
Inferring Delay Discounting Factors from Public Observables:
Applications in Risk Analysis and the Design of Adaptive Incentives
Adam Szekeres and Einar Snekkenes
Department of Information Security and Communication Technology,
Norwegian University of Science and Technology - NTNU, Gjøvik, Norway
Keywords:
Delay Discounting, Temporal Preferences, Psychological Profile, Information Security Risk Analysis,
Stakeholder Behavior Prediction, Adaptive Incentives.
Abstract:
Decision-makers regularly need to make trade-offs between benefits in the present and the future. Smaller
immediate rewards are often preferred over larger delayed rewards. The concept of delay discounting describes
how rewards further in the future lose their value in comparison to immediate or more proximal rewards.
Empirical evidence shows that people discount future rewards using a hyperbolic function, which gives rise to
preference reversals as the delay between a decision and receipt of the reward increases. People show great
differences in terms of their tendency to discount future benefits. The extent of discounting is characterized
by each individuals’ discounting factor k. This study investigates the extent to which the discounting factor
k can be inferred from publicly observable pieces of information (i.e. ownership of items, habits) linked to
individuals. Data was collected from 331 respondents in an online questionnaire. The analyses show that
37% of the variance can be explained by public observables in the best case, and between 17-33%, when the
predictive model is tested on unseen data. The results contribute to the development of a risk analysis method
within the domain of information security, which currently lacks the temporal dimension when predicting
stakeholder behavior. Furthermore, the results have key implications for the emerging e-health sector, where
individuals’ immediate incentives need to be aligned with long-term societal benefits.
1 INTRODUCTION
Information security-related decisions involve trade-
offs in the dimension of time. Resources need to be al-
located in the present, while their benefits may mate-
rialize in the future. In order to enjoy greater benefits
in the future, immediate, smaller rewards often must
be foregone. For example, a trade-off exists between
gaining immediate gratification from various web ser-
vices (i.e. small immediate reward) and being pro-
tected from future privacy breaches (i.e. greater later
rewards) (Acquisti and Grossklags, 2003). E-health
initiatives aim at reaping the benefits from digitiza-
tion within the health care sector (Eysenbach, 2001).
The health care eco-system is characterized by the
interaction of a large number of stakeholder groups
(e.g. citizens/patients, healthcare professionals, re-
searchers, data analytic and service providers, etc.),
where each group has specific incentives to interact
with the system. Future societal benefits (e.g. en-
hanced drug and treatment research, predictive care,
etc.) are fundamentally dependent on the willingness
of primary data subjects (i.e. citizens or patients) in
the present to share their sensitive health data. The
situation requires that all stakeholder groups perceive
appropriate incentives to cooperate toward collective
goals instead of acting in their individual self-interest
which may result in tragedy of the commons (e.g.
degradation of common pool information resources
by overuse or distrust due to invasion of privacy) (Re-
gan, 2002).
Intertemporal choices are decisions involving
trade-offs among costs and benefits at different times.
The concept of delay discounting refers to the phe-
nomenon where immediate rewards have a higher
value than delayed rewards, giving rise to preferences
which are biased toward the present (Acquisti and
Grossklags, 2003). Individuals can be characterized
by their unique discounting factor k, which governs
the rate at which future rewards lose value. Empir-
ical investigations revealed that the discounting fac-
tor k shows great inter-individual differences and that
such differences are associated with important and
varied health-related and economic outcomes (Kirby
and Marakovi
´
c, 1996; Frederick et al., 2002). There-
fore, the assessment of a decision-maker’s discount-
70
Szekeres, A. and Snekkenes, E.
Inferring Delay Discounting Factors from Public Observables: Applications in Risk Analysis and the Design of Adaptive Incentives.
DOI: 10.5220/0010663400003060
In Proceedings of the 5th International Conference on Computer-Human Interaction Research and Applications (CHIRA 2021), pages 70-80
ISBN: 978-989-758-538-8; ISSN: 2184-3244
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

ing factor k can have useful implications for several
purposes. On one hand it enables the prediction of
decisions across time for the purpose of risk analy-
sis; and on the other hand it can enable the design
of adaptive incentives which take into account inter-
individual differences regarding temporal preferences
in an emerging e-health ecosystem.
1.1 Problem Statement and Research
Question
This paper aims at contributing to the enhancement of
a risk analysis method which is to be applied within
the context of a democratic e-health eco-system in-
volving multiple stakeholders with conflicting incen-
tives. To date, the risk analysis method lacks the
temporal dimension regarding the stakeholder mod-
els, representing a limitation in its behavior predic-
tion capabilities. Thus, the primary objective is to
enhance the risk analysis method, while the second
objective is to propose a method for incentive de-
sign within a e-health context, which takes into con-
sideration stakeholders’ individual differences regard-
ing temporal preferences. Temporal preferences need
to be assessed unobtrusively based on publicly avail-
able pieces of information linked to decision-makers
to reach inaccessible or adversarial subjects. There-
fore, the main research question is as follows:
Research Question: To what extent is it possible to
infer individuals’ discounting factor k based on
publicly available and observable pieces of infor-
mation linked to decision-makers?
The paper is organized as follows: Section 2 pro-
vides an overview about the theoretical and empiri-
cal results related to delay discounting followed by
a presentation of the risk analysis method under de-
velopment. The section concludes with a description
of a democratic e-health ecosystem as an application
domain for the results. Section 3 describes the in-
struments used for data collection, procedures and the
composition of the sample. Section 4 presents the
findings and answers the main research question. Sec-
tion 5 discusses results and their relevance for risk
analysis and the democratic e-health ecosystem. Sec-
tion 6 concludes the paper.
