
Fake News Detection using Support Vector Machine
Alpna Patel
1
, Arvind Kumar Tiwari
1
, S. S. Ahmad
2
1
Department of Computer Science & Engineering, Kamla Nehru Institute of Technology, Sultanpur, India
2
KL Ghurair University, Dubai, UAE
Keywords: Natural Language Processing; Fake News Detection; Machine Learning; SVM.
Abstract: Social media is a rich source of information now days. If we look into the dark side of social media, we
observed that fake news is one of the serious issues of society. Fake news is being used to spread false
information over social media platforms. Fake news detection is the substantial area of research in the field
of Natural Language Processing. Thispaper gives the comparative study of well-known machine learning
approaches like Naïve Bayes, SVM, Decision tree classifier, Random Forest, Multinomial NB and Logistic
Regression. The experimental result shows that SVM classifier outperforms the other approaches and
achieved accuracy of 94.93%.
1 INTRODUCTION
Natural Language Processing(NLP) is a subfield of
Artificial Intelligence that concerns about machines
and humans interaction. If we look into the
applications of NLP, there are numerous
applications such as chatboats, social media
monitoring, language translator, sentiment analysis,
fake news detection, voice assistant, grammar
checker and many more.Fake News detection is one
of the substantial applications of Natural Language
Processing.
In a growing phase of social networking sites,
some of the dark sides come into the picture. Fake
news is one of the dark sides of social media. It
became serious issue of society nowadays. Fake
news is about to spread false information over
various social media platforms like facebook,
twitter, instagram, whatsapp etc. In this paper, we
are presenting a survey on fake news detection by
using machine learning classifiers.
2 RELATED WORK
In order to do survey on fake news detection, many
researchers have given their review on machine
learning models in ongoing years. This section
briefly elaborates on the numerous researches,
related to fake news detection by using machine
learning classifiers.
Fake news stands for misleading the information
that comes from different sources. There are various
machine learning algorithms that achieve better
accuracy. In order to do analysis on fake news
detection authors have presented different data
mining perspective (Ruchansky N, 2017). A hybrid
model has been proposed for fake news detection
(Wang Y, 2018).
The authors have presented the novel approach
that representsmulti model fake news detection. This
model can derive event invariant features ( Zhou X,
2019). Xinyi Zhou et. al.has shared fundamental
theories, detection strategies and challenges about
fake news (Granik M, 2017). The authors have
achieved accuracy up to the mark by using naïve
bayes classifier. The authors has shared their views
on the role of social context for fake news detection.
In this paper they discussed the social context that
has been used to spread false information (Shu K,
2019). Social media is a huge source of information
now days. The author F Montiet. al. have proposed a
novel approach for detection of fake news using
deep learning (Monti F, 2019).The authors have
presented a deep neural network method for
detection of fake news. In this paper, they have
presented the three level hierarchal attention
network for accurate and fast detection of fake news
(Singhania S, 2017). The authors have proposed a
novel approach named multi model variational auto
34
Patel, A., Tiwari, A. and Ahmad, S.
Fake News Detection using Suppor t Vector Machine.
DOI: 10.5220/0010562000003161
In Proceedings of the 3rd International Conference on Advanced Computing and Software Engineering (ICACSE 2021), pages 34-38
ISBN: 978-989-758-544-9
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

encoder for fake news detection. They have used
different deep learning techniques to achieve the
better result (Khattar D, 2019).Panet. al have given
the survey on fake new detection using knowledge
graphs (Ravi K,2015).
3 METHODOLOGY
In this paper fake news detection using machine
learning approach such as data collection, data pre-
processing and so on. Data preprocessing contains
different techniques like cleaning, tokenization etc.
3.1 Machine Learning based Approach
This approach is used to predict fake news detection
that is based on trained data sets as well as test
datasets. It uses different Machine learning
algorithms to train the dataset and these trained
models are used for specific purposes. There are two
learning approaches used for training model named
as supervised learning method and unsupervised
learning method (Jeff Z., 2018).
