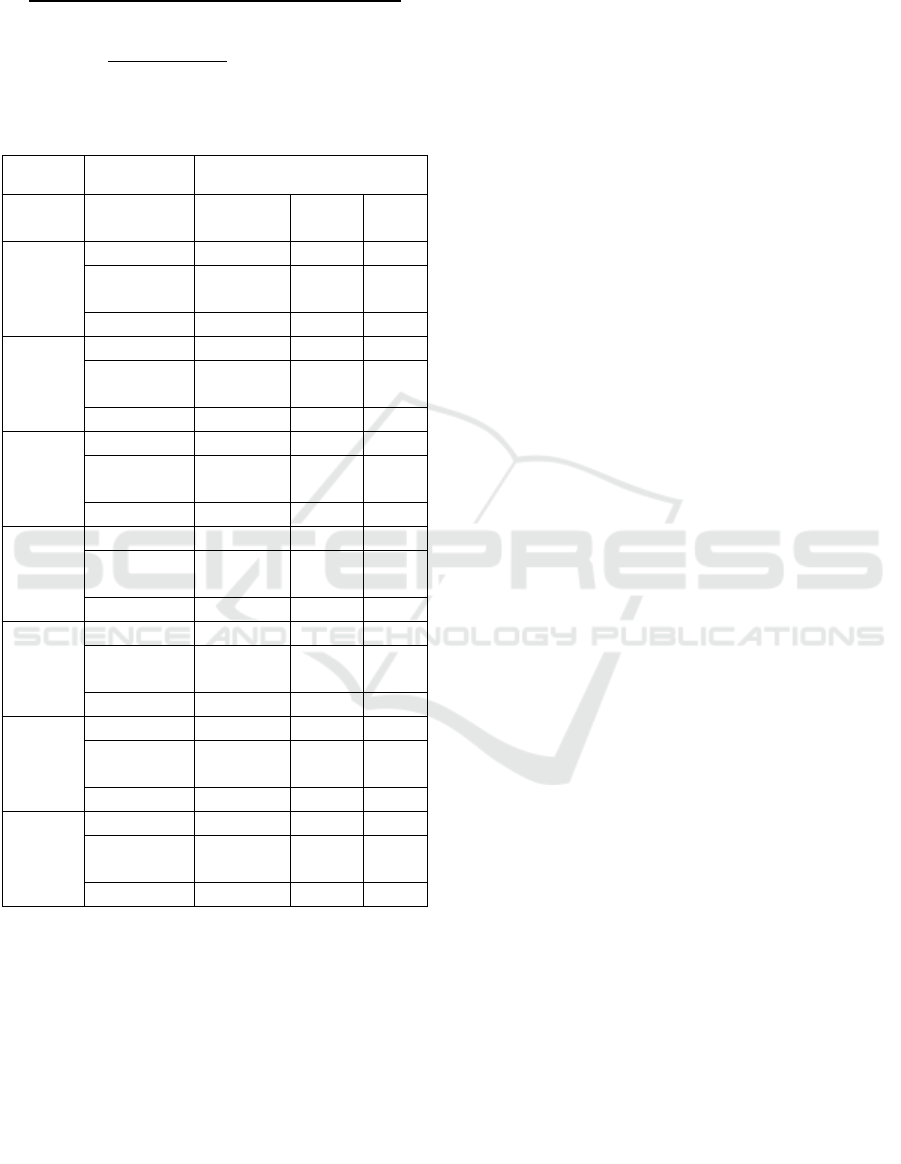
Table 3: Result of Conventional Machine-Learning
Classifiers
Performance
Models Class Precision Recall F1-
score
SVM
Depressive 0.86 0.86 0.86
Non-
depressive
0.91 0.91 0.91
Wei
g
hte
d
0.89 0.89 0.89
RF
Depressive 0.93 0.39 0.55
Non-
depressive
0.71 0.98 0.82
Wei
g
hte
d
0.80 0.75 0.72
DT
Depressive 0.75 0.72 0.73
Non-
depressive
0.82 0.84 0.83
Wei
g
hte
d
0.79 0.79 0.79
KNN
Depressive 0.91 0.23 0.37
Non-
depressive
0.66 0.98 0.79
Wei
g
hte
d
0.76 0.69 0.62
LR
Depressive 0.86 0.84 0.85
Non-
depressive
0.90 0.91 0.90
Wei
g
hte
d
0.88 0.88 0.88
GB
Depressive 0.87 0.63 0.73
Non-
depressive
0.79 0.94 0.86
Wei
g
hte
d
0.82 0.82 0.81
NB
Depressive 0.75 0.91 0.82
Non-
depressive
0.93 0.80 0.86
Wei
g
hte
d
0.86 0.84 0.84
7 DISCUSSION AND
LIMITATIONS
The significant finding of this research is that the
proposed analysis of conventional machine-learning
classifiers is analyzed for identifying depression in
the case of the user-created dataset. From the result
table number: 3, it is evident that the SVM is
performing well as compare to another remaining
conventional machine learning classifier. The SVM
achieved an F1-score of 0.89. Whereas in the case of
KNN classifier is achieved an F1-score of 0.62 that
is worst among all conventional machine-learning
classifier. The recall of 0.89 for the depressive class
means that the SVM can identify depressive
symptoms in 87 cases out of depressive tweets.