2 RELATED WORK
2.1 Delay Discounting
Patience, self-control, willpower are similar concepts
describing one’s ability to postpone immediate grati-
fication for later, better outcomes. Psychological ex-
periments were conducted about delayed gratification
using marshmallows as rewards for preschool chil-
dren (Mischel et al., 1972). Significant individual dif-
ferences were found among children in their ability to
delay gratification. Follow-up studies with the same
subjects revealed that self-control in preschool chil-
dren was a useful predictor of later outcomes such as
scholastic performance, skills to cope with stress, so-
cial competences, etc. Willpower has been conceptu-
alized as a cognitive skill which can be enhanced and
trained with simple strategies to regulate emotions,
overcome temptations and to become more future-
oriented (Mischel et al., 1989). The concept has been
also incorporated into behavioral economic theories
to improve decision-maker models by including the
temporal dimension. The concept is known as de-
lay discounting characterizing a decision-maker’s im-
pulsivity or present-orientedness. “Delay discount-
ing is a behavioral phenomenon wherein reinforcers
become devalued as a function of their delay to re-
ceipt” (Kaplan et al., 2016). Two models have been
proposed to capture decision-makers’ temporal pref-
erences: exponential discounting and hyperbolic
discounting. Exponential discounting refers to a
constant-rate discounting (constant across delays and
reward amounts), described by the following equa-
tion:
V = Ae
−kD
,
where V is the present value of the delayed reward,
A is the amount of the delayed reward, k is the dis-
counting rate parameter, and D is the delay (Kirby
and Marakovi
´
c, 1996). In contrast, hyperbolic dis-
counting assumes that discounting rates are not con-
stant across delays (higher for small delays and lower
for long delays). Empirical investigations showed that
real-world decision-makers’ behavior is best approx-
imated by a hyperbolic function of the form (Kirby
and Marakovi
´
c, 1996):
V =
A
1 + kD
.
The key implication of hyperbolic discounting is that
it gives rise to temporal preferences for smaller im-
mediate rewards over larger later rewards, but these
preferences change as the delay between the choice
and receipt of rewards increases. Thus, a preference
reversal occurs, such that individuals make choices
in the present that their future-self would prefer not
to have made (Kirby and Marakovi
´
c, 1996). Fig-
ure 1 demonstrates how two rewards (i.e. a Smaller
Earlier Reward (SER) and a Larger Delayed Reward
(LDR)) are discounted across time according to expo-
nential and hyperbolic functions. Preferences remain
stable over time (i.e. SER > LDR for both proximal
Inferring Delay Discounting Factors from Public Observables: Applications in Risk Analysis and the Design of Adaptive Incentives
71
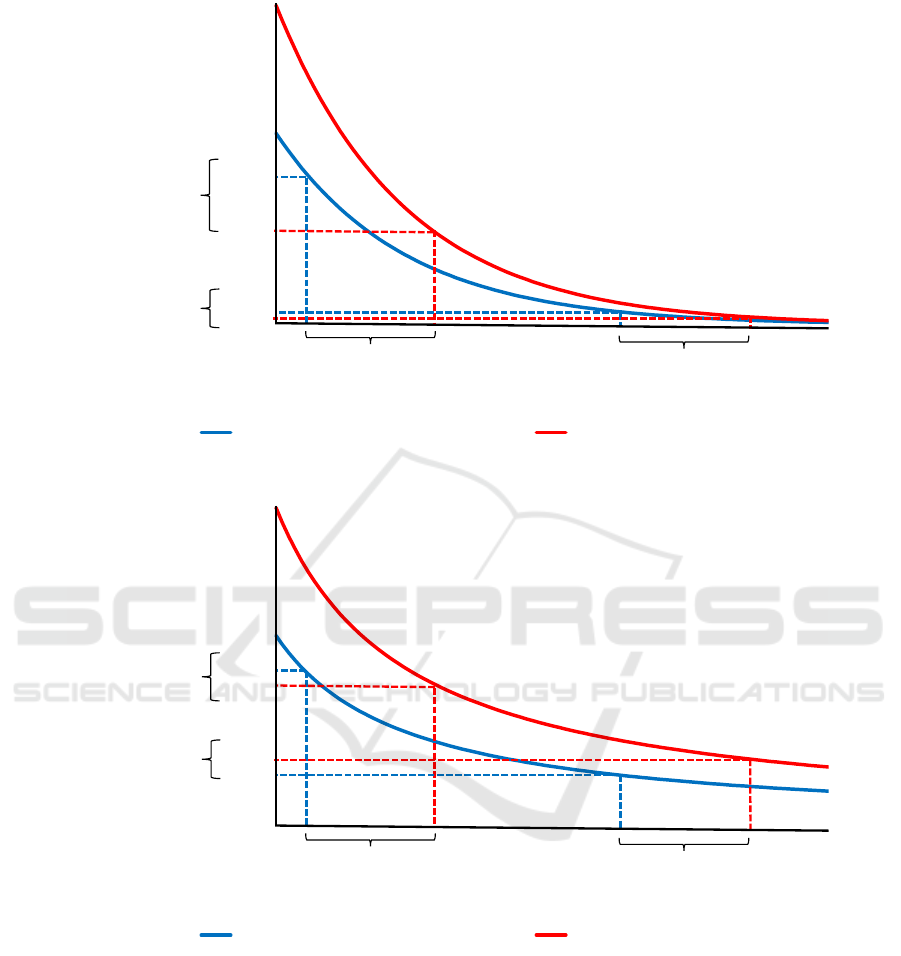
Exponential discounting
smaller earlier reward (SER) larger delayed reward (LDR)
V
LDR
V
SER
V
SER
V
LDR
V >
SER
V
LDR
V >
SER
V
LDR
d
d
PROXIMAL REWARDS
DISTANT REWARDS
Value
Time
(a) Exponential discounting.
Hyperbolic discounting
smaller earlier reward (SER) larger delayed reward (LDR)
V
LDR
V
SER
V
SER
V
LDR
V >
SER
V
LDR
V <
SER
V
LDR
d
d
PROXIMAL REWARDS
DISTANT REWARDS
Value
Time
(b) Hyperbolic discounting.
Figure 1: Exponential and hyperbolic discounting functions adapted from (Kalenscher and Pennartz, 2008). The delay (d)
between options (i.e. SER or LDR), is identical for exponential and hyperbolic functions as well as for proximal and distant
rewards. The amounts of reward (A) and discounting factors (k) are identical for both functions.
and distant rewards) with the exponential function as
shown in Figure 1a. With the hyperbolic function
(Figure 1b), immediate or proximal rewards get dis-
counted more steeply, compared to distant rewards,
resulting in preference for the SER, whereas the LDR
is preferred when a significant delay is introduced be-
tween the choice and receipt of the reward (i.e. pref-
erence reversal occurs: SER > LDR for proximal re-
wards, but SER < LDR for distant rewards).
