
Modeling Credibility in Social Big Data using LSTM Neural Networks
Athanasios Lyras
1
, Sotiria Vernikou
1
, Andreas Kanavos
2
, Spyros Sioutas
1
and Phivos Mylonas
3
1
Computer Engineering and Informatics Department, University of Patras, Patras, Greece
2
Department of Digital Media and Communication, Ionian University, Kefalonia, Greece
3
Department of Informatics, Ionian University, Corfu, Greece
Keywords:
Big Data, Deep Learning, Deep Learning Neural Networks, LSTM, Natural Language Processing, Social
Media, Text Mining, Trust Modeling, Twitter.
Abstract:
Communication accounts for a vital need among people in order to express and exchange ideas, emotions,
messages, etc. Social media fulfill this necessity as users can make use of a variety of platforms like Twitter,
to leave their digital fingerprint by uploading personal data. The ever humongous volume of users claims
for evaluation and that is why the subject of user credibility or trust in a social network is equally vital and
meticulously discussed in this paper. Specifically, a trust method, as we measure user credibility and trust in a
social environment using user metrics, is proposed. Our dataset is derived from Twitter and consists of tweets
from a popular television series. Initially, our text data are analyzed and preprocessed using NLP tools and
in following, a balanced dataset that serves in model evaluation and parameter tuning, is constructed. A deep
learning forecasting model, which uses LSTM/BiLSTM layers along with classic Artificial Neural Network
(ANN) and predicts user credibility, is accessed for its worth in terms of model accuracy.
1 INTRODUCTION
Internet growth is rapidly developing and undoubt-
edly affects every single sector of our lives. This de-
velopment is chaotic and continues to increase day
after day due to the exploding volume of data and in-
formation. Most of these data are created through hu-
man interaction in social networks where social media
platforms like Twitter, Facebook and Linkedin make
distant communication feasible. Specifically, in UK,
an astonishing 82% of Internet users maintain a pro-
file or account either at one or more social media sites
or applications and another astonishing 84% resort
daily to messaging chats or applications
1
.
One of the most popular social network applica-
tions is Twitter, which provides all sorts of informa-
tion and allows its users to post text messages called
“tweets”. Its user database is extremely vast as 330
millions use it on a monthly basis and another 145
millions on a daily basis creating over 500 millions
tweets everyday
2
. As a result, these characteristics
make Twitter an excellent choice for knowledge ex-
1
https://www.ofcom.org.uk/ data/assets/pdf file/0025/
217834/adults-media-use-and-attitudes-report-2020-21.
pdf
2
https://www.internetlivestats.com/Twitter-statistics/
traction since users can post anything they feel and
thus it’s of great importance to identify their credibil-
ity.
Nevertheless, despite its advantages, Twitter is of-
ten deemed as an untrustworthy news resource be-
cause tweets are posted directly by users and not by
verified authorities (Zhao et al., 2016). Moreover,
most approaches for trust or credibility measurement
utilize statistic metrics such as the number of follow-
ers and retweets of tweets (Cardinale et al., 2021).
We should bear in mind that Twitter interactions, like
following, mentioning and retweeting, can be forged
from malicious users. On the other hand, content-
based approaches can be problematic due to the fact
that tweets don’t regularly follow classic linguistic
rules.
Trust assessment is mandatory especially for ap-
plications such as Twitter because it is considered a
complex relationship (Sherchan et al., 2013). There
are multiple ways to decide trusting someone; most
of the times, we trust someone with which we had
common experiences or share the same ideas. Psy-
chology and human emotions play an important role
too, since introvert people struggle with trusting oth-
ers. Moreover, in social networks like Twitter, user
interactions show to what extend an individual feels
Lyras, A., Vernikou, S., Kanavos, A., Sioutas, S. and Mylonas, P.
Modeling Credibility in Social Big Data using LSTM Neural Networks.
DOI: 10.5220/0010726600003058
In Proceedings of the 17th International Conference on Web Information Systems and Technologies (WEBIST 2021), pages 599-606
ISBN: 978-989-758-536-4; ISSN: 2184-3252
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
599

since one can demonstrate trust by forwarding their
post. Thus, a model that can identify highly trustwor-
thy users based on both text and arithmetic data of
Twitter’s platform, is crucial.
