
Service Selection for Service-Oriented Architecture using Off-line
Reinforcement Learning in Dynamic Environments
Yuya Kondo and Ahmed Moustafa
Nagoya Institute of Technology, Japan
Keywords:
Reinforcement Learning, Offline Reinforcement Learning, Transfer Learning.
Abstract:
Service-Oritented Architeture (SOA) is a style of system design in which the entire system is built from a
combination of services, which are functional units of software. The performance of a system designed with
SOA depends on the combination of services. In this research, we aim to use reinforcement learning for ser-
vice selection in SOA. Service selection in SOA is characterized by its dynamic environment and inefficient
collection of samples for training. We propose an offline reinforcement learning method in a dynamic envi-
ronment to solve this problem. In the proposed method, transfer learning is performed by applying fine tuning
and focused sampling. Experiments show that the proposed method can adapt to dynamic environments more
efficiently than redoing online reinforcement learning every time the environment changes.
1 INTRODUCTION
Service oriented computing (SOC) (Papazoglou,
2003) is computing paradigm that utilize service
as fundamental elements for developing applica-
tions/solutions. The aim of SOC is to enable the inter-
operability among different software and data appli-
cations running of a variety of platforms. Service ori-
ented architecture (SOA) is is one of method to create
large scale computer system which consists of multi-
ple services across network or platform. The benefit
of SOA is high flexibility in system development. Af-
ter each service is created, the system is assembled
in SOA. If there is an inconvenient service during the
assembly process, it is possible to modify that service
and replace it with another service. As the number
of options expands with the number of combinations,
the system can be developed more flexibly. We can
pick and choose what we need from the services we
have created in the past, combine them, and add or
recreate only the parts we need. This is another major
advantage of SOA.
In SOA, multiple services are used to fulfill given
task. Decision making in selecting service compo-
nent to fulfill given task is needed. Reinforcement
learning is good approach to solve this problems, and
there are several related works. (Wang et al., 2020)
(Moustafa and Ito, 2018) The aim of reinforcement
learning is optimizing agent’s action sequence during
the interaction with learning environment. Reward is
given when agent do good behavior to fulfill the goal.
Agent learns good behavior by maximizing total re-
ward. Game AI, recommend system and automated
driving are the examples of application of reinforce-
ment learning. (Silver et al., 2017) (Ie et al., 2019)
(Wang et al., 2018) There are two major problems in
using reinforcement learning for service selection in
SOA.
• The cost of learning interactively with real-world
environments is high.
• Service selection in SOA is a dynamic environ-
ment.
It requires huge number of trials for reinforcement
learning. The cost of learning by constructing system
in the real environment and getting feedback is high.
Most conventional reinforcement learning methods
assume a static environment. Therefore, it is difficult
to apply them to real-world problems that deal with
dynamic environments.
In this study, we propose an offline RL (Levine
et al., 2020) method that is robust to dynamic envi-
ronments. We improve the efficiency of relearning
in exchange for some accuracy by reusing previous
learning results for relearning when the environment
changes and intentionally biasing the sampling of the
dataset used for relearning. The proposed method ad-
dresses the problem of conventional methods which
require relearning from the beginning every time the
environment changes in a dynamic environment. We
64
Kondo, Y. and Moustafa, A.
Service Selection for Service-Oriented Architecture using Off-line Reinforcement Learning in Dynamic Environments.
DOI: 10.5220/0010872400003116
In Proceedings of the 14th International Conference on Agents and Artificial Intelligence (ICAART 2022) - Volume 1, pages 64-70
ISBN: 978-989-758-547-0; ISSN: 2184-433X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

validate the proposed method through simulations of
the SOA system construction. For real-world appli-
cations, the proposed method is effective in problem
settings such as SOA system construction, where a
dynamic environment and AI with strict accuracy are
not required.
2 PRELIMINARIES
2.1 Service Oriented Architecture
These days, Computer System spreads to everywhere
around us. It is impossible to control all of computer
in one place. So distributed control is needed. These
computers consist of various type of platform and de-
vice and each computer has their own function. Link-
ing these function across devices and platforms has a
potential to create good and large scale service. Ser-
vice Oriented Architecture (SOA) is one of method to
create large scale computer system which consist of
multiple services across network or platform.
