
Personalized Curiosity Engine (Pique): A Curiosity Inspiring Cognitive
System for Student Directed Learning
Safat Siddiqui
1
, Mary Lou Maher
1
, Nadia Najjar
1
, Maryam Mohseni
1
and Kazjon Grace
2
1
University of North Carolina at Charlotte, NC, U.S.A.
2
University of Sydney, Sydney, Australia
Keywords:
Personalized Learning, Curiosity, Recommender Systems for Education, Computational Models of Novelty.
Abstract:
Pique is an AI-based system for student directed learning that is inspired by a cognitive model of curiosity.
Pique encourages self-directed learning by presenting a sequence of learning materials that are simultaneously
novel and personalized to learners’ interests. Pique is a web-based application that applies computational
models of novelty to encourage curiosity and to inspire learners’ intrinsic motivation to explore. We describe
the architecture of the Pique system and its implementation in personalizing learning materials. In exploring
the use of Pique by students in undergraduate and graduate courses in Computer Science, we have developed
and implemented two computational models of novelty using Natural Language Processing techniques and
concepts from recommender systems. In this paper, we describe the Pique model, the computational models
for measuring novelty in text-based documents, and the computational models for generating sequences of
personalized curiosity-eliciting learning materials. We report the response from students in the use of Pique in
four courses over two semesters. The contribution of this paper is a unique approach for personalized learning
that encourages curiosity.
1 INTRODUCTION
One of the most significant challenges in education
at scale is how to personalize learning (Sampson and
Karagiannidis, 2002). This problem is particularly
prevalent when considering problem- (Wood, 2003),
project- (Krajcik and Blumenfeld, 2006) and studio-
(Carter and Hundhausen, 2011) based learning, in
which content is open ended and students have auton-
omy in deciding how to focus their learning. How can
each student be presented with knowledge and chal-
lenges that fit their interests and encourage curiosity?
One approach is to devote instructor time to provid-
ing personalized learning materials and advice to each
student, which is highly effective in small classrooms
but does not scale. We present the use of AI meth-
ods — specifically Natural Language Processing—for
personalized learning, based on eliciting curiosity us-
ing computational models of novelty. We contextual-
ize our models of novelty in an interactive system for
recommending course relevant publications to Uni-
versity students.
Curiosity can be defined as the desire to learn
or know. Curiosity can be both a trait and a state
(Berlyne, 1966). Curiosity-as-trait refers to an innate
desire possessed by different people to different de-
grees, while curiosity-as-state refers to a motivation
to seek novel stimuli. This latter definition is the ba-
sis for encouraging curiosity in Pique. The curiosity
state can arise from exposure to appropriately novel
stimuli, with insufficiently novel stimuli being bor-
ing and overly novel stimuli being alienating, a model
first proposed by early psychologist Wilhelm Wundt
(Berlyne, 1966). This creates a region of optimal nov-
elty within the space of possible stimuli, in which cu-
riosity is maximally likely to be stimulated. The pa-
rameters of this region are dependent on experiences,
context, and personal preference for novelty (Boyle,
1983; Kashdan and Fincham, 2004). The goal of
Pique is to stimulate the curiosity state of the student
and recommend resources that place them in a state
of maximal curiosity by combining their interests and
novelty in selecting course materials.
The Pique system is built on the principle theo-
rized by Loewenstein (Loewenstein, 1994) that de-
notes curiosity as the result of an ‘information gap’
— the distance between what is known and what is
desired to be known. This leads to a model of curios-
ity as a kind of intellectual hunger, in which small
amounts of new knowledge prime further desire to
Siddiqui, S., Maher, M., Najjar, N., Mohseni, M. and Grace, K.
Personalized Curiosity Engine (Pique): A Curiosity Inspiring Cognitive System for Student Directed Learning.
DOI: 10.5220/0010883200003182
In Proceedings of the 14th International Conference on Computer Supported Education (CSEDU 2022) - Volume 1, pages 17-28
ISBN: 978-989-758-562-3; ISSN: 2184-5026
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
17

learn, but larger amounts have a satiating effect (Kang
et al., 2009). A related notion from developmental
psychology is Vygotsky’s ‘Zone of Proximal Devel-
opment’ (Vygotsky, 1978): the space of all knowl-
edge that is adjacent to current knowledge and thus
is comprehensible given it. These theories of knowl-
edge acquisition all use spatial metaphors for describ-
ing curiosity’s influence, which suggests approaches
for how it might be operationalized. Computational
models of curiosity based on these approaches have
led to AI systems that value the unexplored and un-
explained (Schmidhuber, 2010; Merrick and Maher,
2009; Grace and Maher, 2015b; Grace and Maher,
2015a). Pique contributes to this computational mod-
eling of curiosity by proposing to stimulate the cu-
riosity of each individual student. This is then com-
bined with a representation of that student’s prefer-
ences and knowledge to produce personalized recom-
mendations.
Throughout our project, we have explored a va-
riety of algorithms for both novelty and the genera-
tion of sequences of learning resources. In this pa-
per we present two computational models of novelty
and three ways to select learning resources to stim-
ulate students’ curiosity. Each of our models are
based on the concept of unexpectedness as a cause
of novelty and surprise, which consequently leads to
curiosity (Grace et al., 2017; Grace et al., 2018).
For instance, information that students find interest-
ing but are not expecting creates a surprising response
when presented as a stimulus to their learning pro-
cess. When students are presented with information
related to their existing knowledge but contain differ-
ent perspectives, those learning materials seem novel
to them. Recently novelty and surprise have been pro-
posed as components of a new kind of recommender
system that attempts to expand its users’ preferences
(Niu et al., 2018; Adamopoulos and Tuzhilin, 2014).
In the Pique system, we use AI-based computational
models to identify novel documents from a data set
of learning resources and develop algorithms to gen-
erate a sequence of learning materials to encourage
curiosity personalized to individuals’ interests. This
approach enables instructors to personalize the learn-
ing experience after identifying the corpus of learning
materials in open ended project based learning.
The four major components of the Pique system
are illustrated in Figure 1: Learning Materials, Artifi-
cial Intelligence Methods (AI), Learner Model, and
User Experience (UX). These components are de-
scribed in Section 3. Pique was applied in undergrad-
uate and graduate courses in Human Centered Design
(HCD) as well as a Graduate Teaching Seminar for
PhD students. The Pique system was used over sev-
eral semesters, throughout which we continually de-
veloped the models of novelty and sequence gener-
ation based on student and instructor feedback. Plat-
form data from the students’ usage of Pique as well as
their reflections on the recommended learning content
were used to answer the following research questions:
• RQ1: How does the experience of using Pique
enable self-directed exploration and personalized
learning?