Machine learning is one of the most common
ways for pattern recognition in complex data. In re-
cent years, computational costs reduced while mem-
ory capacity has increased leading to real-world ap-
plications that benefit from these techniques. Deep
learning is a sub-category of machine learning (Hin-
ton et al., 2006) that has exhibited a novel idea of
translating matrix pixels to a fresh new form that is
based on iterative learning. The algorithms related to
the Deep Learning field follow a high-level general-
ization of the available data, by using a hierarchical
stack of processing layers (Aggarwal, 2018).
As mentioned before, this paper addresses the
problem of user credibility or trust in Twitter. We
have measured it by exploiting user metrics in or-
der to predict human trustworthiness. A real dataset
is created from Twitter that consists of both numeri-
cal and text data (tweets). The pre-processing steps
along with the utilization of deep learning models,
have been implemented in the proposed methodology
and have been evaluated in terms of model accuracy.
Last but not least, another contribution constitutes the
development of various models and the exploration
for identifying the best implementation for different
number of layers.
The rest of the text is outlined as follows: In Sec-
tion 2, we provide a literature view of trust metrics
on Twitter and on social networks in general, while
Section 3 focuses on the trust model along with the
basic concepts and algorithms utilized in this paper.
Section 4 details our implementation and presents the
forecasting model as well as the deep learning tech-
niques we implemented, whereas Section 5 presents
the various research results. In Section 6, we summa-
rize our contributions and future directions.
2 RELATED WORK
It is a fact that there have been a great number of
recent studies regarding trust in computer and social
science. Trust models are considered a popular field
in which researchers try to predict human credibility.
In (Kamvar et al., 2003), authors present a method
to measure trust in peer-to-peer networks where their
algorithm is called EigenTrust and it creates a trust
matrix with information for every pair of nodes in the
network. They calculate trust propagation by comput-
ing an eigenvector matrix which is actually based on
the trust matrix.
In (Adali et al., 2010), a model using statistical
data which is based on timestamps and messages be-
tween two users, is developed. This trust model, enti-
tled behavioral trust, can be described by two metrics:
the conversational and the propagation trust. The con-
versational trust is measured based on how long and
how frequent two users communicate, while the prop-
agation trust is estimated based on the propagation of
the information. The basic idea is that an indication of
trust is considered when a user propagates messages
of a third user.
Some similar works that implement models for
calculating trust based on additional dimensions like
the sentiment, are presented in following. Authors in
(Alowisheq et al., 2017) investigate the relationship
between trust and sentiment as they initially figure the
trust score based on (Adali et al., 2010). Then, the
sentiment agreement matrix score is computed using
the hashtags of every user and by comparing these
two matrices, the authors can assess the relation be-
tween users and whether they agree on different topics
they are interested in. Similarly, the aim of (Boertjes
et al., 2012) is to develop a model that takes into ac-
count both textually expressed sentiment and source
authority. The final degree of trust is calculated based
on situational trust, behavioral trust momentary sen-
timent and authority. Specifically, situational trust is
determined by the opinions and the resulting trust ut-
terances of people with higher authority whereas, be-
havioral trust is the degree of trust that is observable
from trust utterances of people in general. Finally, the
momentary sentiment is an instance of sentiment and
authority that reflects the user popularity as it is cal-
culated purely based on followers.
Delving further in sentiment analysis, authors in
(Roy et al., 2016) have developed a TSM algorithm
for measuring individual users’ trust levels in a social
network where a pair of complementary scores is as-
signed to each actor in the network. The scores are
defined as trustingness and trustworthiness; the first
one specifies the propensity of an actor to trust others
in the network while the latter refers to how trustwor-
thy an actor thinks others can be. Furthermore, the
TSM algorithm takes as input a directed graph and
computes both scores for every node. In following
it converges, after some iterations or when a conver-
gence criterion is met like the maximum difference
among all actors.
A novel topic-focused trust model in order to eval-
uate trustworthiness of users and tweets is also pre-
sented in (Zhao et al., 2016); in this work, authors
take into account data from heterogeneous topics that
derive from multiple users. Trust scores are computed
for both users and tweets where the trustworthiness of
DMMLACS 2021 - 2nd International Special Session on Data Mining and Machine Learning Applications for Cyber Security
600

a tweet can be estimated by whether its content refers
to things that actually took place. Another work that
focuses on discovering emotional influence on Twit-
ter conversations based on the affective potential of
a tweet to change the overall sentiment of that con-
versation is introduced in (Drakopoulos et al., 2021).
This idea leads to the study of emotional dynamics of
tweets and how should a sequence of tweets be seg-
mented in order to reveal truly influential tweets.