Several similar works [12, 13, 14 and 21] are
also reported for identifying depressive sentences
from Twitter.
Alsaleem et al. [22] proposed a new technique
based on the SVM model. It utilizes features such as
Arabic prefixes, pronouns and prepositions and
achieved an accuracy of 77.8% on the Arabic
dataset.Liparas et al. [15] proposed a model in which
the data is collected from the News Articles. They
employed N-gram and (Textual + Visual features)
on the Random Forest model and scored an accuracy
of 86.2%. Hussain et al. [16] employed feature
Frequency Counter of Ambiguous Keywords and
Valid features using the decision tree model and
gained an accuracy of 75.7%.
One of the limitations of this work that is that we
have only used English language sentences to train
our model. However, several depressive messages
are also posted in regional languages on social
media. Another limitation of this work is that we
have only used textual content from the tweets to
identify the depressive sentences. Social media post
also contains emoji's, hyperlinks images and videos,
which are not taken into accounts in the current
research.
8 CONCLUSION
Identifying depression from the textual contents is
challenging in the natural language processing area.
The performance of the SVM outperforms several
conventional machine-learning classifiers. The
current research can also be extended to include the
other modalities present in a social media post, such
as images, videos, and audio clips. The inclusion of
emoji’s and other hyperlinks present in a social
media post can also be validated.
REFERENCES
Peng, Z., Hu, Q. & Dang, J. Multi-kernel SVM based
depression recognition using social media data. Int. J.
Mach. Learn. & Cyber. 10, 43–57 (2019).
arXiv:2003.04763v1 [cs.SI]
ICACSE 2021 - International Conference on Advanced Computing and Software Engineering
26

M. M. Tadesse, H. Lin, B. Xu and L. Yang, "Detection of
Depression-Related Posts in Reddit Social Media
Forum," in IEEE Access, vol. 7, pp. 44883-44893,
2019, doi: 10.1109/ACCESS.2019.2909180.
A. U. Hassan, J. Hussain, M. Hussain, M. Sadiq and S.
Lee, "Sentiment analysis of social networking sites
(SNS) data using machine learning approach for the
measurement of depression," 2017 International
Conference on Information and Communication
Technology Convergence (ICTC), Jeju, 2017, pp. 138-
140, doi: 10.1109/ICTC.2017.8190959.
Sharath Chandra Guntuku, David B Yaden, Margaret L
Kern, Lyle H Ungar, Johannes C Eichstaedt, Detecting
depression and mental illness on social media: an
integrative review, Current Opinion in Behavioral
Sciences, Volume 18, 2017, Pages 43-49, ISSN 2352-
1546, https://doi.org/10.1016/j.cobeha.2017.07.005.
V. Arun, P. V., M. Krishna, A. B.V., P. S.K. and S. V., "A
Boosted Machine Learning Approach For Detection of
Depression," 2018 IEEE Symposium Series on
Computational Intelligence (SSCI), Bangalore, India,
2018, pp. 41-47, doi: 10.1109/SSCI.2018.8628945.
M. R. H. Khan, U. S. Afroz, A. K. M. Masum, S. Abujar
and S. A. Hossain, "Sentiment Analysis from Bengali
Depression Dataset using Machine Learning," 2020
11th International Conference on Computing,
Communication and Networking Technologies
(ICCCNT), Kharagpur, India, 2020, pp. 1-5, doi:
10.1109/ICCCNT49239.2020.9225511.
arXiv:1607.07384v1 [cs.SI]
S. Jain, S. P. Narayan, R. K. Dewang, U. Bhartiya, N.
Meena and V. Kumar, "A Machine Learning based
Depression Analysis and Suicidal Ideation Detection
System using Questionnaires and Twitter," 2019 IEEE
Students Conference on Engineering and Systems
(SCES), Allahabad, India, 2019, pp. 1-6, doi:
10.1109/SCES46477.2019.8977211.