• RQ2: How does the experience of using Pique as-
sist students in expanding their learning interests?
The remainder of this paper describes the related
work and theoretical background (Section 2), the
components of the Pique system (Section 3), the ex-
periences of the students who used it in the classroom
(Section 4), and directions for extending this research
(Section 5).
2 BACKGROUND
Pique contributes to the broad field of AI in education.
Baker and Smith (Baker et al., 2019) identify three
perspectives on educational AI: learner-facing (which
focus on assisting students), teacher-facing (which fo-
cus on reducing teachers’ workloads), and system-
facing (which focus on institutions’ administrative
and management capabilities). Zawacki-Richter et al.
(Zawacki-Richter et al., 2019) similarly identify four
areas of AI applications in higher education: adaptive
systems and personalization, assessment and evalua-
tion, profiling and prediction, and intelligent tutoring
systems (ITSs). In this paper, we present Pique - a
unique approach to adaptive systems and personaliza-
tion in educational AI as it aims to include curiosity-
inspiring content in the students’ learning process.
Pique combines elements of the Educational Rec-
ommender Systems (i.e., recommendation of cus-
tomized course materials) and ITS approaches to pro-
viding personalized learning activities. The differ-
ence between Pique and existing educational rec-
ommender systems is that we adopt a cognitively-
inspired model of curiosity as the basis of our recom-
mended sequences of resources, rather than a focus
on explicit learning goals.
2.1 Intelligent Tutoring Systems and
Personalized Learning Technologies
The broad goal of intelligent tutoring is to leverage AI
techniques to provide the instructional capability that
adapts to the needs of individual students. To sup-
port students in effective ways, models have been de-
CSEDU 2022 - 14th International Conference on Computer Supported Education
18
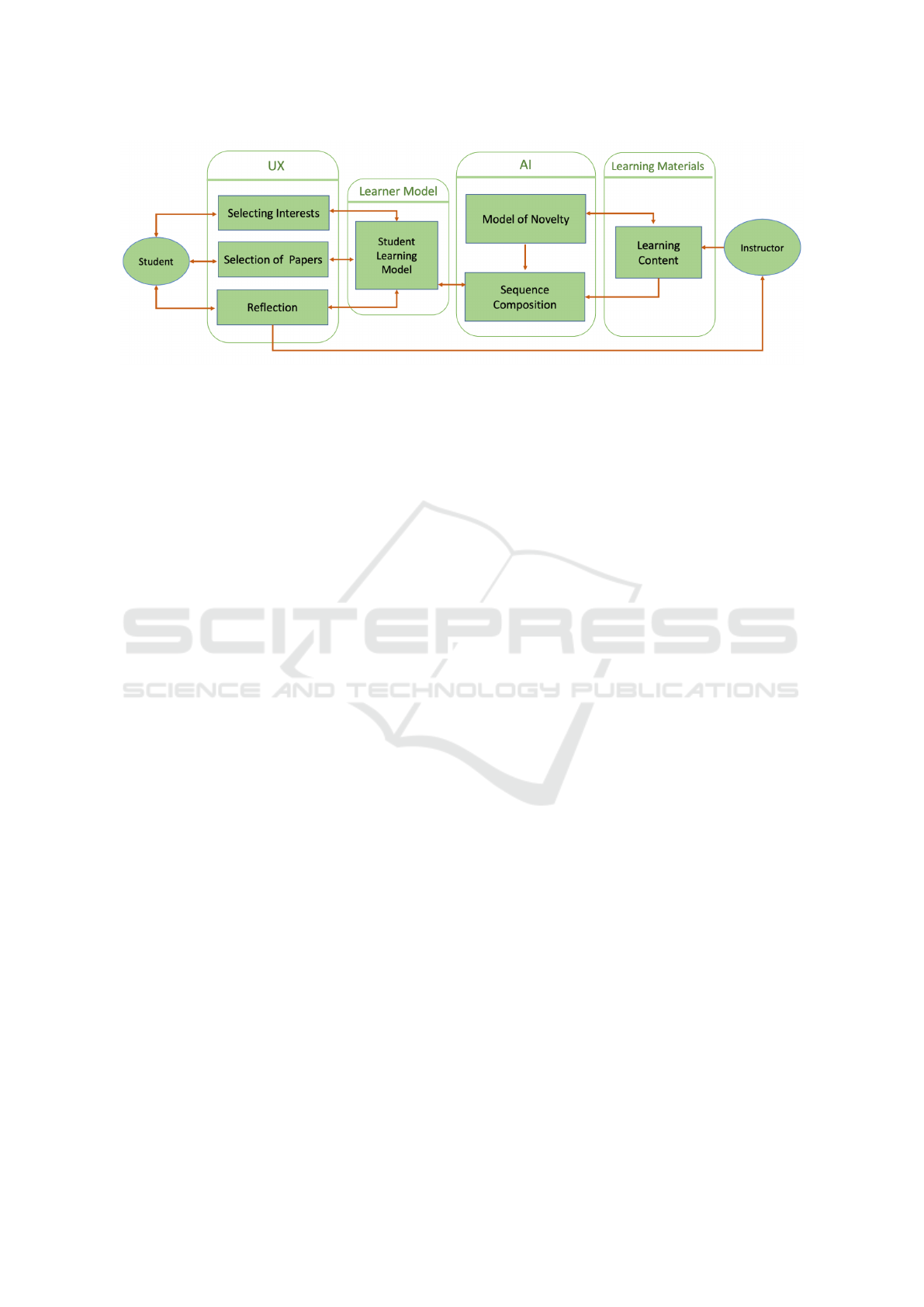
Figure 1: Architecture of the Pique Cognitive System.
veloped to distinguish students’ search behaviors (An
et al., 2020). Learning Management Systems (LMS)
can monitor students’ learning patterns and categorize
students based on their behavioral patterns (Kuo et al.,
2021; Papamitsiou and Economides, 2014). Ai et al.
(Ai et al., 2019) have applied deep knowledge models
to trace students’ knowledge status and have adopted
reinforcement learning to recommend exercises. In-
telligent tutoring systems have been developed to pro-
vide personalized feedback for learning programming
courses (Keuning et al., 2018) and to support stu-
dents’ mathematical problems solving process (Pozd-
niakov et al., 2021). While we do not present Pique
as an ITS, it can be thought of as analogous to one:
it models student preferences, represents the learning
resources to be recommended, and has a strategy for
composing resource sequences that focus on students’
motivation and maximizing their learning curiosity.