MarkovTrust, a recommender system that esti-
mates trust from Twitter interactions between users
in a social network, is proposed in (Lumbreras and
Gavald
`
a, 2012). This system utilizes Markov chains
which make computation more efficient and effective
and particularly, the trust score is measured based on
interactions like mentioning and retweeting. Specif-
ically, authors apply a random-walk algorithm to
measure the propagation trust between distant users.
Moreover, in (Kang et al., 2012), three models for
recommending credible topic-specific information are
introduced. Concretely, the first model computes user
credibility using a multi-weight formula that takes
into account data from tweets in terms of various top-
ics. The second model focuses on tweet content to
compute user credibility and the third one combines
the former two techniques in a hybrid method.
In numerous real-world applications, complex
pattern recognition problems are required to be exe-
cuted in our personal computers, such as visual pat-
tern recognition. Since the conventional strategies are
clearly not appropriate for this type of problems, we
therefore adopt characteristics and features from brain
physiology and in following use them as a premise for
novel processing models. This is well known as Ar-
tificial Neural Systems technology or essentially just
as Neural Networks (Freeman and Skapura, 1991).
Furthermore, authors in (Kanavos et al., 2021) in-
corporate deep neural networks for the problem of
forecasting aviation demand time series, where they
utilized various models and identified the best imple-
mentation among several strategies. One of the most
recent works exhibits an LSTM-CNN based system
for classification (Savvopoulos et al., 2018). Specifi-
cally, the classification task was improved as the pro-
posed method reduced the execution time by values
ranging from 30% to 42%. Thus, the effectiveness of
LSTM neural network and its important contribution
for specific tasks was proved.
3 PROPOSED ARCHITECTURE
Initially, the user credibility measurement along with
the model equations, is introduced. The data pipeline,
where exploratory analysis is applied, is considered
a major aspect and has been taken into consideration
in our proposed methodology. Furthermore, data pre-
processing is utilized and the deep learning model is
fully presented.
3.1 Measuring Credibility
The trust model for measuring social credibility of
Twitter users, which is computed in two steps, is
utilized. Initially, the Twitter domain is considered
as the quintuple (U, F
o
, F
e
, T, X) where U represents
the users, F
o
, F
e
represents the user’s followers and
friends respectively, T represents tweets and X is the
set of topics of the corresponding domain. The model
consists of the following Equations 1 to 6 that em-
ploy Twitter metrics like retweets, friends, followers
(Kafeza et al., 2020; Kafeza et al., 2014; Kang et al.,
2012; Zamparas et al., 2015).
In detail, we measure the retweet deviation for ev-
ery user from the average retweet rate in Equation 1.
Retweets constitute an important sign of credibility
and are mapped to a log-log scale to handle large out-
liers.
Cred
RT
(u, x) = |RT
u
− RT
x
| (1)
In equation 2, we measure the distance of the
retweet rates multiplied by the number of followers
normalized by tweets.
Utility
RT
(u, x) = |
RT
u,x
× F
o
(u)
t
u,x
−
RT
x
× F
o,x
t
x
| (2)
Likewise to equation 1, a social score utilizing the
number of followers divided by the number of tweets
is computed in equation 3.
Cred
social
(u) = |
F
o
t
u
−
F
o
t
| (3)
In equation 4, the ratio of followers to friends as
a deviation is measured. In this way, accounts with
many friends but few followers can be filtered out.
Balance
social
(u) = |
F
o
(u)
F
e
(u)
−
F
o
F
e
| (4)
Social credibility in computed in equation 5,
which is similar to equation 3, although it takes into
account different topics. In our study, a single topic is
considered, so these two metrics have the same value.
Cred
social(u,x)
= |
F
o
(u, x)
t
u,x
−
F
o,x
t
x
| (5)
Modeling Credibility in Social Big Data using LSTM Neural Networks
601

The last metric addresses the behavior of a user
towards a given topic against all topics. Equation 6 is
equal to 1 because we have a specific theme.
Focus(u, x) = |
∑
t∈T
t
u,x
∑
t∈T
t
u
| (6)
We should bear in mind that user credibility is
measured based on Equation 7.
C
u
= α(Focus(u, x) + β(Balance(u) ×Cred
social
(u))+
γ(Utility
RT
(u, x) ×CredRT (u, x))
(7)
The users that have been manually verified by
Twitter constitute a small minority. This verification
is initiated by Twitter and it cannot be requested by a
specific user as it signifies a trustworthy person (Mo-
rozov and Sen, 2014). In the second step, the trust
score only for verified users as presented in equation
8 is updated; this weighted formula boosts verified
credibility based on the score of the most credible and
verified persons.