3.1.1 Supervised Learning Approach
This approach is used when there is finite number of
classes defined named as positive or negative. It uses
labelled dataset for training purpose. Decision tree
algorithm, Artificial neural network, Random forest,
Regression, Logistic Regression, Support Vector
Machine, Nearest Neighbour, Naïve Bayes, are the
several supervised learning algorithms.
3.1.2 Unsupervised Learning Method
This method does not require labelled datasets and it
is work on document- level SA. The aim is to
identify semantic orientation in given phrase.
Partitioning clustering is the unsupervised learning
algorithm.
3.2 Data Collection
This is very initial and important phase in order to
perform fake news detection. Now a day, there are
various freely available data sources that are public
to everyone such as twitter dataset for analysis.
Apart from this, data can be acquire from different
world wide web, social media sites like twitter,
facebook, instagram and online blogging sites and
many more. These websites contains large amount
of data that is used to perform analysis. This dataset
contains two parts of data i.e fake news and real
news. This dataset includes 21418 numbers of data
on true news and 23503 numbers of data on fake
news from the kaggle website (Khattar D, 2019).
This datasets used for the detection of fake news by
using different machine learning approach.
3.3 Data Pre-processing
Data preprocessing method includes different
essential phases such as data cleaning, data
formatting and many more. The data sources contain
raw information that is preprocessed by applying
some data formatting and cleaning process (Shu K,
2017). There are some preprocessing techniques
available named as tokenization, stemming, feature
extraction, POS (part of speech) tagging, stop word
removal and so on. In this research paper, we used
preprocessing techniques for cleaning dataset. The
detail information is following:
3.3.1 Tokenization
It is the procedure of breaking the sentences into
phrases, symbols, words and other meaningful
tokens. This process is done by applying different
open source tools such as Natural Language
Processing Tokenizers.
3.3.2 Stemming
The sentence or document contains different form of
words like organize, organizing and organizes;
stemming is the procedure of reducing this kind of
word which is in derivationally related form.
3.3.3 Stop Word Removal
The sentence contains stop words. Stop word can be
defined as ‘a’ and ‘the’ in article, ‘he’, ’they’, ’it’ in
pronouns are stop words that leads the complexity in
the process of sentiment analysis. The process of
removing this kind of stop words are stop word
removal process.
3.3.4 Feature Extraction
This procedure is related to extract the most relevant
feature from text to perform sentiment analysis task.
Feature extraction comes under the classification
task. We select different feature from text and train
the different models by using classification methods.
Numerical feature and binary feature are the feature
vector categories that show the frequency
occurrences. Several texts feature is given below:
Fake News Detection using Support Vector Machine
35

N-grams: It shows the frequently occurred letters or
words in given text. It is categorized into unigram
(one- word), bigram (two- words) and trigram (more
than two-words).
Stop words: This is other text feature which is
frequently occurred in texts. For example a, the, an,
beside, near, he, she, it, they and so in.
Part of Speech tagging: This term is related to parts
of speech named as adjective, noun, pronoun,
adverb, verb and many more and in a text it holds
the maximum sentiment.
Negation: Negation word shows the negative word
in the text and it is related ‘not’. Some sentences
hold the positive meaning but the negation word
inverts the meaning of whole sentence. For example
‘Biryani is not good’ in this sentence good holds the
positive meaning but not inverts the meaning of
whole sentence.