Delay discounting shows significant inter-
individual differences, and the concept has been
used to explain procrastination (Steel and König,
2006), various addictions (e.g. heroin, alcohol,
tobacco, gambling) where immediate short-term
CHIRA 2021 - 5th International Conference on Computer-Human Interaction Research and Applications
72

rewards are chosen at the expense of larger delayed
rewards (i.e. better health, longevity) (Kirby et al.,
1999). Empirical evidence also shows that people
use different discounting rates in different contexts.
For example, health-related future benefits are dis-
counted at a higher rate than rewards in the monetary
domain (Chapman and Elstein, 1995). Results about
the intra-individual stability of the delay discounting
construct are mixed. While some data suggests that
delay discounting can be assumed as a relatively
stable, enduring trait (Odum, 2011), a more recent
systematic review (Scholten et al., 2019) identified
several studies reporting interventions which success-
fully decreased discounting rates on the short-term.
These results suggest that delay discounting may
better be conceptualized as a state variable.
2.2 Conflicting Incentives Risk Analysis
The Conflicting Incentives Risk Analysis (CIRA) was
developed within the domain of information security
and privacy to simplify the risk analysis procedure by
focusing on human stakeholders and their perceived
incentives (Rajbhandari and Snekkenes, 2013). Risks
within CIRA result from the interdependent relation-
ship between stakeholders, where one person is ex-
posed to the actions or inactions of another person.
Two different stakeholder categories are distinguished
in the game-theoretic framework: risk owner and
strategy owner. Each stakeholder is modelled by
their overall utility using multi-attribute utility the-
ory. Incentives refer to the benefits or losses expected
by a stakeholder when interacting with a system and
other stakeholders. Incentives may be aligned or mis-
aligned. When incentives are misaligned, there is
a risk and every risk is represented by another per-
son’s incentive. Risks are subjective to the person (i.e.
risk owner) being exposed to the conscious choices of
other stakeholders (i.e. strategy owners). Two types
of incentive misalignment are possible. Threat risk
refers to undesirable outcomes for the risk owner and
a potential gain for the strategy owner which resem-
bles the traditional notion of risk referring to unde-
sirable consequences. A ransomware attack on pa-
tient health records can be considered a threat risk
where the patient, or hospital personnel are risk own-
ers, and the hackers motivated by monetary gains are
strategy owners. Incentives can also be misaligned in
a way that results in opportunity risk, where strat-
egy owners lack incentives to act in a desirable way
for the risk owner. For example citizens of e-health
system may lack incentives to share their data (Spil
and Klein, 2014; Sunyaev, 2013), which may result in
suboptimal societal outcomes on the long-term (i.e.
missed opportunities for better treatments, decreased
overall efficiency, etc.). The CIRA method assumes
adversarial and inaccessible stakeholders during the
risk analysis procedure, therefore the method relies
on unobtrusive (i.e. indirect) assessment of personal
attributes of stakeholders to decrease the possibility of
motivated misrepresentation or cheating by the stake-
holders under investigation. Previous work has inves-
tigated the extent to which publicly observable fea-
tures are useful for inferring stakeholder motivational
profiles for the purpose of risk analysis (Szekeres and
Snekkenes, 2020). Another study demonstrated how
unobtrusive psychological profiling can be conducted
using publicly available interviews for the improve-
ment of the CIRA method (Szekeres and Snekkenes,
2019).
2.3 Health Democratization
Healthcare is undergoing radical changes due to dig-
itization. The domain is characterized by a large
number of stakeholders including patients, healthcare
professionals, researchers, industrial players (e.g.
pharmaceutical companies, equipment manufactur-
ers), the authorities, national health insurance, etc.,
each having distinct goals and incentives for interact-
ing with the system (Direktoratet for e-helse, 2018).
Incentive conflicts are inherent is such complex sys-
tems, therefore it is important to identify and miti-
gate risks, so that patients get a favourable deal. The
Norwegian Health Democratization project aims at
reinforcing the health data infrastructure in mobility
and assurance through data democratization (N.A.,
2019). While democracy is a broad concept and sev-
eral ideas can be included, a key democratic aspect
in the project is that all stakeholders will be rep-
resented as equal entities in the protocol, such that
their unique distinguishing features (e.g. market in-
fluence, administrative power, profitability) are dis-
regarded when parties prove, negotiate and configure
their rights w.r.t. health data (N.A., 2019). As the
primary data subjects will have increased possibili-
ties to influence outcomes related to how their data
is used, their willingness to contribute with sensitive
health data is crucial for the expected societal bene-
fits (e.g. cost reduction, improved drug and treatment
discoveries, predictive healthcare, etc.). Another im-
portant democratic aspect is related to the possibility
of choices. The system needs to implement various
opportunities to incentivize data trading for benefit or
profit depending on several factors (e.g. risks, bene-
fits, temporal preferences, etc.). Democratic e-health
initiative’s build on citizen’s active participation in
the decision-making, where patients are treated as
Inferring Delay Discounting Factors from Public Observables: Applications in Risk Analysis and the Design of Adaptive Incentives
73

partners in health-related decision-making (Aaviksoo,
2015). This approach represents a move away from
the traditional paternalistic model of medicine, where
specialized service providers assist both doctors and
patients in a cooperative decision-making. The en-
visaged system will utilize autonomous agent-based
solutions and smart contracts for data sharing, where
agents can represent people, software, or other ap-
plications. Various agents (e.g. patient agent, GP
agent, ambulance agent) will interact with each other
on behalf of their principals. The agents need
to be equipped with negotiation mechanisms, rules
and protocols, strategies and decision-making mod-
els (Boudko and Leister, 2019).
2.4 Summary of Related Work
In a democratic e-health ecosystem patients or citi-
zens considering sharing their data with other entities
can be conceptualized both as risk owners and strat-
egy owners in terms of CIRA using a two-step pro-
cess model. In the first step, a citizen takes the role
of the risk owner and conducts an implicit risk as-
sessment considering risks (e.g. data breaches, ran-
somware attacks, data misuse, etc.) and benefits (e.g.
improved treatment, health monitoring, monetary in-
centives, etc.) associated with sharing sensitive health
data. In the second step, citizens take the role of the
strategy owner and set sharing options, terms and con-
ditions, rules and access rights, etc. depending on the
results of the risk assessment. Such decisions have
a high level of complexity and relative rarity; there-
fore, people are not expected to be skilled in making
these decisions. In such situations people can benefit
from Nudges or other choice architecture approaches
implemented in the system to make socially optimal
decisions (Thaler and Sunstein, 2009). On the larger
scale the main objective is to mitigate the opportunity
risk (i.e. benefits foregone) at the societal level re-
sulting from reluctance of citizens to share their data
which may be due to lack of trust, too high risk or a
lack of incentives. Future societal benefits can only
get realized if decisions in the present are made ac-
cording to long-term preferences, thus adaptive incen-
tive designs need to be developed to match individ-
ual’s discounting profiles with a variety of incentives
offered.