2.2 Deep Reinforcement Learning
Reinforcement learning (RL) (Sutton and Barto,
2018) is optimization for action sequence in given
environment. Agent learns behavior to fulfill the
goal during the interaction with environment. Agent
decides its behavior based on policy. Agent can
recognize various information from environment,
this information treat as state. After agent take some
action, agent moves to next state due to change of
information given from environment. This single
process is called step and this is minimum unit of
agent’s behavior. Agent repeats this process until
agent moves from initial state to terminal state. This
sequential process is called episode. In shooting
game, one step is one minimum recognizable frame
and one episode is a flow from the start to end of
game. To evaluate behavior, scalar value is used and
this value is called reward. Agent acts in environment
and get reward. Agent improves the policy based
on reward. In reinforcement learning, markov
decision process (MDP) is used to define learning
environment. MDP consists of state, reward, action
and transition probability.
Q-Learning: Q-Learning (Watkins and Dayan, 1992)
is classic method of reinforcement learning. In Q-
Learning, Q-function is used to predict the expected
total reward. Q-function is updated based on Be-
low equation learning rate α adjusts weight ratio of
current q-value when q-value is updated. γ is dis-
count rate which decides the importance of the re-
wards given in later steps.
Q(s
t
, a
t
) = (1 − α)Q(s
t
, a
t
) +
α(R(s
t
, a
t
) + γ max
a
t+1
Q(s
t+1
, a
t+1
))
Deep Q-Network: DQN (Mnih et al., 2015) (Mnih
et al., 2013) is an extension of Q-learning. DQN uses
deep neural network to represent Q-function. DQN
also uses experience replay. Experience replay is a
method to use previous trajectory within the last fixed
period for updating Q-function.
2.3 Offline RL
Traditional RL supposes interaction with environment
to collect information. However, infinite times of in-
teraction with environment is impossible in real appli-
cation. For example, recommender system limits the
times to interact with environment because the time
of user access is not infinite. In autonomous driv-
ing, learning model from scratch is dangerous, be-
cause infant model will causes traffic accident. Social
Game often changes the game setting like introduc-
ing new function to the game. It would be very costly
to learn from scratch each time game change the set-
ting slightly. Hence, the problems of RL to adopt real
application are below.
• Problem 1 : the times to collect data or available
data is limited.
• Problem 2 : pre-training model which provide
minimum required ability is needed.
• Problem 3 : changing environment setting makes
the model useless.
In Offline RL, agent learns from the fixed dataset.
Offline RL tackle the problem 1 and 2. Offline
RL doesn’t always solve Problem 3. This research
tackles problem 3. Suppose that dataset is a bit of
datum which consists of state, action, transited state
and reward. Offline RL uses this dataset to learn
from. Learning from fixed dataset causes problem
that the information agent can use is limited. In
detail, agent don’t uses the action sequences which
is not contained in dataset. This force agent to learn
the model to maximize their utility in the distribution
dataset gives. The distribution which is not contained
in dataset called out-of-distribution (OOD). It is
important to keep utility in OOD having no-effect to
utility of q-function. The rest of this section focuses
on introduction of method for Offline RL.