N. A. Asad, M. A. Mahmud Pranto, S. Afreen and M. M.
Islam, "Depression Detection by Analyzing Social
Media Posts of User," 2019 IEEE International
Conference on Signal Procesing, Information,
Communication & Systems (SPICSCON), Dhaka,
Bangladesh, 2019, pp. 13-doi:
10.1109/SPICSCON48833.2019.9065101.
arXiv:1805.11869v1 [cs.CL]
E. Lunando and A. Purwarianti, "Indonesian social media
sentiment analysis with sarcasm detection," 2013
International Conference on Advanced Computer
Science and Information Systems (ICACSIS), Bali,
2013, pp. 195-198, doi:
10.1109/ICACSIS.2013.6761575.
Mondher Bouazizi and TomoakiOhtsuki. 2015. Opinion
Mining in Twitter How to Make Use of Sarcasm to
Enhance Sentiment Analysis. In Proceedings of the
2015 IEEE/ACM International Conference on
Advances in Social Networks Analysis and Mining
2015 (ASONAM '15). Association for Computing
Machinery, New York, NY, USA, 1594–1597.
DOI:https://doi.org/10.1145/2808797.2809350
K. Parmar, N. Limbasiya and M. Dhamecha, "Feature
based Composite Approach for Sarcasm Detection
using MapReduce," 2018 Second International
Conference on Computing Methodologies and
Communication (ICCMC), Erode, 2018, pp. 587-591,
doi: 10.1109/ICCMC.2018.8488096.
Liparas D., HaCohen-Kerner Y., Moumtzidou A.,
Vrochidis S., Kompatsiaris I. (2014) News Articles
Classification Using Random Forests and Weighted
Multimodal Features. In: Lamas D., Buitelaar P. (eds)
Multidisciplinary Information Retrieval. IRFC 2014.
Lecture Notes in Computer Science, vol 8849.
Springer, Cham. https://doi.org/10.1007/978-3-319-
12979-2_6
I. Hussain, O. Ormandjieva and L. Kosseim, "Automatic
Quality Assessment of SRS Text by Means of a
Decision-Tree-Based Text Classifier," Seventh
International Conference on Quality Software (QSIC
2007), Portland, OR, 2007, pp. 209-218, doi:
10.1109/QSIC.2007.4385497.
Desjarlais, Robert R. World mental health: Problems and
priorities in low-income countries. Oxford University
Press, USA, 1995.
Murray, C. J., Lopez, A. D., & World Health
Organization. (1996). The global burden of disease: a
comprehensive assessment of mortality and disability
from diseases, injuries, and risk factors in 1990 and
projected to 2020: summary. World Health
Organization.
P. V. Narayanrao and P. Lalitha Surya Kumari, "Analysis
of Machine Learning Algorithms for Predicting
Depression," 2020 International Conference on
Computer Science, Engineering and Applications
(ICCSEA), Gunupur, India, 2020, pp. 1-4, doi:
10.1109/ICCSEA49143.2020.9132963.
Islam, M.R., Kabir, M.A., Ahmed, A. et al. Depression
detection from social network data using machine
learning techniques. Health Inf Sci Syst 6, 8 (2018).
González-Ibánez, Roberto, Smaranda Muresan, and Nina
Wacholder. "Identifying sarcasm in Twitter: a closer
look." Proceedings of the 49th Annual Meeting of the
Association for Computational Linguistics: Human
Language Technologies. 2011.
Alsaleem, S., 2011. Automated Arabic Text
Categorization Using SVM and NB. Int. Arab. J. e
Technol., 2(2), pp.124-128.
M. Bouazizi, T. OtsukiOhtsuki. A Pattern-Based
Approach for Sarcasm Detection on Twitter. In IEEE
Access, vol. 4, pp. 5477-5488, 2016.
Tom'asPt'acek, Ivan Habernal, Jun Hong, Tom'asHercig.
Sarcasm Detection on Czech and English Twitter. In
COLING (2014).
David Bamman, Noah Smith. Contextualized Sarcasm
Detection on Twitter. In International AAAI
Conference on Web and Social Media (2015).
Exploring Machine-learning Techniques for Early Detection of Depression from Social Media Posts
27