3 METHODS
This section describes the data collection procedures,
the sample and the instruments used for collect-
ing data from participants about personal attributes
(i.e. discounting profiles) and public observables (i.e.
habits, items owned by respondents).
3.1 Sample and Procedure
As the primary purpose of the study was to assess the
usefulness of a large set of publicly observable pieces
of information for the construction of stakeholder dis-
counting profiles (i.e. discounting factor k), it was
necessary to reach a high number of respondents from
the working age population (above 18 years). There-
fore, an online survey was selected as the most ap-
propriate data collection method and invitations were
distributed on several online channels: first, a pilot
study was conducted on Amazon Mechanical Turk
(AMT) to test the feasibility of data collection. Based
on the results of the pilot study, some modifications
were implemented and links to the online survey were
distributed on university mailing lists, and key so-
cial media platforms (Norwegian Facebook groups,
the biggest Norwegian reddit group). The survey was
available in English and Norwegian, and the Norwe-
gian version was proof-read by a professional edito-
rial service. The survey was implemented in the open-
source Limesurvey tool and was hosted on internal
servers provided by the Norwegian University of Sci-
ence and Technology (NTNU). The questionnaire was
completely anonymous, and participants had to read
and accept a consent form before the questionnaire
started upon visiting the link. The number of fully
completed questionnaires is shown in Table 1, orga-
nized according to distribution channels.
Table 1: Number of completed surveys by distribution chan-
nels. AMT: Amazon Mechanical Turk.
Distribution
channel
Number of
completed surveys
AMT 9
Social media 25
University e-mail lists 332
Total 366
Respondents who completed the survey under 10
minutes (average completion time: 23 minutes) were
removed to increase the validity of the dataset. Thus,
the final convenience sample consisted of (n = 331)
respondents (173 males, 153 females, and 5 with un-
known sex). The mean age was 40.28 years (SD =
13.27). Most respondents were from Norway (75%),
while other countries represented 25% of the sam-
ple. Most subjects had a completed Master’s degree
(53%), followed by a PhD (24%), Bachelor’s (16%),
and completed secondary education (7%). Most re-
spondents were married or in a long-term relation-
CHIRA 2021 - 5th International Conference on Computer-Human Interaction Research and Applications
74

ship (71%), followed by singles (24%) and divorced
or separated individuals (5%).
3.2 Measures
The online survey consisted of three main parts fol-
lowing the introduction explaining the purpose of the
data collection:
1. Basic demographic information (age, sex, level of
education, nationality).
2. Behavioral responses for deriving individuals’ de-
lay discounting rates.
3. Publicly observable features linked to the individ-
uals.
3.2.1 Delay Discounting - MCQ-21
The validated 21-item Monetary Choice Question-
naire (MCQ-21) instrument was used for collecting
responses from participants to compute each individ-
ual’s overall discounting factor k. The MCQ-21 is a
self-reporting questionnaire comprising of a set of 21
questions requiring participants to make a choice be-
tween a smaller, immediate reward (SIR) or a larger,
delayed reward (LDR) with monetary values (Kaplan,
2016). The original instructions for the question-
naire: “For each of the next 21 choices, please in-
dicate which reward you would prefer: the smaller
reward tonight, or the larger reward in the specified
number of days. Although you will not actually re-
ceive any of the money, pretend that you will actually
be receiving the amount that you indicate. Therefore,
please answer each question honestly and as if you
will actually receive the amount chosen either tonight
or after a specified number of days. To indicate your
choice, please clearly circle the amount and time as
shown in following example: 0. Would you prefer
$100 tonight, or $100 in 45 days?” (Kaplan, 2016)
were modified so they suit better for the online survey
format. For each question two radio buttons were pro-
vided to make the choice task clear: e.g. $30 tonight
or $85 in 14 days.
Discounting metrics were computed for each re-
spondent using the Excel-based automated scoring
tool, which facilitates the complex computations to
derive the discounting factor k from MCQ-21 (Ka-
plan et al., 2016). The tool reports summary statistics
for the whole sample, checks consistency and outputs
several discounting metrics on the individual level:
overall k, small k, medium k, large k, geomean k (tak-
ing the geometric mean of the small, medium, and
large k values), as well as the log and ln for each of
the k scores. The following analyses use the "overall k
factor" measuring the daily rate at which rewards lose
their value. Rearranging the equation of the hyper-
bolic function gives the formula for the discounting
factor k:
k =
A
V
− 1
D
where V is the smaller, immediate reward; A is the
larger, delayed reward; and D is the delay associated
with A. For a more detailed explanation on deriving
the overall k factor see: (Kaplan et al., 2016).
3.2.2 Publicly Observable Attributes
This section of the questionnaire aimed at collecting
information linked to respondents, which can be eas-
ily observed in most public settings (e.g. work) with-
out direct interaction with the stakeholder. Two cat-
egories of data can be distinguished: ownership of
items and habits. Ownership questions focused on
the presence of attributes, while questions related to
habits were concerned with the frequency of various
actions.
A single choice response format was used to as-
sess the presence of the attributes, and for certain
attributes, additional questions were included to ob-
tain a more detailed description. Question cate-
gories were as follows: real estate (number, loca-
tion, size), car (number, brand, model, type, color, en-
ergy source, unique license plate), motorcycle (num-
ber, brand, type), bicycle (brand, type), boat (brand,
type), phone (brand, model, color, cover, cover color),
laptop (brand, OS, size, camera cover, decoration),
tablet (brand, size), watch (type, brand), headphones
(brand), sunglasses (brand), backpack (brand), brief-
case (brand), jewellery (type, material), wallet (ma-
terial), sport equipment (17 items), pets (7 species
+ other), style description (15 categories), cosmetic
surgery, hair dye, hair length, facial hair, dietary
lifestyle (7 categories), tattoo (general categories,
place of tattoo), social media (existing accounts), pre-
ferred browser, preferred search engine.