Table 1: Environmental Setup
Harware and Software specification Configuration
Processor Intel(R) Core (TM) i3-5005U CPU @ 2.00 GHz
Random Access Memory 4.00 GB
System Type 64 bit
Operating System Windows 7
Development Environment
Anaconda 2.0.0
Keras
Table 2: Confusion Matrix
Label 1 (Predicted) Label 2 (Predicted)
Label 1 (Actual) Tn Fp
Label 2 (Actual) Fn Tp
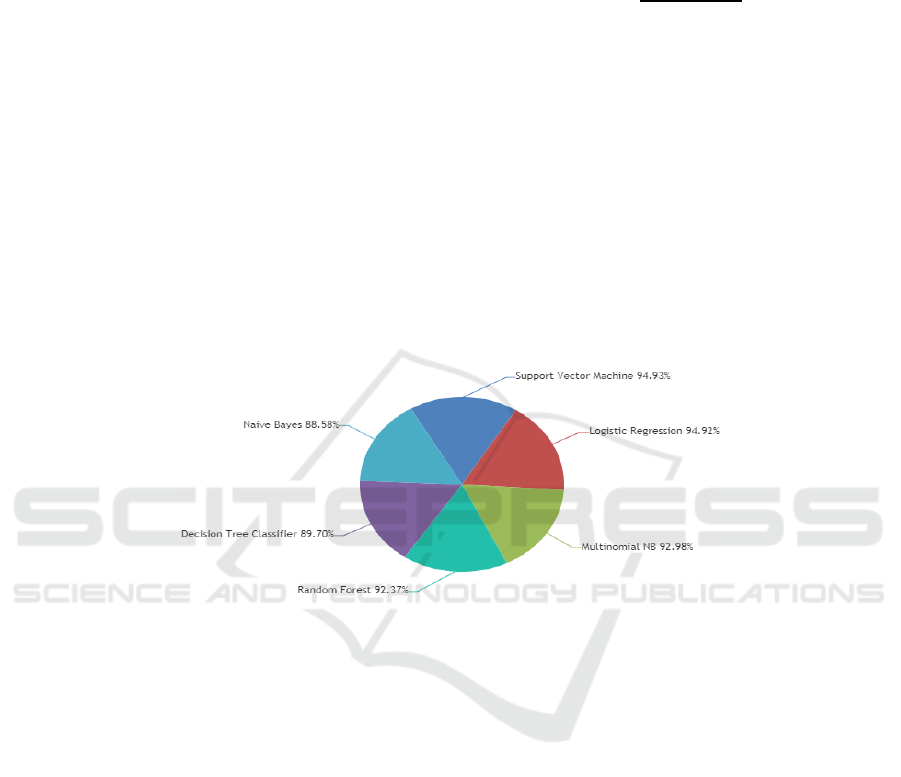
Table 3: Accuracy Comparison of Machine Learning Approach for Fake News Detection
S.No. Models Accuracy(%) Precision(%) Recall(%) F-1 Score(%)
1. NB 88.58 93.99 93.26 93.62
2.
Decision Tree
Classifie
r
89.70 89.90 90.79 90.34
3. Random Forest 92.37 92.38 93.33 92.85
4. Multinomial NB 92.98 93 92 93
5.
Logistic
Regression
94.92 92.99 95.61 94.28
6. SVM 94.93 93.98 96.04 94.99
3.4 Support Vector Machine
Support Vector Machine is a supervised learning
method. It is a classification as well as regression
algorithm that is used to find a hyperplane in an N-
dimensional space (n is number of features you
have). SVM is based on discrimination. Support
vectors represent datapoints that are closet to
hyperplane.
4 RESULTS AND DISCUSSION
This section provide the briefly information about
the experimental setup and measures the
performance of machine learning models. The
following subsection represents detailed overview of
experimental setup, confusion matrix, etc.
ICACSE 2021 - International Conference on Advanced Computing and Software Engineering
36
4.1 Environmental Setup and
Parameter Setting
Anaconda is a package provider for machine
learning models by using python language.
Tensorflow is the framework that provides the
environment for machine learning models. In this
survey paper, we have used python version 3.6.5,
jupyter notebook and keras for implementing
machine learning models for analysis. Keras is the
higher level API that is use tensorflow in backend
and it is used for sequential modeling. The detail has
given in below Table I.