Models of student motivation have previously
been used to augment the instructional capabilities
of ITSs. Del Soldato & Boulay (Del Solato and
Du Boulay, 1995) describe an approach to planning
communication with a student performing a series of
learning tasks based on a model of the student’s mo-
tivations. They base the motivational reasoning on
Keller’s (Keller, 1987) model of motivation as con-
sisting of curiosity, challenge, confidence and control,
previously used in computer-supported collaborative
learning (Jones and Issroff, 2005). The Pique sys-
tem focuses on the first of these motivational factors:
curiosity, which is stimulated by surprise and nov-
elty. We explore the computational models of novelty
and recommend resources calculated to increase stu-
dent familiarity with concepts, but additionally aim to
elicit their surprise and curiosity.
2.2 Educational Recommender Systems
(ERS)
The goal of ERSs is to recommend learning resources,
and they can be applied in either formal or informal
educational contexts, and used by either students or
instructors. The Pique system is intended to be ap-
plied to open-ended learning tasks, which — while
part of a formal educational context — share many of
the features of informal learning. Open-ended learn-
ing tasks require students to select a scope of focus for
their work within the proposed problem space (Hill
and Land, 1998), which means that students are self-
directed to a degree, an aspect shared with informal
educational contexts.
Educational recommender systems have been
used to recommend course material for students in
Computer Science (Kose and Arslan, 2016) and Busi-
ness and Administration studies (Hall Jr and Ko,
2008). Cobos et al. (Cobos et al., 2013) have de-
veloped a recommendation system for the instruc-
tors to prepare course content. Educational recom-
mender systems include explainability to justify the
recommendation. Barria-Pineda et al. (Barria-Pineda
et al., 2019) have helped students minimize misun-
derstandings related to solving programming prob-
lems and have explained the reasoning behind the
recommended learning activities. Barria Pineda and
Brusilovsk (Barria Pineda and Brusilovsky, 2019)
identify that students spend more time on the ex-
ploratory interface and suggest the effectiveness of
the transparent recommendation process. In Pique,
we show students the calculated novelty scores of the
papers to facilitate students’ paper selection process.
Personalized Curiosity Engine (Pique): A Curiosity Inspiring Cognitive System for Student Directed Learning
19

3 THE PIQUE SYSTEM
3.1 The Learning Materials Component
The Learning Materials component is the source
of documents provided by the instructor for a spe-
cific course. For Pique, these documents are repre-
sented as unstructured text, drawn from articles from
relevant conferences, journals, and digital libraries.
The preparation of the learning materials for use in
Pique includes data collection, dataset preparation,
and dataset description to prepare the text documents
for applying computational models of novelty.
Pique has been included in two courses in a Com-
puter Science program. The first, ‘Human Centered
Design’, has a focus on human computer interac-
tion. The learning materials are papers published in
the ACM Digital Library under the classification of
Human Centered Computing. The second, ‘Gradu-
ate Teaching Seminar’, has a focus on educational re-
search in computer science, and the relevant learning
materials are papers published in the ACM SIGCSE
(Special Interest Group on Computer Science Educa-
tion) proceedings.
For the Human Centered Design Course we ex-
tracted 9,452 conference, journal and magazine pa-
pers with publication dates from 2008-2018. For each
publication we collected the following metadata: ti-
tle, ISSN, location, abstract, publisher, address, ACM
ID, journal, URL, volume, issue date, DOI, number,
month, year, pages, and tags/keywords. For the Grad-
uate Teaching Seminar we extracted 1172 papers with
publication dates from 2008-2018, with the following
metadata: title, author, conference, year, DOI, key-
words, and abstract.
3.2 The AI Component
The AI component of the Pique system applies NLP
and novelty detection algorithms to rank the novelty
of items in the learning content module as a basis for
generating a personalized sequence of learning ma-
terials. The AI component has two subcomponents:
the Model of Novelty and the Sequence Composition.
The Model of Novelty module receives a set of doc-
uments from the Learning content module and gener-
ates novelty scores for each of the learning items in
the corpus. This subcomponent uses a list of features
to represent each learning item based on topic models
or keywords associated with each item. These fea-
tures provide the basis for computing a novelty score
for each item. The Sequence Composition subcom-
ponent uses the novelty score, information about the
learner’s interests, and the information from their in-
teraction with Pique to generate a sequence of learn-
ing materials. These materials are personalized to en-
courage the learner’s curiosity and their intrinsic mo-
tivation to explore the learning resources.
3.2.1 Models of Novelty
In developing Pique, we implemented two compu-
tational models of novelty, each based on the prob-
abilities of keywords and topic models associated
with each document. We refer to these models as
the ‘Keyword co-occurrence model’ and the ‘Topic
co-occurrence model’. The keyword co-occurrence
model represents each item in the learning materials
as a bag of keywords. The topic co-occurrence model
represents each item in the learning materials as a vec-
tor of topic distributions by applying a topic modeling
algorithm (Blei and Lafferty, 2007) to the corpus of
learning materials. This section describes how these
computational approaches generate novelty scores for
the corpus of learning materials provided by the in-
structors.
Keyword Co-occurrence Model. The keyword co-
occurrence model is based on the probability of the
co-occurrence of each pair of keywords in the cor-
pus. The challenge in this model is to identify the
keywords for the learning materials. In our corpus,
each paper has two fields in the metadata that can
serve as the keywords for this model: the keywords
selected from the ACM’s Computing Classification
System (CCS) and the author defined keywords. The
ACM Computing Classification System has been de-
veloped as a poly-hierarchical ontology that results in
common topics relevant to all papers, but they do not
specifically represent the content in each paper. Con-
versely, author-defined keywords are defined specifi-
cally for each paper, but do not follow any standard
representation.
To calculate the probability of keyword co-
occurrence, we synthesized the list of keywords from
each paper into a master list of keywords for the cor-
pus. Due to the large number of keywords in the mas-
ter list of keywords, we manually curated a reduced
set that can be used to create a mapping from a user’s
interests to the concepts in the learning materials. In
reducing the number of keywords we tried to target
the largest number of keywords that are reasonable
to present to students for selection: too many key-
words would be overwhelming, and not enough key-
words would not represent the dataset with enough fi-
delity. In our pilot study of using Pique in the Human-
Centered Design course, when using the CCS classi-
fication as keywords, we gave students 118 different
CSEDU 2022 - 14th International Conference on Computer Supported Education
20

keywords to select from. This was perceived by the
students as too many, and it resulted in a very sparse
user preference vector. As a result, we reduced this
set in subsequent semesters. We manually replaced
keywords that were not in the reduced list to be the
most relevant keyword in the reduced set. Across the
semesters, feedback from students indicated that our
reduced set of 35-55 keywords was sufficient for stu-
dents to express their interests.