Questions related to habits asked the frequency of
various activities on a 9-point response format where
each point had a textual label ranging from 0 - never in
the last 12 months to 8 - every day or nearly every day.
Questions assessed the frequency of: wearing certain
clothes (23 items), doing various sports (17 sports),
listening to music (14 genres), consuming drinks (11
drink types), consuming other products (6 items), en-
gaging in various other activities (26 activities).
4 RESULTS
The final dataset contained valid responses from a
total 331 subjects. The key dependent variable for
Inferring Delay Discounting Factors from Public Observables: Applications in Risk Analysis and the Design of Adaptive Incentives
75

the analysis was individuals’ overall k score. Based
on the automated scoring tool for MCQ-21, descrip-
tive statistics were as follows: Mean overall k scores
= 0.0115, (SD = 0.0235). Overall consistency of
choices was high: 95.6% (SD = 6.21%) showing the
dataset had a high validity, while the overall pro-
portion of LDR (larger delayed reward) chosen was
67.33% (SD = 26.34%), indicating a low general ten-
dency to discount future benefits. Overall k scores
in the present sample were smaller (i.e. evidence of
greater self-control) than the same overall k scores
(Mean = 0.0727, SD = 0.0886) found in a similar-
sized sample (n = 328) with a gambling disorder di-
agnosis (Steward et al., 2017). The computed dis-
counting scores were fed back to the master database,
and independent categorical (i.e. nominal) variables
were dummy coded into indicator variables (where
0 = no/attribute is not present; 1 = yes/attribute is
present). This procedure allows categorical variables
to be included in regression models. The analyses
were performed in SPSS 25 and scikit-learn library
for Python.
The forward selection algorithm was used for con-
structing multiple linear regression models with over-
all k as the single dependent variable and the set of
publicly observable features as predictors in SPSS.
The algorithm is a stepwise feature selection proce-
dure which enters variables into the equation based
on their strength of correlation with the dependent
variable. Criterion for probability of entry was set
to: p ≤ 0.05 and p ≥ 0.1 for exclusion. The pro-
cedure terminated when no more variables met the
criterion of entry (IBM, 2016). Model performance
was evaluated by two metrics provided by SPSS: R
2
- coefficient of determination or the proportion of the
variance in the dependent variable explained by the
set of independent variables in the model; and the ad-
justed R
2
score which penalizes each additional pre-
dictor, providing a more conservative estimate about
the model’s goodness-of-fit. Following the feature se-
lection and model construction procedures the best re-
gression model (F(21, 309) = 6.125, p < 0.00) with an
R
2
= 0.371, adjusted R
2
= 0.311 was found, as shown
in Figure 2. The complete model with the best fit for
predicting the overall k score is provided in Table 2.
Based on the formula for multiple linear regression,
an individual’s overall discounting factor k can be pre-
dicted by:
Y
i
= β
0
+ β
1
X
1
+ ... + β
k
X
k
+ ε
summing the unstandardized β
0
− β
k
coefficients of
the predictors multiplied by the unobtrusively as-
sessed raw scores X
1
− X
k
(using 0-8 for frequency
of habits, and 0-1 for indicator variables) with the rel-
evant ε error terms. All predictors were significant at
p ≤ 0.05. The model can be considered a best-case
scenario, since the metrics only provide information
about the model’s fit, but the error of prediction for
unobserved data is not assessed in this step.
0.371
0.311
0 0.2 0.4 0.6 0.8 1
R-squared
Adj. R-squared
Prediction accuracy of Overall k
Best-case scenario
Upper bound
(95 % CI),
0.33
Mean R-squared,
0.25
Lower bound
(95 % CI),
0.17
0.0 0.2 0.4 0.6 0.8 1.0
Prediction accuracy of Overall k
5-fold cross validation
Figure 2: Prediction accuracy for the overall k discount-
ing factor. Goodness-of-fit metrics (R
2
and Adjusted R
2
)
provide best case scenarios, since error of predicting un-
observed data is not assessed. An R
2
= 1 would indicate
perfect fit of the model.
In order to assess the model’s expected perfor-
mance on unseen data, a 5-fold cross-validation pro-
cedure was conducted. Cross-validation makes it pos-
sible to quantify how well the model performs on un-
seen data (i.e. how well the model generalizes be-
yond the sample used for training the model) (Yarkoni
and Westfall, 2017). Due to the relatively small num-
ber of subjects, a train-test split was performed where
each model was trained on 80% of the original dataset
and performance was tested on the remaining 20% of
data. The dataset was randomized for each run. The
results of the 5-fold cross-validation are presented in
Figure 3. Compared to the best-case scenario the ex-
pected performance of the model on unseen data re-
duces to R
2
: 0.253 +/- 0.079 (with CI 95%), using
the mean of the R
2
scores derived from 5 independent
runs.
4.1 Illustrative Scenarios
In order to illustrate the utility of inferring individu-
als’ discounting factor (k) two simple cases relevant
to the paper’s topic (i.e. prediction of stakeholder be-
havior for risk analysis and adaptive incentives) are
presented. The following examples only focus on dif-
ferences in sensitivity to delayed rewards, while the
security of the e-health system and the risks of data
sharing, etc. are not considered. These critical factors
need to be addressed carefully during the design and
implementation of the system.