C
u
(ver) = 0.2 ·C
u
(ver)
max ver
+ 0.8 ·C
u
(ver)
(8)
3.2 Data Pipeline Procedure
The major modules of our proposed methodology are
presented in following. Initially, we gather our data
based on tweets regarding a specific topic as will be
presented in Section 4.1. The exploratory analysis in
our dataset for investigating and summarizing its main
characteristics will be then applied; this will help in
avoiding any assumptions as patterns will be identi-
fied and outliers or anomalous events will be detected.
Later on the credibility, based on the common metrics
of the Twitter dataset, will be measured as discussed
in Section 3.1.
Data pre-processing constitutes an essential part
of the proposed model since the text is cleaned and
any redundant features are totally eliminated. More-
over, the NLP characteristics such as the number of
verbs, nouns, and symbols will be extracted with the
use of spaCy python linguistic tool (Hotho et al.,
2005). These features will be then used as input in
our proposed deep learning model in order to forecast
credibility for each particular user.
3.3 Data Pre-processing
The data pre-processing phase consists of several
steps as we aim to reduce the noise of the data and
thus, the complexity of our proposed model. Specifi-
cally, in order for the model to be more robust and ef-
ficient, all characters are converted to lowercase, and
the hyperlinks along with the stop words are removed
as they don’t add any useful linguistic information
(Kaur and Buttar, 2018; Luhn, 1960). Furthermore,
mentions and hashtags that are often used on Twitter
messages to attract other users’ attention, are also re-
moved.
Part-of-Speech (POS) tagging was in following
implemented for extracting the useful features and
enhance our deep learning model. Tokenization and
lemmatization were also considered, where the first
one is the process of turning text data into tokens and
is performed in order to obtain tokens and prepare a
vocabulary, which consists of the unique tokens of
the corpus and the latter is the process of replacing
a given word with its root in order to reduce the vo-
cabulary size.
Moreover, in the data pre-processing step, we had
to deal with the “padding” or “text padding” prob-
lem where our system faced the RAM capacity fail-
ure. Our implementation revealed that several users
posted long text messages, which were given as data
input. More specifically, a particular user had word
count equal to 16.000 in his tweets, which can be
problematic during the embedding phase, as can be
illustrated in Figure 1(a). In order for the system to
make equal vectors for every users, it fills in with ze-
ros so every user has the same length as every word
corresponds to a specific number; this filling phase
is called “padding”. As presented in Figure 1(b), we
tackle this problem by deleting users with word count
above 150, which accounts for less than 1% of the
former user count.
As previously mentioned, spaCy library
3
with its
English vocabulary set called “en core web lg” was
employed. Six different dataset instances were cre-
ated according to the vocabulary size, with 10.000,
20.000, 30.000, 40.000, 50.000 and 60.000 different
words, respectively. spaCy was selected because it
is an open source toolkit for NLP problems, mainly
used in the industry. It is easy to learn and can be
up to 20 times faster than other NLP libraries such
as NLTK. Moreover, spaCy has one implemented
method, which chooses the most efficient algorithm
currently available, whereas its implementation is
simple as users can process big text files with few
lines of code.
3
https://spacy.io/
DMMLACS 2021 - 2nd International Special Session on Data Mining and Machine Learning Applications for Cyber Security
602

(a) Before solution (b) After solution
Figure 1: Padding problem before and after solution.
3.4 Deep Learning Model
The deep learning model we utilized for predicting
user credibility is illustrated in Figure 2 consisting of
two different modules (Patterson and Gibson, 2017).
Specifically, the first module takes as input the prepro-
cessed text and adds an embedding layer. This layer
transforms words into their corresponding word em-
beddings with the aim of compressing the input fea-
ture space into a smaller one. Word embeddings are
in fact a set of processes, where individual words are
represented as real-valued vectors in a predefined vec-
tor space.
After the embedding layer, the spatial dropout,
the LSTM or BiLSTM layers and the normal dropout
(Buduma and Locascio, 2017) were added. In our
model, we employ both LSTM and bidirectional
LSTM neural networks. Long Short Term Mem-
ory networks are a special kind of Recurrent Neural
Networks that are capable of learning long term de-
pendencies and provide impressive performance es-
pecially on Natural Language Processing problems
(Hochreiter and Schmidhuber, 1997; Savvopoulos
et al., 2018). The difference is that LSTM networks
preserve information from the past while BiLSTM
networks preserve information from both past and fu-
ture. The second module consists of the classic ANN
network, that takes as input arithmetic features.