With the keywords for each paper, we created a
bag-of-keywords representation to calculate the co-
occurrence of keywords for measuring novelty. First
we eliminated papers that had fewer than two key-
words. We then measured the probability of each pair
of keywords appearing together in the corpus. We
used these probabilities (see eq. 1, eq. 2) to calcu-
late the probability of keywords x
1
and x
2
occurring
together in the corpus (eq. 3) and took its logarithm as
the novelty score for that pair of keywords (as in (Niu
et al., 2018), (Bouma, 2009)). We prepared a novelty
matrix, NM (eq. 4) by applying this process to all
pairs of keywords in the corpus. This matrix serves
as the look-up table for identifying the novelty scores
among the keyword pairs in the papers. To convert
from this keyword-pair novelty score to the score for
a paper, we took the highest value of all keyword pairs
present in the paper (eq. 5) as surprising combinations
stand out (Grace et al., 2017).
prob(x
1
) =
# o f papers have x
1
# o f total papers
(1)
prob(x
2
) =
# o f papers have x
2
# o f total papers
(2)
prob(x
1
, x
2
) =
# o f papers have both x
1
and x
2
# o f total papers
(3)
NM(x
1
, x
2
) =
log
2
(prob(x
1
, x
2
))
prob(x
1
) ∗ prob(x
2
)
(4)
NoveltyScore P
n
= max(NM(x
1
, x
2
), NM(x
1
, x
3
), ...)
(5)
Topic Co-occurrence Model. The Topic Co-
occurrence Model calculates the novelty score based
on frequency and proportion of topics present in the
corpus. We applied the topic modeling approach on
the abstract of the papers. Topic modeling produces a
set of ‘topics’ each comprising a distribution over all
the words in the corpus (Grace et al., 2017). The ad-
vantage to using topic modeling compared to author
defined keywords is that there is consistency in the
identification of features across the entire data set in
topic modeling, where author defined keywords pro-
vide features relevant to the author of a single item in
the corpus.
We used the R package ‘STM’ (Structural Topic
Model) (Roberts et al., 2019), a topic model extension
that is equivalent to CTM (Correlated Topic Model)
(Blei and Lafferty, 2007). Correlated topic models
relax the assumption made by earlier topic modeling
algorithms that all the topics in a corpus are indepen-
dent and therefore no one pair of topics is more likely
to occur together in a document than any other. The
STM algorithm was run on the dataset to obtain a vec-
tor of topic proportions for each paper and a topic
correlation matrix. Each paper in the corpus is rep-
resented with a 20-dimensional vector containing the
prevalence of topics in that document. The correlation
matrix is a 20 × 20 matrix including the correlation
coefficient for all topic pairs.
We calculate the novelty of a document as equal
to the most novel concept or combination of concepts
within that material (Grace et al., 2017). The novelty
of a document is the highest negative correlation co-
efficient among all pairs of topics present in that doc-
ument (above a certain threshold), weighted by the
proportion of the document which contains that pair
(Grace et al., 2017). In order to determine whether
a topic is significantly present in a document a topic
proportion threshold of 0.1 is used (i.e. the document
should be at least 10% of that topic). This novelty
formula is based on previous work in topic-model
approaches to novelty (Grace et al., 2017). Equa-
tion 6 shows the formula for a paper p given p =
[t
i
, t
j
, . . . , t
n
] as the set of topics significantly present
in p. The pair of topics with the highest negative cor-
relation coefficient are denoted by t
i
and t
j
. This co-
efficient is normalized against the most novel pair of
topics in the whole corpus (here denoted t
a
and t
f
) and
then weighted by the proportions of each topic in p to
calculate the novelty score.
NoveltyScore P
n
=
CovMat
(t
i
,t
j
)
CovMat
(t
a
,t
f
)
×2(min(prop(d, t
i
), prop(d, t
j
))) (6)
CovMat is the covariance matrix obtained from
the STM model. CovMat
(t
i
,t
j
)
is the correlation of the
document’s most atypical topic combination (t
i
, t
j
),
and CovMat
(t
a
,t
f
)
is the correlation of the most atypi-
cal topic combination among the whole corpus (t
a
and
t
f
). prop(d, t) is the proportion of document d that
consists of topic t. This corresponds to the novelty
of the document’s most novel topic combination, rela-
tive to the corpus’s most novel combination, weighted
by how much of the document consists of that com-
bination. The reason for using the minimum of the
Personalized Curiosity Engine (Pique): A Curiosity Inspiring Cognitive System for Student Directed Learning
21

two topic proportions rather than their average is to
prevent favoring documents that just passed the sig-
nificance threshold with one topic, and were thus not
particularly novel in combining it with another, much
more weighted topic (Grace et al., 2017). In the Top-
ics Co-occurrence Model, the novelty rating for docu-
ments containing many relatively novel topic combi-
nations will be higher than for documents containing
only a little of the most novel pair of topics (Grace
et al., 2017). Equation 6 assigns a novelty score of
1 to a document that is made up of 50% of each t
i
and t
j
. The equation assigns 0 as the novelty score
to the document when the rarest topic combination
in it is independent, and assigns negative scores when
the only topic combinations above the threshold in the
document are positively correlated.
3.2.2 Sequence Composition
The purpose of the Sequence Composition subcom-
ponent is to take the novelty ratings of each document
in the corpus and construct a sequence of learning re-
sources that will maximize the chance of a student
experiencing optimal novelty. The Sequence Compo-
sition subcomponent generates a sequence of learn-
ing resources to support student-directed learning and
to stimulate students’ curiosity about learning. Dur-
ing the course of our project we explored three se-
quence generator models, which we call the ‘Origin-
Destination model’, the ‘Destination model’, and the
‘User-Directed model’.
Pique generates a personalized sequence of nine
documents in sets of three papers from the corpus of
learning resources in the Learning Materials compo-
nent, based on information from the Learner Model.
Students choose one paper from each set of three, read
it, and reflect on it before they are presented with the
next set. The different sequence generator models are
based on different representations of student interests.