In a CIRA-type scenario a CEO of a small or
medium-sized enterprise (strategy owner) needs to
make a choice between taking out an immediate div-
idend or investing in security controls with delayed
benefits. The discounting factor k of the stakeholder
CHIRA 2021 - 5th International Conference on Computer-Human Interaction Research and Applications
76
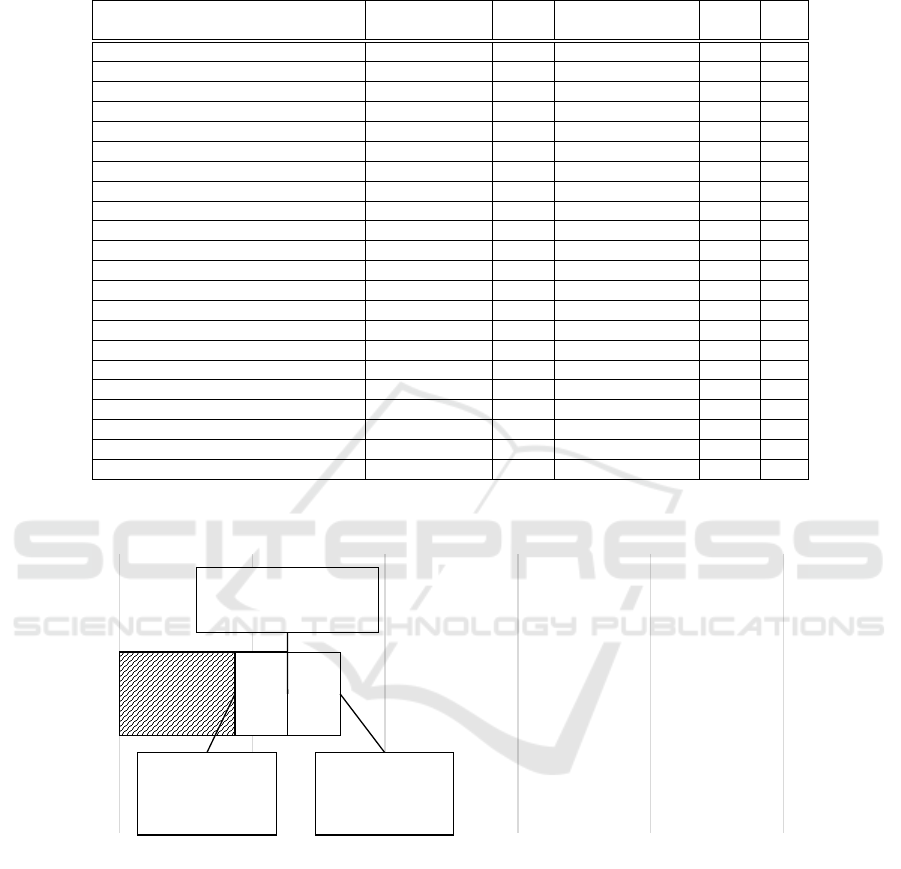
Table 2: Regression model for predicting the overall k discounting factor. Predictors are sorted in order of importance from
most important to least important based on the Standardized β coefficients. Variables assessing frequency of activity are
marked with (freq), dummy variables are marked with (y/n).
Predictors
Standardized β
Coefficients
t
Unstandardized β
Coefficients
Std.
Error
Sig.
Constant 5.516 0.032 0.006 0.00
style: wearing tattoo (y/n)
0.264 4.566 0.025 0.005 0.00
gambling (freq)
0.221 4.453 0.004 0.001 0.00
wearing shorts (freq)
-0.220 -4.478 -0.003 0.001 0.00
going to party (freq)
-0.206 -4.052 -0.003 0.001 0.00
style: facial hair (y/n)
0.173 3.57 0.019 0.005 0.00
listening to blues music (freq)
-0.171 -2.894 -0.002 0.001 0.00
listening to jazz music (freq)
0.163 2.992 0.001 0.000 0.00
ownership of SUV (y/n)
0.156 3.176 0.013 0.004 0.00
going fishing (freq)
0.147 3.046 0.002 0.001 0.00
listening to electronic music (freq)
-0.143 -2.777 -0.001 0.000 0.01
drinking coffee (freq)
-0.139 -2.877 -0.001 0.000 0.00
home location: countryside (y/n)
-0.133 -2.781 -0.012 0.004 0.01
wearing baseball cap (freq)
-0.129 -2.654 -0.001 0.001 0.01
ownership of boat (y/n)
0.127 2.668 0.015 0.005 0.01
watch type: digital (y/n)
0.126 2.636 0.010 0.004 0.01
listening to country music (freq)
0.114 2.168 0.001 0.000 0.03
brand of sunglasses: Ray-Ban (y/n)
0.112 2.334 0.006 0.003 0.02
search engine: other than Google (y/n)
-0.112 -2.358 -0.009 0.004 0.02
no account on Instagram (y/n)
0.104 2.088 0.005 0.002 0.04
phone color: white (y/n)
0.103 2.144 0.010 0.004 0.03
playing football (freq)
0.101 2.047 0.002 0.001 0.04
0.371
0.311
0 0.2 0.4 0.6 0.8 1
R-squared
Adj. R-squared
Prediction accuracy of Overall k
Best-case scenario
Upper bound
(95 % CI),
0.33
Mean R-squared,
0.25
Lower bound
(95 % CI),
0.17
0.0 0.2 0.4 0.6 0.8 1.0
Prediction accuracy of Overall k
5-fold cross validation
Figure 3: Prediction accuracy of overall k based on 5-fold cross-validation in terms of the mean R
2
metric.
is assessed as 0.01 % /day according to MCQ-21. The
bonus (smaller earlier reward - SER) is worth 300k,
while the losses avoided by the investment in controls
(larger delayed reward - LDR) is worth 500k. Us-
ing knowledge about the individual’s discounting rate
k and the amounts of rewards involved, it is possi-
ble to predict the stakeholder’s choices in time. In
this specific case, when a delay of more than 66 days
is present between the SER and the LDR, the person
would chose the smaller earlier reward (i.e. bonus)
and discount the later benefits of protection, meaning
that U
SER
> U
LDR
. If the same choice was to be made
1 day later with the same amount of delay, the prefer-
ences would be reversed so that U
SER
< U
LDR
, where
U refers to the utility of a choice.
Within a democratic e-health system, citi-
zens/patients will exhibit great heterogeneity regard-
ing their delay discounting factors. Based on the as-
sumption, that distant societal benefits fundamentally
depend on the population’s willingness to share their
data in the present, it is reasonable to design adap-
tive incentives, which can be customized based on
Inferring Delay Discounting Factors from Public Observables: Applications in Risk Analysis and the Design of Adaptive Incentives
77

the needs of different individuals. For example, the
willingness to share data with commercial data ana-
lytic providers may be increased by matching incen-
tives based on each individual’s discounting factor. A
citizen with a high overall discounting factor k of 0.2
is more likely to share data in exchange for smaller
immediate rewards (e.g. immediate social approval),
while a patient with a low overall discounting factor
k of 0.01, is more likely to wait for a greater later re-
ward (e.g. a valuable travel voucher). Thus, a demo-
cratic health ecosystem system can be designed which
enables people to exercise freedom of choice with re-
spect to various incentives / business models match-
ing their preferences.