Both models concatenate in a single artificial neu-
ral network that can fit on both textual and numeric
data. Here, Keras deep learning library was used for
implementing our proposed methodology.
Figure 2: Deep Learning Model Architecture.
4 IMPLEMENTATION
4.1 Dataset
We have used a dataset entitled “Game of Thrones
S8”, which captures the release of all six Game of
Modeling Credibility in Social Big Data using LSTM Neural Networks
603
Thrones episodes from the popular television series
that premiered on 14th of April, 2019
4
. It consists of
403.903 unique users that have contributed a number
of tweets equal to 760.626.
This dataset was reconstructed as most features
were removed and new linguistic characteristics were
added. Specifically, every user was rated in a scale
of 1 to 5 depending on the credibility score, where
more trustworthy users are rated higher. Finally, a
very small portion of the users was removed as they
had zero followers or friends and thus, user credibility
in this case could not be computed.
The distribution of the users is presented in Table
1; the majority of them were categorized as non trust-
worthy and slightly trustworthy.
Table 1: User Categories of Initial Dataset.
Classes Number of Users
non trustworthy 285.793
slightly trustworthy 106.443
somewhat trustworthy 8.939
pretty trustworthy 1.253
most trustworthy 71
Total 402.499
4.2 Balanced Dataset
At a later stage, a new dataset was constructed be-
cause the initial dataset was exceptionally large and
awfully imbalanced. This dataset is called the “bal-
anced” one and was utilized in order to precisely eval-
uate and fine-tune our proposed deep learning model.
Moreover, a more balanced dataset will provide us
with more accurate results in terms of accuracy as
well as validation accuracy.
In order to create this dataset, we had to deal with
the problem of the extremely few values of the last
category. To achieve this, we normalized the values
within a new range in order to have a small difference
between the classes.
The distribution of the users per each class after
the balancing process, is presented in Table 2.
5 EVALUATION
In this section, we evaluate our model on the two
datasets for different vocabulary sizes and for differ-
ent number of layers in terms of accuracy and valida-
tion accuracy, which are the most common metrics to
evaluate deep learning models.
4
https://www.kaggle.com/monogenea/
game-of-thrones-twitter
Table 2: User Categories of Balanced Dataset.
Classes Number of Users
non trustworthy 10.000
slightly trustworthy 10.000
somewhat trustworthy 10.000
pretty trustworthy 4.316
most trustworthy 686
Total 35.002
Primarily, the results regarding the initial dataset
are presented; here 10 hidden layers in the corre-
sponding LSTM network were implemented. We
have to mention here that the evaluation with bidi-
rectional LSTM neural networks performed almost
the same and thus, the results are omitted. Table 3
presents the accuracy and validation accuracy on dif-
ferent ratio splits, where they assume values larger
than 81% presuming that the dataset is large enough
and as a result, we can not observe any actual differ-
ences.
Table 3: Accuracy and Validation Accuracy on different Ra-
tio Splits on initial Dataset.
Ratio Split Accuracy Validation Accuracy
0.05 0.8157 0.8132
0.10 0.8147 0.8189
0.15 0.8136 0.8139
0.20 0.8153 0.8143
0.25 0.8148 0.8160
0.30 0.8141 0.8186
0.35 0.8146 0.8160
0.40 0.8156 0.8159
In following, in Table 4, we evaluate our system
by using only text data and features that were created
from NLP procedure. Here we don’t use any of the
numerical features that we were present in the initial
dataset; these numerical features will be utilized in
following Table 5. Specifically, accuracy and valida-
tion accuracy achieve values close to 72% denoting
the importance of NLP procedure.
Table 4: Accuracy and Validation Accuracy of Deep Learn-
ing Model with Text and NLP Features (initial Dataset).