Service Selection for Service-Oriented Architecture using Off-line Reinforcement Learning in Dynamic Environments
65
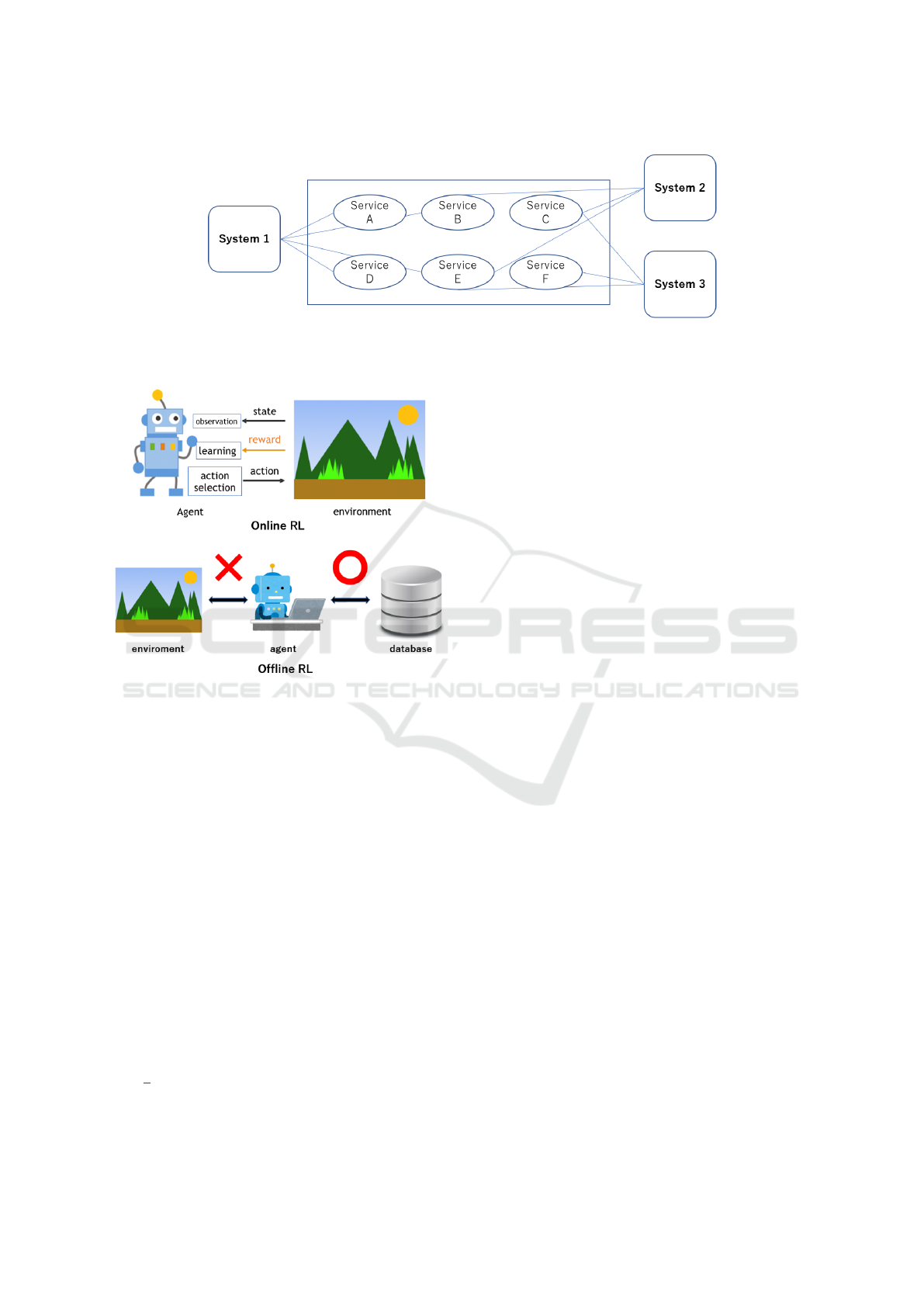
Figure 1: In SOA, multiple services are combined to build a system. It is also possible to divert the same service to different
systems.
Figure 2: Explanation of online RL and offline RL.
Conservative Q-Learning: In Offline-RL or off-
policy RL, overestimation of values induced by the
distribution shift between the dataset and learned pol-
icy can cause failure of RL learning. In addition
to this, Offline RL promise to learn effective poli-
cies from previously-collected, static datasets without
further interaction. Conservative Q-Learning (CQL)
(Kumar et al., 2020) aims to address these limitations
by learning conservative Q-function such that the ex-
pected value of a policy under this Q-function lower-
bounds its true value. CQL can be adopted to both
of Q-Learning and actor-critic method. Actor critic is
methods in which policy function and value function
are learned explicitly. CQL can be combined with
particular choice of regularizer. Below equation is
instance of updates for CQL method with particular
choice of regularizer R (µ).
min
Q
max
µ
{α(E
s∼D,a∼µ(a|s)
[Q(s, a)] − E
s∼D,a∼
ˆ
π
β
(a|s)
[Q(s, a)])
+
1
2
E
s,a∼D
[(Q(s, a) −
ˆ
β
π
ˆ
Q
k
(s, a))
2
] + R (µ)}(CQL(R ))
3 RELATED WORK
3.1 Integrating Recurrent Neural
Networks and Reinforcement
Learning for Dynamic Service
Composition (Wang et al., 2020)
This work adopts DQN and LSTM to capture time-
series reward. Specifically, they use a recurrent neu-
ral network to predict the QoS, and then make dy-
namic service selection through reinforcement learn-
ing. This method focus only on the situation where
the size of candidate services is very small.