5 DISCUSSION AND FURTHER
WORK
The purpose of this study was to investigate the ex-
tent to which individual’s discounting factor k can
be inferred from publicly observable pieces of infor-
mation. The discounting concept has been shown to
play a significant role in various socially important
behaviors (e.g. substance use disorders, obesity, envi-
ronmental concerns, sexual risks, technology depen-
dence, etc.) (Kaplan et al., 2016). To the authors’
knowledge this is the first study to investigate the ex-
tent of predictability of the discounting factor k from
publicly observable pieces of information.
This online survey-based study collected data
about a broad range of items possessed by subjects
and about their habits. The survey utilized the vali-
dated instrument MCQ-21 and the accompanying au-
tomated scoring tool which facilitates the computa-
tion of several discounting metrics (Kaplan et al.,
2016). The results indicate that the best model is ca-
pable of explaining around 31-37% of the variance in
the overall k scores, and between 17-33% when a 5-
fold cross-validation technique is used to assess how
well the model generalizes beyond the training set.
The results can be applicable in two domains for
different purposes. The primary use of the results
is within the CIRA method, which can be enhanced
with the temporal dimension to predict stakeholder
behavior. Inferring the discounting factor of inac-
cessible and/or adversarial stakeholders from publicly
observable pieces of information can increase the an-
alyst’s capability to assess the action-desirability as
perceived by the stakeholder allowing the prediction
of behavior in the temporal dimension. However,
there is a need to decrease uncertainties in the predic-
tion accuracy which may be achieved by increasing
the number of respondents in subsequent studies and
by including other sets of publicly available pieces of
information.
The other domain where the results are to be uti-
lized is within the Health Democratization project,
where the existence of the right incentives for data
subjects (i.e. citizens, patients) in the present, is
crucial for generating desirable societal outcomes in
the future. People face different risks based on their
needs, expectations and health conditions. In a demo-
cratic healthcare ecosystem where patients are both
risk owners (i.e. facing the risk of data breaches) and
strategy owners (i.e. able to influence outcomes and
make informed decisions), it is important to match in-
centives for data sharing with various personal pref-
erences (e.g. temporal, risk tolerance, etc.). Health
data is being generated by more and more devices and
organizations (e.g. fitness devices and apps, medical
devices in outpatient care settings). Currently the key
incentives for citizens is to access health-related in-
formation generated by wearable devices; receive ser-
vices (e.g. data analytics, health-related recommen-
dations) or get improved care in case of medical mon-
itoring sensors (Baig et al., 2017). The willingness
of data subjects to share or trade health data for other
purposes (e.g. research, profit) needs to be explored
and various incentive mechanisms may be necessary
to facilitate data portability beyond current possibil-
ities. Trust in organizations which generate and col-
lect personal health data is necessary which can be
established by making organizational practices trans-
parent and easy to understand. Allowing people to
make informed choices and opting out of undesirable
data processing activities (e.g. local storage of data)
without negative consequences is important to give
people control over their data and facilitate portabil-
ity (Garmin, 2021). In order to avoid a tragedy of the
commons scenario regarding privacy (Regan, 2002)
in the e-health sector, incentives for all stakeholder
groups (e.g. citizens, commercial actors, regulators)
should be designed so that self-interests are aligned
with societal interests. Future work also needs to in-
vestigate how negotiation agents (Boudko and Leis-
ter, 2019) can be enhanced with information about the
principal’s temporal preferences and other character-
istics to mitigate risks. Future work will also inves-
tigate how various health conditions can be used to
augment risk owner profiles using international clas-
sifications such as the International Statistical Clas-
sification of Diseases and Related Health Problems
(ICD) (WHO, 2021).
It is important to mention that the study is not
without limitations. The sample was a convenience
sample, therefore probabilistic sampling methods
with more subjects would be desirable for future stud-
CHIRA 2021 - 5th International Conference on Computer-Human Interaction Research and Applications
78

ies to increase generalizability. It should be noted
that the instrument (MCQ-21) used for collecting dis-
counting scores is restricted to monetary rewards. As
evidence shows, people tend to use different discount-
ing rates for different contexts (Chapman and El-
stein, 1995), thus the utility of the derived discount-
ing rates outside of the monetary domain is question-
able. Additionally, the MCQ-21 uses relatively small
hypothetical rewards (highest reward is $85), there-
fore the validity of the discounting scores for much
larger rewards needs careful considerations. Other in-
struments focusing on rewards in different domains
and with higher reward values can be used in future
studies as well. Considering that emotions and moral
concerns play a key role in human decision-making,
it is also important to investigate how non-monetary
incentives (e.g. emotional, moral, social) are dis-
counted, and which non-monetary incentives are ap-
plicable in the e-health domain. These questions are
especially relevant since the commercial exploitation
of human biological materials and personal health
data is often seen as morally problematic. However,
the promotion of communal benefit sharing and the
establishment of appropriate regulations (which hin-
der the commodification of the human body) could
render the commercial use of biobanks and health
data more acceptable (Steinsbekk et al., 2013).
Finally, certain principles and ethical standards
need to be considered for incentive-designers. The
potential to abuse information gained from unobtru-
sive measures needs careful attention (e.g. unfair in-
centive schemes). Vulnerable groups (e.g. high dis-
counters) may get offered lower pay-outs and false
incentives if unethical actors infer discounting scores.
Regulations need to be designed with the expectation
that certain actors will try to maximize their benefits
at the expense of other stakeholders in an unfair man-
ner.
6 CONCLUSIONS
Despite increasing levels of digitization in several
domains of life, people are fundamentally respon-
sible and accountable for the decisions which af-
fect themselves and others. E-health represents an
emerging domain where incentive conflicts will be
highly prevalent due to the large number of stake-
holder groups in an interdependent relationship. Un-
derstanding how people overvalue the present at the
expense of the future has key implications for be-
havior prediction within risk analysis using the CIRA
method, and for designing incentives based on indi-
vidual differences in a democratic e-health system,
where individual’s will be active participants with a
desire to make informed decisions related to how their
data is used. Aligning incentives in the present so that
people make decisions which will generate beneficial
outcomes in the future is key to a successful demo-
cratic health eco-system.
ACKNOWLEDGEMENTS
This work was supported by the Health Democratiza-
tion project, funded by the Research Council of Nor-
way, IKTPLUSS program, grant number 288856.