The Destination Model uses a single set of
student-specified interests as the input to the algo-
rithm, while the Origin-Destination Model uses two
student-specified sets of keywords: one that they self-
report as already knowing about (the ‘origin’ set) and
one that they want to learn more about (the ‘desti-
nation’) set. The User-Directed Model builds on the
Origin-Destination Model to include other keywords
from the papers most recently selected by the student.
The sequence generator use these keywords to rep-
resent student preference, and combine that with the
novelty score for each paper to select and sequence
learning resources with the goal of inspiring curios-
ity.
Destination Model. The Destination Model priori-
tizes what students desire to learn. It recommends a
set of nine novel documents containing information
related to their stated desires. When used with our
keyword co-occurence novelty model, the student in-
terests can be directly mapped to corpus keywords.
When using the topic co-occurrence model, a map-
ping was manually built between the keyword set we
had constructed and the automatically generated topic
model topics. Here we refer to ‘novel documents’
generally, without specifying which of the novelty
models labeled them as such.
Students select their learning interests, which be-
come the destination set, D. The destination model
then identifies candidate documents from the learning
materials corpus for which the top N topics within
that document include at least one of the user’s se-
lections. After some experimentation we decided on
N=3, as most documents in our corpus included at
least this many topics at reasonable proportions. From
this set of candidate documents the nine most novel
papers are selected and sorted based on their novelty,
with the most novel last. In this way the Destination
Model returns nine documents as output containing
information that students’ want to learn, starting with
a document of moderate novelty but then scaling up
to highly-novel documents as the student reads more
and learns about the topics they are interested in.
Origin-destination Model. The Origin-
Destination model intends to inspire students to
explore learning materials that contain some infor-
mation that they already know, combined with some
new information that they don’t. This is based on
ideas from educational psychology like Vygotsky’s
Zone of Proximal Development (Vygotsky, 1978), in
which new material is only learnable if it is at least
somewhat connected to topics already known. The
model selects a sequence that interpolates from what
the student already knows to what they want to know.
This recommendation generator is inspired from the
surprise walks algorithm (Grace et al., 2018) that
similarly tries to interpolate from an unsurprising
source to a surprising destination.
The Origin-Destination Model stimulates individ-
uals’ curiosity by presenting learning materials in
three steps: ‘close’, ‘far’, and ‘farther’. By rec-
ommending the learning materials step by step, the
model assists students to learn new materials similar
to what they already know and inspire them to explore
without recommending materials that are so novel as
to be unfamiliar or alien for them (Berlyne, 1966).
In the first step, the model recommends papers that
are similar to what students already know and labels
CSEDU 2022 - 14th International Conference on Computer Supported Education
22

those papers as the ‘close’ category of learning ma-
terials for that student. In the second step, the model
recommends papers that are similar to both what the
students already know and what they want to learn,
and labels those papers as the ‘far’ category. Finally,
in the third step, the model recommends papers that
contain materials related only to what students want
to learn, and labels those papers as the ‘farther’ cate-
gory.
In the ‘close’ category, the model identifies can-
didate papers that contain at least one common key-
word (or topic) from the students’ ‘source’ interest
set. The model uses the k-means algorithm and clus-
ters the candidate papers based on their novelty scores
to distinguish papers with three novelty levels: high,
medium, and low. The model also calculates the pa-
per’s familiarity score, which is the number of key-
words in common between the paper and the ‘origin’
set of topics/keywords the student already knows. The
papers with highest familiarity scores in each novelty
level are selected. The algorithm recommends one
low, one medium, and one high novelty paper
In the ‘far’ category step, the model recommends
another three papers intended to extend students’
learning from what they are familiar with to the new
topics they desire to learn. The candidate papers of
this category contain at least one common keyword
from the ‘origin’ keywords set (O) and at least one
common keyword from the destination keywords set
(D). The model uses the same clustering approach to
identify low, medium, and high novelty candidate pa-
pers, and identifies the candidate paper in each level
with the highest number of common keywords.
In the ‘farther’ category step, the model presents
papers that contain information that students desire to
learn. The candidate papers of this category contain at
least one keyword from the destination keywords set
(D), and are categorized into three levels of novelty
just like the other two sets.
User-directed Model The User-Directed model is
an adaptation of the Origin-Destination Model that
considers students’ decisions during the recommen-
dation process to recommend materials aligned with
their evolving interests. The model recommends
papers step by step (close, far, and farther) as in
the Origin-Destination model, but additionally keeps
track of students’ selections of papers from the previ-
ous step. The keywords in the papers from the previ-
ous step are used to prioritize similar resources in the
recommendations of the next step.
Specifically, the User-Directed model filters the
candidate papers for the far step to those that share
at least one keyword papers selected in the close step.
Likewise, the model first identifies candidate papers
for the farther step that contain at least one keyword
match with the keywords of the paper selected in the
far step. Other than this additional filtering, the model
is identical to the Origin-Destination model: it recom-
mends one low, one medium, and one high novelty
paper in each of the close, far, and farther steps.
3.3 The Learner Model Component
The Learner Model in Pique is primarily focussed
on collecting information about the learner to sup-
port the selection and presentation of learning ma-
terials as well as information needed to analyze the
use of Pique. The Learner model is not a comprehen-
sive model of the learner. This component stores two
kinds of information: information about the students
and how they have used Pique to date. Most infor-
mation about students remains constant: their name,
ID, email address, and course. The IDs are auto-
matically generated by the Pique system and serve
to de-identify students as required by our IRB ap-
proval. The final component of the student profile is
the one that can change: their interests, which they
select when they start using Pique but are prompted
to change each recommendation ‘cycle’. Each time
the student uses Pique, their data is updated with a
new cycle record, containing timestamps, the papers
they selected, the options they chose from, and their
reflections. Their reflections comprise responses to
three questions: 1) why the student has selected the
paper, 2) whether the selected paper matches their in-
terests, and 3) what topics the student expects to learn
from the paper when they read it.
3.4 The UX Component of Pique
The User Experience Component of Pique supports
students’ interaction with the following three subcom-
ponents: Selecting interests, Selection of papers, and
Reflection.
3.4.1 Selecting Interests
The Selecting Interests subcomponent captures stu-
dents’ interest by prompting them to identify what
they want to know. This prompt assists students to
formulate their learning goals and provide them more
control over their learning choices and enables self-
directed learning. Figure 2 shows the user interface
with the learning options for the students as they were
in the Graduate Teaching Seminar course.
Personalized Curiosity Engine (Pique): A Curiosity Inspiring Cognitive System for Student Directed Learning
23

Figure 2: UX for selecting interests in Pique.