3.2 A Deep Reinforcement Learning
Approach for Large-scale Service
Composition (Moustafa and Ito,
2018)
This work proposes an approach for adaptive ser-
vice composition in dynamic and large-scale envi-
ronments. The proposed approach employs deep re-
inforcement learning in order to address large-scale
service environments with large number of service
providers. This method uses DQN with Double DQN
and prioritized experience replay. Their action space
is from 100 to 200 and total service selection is from
600 to 800. This work uses three types of parameter
to calculate QoS - availability, response time and re-
liability. They also consider the setting where part of
services changes per concrete value episodes.
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
66
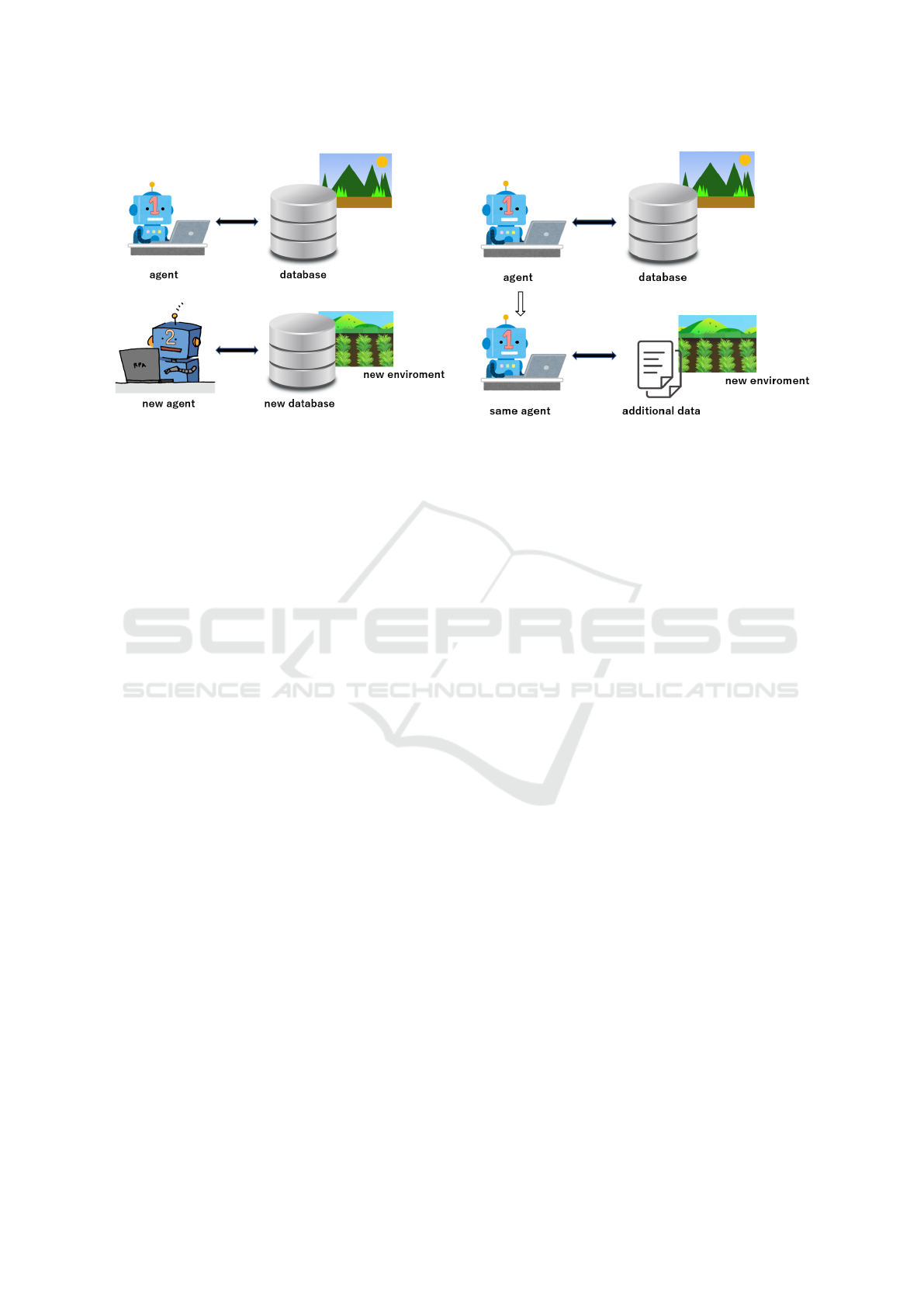
Figure 3: Re-learn with existing methods.