4.2 Performance Measure
In order to evaluate the performance of the machine
learning model, a confusion matrix has been used
that contains some parameters such as Tp as true
positive, Tn as true negative, Fp as false positive,
and Fn as false negative on test data. The confusion
matrix is given in Table II.
The formula for calculating accuracy is given
below:
Accuracy=
்ା்
்ା்ାிାி
X 100%
The parameter accuracy is used to validate machine
learning model by using the test set and validate set.
The Table III presents the comparative study of
machine learning classifier.
The table III shows the comparative study of
machine learning approaches for fake news
detection. It contains the result analysis in the form
of accuracy, precision, recall and F-1 score. If we
look into the analysis process, we found that SVM
performs better compare to other approaches. This
analysis shows that SVM achieve the accuracy
94.93%. The below chart shows the graphical
representation of result analysis.
Figure 4.1: Summary of Machine Learning Approaches for Fake News detection
5 CONCLUSION
Fake news is being used to spread false information
over social media platforms. Fake news detection is
the substantial area of research in the field of Natural
Language Processing. This paper provided the
comparative analysis of machine learning
approaches for fake news detection. To do the
analysis process, this paper used fake and real news
dataset. This paper provided the comparative
analysis of well-known machine learning approaches
like Naïve Bayes, SVM, and Decision tree classifier,
Random Forest, Multinomial NB and Logistic
Regression. The experimental result showed that
SVM classifier outperforms the other approaches
and achieved accuracy of 94.93%.
REFERENCES
Granik M, Mesyura V. Fake news detection using naive
Bayes classifier. In2017 IEEE First Ukraine
Conference .
Khattar D, Goud JS, Gupta M, Varma V. Mvae:
Multimodal variationalautoencoder for fake news
detection. InThe World Wide Web Conference 2019
May 13 (pp. 2915-2921).
Monti F, Frasca F, Eynard D, Mannion D, Bronstein MM.
Fake news detection on social media using geometric
deep learning. arXiv preprint arXiv:1902.06673. 2019
Feb 10.
Pan, Jeff Z., et al. "Content based fake news detection
using knowledge graphs." International semantic web
conference. Springer, Cham, 2018.
Ravi K, Ravi V. A survey on opinion mining and
sentiment analysis: tasks, approaches and applications.
Knowledge-Based Systems. 2015 Nov 1;89:14-46.
Ruchansky N, Seo S, Liu Y. Csi: A hybrid deep model for
fake news detection. In Proceedings of the 2017 ACM
Fake News Detection using Support Vector Machine
37

on Conference on Information and Knowledge
Management 2017 Nov 6 (pp. 797-806).
Shu K, Sliva A, Wang S, Tang J, Liu H. Fake news
detection on social media: A data mining perspective.
ACM SIGKDD explorations newsletter. 2017 Sep
1;19(1):22-36.
Shu K, Wang S, Liu H. Beyond news contents: The role of
social context for fake news detection. InProceedings
of the Twelfth ACM International Conference on Web
Search and Data Mining 2019 Jan 30 (pp. 312-320).
Singhania S, Fernandez N, Rao S. 3han: A deep neural
network for fake news detection. InInternational
Conference on Neural Information Processing 2017
Nov 14 (pp. 572-581). Springer, Cham.
Wang Y, Ma F, Jin Z, Yuan Y, Xun G, Jha K, Su L, Gao
J. Eann: Event adversarial neural networks for multi-
modal fake news detection. InProceedings of the 24th
acmsigkdd international conference on knowledge
discovery & data mining 2018 Jul 19 (pp. 849-857).
Zhou X, Zafarani R, Shu K, Liu H. Fake news:
Fundamental theories, detection strategies and
challenges. InProceedings of the twelfth ACM
international conference on web search and data
mining 2019 Jan 30 (pp. 836-837).
ICACSE 2021 - International Conference on Advanced Computing and Software Engineering
38