3.4.2 Selection of Papers
The Selection of Papers subcomponent of Pique en-
ables students’ self-regulated learning, with the inten-
tion of stimulating their intrinsic motivation to learn
and explore. This module presents the papers that
are recommended by the sequence composition mod-
ule of Pique’s AI component. Pique presents the nine
papers in sets of three, based on the Sequence Com-
position subcomponent (see Section 3.2.2). Figure 3
shows an example of papers being recommended in
the Graduate Teaching Seminar course based on the
Orign-Destination sequence composition model: the
top three are closely related to what the student al-
ready knows, the middle three are related to both what
they know and what they are interested in, and the bot-
tom three what they are interested in only. The Selec-
tion of Papers subcomponent informs students about
how novel a particular paper is, and allows them to
manually choose more or less novel papers by select-
ing the drop-down menu labeled ‘show me papers’ in
the top right corner of Figure 3.
Figure 3: The UX for selecting learning content based on
interests and novelty scores.
3.4.3 Reflection
The third subcomponent of the Pique UX compo-
nent is Reflection. Cognitive studies of students
demonstrate that reflection is key to effective learning
[(Sch
¨
on, 2017), (Kolb, 1999), (Cowan, 2006)]. The
Pique system includes two types of reflection: one ap-
pears when students select a paper to read (see Figure
4), and one at the end of the semester. The first allows
them to reflect on their paper selection and to describe
what they expect to learn from it.
The second type of reflection asks students to re-
flect on their overall learning experience. Students
are asked to summarize the papers they read and cat-
egorize those papers into groups. Students are asked
to identify the paper they found most interesting and
justify why. This reflection allows students to orga-
nize their newly acquired knowledge where the learn-
ing paths are constructed by the students rather than
the instructors. It was also critical for evaluating the
impact of this educational innovation on the student
experience.
Figure 4: Pique nudges students to reflect on their paper
selection and learning expectations.
4 THE COURSE EXPERIENCE
OF USING PIQUE
In this section, we present the experiences of students
who have used Pique in the classroom to respond to
the Research Questions presented in Section 1. We
used Pique over four semesters in both undergradu-
ate and graduate courses in Human Centered Design
as well as a PhD course, a Graduate Teaching Sem-
inar. In the Human Centered Design course students
were asked to use Pique for six weeks, and had to sub-
mit weekly and end of semester writing assignments
about the papers they had read. Each week they were
CSEDU 2022 - 14th International Conference on Computer Supported Education
24

asked to submit a summary of the three papers they
downloaded and read, and identify the most interest-
ing paper among the three. For the end of semester
report, the students were asked to describe their expe-
rience of using Pique, what they learnt, and the most
interesting paper they found (and why). For the Grad-
uate Teaching Seminar course, students were asked
to use the Pique system for the whole semester, but
submitted only a final report without any weekly sub-
missions. This was due to the PhD students’ greater
familiarity with reading published articles, as well as
their overall greater autonomy as learners.
In response to our first research question concern-
ing how the use of Pique helped enable self-directed
exploration we investigated how the student cohort
differed in the resources they explored, as a measure
of how self-directed their experiences were. In Table
1 we summarize our results. Though students’ op-
tions for selecting interests remain constant (39 and
55 interests in Human Centered Design and Teach-
ing Seminar courses, respectively), we found that stu-
dents were presented with very diverse sequences of
learning resources. Pique recommended a total of
621 unique papers for one semester of the Gradu-
ate Teaching Seminar course, even though that course
only included five students. 55% of those papers were
recommended to at least two students, due to overlaps
in topics of interest. Those five students selected a
total of 66 papers to read, with 86% of the selected
papers being selected by only one student. Across all
four courses we saw 72% of recommended papers be-
ing recommended to at least another student, but the
selections made by students were highly diverse, with
70% of the selected papers being unique to that indi-
vidual student.
Our second research question asked how using
Pique assisted students in expanding their learning in-
terests. In response to this we investigated the change
in students’ interests over time, illustrated in Figure
5. The top two sub-figures are for HCD courses
(Spring and Fall) and the bottom two sub-figures are
for Graduate Teaching Seminar courses (Spring and
Fall), where X-axis represent the number of Pique
cycles and Y-axis represents the average cumulative
growth of interest selections. We calculated the num-
ber of interests selected by each student during each
cycle. We aggregated this across students within a co-
hort to give the average number of interests selected
by the students in that cycle. The cumulative num-
ber of interests in Figure 5 shows the expansion of
stated interests over the semester. When starting to
use Pique, total students in the HCD courses selected
an average of just four interests. The searching of
learning interests increased as students used the Pique
system, and at the end of the semester all students had
explored an average of 67 interests. Similarly, total
students in the Graduate Teaching Seminar on average
started with only two interests, and over the semester
their average number of searching learning interests
increased to 42.
Figure 5: The growth of learning interests over the courses.
We noticed a difference between the students in
the HCD courses and those in the Graduate Teaching
Seminar, illustrated in Figure 6. The top two sub-
figures are for HCD courses (Spring and Fall) and
the bottom two sub-figures are for Graduate Teach-
ing Seminar courses (Spring and Fall), where X-axis
represent the number of Pique cycles and Y-axis rep-
resents the percentage of students searched for new
interests that they had not selected in earlier Pique
cycles. The students in the HCD courses were un-
dergraduate and graduate students who initially ex-
panded their learning interests and over time they re-
duced the number of new interests. In contrast, the
students in the Graduate Teaching Seminar courses
were PhD students who kept exploring new interests.
For instance, all the PhD students in the Fall semester
of Graduate Teaching Seminar continued to add new
interests until the end of the semester. 71% of Grad-
uate Teaching Seminar PhD students in the Spring
semester included new interest in their 8th Pique cy-
cle, but only 18% of the undergraduate students in the
HCI course continued exploring in the 8th Pique cy-
cle. This result indicates that students use the Pique
system differently to expend their learning selections.
After the students had finished using Pique, stu-
dents were asked to reflect on which paper from the
system they found most interesting and why. Two re-
searchers performed a thematic analysis on students’
written responses to identify meaningful patterns in
the data (Braun and Clarke, 2006). The use of mul-
tiple coders provided investigator triangulation to our
analysis (Patton, 1999). To establish a broad consen-
Personalized Curiosity Engine (Pique): A Curiosity Inspiring Cognitive System for Student Directed Learning
25

Table 1: Distribution of learning materials to personalize learning.