4 PROBLEM DESCRIPTION AND
RL ARCHITECTURE
4.1 Objective
The purpose of the proposed offline reinforcement
learning agent is to perform service selection for SOA
system construction in a dynamic environment. The
performance of the system depends on the combina-
tion of services. The agent learns to build a system
with good performance. The premise is that the com-
position of services changes in SOA system build-
ing. Re-learning needs to be done efficiently when
the composition of services changes.
With existing methods, new data is required every
time the environment changes, and the learning pro-
cess has to be redone from the beginning. The pro-
posed method aims to improve retraining efficiency
by inheriting models that have been trained in the en-
vironment before the change and prioritizing the sam-
pling of additional data to be used during retraining.
4.2 Environment
Figure 5 shows the definition of MDP. In this re-
search, WS-DREAM dataset (WSD, ) is used to cre-
ate environment which follows the definition of MDP.
WS-DREAM is a Distributed REliability Assess-
ment Mechanism for Web Services. WS-DREAM
repository maintains 3 sets of data, QoS (Quality-of-
Service) datasets ,log datasets, and review datasets.
QoS datasets are used in this research.
Each state is assigned a service group consisting
of n services. The agent selects one of the services
from the service group by action. The reward is cal-
Figure 4: Re-learn with propose methods.
culated based on the QoS datasets and normalized
among the service group.
In this study, we experimented with the case
where a service was added or removed from a group
of services. When a group of services is changed,
10% of the services are removed and replaced with
new ones. The method for relearning after the en-
vironment changes is described in the Replay Buffer
section.
4.3 Model
Online RL Method: Online method is DQN based
method. In this paper, the online method is used to
prepare the replay buffer.
Offline RL Method: Offline Method expands
online method for Offline Setting. This research
adopts CQL method for offline setting and the
method used in online setting is expanded by using
CQL.
4.4 Replay Buffer
Offline reinforcement learning is trained using a fixed
data set called replay buffer. In this study, the replay
buffer is the history obtained from the training of the
online method (DQN). We aim to improve the effi-
ciency of relearning by selecting the data to use for
the replay buffer. We select the data used for the re-
play buffer using the following algorithm.
Service Selection for Service-Oriented Architecture using Off-line Reinforcement Learning in Dynamic Environments
67

Figure 5: Definition of MDP.
Algorithm 1: Obtaining the replay buffer of the proposed
method.
1: List of elements that have been added/removed L
2: Initialize replay buffer B to capacity N
3: while N ≥ size of B do
4: e ← An element chosen randomly from L
5: D ← Randomly generate an episode with e
6: add D to B
7: end while
5 EXPERIMENTAL RESULTS
We use data of 50000 episodes obtained by execut-
ing DQN in the same environment for the first 25000
steps. After 25000 steps, we delete 10% of the exist-
ing services and replace them with new ones. Then
the model is retrained.
5.1 Replay Buffer Size during
Relearning
In this experiment, we investigate the replay buffer
size required for retraining. Figure 6 compares reward
transitions during retraining when the replay buffer
data is prepared with the same size as the original one
and with 30% of the original one. When the size of
the replay buffer is 30%, the reward after relearning
is low. This may be due to the fact that there is not
enough data for relearning.
Figure 7 compares reward transitions during re-
training when the replay buffer data is prepared with
Figure 6: Reward transitions of 30% and 100%.
various size. In this experimental setting, the results
were almost the same if the data size of the replay
buffer used for relearning was at least 70% of the orig-
inal. Depending on the magnitude of the environmen-
tal change, the data size required for relearning may
not need to be as large as the initial training. If there is
too little data, the converged reward tends to be small.
5.2 Importance Sampling of Data in
Replay Buffer
In this experiment, we investigate the sample used for
the replay buffer during relearning. Figure 8 com-
pares reward transitions during retraining when replay
buffer data is prepared randomly and when replay
buffer is prepared with importance sampling. The re-
play buffer prepared with importance sampling con-
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
68

Figure 7: Reward transitions of 10%,30%,50%,70%, and
100%.