REFERENCES
Aaviksoo, A. (2015). E-Health Brings Democracy to
Healthcare. [Online; accessed 26. May 2021].
Acquisti, A. and Grossklags, J. (2003). Losses, gains, and
hyperbolic discounting: An experimental approach
to information security attitudes and behavior. In
2nd Annual Workshop on Economics and Information
Security-WEIS, volume 3, pages 1–27. Citeseer.
Baig, M. M., GholamHosseini, H., Moqeem, A. A., Mirza,
F., and Lindén, M. (2017). A systematic review
of wearable patient monitoring systems–current chal-
lenges and opportunities for clinical adoption. Journal
of medical systems, 41(7):1–9.
Boudko, S. and Leister, W. (2019). Building blocks of ne-
gotiating agents for healthcare data. In Proceedings
of the 21st International Conference on Information
Integration and Web-based Applications & Services,
pages 635–639.
Chapman, G. B. and Elstein, A. S. (1995). Valuing the
future: Temporal discounting of health and money.
Medical decision making, 15(4):373–386.
Direktoratet for e-helse (2018). Konseptvalgutredning for
helseanalyseplattformen. [Online; accessed 2. Jun.
2021].
Eysenbach, G. (2001). What is e-health? Journal of medical
Internet research, 3(2):e20.
Frederick, S., Loewenstein, G., and O’donoghue, T. (2002).
Time discounting and time preference: A critical re-
view. Journal of economic literature, 40(2):351–401.
Garmin (2021). Privacy policy for Garmin Connect, Garmin
Sports and compatible Garmin devices. [Online; ac-
cessed 16. Jun. 2021].
IBM (2016). Linear Regression Variable Selection Meth-
ods. [Online; accessed 4. Jun. 2021].
Kalenscher, T. and Pennartz, C. M. (2008). Is a bird in the
hand worth two in the future? the neuroeconomics of
intertemporal decision-making. Progress in neurobi-
ology, 84(3):284–315.
Kaplan, B. (2016). 21-item-mcq.pdf. [Online; accessed 2.
Jun. 2021].
Inferring Delay Discounting Factors from Public Observables: Applications in Risk Analysis and the Design of Adaptive Incentives
79

Kaplan, B. A., Amlung, M., Reed, D. D., Jarmolowicz,
D. P., McKerchar, T. L., and Lemley, S. M. (2016).
Automating scoring of delay discounting for the 21-
and 27-item monetary choice questionnaires. The Be-
havior Analyst, 39(2):293–304.
Kirby, K. N. and Marakovi
´
c, N. N. (1996). Delay-
discounting probabilistic rewards: Rates decrease as
amounts increase. Psychonomic bulletin & review,
3(1):100–104.
Kirby, K. N., Petry, N. M., and Bickel, W. K. (1999). Heroin
addicts have higher discount rates for delayed rewards
than non-drug-using controls. Journal of Experimen-
tal psychology: general, 128(1):78.
Mischel, W., Ebbesen, E. B., and Raskoff Zeiss, A. (1972).
Cognitive and attentional mechanisms in delay of
gratification. Journal of personality and social psy-
chology, 21(2):204.
Mischel, W., Shoda, Y., and Rodriguez, M. I. (1989). Delay
of gratification in children. Science, 244(4907):933–
938.
N.A. (2019). Health Democratization – IKTPLUSS NFR
project - NTNU. [Online; accessed 2. Jun. 2021].
Odum, A. L. (2011). Delay discounting: trait variable? Be-
havioural processes, 87(1):1–9.
Rajbhandari, L. and Snekkenes, E. (2013). Using the con-
flicting incentives risk analysis method. In IFIP Inter-
national Information Security Conference, pages 315–
329. Springer.
Regan, P. M. (2002). Privacy as a common good in the
digital world. Information, Communication & Society,
5(3):382–405.
Scholten, H., Scheres, A., De Water, E., Graf, U., Granic, I.,
and Luijten, M. (2019). Behavioral trainings and ma-
nipulations to reduce delay discounting: A systematic
review. Psychonomic bulletin & review, 26(6):1803–
1849.
Spil, T. and Klein, R. (2014). Personal health records suc-
cess: why google health failed and what does that
mean for microsoft healthvault? In 2014 47th Hawaii
International Conference on System Sciences, pages
2818–2827. IEEE.
Steel, P. and König, C. J. (2006). Integrating theories of mo-
tivation. Academy of management review, 31(4):889–
913.
Steinsbekk, K. S., Ursin, L. Ø., Skolbekken, J.-A.,
and Solberg, B. (2013). We’re not in it for the
money—lay people’s moral intuitions on commercial
use of ‘their’biobank. Medicine, Health Care and Phi-
losophy, 16(2):151–162.
Steward, T., Mestre-Bach, G., Fernández-Aranda, F.,
Granero, R., Perales, J. C., Navas, J. F., Soriano-Mas,
C., Baño, M., Fernández-Formoso, J. A., Martín-
Romera, V., et al. (2017). Delay discounting and im-
pulsivity traits in young and older gambling disorder
patients. Addictive Behaviors, 71:96–103.
Sunyaev, A. (2013). Evaluation of microsoft healthvault
and google health personal health records. Health and
Technology, 3(1):3–10.
Szekeres, A. and Snekkenes, E. A. (2019). Predicting ceo
misbehavior from observables: Comparative evalua-
tion of two major personality models. In E-Business
and Telecommunications. ICETE 2018. Communica-
tions in Computer and Information Science, volume
1118, pages 135–158. Springer, Cham.
Szekeres, A. and Snekkenes, E. A. (2020). Construction
of human motivational profiles by observation for risk
analysis. IEEE Access, 8:45096–45107.
Thaler, R. H. and Sunstein, C. R. (2009). Nudge: Improving
decisions about health, wealth, and happiness. Pen-
guin.
WHO (2021). International Statistical Classification of Dis-
eases and Related Health Problems (ICD). [Online;
accessed 4. Jun. 2021].
Yarkoni, T. and Westfall, J. (2017). Choosing prediction
over explanation in psychology: Lessons from ma-
chine learning. Perspectives on Psychological Sci-
ence, 12(6):1100–1122.
CHIRA 2021 - 5th International Conference on Computer-Human Interaction Research and Applications
80