Course name
Graduate
Teaching
Seminar
Graduate
Teaching
Seminar
Human
Centered
Design
Human
Centered
Design
Semester Spring 2020 Fall 2020 Spring 2020 Fall 2020
Number
of students
24 5 12 12
Number of unique
learning sequences
generated by students
24 5 12 12
Total papers selected
by students over
the Pique cycles
221 66 76 77
% of selected papers
uniquely picked
by individuals
50%
(111 papers)
86%
(57 papers)
71%
(54 papers)
74%
(57 papers)
Total papers recommended
by Pique
1987 612 729 774
% of papers recommended
to at least one other
84%
(1669 papers)
54%
(333 papers)
75%
(548 papers)
72%
(558 papers)
% of papers recommended
to only one student
16%
(318 papers)
46%
(279 papers)
25%
(181 papers)
28%
(216 papers)
Figure 6: Percentage of students searching for new learning
interests over the pique cycles.
sus, the two researchers conducted a parallel coding
workshop on the first 10% of the written responses.
After identifying this initial set of themes, they each
coded the rest of the data separately and then con-
verged on a set of collaboratively authored themes
through follow-up workshops.
Through this analysis we identified three major
themes underlying why most students found papers
interesting: novelty, personal relevance, and curios-
ity. The first theme captured how students found pa-
pers interesting because of the novelty and innova-
tion of the idea presented in it. The second theme
captured how students found papers particularly in-
teresting when they could connect its contributions or
implications to their current work or personal experi-
ence. For example, one student found a paper describ-
ing a VR gaming application named ‘Spider Hero’ in-
teresting because he was a huge Spiderman fan. The
third theme captured how the recommended papers
made students curious about the research field as a
whole (HCI or computing education) and helped to
grow their interest in the field. For example, one stu-
dent expressed that they learned something new from
each of the recommended papers, and became so curi-
ous that they did extensive further personal research to
learn more about those specific topics. We observed
that this curiosity theme was related to the idea of stu-
dents connecting their class lessons with the recom-
mended papers. For example, one student learned the
concept of a ‘Wizard-of-Oz’ study through the HCI
class lectures and got excited when he found the same
concept in a research paper. Taken overall, these writ-
ten responses show that the recommended papers mo-
tivated students to explore and learn more in the do-
main.
5 CONCLUSION AND FUTURE
WORK
We present a cognitively inspired system architecture,
Pique, that presents students with personalized se-
quences of novel learning resources. We have shown
that these sequences encourage curiosity and may be
CSEDU 2022 - 14th International Conference on Computer Supported Education
26

helpful to support self-directed learning. Pique uses
computational models of novelty to identify docu-
ments from a corpus of learning materials that are
both relevant to the student’s interest and novel with
respect to the corpus. Pique is effectively an educa-
tional recommender system with a goal of inspiring
individuals’ curiosity to learn rather than shepherding
them through a specific curriculum.
Through our four-semester evidence-based explo-
ration of how to inspire students’ curiosity, we devel-
oped two separate computational models of novelty:
one based on keyword co-occurrence and one based
on the co-occurrence of topics from a topic model-
ing algorithm. These computational models rely on
the same underlying information theoretic approach
to novelty or surprise as features that negatively cor-
relate, but differ in the way we generated a keyword
or topic representation of the documents. Both had
their strengths and their weaknesses, and each was
able to identify some surprising-seeming papers that
the other missed. In future work we aim to explore
a variety of other approaches to representing our cor-
pus, including NLP and machine learning techniques.
These new representations would extend our current
computational models of learning resource novelty.
Throughout the Pique project we also developed
three recommendation models: one based only on
the student’s stated interests (their ‘destination’), one
based on taking them on a journey from what they
already knew (their ‘origin’) to their interests (their
‘destination’ again), and one based on blending that
origin-destination effect with similarity to the things
they’ve recently explored. Each of these recommen-
dation models combined student preferences with our
computational models of novelty to encourage curios-
ity in the learning process. We did not compare our
sequence recommendation models directly, although
we do believe, from the evidence of using them in the
classroom, that the latter two models both offer ad-
vantages over their predecessors.
This paper presents a proof of concept and deploy-
ment of Pique, a personalized curiosity engine for ed-
ucation. A limitation of our study is that we did not
collect data on how much time the students spent on
reading the papers before reflecting on them. From
evaluating the experiences of students who used Pique
extensively as part of their courses, we identified three
aspects that made recommended learning materials
interesting: how novel they were, how personally rel-
evant they were, and the curiosity and further self-
directed learning that they evoked. These findings are
evidence of how curiosity can be elicited from stu-
dents as part of a course experience, at least when
self-directed and open-ended engagement with learn-
ing resources is desirable. While we cannot claim
that student curiosity was entirely due to Pique, we
conclude that the approach of encouraging curiosity
Pique shows promise for future research on computa-
tional novelty in open-ended learning environments.
REFERENCES
Adamopoulos, P. and Tuzhilin, A. (2014). On unexpected-
ness in recommender systems: Or how to better ex-
pect the unexpected. ACM Transactions on Intelligent
Systems and Technology (TIST), 5(4):1–32.
Ai, F., Chen, Y., Guo, Y., Zhao, Y., Wang, Z., Fu, G.,
and Wang, G. (2019). Concept-aware deep knowl-
edge tracing and exercise recommendation in an on-
line learning system. International Educational Data
Mining Society.
An, S., Bates, R., Hammock, J., Rugaber, S., Weigel,
E., and Goel, A. (2020). Scientific modeling using
large scale knowledge. In International Conference
on Artificial Intelligence in Education, pages 20–24.
Springer.
Baker, T., Smith, L., and Anissa, N. (2019). Educ-ai-tion
rebooted? exploring the future of artificial intelligence
in schools and colleges. Retrieved May, 12:2020.
Barria-Pineda, J., Akhuseyinoglu, K., and Brusilovsky,
P. (2019). Explaining need-based educational rec-
ommendations using interactive open learner mod-
els. In Adjunct Publication of the 27th Conference
on User Modeling, Adaptation and Personalization,
pages 273–277.
Barria Pineda, J. and Brusilovsky, P. (2019). Making edu-
cational recommendations transparent through a fine-
grained open learner model. In Proceedings of Work-
shop on Intelligent User Interfaces for Algorithmic
Transparency in Emerging Technologies at the 24th
ACM Conference on Intelligent User Interfaces, IUI
2019, Los Angeles, USA, March 20, 2019, volume
2327.
Berlyne, D. E. (1966). Curiosity and exploration. Science,
153(3731):25–33.