Figure 8: Reward transitions of 30% with propose method
and 100% with random.
sists of data related to environment changes. In this
experimental setting, convergence is faster when the
replay buffer is prepared with the proposed method
than when the replay buffer is prepared with random
data.
6 DISCUSSION ON THE
PROPOSED METHOD
The above experiments show the sample efficiency
of the proposed method in relearning in dynamic en-
vironments. The proposed method is effective for
practical applications of reinforcement learning in
dynamic environments where sample acquisition is
costly. Since the implementation is based on offline
reinforcement learning methods, it is relatively easy
to adapt the proposed method to existing systems.
On the other hand, the definition of data related to
changes in the environment varies greatly depending
on the problem setting. It is not clear what factors
should be prioritized when environmental changes are
complex. Also, there is room for future verification of
the degree to which the system can handle changes.
7 CONCLUSION AND FUTURE
DIRECTIONS
In this study, we proposed an offline reinforcement
learning method in a dynamic service selection en-
vironment in SOA. The proposed approach takes a
model learned in the environment before it is modi-
fied, and performs efficient relearning by data related
to the environment differences. The proposed method
is able to adapt to changes in the environment with
less data and shorter time.
The appropriate replay buffer size during relearn-
ing is treated as a hyperparameter. In the proposed
method, all the data used in the replay buffer are re-
lated to the changes in the environment, but this ratio
also needs to be considered.
ACKNOWLEDGEMENT
This work has been supported by Grant-in-Aid for
Scientific Research [KAKENHI Young Researcher]
Grant No. 20K19931.
REFERENCES
WS-DREAM Dataset. https://github.com/wsdream/
wsdream-dataset.
Ie, E., Jain, V., Wang, J., Narvekar, S., Agarwal, R., Wu, R.,
Cheng, H.-T., Chandra, T., and Boutilier, C. (2019).
Slateq: A tractable decomposition for reinforcement
learning with recommendation sets.
Kumar, A., Zhou, A., Tucker, G., and Levine, S. (2020).
Conservative q-learning for offline reinforcement
learning. arXiv preprint arXiv:2006.04779.
Levine, S., Kumar, A., Tucker, G., and Fu, J. (2020). Of-
fline reinforcement learning: Tutorial, review, and
perspectives on open problems. arXiv preprint
arXiv:2005.01643.
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A.,
Antonoglou, I., Wierstra, D., and Riedmiller, M.
(2013). Playing atari with deep reinforcement learn-
ing. arXiv preprint arXiv:1312.5602.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Ve-
ness, J., Bellemare, M. G., Graves, A., Riedmiller, M.,
Fidjeland, A. K., Ostrovski, G., et al. (2015). Human-
level control through deep reinforcement learning. na-
ture, 518(7540):529–533.
Service Selection for Service-Oriented Architecture using Off-line Reinforcement Learning in Dynamic Environments
69

Moustafa, A. and Ito, T. (2018). A deep reinforcement
learning approach for large-scale service composition.
In PRIMA.
Papazoglou, M. P. (2003). Service-oriented computing:
Concepts, characteristics and directions. In Proceed-
ings of the Fourth International Conference on Web
Information Systems Engineering, 2003. WISE 2003.,
pages 3–12. IEEE.
Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai,
M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D.,
Graepel, T., et al. (2017). Mastering chess and shogi
by self-play with a general reinforcement learning al-
gorithm. arXiv preprint arXiv:1712.01815.
Sutton, R. S. and Barto, A. G. (2018). Reinforcement learn-
ing: An introduction. MIT press.
Wang, H., Li, J., Yu, Q., Hong, T., Yan, J., and Zhao,
W. (2020). Integrating recurrent neural networks and
reinforcement learning for dynamic service composi-
tion. Future Generation Computer Systems, 107:551–
563.
Wang, S., Jia, D., and Weng, X. (2018). Deep reinforce-
ment learning for autonomous driving. arXiv preprint
arXiv:1811.11329.
Watkins, C. J. and Dayan, P. (1992). Q-learning. Machine
learning, 8(3-4):279–292.
ICAART 2022 - 14th International Conference on Agents and Artificial Intelligence
70