Vocabulary Size
(words) Accuracy
Validation
Accuracy
10.000 0.7112 0.7102
20.000 0.7121 0.7097
30.000 0.7100 0.7107
40.000 0.7110 0.7105
50.000 0.7096 0.7137
60.000 0.7107 0.7131
In Table 5, we add numerical features, except text
data and several other features through NLP process
DMMLACS 2021 - 2nd International Special Session on Data Mining and Machine Learning Applications for Cyber Security
604
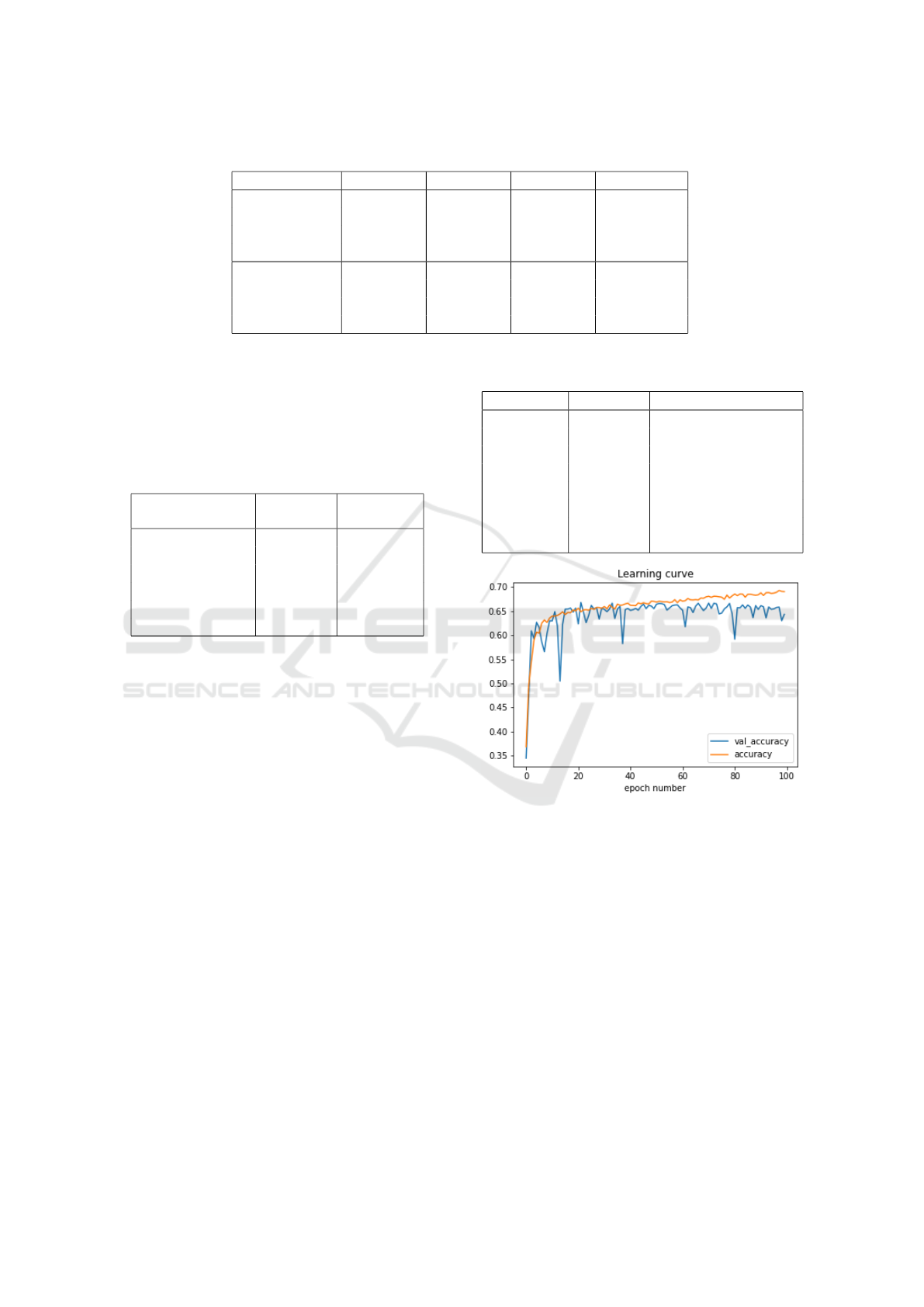
Table 6: Accuracy of Deep Learning Model with Text, NLP and Numerical Features (balanced Dataset).
Dense × 1 Dense × 3 Dense × 5 Dense × 10
LSTM × 1 0.4834 0.7099 0.7071 0.7100
LSTM × 3 0.6400 0.7032 0.7075 0.7050
LSTM × 5 0.7027 0.7129 0.7097 0.7099
LSTM × 10 0.7048 0.6900 0.7106 0.7083
BiLSTM × 1 0.9670 0.9688 0.9657 0.9702
BiLSTM × 3 0.9591 0.9491 0.9602 0.9522
BiLSTM × 5 0.8816 0.9267 0.9297 0.8865
BiLSTM × 10 0.6908 0.7094 0.7022 0.7111
like POS tagging. This results to accuracy score of
81% and thus, highlighting the significance of the
combination of these features with the NLP proce-
dure.