Blei, D. M. and Lafferty, J. D. (2007). A correlated topic
model of science. The annals of applied statistics,
1(1):17–35.
Bouma, G. (2009). Normalized (pointwise) mutual in-
formation in collocation extraction. Proceedings of
GSCL, 30:31–40.
Boyle, G. J. (1983). Critical review of state-trait curiosity
test development. Motivation and Emotion, 7(4):377–
397.
Braun, V. and Clarke, V. (2006). Using thematic analysis
in psychology. Qualitative Research in Psychology,
3(2):77–101.
Carter, A. S. and Hundhausen, C. D. (2011). A review of
studio-based learning in computer science. Journal of
Computing Sciences in Colleges, 27(1):105–111.
Cobos, C., Rodriguez, O., Rivera, J., Betancourt, J., Men-
doza, M., Le
´
on, E., and Herrera-Viedma, E. (2013).
Personalized Curiosity Engine (Pique): A Curiosity Inspiring Cognitive System for Student Directed Learning
27

A hybrid system of pedagogical pattern recommenda-
tions based on singular value decomposition and vari-
able data attributes. Information Processing & Man-
agement, 49(3):607–625.
Cowan, J. (2006). On becoming an innovative university
teacher: Reflection in action: Reflection in action.
McGraw-Hill Education (UK).
Del Solato, T. and Du Boulay, B. (1995). Implementation
of motivational tactics in tutoring systems. Journal of
Artificial Intelligence in Education, 6:337–378.
Grace, K. and Maher, M. L. (2015a). Specific curiosity as a
cause and consequence of transformational creativity.
In ICCC, pages 260–267.
Grace, K. and Maher, M. L. (2015b). Surprise and reformu-
lation as meta-cognitive processes in creative design.
In Proceedings of the third annual conference on ad-
vances in cognitive systems ACS, page 8.
Grace, K., Maher, M. L., Davis, N., and Eltayeby, O.
(2018). Surprise walks: Encouraging users towards
novel concepts with sequential suggestions. In Pro-
ceedings of the 9th International Conference on Com-
putational Creativity (ICCC 2018). Association of
Computational Creativity.
Grace, K., Maher, M. L., Mohseni, M., and PEREZ
Y PEREZ, R. (2017). Encouraging p-creative be-
haviour with computational curiosity. ICCC.
Hall Jr, O. P. and Ko, K. (2008). Customized content deliv-
ery for graduate management education: Application
to business statistics. Journal of Statistics Education,
16(3).
Hill, J. R. and Land, S. M. (1998). Open-ended learning
environments: A theoretical framework and model for
design.
Jones, A. and Issroff, K. (2005). Learning technologies:
Affective and social issues in computer-supported
collaborative learning. Computers & Education,
44(4):395–408.
Kang, M. J., Hsu, M., Krajbich, I. M., Loewenstein,
G., McClure, S. M., Wang, J. T.-y., and Camerer,
C. F. (2009). The wick in the candle of learning:
Epistemic curiosity activates reward circuitry and en-
hances memory. Psychological science, 20(8):963–
973.
Kashdan, T. B. and Fincham, F. D. (2004). Facilitating cu-
riosity: A social and self-regulatory perspective for
scientifically based interventions.
Keller, J. M. (1987). Strategies for stimulating the motiva-
tion to learn. Performance and instruction, 26(8):1–7.
Keuning, H., Jeuring, J., and Heeren, B. (2018). A system-
atic literature review of automated feedback genera-
tion for programming exercises. ACM Transactions
on Computing Education (TOCE), 19(1):1–43.
Kolb, D. A. (1999). Learning style inventory. McBer and
Company Boston, MA.
Kose, U. and Arslan, A. (2016). Intelligent e-learning sys-
tem for improving students’ academic achievements
in computer programming courses. The International
journal of engineering education, 32(1):185–198.
Krajcik, J. and Blumenfeld, P. C. (2006). The cambridge
handbook of the learning sciences. r. keith sawyer.
Kuo, R., Krahn, T., and Chang, M. (2021). Behaviour
analytics-a moodle plug-in to visualize students’
learning patterns. In International Conference on In-
telligent Tutoring Systems, pages 232–238. Springer.
Loewenstein, G. (1994). The psychology of curiosity: A
review and reinterpretation. Psychological bulletin,
116(1):75.
Merrick, K. E. and Maher, M. L. (2009). Motivated rein-
forcement learning: curious characters for multiuser
games. Springer Science & Business Media, .
Niu, X., Abbas, F., Maher, M. L., and Grace, K. (2018).
Surprise me if you can: Serendipity in health informa-
tion. In Proceedings of the 2018 CHI Conference on
Human Factors in Computing Systems, pages 1–12.
Papamitsiou, Z. and Economides, A. A. (2014). Learn-
ing analytics and educational data mining in prac-
tice: A systematic literature review of empirical ev-
idence. Journal of Educational Technology & Society,
17(4):49–64.
Patton, M. (1999). Enhancing the quality and credibil-
ity of qualitative analysis. Health services research,
34:1189–1209.
Pozdniakov, S., Posov, I., and Anton, C. (2021). Interaction
of human cognitive mechanisms and “computational
intelligence” in systems that support teaching math-
ematics. In International Conference on Intelligent
Tutoring Systems, pages 259–266. Springer.
Roberts, M. E., Stewart, B. M., and Tingley, D. (2019). Stm:
An r package for structural topic models. Journal of
Statistical Software, 91(1):1–40.
Sampson, D. and Karagiannidis, C. (2002). Personalised
learning: educational, technological and standarisa-
tion perspective. Digital Education Review, (4):24–
39.
Schmidhuber, J. (2010). Formal theory of creativity, fun,
and intrinsic motivation (1990–2010). IEEE Transac-
tions on Autonomous Mental Development, 2(3):230–
247.
Sch
¨
on, D. A. (2017). The reflective practitioner: How pro-
fessionals think in action. Routledge.
Vygotsky, L. (1978). Interaction between learning and de-
velopment. Readings on the development of children,
23(3):34–41.
Wood, D. F. (2003). Problem based learning. Bmj,
326(7384):328–330.
Zawacki-Richter, O., Mar
´
ın, V. I., Bond, M., and Gou-
verneur, F. (2019). Systematic review of re-
search on artificial intelligence applications in higher
education–where are the educators? International
Journal of Educational Technology in Higher Educa-
tion, 16(1):1–27.
CSEDU 2022 - 14th International Conference on Computer Supported Education
28