Table 5: Accuracy and Validation Accuracy of Deep Learn-
ing Model with Text, NLP and Numerical Features (initial
Dataset).
Vocabulary Size
(words) Accuracy
Validation
Accuracy
10.000 0.8172 0.8149
20.000 0.8153 0.8143
30.000 0.8155 0.8163
40.000 0.8163 0.8151
50.000 0.8144 0.8182
60.000 0.8156 0.8164
In following, the performance of our model in the
balanced dataset using different numbers of LSTM
and BiLSTM layers is depicted in Table 6. We ob-
serve that in the case of using more than 5 hidden lay-
ers on both textual and arithmetic data, the accuracy
is maxed at 70% regarding LSTM networks whereas
BiLSTM clearly outperforms this value as it consists
of two LSTMs; one taking the input in a forward di-
rection, and the other in a backward direction. BiL-
STMs effectively increase the amount of information
available to the network, improving the context avail-
able to the algorithm.
Finally, all the obtainable optimizers of Keras li-
brary were taken into consideration and the results are
introduced in Table 7 showing that Adam is the best
choice. Another outcome is the minimum number of
epochs we need to train our model, which is 10 as
illustrated in Figure 3.
6 CONCLUSIONS AND FUTURE
WORK
In our proposed work, we have presented a methodol-
ogy that measures user credibility on Twitter and can
predict human trustworthiness. We have included var-
Table 7: Accuracy and Validation Accuracy of Models with
different Optimizers (balanced Dataset).
Optimizer Accuracy Validation Accuracy
Adadelta 0.2962 0.2896
Adagrad 0.2833 0.3337
Adam 0.6938 0.6980
Adamax 0.6841 0.6955
Ftrl 0.2873 0.2833
Nadam 0.6977 0.6907
Rmsprop 0.6828 0.6816
SGD 0.4812 0.5100
Figure 3: Learning Curve on balanced Dataset.
ious features, such as numerical and text data utilizing
the NLP process and have evaluated them in terms
of accuracy. LSTM and BiLSTM neural networks
have been implemented and experiments with differ-
ent number of hidden layers were conducted. The re-
sults demonstrate that our proposed model can predict
user credibility with high values of accuracy and this
can be promising for such complicated problems.
Regarding future work, the proposed methodol-
ogy can be augmented by incorporating Batch Nor-
malization, which normally accelerates the training of
deep networks. In addition to that, the inefficiencies
of single models can be resolved by applying several
combination techniques, which will lead to more ac-
curate results as in (Drakopoulos et al., 2016; Kyri-
azidou et al., 2019).
Modeling Credibility in Social Big Data using LSTM Neural Networks
605

REFERENCES
Adali, S., Escriva, R., Goldberg, M. K., Hayvanovych,
M., Magdon-Ismail, M., Szymanski, B. K., Wallace,
W. A., and Williams, G. T. (2010). Measuring behav-
ioral trust in social networks. In IEEE International
Conference on Intelligence and Security Informatics
(ISI), pages 150–152.
Aggarwal, C. C. (2018). Neural Networks and Deep Learn-
ing - A Textbook. Springer.
Alowisheq, A., Alrajebah, N., Alrumikhani, A., Al-
Shamrani, G., Shaabi, M., Al-Nufaisi, M., Alnasser,
A., and Alhumoud, S. (2017). Investigating the re-
lationship between trust and sentiment agreement in
arab twitter users. In 9th International Conference on
Social Computing and Social Media (SCSM), volume
10283, pages 236–245.
Boertjes, E. M., Gerrits, B., Kooij, R. E., van Maanen, P.,
Raaijmakers, S., and de Wit, J. (2012). Towards a
social media-based model of trust and its application.
In 10th IFIP TC International Conference on Human
Choice and Computers (HCC10), volume 386, pages
250–263.
Buduma, N. and Locascio, N. (2017). Fundamentals of
Deep Learning: Designing Next-Generation Machine
Intelligence Algorithms. O’Reilly Media, Inc.
Cardinale, Y., Dongo, I., Robayo, G., Cabeza, D., Aguilera,
A. I., and Medina, S. (2021). T-creo: A twitter cred-
ibility analysis framework. IEEE Access, 9:32498–
32516.
Drakopoulos, G., Kanavos, A., Mylonas, P., and Sioutas,
S. (2021). Discovering sentiment potential in twitter
conversations with hilbert-huang spectrum. Evolving
Systems, 12(1):3–17.
Drakopoulos, G., Kanavos, A., and Tsakalidis, A. K.
(2016). Evaluating twitter influence ranking with
system theory. In 12th International Conference
on Web Information Systems and Technologies (WE-
BIST), pages 113–120.
Freeman, J. A. and Skapura, D. M. (1991). Neural Net-
works: Algorithms, Applications, and Programming
Techniques. Computation and Neural Systems Series.
Addison-Wesley.
Hinton, G. E., Osindero, S., and Teh, Y. W. (2006). A fast
learning algorithm for deep belief nets. Neural Com-
putation, 18(7):1527–1554.
Hochreiter, S. and Schmidhuber, J. (1997). Long short-term
memory. Neural Computation, 9(8):1735–1780.
Hotho, A., N
¨
urnberger, A., and Paass, G. (2005). A brief
survey of text mining. LDV Forum, 20(1):19–62.
Kafeza, E., Kanavos, A., Makris, C., Pispirigos, G., and
Vikatos, P. (2020). T-PCCE: twitter personality based
communicative communities extraction system for big
data. IEEE Transactions on Knowledge and Data En-
gineering, 32(8):1625–1638.
Kafeza, E., Kanavos, A., Makris, C., and Vikatos, P.
(2014). T-PICE: twitter personality based influential
communities extraction system. In IEEE International
Congress on Big Data, pages 212–219.
Kamvar, S. D., Schlosser, M. T., and Garcia-Molina, H.
(2003). The eigentrust algorithm for reputation man-
agement in P2P networks. In 12th International World
Wide Web Conference (WWW), pages 640–651.
Kanavos, A., Kounelis, F., Iliadis, L., and Makris, C.
(2021). Deep learning models for forecasting aviation
demand time series. Neural Computing and Applica-
tions, pages 1–15.
Kang, B., O’Donovan, J., and H
¨
ollerer, T. (2012). Mod-
eling topic specific credibility on twitter. In 17th In-
ternational Conference on Intelligent User Interfaces
(IUI), pages 179–188.
Kaur, J. and Buttar, P. K. (2018). A systematic review on
stopword removal algorithms. International Journal
on Future Revolution in Computer Science & Com-
munication Engineering, 4(4):207–210.
Kyriazidou, I., Drakopoulos, G., Kanavos, A., Makris, C.,
and Mylonas, P. (2019). Towards predicting mentions
to verified twitter accounts: Building prediction mod-
els over mongodb with keras. In 15th International
Conference on Web Information Systems and Tech-
nologies (WEBIST), pages 25–33.
Luhn, H. P. (1960). Keyword-in-context index for techni-
cal literature (kwic index). American Documentation,
11(4):288–295.
Lumbreras, A. and Gavald
`
a, R. (2012). Applying trust
metrics based on user interactions to recommenda-
tion in social networks. In International Conference
on Advances in Social Networks Analysis and Mining
(ASONAM), pages 1159–1164.
Morozov, E. and Sen, M. (2014). Analysing the Twitter So-
cial Graph: Whom Can we Trust? PhD thesis, MS
Thesis, Department Computer Science, University of
Nice Sophia Antipolis, Nice, France.
Patterson, J. and Gibson, A. (2017). Deep Learning: A
Practitioner’s Approach. O’Reilly Media, Inc.
Roy, A., Sarkar, C., Srivastava, J., and Huh, J. (2016). Trust-
ingness & trustworthiness: A pair of complementary
trust measures in a social network. In 2016 IEEE/ACM
International Conference on Advances in Social Net-
works Analysis and Mining (ASONAM), pages 549–
554. IEEE Computer Society.
Savvopoulos, A., Kanavos, A., Mylonas, P., and Sioutas,
S. (2018). LSTM accelerator for convolutional object
identification. Algorithms, 11(10):157.
Sherchan, W., Nepal, S., and Paris, C. (2013). A survey
of trust in social networks. ACM Computing Surveys,
45(4):47:1–47:33.
Zamparas, V., Kanavos, A., and Makris, C. (2015). Real
time analytics for measuring user influence on twitter.
In 27th IEEE International Conference on Tools with
Artificial Intelligence (ICTAI), pages 591–597.
Zhao, L., Hua, T., Lu, C., and Chen, I. (2016). A topic-
focused trust model for twitter. Computer Communi-
cations, 76:1–11.
DMMLACS 2021 - 2nd International Special Session on Data Mining and Machine Learning Applications for Cyber Security
606
